5.1 for和range
循环是所有编程语言都有的控制结构,除了使用经典的"三段式"循环之外,Go语言还引入了另一个关键字range帮助我们快速遍历数组、切片、哈希表以及Channel等集合类型。本节将深入分析Go语言的两种不同循环,也就是经典的for循环和for/range循环,我们会分析这两种循环的运行时结构以及它们的实现原理。
for循环能够将代码中的数据和逻辑分离,让同一份代码能够多次复用处理同样的逻辑。我们先来看一下Go语言for循环对应的汇编代码,下面是一段经典的三段式循环的代码,我们将它编译成汇编指令:
go
package main
func main() {
for i := 0; i < 10; i++ {
println(i)
}
}它的汇编如下:
go
// "".main表示函数名
// STEXT表示这是一个文本段,用于代码
// size=98表示代码段大小为98字节
// args=0x0表示参数大小为0字节
// locals=0x18表示局部变量大小为0x18字节
"".main STEXT size=98 args=0x0 locals=0x18
// TEXT命令定义了函数,$24-0表示在栈上预留了24字节空间
0000 (main.go:3) TEXT "".main(SB), $24-0
....
// 将寄存器AX与自身异或,表示清零
0029 (main.go:3) XORL AX, AX ;; i := 0
// 无条件跳转代码到75处
0031 (main.go:4) JMP 75
// 将寄存器AX中存放的i的值移动到栈顶偏移8字节的位置
0033 (main.go:4) MOVQ AX, "".i+8(SP)
// 调用runtime.printlock,在打印前获取一个全局的打印锁
0038 (main.go:5) CALL runtime.printlock(SB)
// 将栈顶偏移8字节位置的值移动到寄存器AX中
0043 (main.go:5) MOVQ "".i+8(SP), AX
// 将寄存器AX中的变量i的值移动到栈顶,准备作为参数传递给runtime.printint函数
0048 (main.go:5) MOVQ AX, (SP)
// 调用runtime.printint,打印栈顶的整数
0052 (main.go:5) CALL runtime.printint(SB)
// 调用runtime.printnl,打印一个换行符
0057 (main.go:5) CALL runtime.printnl(SB)
// 调用runtime.printunlock,释放打印锁
0062 (main.go:5) CALL runtime.printunlock(SB)
// 将栈顶偏移8字节位置的变量i的值移动到寄存器AX中
0067 (main.go:4) MOVQ "".i+8(SP), AX
// 自增寄存器AX中存放的变量i的值
0072 (main.go:4) INCQ AX ;; i++
// 将寄存器AX中存放的递增后的变量i的值与立即数10做比较
0075 (main.go:4) CMPQ AX, $10 ;; 比较变量i和10
// 如果寄存器AX中存放的递增后的变量i的值小于10,则跳转回33处,即循环的开始
0079 (main.go:4) JLT 33 ;; 如果i<10,跳转到33行
.... 我们将上述汇编指令的执行过程分成三个部分进行分析:
1.0029~0031行负责循环的初始化,对寄存器AX中的变量i进行初始化并执行JMP 75指令跳转到0075行;
2.0075~0079行负责检查循环的终止条件,将寄存器中存储的数据i与10比较:
(1)JLT 33命令会在变量小于10时跳转到0033行执行循环主体;
(2)JLT 33命令会在变量的值大于等于10时跳出循环体执行下面的代码;
3.0033~0072行时循环内部的语句:
(1)通过多个汇编指令打印变量中的内容;
(2)INCQ AX指令会将变量加一,然后再与10进行比较(第二步的过程);
for/range循环经过优化的汇编代码有着完全相同的结构。无论是变量的初始化、循环体的执行、最后的条件判断都是完全一样的,所以这里也就不展开分析对应的汇编指令了。
go
package main
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
println(i)
}
}在汇编语言中,无论是经典的for循环还是for/range循环都会使用JMP以及相关的命令跳回循环体的开始位置来多次执行代码的逻辑。从不同循环具有相同的汇编代码可以猜到,使用for/range的控制结构最终也会被Go语言编译器转换成普通的for循环,后面的分析会印证这一点。
5.1.1 现象
在深入语言的源代码中了解两种不同循环的实现之前,我们可以先来看一下使用for和range会遇到的一些现象和问题,我们可以带着这些现象和问题去源代码中寻找答案,这样能更高效地理解实现。
循环永动机
如果我们在遍历数组的同时修改数组的元素,能否得到一个永远都不会停止的循环呢?你可以自己尝试运行下面的代码来得到结果:
go
func main() {
arr := []int{1, 2, 3}
for _, v := range arr {
arr = append(arr, v)
}
fmt.Println(arr)
}运行它:
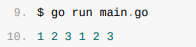
上述代码的输出意味着循环只遍历了原始切片中的三个元素,我们在遍历切片时追加的元素不会增加循环的执行次数,所以循环最终还是停了下来。
神奇的指针
第二个例子是使用Go语言经常会犯的错误。当我们遍历一个数组时,如果获取range返回变量的地址并保存到另一个数组或者哈希时,就会遇到令人困惑的现象:
go
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
newArr = append(newArr, &v)
}
for _, v := range newArr {
fmt.Println(*v)
}
}运行它:
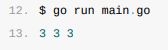
上述代码最终会输出三个连续的3,这个问题比较常见,一些有经验的开发者不经意也会犯这种错误,正确的做法应该是使用&arr[i]替代&v,我们会在下面分析这一现象背后的原因。
对于以上问题,我在go1.22.1版本运行的结果是1 2 3,可能是编译器或环境差异。
遍历清空数组
当我们想要在Go语言中清空一个切片或者哈希表时,我们一般会使用以下方法将切片中的元素置零,但是依次去遍历切片和哈希表看起来是非常耗费性能的事情:
go
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
arr[i] = 0
}
}因为数组、切片、哈希表占用的内存空间都是连续的,所以最快的方法是直接清空这片内存中的内容,当我们编译上述代码时会得到以下汇编指令:
go
"".main STEXT size=93 args=0x0 locals=0x30
// $48-0表示栈帧有48字节用于局部变量,无参数传递
0x0000 00000 (main.go:3) TEXT "".main(SB), $48-0
...
// 将栈基址指针处的静态临时变量的值移动到寄存器AX
0x001d 00029 (main.go:4) MOVQ "".statictmp_0(SB), AX
// 将寄存器AX中的值移动到栈指针偏移16字节的位置,该位置是一个局部临时自动变量autotmp_3
0x0024 00036 (main.go:4) MOVQ AX, ""..autotmp_3+16(SP)
// 将栈基址指针处的静态临时变量statictmp_0移动到寄存器X0中
// MOVUPS指令用于移动浮点数
0x0029 00041 (main.go:4) MOVUPS "".statictmp_0+8(SB), X0
// 将寄存器X0中的浮点值移动到栈顶偏移24字节的位置
0x0030 00048 (main.go:4) MOVUPS X0, ""..autotmp_3+24(SP)
// PCDATA是与垃圾回收和堆栈跟踪相关的伪指令,它不会被转换为任何机器码
// 此指令告诉编译器要跟踪指针状态,开始考虑指针相关的操作
0x0035 00053 (main.go:5) PCDATA $2, $1
// 将栈顶偏移16字节位置的临时变量autotmp_3的地址加载到寄存器AX中
0x0035 00053 (main.go:5) LEAQ ""..autotmp_3+16(SP), AX
// 从此处开始指针相关操作已完成
0x003a 00058 (main.go:5) PCDATA $2, $0
// 将寄存器AX中的值移动到栈顶
0x003a 00058 (main.go:5) MOVQ AX, (SP)
// 将立即数24移动到栈顶偏移8字节的位置,这条指令和上一条指令一起,为接下来的函数调用提供参数
0X003e 00062 (main.go:5) MOVQ $24, 8(SP)
// 调用runtime.memclrNoHeapPointers清零没有指向堆内存的内存块
0x0047 00071 (main.go:5) CALL runtime.memclrNoHeapPointers(SB)从生成的汇编代码我们可以看出,编译器会直接使用runtime.memclrNoHeapPointers清空切片中的数据,这也是我们在下面的小节会介绍的内容。
随机遍历
当我们在Go语言中使用range遍历哈希表时,往往都会使用如下的代码结构,但是这段代码在每次运行时都会打印出不同的结果:
go
func main() {
hash := map[string]int{
"1": 1,
"2": 2,
"3": 3,
}
for k, v := range hash {
println(k, v)
}
}两次运行上述代码可能会得到不同的结果,第一次会打印2 3 1,第二次会打印1 2 3,如果我们运行的次数足够多,最后会得到几种不同的遍历顺序。
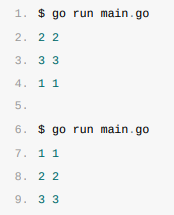
这时Go语言故意的设计,它在运行时为哈希表的遍历引入不确定性,也是告诉所有Go语言使用者,程序不要依赖于哈希表的稳定遍历,我们在下面的小节会介绍在遍历的过程是如何引入不确定性的。
5.1.2 经典循环
Go语言中的经典循环在编译器看来是一个OFOR类型的节点,这个节点由以下四个部分组成:
1.初始化循环的Ninit;
2.循环的终止条件Left;
3.循环体结束时执行的Right;
4.循环体NBody;
go
for Nint; Left; Right {
NBody
}在生成SSA中间代码的阶段,cmd/compile/internal/gc.stmt方法在发现传入的节点类型是OFOR时就会执行以下代码块,这段代码会将循环的代码分成不同的块:
go
func (s *state) stmt(n *Node) {
switch n.Op {
case OFOR, OFORUNTIL:
// 初始化四个控制块,分别是条件块bCond、循环体块bBody、增量块bIncr、结束块bEnd
bCond, bBody, bIncr, bEnd := ...
