今天学习了Vision Transformer图像分类,这是一种基于Transformer模型的图像分类方法,它不依赖卷积操作,而是通过自注意力机制捕捉图像块之间的空间关系,从而实现图像分类。
基本原理:
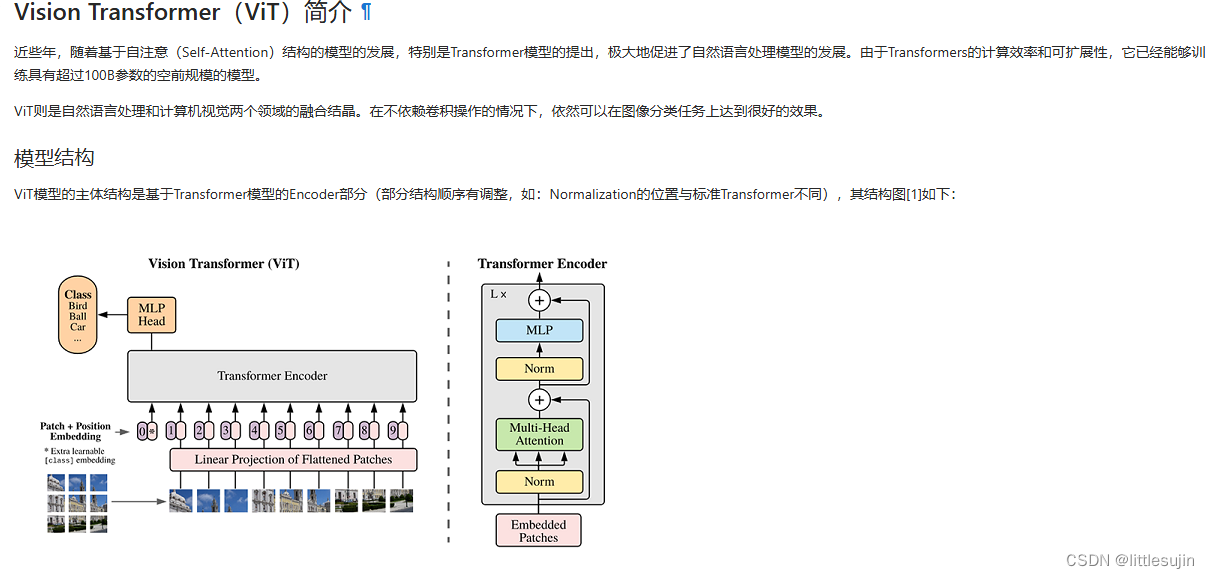
- 图像分块: 将原始图像划分为多个patch(图像块),并将二维patch转换为一维向量。
- 位置编码: 为了让模型理解patch的空间位置信息,引入位置编码,将位置信息融入到patch向量中。
- Transformer编码器: 模型的主体结构是基于Transformer的Encoder部分,包含多个Transformer块。每个Transformer块包含自注意力机制和前馈网络,用于捕捉patch之间的空间关系并进行特征提取。
- 分类器: 最后一个Transformer块的输出连接一个全连接层,用于分类。
与其他图像分类算法的区别和特色:
- 不依赖卷积操作: Vision Transformer不使用卷积操作,而是通过自注意力机制捕捉图像块之间的空间关系,这使得模型更加灵活,能够更好地捕捉图像的全局特征。
- 可扩展性: Transformer模型具有良好的可扩展性,可以轻松扩展到更大的模型,从而提高模型的性能。
打个比方:
Vision Transformer就像一位棋手,它不是通过记住棋盘上的每个棋子的位置,而是通过分析棋子之间的相互关系来下棋。同样,Vision Transformer不是通过分析图像中的每个像素,而是通过分析图像块之间的空间关系来进行图像分类。
本文档所用的数据库:
本文档使用的是ImageNet数据集 (包含了超过1400万个图像,涵盖了大约22000个类别。ImageNet数据集由Stanford大学计算机视觉实验室创建,旨在推动图像识别技术的发展。)的子集,包含训练集、验证集和测试集。
之前的学习中,涉及到多种图像分类算法如ResNet50, ShuffleNet,它们之间的区别和特点,总结下来感觉是这样:
ResNet50, ShuffleNet, 和 Vision Transformer (ViT) 是三种常用的图像分类算法,它们各自拥有不同的原理和特色。
1. ResNet50:
- 原理 : ResNet50 是一种深度卷积神经网络,它使用残差学习来解决深度网络训练过程中的梯度消失问题。ResNet50 通过引入残差连接,将输入直接连接到后续层,从而使得梯度可以直接传播到前面的层,避免了梯度消失的问题。
- 特色: ResNet50 具有很强的特征提取能力,能够捕捉图像中的复杂特征,并且具有良好的泛化能力。此外,ResNet50 还可以通过修改网络深度和宽度来调整模型复杂度,从而适应不同的任务需求。
2. ShuffleNet:
- 原理: ShuffleNet 是一种轻量级卷积神经网络,它使用通道混洗和分组卷积来减少模型参数量和计算量,从而降低模型复杂度。ShuffleNet 通过将输入通道划分为多个组,并在组内进行卷积操作,从而减少参数量和计算量。
- 特色: ShuffleNet 具有轻量级的特性,能够在移动设备上高效运行。此外,ShuffleNet 还可以通过调整分组数来调整模型复杂度,从而适应不同的计算资源限制。
3. Vision Transformer (ViT):
- 原理: ViT 是一种基于Transformer的图像分类算法,它将图像分割成多个patch,并使用Transformer编码器来捕捉patch之间的空间关系。ViT 使用自注意力机制来学习图像的全局特征,从而实现图像分类。
- 特色: ViT 不依赖卷积操作,而是通过自注意力机制捕捉图像块之间的空间关系,这使得模型更加灵活,能够更好地捕捉图像的全局特征。此外,ViT 具有很强的可扩展性,可以轻松扩展到更大的模型,从而提高模型的性能。
讨论:
例子: 假设我们有一个包含猫和狗的图像数据集,我们需要使用图像分类算法来区分猫和狗。
- ResNet50: ResNet50 可以有效地提取图像中的特征,例如猫的耳朵、狗的鼻子等,从而区分猫和狗。
- ShuffleNet: ShuffleNet 可以在移动设备上高效运行,因此我们可以使用ShuffleNet在手机上进行猫狗分类。
- ViT: ViT 可以更好地捕捉图像的全局特征,例如猫和狗的整体形状和姿态,从而更准确地区分猫和狗。
代码实现过程:
- 环境准备: 安装MindSpore库,并下载ImageNet数据集子集。
- 数据读取: 使用ImageFolderDataset读取数据集,并进行数据增强。
- 模型构建: 构建ViT模型,包括patch嵌入层、位置编码层、Transformer编码器层和分类器层。
- 模型训练: 设置损失函数、优化器和回调函数,并进行模型训练。
- 模型验证: 使用ImageFolderDataset读取验证集数据,并进行模型验证,评估模型的性能。
- 模型推理: 使用ImageFolderDataset读取测试集数据,并进行模型推理,预测图像类别。
代码说明:
- PatchEmbedding: 将图像块转换为向量,并添加class embedding和位置编码。
- TransformerEncoder: 包含多个Transformer块,每个Transformer块包含自注意力机制和前馈网络。
- CrossEntropySmooth: 损失函数,用于计算预测结果和真实标签之间的差距。
- Model: 用于编译模型,设置损失函数、优化器和评价指标。
- ImageFolderDataset: 用于读取数据集,并进行数据增强。
- show_result: 将预测结果标记在图片上。
具体代码和训练过程如下: