一、Sqoop安装
1 上传安装包并解压缩(在hadoop101上)
cd /opt/software
点击xftp上传sqoop的安装文件sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
-C /opt/module/
cd /opt/module/
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop
2 修改配置文件(在hadoop101上)
cd /opt/module/sqoop/conf
mv sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
======添加内容如下=======
bash
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3
export HIVE_HOME=/opt/module/hive列出mysql中所有数据库
bash
sqoop list-databases --username root --password 123456 --connect jdbc:mysql://localhost:3306/结果如下:
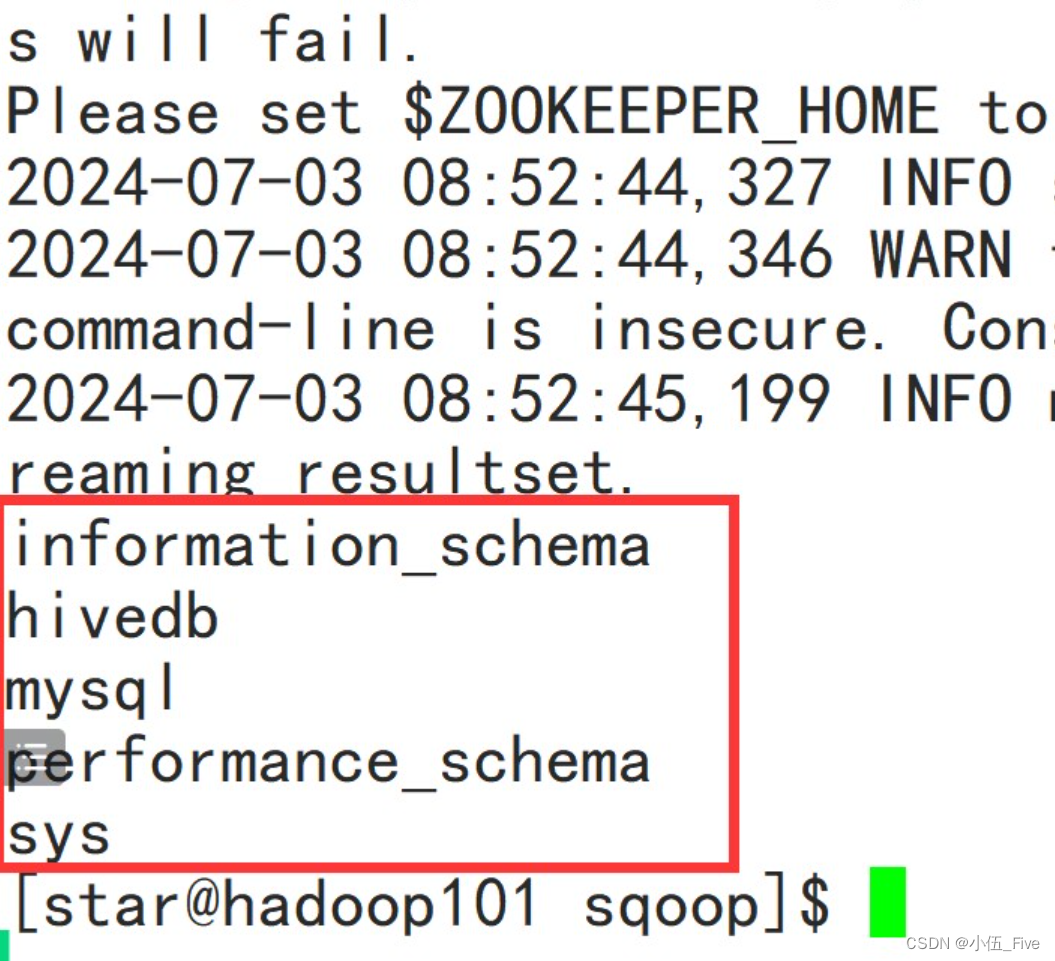
二、Hadoop的安装(windows)
1 解压缩hadoop-3.1.0.rar
复制到根目录
E:\hadoop-3.1.0
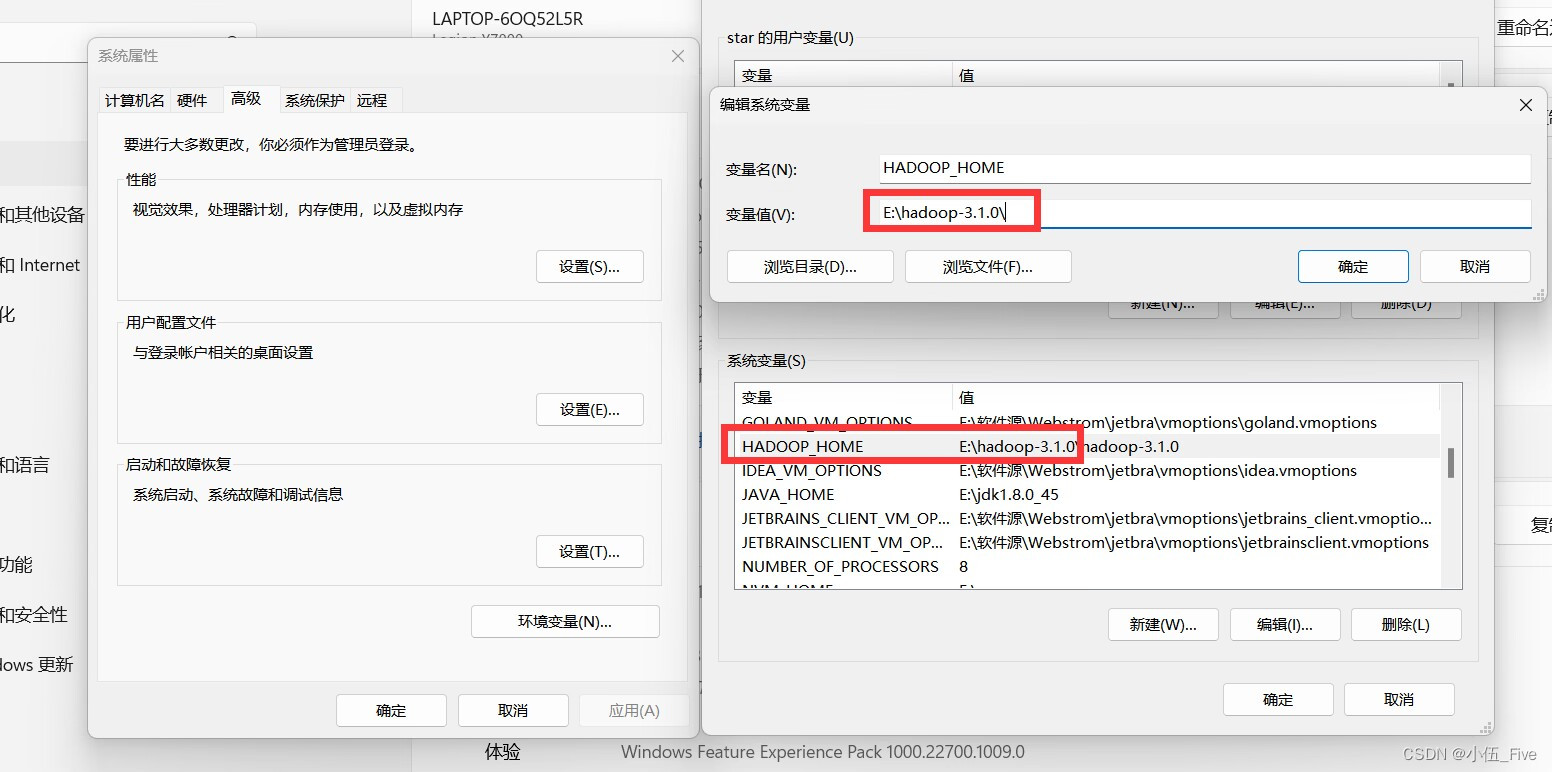
2 环境变量设置
此电脑===>右击属性===>高级系统变量
===>环境变量===>系统变量(新建 HADOOP_HOME 设置的值E:\hadoop-3.1.0)
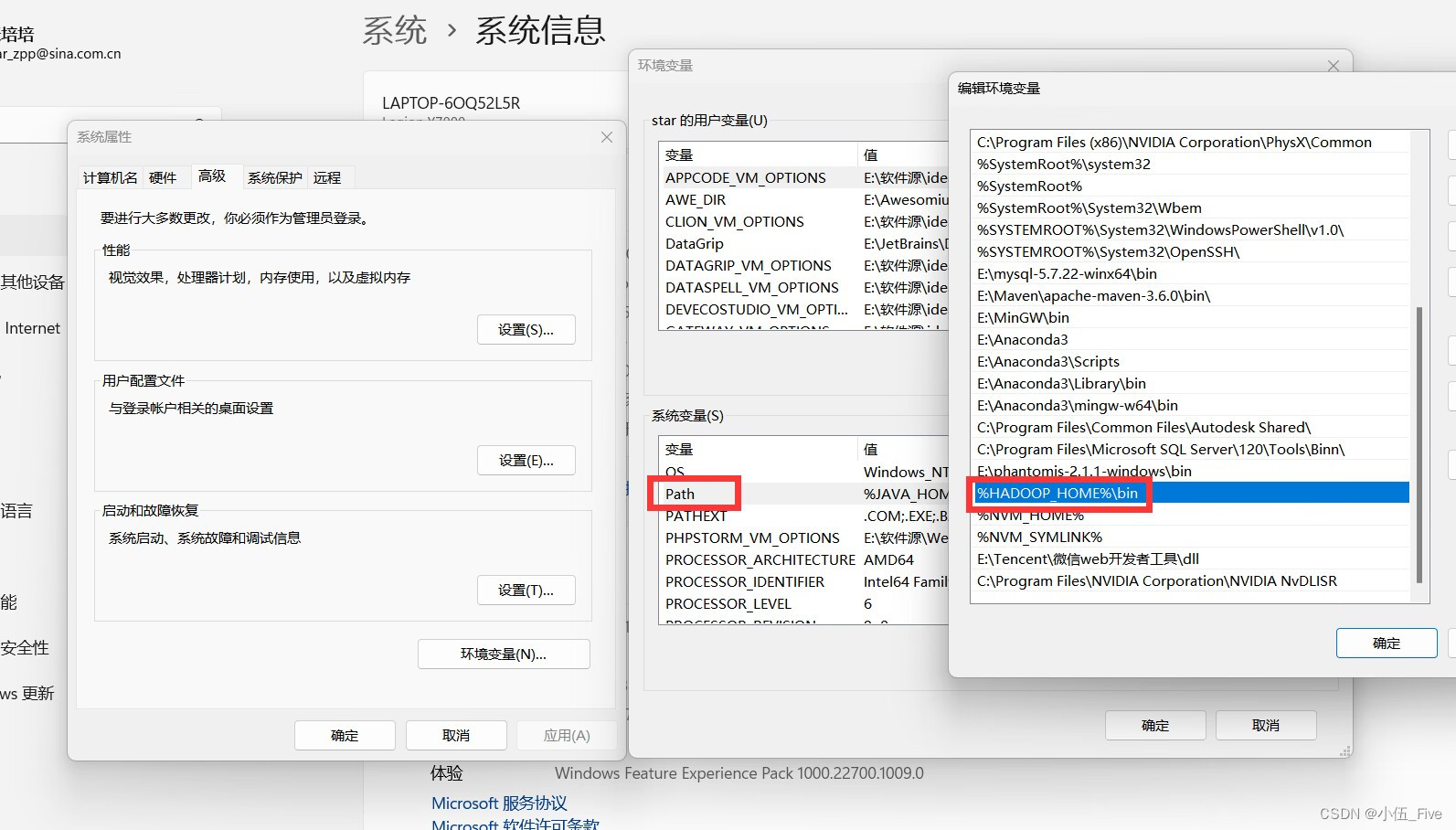
===>系统变量path(新建$HADOOP_HOME/bin)
3 测试是否成功
运行===>cmd===>hadoop version

三、 idea安装
-
找到IDEA 2023.1.zip
-
解压缩
-
双击stepup.exe的安装
注意事项:
1.安装目录不要有中文路径
2.需要勾选添加环境变量 add path
3.勾选java选项 .java
4.添加桌面快捷方式 64位
5.勾选删除以前的idea安装 uninstall
6.添加主菜单 add Menu...
- 破解idea
找到 IDEA 2023.1.zip\Crack\jetbra\scripts
双击 install.vbs 或者install-current-user.vbs
弹出一个框 点击确定/OK
等一个世纪
会自动再弹出一个框 点击确定/OK
- 添加注册码
打开idea会弹出一个注册框
Activte code 选择中间选项
将注册码.txt中注册码复制到文本框中
四、 Maven安装配置
- 解压缩apache-maven-3.6.0.zip
E:\Maven\apache-maven-3.6.0
不要有中文路径以及空格等
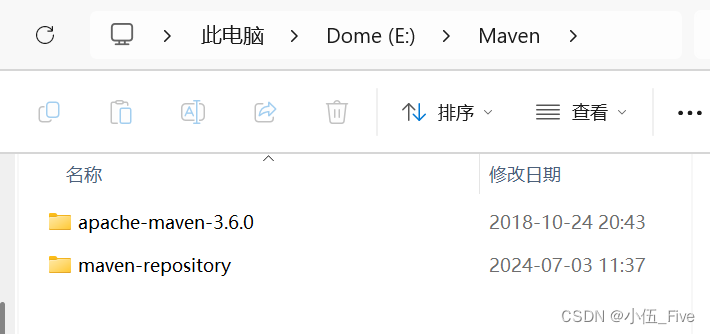
- 新建本地仓库
E:\Maven\maven-repository
- 设置配置文件
找到E:\Maven\apache-maven-3.6.0\conf
复制所给的settings.xml覆盖原始的文件
使用记事本打开settings.xml文件
=========修改内容如下=====
<localRepository>E:\Maven\maven-repository</localRepository>
将这个目录修改成自己的本地仓库目录
===========================
- 用idea配置maven
设置maven的目录
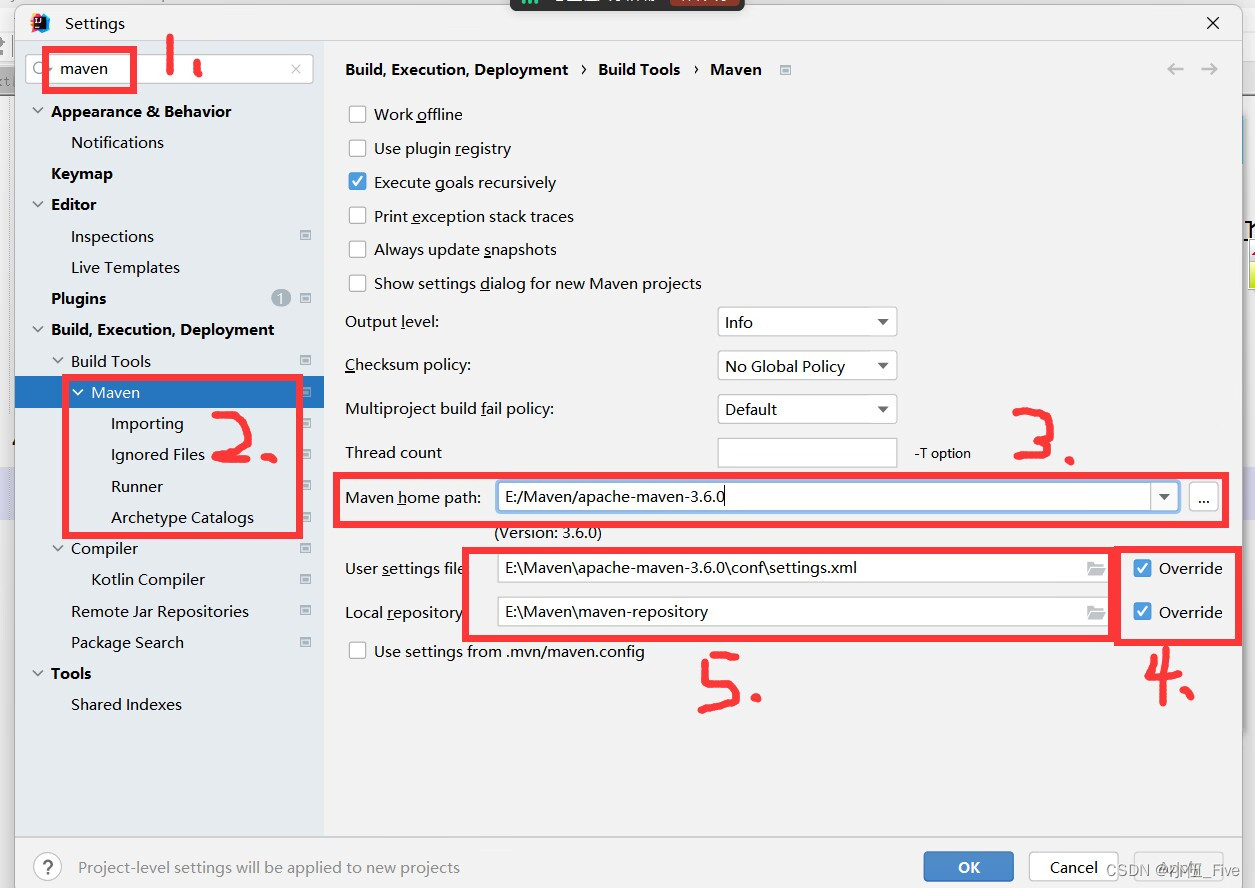
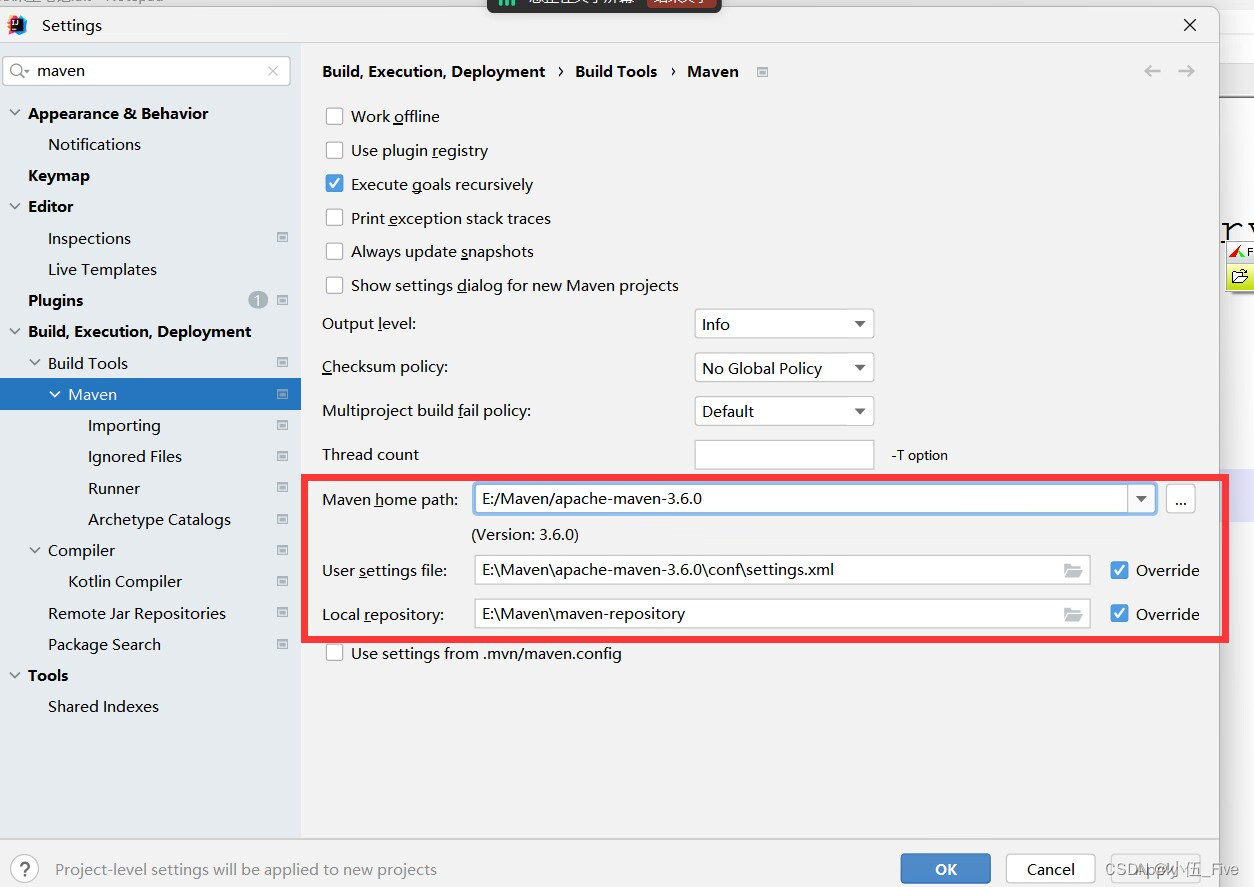
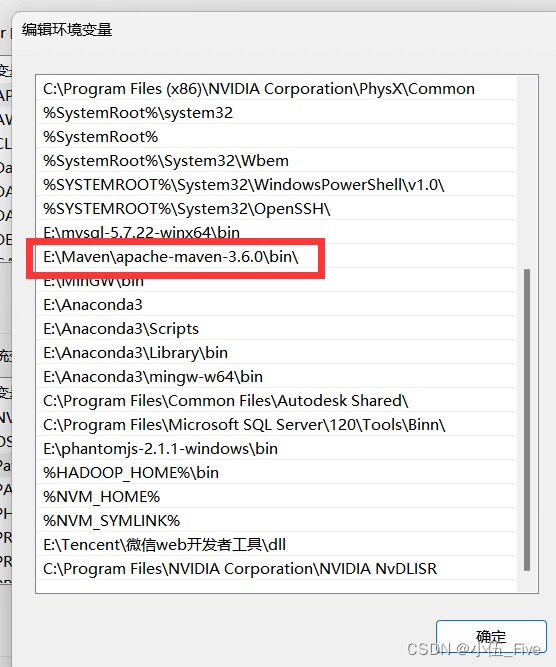
- 配置maven的环境变量
此电脑==>属性==>高级系统变量
===>环境变量===>系统变量(path)
===>新建输入值 E:\Maven\apache-maven-3.6.0\bin\
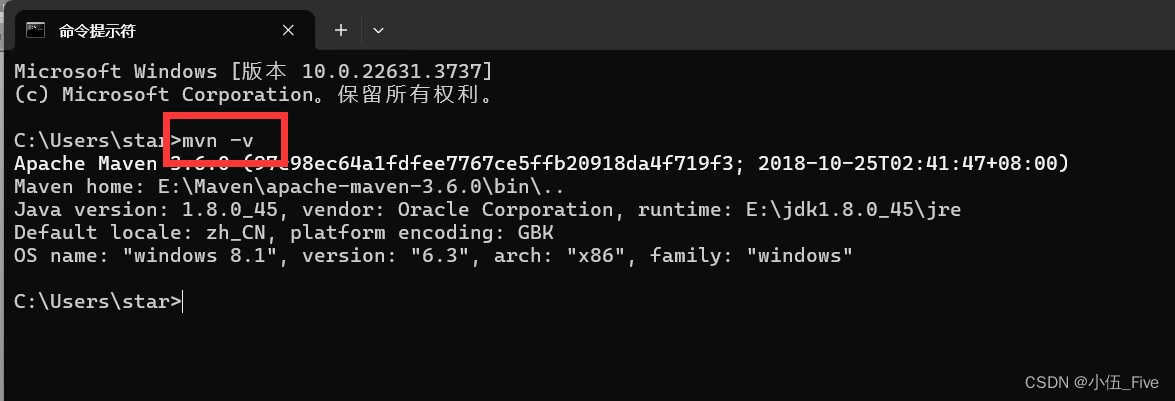
