在第 5 章中,我们基于 Oceanic Airlines 的参考架构,探讨了 Medallion 架构中 Bronze 层的基础设计与搭建。我们审视了部署与配置,并通过大量代码片段与示例加深理解。你已经了解到,由于源系统不断演进且复杂多变,要打造一个可查询的 Bronze 层颇具挑战。
接下来,本章将在此基础上继续前进,构建 Medallion 架构中的下一层------Silver 层,其目标是对数据进行精炼、清洗与标准化。我们将按以下顺序深入几个关键领域:
- 通过元数据驱动的方法确保数据完整性
- 清洗数据以提升质量
- 将数据转为便于访问的反规范化模型
- 对数据进行丰富(可能结合主数据管理)
- 实施数据历史化以追踪随时间的变更
- 关注优化类作业
- 使用 Airflow 编排数据管道,实现端到端自动化处理
与第 5 章类似,本章将引导你完成关键配置步骤与编码实践。将包含可直接在你的项目中实施的动手练习,如元数据驱动的校验、数据清洗与历史化任务。
本章还将讨论多种数据转换与数据质量工具,例如 dbt、DLT 与 Great Expectations 等。此外,我们会探讨"数据产品"的概念,以及你的组织是否应在 Silver 层采用该思路。读完本章,你将充分理解 Silver 层的设计考量,并掌握其实现方法。
需要说明的是,尽管 Oceanic Airlines 的示例聚焦于批处理场景,但这些设计考量与最佳实践同样适用于实时数据采集。因此,你在此学到的原则具有通用性,可适配多种数据处理场景。
在深入 Silver 层之前,先快速回顾一下目前进展。
快速回顾
在第 4 与第 5 章中,我们奠定了 Medallion 架构的基础:完成了环境搭建、在 Azure SQL 中部署了 AdventureWorks 数据库,并使用 Data Factory 构建了数据管道,将数据摄取并存储为 Delta 表。我们也强调了模式(schema)管理的重要性,为后续深入做好铺垫。
本章将在此基础上构建 Silver 层。练习首先从实现一种元数据驱动的方法入手(见图 6-1 顶部)。该元数据存储在 Silver 层中用于驱动技术校验,使流程更自动、更高效。随后,你将推进所有构建 Silver 层所需的数据转换相关活动。
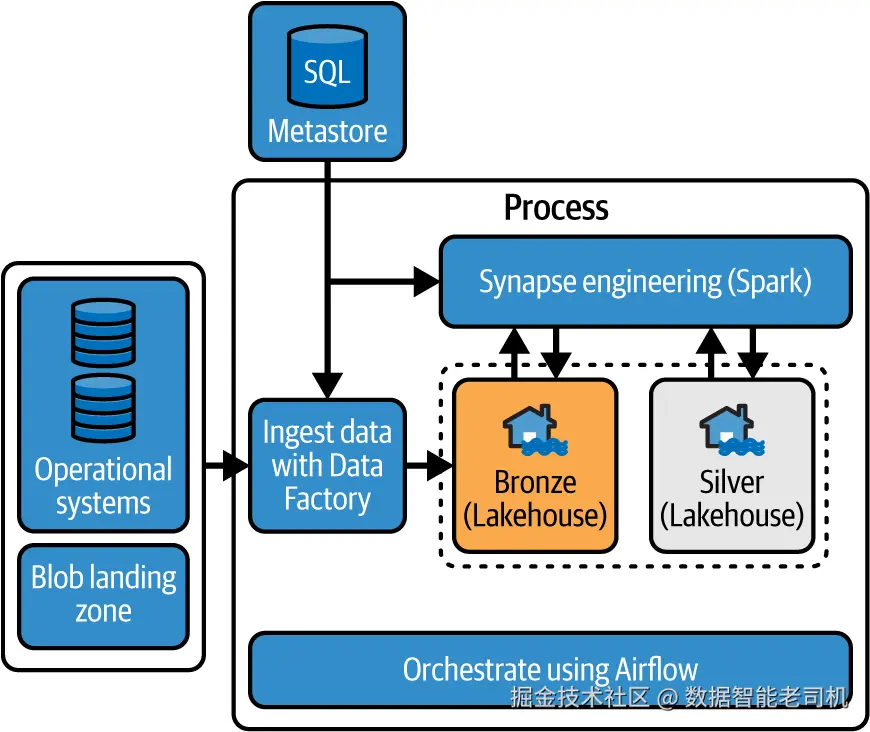
图 6-1.成功实现 Silver 层后的整体设计
此外,你还将了解用于管理数据管道的编排层(见图 6-1 底部)。这是一项关键组件。下面让我们动手实践,看看这些要素如何协同,来增强整体数据架构。
实现元数据驱动方法
新建的架构已进入一个更具活力的阶段。你在摄取阶段了解到,源系统常常需要定制管道与专用脚本来变换文件格式;有时还要增加集成服务或预落地区域。Bronze 层的复杂性会削弱标准化,进而增加数据处理管道的维护与扩展难度。
不过,Silver 层的可预测性更强,因为 Bronze 层的数据已被标准化存为 Delta 表。这种标准化让你可以在 Silver 层实现更高程度的自动化,此时元数据驱动的方法就尤为有用。
元数据驱动的方法利用"关于数据的数据"来自动化数据管理与工程流程,包括数据集成、数据质量校验与数据治理等。通过使用元数据,组织可以提升数据管理的效率与准确性。本质上,这能减少自定义脚本与重复劳动。
要让元数据驱动的方法奏效,一个元存储(metastore)至关重要。元存储是一个(集中式)仓库,用于保存模式结构、源与目标位置、所有权信息与使用详情等元数据。它还能帮助在项目范围内定义并执行数据策略与规则。此外,元存储便于在不同数据管理与工程工具之间共享元数据。例如,你可以用同一份元数据来驱动 Microsoft Fabric 与其他基于 Spark 的环境(如 Azure Databricks)上相同的转换流程。
注意
在本示例中,校验作为"闸门",确保只有通过技术校验的数据才能从 Bronze 进入 Silver 层。但如果确保 Bronze 层的完整性是你的首要关注点,也可以将这些技术检查前移一层。
接下来的小节将指导你实现元数据驱动的方法。你将先新建一个数据库作为元数据存储。然后,从 AdventureWorks 示例数据库收集模式元数据,用于建立数据校验规则。完成初步结论后,继续后续任务(有些需要你亲自实施,有些仅供学习),包括数据清洗、反规范化、轻量级丰富、历史化,以及表的管理与优化。
实施元数据存储
让我们通过再部署一个 Azure SQL 数据库来创建元数据存储。^1 返回 Azure 门户,新建一个任意名称的数据库,本例命名为 metadatastore 。部署完成后打开查询编辑器,新建一张名为 SchemaMetadata 的表,用于保存处理所需的元数据。复制并执行以下 SQL 脚本以创建数据表:
scss
CREATE TABLE SchemaMetadata
(
Id INT IDENTITY(1,1) PRIMARY KEY,
SchemaName NVARCHAR(128),
TableName NVARCHAR(128),
ColumnName NVARCHAR(128),
DataType NVARCHAR(128),
CharacterMaximumLength INT,
NumericPrecision INT,
NumericScale INT,
IsNullable NVARCHAR(3),
DateTimePrecision INT,
IsPrimaryKey BIT DEFAULT 0
)
GO以上脚本创建了新的 SchemaMetadata 表,用于存储数据库模式的各类信息。此练习旨在阐释通用概念,并非穷尽做法。真实环境中,你往往需要扩展更多第三方方案或脚本,以纳入其他元数据,如目标模式元数据、安全标签、行级过滤信息与列映射等。
建表后,需要从 AdventureWorks 示例数据库中提取模式元数据。为此,我编写了一个简单脚本,从 AdventureWorks 的系统表读取所需元数据,并生成插入到元数据存储的 INSERT 语句。此处以 Address 表为例;在真实场景中,你应遍历数据库内所有所需表:
vbnet
SELECT
'AdventureWorks' as 'SchemaName',
TABLE_NAME as 'TableName',
COLUMN_NAME as 'ColumnName',
DATA_TYPE as 'DataType',
CHARACTER_MAXIMUM_LENGTH as 'CharacterMaximumLength',
NUMERIC_PRECISION as 'NumericPrecision',
NUMERIC_SCALE as 'NumericScale',
IS_NULLABLE as 'IsNullable',
DATETIME_PRECISION as 'DateTimePrecision',
COLUMNPROPERTY(OBJECT_ID(TABLE_NAME), COLUMN_NAME, 'IsIdentity')