// 结束当前块
b := s.endBlock()
// 控制流连接到下一个块(条件块)
b.AddEdgeTo(bCond)
// 开始条件块
s.startBlock(bCond)
// 根据条件块n.Left创建一个条件分支到循环体块bBody或结束块bEnd
s.condBranch(n.Left, bBody, bEnd, 1)
// 开始循环体块
s.startBlock(bBody)
// 处理循环体内的所有语句
s.stmtList(n.Nbody)
// 控制流连接到下一个块(增量块)
b.AddEdgeTo(bIncr)
// 开始处理增量块
s.startBlock(bIncr)
// 处理增量语句
s.stmt(n.Right)
// 控制流连接到下一个块(条件块)
b.AddEdgeTo(bCond)
// 开吃处理结束块
s.startBlock(bEnd)
}
}一个常见的for循环代码会被cmd/compile/internal/gc.stmt方法转换成下面的控制结构,该结构中包含了4个不同的块,这些代码块之间的连接就表示汇编语言中的跳转关系,与我们理解的for循环控制结构其实没有太多的差别。
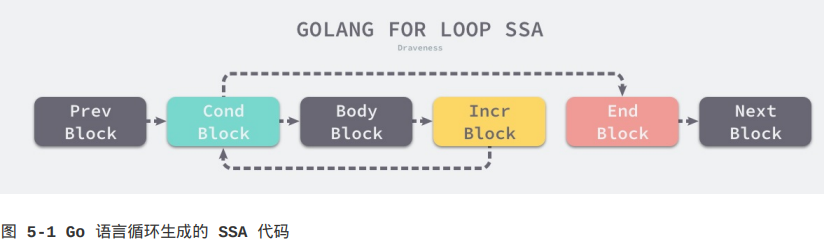
机器码生成阶段会将这些代码块转换成机器码,以及指定CPU架构上运行的机器语言,就是我们在前面编译得到的汇编指令(作者的这句话有问题,汇编指令并不是机器语言,汇编指令会经过汇编编程机器码,机器码才是在CPU上运行的)。
5.1.3 范围循环
与简单的经典循环相比,范围循环在Go语言中更常见、实现也更复杂。这种循环同时使用for和range两个关键字,编译器会在编译期间将所有for/range循环变成经典循环。从编译器的视角来看,就是将ORANGE类型的节点转换成OFOR节点:
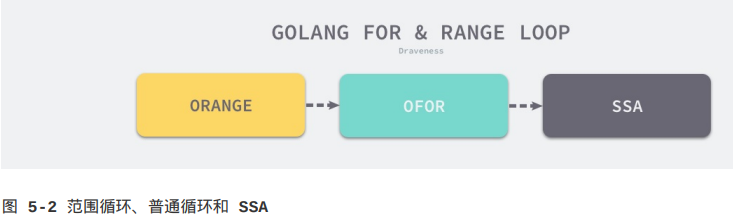
节点类型的转换都发生在SSA中间代码生成阶段,所有的for/range循环都会被cmd/compile/internal/gc.walkrange函数转换成不包含复杂结构、只包含基本表达式的语句。接下来,我们按照循环遍历的元素类型依次介绍遍历数组和切片、哈希表、字符串、管道时的过程。
数组和切片
对于数组和切片来说,Go语言有三种不同的遍历方式,这三种不同的遍历方式分别对应着代码中的不同条件,它们会在cmd/compile/internal/gc.walkrange函数中转换成不同的控制逻辑,我们将该函数的相关逻辑分成几个部分进行分析:
1.分析遍历数组和切片清零元素的情况;
2.分析使用for range a {}遍历数组和切片,不关心索引和数据的情况;
3.分析使用for i := range a {}遍历数组和切片,只关心索引的情况;
4.分析使用for i, elem := range a{}遍历数组和切片,关心索引和数据的情况;
go
func walkrange(n *Node) *Node {
switch t.Etype {
case TARRAY, TSLICE:
if arrayClear(n, v1, v2, a) {
return n
}cmd/compile/internal/gc.arrayClear是一个非常有趣的优化,这个函数会优化Go语言遍历数组或者切片并清零全部元素的逻辑:
go
// original
for i := range a {
a[i] = zero
}
// optimized
if len(a) != 0 {
hp = &a[0]
hn = len(a)*sizeof(elem(a))
memclrNoHeapPointers(hp, hn)
i = len(a) - 1
}相比于依次清除数组或者切片中的数据,Go语言会直接使用runtime.memclrNoHeapPointers或者runtime.memclrHasPointers函数直接清除目标数组对应内存空间中的数据,并在执行完成后更新用于遍历数组的索引,这也印证了我们在遍历清空数组一节中观察到的现象。
处理了这种特殊的情况后,我们就可以继续回到ORANGE节点的处理过程了。这里会设置for循环的Left和Right字段,也就是终止条件和循环体每次执行结束后运行的代码:
go
ha := a
// 创建两个int型临时变量hv1和hn
hv1 := temp(types.Types[TINT])
hn := temp(types.Types[TINT])
// 向init列表里添加两个节点
// OAS表示赋值操作,第一行将hv1赋值为nil,第二行将hn赋值为ha的长度
init = append(init, nod(OAS, hv1, nil))
init = append(init, nod(OAS, hn, nod(OLEN, ha, nil)))
// 设置节点n的左节点,OLT表示小于操作,因此左子节点为hv1小于hn的比较操作
n.Left = nod(OLT, hv1, hn)
// 设置节点n的右节点,该节点是一个赋值节点,表示将hv1加1后的值赋值给自身(hv1)
n.Right = nod(OAS, hv1, nod(OADD, hv1, nodintconst(1)))
// 如果原始循环既不关心数组的索引,也不关心数据
if v1 == nil {
break
}如果原始的循环是for range a {},那么就满足v1 == nil的条件,即循环不关心数组的索引和数据,它会被编译器转换成如下所示的代码:
go
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
// ...
}这是ORANGE结构在编译期间被转换的最简单形式,由于原始代码不需要获取数组的索引和元素,只需要使用数组或者切片的数量执行对应次数的循环,所以会生成一个最简单的for循环。
如果我们在遍历数组时需要使用索引for i := range a {},那么编译器会继续执行下面的代码:
go
// 如果只关心数组使用的索引
if v2 == nil {
// 初始化body为Node*切片,其中包含一个元素,将v1赋值给hv1,表示将索引hv1赋值给循环变量v1
body = []*Node{nod(OAS, v1, hv1)}
break
}v2 == nil意味着调用方不关心数组的元素,只关心遍历数组使用的索引。它会将for i := range a {}转换成如下所示的逻辑,与第一种循环相比,这种循环在循环体中添加了v1 := hv1语句,传递遍历数组时的索引:
go
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
v1 := hv1
// ...
}上面的两种情况虽然也是使用range经常遇到的情况,但是同时去遍历索引和元素也很常见。处理这种情况会使用下面这段代码:
go
// OINDEX表示索引操作,ha是被索引的切片或数组,hv1是索引
tmp := nod(OINDEX, ha, hv1)
// 为tmp节点设置有界属性,这意味着编译器已验证索引是安全的,即不会越界
// 有助于优化生成的代码,比如省略运行时的越界检查
tmp.SetBounded(true)
// 创建节点a,OAS2表示多个赋值操作
a := nod(OAS2, nil, nil)
// 设置v1、v2为赋值操作的目标变量,v1为索引,v2为值
a.List.Set2(v1, v2)
// 设置赋值操作的来源列表,即hv1和tmp(即ha[hv1])分别被赋值给v1和v2
a.Rlist.Set2(hv1, tmp)
// 初始化body为Node*切片,其中只包含一个元素a
body = []*Node{a}
}
// 将init列表中所有节点添加到n节点的初始化部分
n.Ninit.Append(init...)
// 将body列表中所有节点添加到n节点的主体部分的开始
n.Nbody.Prepend(body...)
return n
}这段代码处理的就是遍历数组和切片时,同时关心索引和切片的情况。它不仅会在循环体中插入更新索引的语句,还会插入赋值操作让循环体内部的代码可以访问数组中的元素:
go
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
tmp := ha[hv1]
v1, v2 := hv1, tmp
// ...
