文章目录
前言
在上篇文章中我介绍了关于流式处理设计模式相关的总结以及案例说明,为了更好地理解Streams的工作原理,需要深入了解并理解API背后的一些设计原则,本文将从架构设计层面对这些原则进行说明总结。
构建拓扑
每个流式处理应用程序都会实现和执行一个拓扑 。拓扑(在其他流式处理框架中叫作DAG,即有向无环图)是一组操作和转换的集合,事件从输入到输出都会流经这个集合。关于流式处理设计模式相关的总结以及案例说明中"字数统计"示例的拓扑如下图所示:
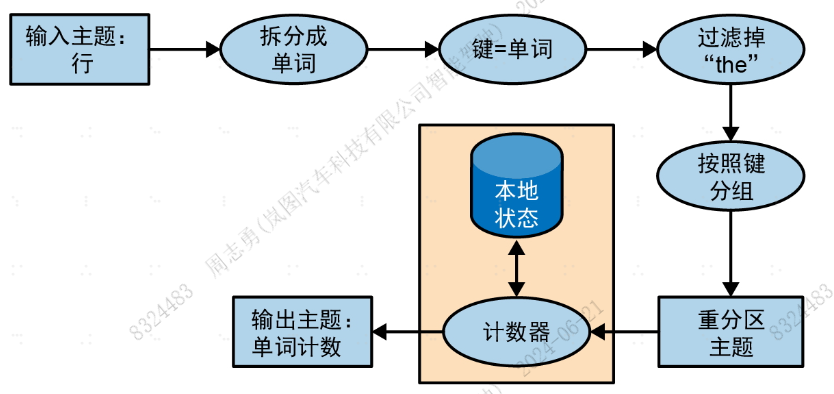
即使是一个简单的应用程序也会有不简单的拓扑。拓扑由处理器组成,处理器是拓扑图中的节点(在图中用椭圆表示)。大部分处理器实现了一个数据操作------过滤、映射、聚合等。数据源处理器从主题读取数据,并将数据传给其他组件,数据池处理器从处理器接收数据,并将数据生成到主题上。拓扑总是从一个或多个数据源处理器开始,并以一个或多个数据池处理器结束。
优化拓扑
默认情况下,在执行使用DSL API构建的应用程序时,Streams会将每个DSL方法独立映射到一个底层的等价对象。因为每个DSL方法都是独立计算的,所以错失了优化整体拓扑的机会。
Streams应用程序的执行分为3个步骤。
- 通过创建
KStream对象和KTable对象并对它们执行DSL操作(比如过滤和连接)来定义逻辑拓扑。 - 调用
StreamsBuilder.build(),从逻辑拓扑生成物理拓扑。 - 调用
KafkaStreams.start()执行拓扑,这是读取、处理和生成数据的步骤。
在第2个步骤中,也就是从逻辑拓扑生成物理拓扑这一步,可以对执行计划进行整体优化。
目前,Kafka只提供了一部分优化,主要与重用主题有关。可以通过将StreamsConfig.TOPOLOGY_OPTIMIZATION设置成StreamsConfig.OPTIMIZE并调用build(props) 来启用这些优化。如果只调用build()但没有传入配置,则仍然无法启用优化。建议对启用了优化和没有启用优化的应用程序进行测试,比较执行时间和写入Kafka的数据量,当然,也要验证各种已知场景中的结果是否相同。
测试拓扑
一般来说,在正式运行应用程序之前,需要对它进行测试。自动化测试被认为是黄金标准,每次修改应用程序或开发库都会自动进行测试。这种可重复的评估方式可以实现快速迭代,并让问题诊断变得更容易。
我们也想对我们的Streams应用程序进行同样的测试。除了自动化端到端测试(使用生成的数据在staging环境中运行流式处理应用程序),我们还想进行更快、更轻量级且更容易调试的单元测试和集成测试。
Streams应用程序的主要测试工具是TopologyTestDriver。自发布1.1.0版本以来,它的API经过了重大改进。从2.4版本开始,它变得越来越容易使用。这些测试看起来就像是普通的单元测试。我们定义输入数据,将其生成到模拟输入主题,然后用这个工具运行拓扑,从模拟输出主题读取结果,并将结果与期望值进行对比。
除了单元测试,还需要进行集成测试。对Streams来说,有两个流行的集成测试框架:EmbeddedKafkaCluster和Testcontainers。前者的broker和测试代码运行在同一个JVM中,后者的broker运行Docker容器中(还有其他需要用到的组件)。建议使用Testcontainer,因为它使用了Docker,可以将Kafka、依赖项和要用到的资源与要测试的应用程序完全隔离开。
扩展拓扑
Streams的伸缩方式有两种,一种是在一个应用程序实例中运行多个线程 ,一种是在分布式实例之间进行负载均衡 。我们可以在一台机器上使用多线程或在多台机器上运行Streams应用程序,不管是哪一种,应用程序中的所有活动线程都将均衡地分摊数据处理工作。
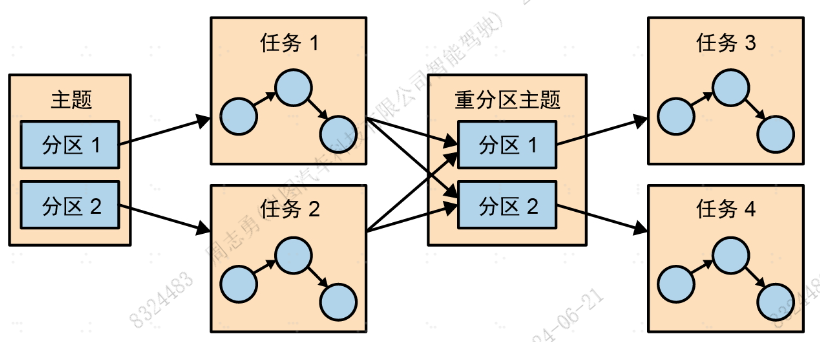