as 'IsPrimaryKey'
FROM
INFORMATION_SCHEMA.COLUMNS
WHERE
TABLE_NAME = 'Address'收集到 AdventureWorks 的模式元数据后,回到元数据存储的 Azure SQL 数据库中执行插入。示例如下:
sql
INSERT INTO SchemaMetadata
(SchemaName, TableName, ColumnName, DataType, CharacterMaximumLength,
NumericPrecision, NumericScale, IsNullable, DateTimePrecision, IsPrimaryKey)
VALUES
('AdventureWorks', 'Address', 'AddressID', 'int',
NULL, 10, 0, 'NO', NULL, 1),
('AdventureWorks', 'Address', 'AddressLine1', 'nvarchar',
60, NULL, NULL, 'NO', NULL, 0),
('AdventureWorks', 'Address', 'AddressLine2', 'nvarchar',
60, NULL, NULL, 'YES', NULL, 0),
('AdventureWorks', 'Address', 'City', 'nvarchar',
30, NULL, NULL, 'NO', NULL, 0),
('AdventureWorks', 'Address', 'StateProvince', 'int',
NULL, 10, 0, 'NO', NULL, 0),
('AdventureWorks', 'Address', 'PostalCode', 'nvarchar',
15, NULL, NULL, 'NO', NULL, 0),
('AdventureWorks', 'Address', 'CountryRegion', 'geography',
NULL, NULL, NULL, 'YES', NULL, 0),
('AdventureWorks', 'Address', 'rowguid', 'uniqueidentifier',
NULL, NULL, NULL, 'NO', NULL, 0),
('AdventureWorks', 'Address', 'ModifiedDate', 'datetime',
NULL, NULL, NULL, 'NO', 3, 0);
GO图 6-2 展示了收集完成后的元数据结果。这个新建的元存储将用于在 Silver 层以自动化方式执行数据质量校验规则。
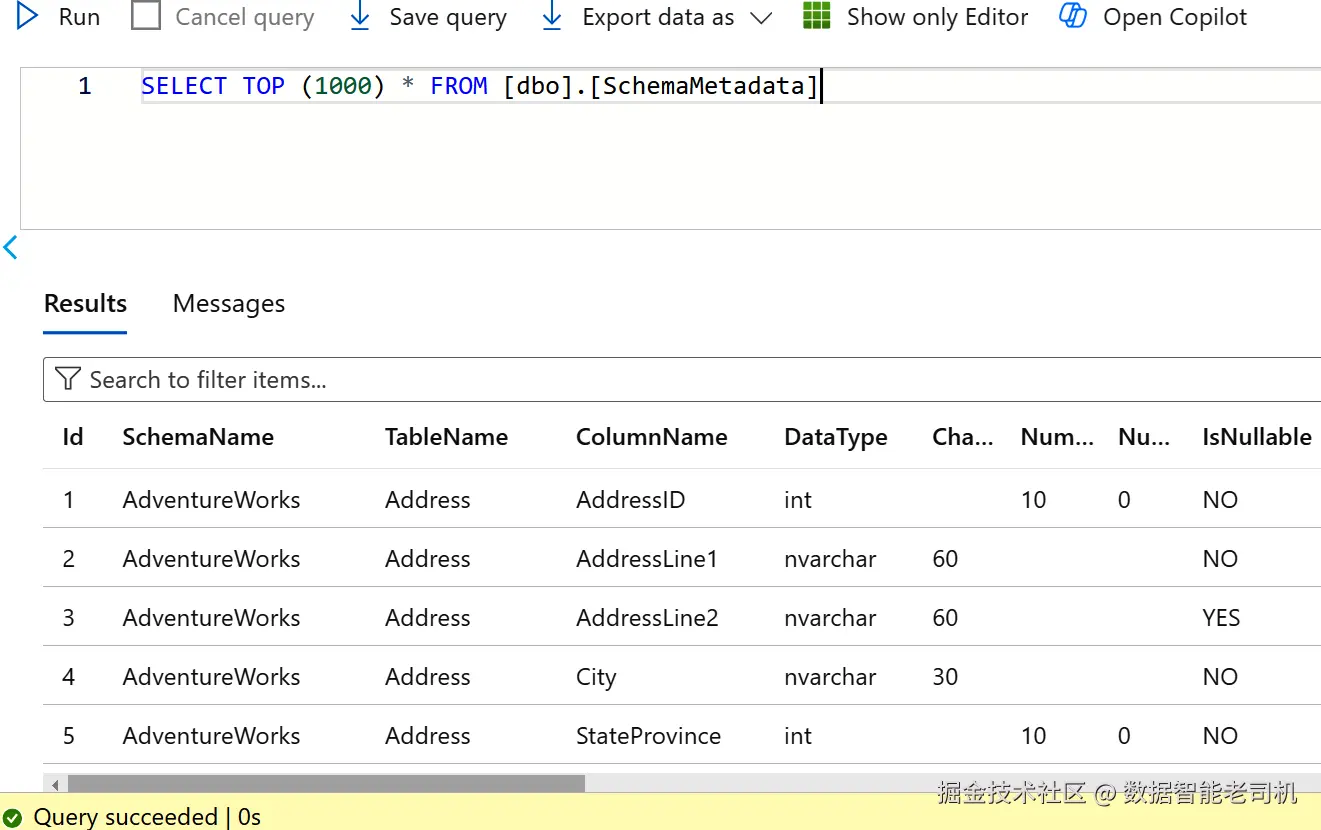
图 6-2.该元数据存储将用于驱动 Silver 层中的数据质量校验
目前收集到的元数据仍较基础,只包含一个数据库的模式信息:表名、列名、数据类型、是否可空、主键等,而且仅限 Address 一张表。
在后续推进中,考虑扩展为包含特定领域的信息、多个源的元数据,以及安全相关元数据(如敏感度标签或行级过滤)。你也可以加入更复杂处理逻辑所需的元数据,比如源到目标的列重命名、执行简单关联或并集、过滤无关数据等。为强化 CI/CD,你还可纳入与环境、部署、版本相关的元数据。最终,元数据框架扩展到何种程度取决于你的具体需求。
接下来,你将把该元存储整合进数据管道,采用元数据驱动的方法。需要完成几个步骤。参考图 6-3 可看到全部配置就绪后的样子。
准备好后,回到 Microsoft Fabric。进入 Settings ,将新的 Azure SQL 数据库注册为一个新的连接(Connection),其体验与配置 AdventureWorks 数据库时类似。随后进入数据管道,打开现有的 ForEach 活动;新增一个 Lookup 活动并拖入工作流,将其连接到负责创建 Delta 表的 notebook 步骤。选中该 Lookup 活动,在 Settings 中将 Connection 设为新的元数据存储。查询(Query)需要以表名作为输入进行调用,将 Query 字段更新为:
ini
@concat('SELECT * FROM [dbo].[SchemaMetadata]
WHERE SchemaName=''AdventureWorks''
AND TableName=''',item().table_name,'''')图 6-3 展示了该 Lookup 活动的配置细节。
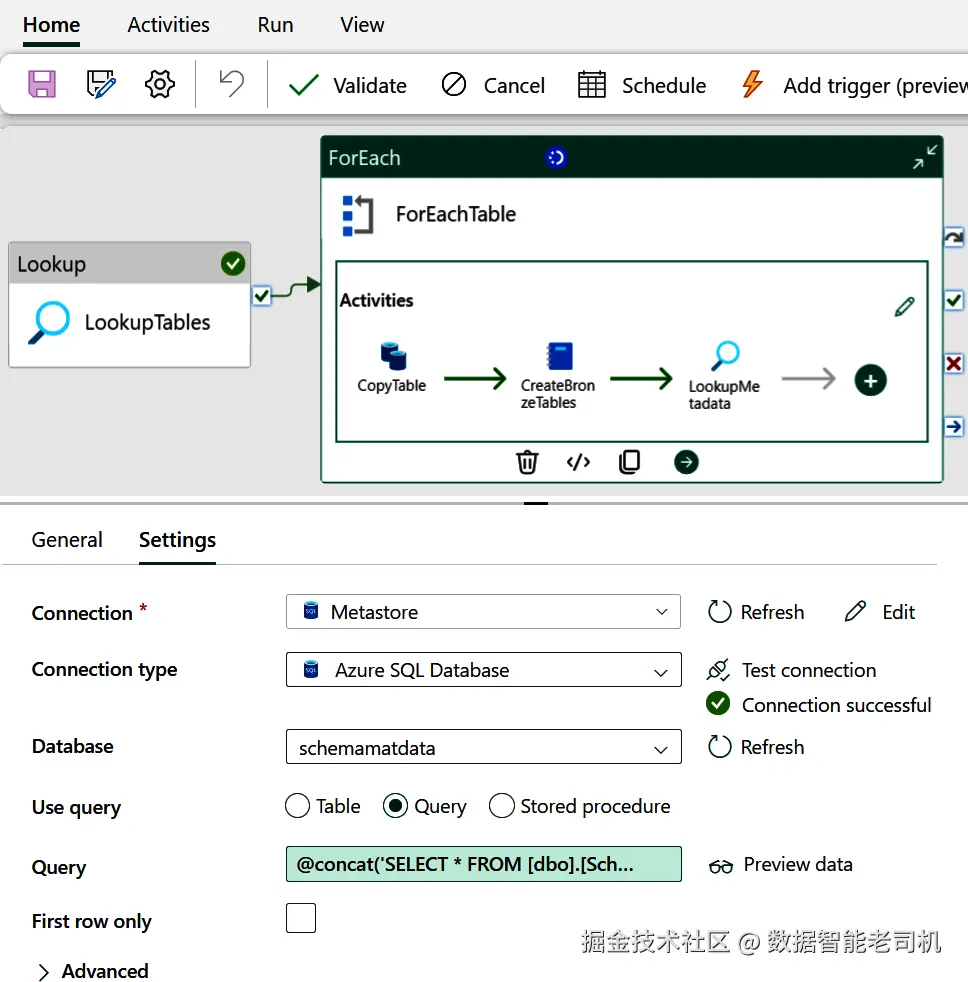
图 6-3.用于检索元数据的 Lookup 活动配置
在此设置中,仅传入了 AdventureWorks 的数据库名与动态的 tableName 参数。在更大型的设置中,你也许会加入更多参数,例如 Workspace 的配置参数、版本信息等。配置完成后请保存。小结一下:对 ForEach 中的每张表,Lookup 活动都会从元存储检索相应的元数据。
现在,进入下一步:调用技术性(数据质量)校验脚本。
实现动态数据校验
接下来的任务是为 ForEach 活动扩展额外步骤,以执行基于元数据驱动的技术校验。双击或打开 ForEach 活动以添加新活动。
TIP
元数据驱动的方法在数据处理管道中至关重要,它能确保数据的准确性、一致性与可靠性,并减少对特定厂商或技术的依赖,因而更具灵活性。
在为 ForEach 活动设计如何使用元数据时,你可以考虑两种思路:
- 严格模式:流水线运行必须依赖数据库中的元数据;如果没有元数据则拒绝运行。
- 弹性模式:即使没有元数据,流水线也允许继续运行。
在本示例中,我们假设元数据不一定总是可用 ,因此采用弹性模式。
为实现这一点,在 ForEach 活动中拖入一个 If Condition 活动。它会根据条件真假决定是否继续后续步骤。这里我们用对 LookupMetadata 活动输出的计数来判断:当返回记录数大于 0 时,说明存在可用的元数据。将 If Condition 的表达式配置为:
kotlin
@greater(activity('LookupMetadata').output.count, 0)配置好 If Condition 后,打开其 True 分支。在该分支下添加一个 Notebook 活动,用以基于 LookupMetadata 活动返回的元数据执行技术校验。
有关 If Condition 配置的更多细节,见图 6-4。
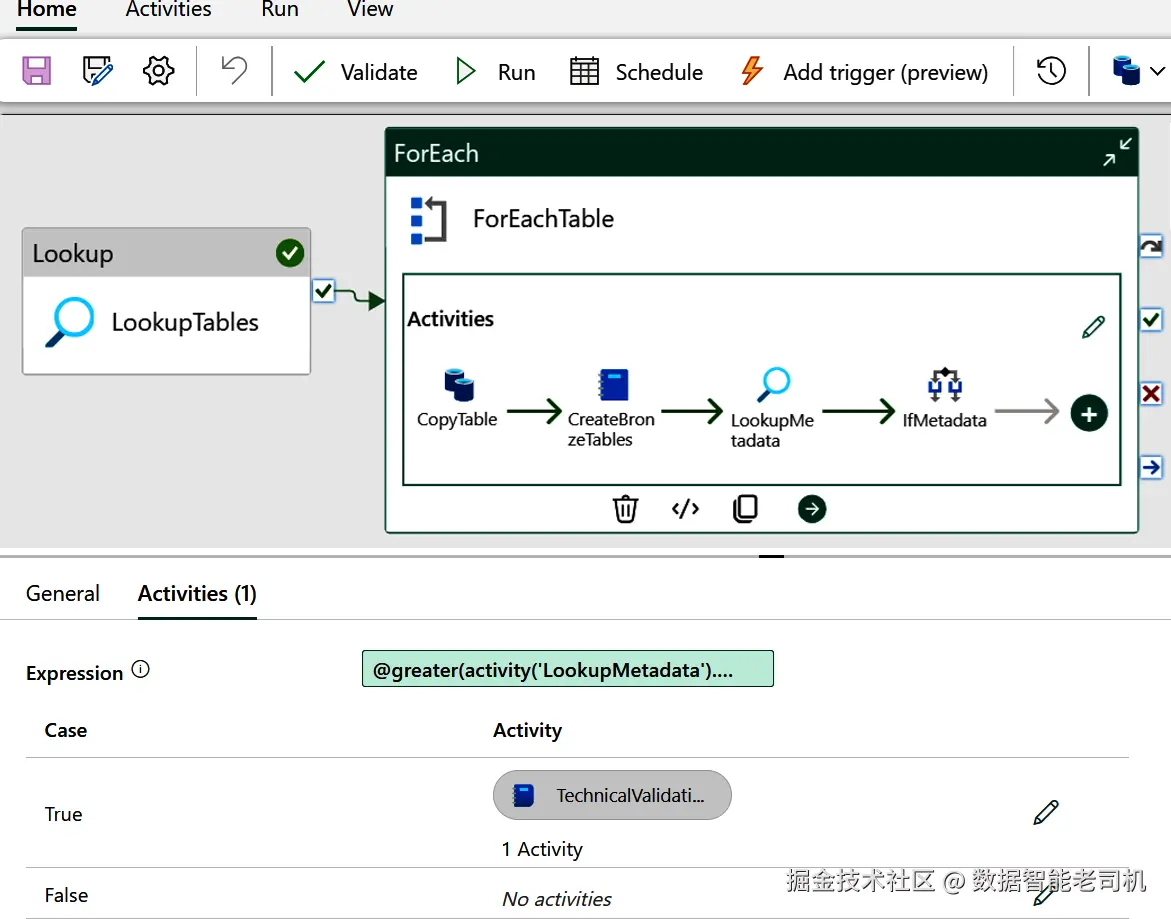
图 6-4.用于启动技术数据校验的 If Condition 配置细节
接着,进入新建 Notebook 活动的 Settings and parameters(设置与参数) 区域,新增三个参数:schemaName、tableName 与 metadata,并为它们赋值如下:
schemaName:adventureworkstableName:@item().table_namemetadata:@string(activity('LookupMetadata').output.value)
Notebook 活动配置详情见图 6-5。
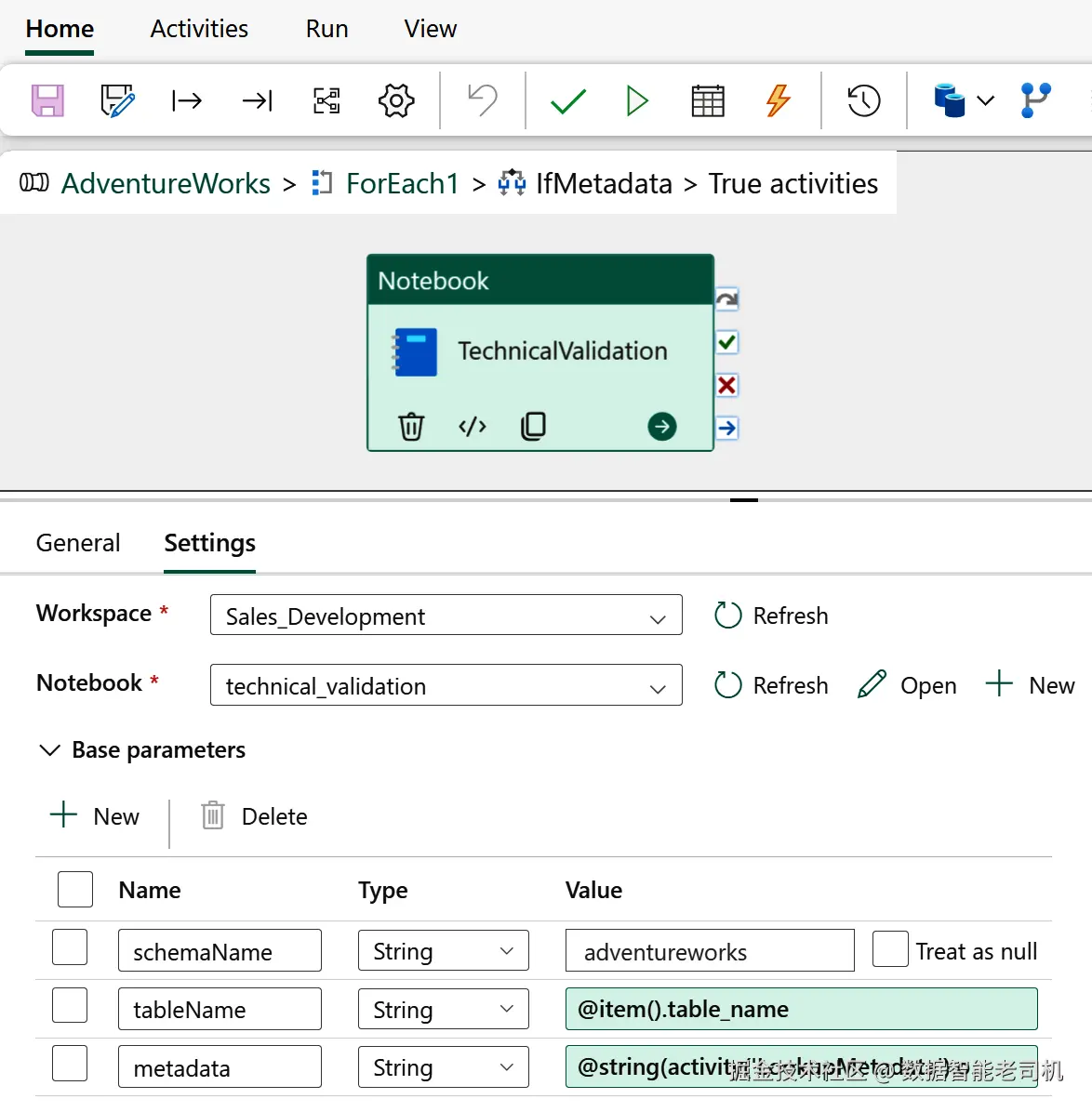
图 6-5.执行技术校验的 Notebook 活动配置细节
然后,回到 Workspace 环境并打开新建的 notebook。本 notebook 的目标是基于数据库中取回的元数据 来校验表模式 。技术校验脚本首先确认 metadata 参数是否存在与有效;随后将其以 JSON 格式加载,并遍历元数据动态构建校验规则 。若发现无效数据,立即中止执行。
在新建的 notebook 中,先粘贴以下代码(参数单元):
ini
# Infer base parameters from the pipeline context
schemaName = ""
tableName = ""
metadata = ""粘贴后,通过单元右上角的"三点"菜单启用 "Toggle parameter cell" (切换为参数单元)。再新增一个代码单元,并粘贴以下代码:
python
# Import the necessary libraries
import json
# Check if the metadata parameter is present
try:
json.loads(metadata)
except ValueError as e:
mssparkutils.notebook.exit("Metadata is not a valid JSON object.")
json_metadata = json.loads(metadata)
# Load data and convert DataFrame
df = spark.read.table(f'bronze.{schemaName}.{tableName}')
# Check if columns in metadata exist in the DataFrame
missing_columns = [item["ColumnName"] for item in json_metadata \
if item["ColumnName"] not in df.columns]
# If columns are missing, stop the process
if missing_columns:
mssparkutils.notebook.exit(f"Technical validations have failed: " \
+ join(missing_columns))完成上述步骤后,运行数据管道。若一切正常,ForEach 活动将遍历所有表,获取对应元数据,并利用 If Condition 判断是否存在元数据;若有,则触发 Notebook 活动执行技术校验。
目前这些校验较为基础------仅核对列名 。你可以轻松扩展该脚本以覆盖主键、可空性、唯一性、字段长度 等规则。一旦某张表不满足标准,流水线即会停止。这种做法为进入 Silver 层的数据设置了一个稳健的"闸门"。
你已完成本节的上手实践。下面我们对元数据驱动方法做一番反思,并讨论潜在的改进方向;之后将继续进行更多实操。
可改进之处
元数据驱动框架围绕一个朴素却强大的理念构建:用关于数据的元数据 来驱动校验、转换与装载流程。核心要素包括:
- 一个元数据仓库用于集中存储;
- 一个编排器读取元数据并动态生成作业、校验与转换(例如由流水线触发 notebook);
- 监控与跟踪能力以掌握各作业运行状态。
若要进一步扩展与规模化,建议考虑以下改进:
- 将元存储外部化并提供 API:实现元数据自助化管理。
- 扩展对多种技术文件格式的处理:利用 ForEach 条件驱动 Parquet→Delta、CSV→Delta 的转换,或解析复杂嵌套的 XML 结构。
- 丰富处理能力 :支持
append、merge、full overwrite等模式;引入复杂转换(如 SQL 模板或 UDF)。有的团队使用 JSON 描述全量转换步骤,有的采用 SQL 模板。 - 在 Silver 层实施模式预配置:呼应前文"Schema Management"的策略。
- 加强数据安全:通过策略驱动的方法创建安全视图(行/列级脱敏),并用 RBAC/ABAC 管理用户组。对敏感数据尤为重要。
- 启用 Notebook 之间的相互调用:用元数据动态管理任务与依赖,简化参数传递,并支持并发运行多个 Notebook。
- 加入审计与日志:精细监控摄取记录,快速定位问题,并收集合规与性能指标。
- 实现通知机制:将成功/失败等关键事件通过 Slack 或 Microsoft Teams 等工具即时告知运维团队。
- 建设运行时可观测性与报表:输出版失败原因、处理记录数、耗时、源端计数等关键信息与性能分析。
与传统"纯代码"管道相比,元数据驱动在管道管理上有明显优势:
- 通用与适配性更强 :能够覆盖多种源与目标、格式、模式与频率,并可灵活适配全量、增量、全量覆盖等多种摄取模式。
- 显著降低代码量与维护成本 :以通用管道替代大量定制 notebook,仅靠元数据驱动适配差异。
- 简化并标准化研发与上线流程:新增校验或修改规则时,无需改代码或重新部署,直接改元数据即可。
- 提升并行与吞吐:按设计可并行执行多个 Copy 或 Notebook 活动,提升性能与效率。
至此,我们已搭建好元数据驱动框架并完成技术性校验的落地。接下来可以动手开展数据清洗 ------这一步往往更不确定,也更需要定制化工作。完成清洗后,我们还会讨论如何借助元数据自动化这类流程。
数据清洗(Data Cleansing)
数据清洗(data cleansing / data cleaning)是识别并修正或移除数据中的错误、不一致和不准确之处的过程。由于人为失误、系统错误或录入差错等多种因素,数据常常包含问题。若不处理,这些问题会显著影响数据质量与准确性,进而导致错误的洞察、决策和业务结果。
数据清洗不同于数据完整性校验 :清洗强调检查并修正 数据集中存在的不准确或错误,以提升数据质量。通常需要先查询与剖析(profile)数据,了解各表中包含什么数据;在此过程中你可能发现错误、异常与不一致。随后再纠正 数据,例如统一格式(如日期格式统一),或为数据补充缺失信息(如客户地理位置)。除了修正异常外,清洗还包括一个关键步骤:整改(remediation) ------在源系统中修复根因,防止问题反复出现。
要做好数据清洗,既要深入理解业务语境与生成数据的流程,也要明白这些数据在流程中的重要性。比如在销售数据集中,若交易日期被错误记录,可通过与发运日期或付款记录等交叉比对识别异常条目并修正日期。
警告
缺乏相关业务知识时,很难判断什么是"正确的数据",从而引入更多错误与不准确。沟通在此过程至关重要!
