本文详细介绍SD模型的三部件之一------VAE,阐述VAE在SD模型中的作用和完整的架构。

目录
[Stable Diffusion核心网络结构](#Stable Diffusion核心网络结构)
[【1】Stable Diffusion中VAE的核心作用](#【1】Stable Diffusion中VAE的核心作用)
[【2】Stable Diffusion中VAE的高阶作用](#【2】Stable Diffusion中VAE的高阶作用)
[【3】Stable Diffusion中VAE模型的完整结构图](#【3】Stable Diffusion中VAE模型的完整结构图)
[【4】Stable Diffusion中VAE的训练过程与损失函数](#【4】Stable Diffusion中VAE的训练过程与损失函数)
[【5】使用Stable Diffusion中VAE对图像的压缩与重建效果示例](#【5】使用Stable Diffusion中VAE对图像的压缩与重建效果示例)
[【6】DaLL-E 3同款解码器consistency-decoder](#【6】DaLL-E 3同款解码器consistency-decoder)
传统VAE
Stable Diffusion核心网络结构
摘录来源:https://zhuanlan.zhihu.com/p/632809634
SD模型整体架构初识
Stable Diffusion模型整体上是一个End-to-End模型 ,主要由VAE (变分自编码器,Variational Auto-Encoder),U-Net 以及CLIP Text Encoder三个核心组件构成。
本文主要介绍U-Net,CLIP Text Encoder和VAE请参考:
【U-Net是最占内存的部件】
在FP16精度下Stable Diffusion模型大小2G(FP32:4G),其中U-Net大小1.6G,VAE模型大小160M以及CLIP Text Encoder模型大小235M(约123M参数)。其中U-Net结构包含约860M参数,FP32精度下大小为3.4G左右。
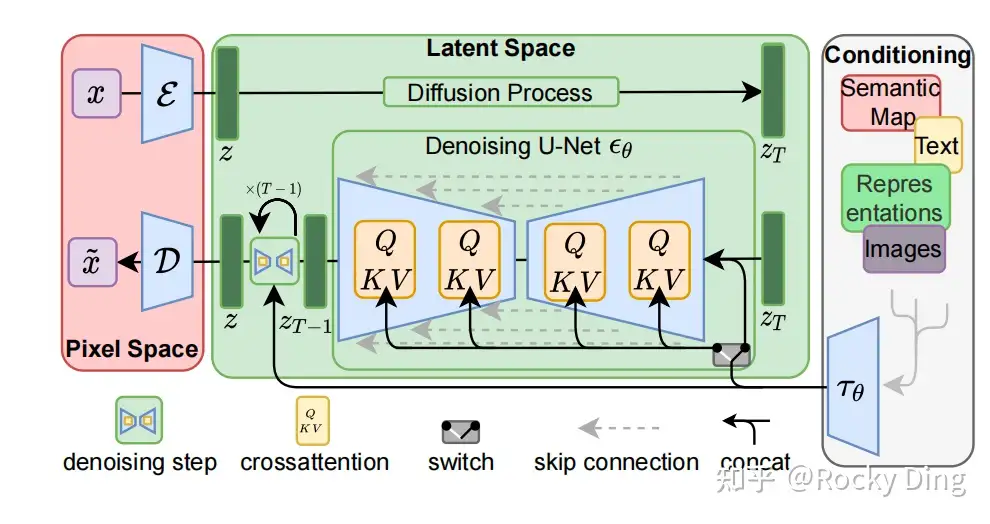 Stable Diffusion整体架构图
Stable Diffusion整体架构图
VAE模型
在Stable Diffusion中,VAE(变分自编码器,Variational Auto-Encoder)是基于Encoder-Decoder架构的生成模型 。VAE的Encoder(编码器)结构能将输入图像转换为低维Latent特征,并作为U-Net的输入 。VAE的Decoder(解码器)结构能将低维Latent特征重建还原成像素级图像。
【1】Stable Diffusion中VAE的核心作用
总的来说,在Stable Diffusion中,VAE模型主要起到了图像压缩和图像重建的作用,如下图所示:
 VAE在Stable Diffusion中的主要功能
VAE在Stable Diffusion中的主要功能
当我们输入一个尺寸为 H×W×C 的数据,VAE的Encoder模块会将其编码为一个大小为h×w×c的低维Latent特征,其中f=H/h=W/w,为VAE的********下采样率(Downsampling Factor) 。反之,VAE的Decoder模块有一个相同的****上采样******率(Upsampling Factor)**将低维Latent特征重建成像素级别的图像。
为什么VAE可以将图像压缩到一个非常小的Latent space(潜空间)后能再次对图像进行像素级重建呢?
因为虽然VAE对图像的压缩与重建过程是一个有损压缩与重建过程 ,但图像全图级特征关联并不是随机的,它们的分布具有很强的规律性 :比如人脸的眼睛、鼻子、脸颊和嘴巴之间遵循特定的空间关系,又比如一只猫有四条腿,并且这是一个特定的生物结构特征。使用VAE将图像重建成不同尺寸的生成图像,实验结论发现如果我们重建生成的图像尺寸在512×512之上时,其实特征损失带来的影响非常小。
【2】Stable Diffusion中VAE的高阶作用
与此同时,VAE模型除了能进行图像压缩和图像重建 的工作外,如果我们在SD系列模型中切换不同微调训练版本的VAE模型 ,能够发现生成图片的细节与整体颜色也会随之改变 (更改生成图像的颜色表现,类似于色彩滤镜 )。
**目前在开源社区常用的VAE模型有:**vae-ft-mse-840000-ema-pruned.ckpt、kl-f8-anime.ckpt、kl-f8-anime2.ckpt、YOZORA.vae.pt、orangemix.vae.pt、blessed2.vae.pt、animevae.pt、ClearVAE.safetensors、pastel-waifu-diffusion.vae.pt、cute_vae.safetensors、color101VAE_v1.pt等。
这里Rocky使用了10种不同的VAE模型,在其他参数保持不变的情况下,对比了SD模型的出图效果,如下所示:
 Stable Diffusion中10种不同VAE模型的效果对比
Stable Diffusion中10种不同VAE模型的效果对比
可以看到,我们在切换VAE模型进行出图时,除了pastel-waifu-diffusion.vae.pt模型外,其余VAE模型均不会对构图进行大幅改变,只对生成图像的细节与颜色表现进行调整。
【3】Stable Diffusion中VAE模型的完整结构图
下图梳理的Stable Diffusion VAE的完整结构图,看着这个完整结构图学习Stable Diffusion VAE模型部分,相信大家脑海中的思路也会更加清晰:
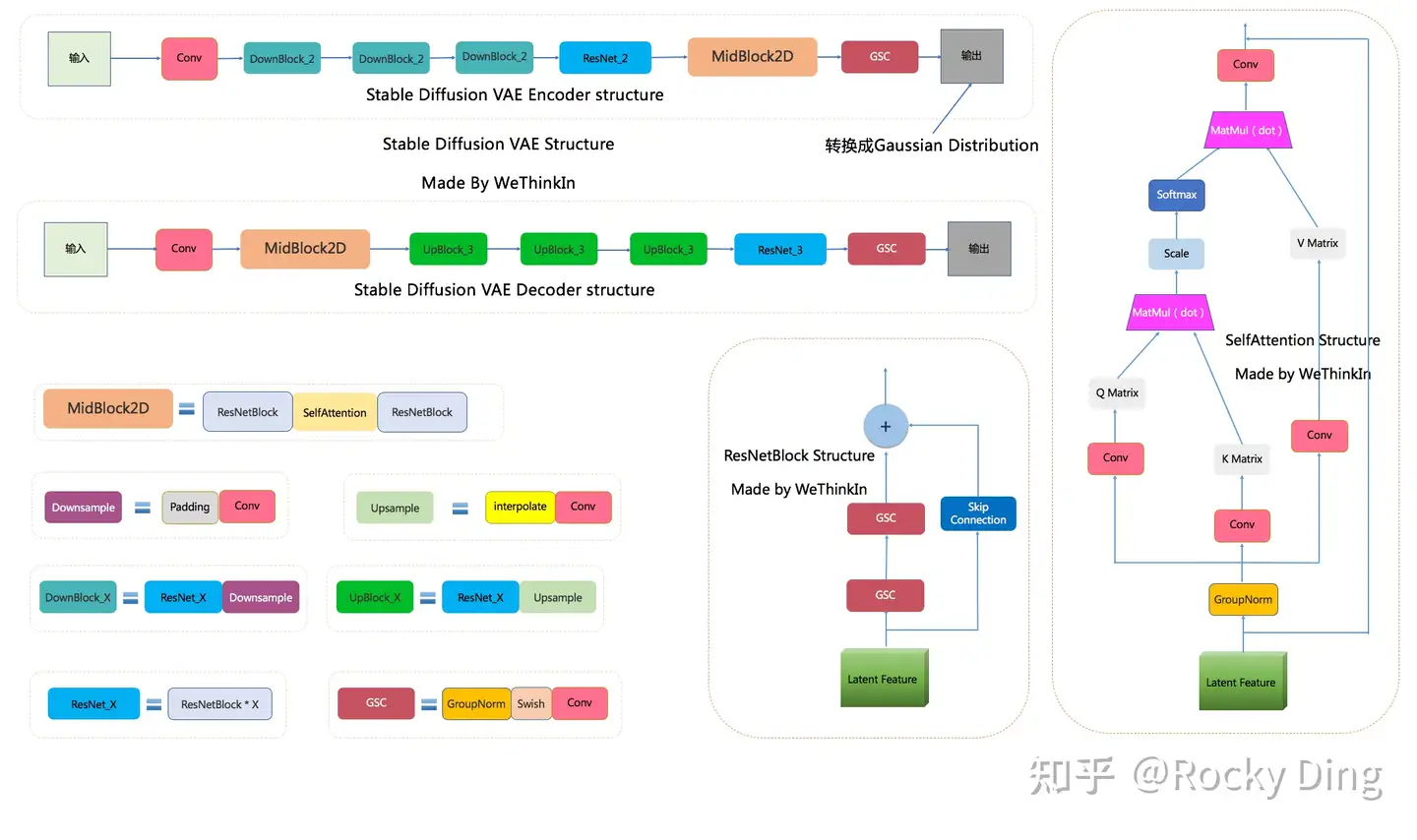 Stable Diffusion VAE完整结构图
Stable Diffusion VAE完整结构图
SD VAE模型中有三个基础组件(如上图):
- GSC组件:GroupNorm+Swish+Conv
- Downsample组件:Padding+Conv
- Upsample组件:Interpolate+Conv
同时SD VAE模型还有两个核心组件(两个模块的结构如上图所示):
- ResNetBlock模块
- SelfAttention模型
SD VAE Encoder 部分包含了三个DownBlock模块、一个ResNetBlock模块以及一个MidBlock模块,将输入图像压缩到Latent空间,转换成为Gaussian Distribution。
而VAE Decoder 部分正好相反,其输入Latent空间特征,并重建成为像素级图像作为输出。其包含了三个UpBlock模块、一个ResNetBlock模块以及一个MidBlock模块。
在Stable Diffusion 的VAE模型中,有几个关键的基础组件和核心模块,帮助模型实现高效的编码和解码过程。以下是对这些组件和模块的简要解释:
基础组件
