目录
- 参考
- Spark简介:
- 架构
-
- Standalone架构
- Cluster集群
- [Saprk On YARN架构](#Saprk On YARN架构)
- 安装
- RDD
- 案例
- [SparkSQL 概述](#SparkSQL 概述)
-
- [1.1 SparkSQL 是什么](#1.1 SparkSQL 是什么)
- [1.2 Hive and SparkSQL](#1.2 Hive and SparkSQL)
- [DataFrame 和Dataset](#DataFrame 和Dataset)
参考
经典大数据开发实战(Hadoop &HDFS&Hive&Hbase&Kafka&Flume&Storm&Elasticsearch&Spark)
Spark简介:
Spark是一种通用的大数据计算框架,是基于RDD(弹性分布式数据集)的一种计算模型。那到底是什么呢?可能很多人还不是太理解,通俗讲就是可以分布式处理大量集数据的,将大量集数据先拆分,分别进行计算,然后再将计算后的结果进行合并。
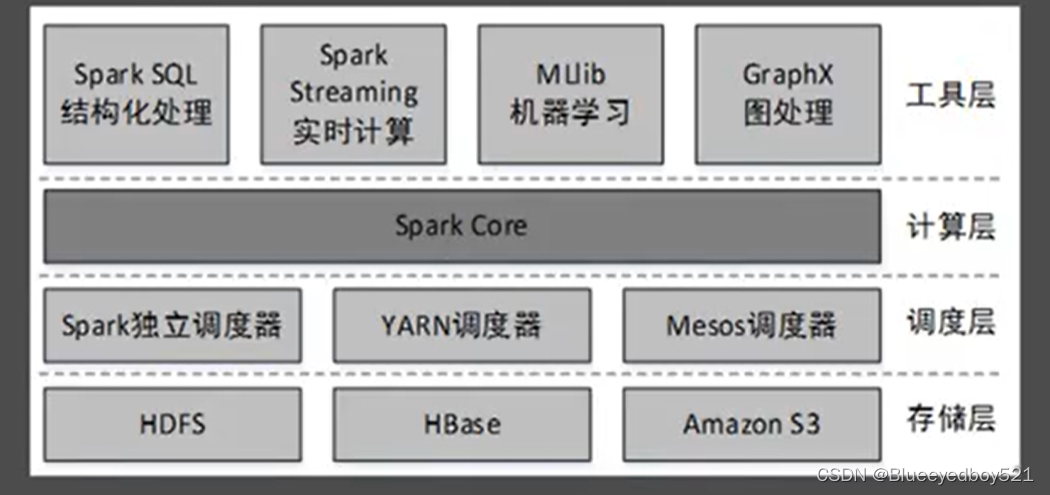
主要组件
Spark是由多个组件构成的软件栈,Spark的核心(SparkCore)是一个对由很多计算任务组成的、运行在多个工作机器或者一个计算集群上的应用进行调度、分发以及监控的计算引擎。
为什么使用Spark
Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是------Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,而且比MapReduce平均快10倍以上的计算速度;因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
Spark优势
速度快
■基于内存数据处理, 比MR快100个数量级以上(逻辑回归算法测试)
■基于硬盘数据处理,比MR快10个数量级以上
易用性
■支持Java、 Scala、 Python、 R语言
■交互式shell方便开发测试
通用性
■一栈式解决方案:批处理、交互式查询、实时流处理、图计算及机器学习
■多种运行模式
■YARN、 Mesos、 EC2、 Kubernetes、 Standalone(独立模式)、 Local(本地模式)
架构
Standalone架构
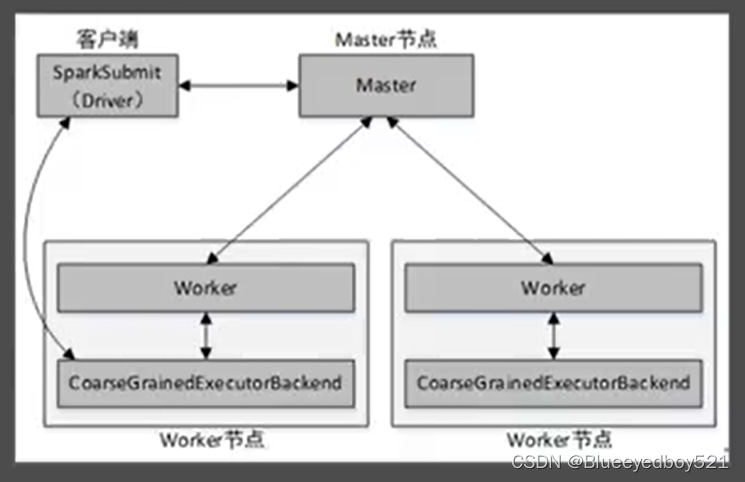
Spark Standalone模式为经典的Master/Slave架构,资源调度是Spark自己实现的。在Standalone模式中,根据应用程序提交的方式不同,Driver(主控进程)在集群中的位置也有所不同。应用程序的提交方式主要有两种:clien如和cluster,默认是client.当提交方式为client时,运行架构:
Cluster集群
Saprk On YARN架构
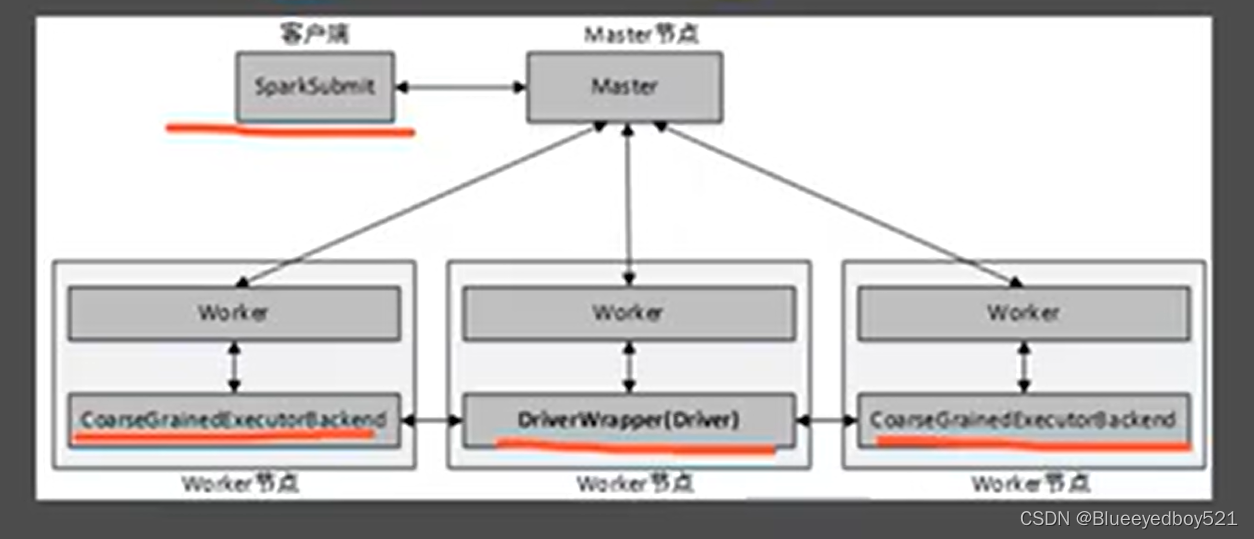