- 测试Maven的环境变量
运行==>cmd===>mvn -v
五、数据预处理
接着去idea进行配置
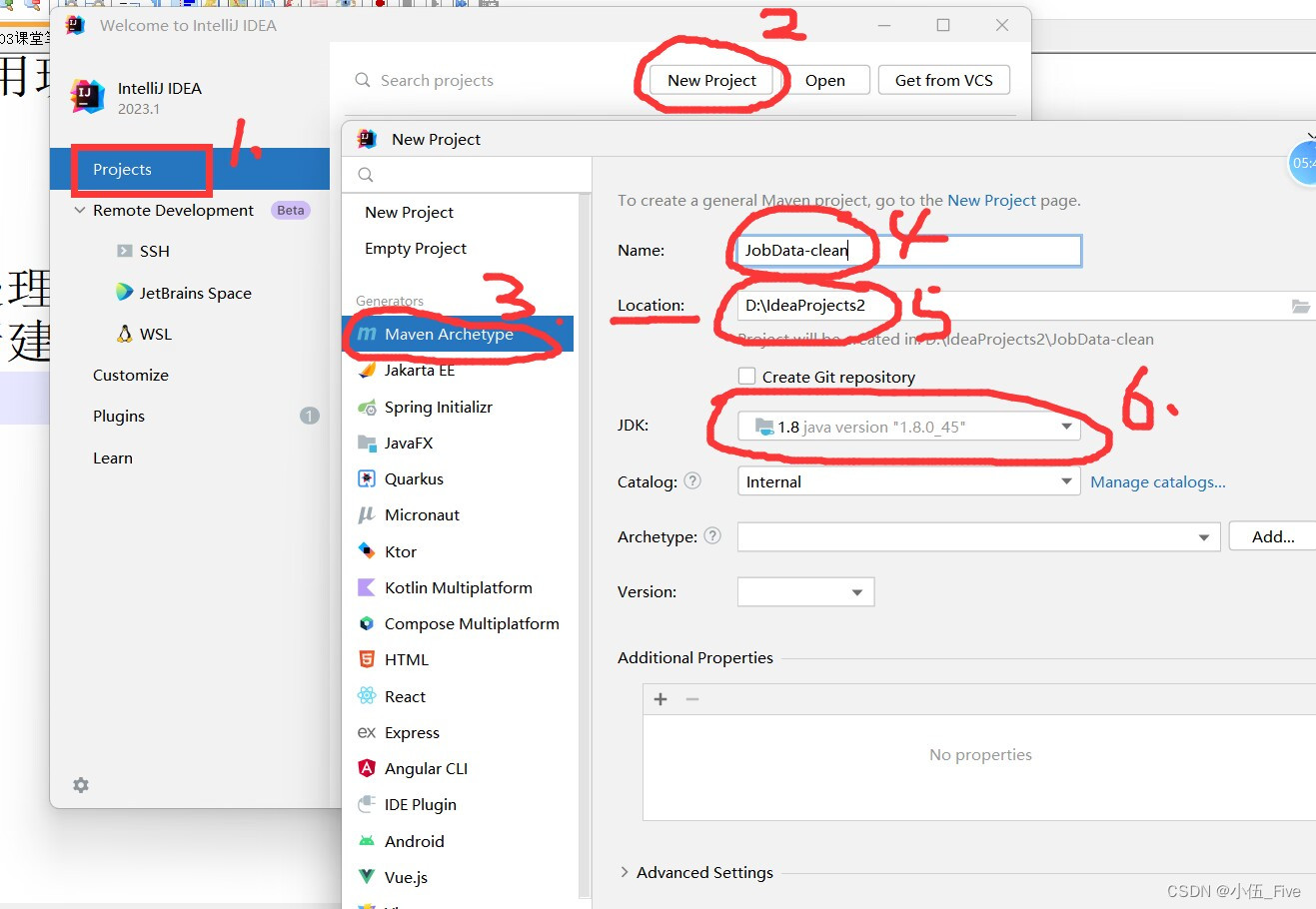
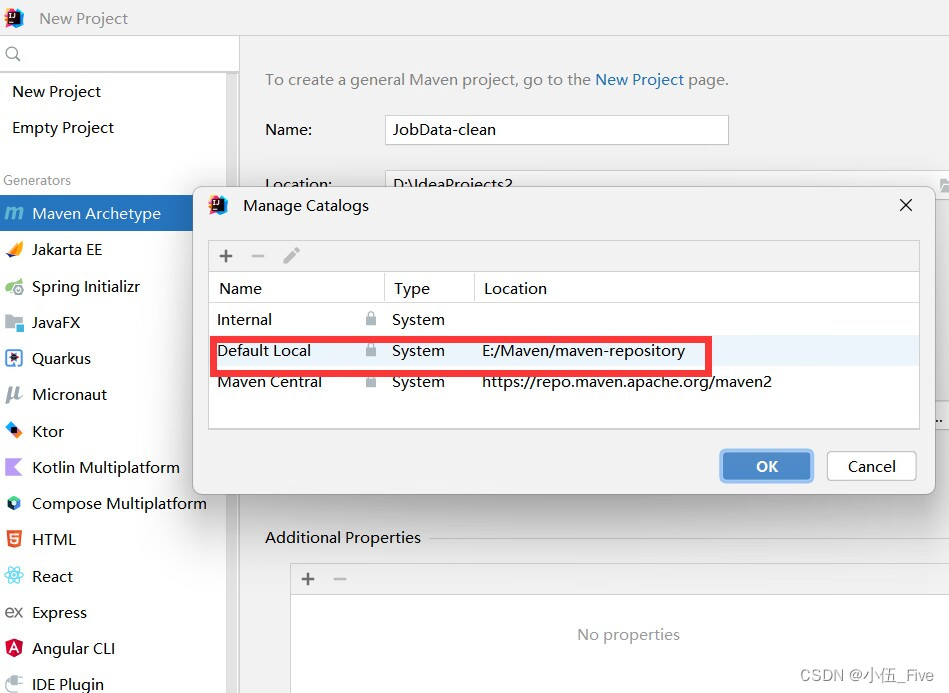
1.新建Mavne项目 JobData-clean
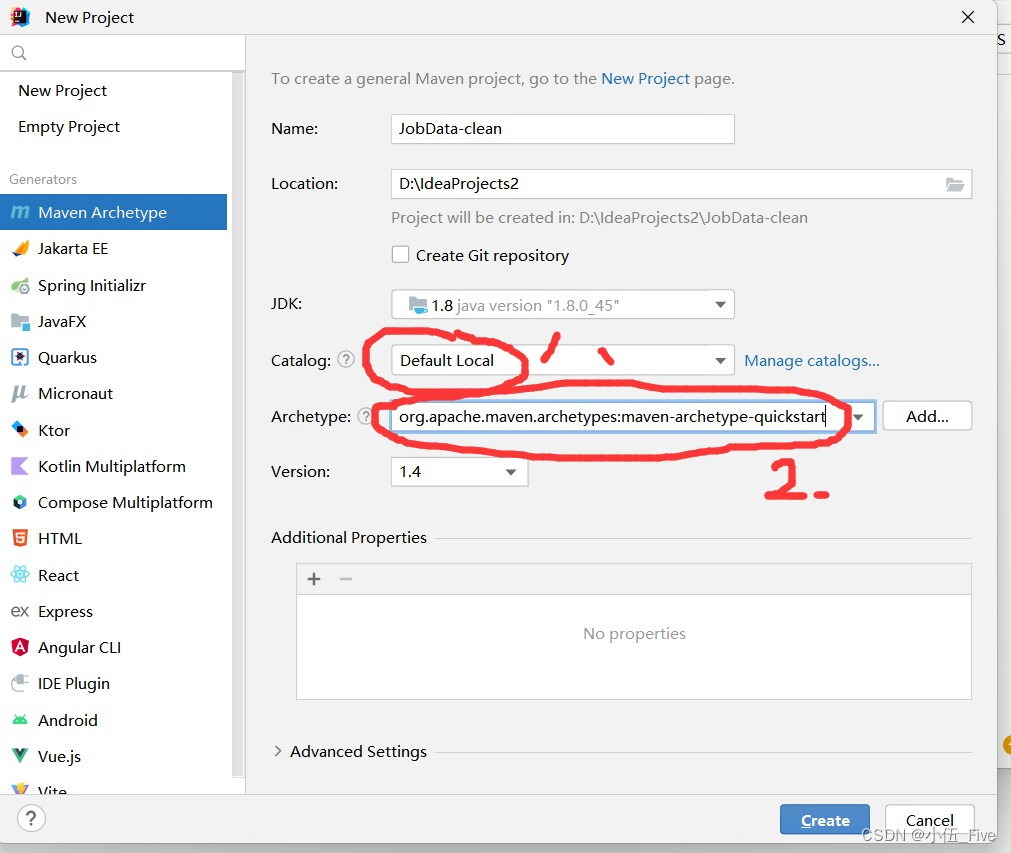
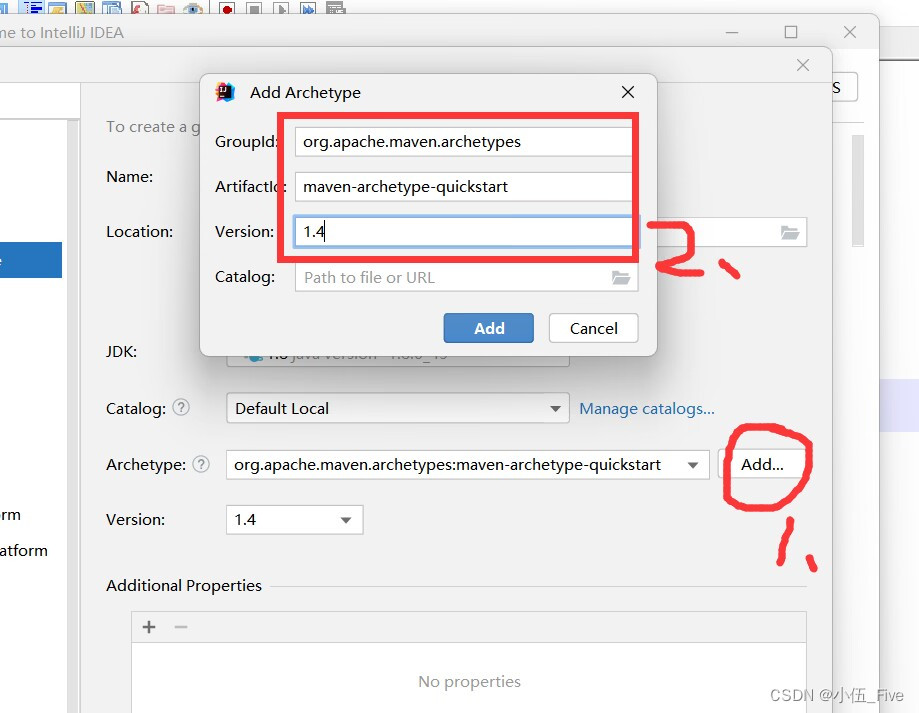
文件夹已经存在文件
2.在pom.xml中添加依赖管理
pom.xml添加依赖
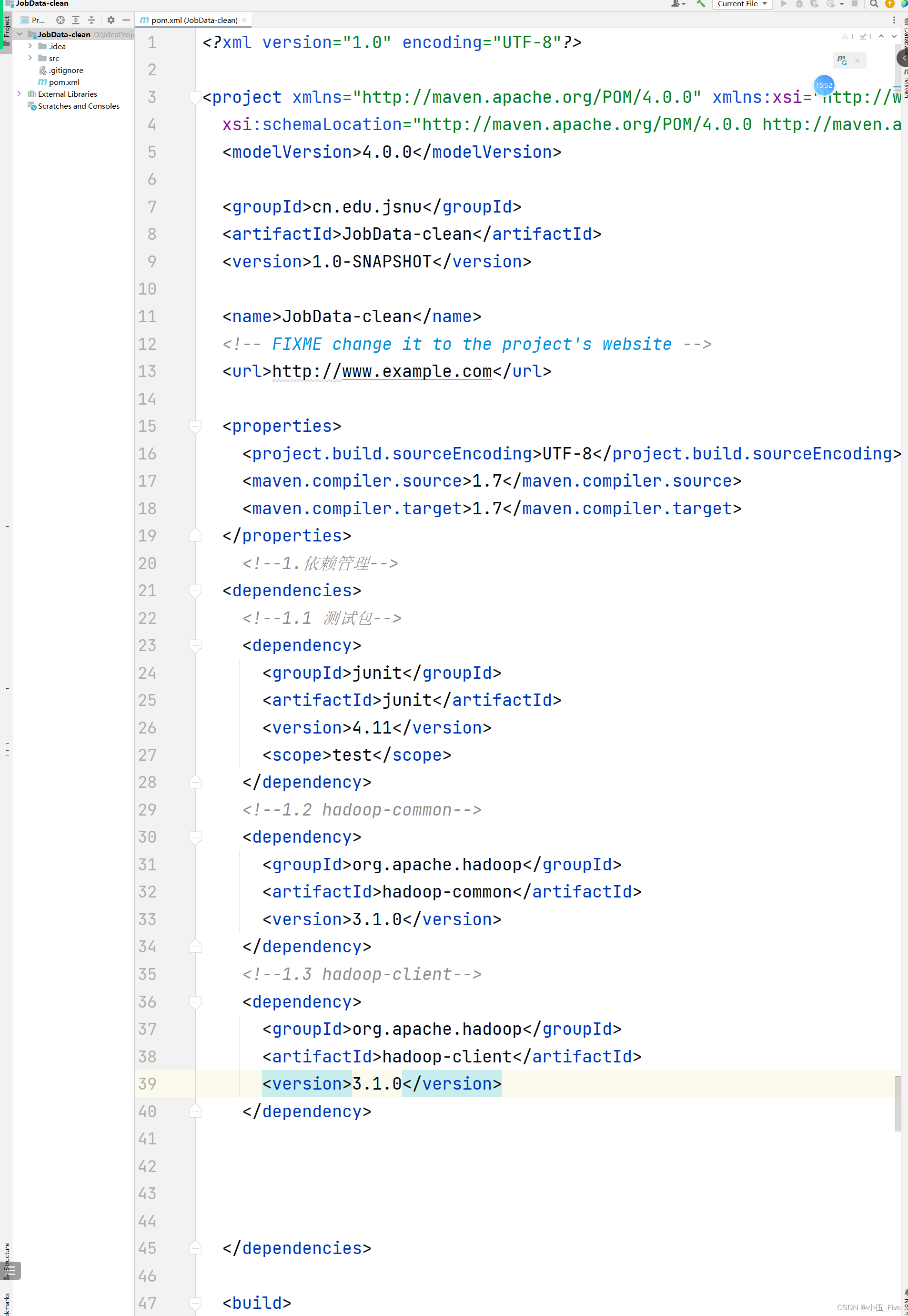
XML
<!--1.依赖管弹-->
<dependencies>
<!--1.1测试包-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!--1.2 hadoop-common-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.0</version>
</dependency>
<!--1.3 hadoop-client-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.0</version>
</dependency>
</dependencies>遇到报错则 选择pom.xml===>右击===>Maven===>reload project
3.创建类 cn.edu.aust.clean 类CleanJob
java
package cn.edu.aust.clean;
import org.codehaus.jettison.json.JSONArray;
import org.codehaus.jettison.json.JSONException;
import org.codehaus.jettison.json.JSONObject;
public class CleanJob {
/**
* 数据清洗结果
* 将hdfs==>/JobData/20240703/page1....30