下文将展示在 Spark 中执行数据清洗的过程,讨论各方法的优劣,并基于发现给出结论。
数据清洗任务的实现
让我们体验清洗的复杂度。回到 Workspace,新建一个 notebook,用于 AdventureWorks 示例库的数据清洗。把该 notebook 集成到数据管道中,位置在 ForEach 活动之后。
将 notebook 命名为 clean_data 。从左侧菜单选择 Silver Lakehouse ,确认环境正确。本演示将从 Bronze 层的 AdventureWorks 数据库加载数据。在 notebook 中先读取 Bronze 层的 customer 表:
ini
customers = spark.read.table("bronze.adventureworks.customer")
display(customers)运行后你会发现数据并不干净(见图 6-6)。
例如:Title 列包含 Mr.、Ms.、Mrs.、Dr. 等称谓;与其依赖称谓,不如推断性别 。SalesPerson 列应去掉 adventure-works 前缀;ModifiedDate 需统一为一致的日期格式;应移除 PasswordHash 列;电话号码也要统一格式,因为部分以 1 (XX) 前缀开头。
这些改进体现了针对 customer 表的基础清洗活动 。请理解:清洗因表而异、常很复杂,并要求对数据和其背后的业务流程有充分认识。
下面的 PySpark 脚本演示如何完成上述清洗:regexp_replace 去除 SalesPerson 前缀,date_format 统一日期格式,udf 用于根据 Title 推断性别:
ini
# Import necessary libraries
from pyspark.sql.functions import *
from pyspark.sql.types import StringType
# Load data
customers = spark.read.table("bronze.adventureworks.customer")
# Drop columns that are not needed
customers = customers.drop("PasswordHash", "PasswordSalt", "rowguid")
# Function to determine gender
def determine_gender(title):
if title == 'Mr.':
return 'Male'
elif title in ('Ms.', 'Mrs.', 'Miss'):
return 'Female'
else:
return 'Unknown' # Add a default value for other cases
determine_gender_udf = udf(determine_gender, StringType())
# Adding gender to each dictionary in the list
customers = customers.withColumn("Gender", \
determine_gender_udf(trim(customers["Title"])))
# Define the strip_prefix function
def strip_prefix(value):
return value.strip("adventure-works\")
# Define the strip_prefix_udf function
strip_prefix_udf = udf(strip_prefix, StringType())
# Updating SalesPerson in each dictionary in the list
customers = customers.withColumn("SalesPerson", \
strip_prefix_udf(customers["SalesPerson"]))
# Changing ModifiedDate type to YYYY-MM-DD
customers = customers.withColumn("ModifiedDate", \
date_format(customers["ModifiedDate"], "yyyy-MM-dd"))
# Making all telephone numbers consistent
customers = customers.withColumn("Phone", \
regexp_replace(customers["Phone"], r"1 (\d{2}) ", ""))
# Write customers data to clean_ table
customers.write.mode("Overwrite") \
.saveAsTable("adventureworks.clean_customer")运行并检查新建的 clean_customer 表(见图 6-7),你会看到数据已更为干净一致,且可查看一些统计信息以进一步理解与排查潜在问题。
使用 PySpark 清洗有时代码较多。另一种做法是使用 pandas 这类库。它在特征工程、预处理、清洗与转换方面很常用。下例用 pandas 完成同样的清洗:
less
# Same code as above but using pandas
import pandas as pd
customers = spark.read.table("bronze.adventureworks.customer")
customers = customers.toPandas().drop(columns=["PasswordHash", \
"PasswordSalt", "rowguid"])
customers['ModifiedDate'] = pd. \
to_datetime(customers['ModifiedDate']).dt.strftime('%Y-%m-%d')
customers['Gender'] = customers['Title'].apply \
(lambda x: "Male" if x == "Mr." else "Female" \
if x in ('Ms.', 'Mrs.', 'Miss') else "Unknown")
customers['SalesPerson'] = customers['SalesPerson']. \
str.replace('adventure-works\', '', regex=False)
customers['Phone'] = customers['Phone']. \
str.replace(r'.*?(\d{3} \d{3}-\d{4})', r'\1', regex=True)
# Check for shared phone numbers
customers['SharedPhone'] = customers.duplicated(subset=['Phone'])
# Show results
display(customers)可以看到,pandas 代码更为简洁易读。但当数据量很大时,pandas 的操作通常在 driver 上执行,不利用 Spark 的分布式能力,可能导致效率低下。为此,Spark 提供了 pandas API on Spark,在保留 pandas 易用性的同时获得分布式伸缩性。
注
Silver 层通常也是执行命名规范与重格式化 以符合领域或组织标准的地方。例如把 cust_id 重命名为 customer_id 等。
掌握了对 customer 表的清洗后,建议继续清洗 AdventureWorks 的其余表。可复用同一 notebook,为每张表新增代码块,并用 _clean 前缀存储清洗结果以便识别。完成后,将该 notebook 集成到数据管道中,放在 ForEach(技术校验)之后,实现清洗自动化。
至于是否持久化中间清洗结果 ,取决于组织需求。有的组织为审计与调试保留清洗中间表(如本例的 _clean 前缀,或使用单独的 schema / Lakehouse);也有的选择不落地中间结果,直接在同一批次里把所有 DataFrame 处理完。按需选择即可。
接下来短暂停下实操,转向数据质量的理论层面 :标准化、富化与 MDM。动手部分将在讨论历史化时恢复。
数据清洗的注意事项
当用脚本构建数据质量与清洗活动时,建议将所有质量检查/更新 进行标记、记录并写入独立表,便于数据工程团队排查并在源系统中修复。例如将"超过 150 岁的客户"写入隔离表(quarantine):
lua
customers.filter(age > 150).write.format("delta") \
.mode("append").saveAsTable("adventureworks.customer_quarantine")你应决定是否需要中断处理 。第 3 章讨论过侵入式数据质量处理 :若预期下游会失败或消费者无法容忍问题,则应停止 管道。可通过统计错误 并在 Fabric Spark 中使用 mssparkutils.notebook.exit 来实现,例如:
ini
customers = spark.read.table("adventureworks.customer")
duplicateIds = customers.toPandas().duplicated(subset=['CustomerID'])
title_not_null = customers.toPandas()['Title'].isnull()
if duplicateIds > 0 or title_not_null > 0:
mssparkutils.notebook.exit(f"DQ duplicateIds error: \
{duplicateIds}, DQ title_not_null error: {title_not_null}")上述清洗示例以批处理 展示,但稍作调整也可用于实时处理。例如结合 Azure Event Hubs 与 Spark Structured Streaming:
makefile
# Streaming data from Azure Event Hubs
df = spark \
.readStream \
.format("eventhubs") \
.options(**ehConf) \
.load()
# Drop rows containing any null or NaN values
output = df.na.drop()
# Write the cleaned data to a Delta table
output.writeStream \
.format("delta") \
.outputMode("append") \
.toTable("adventureworks.events")该脚本从 Event Hubs 拉取数据,删除包含 null/NaN 的行,并即时写入 Delta 表(可位于 Silver 层),实现数据到达即清洗。
关于如何组织清洗活动,你有多种选择:
- 有的工程师按数据源一个 notebook,便于集中查看与追踪变化;
- 也有人按活动类型拆分多个 notebook,便于在复杂数据集/多阶段清洗场景下保持整洁,并让不同成员各司其职、互不干扰。
由于数据千差万别,要把清洗完全标准化 很难。能否用元数据驱动 来简化?既可以,也不总是行 。若清洗主要是通用质量规则 (如对照中心参照数据进行校验),可使用元数据驱动的通用 notebook 并通过参数化传入;但从整体上看,每个数据集通常仍需要量身定制的处理逻辑。
因此,开发者常将数据质量规则保存在单独的 notebook/脚本 中,或以元数据(如 Delta 表)形式存储,从而实现更个性化和有效的清洗策略。同时,务必给工程团队提供明确规范 :代码风格、注释、缩进与模块化等最佳实践;并约定优先使用的框架/工具。
下一节我们将继续探讨如何选择合适的工具与框架。
数据转换框架与数据质量工具
在开发与维护数据转换(同时涵盖数据质量与数据清洗目标)时,可选的框架与工具很多,各有功能、优劣与适用场景。应根据组织的具体需求做选择。下面是数据转换、数据质量与数据清洗领域常见的工具与框架:
dbt(data build tool)
dbt 是最流行的 ETL 工具之一,允许数据分析师与数据工程师用 SQL 模板 为多种平台编写转换。通过以通用方式编写模板,dbt 能对数据转换进行测试,确保其按预期运行。
一大优势在于:dbt 对你把数据转换到数据仓库或湖仓持平台无关 态度。它会将你的 SQL 代码转译 为目标引擎的 SQL 方言。也就是说,你可以用一种 SQL 方言写转换,并在任意 SQL 数据库上运行,例如 Fabric Spark、Fabric Warehouse 或 Databricks Spark。相对地,随着对 dbt 使用更深入,可能会发现简单的 SQL 配置不再够用;这时 Jinja 模板 与 Python models 可以帮助你动态定制并控制 SQL 的生成。尽管强大,但也引入了学习曲线,且可能偏离 dbt 的"数据库无关"理想。
此外,dbt 提供内置的血缘 与文档 能力,以及测试框架来确保转换正确。它既有开源版本,也有按用户付费的 SaaS 托管版。
Delta Live Tables(DLT)
DLT 是 Databricks 数据智能平台上的声明式 ETL 框架 ,简化流式与批式 ETL,能与 MLflow、Unity Catalog 集成以增强血缘。DLT 还提供定义与评估数据质量标准的方法,帮助构建数据处理流水线。对于 CDC,DLT 尤其适合,因为它能正确处理乱序事件等手工实现较难的问题。
DLT 没有免费层,且会加深对 Databricks 的依赖。它要求采用 Databricks 特有的编码实践,可能限制你在供应商之间的切换或与其他平台的集成灵活性。
Great Expectations
Great Expectations 是专注数据质量 的开源 Python 库,用于测试、文档化与画像数据。你可以定义数据质量期望(expectations) ,并将数据与这些期望进行验证;该工具会生成报告,帮助判断数据是否准确可靠。
与 dbt、DLT 的一个关键差异是:Great Expectations 主要聚焦于质量验证与文档化,而非数据转换。这意味着将其嵌入现有数据管道可能需要更多前期配置。相比之下,dbt 与 DLT 旨在与更广泛的数据生态工具无缝融合,因此在这些场景下可能更易上手。
此外,诸如 Ataccama 、Monte Carlo 等第三方数据质量与可观测性工具还提供基于 AI 的智能画像、整改与跟进管理服务,以及用于数据质量深度洞察的报告生成功能。
与"原生"PySpark/库的对比
在选择数据转换、质量与清洗工具时,也应权衡直接使用原生 PySpark (以及 pandas、Polars 等库)。原生 PySpark 的优势是灵活性最大 、避免厂商锁定 。但若你需要血缘跟踪、自动化测试、依赖管理与流处理等特性,则往往需要自行开发自定义库来补齐,这会增加前期工作量。
仅用 SQL 的方式
有些开发者偏好使用纯 SQL 完成转换,因其简单且跨多种数据库具备可移植性。可将 SQL 存放在 notebook 中或做成数据库视图,便于访问与管理。这种方法利用了通用语言,避免专用工具的复杂性,并能直接与数据库交互以精细控制数据操作。不过,SQL 灵活性不及 Python,在某些复杂转换上会受限。
选择合适的数据转换、质量与清洗框架/工具取决于你的具体需求 。务必评估多种选项以找到最佳匹配,从而确保数据的准确性与可靠性 ,为科学决策提供基础。一旦确定了理想的方法与工具集,应在组织范围内统一标准,保证各数据工程团队之间的一致性与效率。
接下来转向另一个关键概念:数据反规范化。清洗提升了数据质量,而反规范化则在复杂结构中优化数据的访问与查询。
通过反规范化优化查询性能
第 3 章已经强调了稳健查询性能 的重要性。提升查询性能的一种策略是反规范化(denormalization) :通过减少代价高昂的表连接来加快取数。为何在 Silver 层考虑采用它?