Spark On YARN模式,遵循YARN的官方规范,YARN只负责资源的管理和调度,运行哪种应用程序由用户自己实现,因此可能在YARN上同时运行MapReduce程序和Spark程序,YARN很好的对每一个程序实现了资源的隔离这使得Spark与MapReduce可以运行于同一个集群中,共享集群存储资源与计算资源。Spark On YARN模式与Standalone模式一样,也分为client和cluster两种提交方式。client提交方式架构:
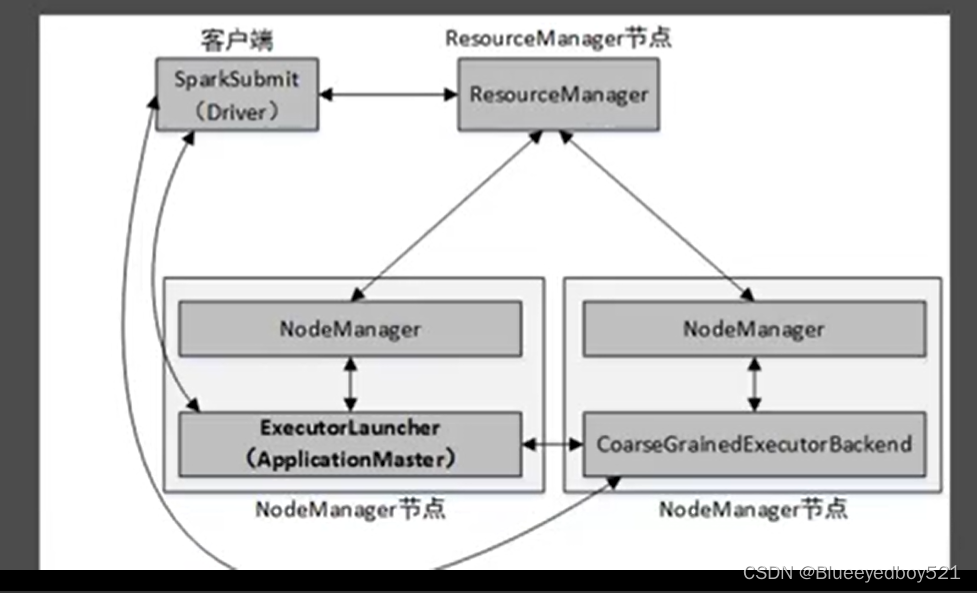
安装
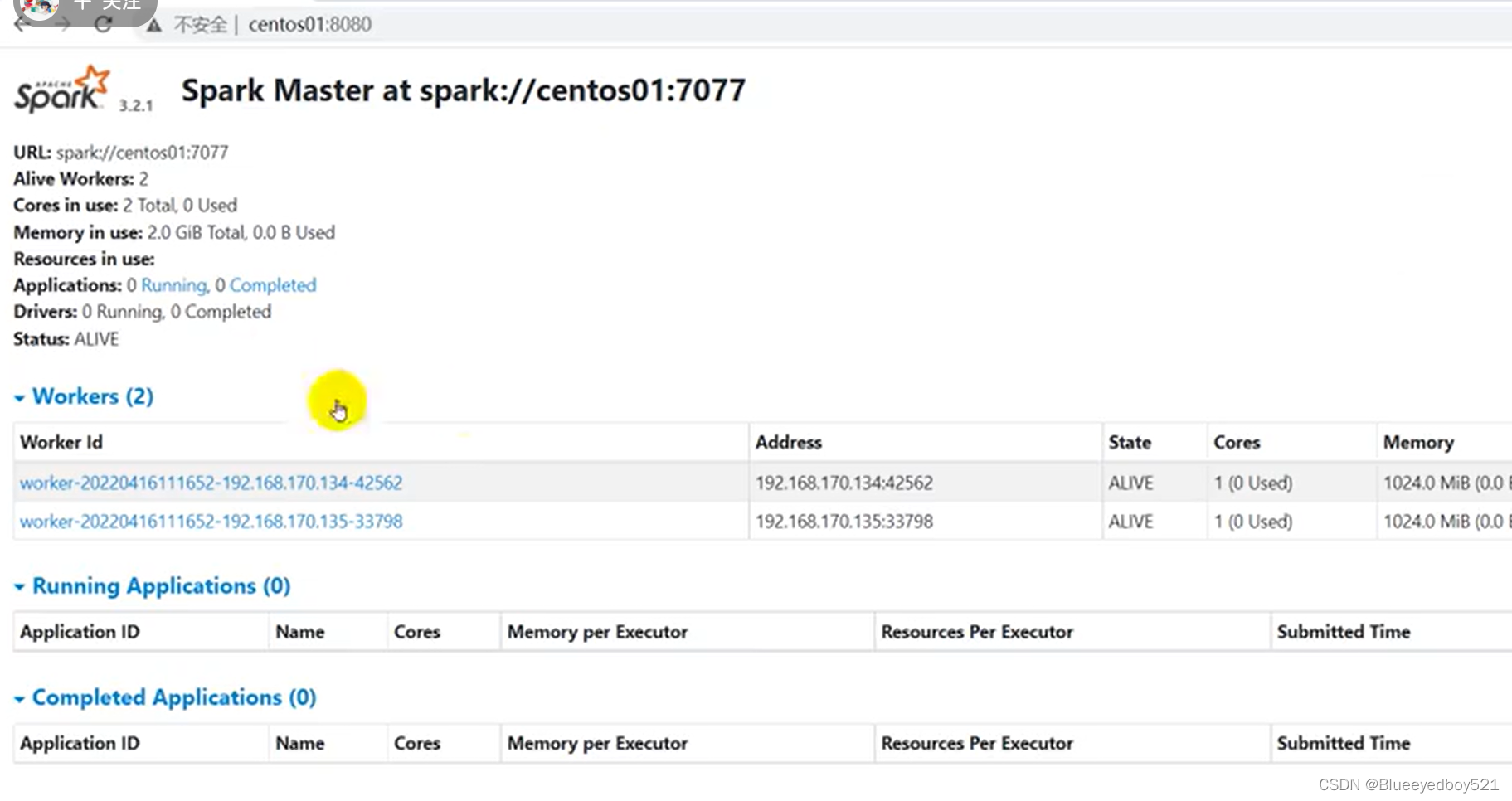
启动界面
8080端口
RDD
概念
Spark提供了一种对数据的核心推象,称为弹性分布式数据集(Resilient Distributed Dataset,简称RDD)中,这个数据集的全部或部分可以缓存在内存并且可以在多次计算时重用。RDD其实就是一个分布在多个节点上的数据集合。