* JSONs数据类型
* @param jobdata
*待处理的职位信息数据
* @return
*/
public static String resultToString(JSONArray jobdata) throws JSONException {
//1.设置结果字符串
String jobResultData = "";
//2.循环遍历所有的职位信息数据
for (int i = 0;i < jobdata.length();i++){
String everyData = jobdata.get(i).toString();
JSONObject everyDataJson =
new JSONObject(everyData);
String city = everyDataJson.getString("city");
String salary =everyDataJson.getString("salary");
//2.5 获取职位信息中福利标签数据
String positionAdvantage = everyDataJson.getString(
"positionAdvantage");
// 2.6获取职位信息中公司数据
JSONArray companyLabelList =
everyDataJson.getJSONArray(
"companyLabelList");
//2.7
JSONArray skillLabels =
everyDataJson.getJSONArray("skillLables");
String salaryNew = deLeteString(salary,'k');
//2.9
String welfare = mergeString(positionAdvantage,companyLabelList);
//2.10
String kill = killResult(skillLabels);
//2.11
if(i == jobdata.length()-1){
jobResultData = jobResultData
+city+","
+salaryNew+","
+welfare+","
+kill;
//合肥,15000,"五险一金。。。"
}else{
jobResultData = jobResultData
+city+","
+salaryNew+","
+welfare+","
+kill+"\n";
}
}
return jobResultData;
}
/**
*2 删除字符串指定字符 10k-15k 删除k值
* @param str
* @param delChar
* @return
*/
public static String deLeteString(
String str , char delChar){
// 1.设置可变长度字符串类型
StringBuffer stringBuffer = new StringBuffer("");// 2.循环字符串的所有字符
for(int i = 0;i < str.length();i++){
// 2.1判断字符是否和指定字符- -致
if(str. charAt(i) != delChar){
// 2.2不一一致的情况则将值添加到stringBuffer中
stringBuffer.append(str.charAt(i));
}
}
return stringBuffer. toString();
}
/*
*3删除福利标签中的所有内容
*/
public static String mergeString(
String position,JSONArray company)
throws JSONException{
String result = "";
if (company.length()!=0){
for(int i=0;i<company.length();i++){
result =result +company.get(i)+"-";
}
}
if(position != ""){
String[] positionList =
position.split(" |;|,|、|,|;|/");
for(int i=0;i< positionList.length;i++){
result =
result + positionList[i].
