目录
一、实现原理
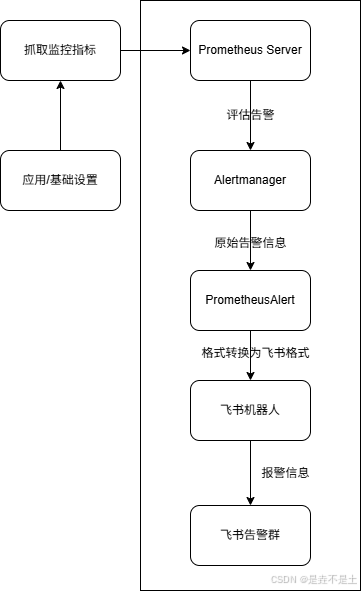
|-------------------|-------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------|
| 组件 | 核心职责 | 关键配置/说明 |
| Prometheus Server | 数据采集:通过Pull模式从监控目标(如Node Exporter)拉取指标。状态评估:根据配置的告警规则(rule_files),持续评估指标状态。触发告警:当指标满足条件(如CPU使用率>80%持续1分钟),生成Alert并发送至Alertmanager。 | 告警规则在prometheus.yml的rule_files部分定义。 |
| Alertmanager | 告警处理:接收Prometheus发送的告警,进行去重(避免重复报警)、分组(将同类告警合并)、抑制(当发生严重故障时,忽略次要告警)。路由分发:根据标签(如team: frontend)将告警路由到不同的接收器(如飞书、邮件等)。 | 在alertmanager.yml中配置route路由树和receivers。 |
| PrometheusAlert | 协议转换:作为中间桥梁,接收Alertmanager的Webhook请求,并将其转换为飞书机器人所能识别的JSON报文格式。消息模板化:将告警信息填充到预定义的飞书消息模板中,生成美观、易读的交互式卡片。 | 这是一个开源中间件,需要独立部署。它解决了Alertmanager不直接支持飞书的问题。 |
| 飞书机器人 | 消息投递:通过其唯一的Webhook URL接收来自PrometheusAlert的请求,将告警消息发送到指定的飞书群。交互入口:告警卡片可提供按钮(如"已处理"、"忽略"),方便团队快速响应。 | 在飞书群中创建机器人时,需设置安全密钥(如自定义关键词"告警"),并获取Webhook地址。 |
二、准备工作:
飞书机器人URL:
创建飞书群、创建机器人、复制URL:
bash
https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxxxxxxxxxxxxxxxx下载软件包:(除PrometheusAlert均可在Prometheus官方下载)
bash
alertmanager-0.28.1.linux-amd64.tar.gz
grafana-enterprise_12.2.0_17949786146_linux_amd64.tar.gz
linux.zip # 开源项目PrometheusAlert,github下载
mysqld_exporter-0.15.1.linux-amd64.tar.gz
node_exporter-1.8.1.linux-amd64.tar.gz
prometheus-3.5.0.linux-amd64.tar.gz
redis_exporter-v1.45.0.linux-amd64.tar.gz三、搭建Prometheus
bash
tar -zxvf prometheus-3.5.0.linux-amd64.tar.gz -C /data/
mv prometheus-3.5.0.linux-amd64/ prometheus
cd prometheus/
prometheus.yml promtool