GSC组件(GroupNorm + Swish + Conv):
GroupNorm:对输入特征进行归一化,增强模型的稳定性,特别适合小批量训练。
Swish激活函数:平滑的激活函数 Swish(x)=x⋅sigmoid(x),比ReLU更有效,提升模型的非线性表达能力。
Conv(卷积层):卷积操作用于提取局部特征,是深度学习中的基础运算单元。
Downsample组件(Padding + Conv):
Padding:对输入数据进行边缘填充,以防止尺寸缩小时丢失边界信息。
Conv(卷积层):通过卷积核对输入进行降采样操作,提取局部特征并缩小图像的空间尺寸。
Upsample组件(Interpolate + Conv):
Interpolate(插值):对图像进行上采样,将图像的空间分辨率放大(通常使用双线性插值)。
Conv(卷积层):对上采样后的图像进行卷积操作,恢复图像细节。
核心组件
ResNetBlock模块:
ResNetBlock 是一种残差结构 ,通过引入跳跃连接(skip connections),让模型在每一层的输出中加入输入信息,解决了深层网络中梯度消失的问题。
结构:输入特征通过若干层卷积和激活处理后,叠加上原始输入特征,增强网络的学习能力和深度。
优点:提高模型的训练效率,帮助模型在深层网络中保持梯度流动,使其能够学习复杂的特征。
Self-Attention模块:
Self-Attention 机制通过计算输入中每个元素(如图像中的像素或特征)与其他元素之间的关系来捕捉全局依赖性。
工作原理:每个元素通过注意力权重与其他元素进行交互,从而获取全局特征。Self-Attention特别擅长捕捉长距离依赖,适用于图像生成任务。
优点:帮助模型捕捉全局信息,与卷积层的局部感受野相辅相成,特别有利于复杂图像细节的生成。
总结
GSC组件 :GroupNorm 归一化 、Swish 激活 、Conv 卷积 ,稳定训练并提取局部特征。
Downsample组件 :通过填充和卷积实现图像的降采样。
Upsample组件 :使用插值和卷积进行上采样,恢复图像细节。
ResNetBlock模块 :残差网络,防止深层网络中梯度消失,提升深度网络的训练效果。
Self-Attention模块 :全局注意力机制,帮助模型捕捉长距离依赖和全局复杂特征。
这些组件和模块共同构成了Stable Diffusion的VAE模型,提供了强大的特征提取和生成能力,确保图像在潜在空间的高效压缩和解码。
GSC组件解释:
【4】Stable Diffusion中VAE的训练过程与损失函数
【三大主要损失函数: L1回归损失、感知损失以及PachGAN的判别器损失】+ 【KL正则化损失】
在Stable Diffusion中,需要对VAE模型进行微调训练 ,主要采用了L1回归损失【 平均绝对误差(Mean Absolute Error, MAE)】和感知损失 (perceptual loss,Learned Perceptual Image Patch Similarity,LPIPS)作为损失函数,同时使用了基于patch的对抗训练策略。
使用 L1 损失、感知损失、PatchGAN 判别器损失和 KL 散度 是为了综合提升生成图像的质量和细节,各自的作用如下:
- L1 损失 :更适合生成图像的像素级对齐,比 L2 损失在保持图像细节上更有效。
- 感知损失 :确保生成图像的高层特征和目标图像一致,更符合人类视觉感知。