}对于所有的range循环,Go语言都会在编译期将原切片或者数组赋值给一个新的变量ha,在赋值的过程中就发生了拷贝,所以我们遍历的切片已经不是原始的切片变量了。
而遇到这种同时遍历索引和元素的range循环时,Go语言会额外创建一个新的v2变量存储切片中的元素,循环中使用的变量v2会在每一次迭代被重新赋值,在赋值时也发生了拷贝。
go
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for i, _ := range arr {
newArr = append(newArr, &arr[i])
}
for _, v := range newArr {
fmt.Println(*v)
}
}因为在循环中获取返回变量的地址都完全相同,所以会发生神奇的指针一节中的现象。所以如果我们想要访问数组中元素所在的地址,不应该直接获取range返回的变量地址&v2,而应该使用&a[index]这种形式。
哈希表
在遍历哈希表时,编译器会使用runtime.mapiterinit和runtime.mapiternext两个运行时函数重写原始的for/range循环:
go
ha := a
hit := hiter(n.Type)
th := hit.Type
mapiterinit(typename(t), ha, &hit)
for ; hit.key != nil; mapiternext(&hit) {
key := *hit.key
val := *hit.val
}上述代码是for key, val := range hash {}生成的,在cmd/compile/internal/gc.walkrange函数处理TMAP节点时会根据接受range返回值的数量在循环体中插入需要的赋值语句:
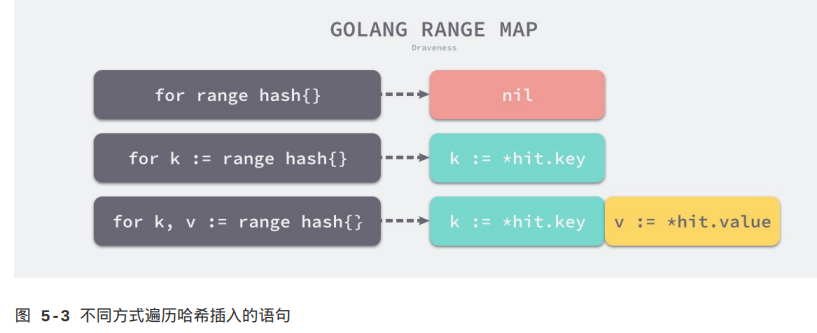
这三种不同的情况会分别向循环体插入不同的赋值语句。遍历哈希表时会使用runtime.mapiterinit函数初始化遍历开始的元素:
go
func mapiterinit(t *maptype, h *hmap, it *hiter) {
it.t = t
it.h = h
it.B = h.B
it.buckets = h.buckets
r := uintptr(fastrand())
// 随机数r的低位用于选择桶
it.startBucket = r & bucketMask(h.B)
// 随机数r的高位用于选择桶里的元素偏移
it.offset = uint8(r >> h.B & (bucketCnt - 1))
it.bucket = it.startBucket
mapiternext(it)
}该函数会初始化hiter结构体中的字段,并通过runtime.fastrand生成一个随机数帮助我们随机选择一个桶开始遍历。Go团队在设计哈希表的遍历时就不想让使用者依赖固定的遍历顺序,所以引入了随机数保证遍历的随机性。
遍历哈希会使用runtime.mapiternext函数,我们在这里简化了很多逻辑,省去了一些边界条件以及哈希表扩容时的兼容操作,这里只需要关注处理遍历逻辑的核心代码,我们会将该函数分成桶的选择和桶内元素的遍历两部分进行分析,首先是桶的选择过程:
go
func mapiternext(it *hiter) {
// map本身
h := it.h
// map的类型信息
t := it.t
// 当前正在遍历的bucket
bucket := it.bucket
// 当前bucket的指针
b := it.bptr
// 当前bucket中的位置索引
i := it.i
// map的key的比较算法
alg := t.key.alg
next:
// 如果b为空,则需要进行一些初始化工作
if b == nil {
// 是否已经回到起始位置,且已经遍历一圈
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.value = nil
return
}
// 计算当前bucket地址
b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize)))
// 将bucket自增1
bucket++
// 如果遍历到最后一个bucket
if bucket == bucketShift(it.B) {
// 回到第一个元素
bukcet = 0
// 记录已回到第一个元素
it.wrapped = true
}
// 从当前桶中的第一个元素开始遍历
i = 0
}这段代码主要有两个作用:
1.在待遍历的桶为空时选择需要遍历的新桶;
2.在不存在待遍历的桶时返回(nil, nil)键值对并中止遍历过程;
runtime.mapiternext函数中第二段代码的主要作用就是从桶中找到下一个遍历的元素,在大多数情况下都会直接操作内存获取目标键值对的内存地址,不过如果哈希表处于扩容期间就会调用runtime.mapaccessK函数获取键值对:
go
// 遍历bucket中的每一个位置
for ; i < bucketCnt; i++ {
// 计算加上随机偏移后,要遍历的位置
offi := (i + it.offset) & (bucketCnt - 1)
// 计算key的地址
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.keysize))
// 计算value的地址
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+uintptr(offi)*uintptr(t.valuesize))
// b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY表示当前元素没有被迁移
// t.reflexivekey()表示key不是自反性键,自反性键与自身比较时总是返回true,可以可靠地进行比较
// alg.equal(k, k)检查key是否相等
// 因此此处的条件为真等价于,当前遍历到的位置未被迁移,或key非自反且与自身不相等
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.reflexivekey() || alg.equal(k, k)) {
it.key = k
it.value = v
// 如果该位置已被迁移
} else {
rk, rv := mapaccessK(t, h, k)
it.key = rk
it.value = rv
}
// 更新迭代器的bucket和索引
it.bucket = bucket
it.i = i + 1
return
}
// 当前bucket遍历完毕,检查是否有溢出桶
b = b.overflow(t)
// 重置索引,准备遍历下一个bucket
i = 0
goto next
}当上述函数已经遍历了正常桶,就会通过runtime.bmap.overflow获取溢出桶一次进行遍历。
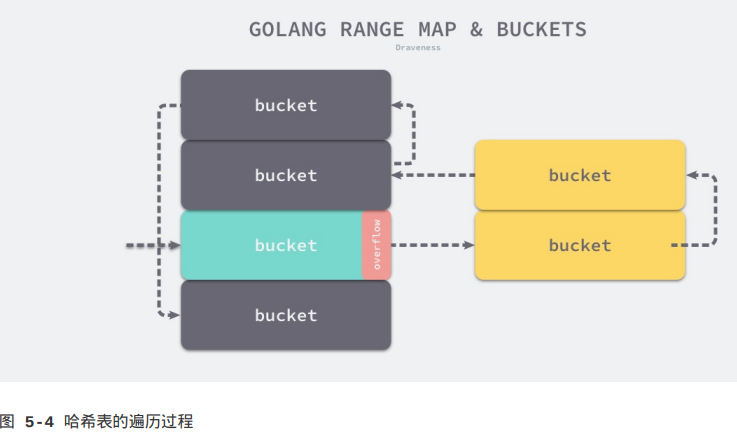
简单总结一下哈希表遍历的顺序,首先会选出一个绿色的正常桶开始遍历,随后遍历所有黄色溢出桶,最后依次按照索引顺序遍历哈希表中其他的桶,直到所有的桶都被遍历完成。
字符串
遍历字符串的过程与数组、切片、哈希表非常相似,只是在遍历时会获取字符串中索引对应的字节并将字节转换成rune。我们在遍历字符串时拿到的值都是rune类型的变量,for i, r := range s {}的结构都会被转换成如下所示的形式:
go
// 将字符串s赋值给ha
ha := s
// 遍历字符串
for hv1 := 0; hv1 < len(ha); {
// 将当前字符串的索引赋值给hv1t
hv1t := hv1
// 将当前遍历到的字符转换为Unicode码点
hv2 := rune(ha[hv1])
// 判断字符是否是单字节的ASCII字符,utf8.RuneSelf的值为128
if hv2 < utf8.RuneSelf {
// ASCII字符的Unicode编码大小是1字节
hv1++
} else {
// decoderune函数解码Unicode编码,返回Unicode码点hv2和下一个Uincode编码的起始位置hv1
hv2, hv1 = decoderune(h1, hv1)
}
// v1是当前遍历到的Unicode编码值的索引,v2是该编码值对应的码点值
v1, v2 = hv1t, hv2
}在前面的字符串一节中我们曾经介绍过字符串是一个只读的字节数组切片,所以范围循环在编译期间生成的框架与切片非常类似,只是细节有一些不同。
使用下标访问字符串中的元素时得到的就是字节,但是这段代码会将当前的字节转换成rune类型。如果当前的rune是ASCII的,那么只会占用一个字节长度,每次循环体运行之后只需要将索引加一,但是如果当前rune占用了多个字节就会使用runtime.decoderune函数解码,具体的过程就不在这里详细介绍了。
通道
使用range遍历Channel也是比较常见的做法,一个形如for v := range ch {}的语句最终会被转换成如下的格式:
go
ha := a
hv1, hb := <-ha
for ; hb != false; hv1, hb = <-ha {
v1 := hv1
hv1 = nil
// ...