当原始数据非常复杂(例如包含上百张小系统表 ,导致访问低效)时,推荐采用反规范化。只要分区合理、避免数据倾斜 ,这种格式对 Parquet 等列式文件 尤其友好。当数据科学家与分析师需要对 Silver 数据进行快速访问(用于机器学习与运营报表)时,反规范化也很有价值。更多内容可回看"反规范化(Denormalization)"与"一张大表(OBT)设计"。
注意
Apache Spark 2.3 及更高版本支持实时联接两张流式 DataFrame 。这有助于将多路流数据合并,并可用于实时反规范化。详见 Spark 文档中的 join 操作。
在开始反规范化之前,务必完成校验与清洗 ,以免出现重复或缺失等问题。进行表连接时,使用子查询与过滤 提升效率,明确连接条件,并指明 INNER 或 LEFT 等连接类型,确保组合数据的正确性与可用性。
总之,在 Silver 层实施反规范化需要慎重权衡 。以 AdventureWorks 为例,Silver 中现有结构已可用,建议保持不变。下面转向如何通过**数据增强(enrichment)**进一步提升数据价值。
轻量级增强(Lightweight Enrichments)
数据增强 即在现有数据上添加额外信息,使其更有用、语义更充分。在 Silver 层,这通常是简单增强 ,无需复杂流程即可提升价值。常见示例包括:追加新属性、地理编码、补时间戳、英制与公制单位转换、聚合、引入参考数据 等。这些增强让数据不仅干净 ,还在可用性上更进一步,便于深入分析。
根据场景不同,增强也可更"高级"。例如,大语言模型(LLM)可为数据注入上下文洞见或生成合成特征 。在特征工程 中,增强被设计为将原始数据转化为对模型更有效的输入。对于 MDM(主数据管理) ,增强在保证数据一致性、准确性与可靠性方面也至关重要。
注意
在 Medallion 架构中,复杂业务规则 通常属于 Gold 层 。Gold 层负责复杂逻辑与高级计算------把"干净的数据"转化为面向具体业务需求的洞察。
当然,增强有时也会很复杂,可能需要高级处理逻辑与 LLM 的参与。例如结合 Azure OpenAI、Fabric AI Services、Databricks AI functions 等 AI 服务实现更"聪明"的增强。此类增强通常需要更复杂的处理技术。
下面这段学习用 代码(被动示例)展示了利用 Azure OpenAI 做一次分类增强 :根据客户表中的 CompanyName 让模型返回 NAICS 分类,并逐条打印结果:
ini
# 配置 Azure OpenAI
AZURE_OPENAI_API_KEY="<your API Key>"
AZURE_OPENAI_ENDPOINT="<your_OpenAI_Endpoint>"
from openai import AzureOpenAI
client = AzureOpenAI(
api_key = AZURE_OPENAI_API_KEY,
api_version = "2024-10-01",
azure_endpoint = AZURE_OPENAI_ENDPOINT
)
# 载入数据
df = spark.read.table("adventureworks.customer")
# 抽取公司名作为提示词
prompts = df.select('CompanyName').map(f=>f.getString(0)) \
.collect.toList.distinct
# 逐条调用
for prompt in prompts:
response = client.chat.completions.create(
model="<your_model_name>",
messages=[
{"role": "user", "content":
"Classify this company by returning the NAICS: " + prompt}
],
max_tokens=100
)
print(f"Prompt: {prompt}")
print("Response:", response.choices[0].message.content)
print()AI 正在深刻简化与自动化数据工程 :自动产码、减少体力活,并通过生成合成数据、画像、清洗与增强 提升数据质量。到 2025 年,AI 在技术数据与语义数据(如数据目录信息)融合上将更显关键,带来更准确、鲁棒的数据增强。
注意
LLM 非确定性 :即便提示精心设计,回答也可能略有差异。比如用 LLM 回取 NAICS 代码,务必做一致性检查 (格式、有效性)。为维持数据完整性与一致性,每次 AI 增强后都执行清洗校验。第 13 章将再谈此题。
数据增强与数据科学中的特征工程 紧密相连:从原始数据生成/选择有助模型表现的变量;增强也帮助校验或细化 这些特征。比如在包含出生日期与性别的客户数据中,可计算并追加 年龄,再用于流失预测(例如分箱 u35 / o35)。
MDM 是另一条增强主线:它把增强原则更进一步,为关键业务数据构建统一真相源 。在 Silver 层整合 MDM 能显著提升一致性、准确性与价值。还是以 AdventureWorks 为例:MDM 可将 CountryRegion、StateProvince 标准化 ,为 CurrencyCode 设定默认参考值 ,并整合多源客户数据、引入 MasterCustomer 标识,形成全组织统一的客户画像。
注意
MDM 往往很复杂,要在多系统间管理海量数据。像 Profisee、CluedIn 这类方案可显著简化流程。
在 Silver 层中,常见会按关注点拆出子层 :如清洗层、稳定的机器学习特征层 、实验性 ML 层、MDM 层等。存在多子层时,团队需理解它们之间的依赖关系 ;此处元数据与血缘对洞察层间数据流至关重要。
接下来离开理论,动手实践数据历史化(Historization) :我们将把新 Notebook 接入管道,以上一步清洗后的数据为输入,为表添加时间维度以跟踪与呈现随时间发生的变更。
数据历史化(Data Historization)
对数据进行历史化是指随时间跟踪变更。这对记录数据如何被修改、监控其全生命周期并支持分析至关重要。历史化有助于识别趋势、模式与异常,从而支持更明智的决策、预测与构建预测模型。历史化可在不同方法与不同分层中实现,各有优劣。常见方式如下:
Bronze 层分区
在 Bronze 层通过数据分区来组织与存放历史数据,需用时即可访问。这种方式在交付入口就对历史进行结构化,便于取用,但可能形成彼此孤立的数据集,后续整合较难。
Delta 时光回溯(time travel)
Delta Lake 能在不同时间点捕获数据快照,允许还原并查询历史版本。用户可基于保存各版本的元数据按时间点读取表。默认保留期为 7 天,可延长至无限期。不过,time travel 不会自动列出差异,对比两个版本的变化需要额外人工步骤。
缓慢变化维(SCD2)
不同于数据集层面的"各自为政"历史化以及 Delta time travel 的手动比对,SCD2 通过在维表中自动记录属性随时间的变化,使得变更追踪与检索更加直接。
每种方法都有其适用性。根据项目需求,组合使用这些技术,常能在历史数据管理上取得更全面的效果。
在迁移到 Silver 层 时,通常将 SCD2 视为最佳实践:它把所有历史记录集中于一张表 ,从而简化访问与分析。做法上会为表追加记录数据加载时间的列,便于按指定日期过滤与取回历史数据,简化历史记录的管理。图 6-8 展示了在 Spark 中处理 SCD2 后的外观。
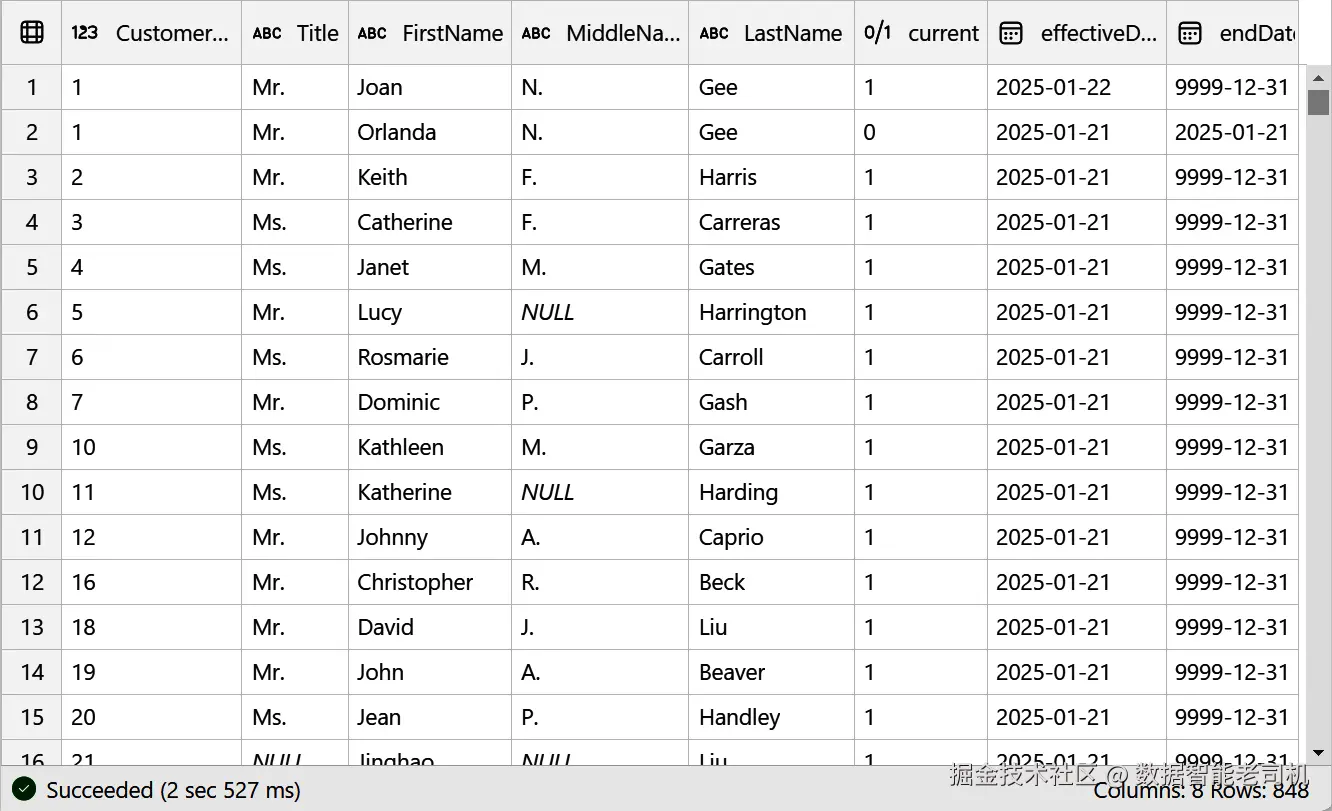
请注意,在图 6-8 中,第一列的 CustomerID=1 在 2025-01-22 被更新,而上一条记录的结束日期是 2025-01-21;同时上一条记录的 current 字段被更新为 false。约定:1 表示当前有效记录 ,0 表示历史记录。
在数据工程社区,关于 SCD 应该落在 Silver 还是 Gold 层始终存在争论,这取决于组织的具体需求。
- 如果需要在原始上下文 中用于分析与报表的历史数据,将 SCD 放在 Silver 层 更合适。这样 Bronze 专注摄取,Gold 专注高性能查询,无需再承受繁重转换逻辑。
- 若组织需要将历史数据整合为统一视图 并频繁在报表中访问,把 SCD 放到 Gold 层更契合性能优化。
因此,无论选择在 Silver、Gold,或两层同时实施 SCD,都应在收益与实施/维护复杂度之间仔细权衡。
用 Delta Lake 删除向量增强 SCD
Delta Lake 的**删除向量(deletion vectors)**能高效管理与跟踪删除,尤其适用于删除频繁的场景(如 SCD 处理)。开启方式:
sqlALTER TABLE tblName SET TBLPROPERTIES ('delta.enableDeletionVectors' = true);启用后,Delta 会将被删行的位置与数据文件分离标记(软删除),读取时再合并(merge-on-read),在不改动原数据文件的前提下提升删除相关操作的性能与完整性。