- PatchGAN 判别器损失 :通过对局部区域的对抗训练,使生成图像的细节和纹理更加真实。
- KL 正则化损失:帮助模型在潜在空间中学习更具结构化的分布,确保生成的图像稳定和多样。
L1回归损失 作为传统深度学习时代的经典回归损失,用在回归问题中衡量**【像素级别】预测值与真实值之间的差异**,在生成模型中很常用,其公式如下所示:

感知损失 同样作为传统深度学习时代的经典回归损失,在AIGC时代继续繁荣。感知损失的核心思想是比较原始图像和生成图像 在传统深度学习模型(VGG、ResNet、ViT等)不同层中特征图之间的相似度 ,而不直接进行像素级别的对比。
传统深度学习模型能够提取图像的高维语义信息的特征,如果两个图像在高维语义信息的特征上接近,那么它们在像素级别的语意上也应该是相似的,感知损失在图像重建、风格迁移等任务中非常有效。
感知损失的公式如下所示:

最后就是基于patch的对抗训练策略 ,我们使用PatchGAN的判别器 来对VAE模型进行对抗训练,通过优化判别器损失 ,来提升生成图像的局部【patch】真实性(纹理和细节)与清晰度。
PatchGAN是GAN系列模型的一个变体,其判别器架构不再评估整个生成图像是否真实,而是评估生成图像中的patch部分是否真实 。具体来说,PatchGAN的判别器接收一张图像,并输出一个矩阵,矩阵中的每个元素代表图像中对应区域的真实性。这种方法能够专注于优化生成图像的局部特征,生成更细腻、更富有表现力的纹理,同时计算负担相对较小。特别适合于那些细节和纹理特别重要的任务,例如图像超分辨率、风格迁移或图生图等任务。
到这里,**Rocky已经帮大家分析好Stable Diffusion中VAE训练的三大主要损失函数:**L1回归损失、感知损失以及PachGAN的判别器损失。
与此同时,为了防止在Latent空间的任意缩放导致的标准差过大 ,在训练VAE模型的过程中引入了正则化损失 ,主要包括KL(Kullback-Leibler)正则化与VQ(Vector Quantization)正则化。KL正则化 主要是让Latnet特征不要偏离正态分布太远,同时设置了较小的权重(~10e-6)来保证VAE的重建效果 。VQ正则化 通过在decoder模块中引入一个VQ-layer,将VAE转换成VQ-GAN,同样为了保证VAE的重建效果 ,设置较高的codebook采样维度(8192)。
Stable Diffusion论文中实验了不同参数下的VAE模型性能表现,具体如下图所示。当f较小和c较大时,重建效果较好(PSNR值较大) ,因为此时图像的压缩率较小。但是VAE模型在ImageNet数据集上训练时发现设置过小的f(比如1和2)会导致VAE模型收敛速度慢 ,SD模型需要更长的训练周期。如果设置过大的f会导致VAE模型的生成质量较差,因为此时压缩损失过大。论文中实验发现,当设置f在4~16的区间时,VAE模型可以取得相对好的生成效果。
通过综合评估正则化损失项、f项以及 c 项,**最终Stable Diffusion中的VAE模型选择了KL正则化进行优化训练,同时设置下采样率f=8,设置特征维度为c=4。**此时当输入图像尺寸为768x768时,将得到尺寸为96x96x4的Latent特征。
 不同参数下的VAE模型性能表现
不同参数下的VAE模型性能表现