}这里的代码可能与编译器生成的稍微有一些出入,但是结构和效果是完全相同的。该循环会使用<-ch从管道中取出等待处理的值,这个操作会调用runtime.chanrecv2并阻塞当前的协程,当runtime.chanrecv2返回时会根据布尔值hb判断当前的值是否存在,如果不存在就意味着当前的管道已经被关闭了,如果存在就会为v1赋值并清除hv1变量中的数据,然后会重新陷入阻塞等待新数据。
5.1.4 小结
这一节介绍的两个关键字for和range都是我们在学习和使用Go语言中无法绕开的,通过分析和研究它们的底层原理,让我们对实现细节有了更清楚的认识,包括Go语言遍历数组和切片时会复用变量(神奇的指针)、哈希表的随机遍历原理以及底层的一些优化,这都能帮助我们理解和使用Go语言。
5.2 select
很多C语言或者Unix开发者听到select想到的都是系统调用,而谈到I/O模型时最终大都会基于select、poll和epoll等函数构建的IO多路复用模型。Go语言的select与C语言中的select有着比较相似的功能。本节会介绍Go语言select常见的现象、数据结构以及四种不同情况下的实现原理。
C语言中的select关键字可以同时监听多个文件描述符的可读或者可写状态,Go语言中的select关键字也能够让Goroutine同时等待多个Channel的可读或者可写,在多个文件或者Channel发生状态改变之前,select会一直阻塞当前线程或者Goroutine。
select是一种与switch相似的控制结构,与switch不同的是,select中虽然也有多个case,但是这些case中的表达式必须是Channel的收发操作。下面的代码就展示了一个包含Channel收发操作的select结构:
go
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <- quit:
fmt.Println("quit")
return
}
}
}上述控制结构会等待c <- x或者<-quit两个表达式中任意一个的返回。无论哪一个表达式返回都会立即执行case中的代码,当select中的两个case同时被触发时,就会随机选择一个case执行。
5.2.1 现象
当我们在Go语言中使用select控制结构时,会遇到两个有趣的现象:
1.select能在Channel上进行非阻塞的收发操作;
2.select在遇到多个Channel同时响应时会随机挑选case执行;
这两个现象是学习select时经常会遇到的,我们来深入了解具体的场景并分析这两个现象背后的设计原理。
非阻塞的收发
在通常情况下,select语句会阻塞当前Goroutine并等待多个Channel中的一个达到可以收发的状态。但是如果select控制结构中包含default语句,那么这个select语句在执行时会遇到以下两种情况:
1.当存在可以收发的Channel时,直接处理该Channel对应的case;
2.当不存在可以收发的Channel时,执行default中的语句;
当我们运行下面的代码时就不会阻塞当前的Goroutine,它会直接执行default中的代码并返回。
go
func main() {
ch := make(chan int)
select {
case i := <-ch:
println(i)
default:
println("default")
}
}运行它:
只要我们稍微想一下,就会发现Go语言设计的这个现象就非常合理。select的作用就是同时监听多个case是否可以执行,如果多个Channel都不能执行,那么运行default中的代码也是理所当然的。
非阻塞的Channel发送和接收操作还是很有必要的,在很多场景下我们不希望向Channel发送消息或者从Channel中接收消息时阻塞当前Goroutine,我们只是想看看Channel的可读或可写状态。下面就是一个常见的例子:
go
// 初始化error通道,容量为tasks的个数
errCh := make(chan error, len(tasks))
wg := sync.WaitGroup()
// 等待len(tasks)个任务完成
wg.Add(len(tasks))
// 遍历每个任务
for i := range tasks {
// 为每个任务启动一个Goroutine
go func() {
// 在Goroutine结束时减少wg的计数器
defer wg.Done()
// 执行当前遍历到的任务,这里的i有问题,应作为参数传递,否则此时的i可能已经变了
// 如果任务执行出错
if err := tasks[i].Run(); err != nil {
// 将错误发送到通道中
errCh <- err
}
}()
}
// 等待计数器为0,即所有任务都已完成
wg.Wait()
select {
case err := <-errCh
return err
default:
return nil
}在上面这段代码中,我们不关心到底多少个任务执行失败了,只关心是否存在返回错误的任务,最后的select语句就能很好地完成这个任务。然而使用select的语法不是最原始的设计,它在最初版本使用x, ok := <-c的语法实现非阻塞收发,以下是与非阻塞收发相关的提交:
1.select default提交支持了select语句中的default情况;
2.gc: special case code for single-op blocking and non-blocking selects提交引入了基于select的非阻塞收发的特性;
3.gc: remove non-blocking send, receive syntax提交将x, ok := <-c语法删除;
4.gc, runtime: replace closed© with x, ok := <- c提交使用x, ok := <-c语法替代closed(c)语法判断Channel的关闭状态;
我们可以从上面的几个提交中看到非阻塞收发从最初到现在的演变。
随机执行
另一个使用select遇到的情况是同时有多个case就绪时,select会选择哪个case执行的问题,我们通过下面的代码简单了解一下:
go
func main() {
ch := make(chan int)
go func() {
// 每秒触发一次循环
for range time.Tick(1 * time.Second) {
ch <- 0
}
}()
for {
select {
case <-ch:
println("case1")
case <-ch:
println("case2")
}
}
}执行它:
从上述代码的输出结果中我们可以看到,select在遇到多个<-ch同时满足可读或者可写条件时会随机选择一个case执行其中的代码。
这个设计是在十多年前被select提交引入并一直保留到现在的,虽然中间经历过一些修改,但是语义一直都没有改变。在上面的代码中,两个case都是同时满足执行条件的,如果我们按照顺序依次判断,那么后面的条件永远都会得不到执行,而随机的引入就是为了避免饥饿问题的发生。
5.2.2 数据结构
select在Go语言的源代码中不存在对应的结构体,但是select控制结构中的case却使用runtime.scase结构体来表示:
go
type scase struct {
c *hchan
elem unsafe.Pointer
kind uint16
pc uintptr
releasetime int64
}因为非默认的case中都与Channel的发送和接收有关,所有runtime.scase结构体中也包含一个runtime.hchan类型的字段存储case中使用的Channel;除此之外,elem是接收或者发送数据的变量地址、kind表示runtime.scase的种类,总共包含以下四种:
go
const (
caseNil = itoa
caseRecv
caseSend
caseDefault
)这四种常量分别表示不同类型的case,相信它们的命名已经能够充分帮助我们理解它们的作用了,所以这里也不一一介绍了。
5.2.3 实现原理
select语句在编译期间会被转换成OSELECT节点。每一个OSELECT节点都会持有一组OCASE节点,如果OCASE的执行条件是空,那就意味着这是一个default节点:
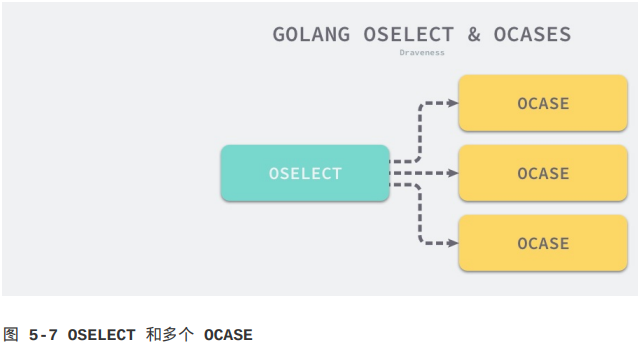
上图展示的就是select语句在编译期间的结构,每一个OCASE既包含执行条件也包含满足条件后执行的代码。
编译器在中间代码生成期间会根据select中case的不同对控制语句进行优化,这一过程发生在cmd/compile/internal/gc.walkselectcases函数中,我们在这里会分四种情况介绍处理的过程和结果:
1.select不存在任何的case;
2.select只存在一个case;
3.select存在两个case,其中一个是default;
4.select存在多个case;
上述的四种情况不仅会涉及编译器的重写和优化,还会涉及Go语言的运行时机制,我们会从编译期间和运行时两方面分析上述情况。
直接阻塞
首先介绍的是最简单的情况,也就是当select结构中不包含任何case时编译器是如何进行处理的,我们截取cmd/compile/internal/gc.walkselectcases函数的前几行代码:
go
func walkselectcases(cases *Nodes) []*Node {
n := cases.Len()
if n == 0 {
return []*Node{mkcall("block", nil, nil)}
}
// ...
}这段代码非常简单并且容易理解,它直接将类似select {}的空语句转换成调用runtime.block函数:
go
func block() {
gopark(nil, nil, waitReasonSelectNoCases, traceEvGoStop, 1)
}runtime.block函数的实现非常简单,它会调用runtime.gopark让出当前Goroutine对处理器的使用权,传入的等待原因是waitReasonSelectNoCases。
简单总结一下,空的select语句会直接阻塞当前Goroutine,导致Goroutine进入无法被唤醒的永久休眠状态。
单一管道
如果当前的select条件只包含一个case,那么就会将select改写成if条件语句。下面展示了原始的select语句和被改写、优化后的代码:
go
// 改写前
select {
case v, ok <- ch: // case ch <- v
// ...
}
// 改写后
if ch == nil {
block()
}
v, ok := <-ch // case ch <- v
// ...cmd/compile/internal/gc.walkselectcases在处理单操作select语句时,会根据Channel的收发情况生成不同的语句。当case中的Channel是空指针时,就会直接挂起当前Goroutine并永久休眠。
非阻塞操作
当select中仅包含两个case,并且其中一个是default时,Go语言的编译器就会认为这是一次非阻塞的收发操作。cmd/compile/internal/gc.walkselectcases函数会对这种情况单独处理,不过在正式优化之前,该函数会将case中的所有Channel都转换成指向Channel的地址。我们会分别介绍非阻塞发送和非阻塞接收时,编译器进行的不同优化。
发送
首先是Channel的发送过程,当case中表达式的类型是OSEND时,编译器会使用if/else语句和runtime.selectnbsend函数改写代码:
go
select {
case ch <- i:
// ...
default:
// ...
}
if selectnbsend(ch, i) {
// ...
} else {
// ...
}这段代码中最重要的就是runtime.selectnbsend函数,它为我们提供了向Channel非阻塞地发送数据的能力。我们在Channel一节(第6章)介绍了向Channel发送数据的runtime.chansend函数包含一个block参数,该参数会决定这一次的发送是不是阻塞的:
go
func selectnbsend(c *hchan, elem unsafe.Pointer) (selected bool) {
return chansend(c, elem, false, getcallerpc())
}由于我们向runtime.chansend函数传入了false,所以哪怕是不存在接收方或者缓冲区空间不足都不会阻塞当前Goroutine而是会直接返回。
接收
由于从Channel中接收数据可能会返回一个或两个值,所以接收数据的情况会比发送稍显复杂,不过改写的套路是差不多的:
go
// 改写前
select {
case v <- ch: // case v, ok <- ch:
// ...
default:
// ...
}
// 改写后,selectnbrecv和selectnbrecv2函数都返回是否case被选中
if selectnbrecv(&v, ch) { // if selectnbrecv2(&v, &ok, ch) {
// ...
} else {
// ...
}返回值数量不同会导致使用函数的不同,两个用于非阻塞接收消息的函数runtime.selectnbrecv和runtime.selectnbrecv2只是对runtime.chanrecv返回值的处理稍有不同:
go
func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected bool) {
selected, _ = chanrecv(c, elem, false)
return
}
func selectnbrecv2(elem unsafe.Pointer, received *bool, c *hchan) (selected bool) {
selected, *received = chanrecv(c, elem, false)
return
}因为接收方不需要,所以runtime.selectnbrecv会直接忽略返回的布尔值,而runtime.selectnbrecv2会将布尔值回传给调用方。与runtime.chansend一样,runtime.chanrecv也提供了一个block参数用于控制这一次接收是否阻塞。
常见流程
在默认情况下,编译器会使用如下流程处理select语句:
1.将所有的case转换成包含Channel以及类型等信息的runtime.scase结构体;
2.调用运行时函数runtime.selectgo从多个准备就绪的Channel中选择一个可执行的runtime.scase结构体;
3.通过for循环生成一组if语句,在语句中判断自己是不是被选中的case;
包含三个case的正常select语句会被展开成如下所示的逻辑,我们可以看到其中处理的三个部分:
go
selv := [3]scase{}
order := [6]uint16
for i, cas := range cases {
c := scase{}
c.kind = ...
c.elem = ...
c.c = ...
