文章目录
前言
每一种流式处理系统都不一样------从基本的消费者、处理逻辑和生产者的组合,到使用了Spark Streaming和机器学习软件包的复杂集群,以及其他很多介于二者之间的系统。但不管怎样,还是有一些基本的设计模式和解决方案,它们是解决流式处理架构常见需求的解决方案。下面将介绍一些众所周知的模式,并举例说明如何使用它们。
流式处理设计模式
单事件处理
处理单个事件是流式处理最基本的模式。这种模式也叫映射(map)模式或过滤器(filter)模式,因为它经常被用于过滤无用的事件或对事件进行转换。(map这个术语是从map-reduce模式中来的,在map阶段转换事件,在reduce阶段聚合事件。)
在这种模式中,应用程序会读取流中的事件,修改它们,再把它们生成到另一个流中。
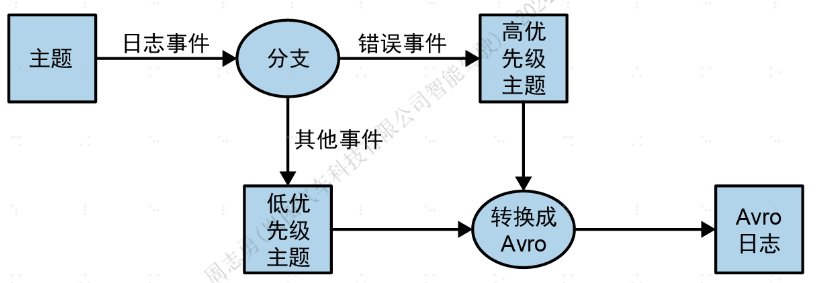
一个例子是,一个应用程序从流中读取日志消息,然后把ERROR级别的消息写到高优先级流中,把其他消息写到低优先级流中。
另一个例子是,一个应用程序从流中读取事件,然后把事件从JSON格式转换成Avro格式。
这类应用程序不需要在程序内部维护状态,因为每一个事件都是独立处理的。这也意味着,从故障或负载均衡中恢复都是非常容易的,因为不需要恢复状态,只需将事件交给另一个实例去处理即可。
这种模式可以使用一个生产者和一个消费者来实现,如下图所示:
使用本地状态
大多数流式处理应用程序需要用到聚合信息,特别是基于时间窗口的聚合。例如,找出每天最低和最高的股票交易价格,并计算移动平均数。
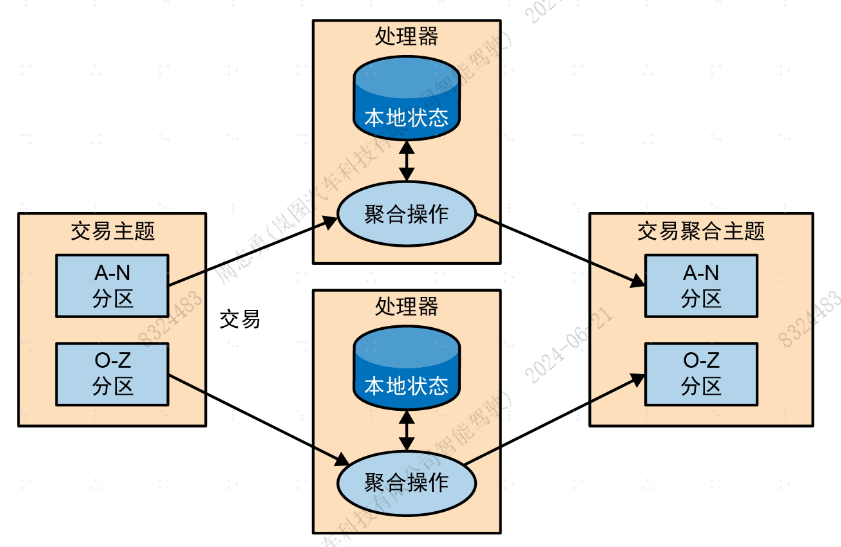
要实现这些聚合操作,需要维护流的状态 。在我们的例子中,为了计算股票每天的最小价格和平均价格,需要将到当前时间为止的最小值、总和以及记录数量保存下来。
这些操作可以通过本地状态(而不是共享状态)来实现,因为示例中的每一个操作都是分组聚合操作。也就是说,我们是对各只股票进行聚合,而不是对整个股票市场进行聚合。我们使用Kafka分区器来确保具有相同股票代码的事件总是被写入相同的分区。然后,应用程序的每个实例会从分配给自己的分区读取事件(这是Kafka的消费者保证),并维护一个股票代码子集的状态。如下图所示:
如果流式处理应用程序包含了本地状态,那么情况就会变得非常复杂。流式处理应用程序必须解决下面这些问题:
内存使用
- 应用程序实例必须有可用的内存来保存本地状态。一些本地存储允许溢出到磁盘,但这对性能有很大影响。
持久化
- 要确保在应用程序关闭时状态不会丢失,并且在应用程序重启后或切换到另一个应用实例时可以恢复状态。
- Streams可以很好地处理这些问题,它使用内嵌的RocksDB将本地状态保存在内存里,同时持久化到磁盘上,以便在重启后恢复。同时,本地状态的变更也会被发送到Kafka主题上。
- 如果一个Streams节点发生崩溃,那么本地状态并不会丢失,因为可以通过重新读取Kafka主题上的事件来重建本地状态。如果本地状态包含"IBM当前最小价格167.19",那么就将其保存到Kafka中,以便通过读取这些数据来重建本地缓存。这些Kafka主题使用了压缩日志,以确保它们不会无限量地增长,方便我们重建状态。
再均衡
- 有时候,分区会被重新分配给不同的消费者。在这种情况下,失去分区的实例必须把最后的状态保存起来,而获得分区的实例必须知道如何恢复到正确的状态。
多阶段处理和重分区
本地状态对按组聚合的操作起到了非常大的作用。但如果需要基于所有可用信息来获得一个结果呢?
假设我们每天要公布排名"前10"的股票,也就是每天从开盘到收盘收益最高的10只股票。
很显然,只是在每个应用程序实例中执行操作是不够的,因为排名前10的股票可能分布在分配给其他实例的分区中。
我们需要一个两阶段解决方案。
- 首先,计算出每只股票当天的涨跌,这个可以在每个实例中进行,并保存本地状态。
- 然后,将结果写到一个包含单个分区的新主题中。
- 另一个独立的应用程序实例会读取这个分区,找出当天排名前10的股票。新主题只包含了每只股票当日的概要信息,比其他包含交易信息的主题要小很多,所以流量很小,使用单个应用程序实例就足以应付。
不过,有时候需要更多的步骤才能生成结果。如下图所示:

使用外部查找:流和表的连接
有时候,流式处理需要将外部数据和流集成在一起,比如根据保存在外部数据库中的规则来验证事务,或者将用户信息填充到点击事件流中。
要使用外部查找来实现数据填充,可以这样做:对于事件流中的每一个点击事件,从用户信息表中查找相关的用户信息,生成一个新事件,其中包含原始事件以及用户的年龄和性别信息,然后将新事件发布到另一个主题上,如下图所示:

延迟与缓存
这种方式最大的问题在于,外部查找会严重增加处理每条记录的延迟,通常为5-15毫秒。这在很多情况下是不可行的。另外,给外部数据存储造成的额外负担也是不可接受的------流式处理系统每秒可以处理10~50万个事件,而数据库正常情况下每秒只能处理1万个事件。这也增加了可用性方面的复杂性,因为当外部存储不可用时,应用程序需要知道该作何处理。
为了获得更好的性能和伸缩性,需要在流式处理应用程序中缓存从数据库读取的信息。不过,管理缓存也是一个大问题。例如,该如何保证缓存中的数据是最新的?如果刷新太过频繁,则仍然会对数据库造成压力,缓存也就失去了应有的作用。如果刷新不及时,那么流式处理用的就是过时的数据。
使用 CDC 优化
如果能够捕获数据库变更事件,并形成事件流,那么就可以让流式处理作业监听事件流,然后根据变更事件及时更新缓存。捕获数据库变更事件并形成事件流的过程叫作CDC,Connect提供了一些连接器用于执行CDC任务,并把数据库表转成变更事件流。这样我们就拥有了数据库表的私有副本,一旦数据库发生变更,我们就会收到通知,并根据变更事件更新私有副本里的数据,如下图所示:
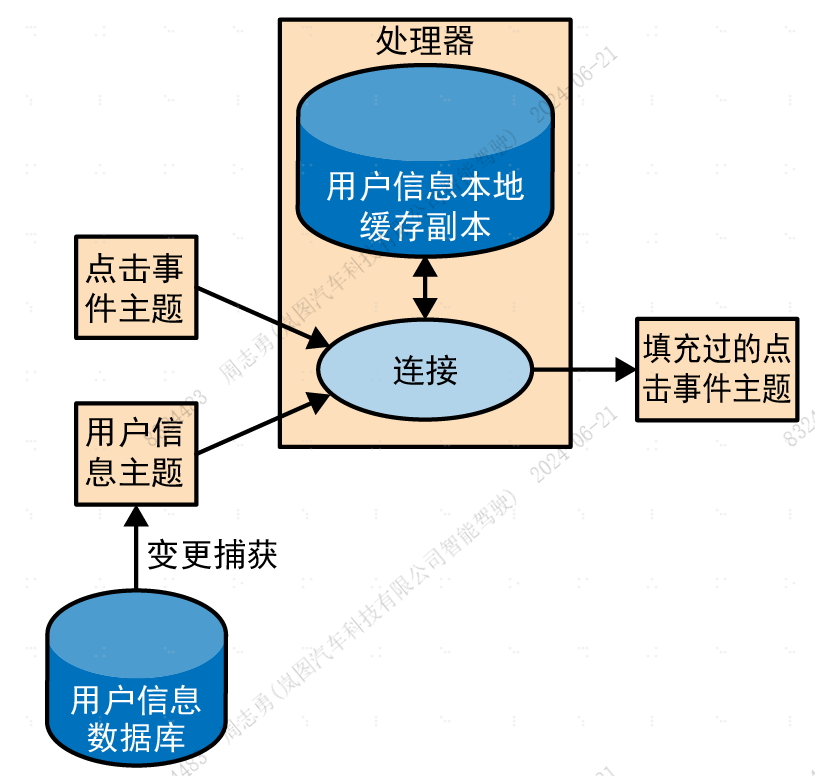
这样一来,每当收到点击事件,我们就从本地缓存里查找user_id,并将其填充到点击事件中。因为使用的是本地缓存,所以具有更强的伸缩性,而且不会影响数据库和其他使用数据库的应用程序。
之所以将这种方式叫作流和表的连接 ,是因为其中一个流代表了本地缓存表的变更。
表与表的连接
前边介绍了表和变更事件流之间的等价性,以及如何连接流和表。那么,我们也完全有理由在连接操作的两边都使用物化表。
连接两张表不是基于时间窗口,在执行连接操作时,连接的是两张表的当前状态。Streams可以实现等价连接(equi-join),也就是说,两张表具有相同的键,并且分区方式也一样,这样我们就可以在大量的应用程序实例和机器之间执行高效的连接操作。
Streams还支持两张表的外键连接(foreign-key join),即一个流或表的键与另一个流或表的任意字段连接。
流与流的连接
有时候,我们需要连接两个真实的事件流,而不是一个流和一张表。什么是"真实"的流?之前一篇介绍流处理相关概念的文章中说明了流是无边界的。如果用一个流来表示一张表,那么就可以忽略流的大部分历史事件,因为我们只关心表的当前状态。但是,如果要连接两个流,则要连接所有的历史事件,也就是将两个流里具有相同键和发生在相同时间窗口内的事件匹配起来。这就是为什么流和流的连接也叫作基于时间窗口的连接 。
假设我们有一个用户搜索事件流和一个用户点击搜索结果事件流。我们想要匹配用户的搜索和用户对搜索结果的点击,以便知道哪个搜索的热度更高。很显然,我们需要基于搜索关键词进行匹配,而且只能匹配一个时间窗口内的事件。假设用户会在输入搜索关键词几秒之后点击搜索结果。因此,我们为每一个流保留了几秒的时间窗口,并对每个时间窗口内的事件进行匹配,如下图所示:
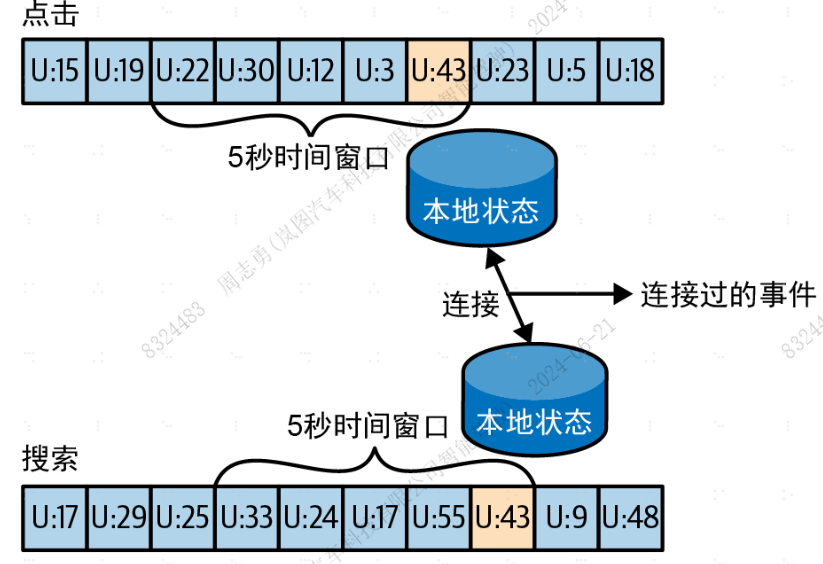
Streams支持等价连接(equi-joins),流、查询、点击事件都是通过相同的键来进行分区的,而且这些键就是连接用的键。这样一来,user_id:43所有的点击事件都会被保存到点击主题的分区5中,而user_id:43所有的搜索事件都会被保存到搜索主题的分区5中。
然后,Streams会确保这两个主题的分区5被分配给同一个任务,这样这个任务就可以看到所有与user_id:42相关的事件。Streams在内嵌的RocksDB中维护了两个主题的连接时间窗口,所以能执行连接操作。
乱序事件
无论是流式处理系统还是传统的ETL系统,处理乱序事件对它们来说都是一个挑战。物联网领域经常出现乱序事件,例如,一个移动设备断开WiFi连接几小时,在重新连上后将几小时以来累积的事件一起发送出去。
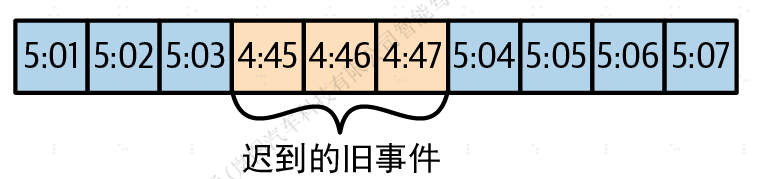
要让流处理应用程序处理好这些场景,需要做到以下几点:
- 识别乱序事件。应用程序需要检查事件的时间,并将其与当前时间对比。
- 定一个时间段用于重排乱序事件。例如,3小时以内的事件可以重排,但3周以外的事件可以直接丢弃。
- 能够带内(in-band)重排乱序事件。这是流式处理与批处理作业的一个主要不同点。如果我们有一个每天运行的作业,一些事件在作业结束之后才到达,那么可以重新运行昨天的作业并更新事件。而在流式处理中,"重新运行昨天的作业"这种事情是不存在的,乱序事件和新到达的事件必须一起处理。
- 能够更新结果。如果处理结果是保存到数据库中,那么可以通过put或update更新结果。如果处理结果是通过邮件发送的,则需要用到一些巧妙的方法。
有些流式处理框架(比如Google Dataflow和Kafka Streams)支持处理独立于处理时间的事件,能够处理比当前时间更晚或更早的事件。它们在本地状态里维护了多个可更新的聚合时间窗口,为开发人员提供了配置时间窗口可更新时长的能力。当然,时间窗口可更新时间越长,维护本地状态需要的内存就越大。
Streams API通常会将聚合结果写到主题中。这些主题一般是压缩日志主题(compacted topics),也就是说,它们只保留每个键的最新值。如果一个聚合时间窗口的结果因为晚到事件需要被更新,那么Streams会直接为这个聚合时间窗口写入一个新结果,将前一个覆盖掉。
重新处理
最后一个重要的模式是重新处理事件,它有两个变种。
- 我们对流式处理应用程序做了改进,用它处理同一个事件流,生成新的结果流,并比较两种版本的结果,然后在某个时间点将客户端切换到新的结果流中。
- 现有的流式处理应用程序有很多bug,修复完bug之后,我们用它重新处理事件流并计算结果。
