近年来,随着生成模型技术的不断突破,视频生成能力在工业界和学术界受到了越来越多的关注。高质量、长序列的视频生成逐渐成为研究热点,相关技术也开始向实际应用场景延伸。阿里通义万相团队近期也陆续开源了 Wan 2.1 、Wan 2.2 模型,凭借其出色的生成效果和开源的属性,在业界引发了广泛反响,进一步推动了视频生成方向的技术发展。
在此背景下,由于视频生成本身需要使用较长的序列且模型大小日益增大,其训练与推理所需的计算资源呈现爆炸式增长,模型训练往往需要数月时间,这对企业研发效率和成本控制构成巨大挑战。尽管大模型具备更优性能,但其严苛的算力需求与推理延迟问题直接影响企业市场响应速度和商业竞争力,构建高效稳定的模型训练体系与推理优化框架已成为科技企业发展的关键战略。
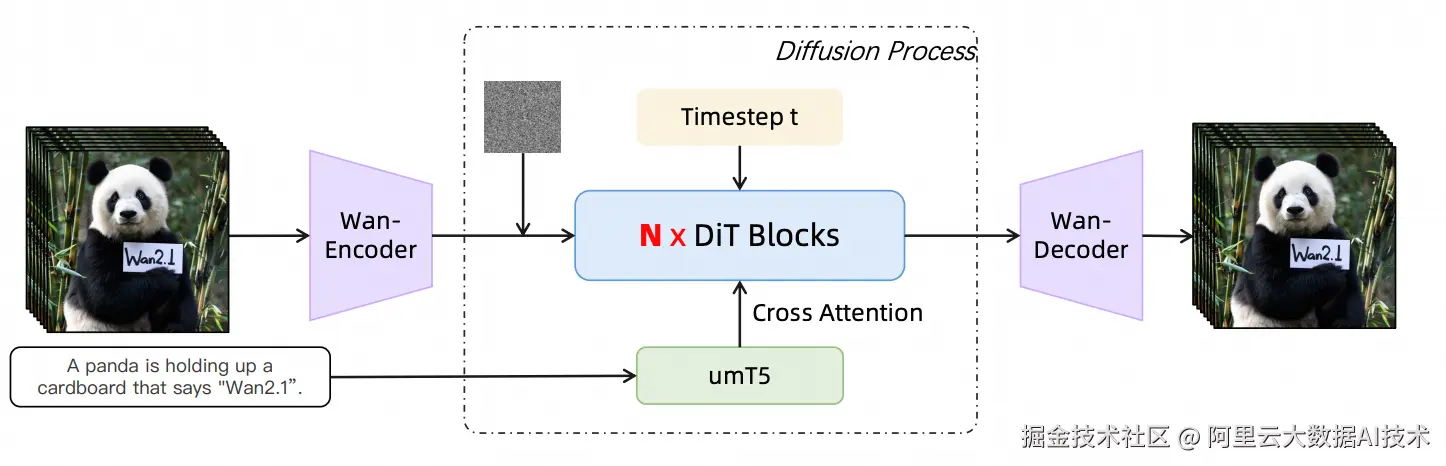
Wan模型架构,来自:https://arxiv.org/pdf/2503.20314
为此,阿里云 PAI 团队推出专为视频生成任务设计的 PAIFuser 框架。针对扩散模型(Diffusion Models),尤其是 DiT(Diffusion Transformer)架构,PAIFuser 通过高性能一体化训练与推理加速框架,有效解决高计算复杂度、显存消耗大、实时性不足等问题。同时,为短视频制作、虚拟现实和创意内容生成等对时效性要求高的场景提供技术支撑,在保障生成质量的前提下显著降低时间成本,加速 AI 技术的落地应用。该框架支持视频生成场景高效的训练和推理。在数千卡集群,训练场景达到了40%+的 MFU。在单机8卡条件下,推理场景生成时间最高减少80%+。
视频生成开销分析
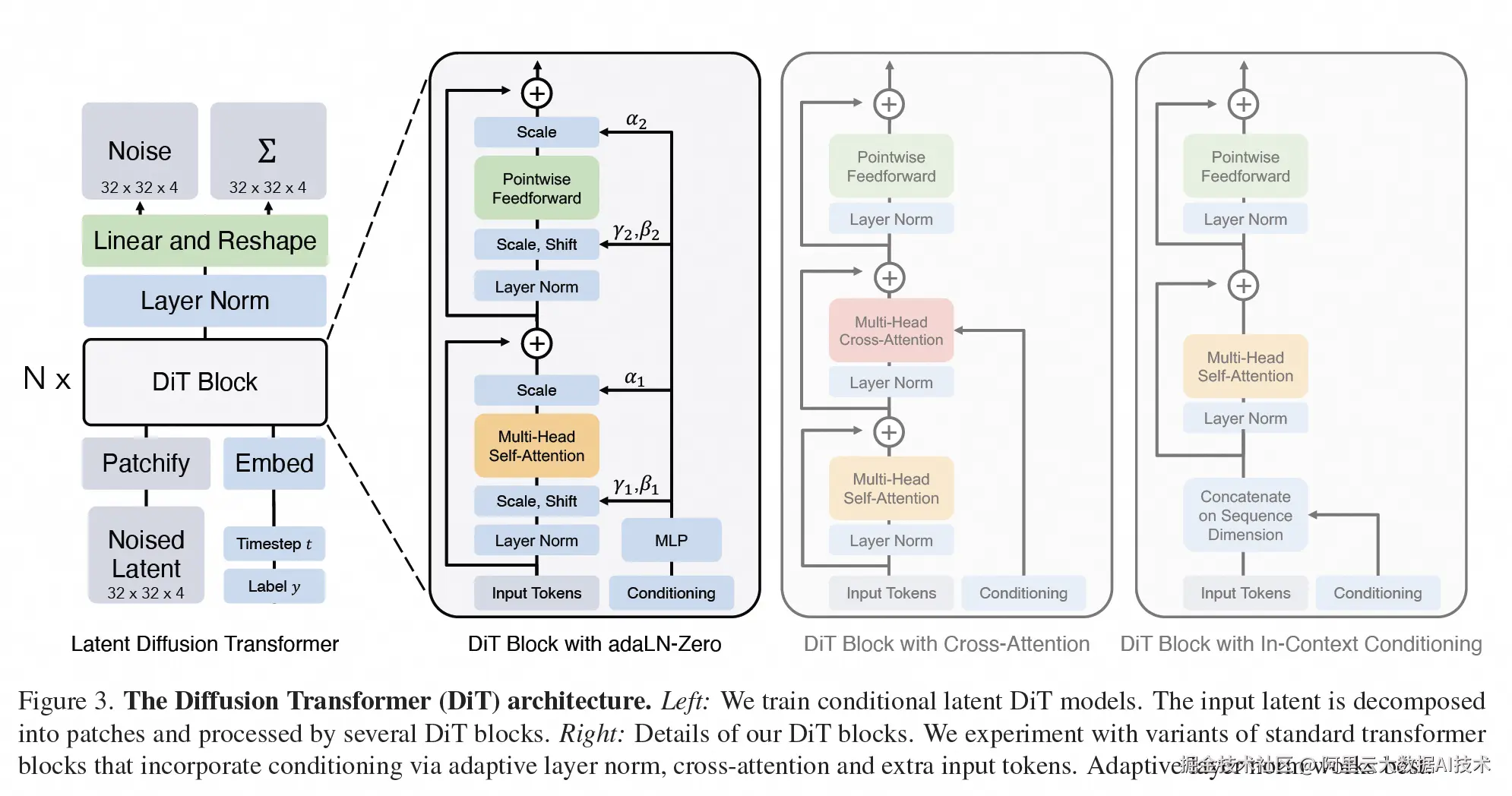
DiT模型的网络结构,来自:https://arxiv.org/abs/2212.09748