./prometheus --version
prometheus, version 3.5.0 (branch: HEAD, revision: 8be3a9560fbdd18a94dedec4b747c35178177202)
build user: root@4451b64cb451
build date: 20250714-16:15:23
go version: go1.24.5
platform: linux/amd64
tags: netgo,builtinassets创建登陆密码:
bash
创建Prometheus登陆密码:
htpasswd -nBC 12 'admin-yyy' | tr -d ':\n'
# 根据密码生成字符串
vim web-config.yml
basic_auth_users:
# admin-yyy
admin: $2y$12$iyD9VLBiu2Gjkctbl3Tlbu4TjG9OaXndKBVgXm8nSSOCtcm/e8UUmroot编写配置文件
bash
vim prometheus.yml
# 全局配置
global:
scrape_interval: 15s # 设置抓取间隔为每15秒。默认是每1分钟。
evaluation_interval: 15s # 每15秒评估一次规则。默认也是每1分钟。
# scrape_timeout 使用全局默认值(10秒)。
# Alertmanager 配置
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# 加载规则文件,并根据 global 'evaluation_interval' 定期评估它们。
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# 包含一个抓取端点的抓取配置:
# 这里是 Prometheus 自身。
scrape_configs:
# job_name 会作为标签 `job=<job_name>` 添加到从该配置抓取的所有时序数据。
- job_name: "prometheus"
# metrics_path 默认为 '/metrics'
# scheme 默认为 'http'。
basic_auth:
username: 'admin' # 替换为你在 web-config.yml 中设置的实际用户名
password: 'admin' # 替换为你的明文密码
static_configs:
- targets: ["localhost:9090"]
# label_name 会作为标签 `label_name=<label_value>` 添加到任何从该配置抓取的时序数据。
labels:
app: "prometheus"编写Prometheus的rules:
bash
mkdir rules/
vim rules/Linux_rule.yml
root@dev:/data/prometheus# cat rules/Linux_rule.yml
groups:
- name: Linux-Server-预警
rules:
# CPU 高使用率
- alert: Linux CPU高使用率
expr: (1 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[2m]))) * 100 > 90
for: 1m
labels:
severity: warning
env: '{{ if eq $labels.instance "192.168.119.4:9100" }}dev{{ else if eq $labels.instance "192.168.119.3:9100" }}uat{{ else if eq $labels.instance "192.168.119.2:9100" }}prod{{ else }}unknown{{ end }}'
annotations:
summary: "CPU 高使用率 ({{ $labels.instance }})"
description: "{{ $labels.instance }} ({{ $labels.env }}) CPU 使用率已持续超过 {{ $value | printf \"%.2f\" }}%"
# 内存高使用率
- alert: Linux 内存高使用率
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 85
for: 1m
labels:
severity: warning
env: '{{ if eq $labels.instance "192.168.119.4:9100" }}dev{{ else if eq $labels.instance "192.168.119.3:9100" }}uat{{ else if eq $labels.instance "192.168.119.2:9100" }}prod{{ else }}unknown{{ end }}'
annotations:
summary: "内存高使用率 ({{ $labels.instance }})"
description: "{{ $labels.instance }} ({{ $labels.env }}) 内存使用率已持续超过 {{ $value | printf \"%.2f\" }}%"
# 磁盘空间不足
- alert: Linux 磁盘空间不足
expr: (1 - (node_filesystem_avail_bytes{fstype!~"tmpfs|overlay"} / node_filesystem_size_bytes{fstype!~"tmpfs|overlay"})) * 100 > 90
for: 3m
labels:
severity: critical
env: '{{ if eq $labels.instance "192.168.119.4:9100" }}dev{{ else if eq $labels.instance "192.168.119.3:9100" }}uat{{ else if eq $labels.instance "192.168.119.2:9100" }}prod{{ else }}unknown{{ end }}'
annotations:
summary: "磁盘空间不足 ({{ $labels.instance }})"
description: "{{ $labels.instance }} ({{ $labels.env }}) 磁盘使用率已持续超过 {{ $value | printf \"%.2f\" }}%"
# 节点不可达
- alert: Linux 节点不可达
expr: up{job="node_exporter"} == 0
for: 1m
labels:
severity: critical
env: '{{ if eq $labels.instance "192.168.119.4:9100" }}dev{{ else if eq $labels.instance "192.168.119.3:9100" }}uat{{ else if eq $labels.instance "192.168.119.2:9100" }}prod{{ else }}unknown{{ end }}'
annotations:
summary: "节点不可达 ({{ $labels.instance }})"
description: "{{ $labels.instance }} ({{ $labels.env }}) 无法访问,可能宕机或 Node Exporter 未运行"
# 网络流量异常(发送)
- alert: Linux 网络发送高流量
expr: rate(node_network_transmit_bytes_total[2m]) > 100000000
for: 2m
labels:
severity: warning
env: '{{ if eq $labels.instance "192.168.119.4:9100" }}dev{{ else if eq $labels.instance "192.168.119.3:9100" }}uat{{ else if eq $labels.instance "192.168.119.2:9100" }}prod{{ else }}unknown{{ end }}'
annotations:
summary: "网络发送流量高 ({{ $labels.instance }})"
description: "{{ $labels.instance }} ({{ $labels.env }}) 网络发送速率超过阈值 {{ $value | printf \"%.2f\" }} B/s"
# 网络流量异常(接收)
- alert: Linux 网络接收高流量
expr: rate(node_network_receive_bytes_total[2m]) > 100000000
for: 2m
labels:
severity: warning
env: '{{ if eq $labels.instance "192.168.119.4:9100" }}dev{{ else if eq $labels.instance "192.168.119.3:9100" }}uat{{ else if eq $labels.instance "192.168.119.2:9100" }}prod{{ else }}unknown{{ end }}'
annotations:
summary: "网络接收流量高 ({{ $labels.instance }})"
description: "{{ $labels.instance }} ({{ $labels.env }}) 网络接收速率超过阈值 {{ $value | printf \"%.2f\" }} B/s"
# 系统负载异常
- alert: Linux 系统负载过高
expr: node_load1 > 4
for: 5m
labels:
severity: warning
env: '{{ if eq $labels.instance "192.168.119.4:9100" }}dev{{ else if eq $labels.instance "192.168.119.3:9100" }}uat{{ else if eq $labels.instance "192.168.119.2:9100" }}prod{{ else }}unknown{{ end }}'
annotations:
summary: "系统负载高 ({{ $labels.instance }})"
description: "{{ $labels.instance }} ({{ $labels.env }}) 1分钟平均负载超过 {{ $value | printf \"%.2f\" }}"将Prometheus加入systemd管理
bash
vim /etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus Monitoring
Wants=network-online.target
After=network-online.target
[Service]
Type=simple
User=root
Group=root
# 工作目录
WorkingDirectory=/data/prometheus
# 启动命令
ExecStart=/data/prometheus/prometheus \
--config.file=/data/prometheus/prometheus.yml \
--storage.tsdb.path=/data/prometheus/data \
--web.config.file=/data/prometheus/web-config.yml
--web.console.templates=/data/prometheus/consoles \
--web.console.libraries=/data/prometheus/console_libraries
Restart=on-failure
RestartSec=5s
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
# 启动服务
systemctl daemon-reload
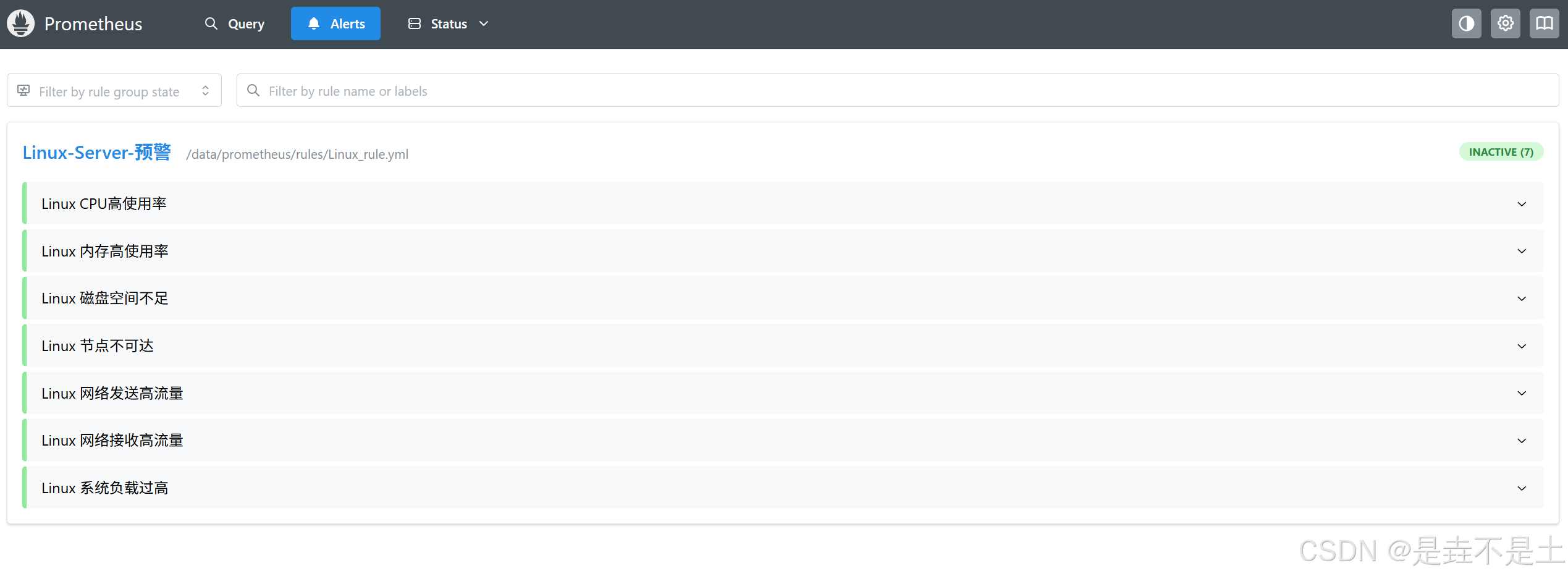
systemctl start prometheus 访问端口9090

 四、搭建node_exporter
四、搭建node_exporter
bash
tar -zxf node_exporter-1.8.1.linux-amd64.tar.gz -C /data/prometheus/node_exporter/
cd /data/prometheus/
mv node_exporter/node_exporter-1.8.1.linux-amd64/* node_exporter/
cd node_exporter/写入system并启动:
bash
vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
After=network.target
[Service]