讲到这里,终于可以给大家展示Stable DIffusion中VAE模型的完整损失函数了,下面是Stable Diffusion中VAE训练的完整损失函数:

【rec是**VAE的经典损失之一------**重建损失】
虽然VAE模型使用了KL正则化,但是由于KL正则化的权重系数非常小 ,实际生成的Latent特征的标准差依旧存在比较大的情况,所以Stable Diffusion论文中提出了一种rescaling方法强化正则效果 。首先我们计算第一个batch数据中Latent特征的标准差σ,然后采用1/σ的系数来rescale后续所有的Latent特征使其标准差接近于1。同时在Decoder模块进行重建时,只需要将生成的Latent特征除以1/σ,再进行像素级重建即可。在SD中,U-Net模型使用的是经过rescaling后的Latent特征,并且将rescaling系数设置为0.18215。
【5】使用Stable Diffusion中VAE对图像的压缩与重建效果示例
VAE在对图像进行压缩和重建时,是存在精度损失的,比如256x256分辨率和256x768分辨率下重建,会出现人脸崩坏的情况。同时我们可以看到,二次元图片比起真实场景图片更加鲁棒,在不同尺寸下重建时,二次元图片的主要特征更容易保留下来,局部特征畸变的情况较少,损失程度较低。
为了避免压缩与重建的损失影响Stable Diffusion生成图片的质量,我们可以在微调训练、文生图、图生图等场景中进行如下设置:
- 文生图场景:生成图像尺寸尽量在512x512以上。
- 图生图场景:对输出图像进行缩放生成时,生成图像尺寸尽量在512x512以上。
- 微调训练:训练数据集尺寸尽量在512x512以上。
同时,StabilityAI官方也对VAE模型进行了优化, 首先发布了基于模型指数滑动平均(EMA)技术微调的vae-ft-ema-560000-ema-pruned版本 ,训练集使用了LAION两个1:1比例数据子集,目的是增强VAE模型对扩散模型数据集的适应性,同时改善脸部的重建效果。在此基础上,使用MSE损失继续微调优化并发布了vae-ft-mse-840000-ema-pruned版本,这个版本的重建效果更佳平滑自然。 ++两个优化版本都只优化了VAE的Decoder部分,由于SD在微调训练中只需要Encoder部分提供Latent特征,所以优化训练后的VAE模型可以与开源社区的所有SD模型都兼容。++
【6】DaLL-E 3同款解码器consistency-decoder
OpenAI开源的**一致性解码器(consistency-decoder),**能生成质量更高的图像内容、更稳定的图像构图,比如在多人脸、带文字图像以及线条控制方面有更好的效果。consistency-decoder既能用于DaLL-E 3模型,同时也支持作为Stable Diffusion 1.x和2.x的VAE模型。
将原生SD VAE模型与consistency-decoder模型在256x256分辨率下的图像重建效果对比,可以看到在小分辨率情况下,consistency-decoder模型确实有更好的重建效果。
但是由于consistency-decoder模型较大(FP32:2.49G,FP16:1.2G),重建耗时会比原生的SD VAE模型大得多,并且在高分辨率(比如1024x1024)下效果并没有明显高于原生的SD VAE模型,所以最好将consistency-decoder模型作为补充储备模型之用。