当前主流生成模型以基于 Transformer 的生成方案为主,由 VAE、Text Encoder、DiT 几个模块组成,其中 Text Encoder 由于序列长度与模型带笑的限制,计算量较小。而 VAE,尽管具有一定的计算量,但因为在生成过程中,仅负责视频与图片的编码解码,仅需要单次执行,无需像 DiT 一样执行多步,因此其计算量相比于 DiT 而言较低。而 DiT 模型,在生成模型中占有最大的参数量、输入序列较长且需要重复执行多步,因此生成模型的开销主要集中在 DiT 模型中。
从模型结构上来看,DiT 包含大量的 Self-Attention 模块、Cross-Attention 模块和 Linear 层。DiT 模型首先对输入的特征进行 Patchify 处理,使其转换为 Transformer 模型需要的 Tokens 序列输入,而后交替使用大量的 Self-Attention 进行自注意力计算,同时通过 Cross-Attention 交叉注意力进行文本信息输入等。视频生成场景通常需要关注全局信息,所以它在使用 Self-Attention 时通常不会使用 Casual Mask 来减少计算量,且由于时间维度的存在,模型序列长度通常较长,这导致视频生成模型计算量更大。因为 Self-Attention 部分的计算量会按照 Token 数平方增长,所以在视频输入的 token 数比较大时,整个模型的计算量绝大部分落在 Self-Attention 上,而不是在 Cross-Attention 模块和 Linear 层。
在显存开销方面,视频生成的显存压力依然主要集中在 DiT 上。Token 数越多显存占用越大,例如在 token 数为 1M 时,14B Wan 模型在训练时,即使使用 Flash Attention 优化,它的 Activation 显存仍然会达到 8000多 GB,在没有合适优化方法的情况下,我们难以进行 Wan 模型的训练。
PAIFuser训练推理加速框架
1、视频生成模型面临的难题
- 模型计算量巨大:高分辨率和长序列视频导致自注意力机制计算量呈平方级增长,多步去噪流程进一步增加整体延迟。视频帧之间的时空一致性要求高,传统单卡推理无法满足高清视频的实时生成需求。
- 显存占用问题突出:在视频生成任务中,随着输入序列长度的增加,模型需要处理的帧数和时空依赖关系呈倍数增长,导致显存占用迅速攀升。尤其在长序列或高帧率生成场景下,显存开销往往成为制约模型训练与推理效率的瓶颈,严重限制了模型的可扩展性和实际应用能力。