}
chosen, recvOK := selectgo(selv, order, 3)
if chosen == 0 {
...
break
}
if chosen == 1 {
...
break
}
if chosen == 2 {
...
break
}展开后的代码片段中最重要的就是用于选择待执行case的运行时函数runtime.selectgo,这也是我们要关注的重点。因为这个函数的实现比较复杂,所以这里分两部分分析它的执行过程:
1.执行一些必要的初始化操作并确定case的处理顺序;
2.在循环中根据case的类型做出不同的处理;
初始化
runtime.selectgo函数首先会执行必要的初始化操作并决定处理case的两个顺序------轮询顺序pollOrder和加锁顺序lockOrder:
go
func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool) {
// 将cas0转换成一个指向大小为1<<16的scase数组的指针
cas1 := (*[1 << 16]scase)(unsafe.Pointer(cas0))
// 将order0转换成一个指向大小为1<<17的uint16数组的指针
order1 := (*[1 << 17]uint16)(unsafe.Pointer(order0))
// 在Go 1.2中引入了slice[low:high:max]的语法来获取切片
// 新增的max表示新切片的cap为max-low
scases := cas1[:ncases:ncases]
// 轮训顺序
pollorder := order1[:ncases:ncases]
// 加锁顺序
lockorder := order1[ncases:][:ncases:ncases]
// 这段循环中还有其他内容,作者去掉了,导致这段循环看起来貌似没用
// 实际上,被去掉的部分是在过滤Channel为nil的scase和Default scase
for i := range scases {
cas := &scases[i]
}
// 随机化轮询顺序
for i := 1; i < ncases; i++ {
j := fastrandn(uint32(i + 1))
pollorder[i] = pollorder[j]
pollorder[j] = uint16(i)
}
// 根据Channel的地址排序确定加锁顺序
// ...
// lockorder的建立过程被删去了
sellock(scases, lockorder)
// ...
}轮询顺序pollOrder和加锁顺序lockOrder分别是通过以下的方式确认的:
1.轮询顺序:通过runtime.fastrandn函数引入随机性;
2.加锁顺序:按照Channel的地址排序后确定加锁顺序;
随机的轮询顺序可以避免Channel的饥饿问题,保证公平性;而根据Channel的地址顺序确定加锁顺序能够避免死锁的发生。这段代码最后调用的runtime.sellock函数会按照之前生成的加锁顺序锁定select语句中包含的所有Channel。
循环
当我们为select语句锁定了所有Channel后就会进入runtime.selectgo函数的主循环,它会分三个阶段查找或者等待某个Channel准备就绪:
1.查找是否已经存在准备就绪(即可以执行收发操作)的Channel;
2.将当前Goroutine加入Channel对应的收发队列上并等待其他Goroutine的唤醒;
3.当前Goroutine被唤醒后找到满足条件的Channel并进行处理;
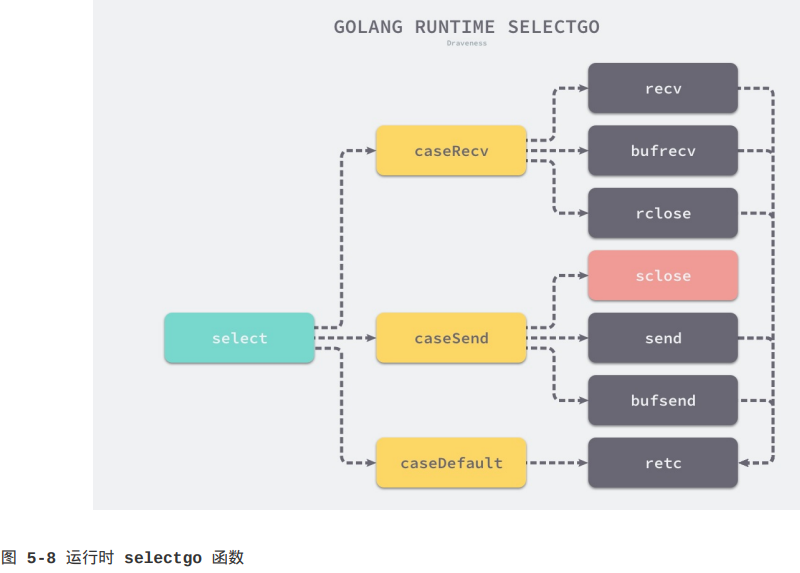
runtime.selectgo函数会根据不同情况通过goto跳转到函数内部的不同标签执行相应的逻辑,其中包括:
1.bufrecv:可以从缓冲区读取数据;
2.bufsend:可以向缓冲区写入数据;
3.recv:可以从休眠的发送方获取数据;
4.send:可以向休眠的接收方发送数据;
5.rclose:可以从关闭的Channel读取EOF;
6.sclose:向关闭的Channel发送数据;
7.retc:结束调用并返回;
我们先来分析循环执行的第一个阶段,查找已经准备就绪的Channel。循环会遍历所有的case并找到需要被唤起的runtime.sudog结构,在这个阶段,我们会根据case的四种类型分别处理:
1.caseNil:当前case不包含Channel,这种case会被跳过;
2.caseRecv:当前case会从Channel中接收数据;
(1)如果当前Channel的sendq上有等待的Goroutine,就会跳到recv标签从Goroutine中读取数据;
(2)如果当前Channel的缓冲区不为空就会跳到bufrecv标签处从缓冲区获取数据;
(3)如果当前Channel已经被关闭就会跳到rclose做一些清除的收尾工作;
3.caseSend:当前case会向Channel发送数据;
(1)如果当前Channel已经被关闭就会直接跳到sclose标签,触发panic尝试中止程序;
(2)如果当前Channel的recvq上有等待的Goroutine就会跳到send标签向Channel发送数据;
4.caseDefault:当前case为default语句,表示前面的所有case都没有被执行,这里会解锁所有Channel并返回,意味着当前select结构中的收发都是非阻塞的;
第一阶段的主要职责是查找所有case中Channel是否有可以立刻被处理的情况。无论是在等待的Goroutine还是缓冲区中存在数据,只要满足条件就会立刻处理,如果不能立刻找到活跃的Channel就会进入循环的下一阶段,按照需要将当前的Goroutine加入到Channel的sendq或者recvq队列中:
go
func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool) {
// ...
// sudog类型在Go的调度器中用于表示一个等待通用资源(如Channel)的Goroutine
sg = (*sudog)(gp.param)
gp.param = nil
// casi表示找到的case的索引
casi = -1
// cas表示找到的case的引用
cas = nil
// sglist表示正在等待的sudog结构列表
sglist = gp.waiting
// 以一个特定顺序锁定每个case
for _, casei := range lockorder {
// k是当前遍历的case
k = &scases[casei]
// 如果找到了对应的case
if sg == sglist {
// 设置找到的case的索引和引用
casi = int(casei)
cas = k
// 如果不是对应的case
} else {
// 根据类型从对应队列中移除该sudog结构
if k.kind == caseSend {
c.sendq.dequeueSudoG(sglist)
} else {
c.recvq.dequeueSugoG(sglist)
}
}
// sgnext是下一个要处理的sudog
sgnext = sglist.waitlink
sglist.waitlink = nil
// 释放或清理sglist
releaseSudog(sglist)
sglist = sgnext
}
c = cas.c
goto retc
// ...
