它来了它来了,它带着 mask 做生成了~
SegGuidedDiff:提出一种用于解剖学可控医学图像生成的扩散模型,在每个采样步骤都遵循多类解剖分割掩码并结合了随机掩码消融训练算法,可助力乳房 MRI 和 腹部/颈部到骨盆 CT 等任务涨点。
论文:Anatomically-Controllable Medical Image Generation with Segmentation-Guided Diffusion Models
代码:https://github.com/mazurowski-lab/segmentation-guided-diffusion
0、摘要
扩散模型能够实现高质量的医学图像生成,但在生成的图像中实现解剖约束具有挑战性。
为此,本文提出了一种基于扩散模型的方法,通过支持解剖可控的医学图像生成,在每个采样步骤中遵循多类解剖分割 mask。
此外,还引入了一种随机 mask 消融训练算法,以实现对选定的解剖约束组合的调节,同时允许其他解剖区域的灵活性。
本文将所提出的方法 SegGuidedDiff 与乳腺MRI和腹部/颈部到骨盆CT数据集的现有方法进行了比较,这些数据集具有广泛的解剖目标。
结果表明,本文的方法在生成图像的忠实性方面达到了SOTA效果,并与一般的解剖现实相符。
该模型还有额外的好处,即可通过潜在空间的插值来调整生成图像与真实图像的解剖相似性。
SegGuidedDiff 有许多应用,包括跨模态转译,以及成对数据或反事实数据的生成。(好像很厉害~)
1、引言
1.1、DDPM的不足
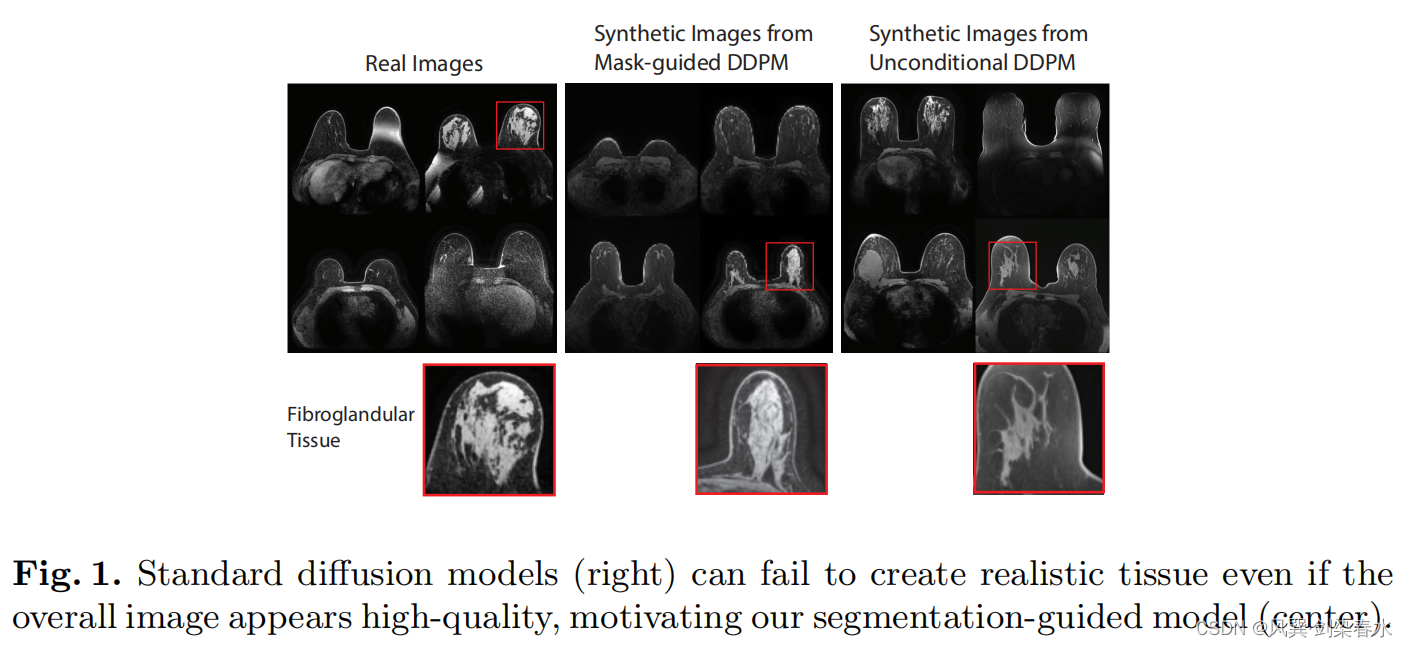
DDPM这样的标准生成模型仍然无法创建解剖学上合理的组织(图1),并且这种解剖结构无法精确定制。
本文提出的解决方案是将不同类型的组织、器官的分割 mask,作为解剖信息先验,以此来生成图像,为网络提供更直接的学习信号,实现解剖真实感。
标准的扩散模型即使生成高质量图像,但无法创建真实的组织:
1.2、从mask生成图像:图像转译任务难点
(1)现有模型没有直接实现精确的像素级解剖约束;
(2)LDM已用于对自然图像的 mask 引导,但其在医学图像上的适应性并不好;
故,本文实现的是图像空间的扩散模型,转换到潜在空间可能会丢失精确的空间引导;
2、方法
2.1、扩散模型简要概述
原文略,可参考:【Diffusion综述】医学图像分析中的扩散模型(一)中2.2节;
2.2、在扩散模型中添加分割引导
主要思想是以分割mask为引导条件生成更符合真实解剖的图像,故本文不直接从非条件分布 p ( x 0 ) {p(x_0)} p(x0) 中采样,而是从 p ( x 0 ∣ m ) {p(x_0|m)} p(x0∣m) 中采样,其中 x 0 ∈ R c × h × w {x_0 \in \mathbb{R}^{c×h×w}} x0∈Rc×h×w, m ∈ { 0 , . . . , C − 1 } h × w {m \in \{ 0,...,C-1 \}}^{h×w} m∈{0,...,C−1}h×w,C为多类别标注 mask 的类别数,包括背景。
