监控组件
以下服务是Kubernetes常用监控组件:
K8S Metric
K8S 自身提供一下Summary API
- API service
- Kubelet 集成的节点资源API,以及cadvisor
通过HTTP访问上述API:
# PS: 使用prometheus-server的token可以保证有权限
TOKEN=$(kubectl get secrets $(kubectl get secrets -n kube-system | grep default-token | awk '{print $1}') -n kube-system -o jsonpath={.data.token} | base64 -d)
TOKEN=$(kubectl get secrets $(kubectl get secrets -n prometheus | grep prometheus-server-token | awk '{print $1}') -n prometheus -o jsonpath={.data.token} | base64 -d)
curl -k -H "Authorization:Bearer $TOKEN" https://<HOST_NAME or HOST_IP>:6443/metrics
curl -k -H "Authorization:Bearer $TOKEN" https://<HOST_NAME or HOST_IP>:6443/api/v1/nodes/<NODE_HOST_NAME>/proxy/metrics
curl -k -H "Authorization:Bearer $TOKEN" https://<HOST_NAME or HOST_IP>:6443/api/v1/nodes/<NODE_HOST_NAME>/proxy/metrics/cadvisor上述可以获取的一些指标:
- API Service
- etcd_object_counts:etcd的对象数目
- etcd_request_duration_seconds:etcd服务的请求时间
- ssh_tunnel_open_count/ssh_tunnel_open_fail_count
- API Service 本身的内存、进程数、GC等信息
- Kubelet Node
- Kubelet节点的证书信息、Token信息等
- Kubelet服务的内存、进程数、GC等信息
- Kubelet cadvisor Metrics
- 略
下面开始进入监控主题:
kubelet通过/metrics暴露自身的指标数据。kubelet有两个端口都提供了这个url,一个是安全端口(10250),一个是非安全端口(10255,kubeadm安装的集群该端口是关闭的)。安全端口使用https协议,而且还需要认证与授权,所以我们通过浏览器直接访问 https://nodeip:10250/metrics, 会返回401 Unauthorized。
有两种方法可以在浏览器访问到这个Url:
-
一个是开启kubelet的非安全端口
-
二是通过apiserver的代理API去访问:
/api/v1/nodes/{nodeName}/proxy/metrics。比如,我们一个集群有两个节点$ kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
peng01 Ready master 35d v1.17.3 192.168.2.101CentOS Linux 7 (Core) 4.19.12-1.el7.elrepo.x86_64 docker://18.9.9
peng02 Ready28s v1.17.3 192.168.2.102 CentOS Linux 7 (Core) 4.19.12-1.el7.elrepo.x86_64 docker://19.3.12
我们可以通过以下两种方式,在浏览器中都可以访问到peng02的kubelet指标
方法一:kubelet的非安全端口
方法二:apiserver的代理API
从Kubelet获取节点运行状态
Kubelet组件运行在Kubernetes集群的各个节点中,其负责维护和管理节点上Pod的运行状态。kubelet组件的正常运行直接关系到该节点是否能够正常的被Kubernetes集群正常使用。
基于Node模式,Prometheus会自动发现Kubernetes中所有Node节点的信息并作为监控的目标Target。 而这些Target的访问地址实际上就是Kubelet的访问地址,并且Kubelet实际上直接内置了对Prometheus的支持。
修改prometheus.yml配置文件,并添加以下采集任务配置:
- job_name: 'kubernetes-kubelet'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
这里使用Node模式自动发现集群中所有Kubelet作为监控的数据采集目标,同时通过labelmap步骤,将Node节点上的标签,作为样本的标签保存到时间序列当中。
重新加载promethues配置文件,并重建Prometheus的Pod实例后,查看kubernetes-kubelet任务采集状态,我们会看到以下错误提示信息:
Get https://192.168.99.100:10250/metrics: x509: cannot validate certificate for 192.168.99.100 because it doesn't contain any IP SANs这是由于当前使用的ca证书中,并不包含192.168.99.100的地址信息。为了解决该问题,第一种方法是直接跳过ca证书校验过程,通过在tls_config中设置 insecure_skip_verify为true即可。 这样Prometheus在采集样本数据时,将会自动跳过ca证书的校验过程,从而从kubelet采集到监控数据:
- job_name: 'kubernetes-kubelet'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
监控Kubelet的指标
- job_name: kubelet
kubernetes_sd_configs:
- role: node由于prometheus中默认设置的kubelet的端口为10255,所以服务发现得到的Target的监听地址会是http://nodeip:10255/metrics,如下,很显然这是访问不通的
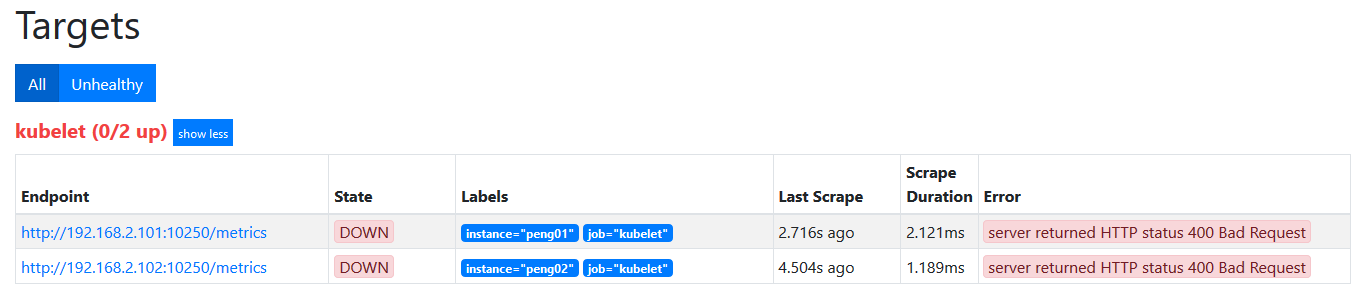
kubelet的安全端口需要认证与授权(参考《kubelet的认证》),kubelet的认证机制有两种,kubeadm安装集群使用的是x509客户证书认证。
在使用prometheus监控kubelet时,由于prometheus容器中没有客户端证书,所我们通过Apiserver的代理API去采集kubelet的指标。
第二种方式,不直接通过kubelet的metrics服务采集监控数据,而通过Kubernetes的api-server提供的代理API访问各个节点中kubelet的metrics服务。
编辑prometheus-config.yaml,在采集任务中添加以下内容:
- job_name: kubelet
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: replace
target_label: __address__
replacement: kubernetes.default.svc:443
- action: replace
