1. zookeeper
是的,Zookeeper 和 Kafka 经常一起使用,Zookeeper 在 Kafka 中扮演了关键角色。以下是 Zookeeper 和 Kafka 在实际项目中的结合使用及其作用的详细说明。
项目背景
假设我们有一个分布式数据处理系统,该系统需要高吞吐量的实时消息处理能力。Kafka 被选作消息队列系统,用于接收、存储和传输大量实时数据。Zookeeper 被用作集群管理工具,以确保 Kafka 集群的高可用性和一致性。
Kafka 与 Zookeeper 的结合
1. Kafka Broker 管理
Kafka 使用 Zookeeper 来管理 Kafka brokers(代理)。Zookeeper 维护了所有 broker 的元数据和状态信息,确保每个 broker 都可以发现和通信其他 brokers。
- Broker 注册:当一个 Kafka broker 启动时,它会向 Zookeeper 注册自己,这样其他 brokers 可以知道集群中的所有成员。
- Leader 选举:Kafka 分区的 leader 选举是通过 Zookeeper 来完成的。每个分区有一个 leader 和多个 follower,leader 负责所有读写操作,而 followers 复制 leader 的数据。
2. Topic 和 Partition 管理
Zookeeper 维护 Kafka 集群中所有 topic 和分区的元数据,包括分区的位置、replicas 和 leader 信息。
- Topic 配置:创建一个 topic 时,Kafka 会将其配置信息(如分区数、副本数)存储在 Zookeeper 中。
- 分区信息:每个分区的 leader 和 followers 信息也存储在 Zookeeper 中,确保集群的元数据一致性。
3. 消费者组协调
Zookeeper 协调 Kafka 消费者组,确保每个消费者实例在集群中唯一且不重复地消费消息。
- 消费者注册:消费者启动时会向 Zookeeper 注册自己,并通过 Zookeeper 获取分配给它的分区。
- 分区再均衡:当消费者实例加入或离开时,Zookeeper 负责触发分区再均衡,确保分区分配在消费者组中保持均衡。
实际项目示例
项目描述
假设我们有一个实时日志处理系统,该系统收集来自多个应用程序的日志数据,进行实时处理和分析。
使用 Kafka 和 Zookeeper
-
数据收集和传输:
- 应用程序将日志数据发送到 Kafka topic。每个应用程序对应一个或多个 Kafka topics。
-
消息队列管理:
- Kafka 集群由多个 brokers 组成,Zookeeper 管理这些 brokers 的元数据和状态,确保集群的高可用性。
- Zookeeper 协助 Kafka 进行分区 leader 选举,确保每个分区都有一个 leader 负责处理读写请求。
-
实时处理:
- 一个 Kafka 消费者组(如 Spark Streaming、Flink 或自定义的消费者应用)从 Kafka topics 中消费日志数据进行实时处理。
- Zookeeper 协调消费者组中的消费者,确保每个分区的数据都被唯一的消费者处理。
-
故障恢复:
- 如果一个 Kafka broker 崩溃,Zookeeper 协助进行 leader 选举,将分区的 leader 转移到其他可用的 brokers。
- 消费者实例崩溃时,Zookeeper 触发分区再均衡,将分区重新分配给其他消费者实例,确保系统继续稳定运行。
结论
Zookeeper 在 Kafka 集群中起到了关键的协调和管理作用,确保了 Kafka 的高可用性和一致性。在实际项目中,Kafka 和 Zookeeper 的结合使用能够处理大量实时数据,提供可靠的消息传输和处理能力。这种架构在大数据、日志处理、实时分析等领域广泛应用,能够满足高吞吐量和低延迟的需求。
zookeeper headless
在yaml文件中 clusterIP: None 代表它是headless svc
10.96.0.10 是k8s 集群内的 dns 解析
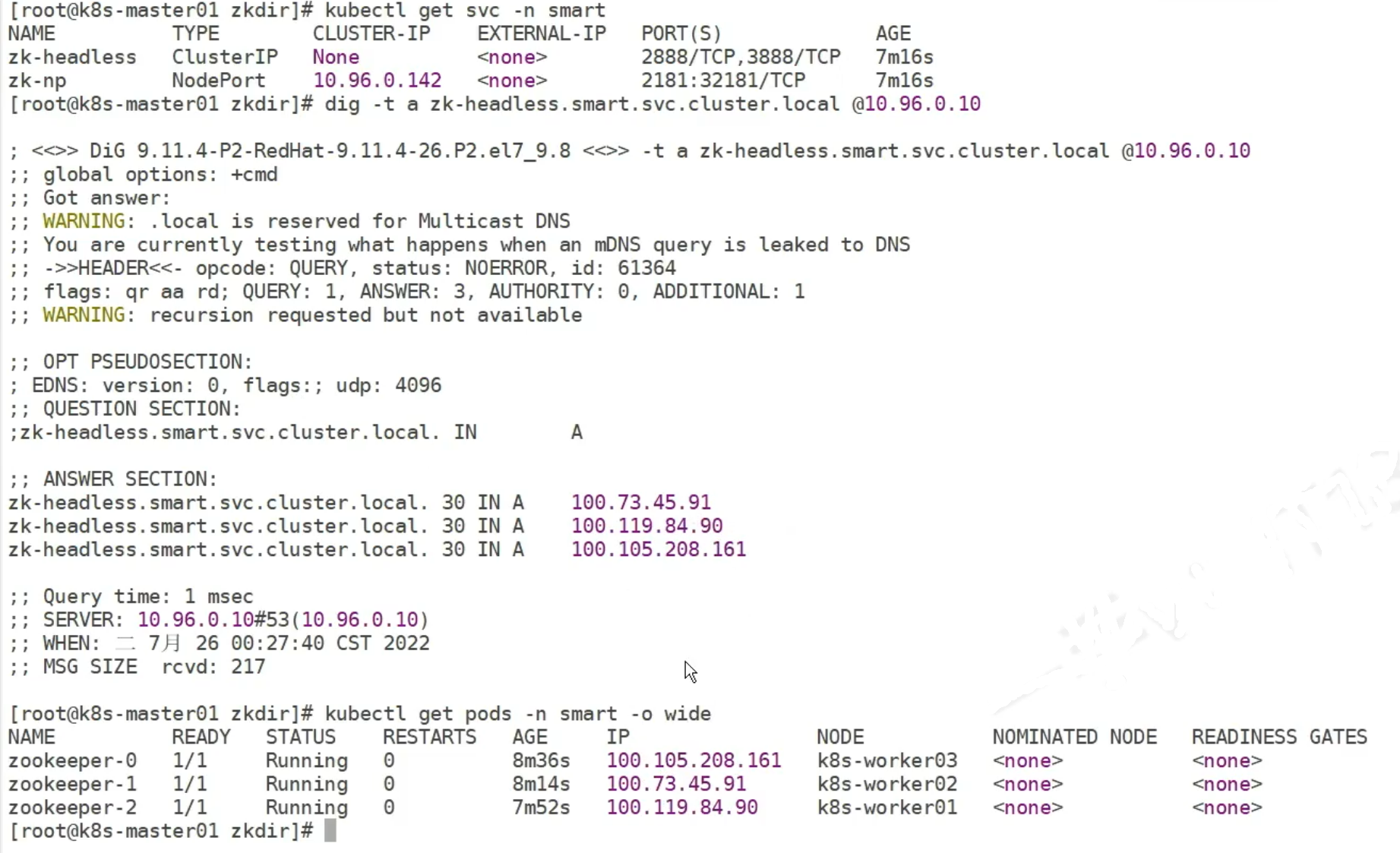
应用验证
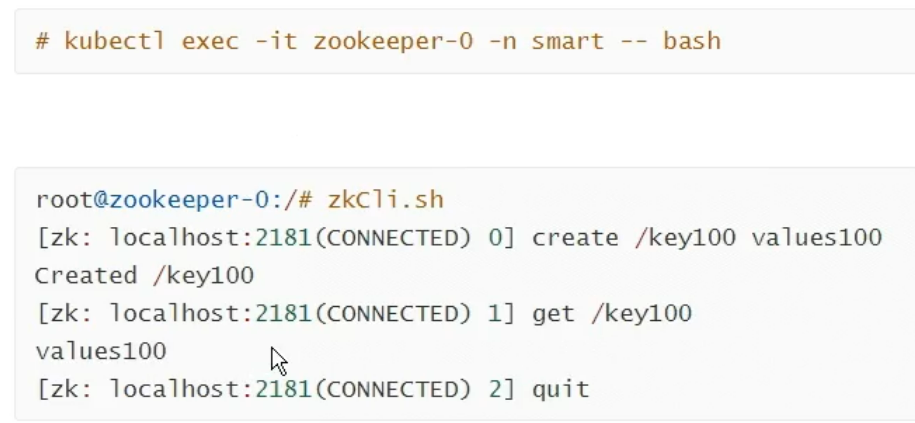
可以获得键值说明zookeeper正常,这是在集群内访问
下面是安装客户端,从外面通过port 访问zookeeper
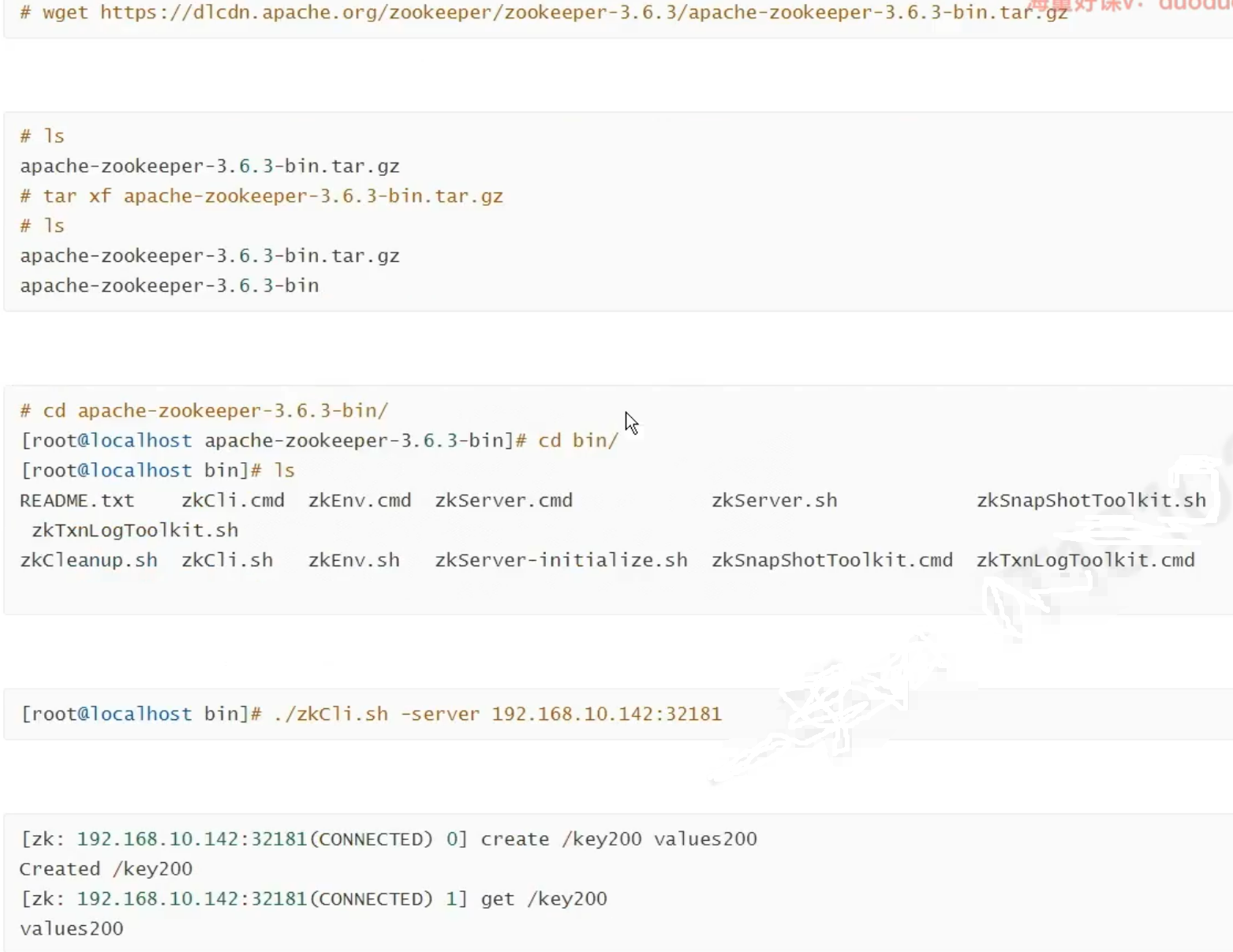
zookeeper的存储可以接nfs
2. kafka
kafka 生产者将数据写入到分区主题, 这些主题通过可配置的副本存储到broker集群上。消费者消费存储在broker 分区生成的数据
示例项目说明
假设你有一个在线零售网站,你希望使用Kafka来处理用户订单数据。以下是如何使用Broker、Topic和分区来实现这一需求的示例:
1. 创建Kafka集群
你创建了一个Kafka集群,包含3个Broker(Broker 0, Broker 1, Broker 2)。
2. 创建Topic
你创建了一个名为orders的Topic,用于存储用户订单数据。为了提高系统的性能和可靠性,你决定将这个Topic分成3个分区,并设置副本因子为2。
bash
kafka-topics.sh --create --topic orders --partitions 3 --replication-factor 2 --zookeeper localhost:21813. 分区和副本分布
Kafka会自动在Broker之间分配分区和副本。例如:
- 分区 0 可能分布在Broker 0和Broker 1上,其中Broker 0是Leader,Broker 1是Follower。
- 分区 1 可能分布在Broker 1和Broker 2上,其中Broker 1是Leader,Broker 2是Follower。
- 分区 2 可能分布在Broker 2和Broker 0上,其中Broker 2是Leader,Broker 0是Follower。
4. 数据生产和消费
- 生产者(Producer): 你的订单服务会将每个订单消息发送到
ordersTopic。Kafka根据某种分区策略(如订单ID的哈希值)将消息分配到不同的分区。 - 消费者(Consumer): 你的订单处理服务会从
ordersTopic中消费消息。消费者可以并行地从不同的分区读取数据,从而提高处理速度。
数据流示例
- 用户A在网站上下单,订单数据被发送到
ordersTopic,Kafka将其放入分区0。 - 用户B在网站上下单,订单数据被发送到
ordersTopic,Kafka将其放入分区1。 - 用户C在网站上下单,订单数据被发送到
ordersTopic,Kafka将其放入分区2。
优点
- 高可用性和容错性: 如果一个Broker宕机,Kafka可以自动切换到其他Broker上的副本,保证数据的可用性。
- 高吞吐量: 多个分区使得生产者和消费者可以并行工作,提高了系统的处理能力。
- 可扩展性: 你可以通过增加分区数和Broker数量来扩展Kafka集群的容量和性能。
kafka高可用集群部署
可以使用helm,或者和zookeeper一起部署,还可以自己的yaml
也可以使用storageclass来持久化存储
在k8s内部验证Kafka的使用test,生产环境不这样用kafka
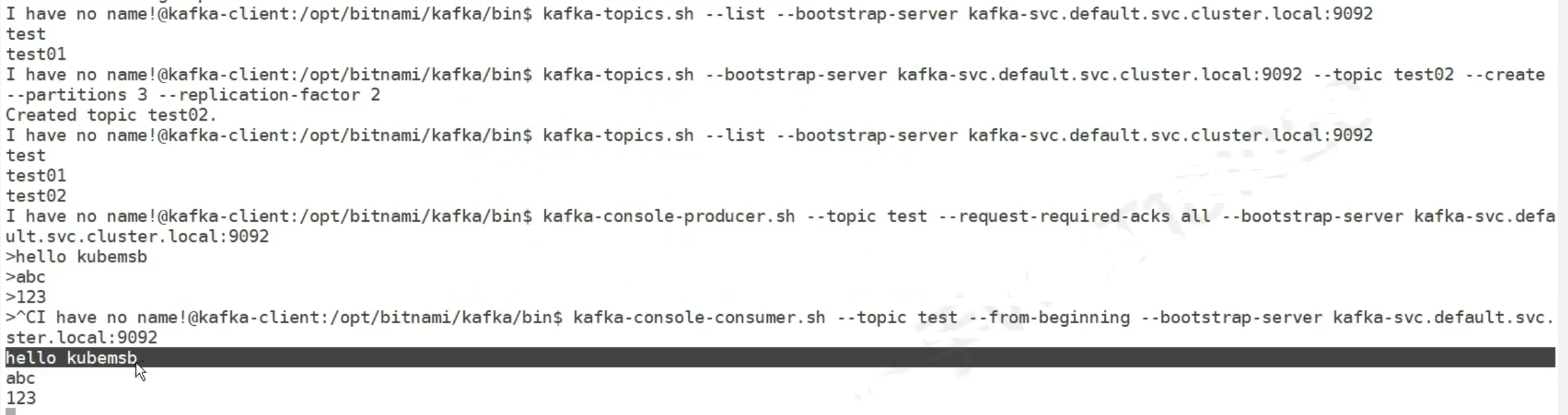
创建一个pod客户端

进入后,如果没有topic,创建topic,然后生产,消费

这个topic名字是test01 topic被分成3个分区,分区使Kafka能够并行处理数据,因为不同的消费者可以消费不同的分区。
副本 2个代表每个分区的数据会被复制到两个不同的 Broker上。
副本是分区的一个副本,存储在不同的Broker上。
Kafka使用主副本(Leader)和从副本(Follower)来管理数据复制。
Leader负责所有读写请求,而Follower被动地复制Leader的数据。
如果Leader宕机,Kafka会自动选举一个新的Leader,从而保证数据的高可用性。
Broker 是实际存储和管理数据的服务器节点。
