本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。
本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。
Apache Seata新特性支持 -- undo_log压缩
Seata新特性支持 -- undo_log压缩
现状 & 痛点
对于Seata而言,是通过记录DML操作的前后的数据用于进行后续可能的回滚操作的,并且把这些数据保存到数据库的一个blob的字段里面。对于批量插入,更新,删除等操作,其影响的行数可能会比较多,拼接成一个大的字段插入到数据库,可能会带来以下问题:
- 超出数据库单次操作的最大写入限制(比如MySQL的max_allowed_package参数);
- 较大的数据量带来的网络IO和数据库磁盘IO开销比较大。
头脑风暴
对于第1点的问题,可以根据业务的实际情况,调大max_allowed_package参数的限制,从而避免出现query is too large的问题;对于第2点,可以通过提高带宽和选用高性能的SSD作为数据库的存储介质。
以上都是通过外部方案或者加钱方案去解决的。那么有没有框架层面解决方案以解决上面的痛点?
此时结合到以上的痛点出现的根源,在于生成的数据字段过大。为此,如果可以把对应的数据进行业务方压缩之后,再进行数据传输以及落库,理论上也可以解决上面的问题。
可行性分析
结合以上头脑风暴的内容,考虑在实际开发中,当需要进行大批量操作的时候,大多会选在较少用户操作,并发相对较低的时间点执行,此时CPU,内存等资源可以相对占用多一点以快速完成对应的操作。因此,可以通过消耗CPU资源和内存资源,来对对应的回滚的数据进行压缩,从而缩小数据传输和存储的大小。
此时,还需要证明以下两件事:
- 经过压缩之后,可以减少网络IO和数据库磁盘IO的压力,这里可以采用数据压缩+落库完成的总时间作为侧面参考指标。
- 经过压缩之后,数据大小跟原来比较的压缩效率有多高,这里使用压缩前后的数据大小来作为指标。
压缩网络用时指标测试:
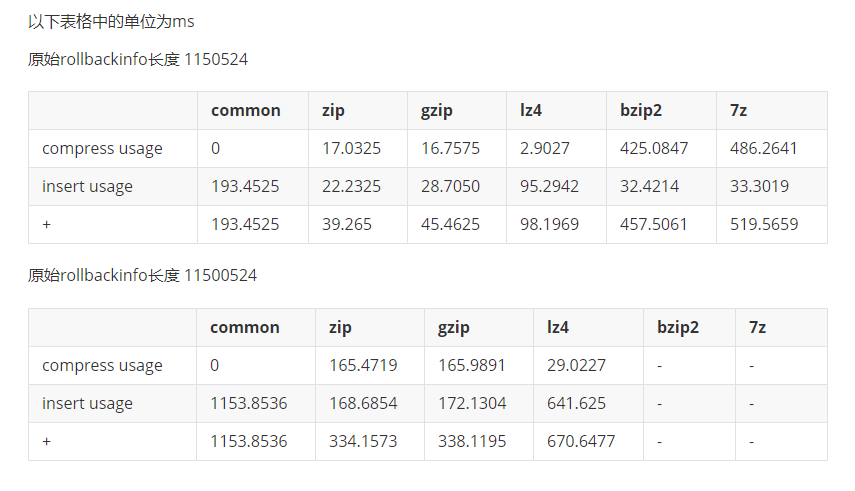
压缩比测试:

通过以上的测试结果,可以明显的看出,使用gzip或zip进行压缩的情况下,可以较大程度的减少数据库的压力和网络传输的压力,同时也可以较大幅度的减少保存的数据的大小。
实现
实现思路

部分代码
properties配置:
properties
# 是否开启undo_log压缩,默认为true
seata.client.undo.compress.enable=true
# 压缩器类型,默认为zip,一般建议都是zip
seata.client.undo.compress.type=zip
# 启动压缩的阈值,默认为64k
seata.client.undo.compress.threshold=64k判断是否开启了undo_log压缩功能以及是否达到压缩的阈值:
java
protected boolean needCompress(byte[] undoLogContent) {
// 1. 判断是否开启了undo_log压缩功能(1.4.2默认开启)
// 2. 判断是否达到了压缩的阈值(默认64k)
// 如果都满足返回需要对对应的undoLogContent进行压缩
return ROLLBACK_INFO_COMPRESS_ENABLE
&& undoLogContent.length > ROLLBACK_INFO_COMPRESS_THRESHOLD;
}确定需要压缩后,对undo_log进行压缩:
java
// 如果需要压缩,对undo_log进行压缩
if (needCompress(undoLogContent)) {
// 获取压缩类型,默认zip
compressorType = ROLLBACK_INFO_COMPRESS_TYPE;
// 获取对应的压缩器,并且进行压缩
undoLogContent = CompressorFactory.getCompressor(compressorType.getCode()).compress(undoLogContent);
}
// else 不需要压缩就不需要做任何操作将压缩类型同步保存到数据库,供回滚时使用:
java
protected String buildContext(String serializer, CompressorType compressorType) {
Map<String, String> map = new HashMap<>();
map.put(UndoLogConstants.SERIALIZER_KEY, serializer);
// 保存压缩类型到数据库
map.put(UndoLogConstants.COMPRESSOR_TYPE_KEY, compressorType.name());
return CollectionUtils.encodeMap(map);
}回滚时解压缩对应的信息:
java
protected byte[] getRollbackInfo(ResultSet rs) throws SQLException {
// 获取保存到数据库的回滚信息的字节数组
byte[] rollbackInfo = rs.getBytes(ClientTableColumnsName.UNDO_LOG_ROLLBACK_INFO);
// 获取压缩类型
// getOrDefault使用默认值CompressorType.NONE来兼容1.4.2之前的版本直接升级1.4.2+
String rollbackInfoContext = rs.getString(ClientTableColumnsName.UNDO_LOG_CONTEXT);
Map<String, String> context = CollectionUtils.decodeMap(rollbackInfoContext);
CompressorType compressorType = CompressorType.getByName(context.getOrDefault(UndoLogConstants.COMPRESSOR_TYPE_KEY,
CompressorType.NONE.name()));
// 获取对应的压缩器,并且解压缩
return CompressorFactory.getCompressor(compressorType.getCode())
.decompress(rollbackInfo);
}结语
通过对undo_log的压缩,在框架层面,进一步提高Seata在处理数据量较大的时候的性能。同时,也提供了对应的开关和相对合理的默认值,既方便用户进行开箱即用,也方便用户根据实际需求进行一定的调整,使得对应的功能更适合实际使用场景。