实战:用脚本实现 SCD2
思路:从 Silver 层取一张已清洗 的表,比较新旧数据识别变化;在 Silver 层建立一张历史表集中跟踪变化,得到完整的演进视图。
操作:在开发 Workspace 新建笔记本,命名为 historize_data_scd2,并将其接到数据质量步骤之后 。左侧选择 Silver Lakehouse,确保环境无误。
注意
SCD 的时间线可多样化:若源系统自带业务时间线 (如生效/有效期),即可按业务时间判断变化,与到达顺序无关;若没有,只能依赖技术时间线(加载时间戳,通常由 Bronze 提供)。
脚本结构(高层概览)
- 引入所需函数。
- 主函数读取
clean_前缀表,设定时间戳,检查主键;若无主键,则生成哈希键 充当业务键。随后比较新旧数据:依据业务键判断新增/修改/删除/无动作,构造目标选择并输出统一结果。 - 对多张表循环调用主函数,传入 schema、表名与(可选)主键。
将以下代码粘贴到首个代码单元------导入依赖:
python
# Import functions
from pyspark import *
from pyspark.sql import functions as F
from pyspark.sql.functions import *新增代码单元,粘贴主函数(略去注释,保持与教程一致):
scss
# SCD2 function
def fn_SCD2(schemaName, tableName, primaryKey):
# Fetch data from Bronze or intermediate Silver layer
dataChanged = spark.read.table(f"{schemaName}.clean_{tableName}")
# Remove loading_date column from dataset
dataChanged = dataChanged.drop('loading_date')
# Generate a hash key if the primary key is missing
if not primaryKey or primaryKey == "":
dataChanged = dataChanged.withColumn("hash",
sha2(concat_ws("||", *dataChanged.columns), 256))
primaryKey = 'hash'
# Create list with all columns
columnNames = dataChanged.schema.names
# Set date
current_date = datetime.date.today()
# Try and read existing dataset
try:
dataOriginal = spark.read.table(f"{schemaName}.hist_{tableName}")
except:
newOriginalData = dataChanged.withColumn('current', lit(True)) \
.withColumn('effectiveDate', lit(current_date)) \
.withColumn('endDate', lit(datetime.date(9999, 12, 31)))
newOriginalData.write.format("delta").mode("overwrite") \
.saveAsTable(f"{schemaName}.hist_{tableName}")
dataOriginal = spark.read.table(f"{schemaName}.hist_{tableName}")
# Rename columns with src_ prefix
df_new = dataChanged.select([F.col(c).alias("src_"+c) for c in dataChanged.columns])
src_columnNames = df_new.schema.names
df_new2 = df_new.withColumn('src_current', lit(True)) \
.withColumn('src_effectiveDate', lit(current_date)) \
.withColumn('src_endDate', lit(datetime.date(9999, 12, 31)))
src_primaryKey = 'src_' + primaryKey
# Full merge on key (latest records)
df_merge = dataOriginal.join(df_new2, (df_new2[src_primaryKey] == dataOriginal[primaryKey]),
how='fullouter')
# Derive action
df_merge = df_merge.withColumn('action',
when(concat_ws('+', *columnNames) == concat_ws('+', *src_columnNames), 'NOACTION')
.when(df_merge.current == False, 'NOACTION')
.when(df_merge[src_primaryKey].isNull() & df_merge.current, 'DELETE')
.when(df_merge[src_primaryKey].isNull(), 'INSERT')
.otherwise('UPDATE')
)
# Target selections
column_names = columnNames + ['current', 'effectiveDate', 'endDate']
src_column_names = src_columnNames + ['src_current', 'src_effectiveDate', 'src_endDate']
df_merge_p1 = df_merge.filter(df_merge.action == 'NOACTION').select(column_names)
df_merge_p2 = df_merge.filter(df_merge.action == 'INSERT').select(src_column_names)
df_merge_p2_1 = df_merge_p2.select([F.col(c).alias(c.replace(c[0:4], "")) for c in df_merge_p2.columns])
df_merge_p3 = df_merge.filter(df_merge.action == 'DELETE').select(column_names) \
.withColumn('current', lit(False)).withColumn('endDate', lit(current_date))
df_merge_p4_1 = df_merge.filter(df_merge.action == 'UPDATE').select(src_column_names)
df_merge_p4_2 = df_merge_p4_1.select([F.col(c).alias(c.replace(c[0:4], "")) for c in df_merge_p2.columns])
df_merge_p4_3 = df_merge.filter(df_merge.action == 'UPDATE') \
.withColumn('endDate', date_sub(df_merge.src_effectiveDate, 1)) \
.withColumn('current', lit(False)).select(column_names)
df_merge_final = df_merge_p1.unionAll(df_merge_p2) \
.unionAll(df_merge_p3).unionAll(df_merge_p4_2).unionAll(df_merge_p4_3)
df_merge_final.write.format("delta").mode("overwrite") \
.saveAsTable(schemaName + ".hist_" + tableName)再建一个代码单元,逐表调用:
erlang
fn_SCD2("adventureworks","address","AddressID")
fn_SCD2("adventureworks","customer","CustomerID")