Topic 是消息的分类和逻辑分组。
分区 是Topic的子集,每个分区是一个独立的、有序的消息日志,使Kafka能够并行处理和分发消息。


3.rokectmq
分布式消息传递,万亿级别
几种模式
Apache RocketMQ 是一个分布式消息队列系统,具有高性能、高可靠性、低延迟和高可扩展性的特点。它支持多种消息模式,以满足不同的业务需求。以下是 RocketMQ 支持的主要消息模式:
1. 单向消息(One-way Messaging)
在单向消息模式下,生产者只负责发送消息到消息队列,不需要等待消息的响应。此模式通常用于不需要确认的日志收集、监控数据等场景。
java
producer.sendOneway(message);2. 同步消息(Synchronous Messaging)
同步消息模式是指生产者发送消息并等待消息服务器返回发送结果。此模式通常用于对可靠性要求较高的场景,如重要通知、短信发送等。
java
SendResult sendResult = producer.send(message);3. 异步消息(Asynchronous Messaging)
异步消息模式是指生产者发送消息后,不需要等待消息服务器的响应,而是通过回调函数来处理发送结果。此模式适用于对响应时间有较高要求的场景,如异步处理任务等。
java
producer.send(message, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
// 处理成功的逻辑
}
@Override
public void onException(Throwable e) {
// 处理异常的逻辑
}
});4. 顺序消息(Ordered Messaging)
顺序消息模式是指确保消息按照发送顺序被消费。RocketMQ 支持全局顺序消息和分区顺序消息:
- 全局顺序消息:所有消息按照发送顺序被消费。
- 分区顺序消息:根据某个消息字段(如订单ID)进行分区,确保同一分区内的消息按照顺序被消费。
java
SendResult sendResult = producer.send(message, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
Long id = (Long) arg;
long index = id % mqs.size();
return mqs.get((int) index);
}
}, orderId);5. 延时消息(Scheduled Messaging)
延时消息模式允许消息在指定时间后再进行消费。RocketMQ 提供了一些固定的延时级别(如1秒、5秒、10秒等),生产者可以选择合适的延时级别来发送消息。