这样添加引导条件不会改变前向过程 q ( x t ∣ x t − 1 ) {q(x_t|x_{t-1})} q(xt∣xt−1) ,但会修改反向过程 p θ ( x t − 1 ∣ x t , m ) {p_{\theta}(x_{t-1}|x_t,m)} pθ(xt−1∣xt,m) 和噪声预测网络 ϵ θ {{\epsilon}_{\theta}} ϵθ ,损失函数如下:
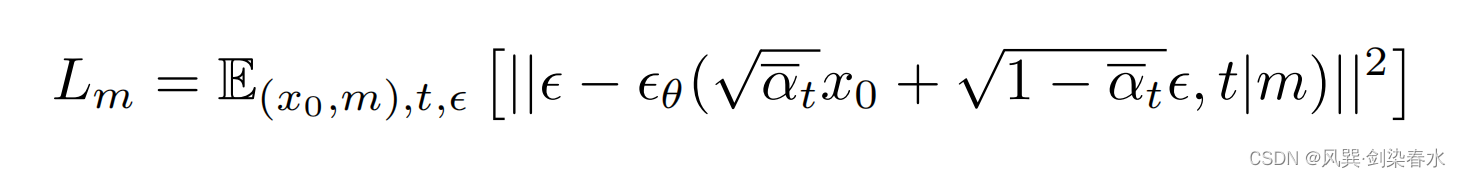
每一个训练 x 0 {x_0} x0 都有一些配对的 mask m {m} m ,在网络中如何实现呢,在去噪过程中,将 m {m} m 个 mask 直接 concat 到 Unet 的输入 x t {x_t} xt 就可以了。
其原代码实现如下:
python
def convert_segbatch_to_multiclass(imgs_shape, segmentations_batch, config, device):
# NOTE: this generic function assumes that segs don't overlap
# put all segs on same channel
segs = torch.zeros(imgs_shape).to(device)
for k, seg in segmentations_batch.items():
if k.startswith("seg_"):
seg = seg.to(device)
segs[segs == 0] = seg[segs == 0]
if config.use_ablated_segmentations:
# randomly remove class labels from segs with some probability
segs = ablate_masks(segs, config)
return segs
def add_segmentations_to_noise(noisy_images, segmentations_batch, config, device):
"""
concat segmentations to noisy image
"""
if config.segmentation_channel_mode == "single":
segs = convert_segbatch_to_multiclass(noisy_images.shape, segmentations_batch, config, device)
# concat segs to noise
noisy_images = torch.cat((noisy_images, segs), dim=1) # 这里,cat在一起!