ExecStart=/data/prometheus/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start node_exporter编写Prometheus配置文件
bash
/data/prometheus
root@dev:/data/prometheus# vim prometheus.yml
- job_name: "node_exporter"
static_configs:
# DEV 环境节点
- targets: ['192.168.119.4:9100']
labels:
instance: '192.168.119.4:9100'
env: 'dev'
# UAT 环境节点
- targets: ['192.168.119.3:9100']
labels:
instance: '192.168.119.3:9100'
env: 'uat'
# PROD 环境节点
- targets: ['192.168.119.2:9100']
labels:
instance: '192.168.119.2:9100'
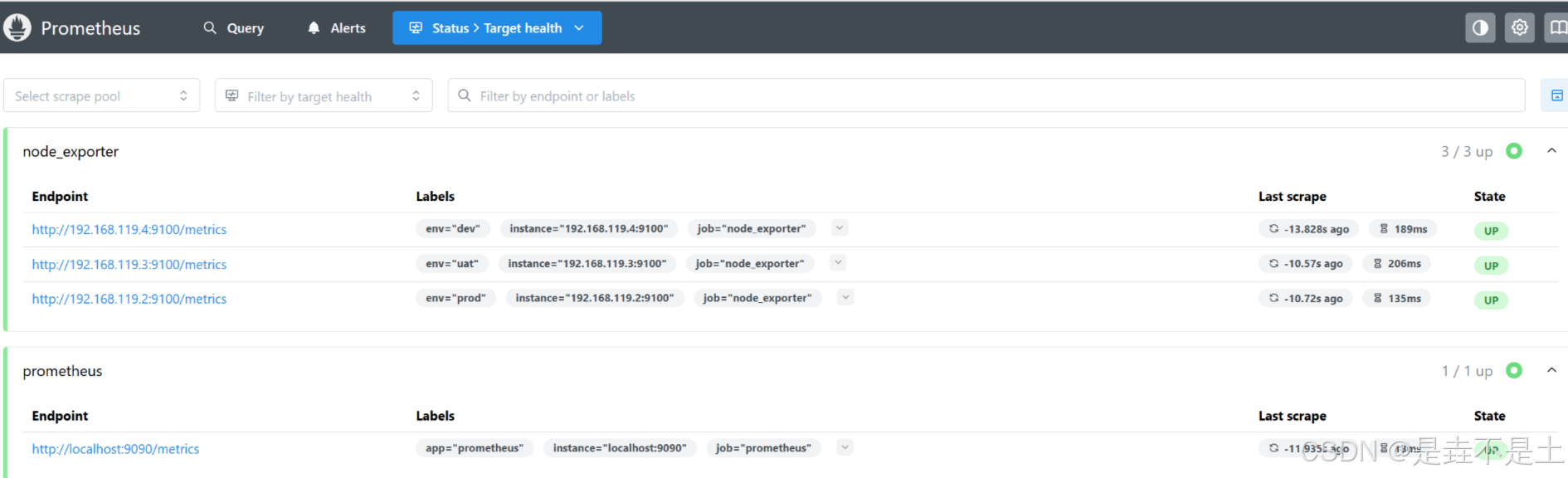
env: 'prod'重启Prometheus后进行查看:
五、搭建Alertmanager
bash
pwd
/usr/local/src/prometheus
# 解压服务
tar -zxvf alertmanager-0.28.1.linux-amd64.tar.gz -C /data/prometheus/
# 编辑配置文件
cd /data/prometheus/alertmanager
vim alertmanager.yml
global:
# 告警解决超时时间,超过时间告警自动标记为已解决
resolve_timeout: 5m
route:
# 按哪些标签分组告警
group_by: ['alertname']
# 当新的告警进入组时等待多久再发送通知
group_wait: 30s
# 同一组告警的重复发送间隔
group_interval: 5m
# 相同告警重复通知的时间间隔
repeat_interval: 1h
# 默认接收者
receiver: 'feishu-webhook'
receivers:
- name: 'feishu-webhook'
webhook_configs:
- url: http://localhost:15103/prometheusalert?type=fs&tpl=prometheus-fs&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxxxxxxxx
# 告警恢复后是否发送通知
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical' # 高级别告警来源
target_match:
severity: 'warning' # 需要被抑制的低级别告警
equal: ['alertname', 'dev', 'instance'] # 当这些标签相同,低级别告警被抑制写入systemd启动,启动alertmanager:
bash
vim /etc/systemd/system/alertmanager.service
[Unit]
Description=Prometheus Alertmanager