}第三次遍历全部case时,我们会先获取当前Goroutine接收到的参数sudog结构,我们会依次对比所有case对应的sudog结构找到被唤醒的case,获取该case对应的索引并返回。
由于当前的select结构找到了一个case执行,那么剩下case中没有被用到的sudog就会被忽略并释放掉。为了不影响Channel的正常使用,我们是需要将这些废弃的sudog从Channel中出队。
当我们在循环中发现缓冲区中有元素或者缓冲区未满时就会通过goto关键字跳转到bufrecv和bufsend两个代码段,这两段代码的执行过程都很简单,它们只是向Channel中发送数据或从缓冲区中获取新数据:
go
bufrecv:
// 接收状态设为成功
recvOK = true
// 根据通道的接收索引获取缓冲区位置
qp = chanbuf(c, c.recvx)
// 如果目标元素非空
if cas.elem != nil {
// 将数据从缓冲区qb移动到cas.elem
typedmemmove(c.elemtype, cas.elem, qp)
}
// 清除缓冲区qb中的数据
typedmemclr(c.elemtype, qp)
// 递增接收索引
c.recvx++
// 如果接收索引溢出,将其置为0,环形缓冲区
if c.recvx == c.dataqsiz {
c.recvx = 0
}
// 减少队列中的元素数量
c.qcount--
// 解锁之前锁定的所有资源
selunlock(scases, lockorder)
goto retc
bufsend:
// 将cas.elem中的要发送数据复制到发送索引对应的缓冲区
typedmemmove(c.elemtype, chanbuf(c, c.sendx), cas.elem)
// 增加发送索引
c.sendx++
// 环形缓冲区
if c.sendx == c.dataqsiq {
c.sendx = 0
}
// 增加队列中的元素数量
c.qcount++
// 解锁之前所有加锁的资源
selunlock(scases, lockorder)
goto retc这里在缓冲区进行的操作和直接调用runtime.chansend和runtime.chanrecv差不多,上述两个过程在执行结束之后都会直接跳到retc字段。
两个直接对Channel收发的情况会调用Channel运行时函数runtime.send和runtime.recv,这两个函数会直接与处于休眠状态的Goroutine打交道:
go
recv:
recv(c, sg, cas.elem, func() { selunlock(scases, lockorder) }, 2)
recvOK = true
goto retc
send:
send(c, sg, cas.elem, func() { selunlock(scases, lockorder) }, 2)
goto retc不过如果向关闭的Channel发送数据或者从关闭的Channel中接收数据,情况就稍微有一点复杂了:
1.从一个关闭Channel中接收数据会直接清除Channel中的相关内容;
2.向一个关闭的Channel发送数据会直接panic造成程序崩溃;
go
rclose:
selunlock(scases, lockorder)
recvOK = false
if cas.elem != nil {
typedmemclr(c.elemtype, cas.elem)
}
goto retc
sclose:
selunlock(scases, lockorder)
panic(plainError("send on closed channel"))总体来看,select语句中的Channel收发操作和直接操作Channel没有太多出入,只是由于select多出了default关键字所以会支持非阻塞的收发。
5.2.4 小结
我们简单总结一下select结构的执行过程与实现原理,首先在编译期间,Go语言会对select语句进行优化,它会根据select中case的不同选择不同的优化路径:
1.空的select语句会被转换成runtime.block函数的调用,直接挂起当前Goroutine;
2.如果select语句中只包含一个case,就会被转换成if ch == nil { block }; n;表达式;
(1)首先判断操作的Channel是不是空的;
(2)然后执行case结构中的内容;
3.如果select语句中只包含两个case且其中一个是default,那么会使用runtime.selectnbrecv和runtime.selectnbsend非阻塞地执行收发操作;
4.在默认情况下会通过runtime.selectgo函数获取执行case的索引,并通过多个if语句执行对应case中的代码;
在编译器已经对select语句进行优化之后,Go语言会在运行时执行编译期间展开的runtime.selectgo函数,该函数会按照以下流程执行:
1.随机生成一个遍历的轮询顺序pollOrder并根据Channel地址生成锁定顺序lockOrder;
2.根据pollOrder遍历所有的case查看是否有可以立刻处理的Channel;
(1)如果存在就直接获取case对应的索引并返回;
(2)如果不存在就会创建runtime.sudog结构体,将当前Goroutine加入到所有相关Channel的收发队列,并调用runtime.gopark挂起当前Goroutine等待调度器的唤醒;
3.当调度器唤醒当前Goroutine时就会再次按照lockOrder遍历所有的case,从中查找需要被处理的runtime.sudog结构对应的索引;
select关键字是Go语言特有的控制结构,它的实现原理比较复杂,需要编译器和运行时函数的通力合作。
5.3 defer
很多现代的编程语言中都有defer关键字,Go语言的defer会在当前函数或方法返回前执行传入的函数。它会经常被用于关闭文件描述符、关闭数据库连接、解锁资源。
在这一节中我们会深入Go语言的源码介绍defer关键字的实现原理,相信读者读完这一节会对defer的数据结构、实现、调用过程有着更清晰的理解。
作为一个编程语言中的关键字,defer的实现一定是由编译器和运行时共同完成的,不过在深入源码分析它的实现前我们还需了解defer关键字的常见使用场景和使用时的注意事项。
使用defer的最常见场景是在函数调用结束后完成一些收尾工作,例如在defer中回滚数据库的事务:
go
func createPost(db *gorm.DB) error {
tx := db.Begin()
defer tx.Rollback()
if err := tx.Create(&Post{Author: "Draveness"}).Error; err != nil {
return err
}
return tx.Commit().Error
}在使用数据库事务时,我们可以使用如上代码在创建事务后立刻调用Rollback保证事务一定会回滚。哪怕事务真的执行成功了,那么调用tx.Commit()后再执行tx.Rollback()也不会影响已提交的事务。
5.3.1 现象
我们在Go语言中使用defer时会遇到两个比较常见的问题,这里会介绍具体的场景并分析这两个现象背后的设计原理:
1.defer关键字的调用时机以及多次调用defer时执行顺序是如何确定的;
2.defer关键字使用传值的方式传递参数时会进行预计算,导致不符合预期的结果;
作用域
向defer关键字传入的函数会在函数返回前运行。假设我们在for循环中多次调用defer关键字:
go
func main() {
for i := 0; i < 5; i++ {
defer fmt.Println(i)
}
}运行它:
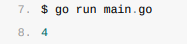
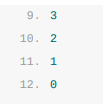
运行上述代码会倒序执行所有向defer关键字中传入的表达式,最后一次defer调用传入了fmt.Println(4),所以这段代码会先打印4。我们可以通过下面这个简单例子强化对defer执行时机的理解:
go
func main() {
{
defer fmt.Println("defer runs")
fmt.Println("block ends")
}
fmt.Println("main ends")
}执行它:

从上述代码的输出我们会发现,defer传入的函数不是在退出代码块的作用域时执行的,它只会在当前函数和方法返回前被调用。
预计算参数
Go语言中所有的函数调用都是传值的,defer虽然是关键字,但也继承了这个特性。假设我们想要计算main函数运行的时间,可能会写出以下代码:
go
func main() {
startAt := time.Now()
defer fmt.Println(time.Since(startedAt))
time.Sleep(time.Second)
}执行它:
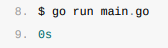
然而上述代码的运行结果并不符合我们的预期,这个现象背后的原因是什么呢?经过分析,我们发现调用defer关键字会立刻对函数中引用的外部参数进行拷贝,所以time.Since(startedAt)的结果不是在main函数退出前计算的,而是在defer关键字调用时计算的,最终导致上述代码输出0s。
想要解决这个问题的方法非常简单,我们只需要向defer关键字传入匿名函数:
go
func main() {
startedAt := time.Now()
defer func() { fmt.Println(time.Since(startedAt) }()
time.Sleep(time.Second)
}执行它:
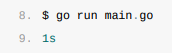
虽然调用defer关键字时也使用值传递,但是因为拷贝的是函数指针,所以time.Since(startedAt)会在main函数结束时被调用并打印出符合预期的结果。
5.3.2 数据结构
在介绍defer函数的执行过程与实现原理前,我们先了解一下defer关键字在Go语言源码中对应的数据结构:
go
type _defer struct {
siz int32
started bool
sp uintptr
pc uintptr
fn *funcval
_panic *_panic
link *_defer
}runtime._defer结构体是延迟调用链表上的一个元素,所有结构体都通过link字段串联成链表。
我们简单介绍一下runtime._defer结构体中的几个字段:
1.siz是参数和结果的内存大小;
2.sp和pc分别代表栈指针和调用方的程序计数器;
3.fn是defer关键字中传入的函数;
4._panic是触发延迟调用的结构体,可能为空;
除了上述字段外,runtime._defer中还包含一些垃圾回收机制使用的字段,这里为了减少理解成本就都省去了。
5.3.3 编译过程
中间代码生成阶段执行的cmd/compile/internal/gc.state.stmt函数会处理defer关键字。从下面这段截取的代码中,我们会发现编译器调用了cmd/compile/internal/gc.state.call函数,这表示defer在编译器看来也是函数调用:
go
func (s *state) stmt(n *Node) {
switch n.Op {
case ODEFER:
s.call(n.Left, callDefer)
}
}cmd/compile/internal/gc.state.call函数会负责为所有函数和方法调用生成中间代码,它的工作包括以下内容:
1.获取需要执行的函数名、闭包指针、代码指针、函数调用的接收方;
2.获取栈地址并将函数或者方法的参数写入栈中;
3.使用cmd/compile/internal/gc.state.newValue1A以及相关函数生成函数调用的中间代码;
4.如果当前调用的函数是defer,那么就会单独生成相关的结束代码块;
5.获取函数的返回值地址并结束当前调用;
go
func (s *state) call(n *Node, k callKind) *ssa.Value {
// ...
var call *ssa.Value
switch {
case k == callDefer:
// 生成一个ssa.Value
// ssa.OpStaticCall表示静态调用操作
//
call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, deferproc, s.mem())
// ...
}
// 应该是设置堆栈大小
call.AuxInt = stksize
s.vars[&memVar] = call
// ...
}从上述代码中我们能看到,defer关键在在运行期间会调用runtime.deferproc函数,这个函数接收了参数的大小和闭包所在的地址两个参数。
编译器不仅将defer关键字都转换成runtime.deferproc函数,它还会通过以下三个步骤为所有调用defer的函数末尾插入runtime.deferreturn函数调用:
1.cmd/compile/internal/gc.walkstmt在遇到ODEFER节点时会执行Curfn.Func.SetHasDefer(true)设置当前函数的hasdefer;
2.cmd/compile/internal/gc.buildssa会执行s.hasdefer = fn.Func.HasDefer()更新state的hasdefer;
3.cmd/compile/internal/gc.state.exit会根据state的hasdefer在函数返回前插入runtime.deferreturn函数调用;
go
func (s *state) exit() *ssa.Block {
if s.hasdefer {
s.rtcall(Deferreturn, true, nil)
}
// ...