elif config.segmentation_channel_mode == "multi":
raise NotImplementedError
return noisy_images2.3、Mask-Ablated训练和采样
本文作者认为,用于引导生成的 mask 质量非常重要,若 mask 标注不全,可能会误导生成图像,因此,作者希望模型可以简单地填充或推断未提供的目标。
那咋整呢,提出了一种 mask-ablated 训练(MAT)策略,该策略提供了具有各种数量和类别组合的 mask 示例,供模型在训练过程中学习生成图像。这可以被认为是解剖对象表征的一种自监督学习形式。
算法中,采用伯努利分布,随机将一些类的 mask 置 0 ,构成各种类别 mask 的组合。
算法流程:

其原代码实现如下:
python
def ablate_masks(segs, config, method="equal_weighted"):
# randomly remove class label(s) from segs with some probability
if method == "equal_weighted":
"""
# give equal probability to each possible combination of removing non-background classes
# NOTE: requires that each class has a value in ({0, 1, 2, ...} / 255)
# which is by default if the mask file was saved as {0, 1, 2 ,...} and then normalized by default to [0, 1] by transforms.ToTensor()
# num_segmentation_classes
"""
# 随机将某一类mask置为False,删除
class_removals = (torch.rand(config.num_segmentation_classes - 1) < 0.5).int().bool().tolist()
for class_idx, remove_class in enumerate(class_removals):
if remove_class:
segs[(255 * segs).int() == class_idx + 1] = 0
elif method == "by_class":
class_ablation_prob = 0.3
for seg_value in segs.unique():
if seg_value != 0:
# remove seg with some probability
if torch.rand(1).item() < class_ablation_prob:
segs[segs == seg_value] = 0
else:
raise NotImplementedError
return segs3、实验与结果
3.1、数据集
(1)杜克大学乳腺癌MRI数据集:
①100例,T1图像,70例训练,15例测试,保留15例训练集做其他实验;
②所有数据有乳腺、血管(BV)、纤维腺/致密组织(FGT)的分割标注,FGT和BV在形状、大小和其他形态特征上具有非常高的变异性,这为生成模型的真实特征捕获提出了挑战;
(2)CT器官:
①40例,腹部CT扫描,包括肝脏、膀胱、肺、肾和骨的分割标注;
②24例训练,8例测试,保留8例训练集;
所有生成模型都是在训练集上进行训练的,辅助分割网络是在保留训练集上进行训练的;
3.2、实施细节
(1)图像大小256×256,归一化到 0,255;
(2)正向过程: β t {\beta_t} βt 线性从 0.0001 到 0.02;
(3)AdamW优化器,余弦调整学习率,初始0.0001,500 linear warm-up steps;
(4)epoch:400;
(5)batch size:64;
(6)显卡:4块 48 GB NVIDIA A6000;
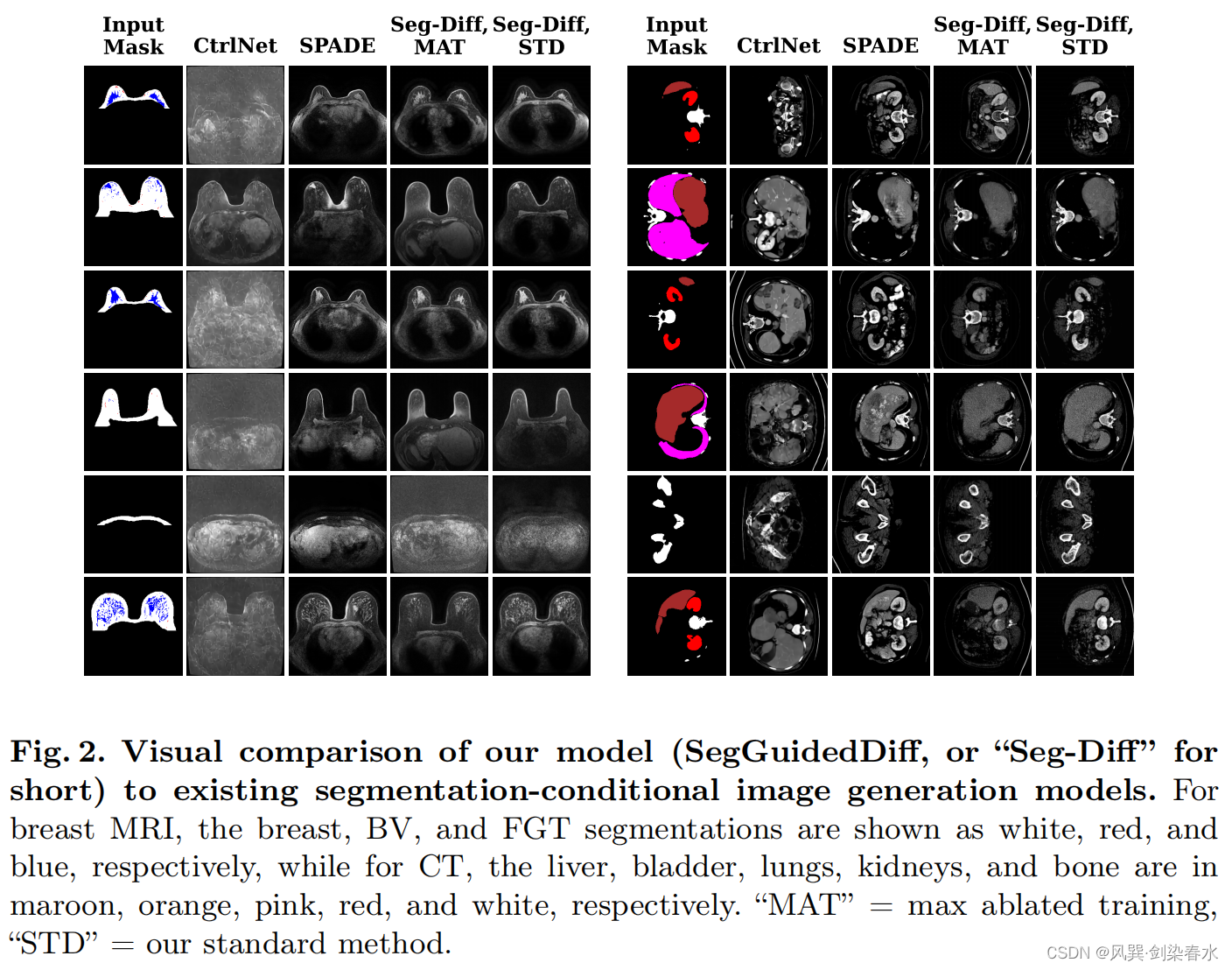
3.3、与现有图像生成模型的比较
STD为标准模型,MAT则采用了mask-ablated 训练策略:
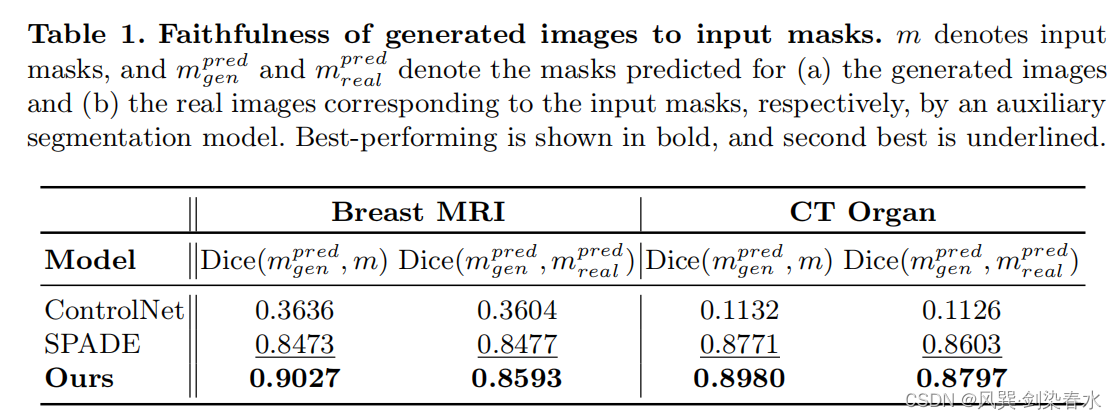
3.4、评估生成的图像对输入掩码的忠实度
使用在真实训练集上训练的辅助分割网络(MONAI UNet),预测从测试集生成的图像的分割mask: m g e n p r e d {m_{gen}^{pred}} mgenpred,计算其与 m {m} m 和 m g e n p r e d {m_{gen}^{pred}} mgenpred 的 Dice 值:
3.5、评估生成图像质量
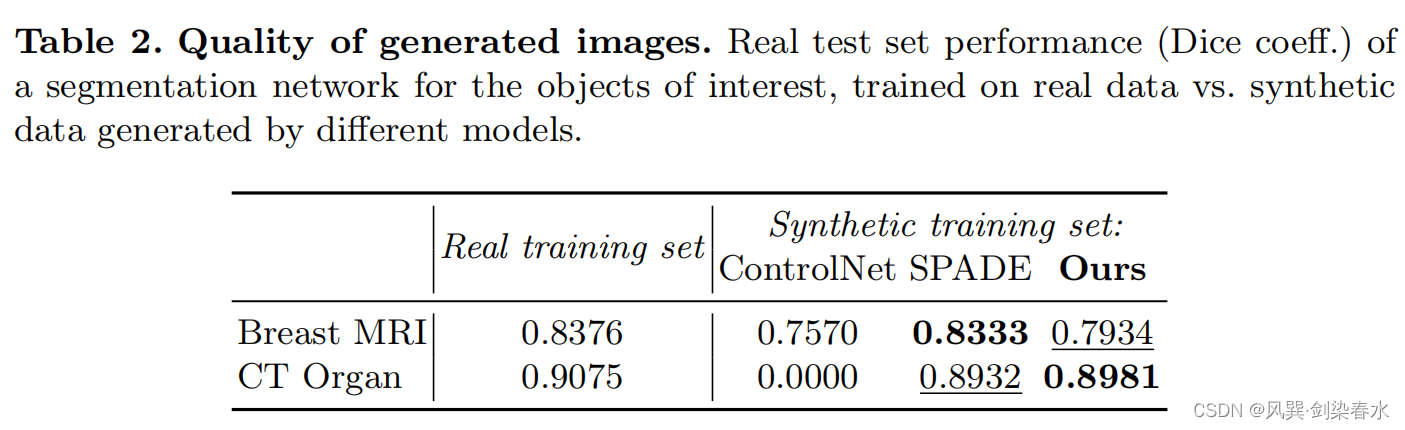
作者认为,FID 这样的基于 CNN 特征的指标无法捕捉到解剖学真实性的全局特征,而这些特征在这些模型生成的图像中可能会有所不同;
作者利用辅助分割网络在合成的图像上训练,将测试集分为两部分,分别验证在真实图像和合成图像上训练的模型,证明了在合成图像训练的模型表现比真实图像训练的模型差不多(≤ 0.04 Dice):
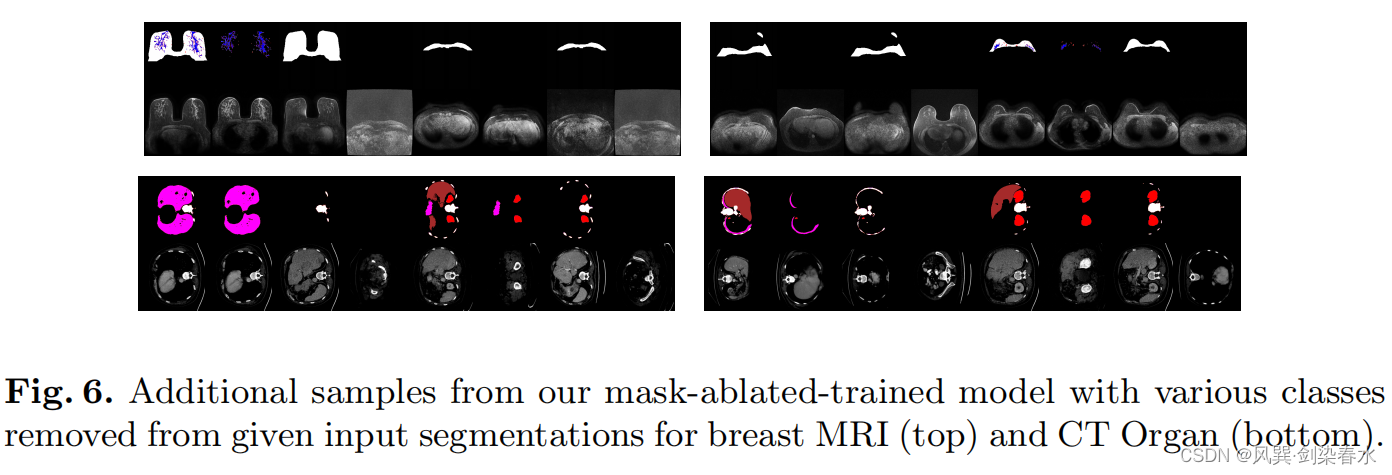