第一种情况很简单,Kafka会将事件流保存在一个可伸缩的数据存储里很长一段时间。要使用两个版本的流式处理应用程序来生成结果,只需满足如下条件。
- 将新版本应用程序作为一个新的消费者群组。
- 让新版本应用程序从输入主题的第一个偏移量开始读取数据(这样它就有了属于自己的输入流事件副本)。
- 让新版本应用程序继续处理事件,等它赶上进度时,将客户端应用程序切换到新的结果流中。
第二种情况具有一定的挑战性。它要求"重置"现有的应用程序,让它回到输入流的起始位置开始处理,同时重置本地状态(这样就不会将两个版本应用程序的处理结果混淆起来了),还可能需要清理之前的输出流。尽管Streams提供了一个用于重置应用程序状态的工具,但建议是,如果有条件运行两个应用程序并生成两个结果流,那么还是使用第一种方案。第一种方案更加安全,因为它可以在多个版本之间来回切换,比较不同版本的结果,而且不会造成数据丢失,也不会在清理过程中引入错误。
交互式查询
如前所述,流式处理应用程序是有状态的,并且状态可以分布在多个应用程序实例中。
大多数时候,流式处理应用程序的用户会从输出主题获取处理结果,但在某些情况下也可以用更简便的办法直接从状态存储里读取结果。如果处理结果是一张表(例如,10本最畅销的图书 ),而结果流又是这张表的更新流,那么直接从流式处理应用程序的状态存储中读取表数据要快得多,也容易得多。
Streams示例
接下来将演示一些使用 Kafka Streams 来实现上述模式的例子。"字数统计"这个例子用于演示map与filter模式以及简单的聚合,"计算股票交易市场统计信息"这个例子用于演示基于时间窗口的聚合,"填充点击事件流"这个例子用于演示流的连接。
字数统计
java
public class WordCountExample {
public static void main(String[] args) throws Exception{
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG,
"wordcount"); ➊
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,
"localhost:9092"); ➋
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG,
Serdes.String().getClass().getName()); ➌
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG,
Serdes.String().getClass().getName());- ❶ 每个Streams应用程序都必须有一个应用程序ID。这个ID即可用于协调应用程序实例,也可用于命名内部的本地存储和相关主题。对于同一个Kafka集群中的每一个Streams应用程序,这个ID必须是唯一的。
- ❷ Streams应用程序通常会从Kafka主题上读取数据,并将结果写到Kafka主题。稍后我们还会看到,Streams应用程序也会将Kafka作为协调工具。所以,应用程序需要知道怎样连接到Kafka。
- ❸ 在读写数据时,应用程序需要对消息进行序列化和反序列化,所以我们提供了默认的序列化类和反序列化类。如果有必要,则可以在稍后创建拓扑时覆盖这些默认值。
配置好之后,开始创建拓扑。