RDD的弹性主要是指:当内存不的多时,数据可以持久化到磁盘,并且RDD有高效的容错能力。分布式数据集是指:一个数据集存储在不同的节点上。每个节点存储数据集的一部分。
例如,将数据集(hello,world,scaa,spark,love,spark,happy)存储在三个节点上,节点一存储(hello,world),节点二存储(scala,spark,love),节点三存储(spark,happy),这样对三个节点的数据可以并行计算,并且三个节点的数据共同组成了一个RDD。
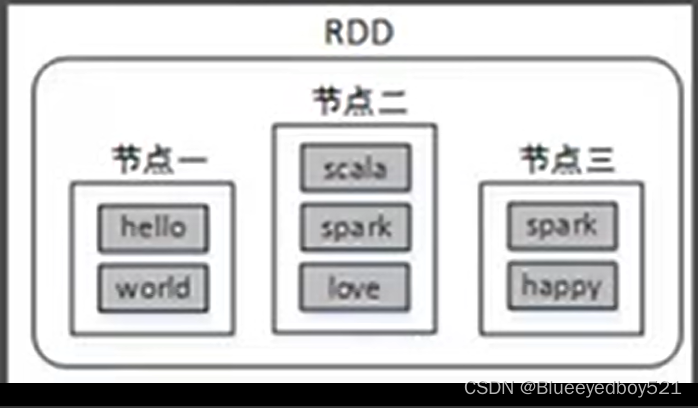
RDD是分散在多个服务器上
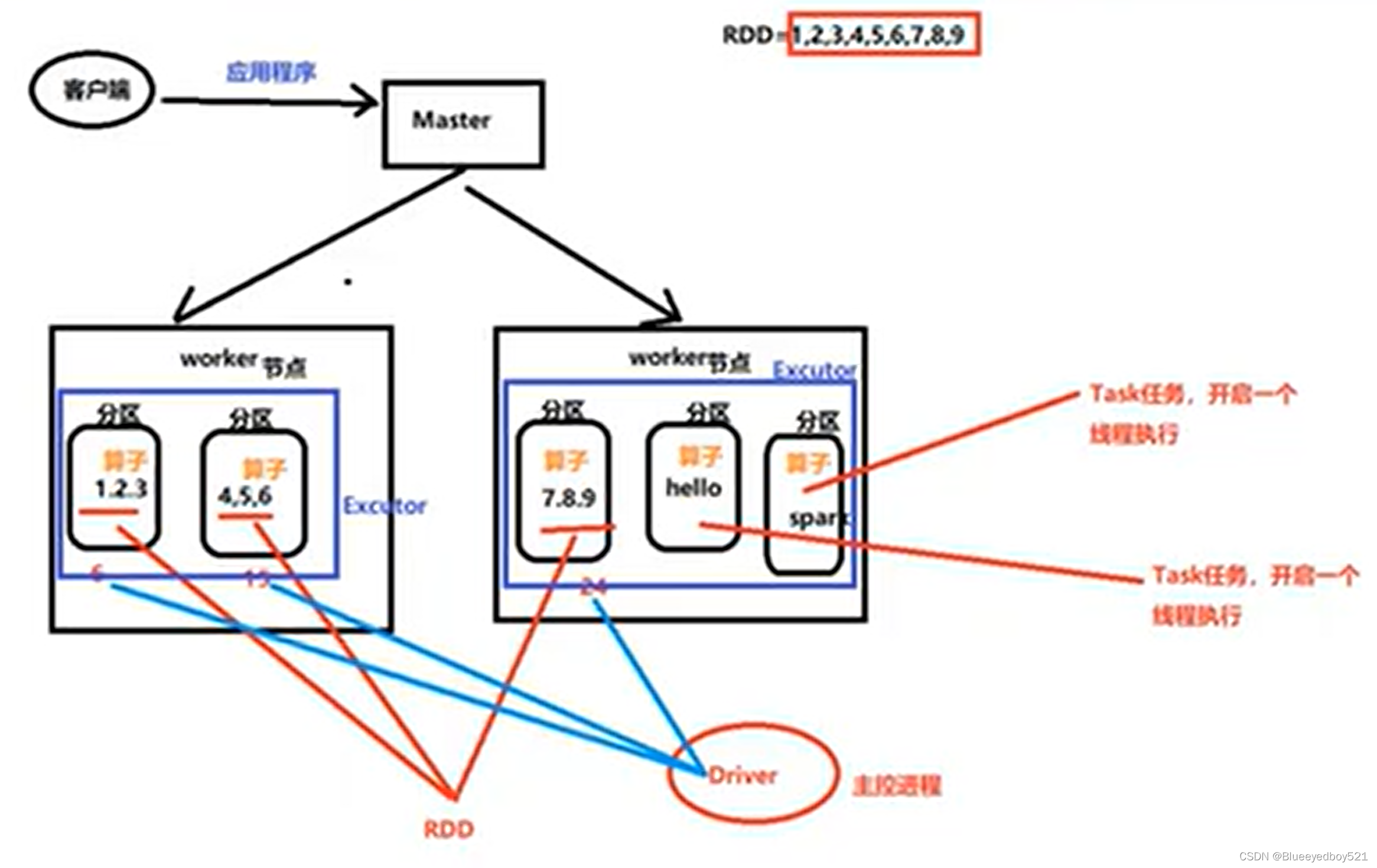
map算子

前面两行只是计划,最后执行collect的时候程序才会执行
flatMap(func)
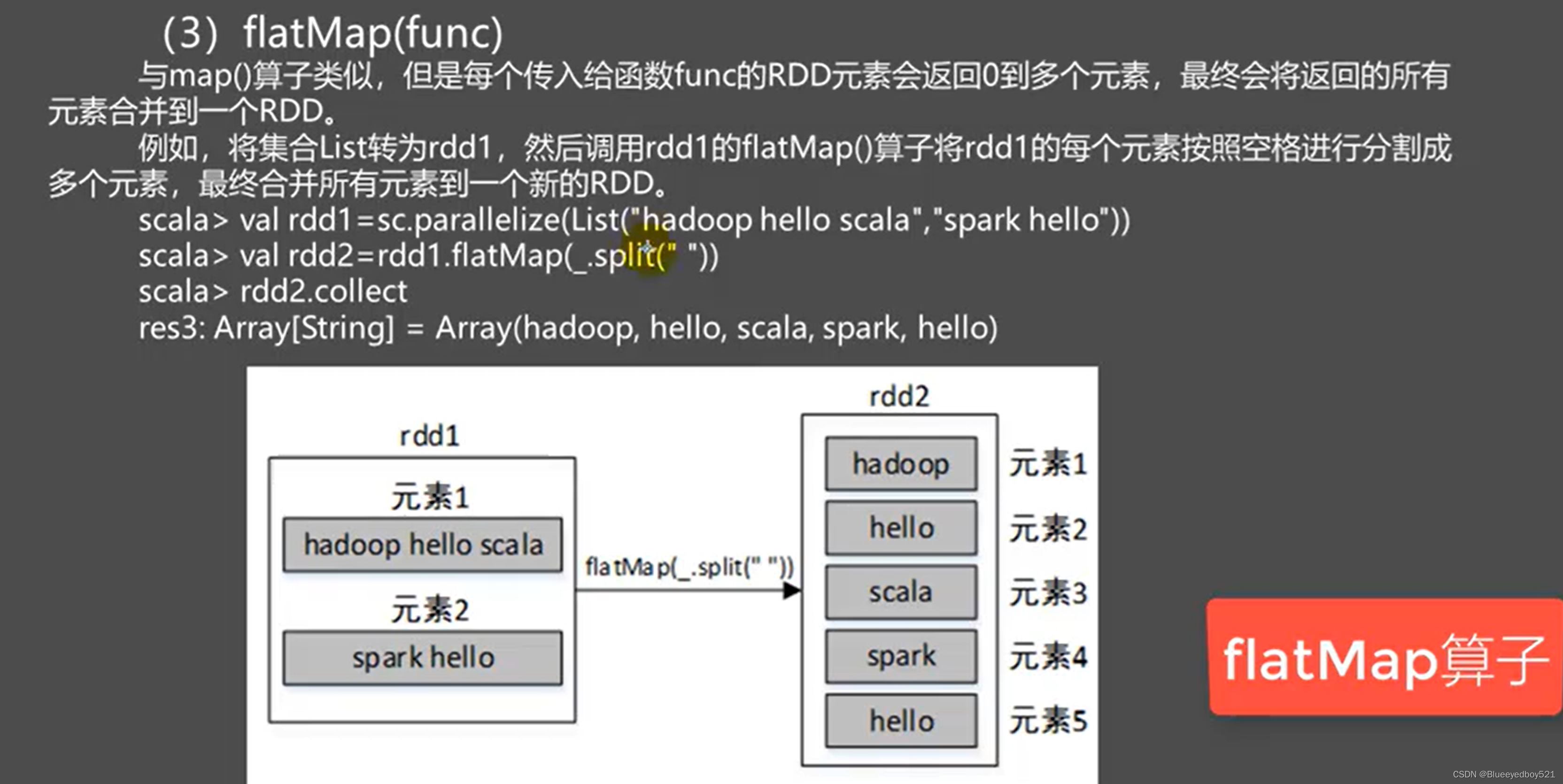