After=network.target
[Service]
Type=simple
User=root
ExecStart=/data/prometheus/alertmanager/alertmanager \
--config.file=/data/prometheus/alertmanager/alertmanager.yml \
--storage.path=/data/prometheus/alertmanager/data \
--web.listen-address=:15104 \
--cluster.listen-address=""
Restart=on-failure
[Install]
WantedBy=multi-user.target
# 启动服务
systemctl daemon-reload
systemctl start alertmanager
# 检测端口是否存在,是否可以访问
netstat -lnpt | grep 15104
tcp6 0 0 :::15104 :::* LISTEN 166255/alertmanager 
六、安装PrometheusAlert
bash
pwd
/usr/local/src/prometheus
unzip linux.zip
mv linux /data/prometheus/
# 编辑配置文件
vim linux/conf/app.conf
appname = PrometheusAlert
#登录用户名
login_user=admin
#登录密码
login_password=admin
#监听地址
httpaddr = "0.0.0.0"
#监听端口
httpport = 15103
runmode = dev
#是否开启飞书告警通道,可同时开始多个通道0为关闭,1为开启
open-feishu=1
#默认飞书机器人地址
fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxxxxxxxx
# webhook 发送 http 请求的 contentType, 如 application/json, application/x-www-form-urlencoded,不配置默认 application/json
wh_contenttype=application/json写入systemd启动柜,并完成启动:
bash
vim /etc/systemd/system/prometheusalert.service
[Unit]
Description=PrometheusAlert Service
After=network.target
[Service]
Type=simple
User=root
ExecStart=/data/prometheus/linux/PrometheusAlert -c /data/prometheus/linux/conf/app.conf
WorkingDirectory=/data/prometheus/linux
Restart=always
RestartSec=5s
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=PrometheusAlert
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start prometheusalert