java
StreamBuilder builder = new StreamBuilder(); ➊
KStream<String, String> source =
builder.stream("wordcount-input");
final Pattern pattern = Pattern.compile("\\W+");
KStream<String,String> counts = source.flatMapValues(value->
Arrays.asList(pattern.split(value.toLowerCase()))) ➋
.map((key, value) -> new KeyValue<String,
String>(value, value))
.filter((key, value) -> (!value.equals("the"))) ➌
.groupByKey() ➍
.count("CountStore").mapValues(value->
Long.toString(value)).toStream(); ➎
counts.to("wordcount-output"); ➏- ❶ 创建一个StreamBuilder对象,并定义一个流,将它指向一个输入主题。
- ❷ 从源主题上读取的每一个事件都是一行文本。先用正则表达式将它拆分成一系列单词,然后将每个单词(事件的值)放到事件的键里,稍后就可以用它们执行分组操作了。
- ❸ 将单词the过滤掉。可见过滤操作有多么简单。
- ❹ 根据键执行分组操作,这样就得到了每一个单词的事件集合。
- ❺ 计算每个集合中的事件数。计算的结果是Long数据类型,我们将它转成String类型,方便其他用户从Kafka中读取结果。
- ❻ 最后把结果写回Kafka。
定义好转换流程后,接下来要做的就是运行它。
java
KafkaStreams streams = new KafkaStreams(builder.build(), props); ➊
streams.start(); ➋
// 一般情况下,Streams应用程序会一直运行下去
// 在这里,我们只让它运行一段时间,然后将其关闭
Thread.sleep(5000L);
streams.close(); ➌- ❶ 基于拓扑和配置属性定义一个KafkaStreams对象。
- ❷ 启动Streams。
- ❸ 过一段时间后将它关闭。
股票市场统计
接下来的这个例子会复杂一些,我们将从一个股票交易事件流里读取事件,这些事件包含了股票行情、卖出价和卖价数量。在股票市场交易中,卖出价 是指卖方的出价,买入价 是指买方建议支付的价格,卖价数量 是指卖方愿意在这个价格出售的股数。为简单起见,我们直接忽略了竞价。数据里不包含时间戳,这里将使用由Kafka生产者填充的事件时间。
我们将创建包含若干时间窗口统计信息的输出流。
- 每5秒内最好的(也即最低的)卖出价。
- 每5秒内的交易股数。
- 每5秒内的平均卖出价。
这些统计信息每秒会更新一次。
为简单起见,假设交易所只有10只不同的股票。应用程序的参数配置与"字数统计"示例差不多。
java
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "stockstat");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, Constants.BROKER);
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG,
Serdes.String().getClass().getName());
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG,
TradeSerde.class.getName());主要的区别在于这次使用的Serde类不一样。在"字数统计"示例中,键和值的类型都是字符串,所以我们使用Serdes.String()类作为序列化器和反序列化器。而在这个例子中,键仍然是字符串,但值是Trade对象,它包含了股票代码、卖出价和卖价数量。为了序列化和反序列化这个对象(还包括应用程序中用到的其他几种对象),我们使用谷歌的Gson开发库从Java对象中生成了JSon序列化器和反序列化器。然后创建了一个包装类,用于生成Serde对象。
java
static public final class TradeSerde extends WrapperSerde<Trade> {
public TradeSerde() {
super(new JsonSerializer<Trade>(),
new JsonDeserializer<Trade>(Trade.class));
}
}这里没什么特别的,只是要记得为存储在Kafka中的每一个对象提供一个Serde对象------输入、输出和中间结果。为了简化这个过程,建议使用GSon、Avro、Protobuf等框架来生成Serde。
配置好以后,开始构建拓扑。
java
KStream<Windowed<String>, TradeStats> stats = source
.groupByKey() ➊
.windowedBy(TimeWindows.of(Duration.ofMillis(windowSize))
.advanceBy(Duration.ofSeconds(1))) ➋
.aggregate( ➌
() -> new TradeStats(),
(k, v, tradestats) -> tradestats.add(v), ➍
Materialized.<String, TradeStats, WindowStore<Bytes, byte[]>>
as("trade-aggregates") ➎
.withValueSerde(new TradeStatsSerde())) ➏
.toStream() ➐
.mapValues((trade) -> trade.computeAvgPrice()); ➑
stats.to("stockstats-output",
Produced.keySerde(
WindowedSerdes.timeWindowedSerdeFrom(String.class, windowSize))); ➒- ❶ 从输入主题上读取事件并执行groupByKey()操作。这个方法实际上并不会执行任何分组操作,但它会确保事件流按照记录的键进行分区。因为在写数据时使用了键,而且在调用groupByKey()方法之前不会修改键,所以数据仍然是按照它们的键进行分区的。也就是说,这个方法什么事情都没做。
- ❷ 定义窗口。这里是5分钟的窗口,每秒移动一次。
