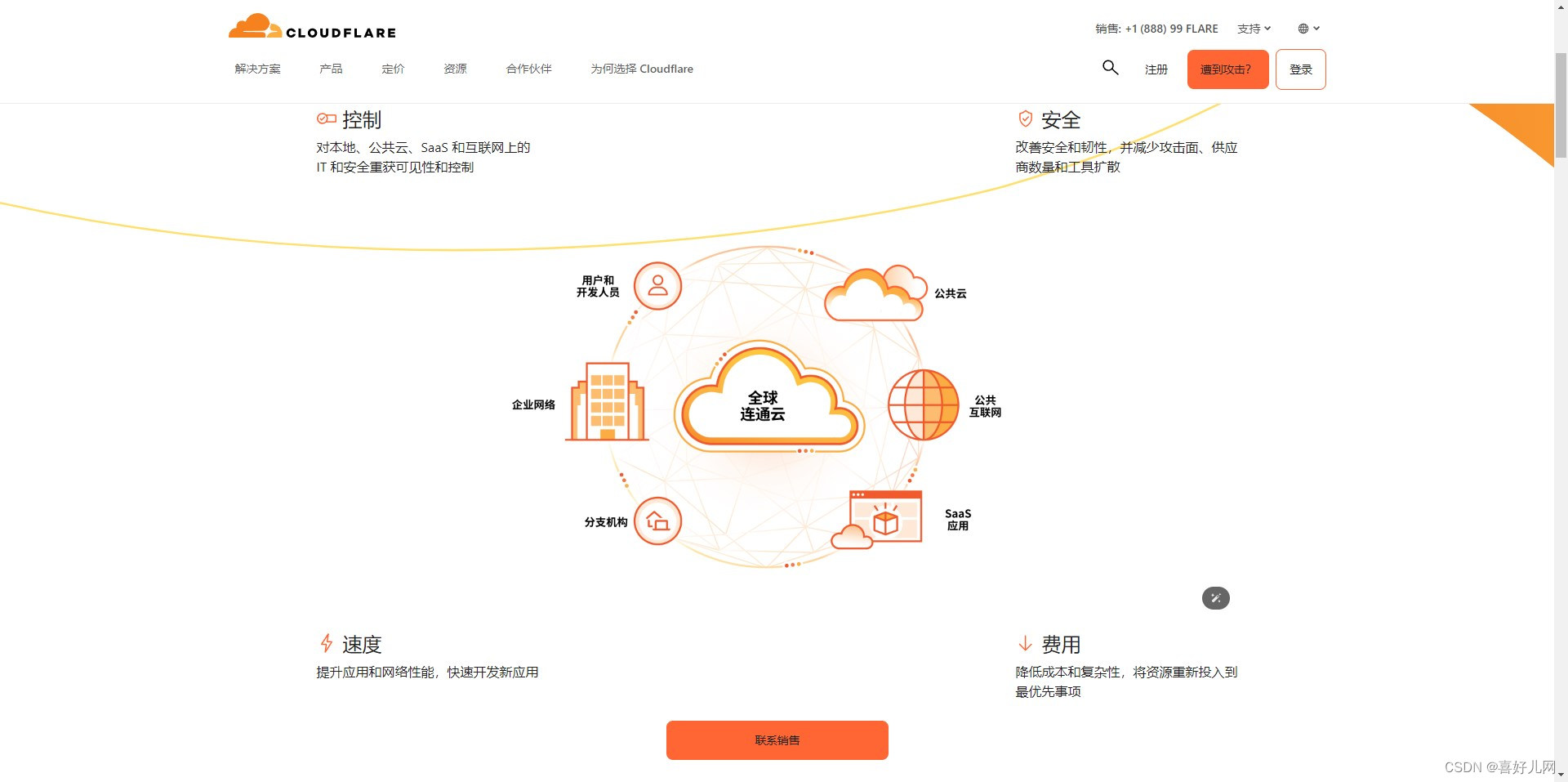
上市云服务提供商Cloudflare推出了一种新的免费工具,可防止机器人抓取其平台上托管的网站以获取数据以训练AI模型。
一些人工智能供应商,包括谷歌、OpenAI 和苹果,允许网站所有者通过修改他们网站的robots.txt来阻止他们用于数据抓取和模型训练的机器人,该文本文件告诉机器人他们可以在网站上访问哪些页面。但是,正如Cloudflare在宣布其机器人对抗工具的帖子中指出的那样,并非所有AI抓取工具都尊重这一点。
喜好儿网
"客户不希望人工智能机器人访问他们的网站,尤其是那些不诚实地这样做的人,"该公司在其官方博客上写道。"我们担心,一些意图规避规则访问内容的人工智能公司将持续适应以逃避机器人检测。"
因此,为了解决这个问题,Cloudflare 分析了 AI 机器人和爬虫流量,以微调自动机器人检测模型。除其他因素外,这些模型还考虑了人工智能机器人是否可能试图通过模仿使用网络浏览器的人的外表和行为来逃避检测。
"当不良行为者试图大规模抓取网站时,他们通常会使用我们能够指纹识别的工具和框架,"Cloudflare写道。"根据这些信号,我们的模型能够适当地将来自规避AI机器人的流量标记为机器人。
Cloudflare 为主机设置了一个表格,用于报告可疑的 AI 机器人和爬虫,并表示随着时间的推移,它将继续手动将 AI 机器人列入黑名单。
随着生成式人工智能的热潮推动了对模型训练数据的需求,人工智能机器人的问题已经得到了极大的缓解。
许多网站对 AI 供应商在其内容上训练模型而不发出警报或补偿持谨慎态度,因此选择阻止 AI 抓取器和爬虫。根据一项研究,网络上排名前1,000的网站中约有26%阻止了 OpenAI 的机器人;另一项研究发现,超过600家新闻出版商已经阻止了该机器人。
然而,阻止并不是万无一失的保护措施。如前所述,一些供应商似乎忽略了标准的机器人排除规则,以在人工智能竞赛中获得竞争优势。AI 搜索引擎 Perplexity 最近被指控冒充合法访问者从网站上抓取内容,据说 OpenAI 和 Anthropic 有时会无视robots.txt规则。
在上个月给出版商的一封信中,内容许可初创公司TollBit表示,事实上,它看到"许多人工智能代理"忽视了robots.txt标准。
像Cloudflare这样的工具可以提供帮助,但前提是它们被证明可以准确检测秘密的AI机器人。而且,它们无法解决更棘手的问题,即出版商冒着牺牲来自谷歌的人工智能概览等人工智能工具的推荐流量的风险,如果它们阻止特定的人工智能爬虫,这些工具就会将网站排除在外。