replaceAll(
"[\\pP\\p{Punct}]",""
)+"-";
}
}
return result.substring(0,result.length()-1);
}
/*
4.处理技能标签
*/
public static String killResult(
JSONArray killData
) throws JSONException{
String result = "";
if(killData.length()!=0){
for(int i=0;i<killData.length();i++){
result =result+killData.get(i)+"-";
}
result = result.substring(0,result.length()-1);
}
return result;
}
}4 创建类 CleanMapper类 Mapreduce
java
package cn.edu.aust.clean;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.codehaus.jettison.json.JSONObject;
import org.codehaus.jettison.json.JSONArray;
import org.codehaus.jettison.json.JSONException;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class CleanMapper extends Mapper<LongWritable,Text,Text,NullWritable>{
@Override
public void map(LongWritable key, Text value,
Mapper<LongWritable,Text,
Text, NullWritable>.Context context)
throws IOException,InterruptedException{
String jobResultData = "";
String reptileData = value.toString();
String jobData = reptileData.substring(
reptileData.indexOf("=",reptileData.indexOf("=")+1)+1,
reptileData.length()-1);
try {
//4
JSONObject contentJson = new JSONObject(jobData);
//5
String contentData =
contentJson.getString("content");
//6
JSONObject positionResultJson =
new JSONObject(contentData);
//7
String positionResultData =
positionResultJson.getString(
"positionResult"
);
//8
JSONObject resultJson =
new JSONObject(positionResultData);
JSONArray resultData =
resultJson.getJSONArray("result");
//9
jobResultData = CleanJob.resultToString(
resultData);
//10
context.write(new Text(jobResultData),
NullWritable.get());