3.6、MAT的优势
MAT的好处是它能够从缺少类的引导 mask 中生成图像:
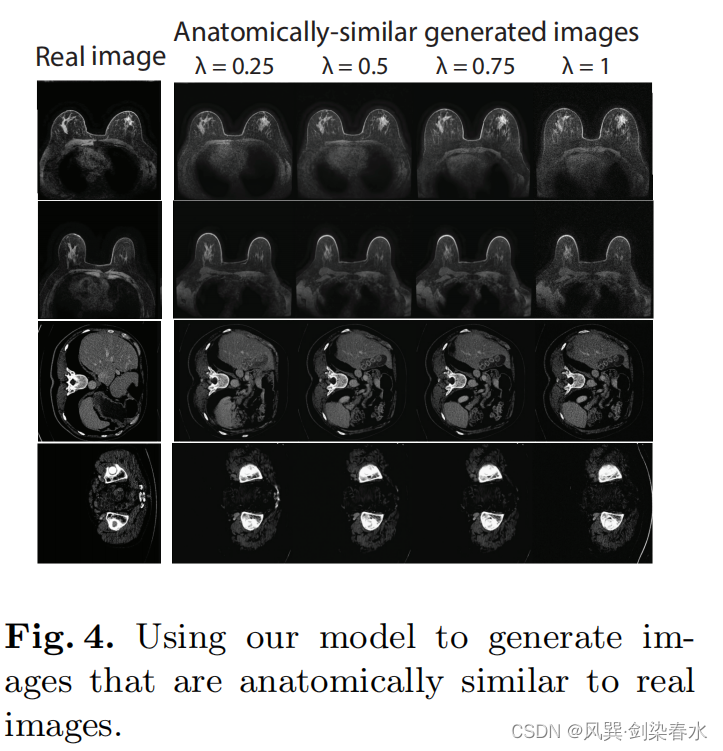
3.7、生成的图像与真实图像的可调解剖相似性
通过在模型的潜在空间中对合成图像和真实图像进行插值来调整由 m {m} m 生成的图像与 x 0 {x_0} x0 的解剖相似性;
在反向过程中, t = T {t=T} t=T,在 t = t ~ {t=\tilde{t} } t=t~ (本文使用 t ~ = 240 {\tilde{t} = 240} t~=240)时获得一个潜在表示 x t ~ ′ {x_{\tilde{t}}^{\prime}} xt~′;使用正向过程,从 x 0 {x_0} x0 获得 t = t ~ {t=\tilde{t} } t=t~ 时的图像 x t ~ {x_{\tilde{t}}} xt~ ,使用 x t ~ λ = ( 1 − λ ) x t ~ + λ x t ~ ′ {x_{\tilde{t}}^{\lambda} = (1-\lambda) x_{\tilde{t}} + \lambda x_{\tilde{t}}^{\prime}} xt~λ=(1−λ)xt~+λxt~′ 融合这两幅图的特征, λ ∈ ( 0 , 1 ] {\lambda \in (0,1]} λ∈(0,1] 控制混合特征与真实图像的相似性; x t ~ λ {x_{\tilde{t}}^{\lambda}} xt~λ 接着去噪,获得 x 0 λ {x_{0}^{\lambda}} x0λ 。
乳腺MRI中只有FGT+BV对受限,而CT器官中只有骨骼受限:
又是羡慕别人diffusion 的一天,怎么拥有一个好用的 diffusion,在线等,挺着急的 (;′⌒`)