- ❸ 在确保有了正确的分区并定义好时间窗口之后,开始聚合操作。aggregate方法会将事件流拆分成相互叠加的时间窗口(每秒出现一个5秒的时间窗口),然后将聚合方法应用在时间窗口内的所有事件上。这个方法的第一个参数是一个新对象,用于存放聚合结果,在这个例子中是TradeStats。我们用这个对象存放每个时间窗口的统计信息,包括最低价格、平均价格和交易数量。
- ❹ 我们提供了一个方法对记录进行聚合,这里,TradeStats的add方法用于更新时间窗口内的最低价格、交易数量和总价。
- ❺ 基于时间窗口的聚合需要用到保存在本地存储中的状态。聚合方法的最后一个参数就是本地状态存储的配置信息。Materialized是本地存储配置对象,它的名字是trade-aggregates,也可以是任意具有唯一性的名字。
- ❻ 作为状态存储配置的一部分,我们还提供了Serde对象,用于序列化和反序列化聚合结果(TradeStats对象)。
- ❼ 聚合结果是一张表,包含了股票行情,并使用时间窗口作为键、聚合结果作为值。我们将表转成事件流。
- ❽ 更新平均价格。现在,聚合结果中包含了总价和交易数量。接下来遍历所有的记录,并使用现有的统计信息计算出平均价格,然后把它写到输出流里。
- ❾ 最后,将结果写到stockstats-output流里。因为结果是窗口操作的一部分,所以我们创建了一个WindowedSerde对象,将结果保存成窗口数据格式,其中包含了窗口时间戳。窗口大小会作为Serde的一个参数被传递进去,尽管它没有被用在序列化中(反序列化需要用到窗口大小,因为输出主题中只有窗口的开始时间)。
定义好流程之后,用它生成KafkaStreams对象,并运行这个对象,就像"字数统计"示例一样。
填充点击事件流
最后一个例子将通过填充网站点击事件流来演示如何连接流。我们将生成一个模拟点击事件流、一个虚拟用户信息数据库表的更新事件流和一个网站搜索事件流。然后再将这3个流连接起来,得到用户活动的360度视图。例如,用户搜索的是什么?他们点击了哪些搜索结果?他们是否修改了"感兴趣"的内容?这些连接操作为数据分析提供了丰富的数据集。产品推荐通常就是基于这些信息。如果用户搜索了自行车,点击了"Trek"的链接,并且爱好旅游,那么就可以向其推荐Trek自行车、头盔和骑行活动(比如去充满异国情调的内布拉斯加州)。
应用程序的配置与前一个例子相似,所以我们跳过这部分,直接进入构建拓扑这一步。
java
KStream<Integer, PageView> views =
builder.stream(Constants.PAGE_VIEW_TOPIC,
Consumed.with(Serdes.Integer(), new PageViewSerde())); ➊
KStream<Integer, Search> searches =
builder.stream(Constants.SEARCH_TOPIC,
Consumed.with(Serdes.Integer(), new SearchSerde()));
KTable<Integer, UserProfile> profiles =
builder.table(Constants.USER_PROFILE_TOPIC,
Consumed.with(Serdes.Integer(), new ProfileSerde())); ➋
KStream<Integer, UserActivity> viewsWithProfile = views.leftJoin(profiles, ➌
