1.

快速排序的非递归是通过栈来实现的,则前序与层次可以通过控制入栈的顺序来实现,因为递归是会一直开辟栈区空间,所以非递归的实现只需要一个栈的大小,而这个大小是小于递归所要的,
非递归与递归的时间复杂度是一样的,本质没有变化
2.

直接插入排序:是把元素从前先后一个一个插入进去,若是相同值的相对位置也不会改变,所以稳定性好
归并排序: 实现方法是分成多组,但是合并的时候还是要比较大小来合,所以相同值的相对位置也不会改变
选择排序:每次选出一个最值,若是最大值有多个会有稳定性不好的情况,但是可以控制变成稳定性好
冒泡排序:冒泡排序是每趟俩俩排序,相同值的相对位置是不会改变的
3.

选择排序:每次会选出一个最大值或者最小值,可以确定位置
快速排序:每次的基准值位置可以确定
堆排序:每次堆顶的元素是可以确定的
归并排序:是分组进行排序的,不能确定一个准确的位置
4.

题目给的序列接近有序的,插入排序在这里的时间复杂度接近为O(n),而快排在这种情况接近O(n^2),归并排序和堆排序都是O(nlogn)
5.

快速排序:初始顺序影响大,如果为有序,则性能最差
插入排序:如果初始为有序,则性能最好
希尔排序:希尔是插入排序的优化,而在有序的情况下插入反而更快
堆排序与归并排序对初始数据的顺序不怎么影响
6.

从题目来看25,21,47,68这些数字位置被确定了,而选择排序确定的最值,所以是希尔排序,
第一次的基准值为25,左边都比25小,右边都比25大,第二次的基准值为20,47(因为第一行的左边与右边的数字是21与47),则第三次的基准值就为15,21,35,68
7.

这里的辅助空间就是空间复杂度为多少,快速排序递归过程中会开辟栈的空间,递归的深度为二叉树的深度为logn,而非递归实现是通过栈来实现 ,最大空间也就是把从头到叶结点,因为每次是成对放入栈里面,所以最大为数的高度俩倍,2*logn
所以空间复杂度就为logn
8.

快速排序会确定基准值的位置 ,所以找满足基准值,因为第二趟所以需要找到俩个基准值,若没有俩个则就不可能为快速排序的第二趟,
a:第一趟可以为2,第二趟可以为3,满足情况
b:第一趟可以为2,第二趟可以为9
c:第一趟基准值只能是9(基准值的位置跟排序好的位置是一样的),则第二趟没有基准值了
d:第一趟可以为9,第二趟可以为5
9.

归并排序需要用到格外辅助空间,要开辟一个跟原数据一样大的空间
归并排序是一种二分排序算法,每次给n个元素排序(理想),排序的过程中深度为logn,所以时间复杂度为nlongn
因为操作是在左右子树排完序之后,进行合并,合并是在遍历完左右子树的情况下,所以就是左右根,所以是后序、
归并排序相同值的相对位置不会改变,稳定性好
10.
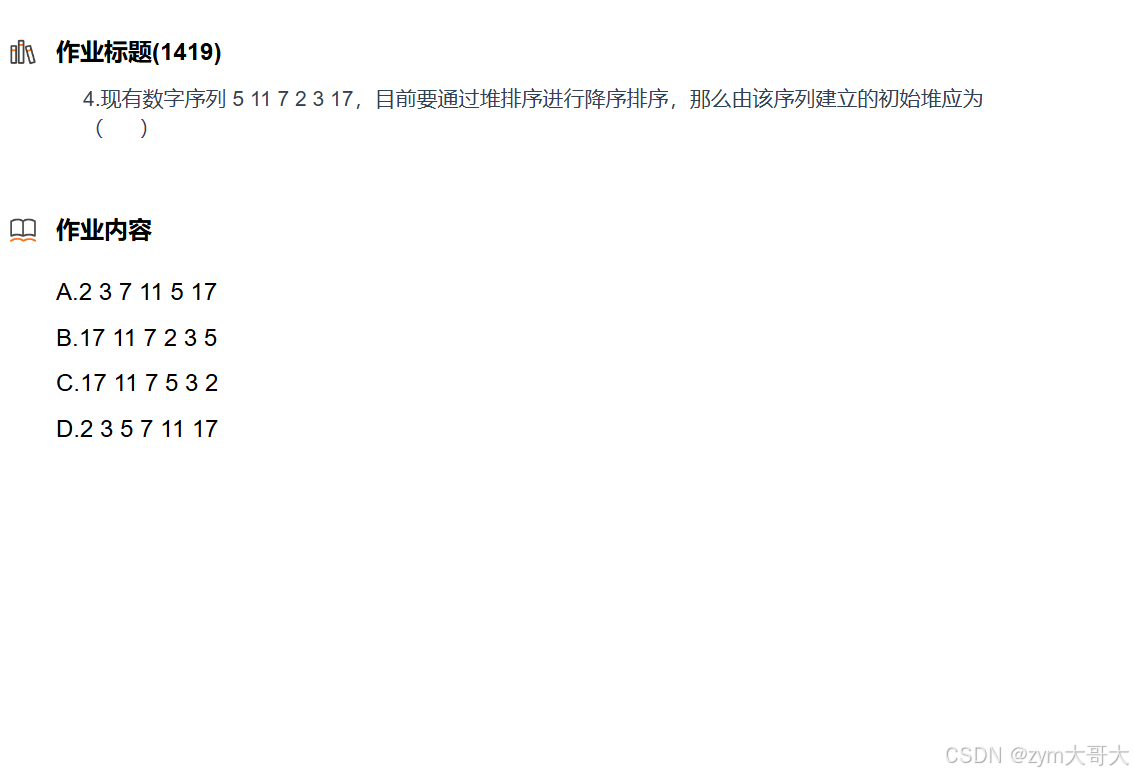
因为要通过堆排序来进行降序,所以要建小堆,而满足情况只用a为小堆