reduceByKey()

案例
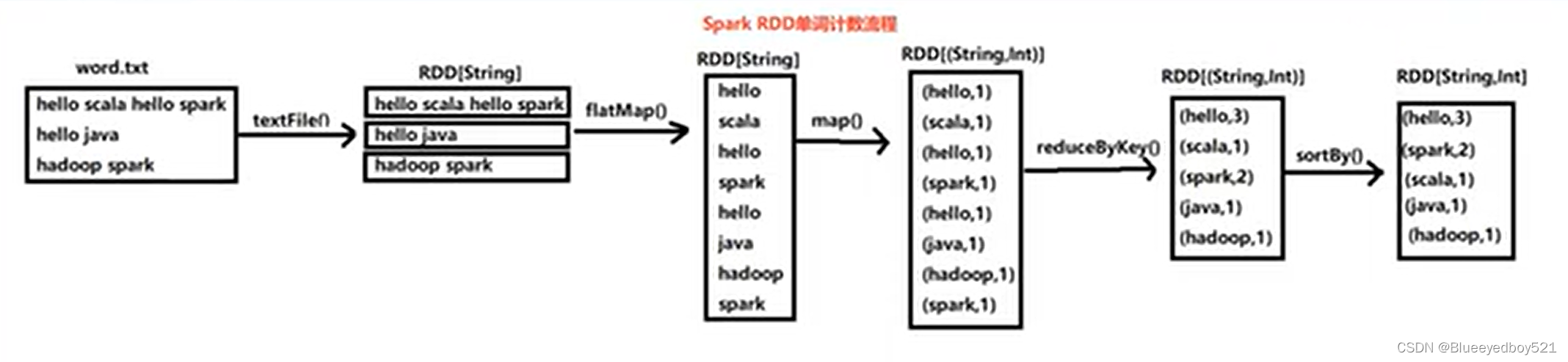
Spark单词计数
流程
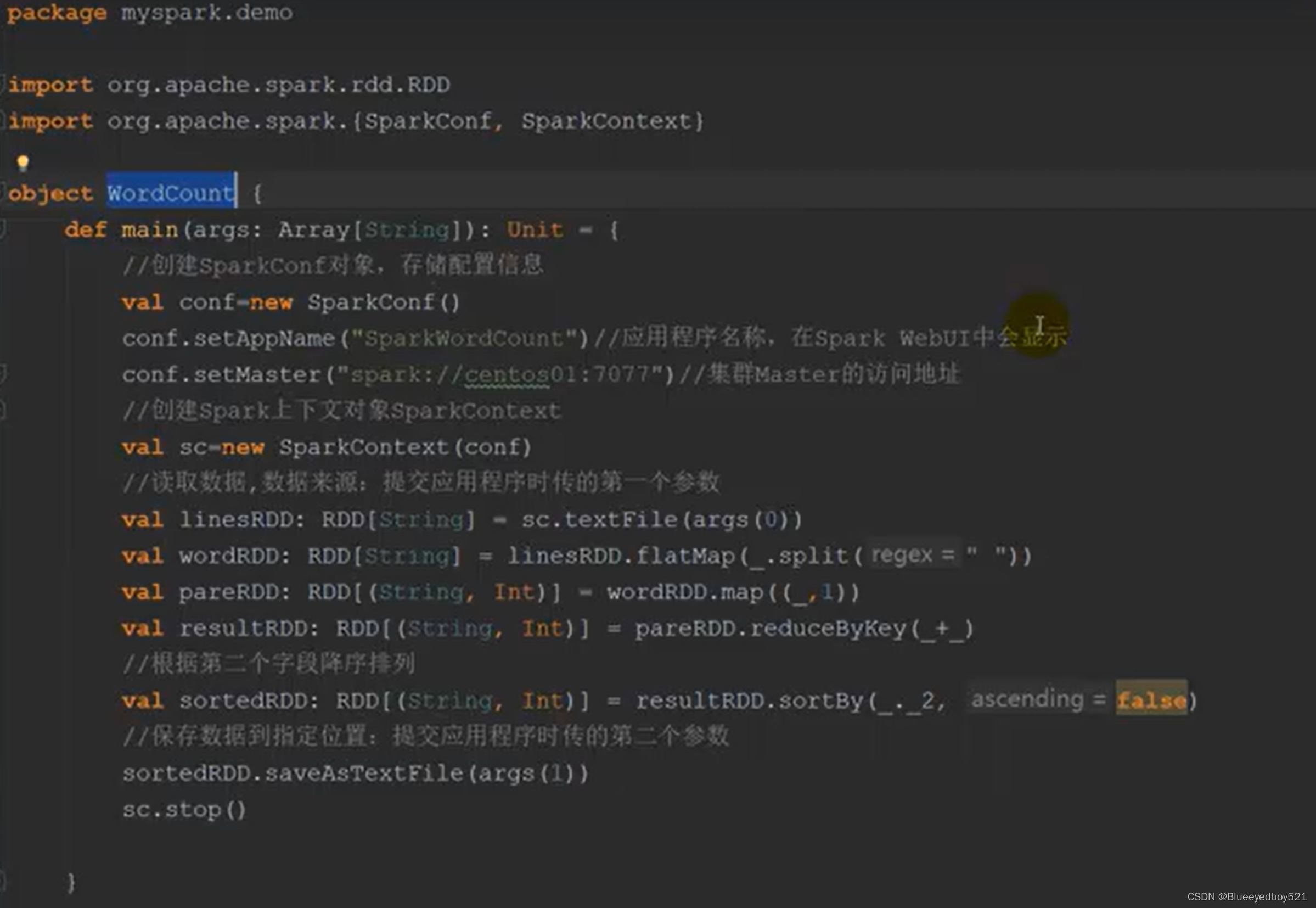
代码
SparkSQL 概述
1.1 SparkSQL 是什么
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。
1.2 Hive and SparkSQL
SparkSQL 的前身是 Shark,给熟悉 RDBMS 但又不理解 MapReduce 的技术人员提供快速上手的工具。
Hive 是早期唯一运行在 Hadoop 上的 SQL-on-Hadoop 工具。但是 MapReduce 计算过程中大量的中间磁盘落地过程消耗了大量的 I/O,降低的运行效率,为了提高 SQL-on-Hadoop的效率,大量的 SQL-on-Hadoop 工具开始产生,其中表现较为突出的是:
⚫ Drill