(page, profile) -> {
if (profile != null)
return new UserActivity(
profile.getUserID(), profile.getUserName(),
profile.getZipcode(), profile.getInterests(),
"", page.getPage()); ➍
else
return new UserActivity(
-1, "", "", null, "", page.getPage());
});
KStream<Integer, UserActivity> userActivityKStream =
viewsWithProfile.leftJoin(searches, ➎
(userActivity, search) -> {
if (search != null)
userActivity.updateSearch(search.getSearchTerms()); ➏
else
userActivity.updateSearch("");
return userActivity;
},
JoinWindows.of(Duration.ofSeconds(1)).before(Duration.ofSeconds(0)), ➐
StreamJoined.with(Serdes.Integer(), ➑
new UserActivitySerde(),
new SearchSerde()));- ❶ 首先,为要连接的点击事件流和搜索事件流创建流对象。在创建流对象时,我们指定了输入主题和键值的Serde,用于从主题读取记录或将记录反序列化成输入对象。
- ❷ 为用户信息定义一个KTable。KTable是一种物化存储,可以通过变更流对其进行更新。
- ❸ 然后,将点击事件流与用户信息表连接起来,将用户信息填充到点击事件里。在连接流和表时,每一个事件都会收到来自用户信息表缓存副本里的信息。这是一个左连接操作,所以那些没有匹配的用户信息的事件仍然可以被保留下来。
- ❹ 这是join方法,它接受两个值,一个来自事件流,一个来自表记录,并会返回一个新值。与数据库不同,我们可以决定如何将两个值合并成一个结果。这里创建了一个activity对象,该对象包含用户信息和浏览过的页面。
- ❺ 接下来,连接用户点击信息和用户搜索。这也是一个左连接,不过现在连接的是两个流,而不是流和表。
- ❻ 这是join方法,我们只是简单地将搜索关键词添加到与之匹配的页面浏览事件中。
- ❼ 这部分很有意思。流和流的连接是基于时间窗口的。如果只是把每个用户所有的点击事件和所有的搜索事件连接起来,那么并没有什么意义。我们要把具有相关性的搜索事件和点击事件连接起来,也就是说,具有相关性的点击事件应该发生在搜索之后的一小段时间内。所以,我们定义了一个1秒的连接时间窗口。首先调用of方法创建了一个在搜索之前一秒和搜索之后一秒的时间窗口,然后再调用before方法,间隔时间为0秒,确保只连接了发生在搜索之后而不是搜索之前一秒的单击事件。结果中将包含相关的点击、搜索关键词和用户信息。这样有助于对搜索和其结果进行全面的分析。
- ❽ 这里定义了连接结果的Serde,包括键和值的Serde。在这个例子中,键是用户ID,所以我们使用了简单的IntegerSerde。
定义好流程之后,用它生成KafkaStreams对象,并运行这个对象,就像"字数统计"示例一样。