fn_SCD2("adventureworks","customeraddress","")
fn_SCD2("adventureworks","product","ProductID")
fn_SCD2("adventureworks","productcategory","ProductCategoryID")
fn_SCD2("adventureworks","productdescription","ProductDescriptionID")
fn_SCD2("adventureworks","productmodel","ProductModelID")
fn_SCD2("adventureworks","productmodelproductdescription","")
fn_SCD2("adventureworks","salesorderdetail","")
fn_SCD2("adventureworks","salesorderheader","SalesOrderID")运行后,Silver 层应出现 hist_ 前缀的历史表,完成历史化,使你能够随时间跟踪变化并获得更深入洞察。
TIP
在本章的元数据驱动方法中,可通过在元数据中给字段标记 IsPrimaryKey 来自动化历史化流程。
上述 PySpark 实现详细呈现了比较与筛选 :识别"无动作""插入""删除""过期-再插入"等场景。PySpark 的通用性强,便于在 Parquet、Delta、Iceberg 间切换(例如只需把 write.format("delta") 改为 "iceberg")。但同时也需要较多代码。
另一种做法是使用 SQL 或 Delta Lake 的原生 MERGE ,只针对 Delta 表即可在一次操作中完成 upsert(插入新记录、更新已有记录、删除过期记录),从而管理历史并确保一致性。第 7 章会给出使用 MERGE 的实操示例。
回顾
Silver 层的数据管道通常是顺序 的:先做技术校验 ,再做清洗 ,然后(可选)联接与增强 ,最后进行历史化 ------这标志着管道的收尾。某些情况下可将管道拆分为多个段(如清洗与增强分离),以增强可维护性并允许并行处理,但必须协调顺序,确保数据按正确流程推进。
接下来我们将讨论优化与编排 。这些内容为理论学习,不包含在 Oceanic Airlines 的动手教程中。
翻译:优化作业(Optimization Jobs)
随着数据版图扩张,对湖仓中 Delta Lake 表进行有效的表维护 变得至关重要;其中,OPTIMIZE 命令是核心。
OPTIMIZE 用于将小文件压缩为大文件 并整理数据布局 以加速查询。定期运行不仅能提速,还能提升成本效率 。最佳实践是根据处理需求每天或每周 调度执行;也可以把它自动化 进数据管道末尾:例如在管道最后附加一个 Notebook 来执行 OPTIMIZE,持续维护与优化 Delta 表。
接下来看看如何用 Apache Airflow 把整条数据管线的任务编排起来。
使用 Apache Airflow 进行编排
在本练习中,你已经体验到诸多数据处理步骤,以及执行先后顺序 的重要性。(Azure) Data Factory 的可视化编排虽强大,但"方框+连线"的界面在复杂场景下容易视觉过载 ,这时往往需要更精简的工作流管理方式。
Apache Airflow 是开源的工作流编排工具,因其通用性 和与多种引擎(如 Microsoft Fabric、Azure Databricks、Synapse Analytics 等)的兼容而被广泛采用。
Airflow 以 DAG(有向无环图) 的形式定义工作流:任务集合以及任务之间的依赖关系,清晰表达执行顺序与条件。创建 DAG 的方式是编写 Python 脚本 (即工作流配置),其中定义任务与依赖。优势在于可将 DAG 提交到 Git 等版本库;同时 Python 让你能在工作流中融入复杂逻辑与控制结构。
本节给出 Airflow 的实践演示。你有两条部署路径可选:
1) 本地手动安装并与 Spark 环境集成
完全可控且不依赖其他托管服务。安装指南见 "Installation of Airflow"。如需连接 Microsoft Fabric,请在 Airflow 环境中加入 apache-airflow-microsoft-fabric-plugin 包。
2) 托管版 Airflow 服务
例如通过 Data Factory 的 Data Workflows 。维护成本更低,并与 Azure 生态自动集成。参考 "Tutorial: Run a Microsoft Fabric Item Job in Apache Airflow DAGs"。
选定自建或托管后,登录 Airflow Web UI 便可创建 DAG。针对 Microsoft Fabric,推荐使用托管服务 ,更简单、无额外步骤。务必先在 Fabric 设置中开启"Users can create and use Apache Airflow jobs "。随后在 Workspace 中新建实体选择 Apache Airflow job,命名、创建后会自动跳转到 Airflow UI。
在 Airflow 中点选 "New DAG file" ,为文件命名(如 Adventureworks ),点击 Create。示例 DAG 如下:
ini
from airflow import DAG
from apache_airflow_microsoft_fabric_plugin.operators.fabric import FabricRunItemOperator
from airflow.utils.dates import days_ago
from airflow.operators.python import PythonOperator
# 默认参数
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'email_on_failure': False
}
def my_python_callable():
pass
with DAG(
'fabric_dag',
description="An ELT workflow with medallion architecture",
start_date=days_ago(2),
schedule_interval=None,
default_args=default_args
) as dag:
clean_data = FabricRunItemOperator(
task_id="clean_data",
workspace_id="92187CE0-B7EB-4FDF-80CE-EFF76639EED8",
item_id="27DE4FE9-666D-40BB-8C71-CFF017976D7",
fabric_conn_id="fabric_conn_id",
job_type="RunNotebook",
wait_for_termination=True,
deferrable=True,
)
clean_data_failure = PythonOperator(
task_id="clean_data_failure",
python_callable=my_python_callable,
trigger_rule="all_failed",
)
# 任务依赖
clean_data >> clean_data_failure上面展示了一个名为 fabric_dag 的示例 DAG,编排清洗与联接 等数据处理任务。你可按需添加更多任务,每个任务通常对应一个Operator,依赖则确定执行顺序。示例中的关键点:
FabricRunItemOperator
用于触发 Microsoft Fabric 中的既有条目 。需提供要运行对象的 item_id,可运行 Notebook、数据管道等各类制品。为提升灵活性与可维护性,建议使用 semPy 包以动态解析 而非硬编码 workspace_id 与 item_id。
保存 DAG 后,可在 Airflow UI 中查看与管理。图 6-9 展示 DAG 视图中的任务顺序与依赖 ;图 6-10 展示持续时间柱状图与网格 视图的运行监控,便于跟踪执行进度与性能并快速定位问题。上方为按持续时间统计的 DAG 运行图,下方为各任务实例。
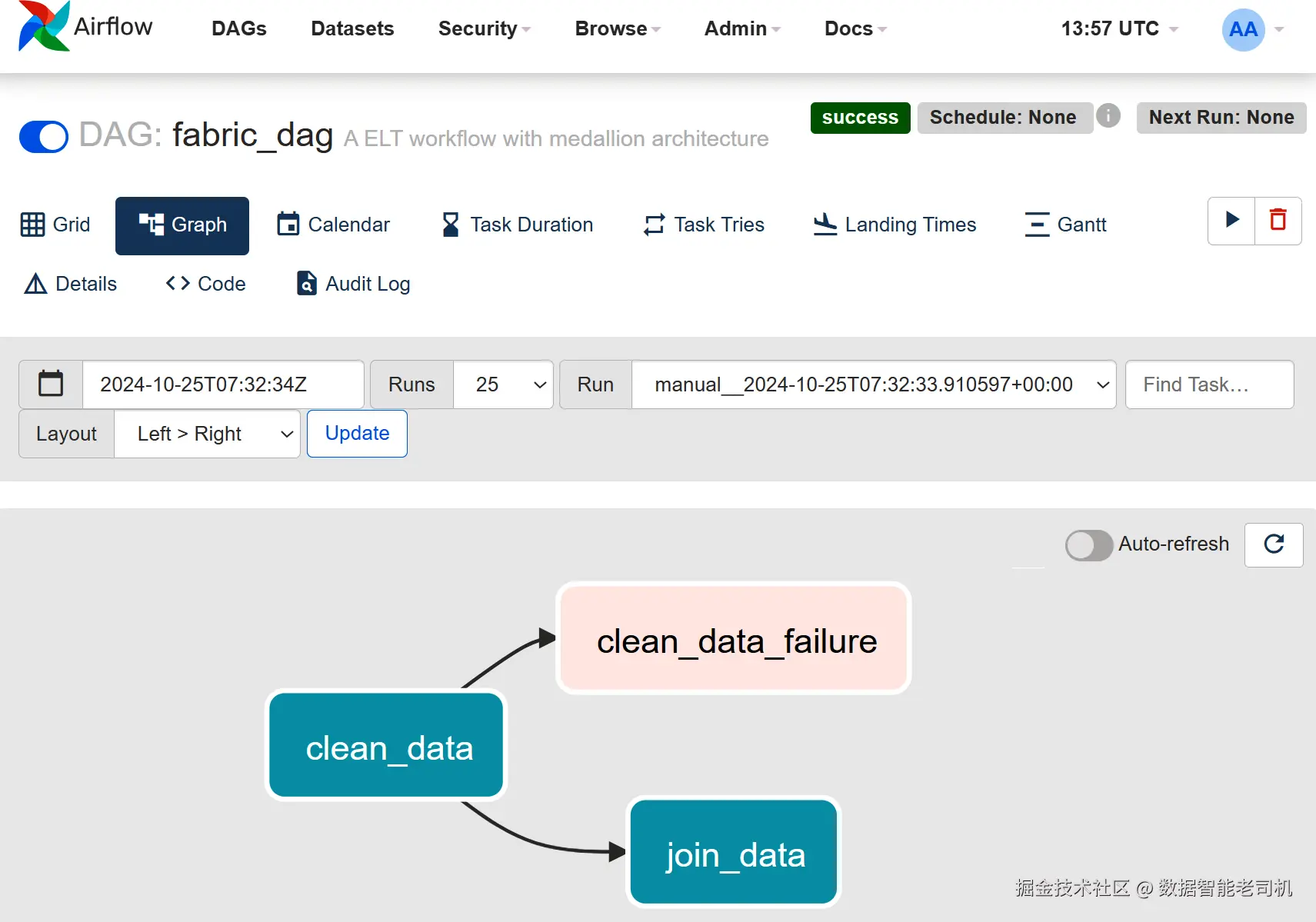
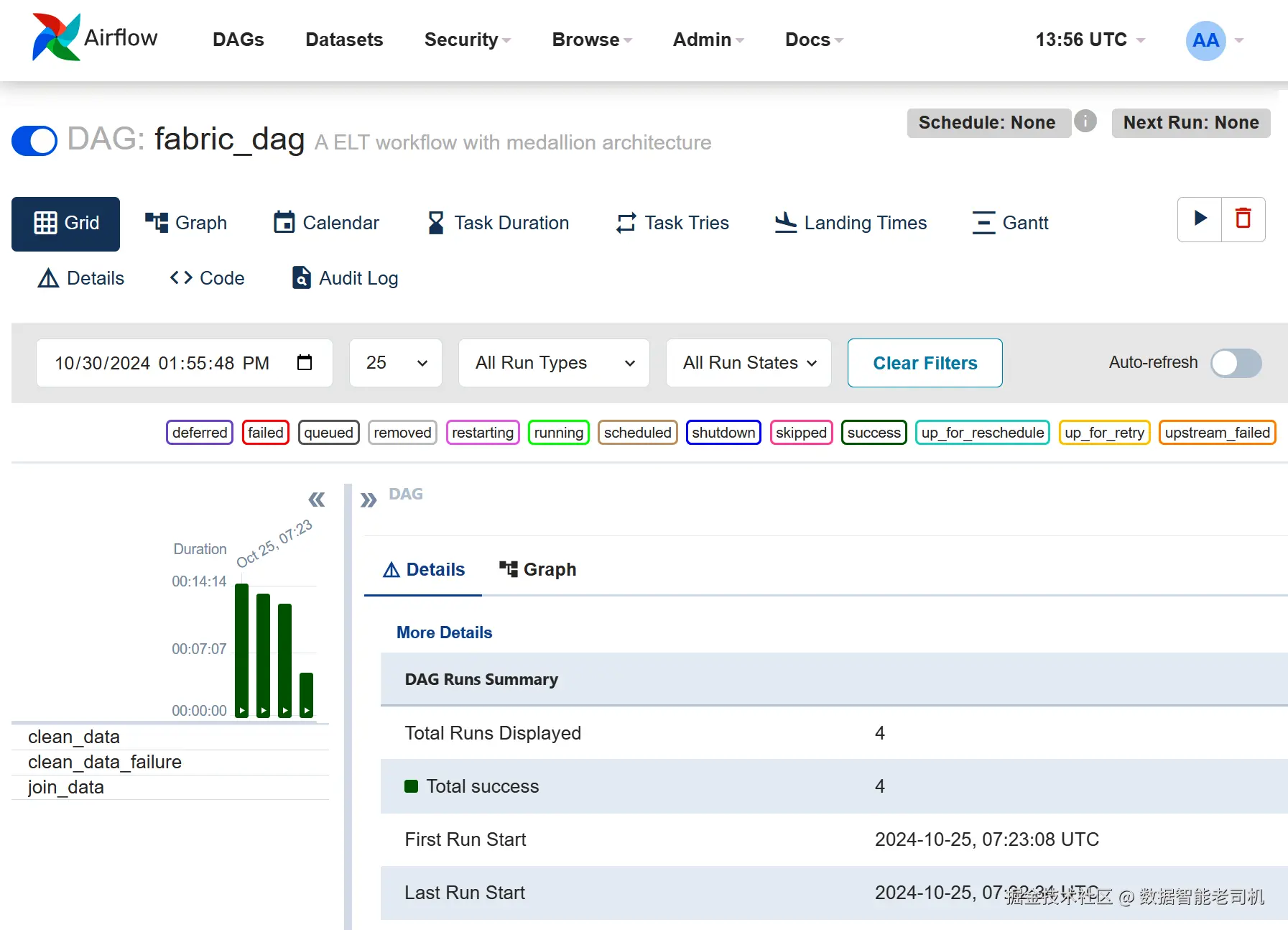
小结 :Apache Airflow 是强大且高效 的复杂数据工作流编排平台。它与 Microsoft Fabric 及 Azure Databricks 等服务深度集成 ;"用代码定义编排 "的方式带来更高的灵活性与精度,因此深受数据工程师青睐,用以简化与自动化数据工作流。
接下来,用一些最后的建议 来收束 Silver 层的实践部分,然后我们将转向数据产品主题。