- 模型结构复杂多样:VAE、Text Encoder、DiT 等模块对硬件资源需求不同,难以高效协同。
2、PAIFuser 核心技术亮点
a、模型推理
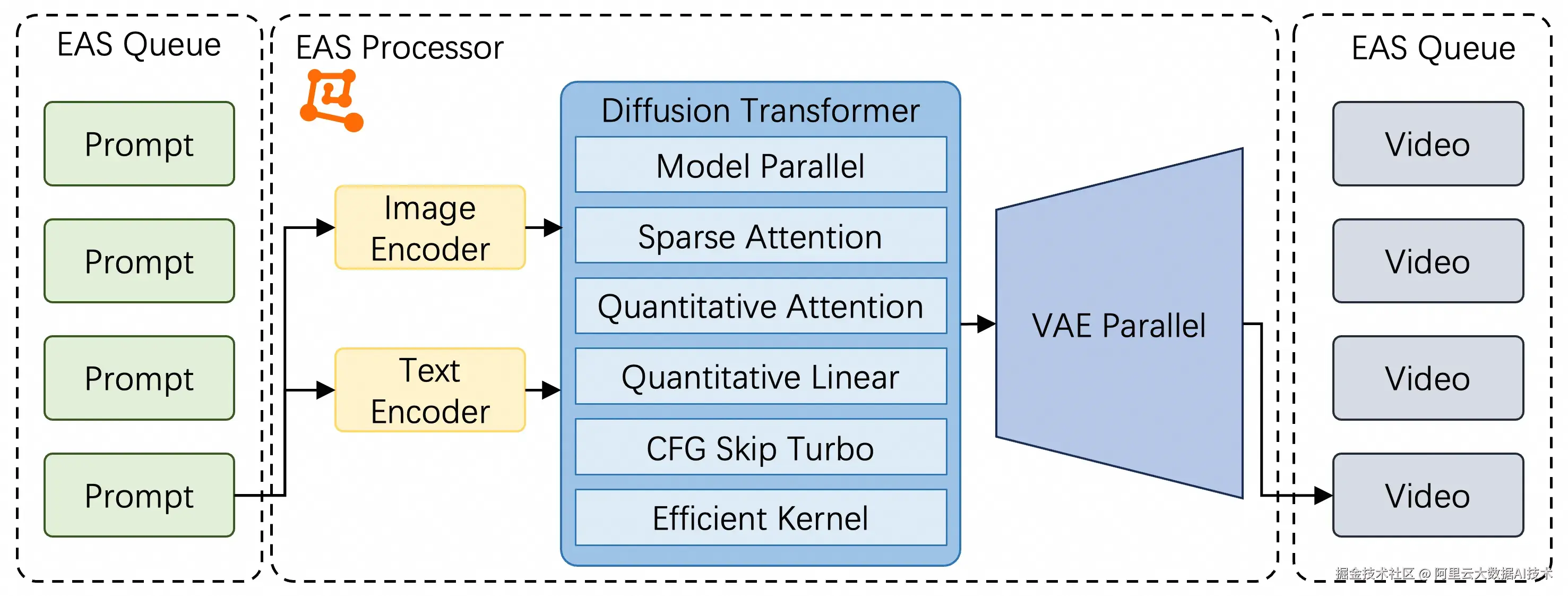 如上图所示,在视频生成推理方面 PAIFuser 通过 EAS 异步服务输入提示词与返回视频结果。PAIFuser 通过优化 DiT 与 VAE 的预测流程,从模型并行、稀疏注意力、模型量化、预测流程等多个方向针对视频生成面临的难题进行优化。
如上图所示,在视频生成推理方面 PAIFuser 通过 EAS 异步服务输入提示词与返回视频结果。PAIFuser 通过优化 DiT 与 VAE 的预测流程,从模型并行、稀疏注意力、模型量化、预测流程等多个方向针对视频生成面临的难题进行优化。
PAIFuser 在 GPU H/L20/GU108 等多种硬件平台表现优异,均展现出显著的性能优势。
- 模型并行:PAIFuser 聚焦视频生成过程中计算负载最高的 Diffusion Transformer 和 VAE 部分,分别制定了高效的并行处理方案。该策略充分发挥多卡计算能力,有效缩短推理时间,增强长序列生成的速度与稳定性,从而在高质量视频生成方面取得显著进展。
- 通信计算重叠:PAIFuser 精巧编排通信和计算 OP,通过计算掩盖序列并行通信时延,减少 GPU 时间浪费,充分释放多卡算力,多卡序列并行推理实现高效扩展。
- 量化优化:PAIFuser 深度适配视频生成模型的复杂结构,针对 Diffusion Transformer 的架构特性,在全连接层与 Attention 模块中分别引入 float8 与 int8 混合精度量化技术,有效降低计算冗余,显著提升运算效率。同时,全面支持模型并行环境下的量化部署,实现高精度与高性能的有机统一,为大规模生成任务提供高效、稳定的底层支撑。