source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics通过relabeling,将从Kubernetes获取到的默认地址__address__替换为kubernetes.default.svc:443。同时将__metrics_path__替换为api-server的代理地址/api/v1/nodes/${1}/proxy/metrics。
解释一下上面的配置。prometheus去采集kubelet时,kubelet指标的完整地址应该为
https://kubernetes.default.svc:443/api/v1/nodes/{nodeName}/proxy/metrics所以,scheme应该为https;tls_config与bearer_token_file的原理参考Kubernetes的《ServiceAccount》。
对于relabel_configs,__address__可以直接重置为kubernetes.default.svc:443。然后是__metrics_path__,值应该为/api/v1/nodes/{nodeName}/proxy/metrics,这个nodeName的值,我们要如何获取呢?
我们先看一下每个Target的初始指标有哪些,如下:

从上面可以发现,通过__meta_kubernetes_node_name可以拿到nodeName的值。对于relabel_configs的原理。
外置prometheus监控kubelet配置(prometheus不在k8s里面)
- job_name: k8s-kubelet
honor_timestamps: true
metrics_path: /metrics
scheme: https
kubernetes_sd_configs: # kubernetes 自动发现
- api_server: https://k8s-uat-api.ztoky.cn:6443 # apiserver 地址
role: node # node 类型的自动发现
bearer_token_file: /apps/svr/prometheus/k8s_cert/cadvisor_token
tls_config:
insecure_skip_verify: true
bearer_token_file: /apps/svr/prometheus/k8s_cert/cadvisor_token
tls_config:
insecure_skip_verify: true
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- separator: ;
regex: (.*)
target_label: __address__
replacement: 10.202.16.131:6443
action: replace
- action: replace
source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
通过获取各个节点中kubelet的监控指标,用户可以评估集群中各节点的性能表现。例如通过指标kubelet_pod_start_latency_microseconds可以获得当前节点中Pod启动时间相关的统计数据。
kubelet_pod_start_latency_microseconds{quantile="0.99"}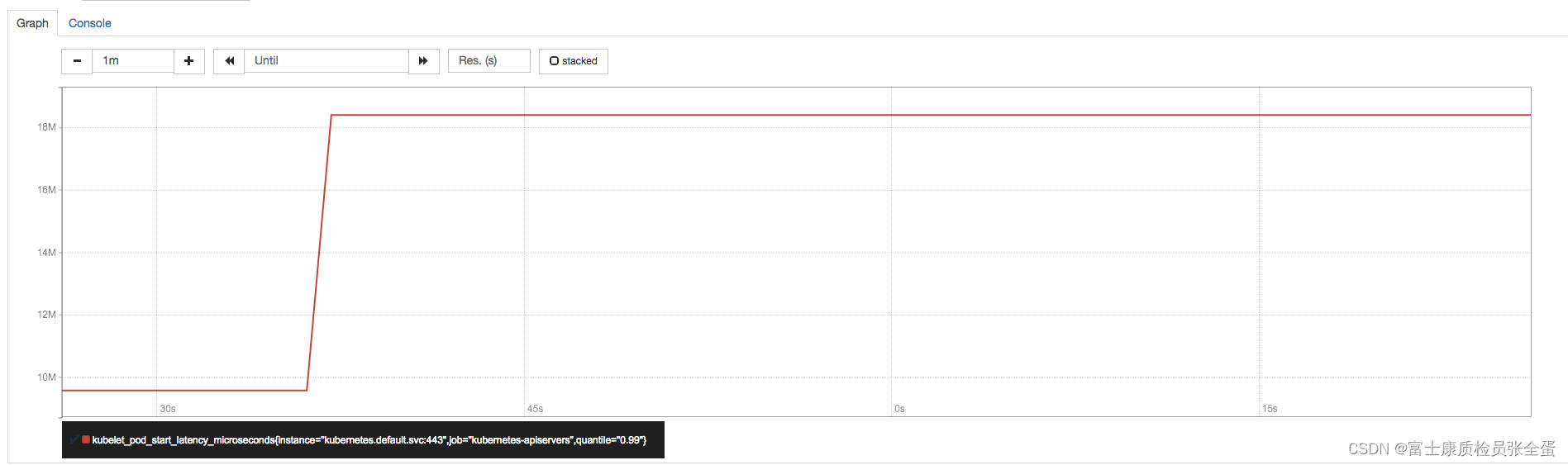
Pod平均启动时间大致为42s左右(包含镜像下载时间):
kubelet_pod_start_latency_microseconds_sum / kubelet_pod_start_latency_microseconds_count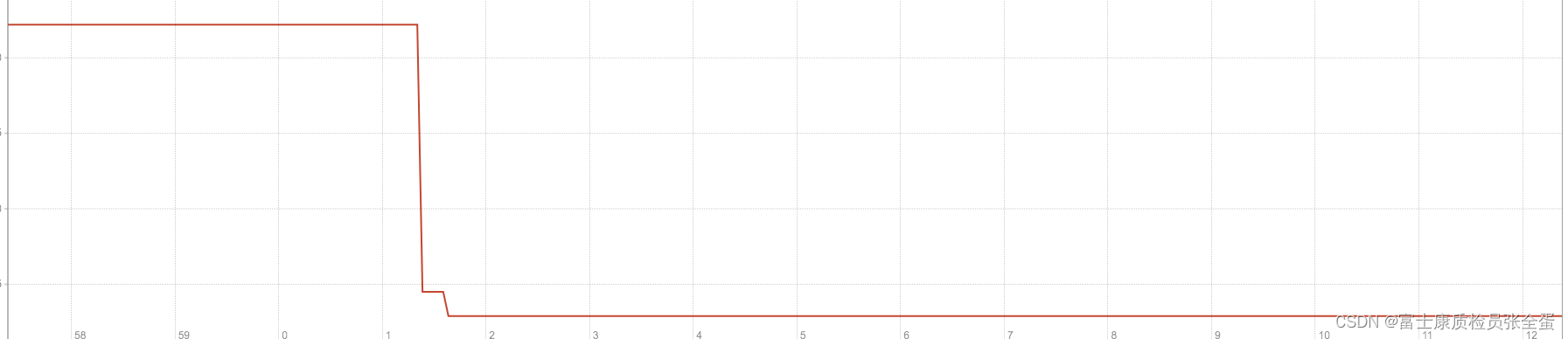
除此以外,监控指标kubelet_docker_*还可以体现出kubelet与当前节点的docker服务的调用情况,从而可以反映出docker本身是否会影响kubelet的性能表现等问题。