}catch(JSONException e){
throw new RuntimeException(e);
}
}
}5 创建类 CleanMain
java
package cn.edu.aust.clean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.log4j.BasicConfigurator;
import java.io.IOException;
public class CleanMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 控制台输出日志
BasicConfigurator.configure();
// 初始化hadoop配置
Configuration conf = new Configuration();
// 从hadoop命令行读取参数
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
// 4.判断命令行读取的参数正常为两个
if (otherArgs.length != 2) {
System.err.println("Usage: clean <in> <out>");
System.exit(2);
}
// 5.定义一个新的job,第一个参数是job配置信息,第二个参数是job的名字
Job job = Job.getInstance(conf, "job");
// 6.设置主类
job.setJarByClass(CleanMain.class);
// 7.设置mapper类
job.setMapperClass(CleanMapper.class);
// 8.处理小文件,默认是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
// 9.n个小文件之和不能大于2M
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);
// 10.n个小文件之和大于2M,情况下需要满足的条件,
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
// 11.设置job输出数据的key类
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 12.设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// 13.启动job
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}6 启动Hadoop集群(在hadoop101上)
cd /opt/module/hadoop-3.1.3/sbin
start-dfs.sh
7 启动yarn(在hadoop102上)
cd /opt/module/hadoop-3.1.3/sbin
start-yarn.sh
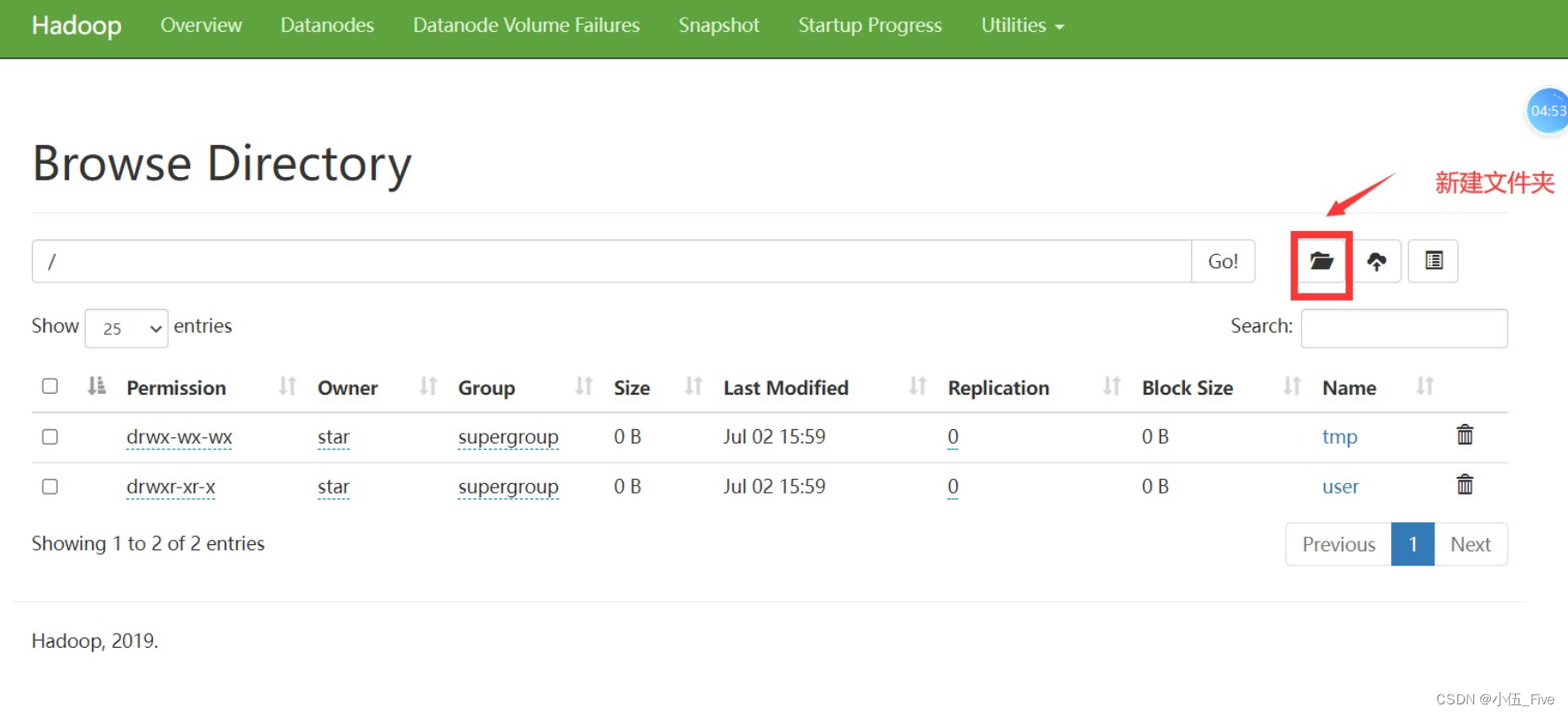
8 新建文件夹以及数据内容到hdfs上
上Utilitls===>Broser the system file
===>新建/JobData/20240703/
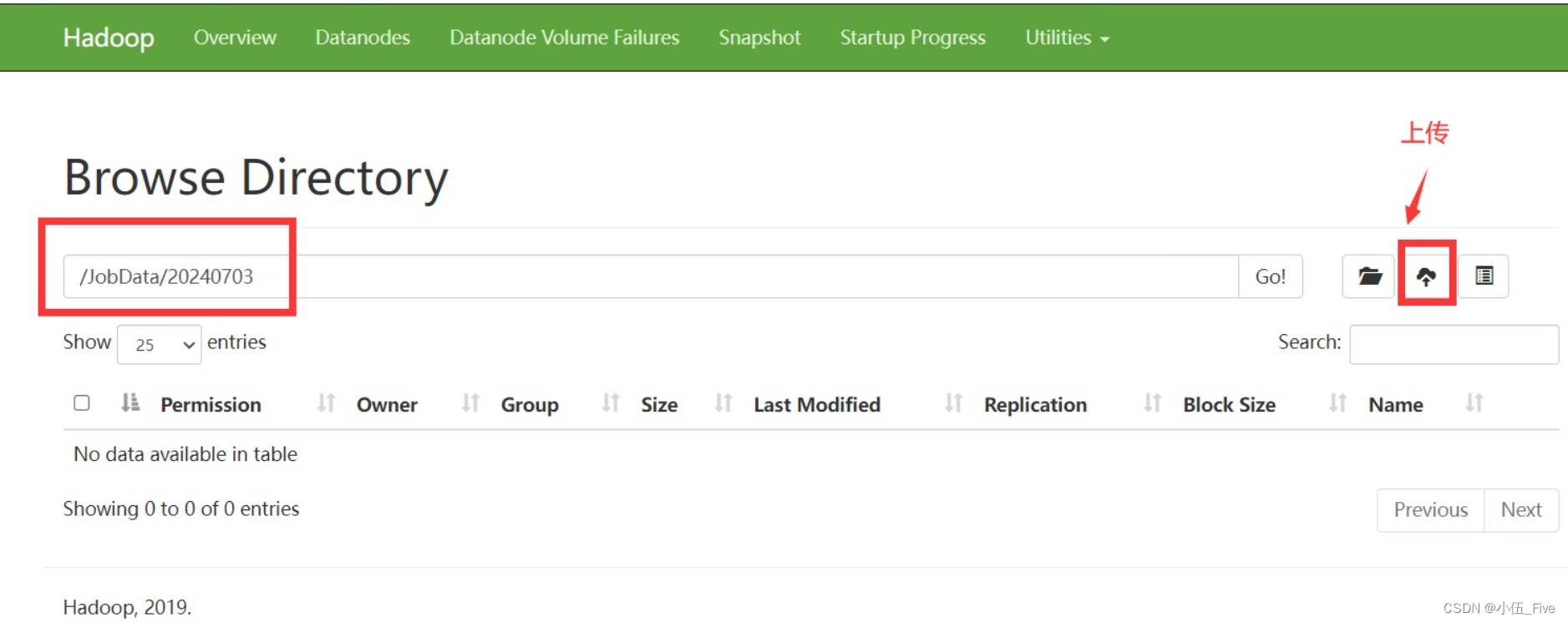
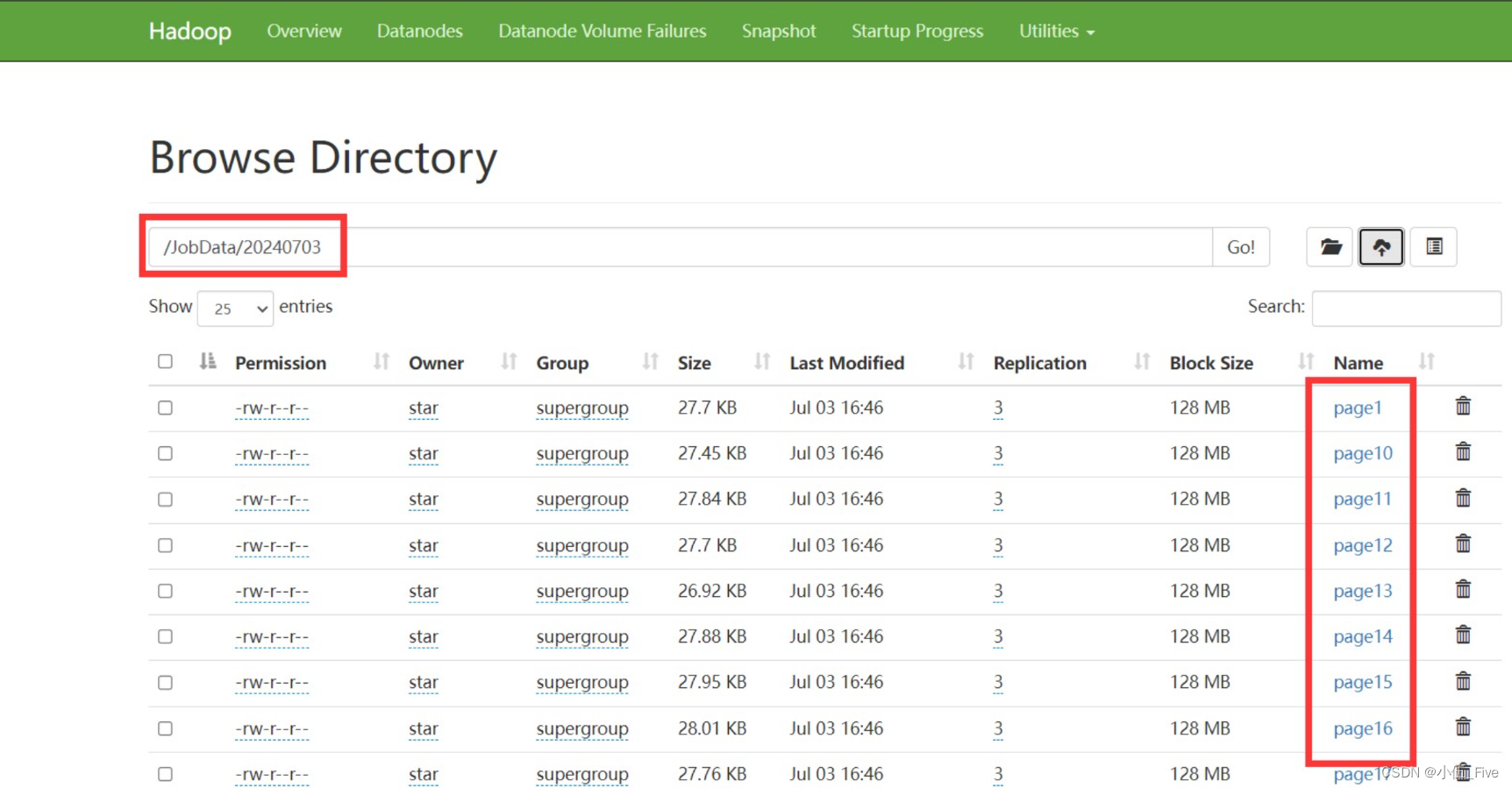
上传page1-page30
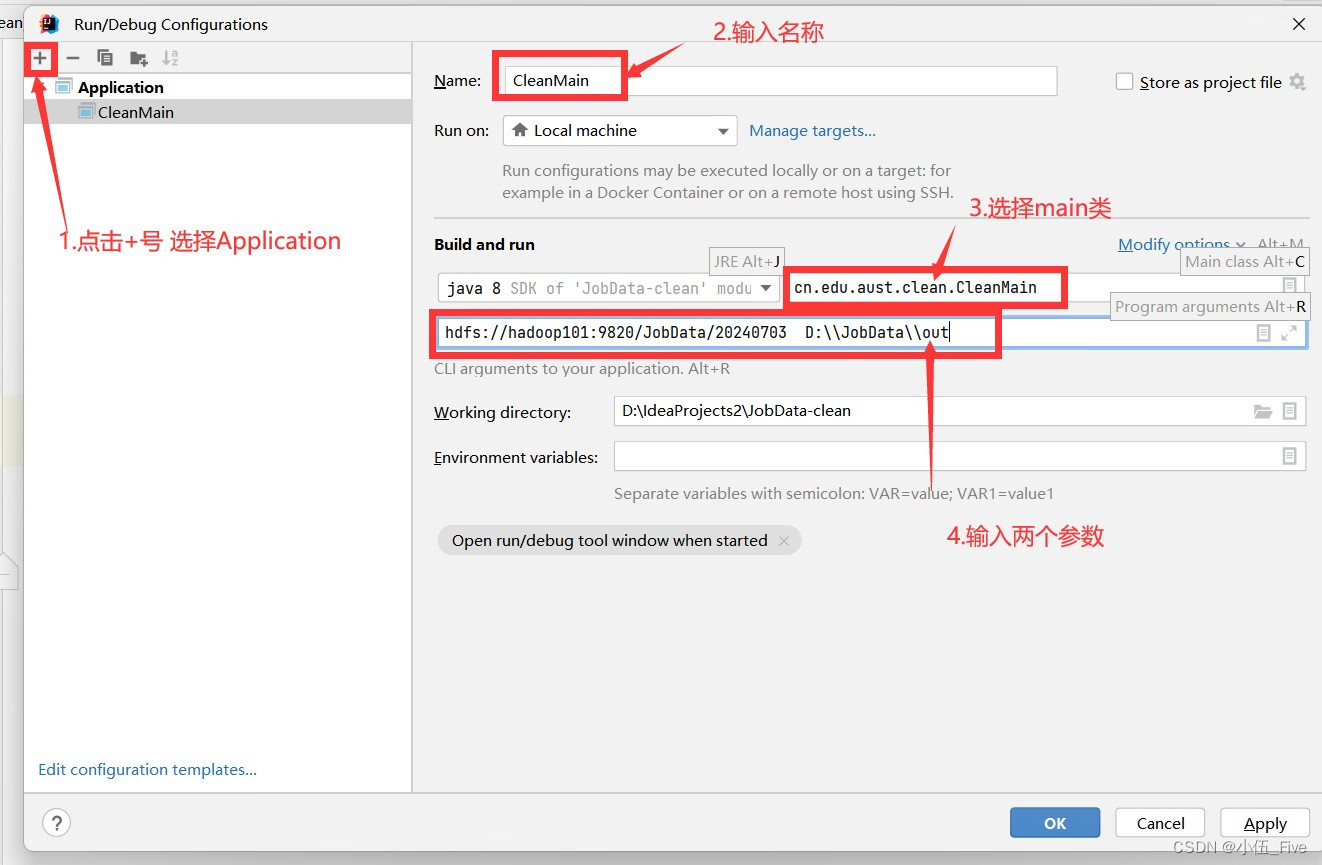
9 设置运行参数
idea右上角的播放按钮左边===>选择==>Edit....