编写飞书模版:Prometheus-fsv2
bash
{{ $var := .externalURL }}
{{ range $k, $v := .alerts }}
{{ if eq $v.status "resolved" }}
**[Prometheus 恢复通知]({{$v.generatorURL}})**
告警名称:{{$v.labels.alertname}}
告警状态:已恢复 > {{$v.labels.severity}}
开始时间:{{GetCSTtime $v.startsAt}}
结束时间:{{GetCSTtime $v.endsAt}}
实例地址:{{$v.labels.instance}}
主机环境:{{if $v.labels.env}}{{$v.labels.env}}{{else}}未知{{end}}
{{ if $v.annotations.recovery }}
**恢复详情:{{$v.annotations.recovery}}**
{{ else }}
**恢复详情:{{$v.labels.instance}} ({{$v.labels.env}}) 已恢复正常**
{{ end }}
{{/* 设置恢复通知卡片为绿色 */}}
<font color="green">✔️ 恢复</font>
{{ else }}
**[Prometheus 告警通知]({{$v.generatorURL}})**
告警名称:{{$v.labels.alertname}}
告警状态:触发中 > {{$v.labels.severity}}
开始时间:{{GetCSTtime $v.startsAt}}
实例地址:{{$v.labels.instance}}
主机环境:{{if $v.labels.env}}{{$v.labels.env}}{{else}}未知{{end}}
{{ if $v.annotations.description }}
**告警详情:{{$v.annotations.description}}**
{{ else }}
**告警详情:暂无说明**
{{ end }}
{{/* 设置告警通知卡片为红色 */}}
<font color="red">❌ 告警</font>
{{ end }}
{{ end }}七、飞书告警测试
测试内容:
-
停止uat的node_exporter,最快通知时间(预测1.5min)
-
查看飞书消息是否正常
-
查看指示颜色是否正常
-
恢复node_exporter后,恢复后最快通知时间(预测5min)
停止node_exporter:

1min后评估结束,确认为Firing:
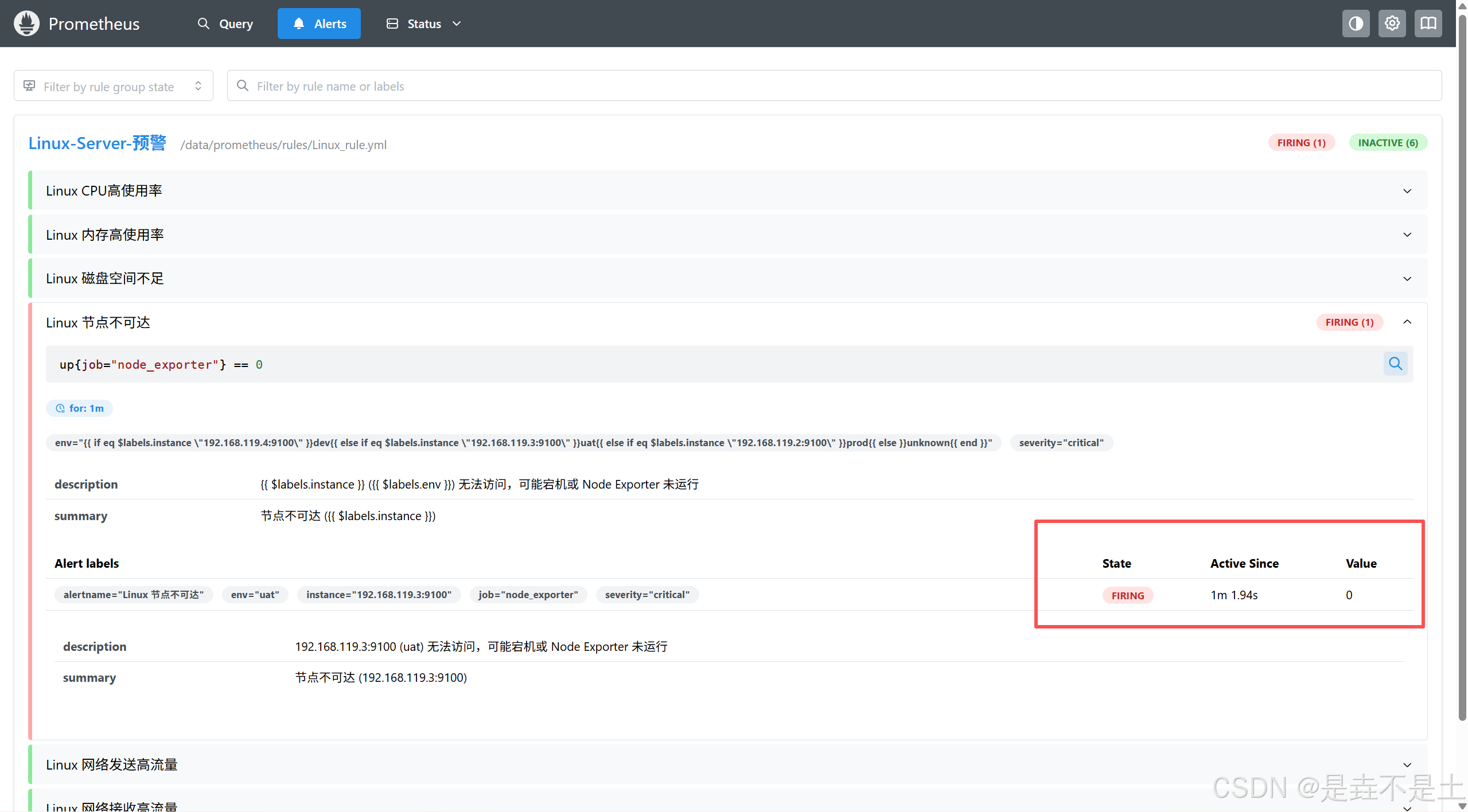
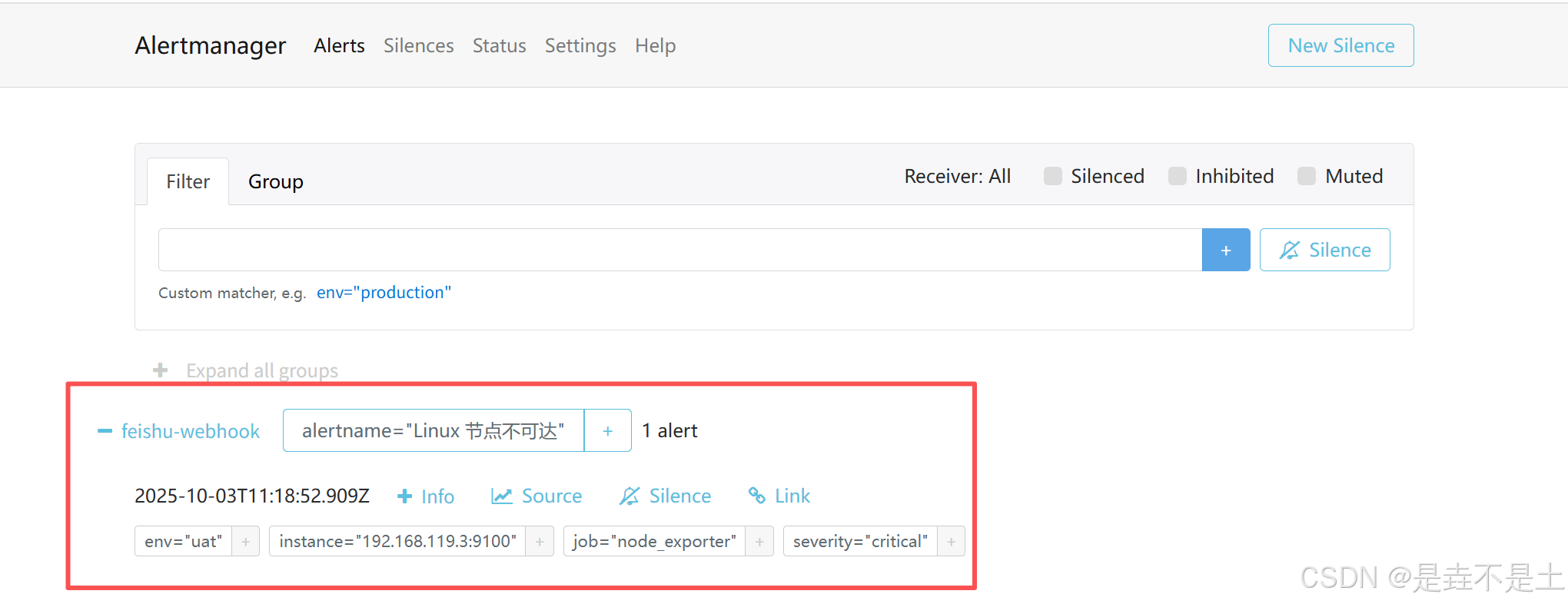
Alertmanager发送webhook:
飞书收到消息:
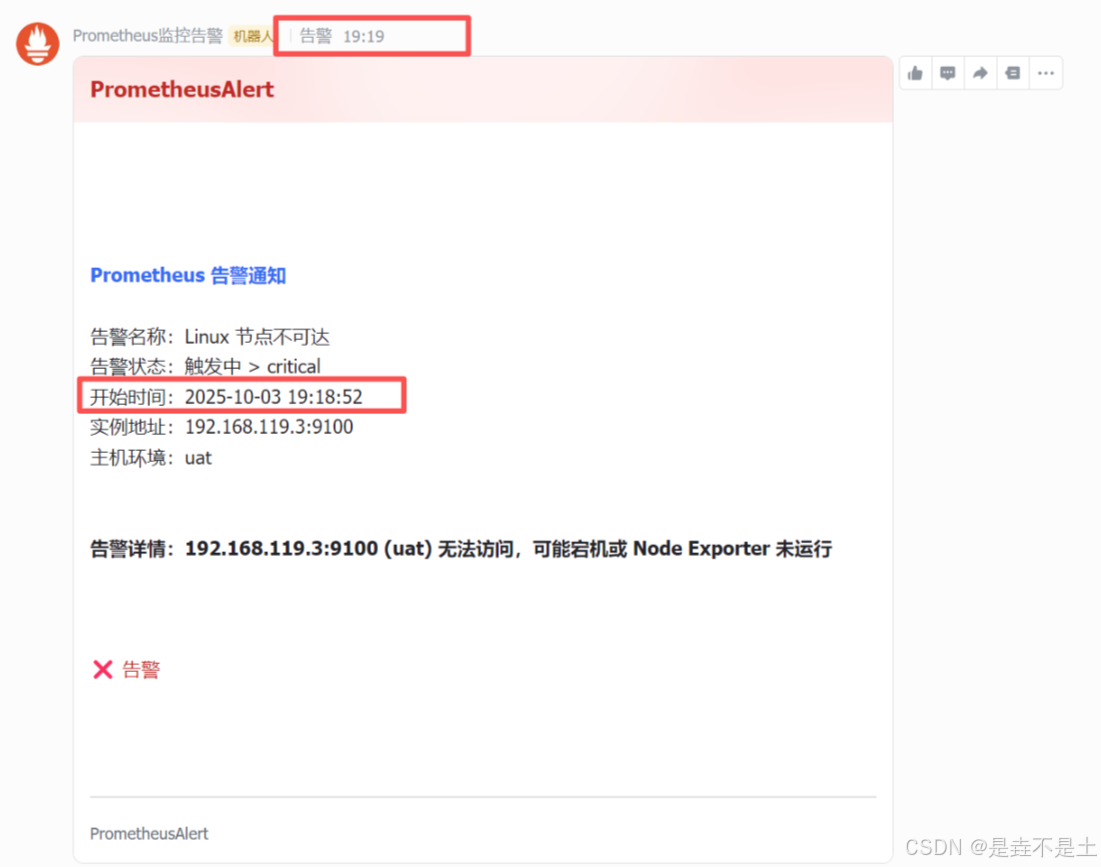
恢复node_exporter :
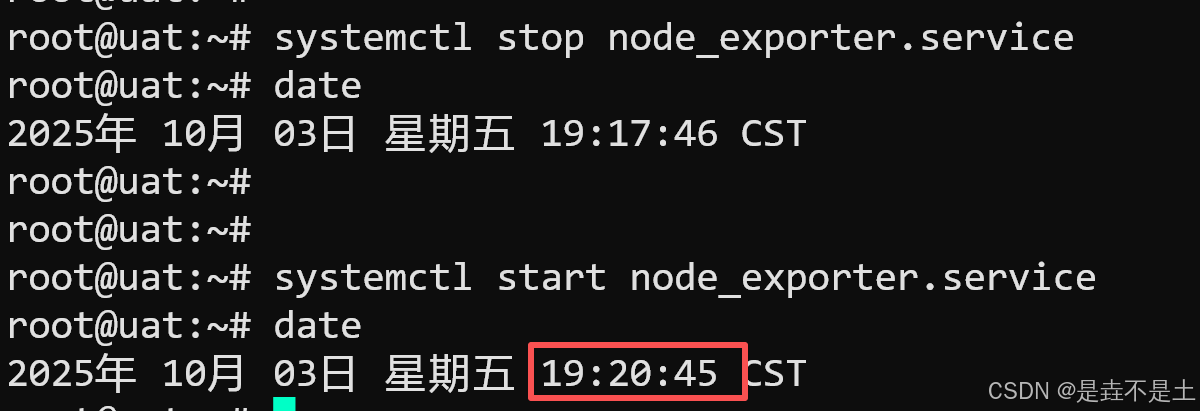
进行PrometheusServer进行评估,评估后发送信息:
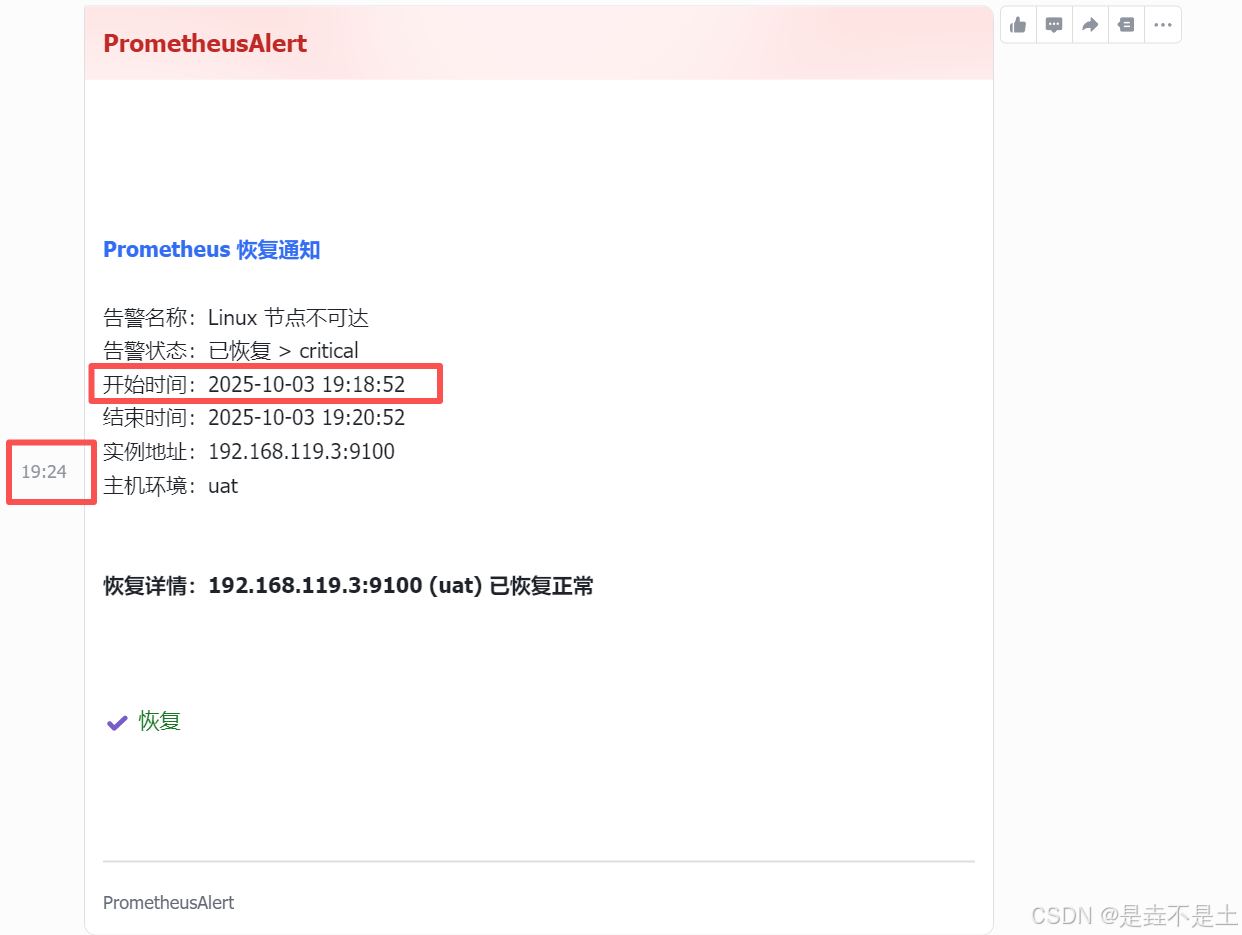
至此,全链路自动化告警搭建完成。