- 稀疏运算:PAIFuser 对自注意力机制进行稀疏化,基于对数据特征的深入分析,运用特定的算法筛选出与当前计算任务最相关的关键信息,从而比避免对序列中所有元素进行全局计算,能够在处理高分辨率图像或长视频的长输入序列时显著提升速度。
- 算子优化:PAIFuser 对视频生成模型中的 RoPE,RMSNorm 和 LayerNorm 等计算密集算子进行针对性优化,在保持精度的同时实现性能提升,全面加速视频生成中的时序建模过程,大幅提升长序列建模效率。
- 预测流程优化:PAIFuser 深度融合视频生成流程,引入 CFG 优化机制,通过智能复用中间计算结果,有效跳过冗余的条件分支计算,显著降低模型运算复杂度,在保障生成质量的前提下,大幅提升推理效率与吞吐能力,实现视频生成性能的高效突破。
b、模型训练
- 模型训练并行:PAIFuser 针对 Diffusion Transformer 模块在训练时设计了高效的并行策略,充分挖掘多卡算力潜能,显著降低训练延迟与显存要求。通过并行协同优化多个显卡同时训练一个样本,提升长序列训练效率并且实现单机训练720P视频。
- 量化优化:PAIFuser 深度适配视频生成模型的复杂结构,针对 Diffusion Transformer 的架构特性,在全连接层中分别引入 float8 混合精度技术,有效降低计算冗余,显著提升运算效率。
- 显存优化:PAIFuser 采用分层的显存优化策略,根据分析选择不同的 layer 进行 offload 和 fine-grained GC 策略优化 Activation 显存,并解决显存碎片问题。
- 算子优化:PAIFuser 针对视频生成模型中的关键计算模块(包括 RoPE、RMSNorm 和 LayerNorm)进行专项优化,通过改进 RoPE 的旋转位置编码算法实现计算流程重构,在保持模型精度的前提下有效减少计算开销,显著加快时序建模速度,最终实现长序列场景下的性能突破。
- 数据预处理:在视频生成模型训练过程中,VAE 和 Text Encoder 用于对输入数据进行特征编码。对于高分辨率、长时序的视频数据,这一过程通常耗时较长。PAIFuser 支持在训练前缓存视频与文本经过 VAE 和 Text Encoder 编码后的中间特征,不仅节省显存开销,更显著提升了整体训练效率,为大规模视频生成任务提供了坚实的基础支持。