Streams引擎会将拓扑分为多个并行执行的任务。任务数由Streams引擎决定,也取决于应用程序处理的主题有多少个分区。每个任务负责处理一部分分区:它们会订阅这些分区并从分区中读取事件。对于所读取的每一个事件,任务都会在将最终结果写入目标主题之前按顺序执行所有的处理步骤。这些任务是Streams最基本的并行执行单元,每个任务都可以独立执行,如下图所示:

应用程序开发人员可以选择每个应用程序使用的线程数。
如果有多个线程可用,则每个线程将执行一部分任务。如果有多个应用程序实例运行在多台服务器上,那么每台服务器上的每一个线程都将执行一部分不同的任务。
这就是流式处理应用程序的伸缩方式:主题有多少分区,就有多少个任务 。如果想处理得更快,则可以添加更多的线程。如果一台服务器的资源被耗尽,就在另一台服务器上启动另一个应用程序实例。Kafka会自动协调任务,也就是说,它会为每个任务分配属于它们的分区,让每个任务独自处理属于自己的分区 ,并在必要时维护与聚合相关的本地状态,如下图所示:

Streams会将连接所需的所有分区分配给同一个任务,这样任务就可以读取所有相关分区并独立执行连接操作。这就是为什么Streams要求所有参与连接操作的主题都要有相同的分区数,并基于连接所使用的键进行分区。
应用程序重新分区也会导致任务间产生依赖关系。例如,在"填充点击事件流"示例中,所有事件都使用用户ID作为键。
如果想基于页面或邮政编码生成统计信息该怎么办?Streams需要用邮政编码对数据进行重新分区,并对新分区执行聚合操作。
假设任务1在处理分区1的数据,这时遇到一个对数据进行重新分区(groupBy操作)的处理器,它需要shuffle数据,或者把数据发送给其他任务。
与其他流式处理框架不同,Streams会将事件写到新主题上,并使用新的键和分区,以此来实现重新分区。然后,另一组新任务会从新主题上读取和处理事件。
重分区会将拓扑拆分成两个子拓扑,每个子拓扑都有自己的任务集。第二个任务集依赖于第一个任务集,因为它们处理的是第一个子拓扑的结果。不过,这两组任务仍然可以独立并行执行,因为第一个任务集会按照自己的速率将数据写到一个主题上,第二个任务集也会按照自己的速率从这个主题读取和处理数据。两个任务集之间不需要通信,不共享资源,也不需要运行在相同的线程或服务器上。这是Kafka提供的最有用的特性之一------减少管道各个部分之间的依赖 ,如下图所示:
在故障中存活下来
Streams的扩展模型不仅允许扩展应用,还能让我们优雅地处理故障。首先,Kafka是高可用的,所以保存在Kafka中的数据也是高可用的。如果应用程序发生故障需要重启,那么可以从Kafka中找到上一次处理的数据在流中的位置,并从这个位置继续处理。如果本地状态丢失(比如可能需要替换服务器),则应用程序可以从保存在Kafka中的变更日志重新创建本地状态。
Streams还利用了消费者的协调机制来实现任务高可用性。如果一个任务失败,那么只要还有其他活跃的线程或应用程序实例,就可以用另一个线程来重启这个任务。这类似于消费者群组的故障处理:如果一个消费者失效,就把分区分配给其他活跃的消费者。
虽然这里所说的高可用性方法在理论上是可行的,但在现实中存在一定的复杂性,其中一个比较重要的问题是恢复速度。当一个线程开始继续处理另一个故障线程留给它的任务时,它需要先恢复状态(比如当前的聚合窗口)。这通常是通过重新读取内部Kafka主题来实现的。在恢复状态期间,流式处理作业将暂停处理数据,从而导致可用性降低和数据过时。
因此,缩短恢复时间往往就变成了缩短恢复状态所需的时间。这里的关键在于要确保所有的Streams主题都是主动压实的------减小min.compaction.lag.ms的值,并将日志片段大小设置为100 MB,而不是默认的1 GB(需要注意的是,每个分区的最后一片段,也就是活跃片段,不会被压实)。
为了让恢复进行得更快一些,建议使用任务备用副本(standby replica)。这些任务是活跃的影子任务,会在其他服务器上保留当前状态。当发生故障转移时,它们已经拥有最新的状态,并准备好在几乎不停机的情况下继续处理数据。