}Go语言的编译器不仅将defer转换成了runtime.deferproc函数调用,还在所有调用defer的函数结尾插入了runtime.deferreturn,接下来我们就需要了解这两个运行时方法的实现原理了。
5.3.4 运行过程
defer关键字的运行时实现分成两个部分:
1.runtime.deferproc函数负责创建新的延迟调用;
2.runtime.deferreturn函数负责在函数调用结束时执行所有的延迟调用;
这两个函数是defer关键字运行时机制的入口,我们从它们开始分别介绍这两个函数的执行过程。
创建延迟调用
runtime.deferproc会为defer创建一个新的runtime._defer结构体、设置它的函数指针fn、程序计数器pc、栈指针sp,并将相关的参数拷贝到相邻的内存空间中:
go
// siz参数表示延迟函数参数的大小
// fn参数表示要执行的延迟函数的指针
func deferproc(siz int32, fn *funcval) {
// 获取使用defer的函数的栈指针
sp := getcallersp()
// 计算要执行的延迟函数的参数的地址,值为函数指针fn的地址加上fn指针的大小,即函数指针fn的后面位置
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)
// 获取使用defer的函数的程序计数器
callerpc := getcallerpc()
// 创建一个新的runtime._defer结构
d := newdefer(siz)
// 检查创建过程是否有异常,如果有
if d._panic != nil {
// 抛出异常
throw("deferproc: d.panic != nil after newdefer")
}
// 设置延迟调用的函数指针
d.fn = fn
// 设置调用者的程序计数器
d.pc = callerpc
// 设置调用者的栈指针
d.sp = sp
switch siz {
// 如果延迟函数的参数大小为0,则不做操作
case 0:
// 如果延迟函数的参数等于指针大小,则直接拷贝指针值
case sys.PtrSize:
*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))
// 使用memmove函数赋值延迟函数的参数内存
default:
memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))
}
return0()
}最后调用的runtime.return0函数的作用是避免无限递归调用runtime.deferreturn,它是唯一一个不会触发延迟调用的函数。
runtime.deferproc中runtime.newdefer的作用是获得一个runtime._defer结构体,方法总共有三种:
1.从调度器的延迟调用缓冲池sched.deferpool中取出结构体并将该结构体追加到当前Goroutine的缓存池中;
2.从Goroutine的延迟调用缓存池pp.deferpool中取出结构体;
3.通过runtime.mallocgc创建一个新的结构体;
go
// 分配并初始化一个runtime._defer结构体
// siz参数表示延迟调用函数的参数大小
func newdefer(siz int32) *_defer {
// d将被用来存储分配或重用的_defer结构体
var d *_defer
// deferclass函数根据延迟调用函数的参数大小计算一个类别,用于从合适大小的池中分配或重用_defer结构体
sc := deferclass(uintptr(siz))
// 获取当前Goroutine指针
gp := getg()
// 查看计算出的类别是否在延迟池的有效范围内
if sc < uintptr(len(p{}.deferpool)) {
// 获取当前Goroutine的延迟调用缓冲池
pp := gp.m.p.ptr()
// 如果当前Goroutine的延迟调用缓冲池为空,但调度器的延迟调用缓冲池非空
if len(pp.deferpool[sc]) == 0 && sched.deferpool[sc] != nil {
// 从调度器的池中取出_defer结构到Goroutine的池中,直到Goroutine的池达到其容量的一半
for len(pp.deferpool[sc]) < cap(pp.deferpool[sc])/2 && sched.deferpool[sc] != nil {
// 从调度器的池中取出一个_defer结构
d := sched.deferpool[sc]
// 将调度器池指向_defer链表的下一个
sched.deferpool[sc] = d.link
// 将调度器池中取出的_defer结构加到Goroutine的池中
pp.deferpool[sc] = append(pp.deferpool[sc], d)
}
}
// 如果Goroutine的池中还有_defer结构
if n := len(pp.deferpool[sc]); n > 0 {
// 从Goroutine的池中取出一个_defer结构
d = pp.deferpool[sc][n-1]
// 将Goroutine池中取出后的位置置空
pp.deferpool[sc][n-1] = nil
// 更新Goroutine池中的_defer切片
pp.deferpool[sc] = pp.deferpool[sc][:n-1]
}
}
// 如果没有从调度器或Goroutine的池中找到可用_defer结构
if d == nil {
// 计算内存对齐后_defer结构所需大小
total := roundupsize(totaldefersize(uintptr(siz)))
// 分配_defer结构
d = (*_defer)(mallocgc(total, deferType, true))
}
// 设置_defer结构的延迟调用函数的参数大小
d.siz = siz
// 将新创建的_defer结构插入当前Goroutine的_defer链表头
d.link = gp._defer
// 更新当前Goroutine的_defer链表头
gp._defer = d
return d
}无论使用哪种方式获取runtime._defer,它都会被追加到所在的Goroutine的_defer链表的最前面。


defer关键字插入链表时每次都插入到链表头,而defer关键字执行在链表中是从前向后的,这就是后调用的defer会先执行的原因。
执行延迟调用
runtime.deferreturn会从Goroutine的_defer链表中取出最前面的runtime._defer结构体并调用runtime.jmpdefer函数传入需要执行的函数和参数:
go
func deferreturn(arg0 uintptr) {
// 获取当前Goroutine指针
gp := getg()
// 获取当前Goroutine的_defer结构链表
d := gp._defer
// 如果没有要执行的延迟调用函数
if d == nil {
// 直接返回
return
}
// 获取使用defer的函数的栈指针
sp := getcallersp()
// 处理延迟函数的参数
switch d.siz {
// 如果延迟函数的参数大小为0,直接什么都不做
case 0:
// 如果参数大小为指针大小
case sys.PtrSize:
// deferArgs函数用于获取延迟函数的参数的地址
// *(uintptr)(deferArgs(d))表示将参数地址类型转换成uintptr,然后解引用,即获取参数地址处的值
// (unsafe.Pointer(&arg0))表示取输入参数的地址,再类型转换成unsafe.Pointer
// 然后再将unsafe.Pointer转换成*uintptr,即二维指针,然后再解引用,结果还是arg0
*(*uintptr)(unsafe.Pointer(&arg0)) = *(uintptr)(deferArgs(d))
// 如果参数大小为其他值
default:
// 调用memmove将延迟函数的参数地址复制到arg0处
memmove(unsafe.Pointer(&arg0), deferArgs(d), uintptr(d.siz))
}
// 获取要延迟执行的函数指针
fn := d.fn
// 更新_defer字段为链表中的下一个值
gp._defer = d.link
// 释放已经获取的_defer结构
freedefer(d)
// 跳转执行延迟函数
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))
}runtime.jmpdefer是一个用汇编语言实现的运行时函数,它的工作就是跳转defer所在的代码段并在执行结束后跳转回runtime.deferreturn。
go
// TEXT指定了一个新的代码段
// runtime.jmpdefer(SB)指定了函数名和符号基址(栈基址)
// NOSPLIT表示不进行栈分裂
// $0-8表示局部变量大小为0字节,参数大小为8字节
TEXT runtime.jmpdefer(SB), NOSPLIT, $0-8
// 等效于MOVL fv(FP), DX
// 将帧指针偏移fv字节处的值(要执行的延迟函数指针)复制到寄存器DX中
MOVL fv+0(FP), DX // fn
// 将帧指针偏移argp+4字节处的值(deferreturn,即调用者的栈指针)复制到寄存器BX中
MOVL argp+4(FP), BX // caller sp
// LEAL(Load Effective Addreess Long)指令将地址加载到某处
// 计算本函数的栈指针值(寄存器偏移-4字节处),并将其存放到寄存器SP中
// 这一步准备了本函数的栈空间
LEAL -4(BX), SP // caller sp after CALL
// 如果是动态库
#ifdef GOBUILDMODE_shared
// 将栈指针减16,调整栈的返回地址,使得CALL后可以返回到执行CALL的位置
SUBL $16, (SP) // return to CALL again
// 如果是静态库
#else
// 将栈指针减5
SUBL $5, (SP) // return to CALL again
#endif
// 将寄存器DX偏移0字节(要执行的延迟函数指针)复制到寄存器BX
MOVL 0(DX), BX
// 跳转到延迟函数,开始执行它
JMP BX // but first run the defered functionruntime.deferreturn函数会多次判断当前Goroutine的_defer链表中是否有未执行的剩余结构,在所有的延迟函数调用都执行完成后,该函数才会返回。
5.3.5 小结
defer关键字的实现主要依靠编译器和运行时的协作,我们总结一下本节提到的内容:
1.编译期:
(1)将defer关键字转换为runtime.deferproc;
(2)在调用defer关键字的函数返回前插入runtime.deferreturn;
2.运行时:
(1)runtime.deferproc会将一个新的runtime._defer结构体追加到当前Goroutine的链表头;
(2)runtime.deferreturn会从Goroutine的链表中取出runtime._defer结构并依次执行;
我们在本节前面提到的两个现象在这里也可以解释清楚了:
1.后调用的defer函数会先执行:
(1)后调用的defer函数会被追加到Goroutine _defer链表的最前面;
(2)运行runtime._defer时是从前到后依次执行;
2.函数的参数会被预先计算。调用runtime.deferproc函数创建新的延迟调用时就会立刻拷贝函数的参数,函数的参数不会等到真正执行时计算;
5.4 panic和recover
本节将分析两个经常成对出现的关键字panic和recover。这两个关键字都与defer有千丝万缕的联系,也都是Go语言中的内置函数,但是提供的功能却是互补的:
1.panic能够改变程序的控制流,函数调用panic时会立刻停止执行函数的其它代码,并在执行结束后在当前Goroutine中递归执行调用方的延迟函数。
2.recover可以中止panic造成的程序崩溃。它是一个只能在defer中发挥作用的函数,在其他作用域中调用不会发挥任何作用。

Andrew Gerrand写过一篇名为Defer, Panic, and Recover的博客很好地介绍了这三个关键字的不同作用以及它们的关系。
5.4.1 现象
我们先通过几个例子了解一下使用panic和recover关键字时遇到的一些现象,部分现象也与上一节分析的defer关键字有关:
1.panic只会触发当前Goroutine的延迟函数调用;
2.recover只有在defer函数中调用才会生效;
3.panic允许在defer中嵌套多次调用;
跨协程失效
首先要展示的例子是panic只会触发当前Goroutine的延迟函数调用。这里有一段简单的代码:
go
func main() {
defer println("in main")
go func() {
defer println("in goroutine")
panic("")
}()
time.Sleep(1 * time.Second)
}执行它:

当我们运行这段代码时会发现main函数中的defer语句没有执行,执行的只有当前Goroutine中的defer。
上一节我们曾介绍过defer关键字对应的runtime.deferproc会将延迟调用函数与调用方所在Goroutine进行关联。所以当程序发生崩溃时只会调用当前Goroutine的延迟调用函数也是非常合理的。

如上图所示,多个Goroutine之间没有太多关联,一个Goroutine在panic时也不应该执行其他Goroutine的延迟函数。
失效的崩溃恢复
初学Go语言的读者可能会写出下面的代码,在主程序中调用recover试图中止程序的崩溃,但是从运行的结果中我们也能看出,如下所示的程序依然没有正常退出。
go
func main() {
defer fmt.Println("in main")
if err := recover(); err != nil {
fmt.Println(err)
}
panic("unknown err")
}执行它:

仔细分析一下这个过程就能理解这种现象背后的原因,recover只有在发生panic后调用才生效。但在上面的控制流中,recover是在panic前调用的,不满足生效的条件,所以我们需要在defer中使用recover关键字。
嵌套崩溃
Go语言中的panic是可以多次嵌套调用的。一些熟悉Go语言的读者可能也不知道这个知识点,如下所示的代码就展示了如何在defer函数中多次调用panic:
go
func main() {
defer fmt.Println("in main")
defer func() {
defer func() {
panic("panic again and again")
}()
panic("panic again")
}()
panic("panic once")
}执行它:

从上述程序的输出,我们可以确定程序多次调用panic也不会影响defer函数的正常执行。所以使用defer进行收尾工作一般来说都是安全的。
5.4.2 数据结构
panic关键字在Go语言的源码中是由数据结构runtime._panic表示的。每当我们调用panic都会创建一个如下所示的数据结构存储相关信息:
go
type _panic struct {
argp unsafe.Pointer
arg interface{}
link *_panic
recovered bool
aborted bool
pc uintptr
sp unsafe.Pointer
goexit bool
}1.argp是指向defer调用时参数的指针(用于panic后调用延迟函数,但panic并不一定会有defer);
2.arg是调用panic时传入的参数;
3.link指向了更早调用的runtime._panic结构;
4.recovered表示当前runtime._panic是否被recover恢复;
5.aborted表示当前的panic是否被强行终止;
从数据结构中的link字段我们可以推测出panic函数可以被连续多次调用,它们之间通过link的关联形成一个链表。
结构体中的pc、sp、goexit三个字段都是为了修复runtime.Goexit的问题引入的。该函数能够只结束调用该函数的Goroutine而不影响其他Goroutine,但是该函数会被defer中的panic和recover取消,引入这三个字段的目的就是为了解决这个问题。
5.4.3 程序崩溃
首先了解一下panic函数是如何终止程序的。编译器会将关键字panic转换成runtime.gopanic,该函数的执行过程包含以下几个步骤:
1.创建新的runtime._panic结构并添加到所在Goroutine _panic链表的最前面;
2.在循环中不断从当前Goroutine的_defer链表获取runtime._defer并调用runtime.reflectcall运行延迟调用函数;
3.调用runtime.fatalpanic中止整个程序;
go
// 当程序遇到panic时,会由运行时系统调用该函数
// e表示引发panic时传入的参数
func gopanic(e interface{}) {
// 获取当前Goroutine状态结构的指针
gp := getg()
// ...
// 初始化_panic类型对象p
var p _panic
// 设置引发panic时的参数
p.arg = e
// 将新_panic对象放到当前Goroutine的_panic链表头
p.link = gp._panic
// noescape函数用于告知垃圾回收器,这个指针只在栈上临时使用,它不会逃逸到堆中,有助于优化垃圾回收性能
// 更新当前Goroutine的_panic链表
gp._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
// 循环处理所有defer调用
for {
// 获取当前Goroutine的延迟执行函数链表的头
d := gp._defer
// 如果没有要延迟执行的函数
if d == nil {
// 跳出循环
break
}
// 更新当前Goroutine的_panic链表
// 这是为了确保当延迟调用的函数中又发生panic时,可以正确链接和处理这些panic
d._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
// 调用延迟函数
reflectcall(nil, unsafe.Pointer(d.fn), deferArgs(d), uint32(d.siz), uint32(d.siz))
// 清空已处理的_defer结构的_panic和fn字段,防止被错误地重用
d._panic = nil
d.fn = nil
// 更新当前Goroutine的_defer链表,去掉头
gp._defer = d.link
// 释放已经处理过的_defer结构
freedefer(d)
// 如果执行defer函数的过程调用了recover
if p.recover {
// ...
}
}
// 如果没有defer函数recover,终止整个程序
fatalpanic(gp._panic)
// 通过向nil指针写入数据,触发一个无法恢复的panic,保证程序崩溃
*(*int)(nil) = 0
}需要注意的是,我们在上述函数中省略了三部分比较重要的代码:
1.恢复程序的recover分支中的代码;
2.通过内联优化defer调用性能的代码:runtime: make defers low-cost through inline code and extra funcdata;
3.修复runtime.Goexit异常情况的代码:runtime: ensure that Goexit cannot be aborted by a recursive panic/recover;
runtime.fatalpanic实现了无法被恢复的程序崩溃,它在中止程序之前会通过runtime.printpanics打印出全部的panic消息以及调用时传入的参数:
go
func fatalpanic(msgs *_panic) {
// 获取调用者的程序计数器
pc := getcallerpc()
// 获取调用者的栈指针
sp := getcallersp()
// 获取本Goroutine的结构信息
gp := getg()
// startpanic_m函数返回是否可以处理panic,如果可以处理,且传入的_panic结构非空
if startpanic_m() && msgs != nil {
// 使用原子操作将runningPanicDefers减1
atomic.Xadd(&runningPanicDefers, -1)
// 打印所有panic信息
printpanics(msgs)
}
// dopanic_m函数会处理panic,如果返回true,表示需要崩溃
if dopanic_m(gp, pc, sp) {
// 崩溃
crash()
}
// 以错误码2退出程序
exit(2)
}打印panic消息之后会通过runtime.exit退出当前程序并返回错误码2,而程序的正常退出也是通过runtime.exit函数实现的。
5.4.4 崩溃恢复
到这里我们已经掌握了panic退出程序的过程,接下来分析defer中的recover是如何中止程序崩溃的。编译器会将关键字recover转换成runtime.gorecover:
go
func gorecover(argp uintptr) interface{} {
p := gp._panic
if p != nil && !p.recovered && argp == uintptr(p.argp) {
p.recovered = true
return p.arg
}
return nil
}这个函数的实现非常简单,如果当前Goroutine没有调用panic,那么该函数会直接返回nil,这也是崩溃恢复在非defer中调用会失效的原因。
在正常情况下,它会修改runtime._panic结构体的recovered字段,runtime.gorecover函数本身不包含恢复程序的逻辑,程序的恢复也是由runtime.gopanic函数负责的:
go
func gopanic(e interface{}) {
// ...
for {
// 执行延迟调用函数,可能会设置p.recovered = true
// ...
// 获取当前_defer结构的程序计数器和栈指针字段
pc := d.pc
sp := unsafe.Pointer(d.sp)
// ...
// 如果panic被恢复
if p.recovered {
// 将当前Goroutine的_panic链表去掉头
gp._panic = p.link
// 如果下一个_panic结构被标记为aborted
for gp._panic != nil && gp._panic.aborted {
// 将它从链表中去掉
gp._panic = gp._panic.link
}
// 如果没有更多_panic结构了
if gp._panic == nil {
// 重置信号
gp.sig = 0
}
// 将当前处理的_defer结构中的栈指针和程序计数器保存到Goroutine的信号代码里
gp.sigcode0 = uintptr(sp)
gp.sigcode1 = pc
// 调用recovery进行恢复
mcall(recovery)
// 如果恢复失败,则抛出异常
throw("recovery failed")
}
}
// ...
}上述这段代码也省略了defer的内联优化,它从runtime._defer结构体中取出了程序计数器pc和栈指针sp并调用runtime.recovery函数触发Goroutine的调度,调度之前会准备好sp、pc、函数的返回值:
go
func recovery(gp *g) {
// 获取先前保存的栈指针和程序计数器
sp := gp.sigcode0
pc := gp.sigcode1
// 设置Goroutine调度器的状态
gp.sched.sp = sp
gp.sched.pc = pc
gp.sched.lr = 0
gp.sched.ret = 1
// gogo函数会切换到指定的调度器状态(sp、pc等),从而恢复Goroutine的执行
gogo(&gp.sched)
}当我们在调用defer关键字时,调用时的栈指针sp和程序计数器pc就已经存储到了runtime._defer结构体中,这里的runtime.gogo函数会跳回defer关键字调用的位置(runtime.deferproc函数)。
runtime.recovery在调度过程中会将函数的返回值中设为1。从runtime.deferproc的注释中我们会发现,当runtime.deferproc函数的返回值为1时,编译器生成的代码会直接跳转到调用方函数返回前并执行runtime.deferreturn:
go
func deferproc(siz int32, fn *funcval) {
// ...
// deferproc return 0 normally.
// a deferred func that stops a panic
// makes the deferproc return 1.
// the code the compiler generates always
// checks the return value and jumps to the
// end of the function if deferproc returns != 0.
return0()
}跳转到runtime.deferreturn函数后,程序就已经从panic中恢复了并执行正常的逻辑,而runtime.gorecover函数也能从runtime._panic结构体中取出调用panic时传入的arg参数并返回给调用方。