===>点击左上角+==>选择Application
===>再选择Main class==>选择CleanMain
===>Name输入CleanMain
====>在Propam...===>输入以下内容
hdfs://hadoop101:9820/JobData/20240703 D:\\JobData\\out
完成之后 点击播放按钮执行代码
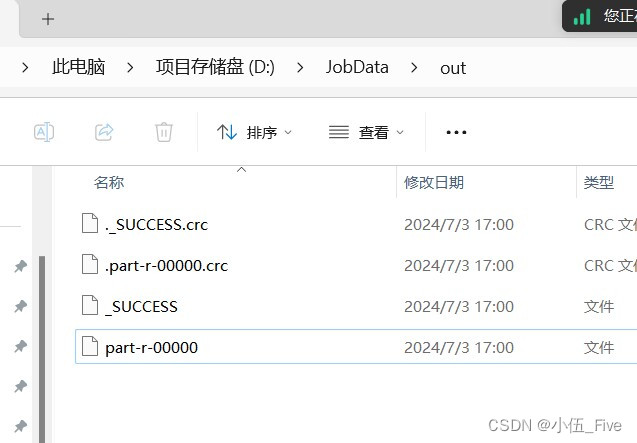
10 问题解决方案
新建包org.apache.hadoop.io.nativeio
复制目录下类org.apache.hadoop.io.nativeio.NativeIo
到该目录下
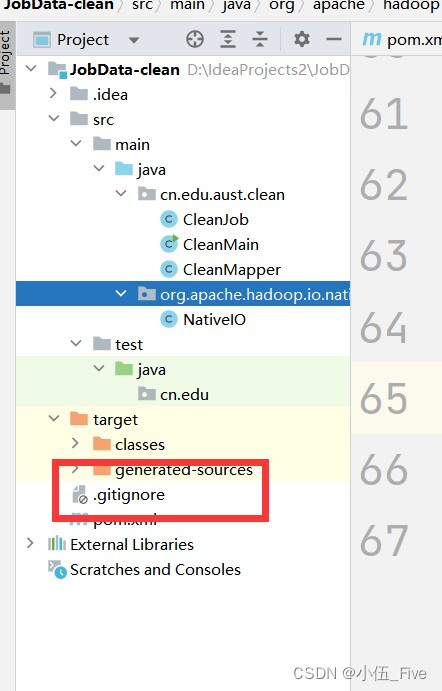
11 打包上传到software中
idea中右侧Maven标签==>Lifecycle===>package
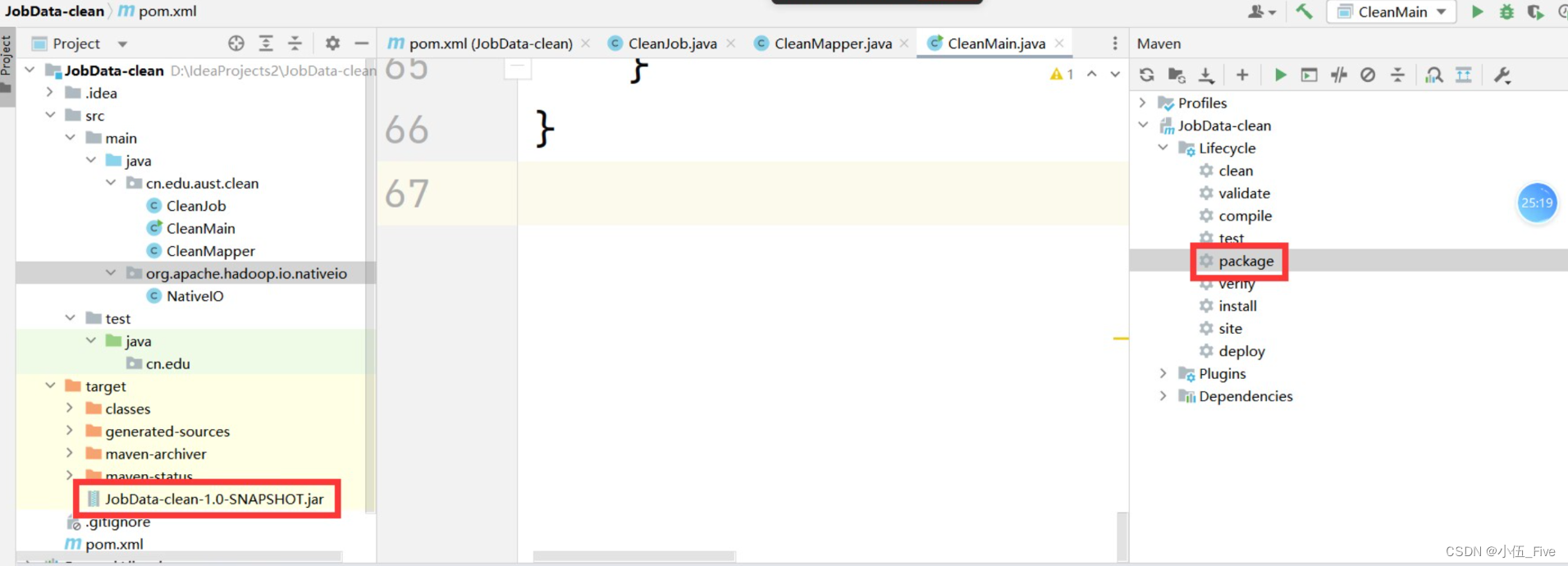
===>双击package===>左侧项目结构中==>target
==>JobData-clean-1.0-SNAPSHOT.jar
在hadoop101上 /opt/software目录中上传
JobData-clean-1.0-SNAPSHOT.jar
12 执行数据预处理(在hadoop101上)
cd /opt/software
hadoop jar JobData-clean-1.0-SNAPSHOT.jar
cn.edu.aust.clean.CleanMain
/JobData/20240703
/JobData/output