- 训练稳定性:借助于阿里云训练集群的智能化调度、慢机检测以及自愈能力,在训练启动阶段自动检测硬件问题并调度健康节点进行训练,在训练过程中,故障节点能够及时下线自愈,任务自动重启和恢复训练,达到强稳定性。
3、实测性能速度提升
a、模型推理
以开源模型 Wan2.2-T2V-A14B 为例,使用8卡生成720P视频。实验结果表明,使用 PAIFuser 相较于开源仓库,视频生成端到端耗时最多有82.96%+缩减,由564.7秒减少至96.2秒。 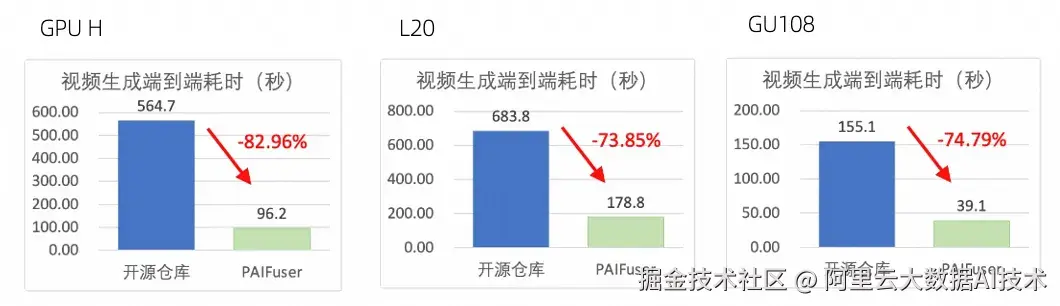
点击图片可放大查看 PAIFuser 模型推理性能实测结果
b、模型训练
以开源模型 Wan2.2-T2V-A14B 为例,训练480P 81帧的视频处理单个样本的时间。实验结果表明,使用 PAIFuser 相较于开源仓库,单个样本训练时间最多有28.13%+缩减,64.7秒减少至46.5秒。 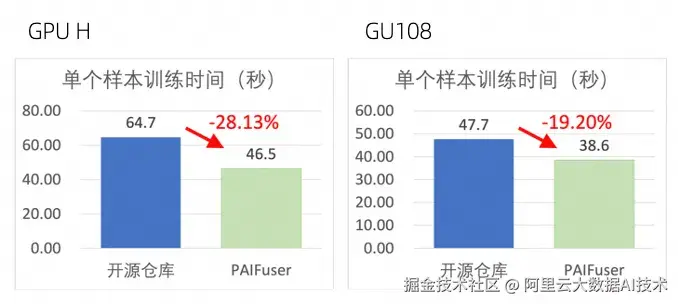
点击图片可放大查看 PAIFuser 模型训练性能实测结果
综上,PAIFuser 在模型推理和训练性能上,相较于开源仓库,均有显著提升。
使用 PAI-DSW 快速体验 PAIFuser 加速能力
基于 PAIFuser 的 Diffusion 模型训练推理加速全过程,可在阿里云人工智能平台 PAI 上完成。
交互式建模 PAI-DSW 提供云端 AI 开发 IDE 或开发机,内置多种开发环境,预置多种开源框架镜像,熟悉 Notebook/VSCode 的用户,为开发者和企业提供灵活、稳定、易用和高性能的大模型开发环境。
1、在 NoteBook Gallery 广场(gallery.pai-ml.com/)找到 PAIFuser 加速例子的 NoteBook "基于PAIFuser的Diffusion模型训练推理加速示例",或通过链接直达该教程, pai.console.aliyun.com/#/dsw-galle... 