⚫ Impala
⚫ Shark
其中 Shark 是伯克利实验室 Spark 生态环境的组件之一,是基于 Hive 所开发的工具,它修改了下图所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在 Spark 引擎上。
DataFrame 和Dataset
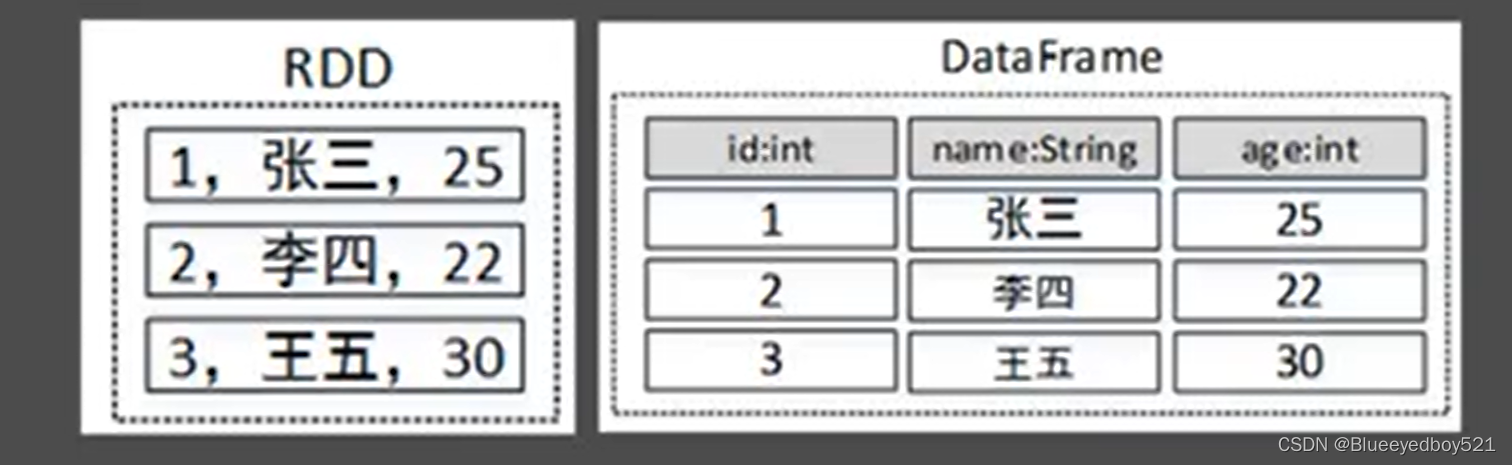
DataFrame是SparkSQL提供的一个编程抽象,与RDD类似,也是一个分布式的数据集合。但与RDD不同的是,DataFrame的数据都被组织到有名字的列中,就像关系型数据库中的表一样。此外,多种数据都可以转化为DataFrame,例如:Spark计算过程中生成的RDD、结构化数据文件、Hive中的表、外部
数据库等。DataFrame在RDD的基础上添加了数据描述信息(Schema,即元信息),因此看起来更像是一张数据库表。

读取数据
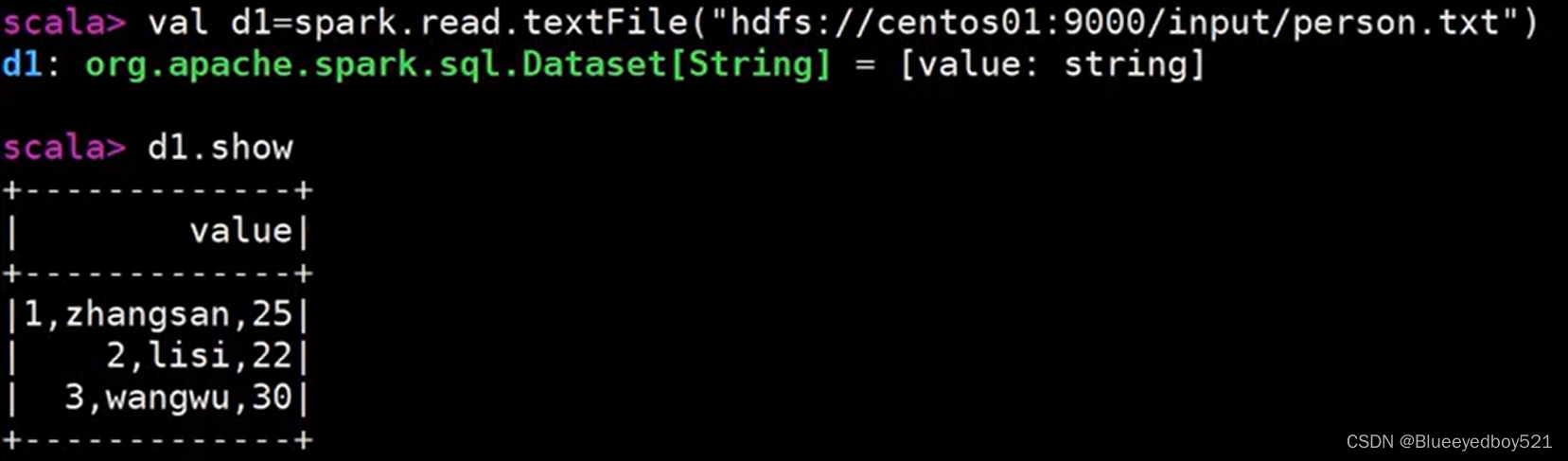
拆分3列
bash
## 定义类
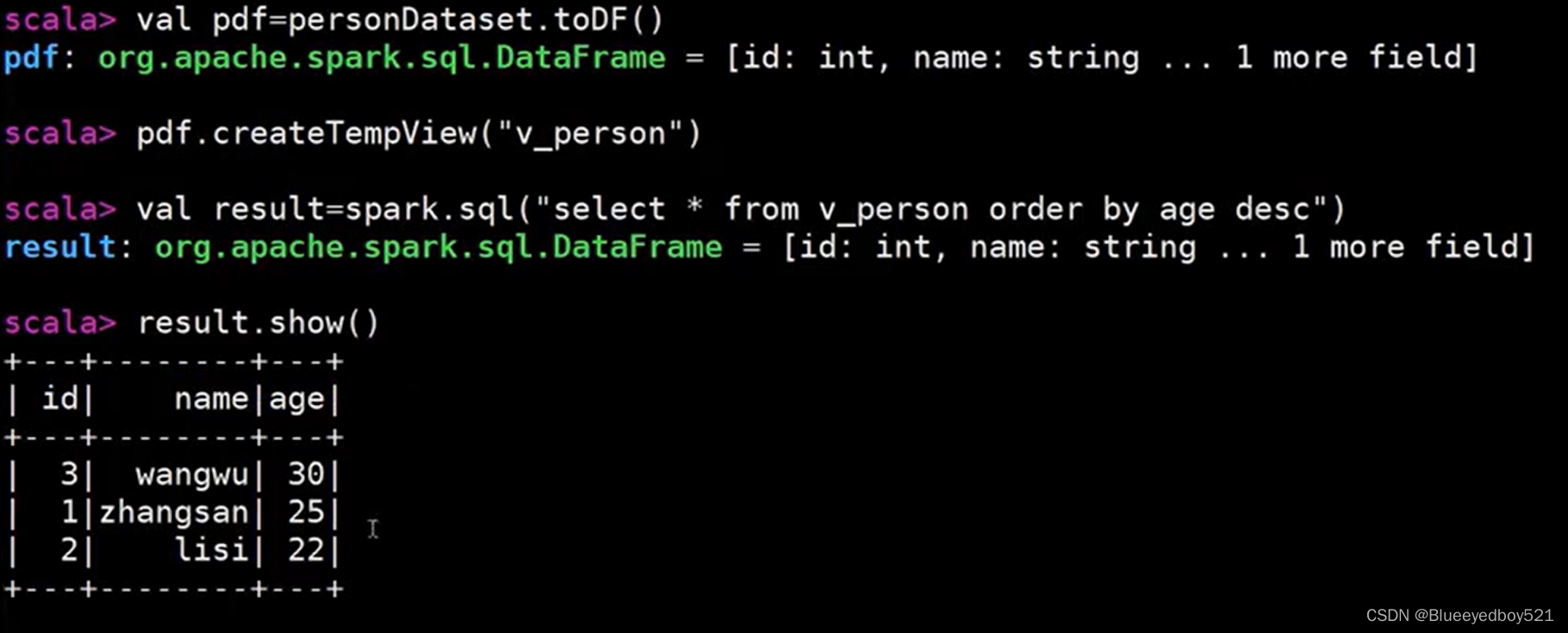
scala> case class Person(id:Int,name:String,age:Int)
defined class Person
## 导入数据
scala> import spark.implicits
import spark.implicits._
scala> val personDataset = dl.map(line=>{
val fields=line.split(',')
val id=fields(0).toInt
val name=fields(1)
val age=fields(2).toInt
Person(id,name,age)
})展示
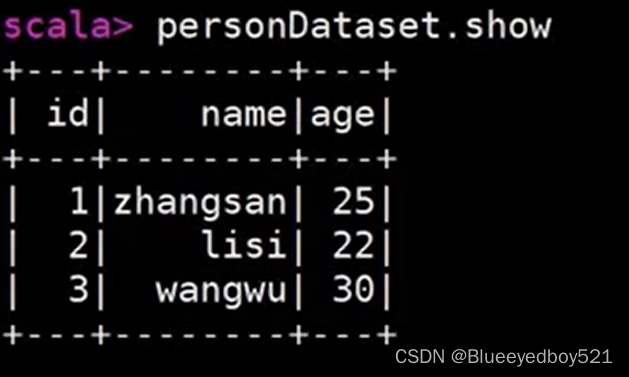
转换DataFrame后可以执行SparkSql