java
message.setDelayTimeLevel(3); // 延时10秒
SendResult sendResult = producer.send(message);6. 批量消息(Batch Messaging)
批量消息模式是指将多个消息合并成一个批量发送,从而提高发送效率。此模式适用于消息量较大且对实时性要求不高的场景。
java
List<Message> messages = new ArrayList<>();
messages.add(new Message("TopicTest", "TagA", "OrderID001", "Hello world 0".getBytes()));
messages.add(new Message("TopicTest", "TagA", "OrderID002", "Hello world 1".getBytes()));
SendResult sendResult = producer.send(messages);7. 过滤消息(Filtered Messaging)
过滤消息模式是指消费者可以通过SQL92标准的条件表达式过滤消息。RocketMQ 提供了两种过滤方式:标签过滤和SQL过滤。
- 标签过滤:生产者在发送消息时指定标签,消费者订阅消息时按标签进行过滤。
java
Message message = new Message("TopicTest", "TagA", "OrderID001", "Hello world".getBytes());
SendResult sendResult = producer.send(message);- SQL过滤:生产者在发送消息时附加属性,消费者通过SQL表达式过滤消息。
java
message.putUserProperty("a", "10");
consumer.subscribe("TopicTest", MessageSelector.bySql("a > 5"));8. 事务消息(Transactional Messaging)
事务消息模式是指生产者在发送消息的同时执行本地事务,根据本地事务的执行结果决定消息是否提交或回滚。此模式适用于金融支付等对数据一致性要求较高的场景。
java
TransactionSendResult sendResult = producer.sendMessageInTransaction(message, localTransactionExecutor);总结
RocketMQ 提供了多种消息模式,涵盖了从简单的单向消息到复杂的事务消息等多种使用场景。根据业务需求选择合适的消息模式,可以更好地利用 RocketMQ 提供的高性能、高可靠性和灵活性。