2、在点击"在DSW中打开"的部分后,创建对应所需的实例。  3、填入实例所需的必填项后,完成实例的创建。
3、填入实例所需的必填项后,完成实例的创建。  4、创建完成后,选择对应的实例进入NoteBook。
4、创建完成后,选择对应的实例进入NoteBook。  5、进入NoteBook,按步骤进行点击。
5、进入NoteBook,按步骤进行点击。 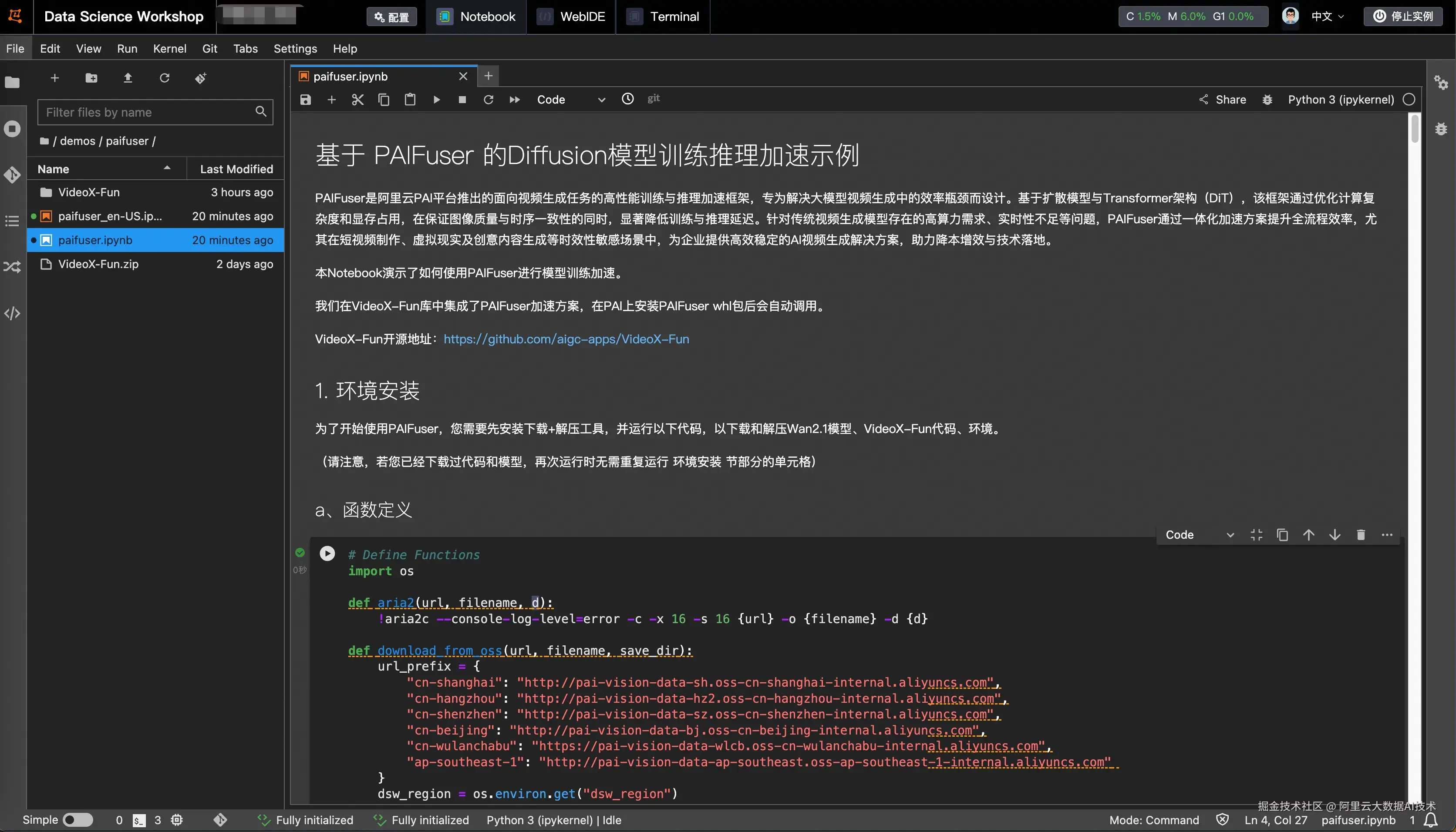
总结与展望
目前,PAIFuser 已在多个业务场景中验证了其有效性,展现出良好的性能与泛化能力。其表现出良好的兼容性,可以适配业界常见的视频生成模型。另外,长序列训练的主要瓶颈集中在 Attention 的计算效率上,而显存访问与计算开销限制了模型的扩展性。未来,我们将持续针对这些问题进行优化,进而提升 PAIFuser 在长序列场景下的训练推理效率与可扩展性。