最终建议(Final Recommendations)
现在你已经了解了为 Silver 层处理数据的各个方面,我们来回顾一下为 Oceanic Airlines 组装整条数据管道的过程,并给出一些最终建议。把自己想象成 Oceanic Airlines 的一名工程师,任务是构建一条健壮的数据管道。
正如第 5 章所述,管道流程从将多个来源的数据摄取到 Bronze 层 开始。完成摄取后,系统会获取描述数据结构的元数据 ,这对数据校验至关重要。随后依次进行数据清洗 与历史化(historization) ;可选地,你还可以执行表连接与数据丰富(enrichment) 。务必按正确的顺序执行这些活动。当一切正确完成后,管道会将数据交付到 Silver 层,如图 6-11 所示。
尽管本练习给出的流程看起来很直接,但在实际应用中常会出现复杂情况。比如数据质量 就是一个广而深的话题:不太可能用单个 Notebook 覆盖所有潜在问题与校验。你可能需要分别验证准确性、完整性、一致性、可靠性 ------而每一类都可能需要独立的规则与流程。随着数据规模与形态演进,保障质量的复杂度也会增长,往往需要多个 Notebook,分别面向不同数据类型或检查点。
相同的复杂度也会出现在数据丰富、反规范化(denormalization)和历史化上。不同用户对数据切片与性能的诉求不同,会催生不同策略,从而带来多本 Notebook。历史化还会引入管理不同版本、归档效率以及便捷访问历史数据等挑战,通常也需要多种技术手段,各自配套相应的 Notebook。
图 6-11:本例中的 Silver 层包含经过校验、清洗、丰富与历史化的数据。
总之,现实中的数据管道往往需要比少数几个静态 Notebook 更动态 、更可适配 。因此,面向 Oceanic Airlines 的工程实践改进,以下是一些可落地的建议,帮助项目更有结构、更易维护:
- 打造成熟的数据工程文化
采用 DevOps 思维,落地 CI/CD,营造协作与知识分享文化,提升项目的质量、可靠性与效率。 - 用 Azure Data Factory 负责数据搬运,用 Airflow 负责编排
先用 ADF 处理抽取与初始搬运;它擅长从多源顺畅编排数据流。将 Apache Airflow 用于复杂工作流的依赖管理与调度。二者结合能构建稳健高效的端到端管道。 - 充分利用元数据
数据就位后,获取所需元数据,用它来驱动下游处理逻辑。 - 用高并发提升查询速度
考虑高并发或会话共享模式,让多个 Notebook 共享 Spark 计算资源,在并行作业时显著提速。注意:Fabric 的高并发模式与 Databricks 的 High Concurrency 集群模式并不相同。 - 用日志替代 print
引入统一的日志模块,保持输出整洁并便于生产排错。最好在 ADF 与 Notebook 两侧统一日志方案,便于端到端监控与分析。 - 保护敏感信息
不要把密码或凭据写进 Python 文件或 Notebook。使用 Azure Key Vault 等安全保管库。 - 逻辑化组织代码
将相关代码聚拢,提升可读性与上下文理解度。Notebook 也要按目的分类(清洗、转换、丰富等),并用清晰的命名便于快速识别。 - 用 Git 做版本管理
把团队制品(如 Notebook)纳入 Git,跟踪变更、协作与追溯。推荐按notebooks/、src/、tests/等目录结构组织仓库。 - 用函数参数替代硬编码
提升复用性与可维护性。 - 保持代码精炼
尽量将 Notebook 控制在 300 行以内 、单个函数 100 行以内。超过就考虑拆分。 - 执行代码样式规范
启用 Pylint 做静态检查并统一风格;同时遵循 PEP 8 等规范。 - 用视图减少存储
中间结果尽量用 视图 而非物化表,降低存储与成本。 - 作业后清理
及时清理临时表与 Spark 计算资源,避免不必要的费用。 - 为代码编写测试
使用 pytest 等框架保障正确性,防止回归。 - 生产代码用 IDE 与 .py
生产中优先用 Python 脚本(.py) 而非 Notebook(.ipynb),配合 VS Code 等 IDE 与 Git 集成,提升工程化与协作效率。
落实以上实践后,Bronze 层输出的已可信数据可被多场景复用。Silver 层数据 非常适合运营报表 (保留了源系统的语境但更干净规范),也适合用于**(运营型)机器学习**,尤其是在与业务应用域构建数字反馈回路时。除此之外,Silver 层数据在某些情况下也可以直接作为数据产品对外提供。
将 Silver 层数据作为产品(Silver-Layer Data as a Product)
"数据即产品(Data as a Product)"这一理念近年快速走红。Zhamak Dehghani 在《How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh》中首次系统阐述了该概念。其核心是要求使用者像管理实体产品一样去管理数据:把数据当作有价值的资产,强调明确的所有权、管理、维护与优化。
在 Medallion 架构语境下,数据产品 逐渐演变为数据目录中的逻辑表示 ,可由多种数据资产组成(如表、文件、报表)。数据产品将用于创造业务价值的数据与必要的元数据(结构、血缘、与物理数据的关系)一并打包。
你可以将数据产品大致分为两类:运营型 与分析型。
- 运营型数据产品 通常存储并使用于 Silver 层 ,并且对齐来源系统 ,因此适合作为运营报表 与机器学习(尤其是贴近业务域的用例)的数据来源。
- 分析型数据产品 通常源自 Gold 层,面向更广泛的数据分析与报表需求。
数据产品的设计与使用有若干细微之处需要权衡:
首先,数据产品应以消费者为中心 ,即可访问、可理解、可使用 。对"可复用"的强调会带来稳定性与向后兼容 的设计约束,从而限制你频繁重构 Silver 层 。因此,若你直接从 Silver 层对外提供数据产品,应将模式(Schema)变更 对这些数据集的影响纳入考量。一个可选做法是建立一个**(虚拟)子层**,专门存放为这些产品准备的稳定拷贝 。
其次,Silver 层的数据往往按来源系统分组 ,这使其不太适合与其他来源做跨域的综合分析。若属实,应确立原则:运营型或 Silver 层的数据产品仅在其所属域内使用。这样既确保合用其用途,也能维护数据质量。我们将在第 7 章再回到这个话题。
结论
本章关于构建与精简 Silver 层 的讨论最后要强调:Silver 层的实际设计会随组织需求而异 。架构可能由若干子层 组成,分别承载不同的处理需求或不同类型的转换与校验。这样的灵活性 有助于量体裁衣,使数据管理策略更贴合组织的目标与挑战。但无论如何,Silver 层内的处理步骤都必须按正确顺序执行!
一个关键问题是如何组织这些处理步骤。例如:
- 是在同一个 Lakehouse 实体 里用表名前缀(如
clean_、quarantine_、hist_)来区分, - 还是为每个处理步骤建立独立的 Lakehouse 实体 ?
答案取决于你的处理复杂度与关注点分离 的需要。做决定时,要在可管理性 与安全性之间做权衡。
采用元数据驱动 的方法已被证明行之有效。它既能简化流程 ,也能显著减少手工脚本与差错 。从完整性校验、到丰富、再到历史化,元数据让你在推动数据穿越各环节的同时,持续维持高标准的数据质量与可靠性。
将数据视为产品能带来诸多机遇:当你像对待实体产品那样精心对待数据,意味着它会被有效管理、维护与优化。这不仅提升运营效率,也增强组织快速分析信息与做出明智决策的能力。
本章其他关键要点如下:
- 聚焦必要的转换以提炼来自 Bronze 层的原始数据:填补缺失、纠错、格式标准化,确保质量与一致性。
- 给出建模建议以支持清晰结构与可分析性。
- 评估是否需要整合多源形成统一视图;若暂不整合 ,请建立守则,确保数据持续对齐其来源系统。
- 纳管参照数据(Reference Data) :制定集中式治理策略,使跨源参照值一致,保障对比与分析的准确性。
- 实现幂等性:保证每个管道操作(如 merge 或 append overwrite)可重复执行且结果一致;避免在无截断的情况下盲目 append 以免重复。
- 提升存储与处理能力 以应对增长的数据量;在管道末尾加入优化与维护作业,确保性能最佳。
- 建立增量更新机制,使 Silver 层保持最新而无需全量重算。
- 封装标准函数以自动化日常处理、例行检查与维护工作。
- 明确 Silver 层数据的可见性指引 :是否允许终端用户与其他域访问?若不允许,考虑在 Silver 内建立子层,为用户提供稳定副本。
- 评估引入数据转换框架 (如 dbt)来简化传统在 Notebook 中维护的复杂任务;并考虑使用 Airflow 做稳健的编排 与调度,提升整个数据管道的效率。
在第 7 章,我们将深入如何构建 Gold 层 :如何为分析优化数据、创建统一视图,并设计支撑业务决策的层;同时也会讨论如何设置数据目录 以实现稳健的数据治理与管理。这将是搭建端到端 Medallion 架构旅程的最后一章。