文章目录
- 【简历写法】
- 【常见面试题】
- [1. 什么是缓存?](#1. 什么是缓存?)
- [2. 请说说有哪些缓存算法?是否能手写一下LRU代码的实现?](#2. 请说说有哪些缓存算法?是否能手写一下LRU代码的实现?)
- [3. 请简述一下项目整体架构。举个例子说明下数据流转过程](#3. 请简述一下项目整体架构。举个例子说明下数据流转过程)
- [4. 项目中为什么选择使用一致性哈希?它相比普通的哈希取模方式有什么优势](#4. 项目中为什么选择使用一致性哈希?它相比普通的哈希取模方式有什么优势)
- [5. 你对一致性哈希的实现有什么优化么](#5. 你对一致性哈希的实现有什么优化么)
- [6. 请解释一下缓存穿透、缓存击穿和缓存雪崩,你在项目中是如何应对这些问题的](#6. 请解释一下缓存穿透、缓存击穿和缓存雪崩,你在项目中是如何应对这些问题的)
-
- [1. 缓存穿透 (Cache Penetration)](#1. 缓存穿透 (Cache Penetration))
- [2. 缓存击穿 (Cache Breakdown)](#2. 缓存击穿 (Cache Breakdown))
- [3. 缓存雪崩 (Cache Avalanche)](#3. 缓存雪崩 (Cache Avalanche))
- [7. singleflight 的实现中为什么使用sync.Map而不是map+sync.RWMutex,它们的适用场景有什么不同](#7. singleflight 的实现中为什么使用sync.Map而不是map+sync.RWMutex,它们的适用场景有什么不同)
-
- [map + sync.RWMutex](#map + sync.RWMutex)
- sync.Map
- [8. 请简述 LRU 算法的原理,你这里的 LRU2 相比普通 LRU 有什么优势](#8. 请简述 LRU 算法的原理,你这里的 LRU2 相比普通 LRU 有什么优势)
- [9. 使用 etcd 做服务注册时有租约机制,请解释一下租约的作用是什么?如果某个缓存节点突然宕机,整个集群是如何感知到这个变化并调整工作状态的?](#9. 使用 etcd 做服务注册时有租约机制,请解释一下租约的作用是什么?如果某个缓存节点突然宕机,整个集群是如何感知到这个变化并调整工作状态的?)
-
- [1. 租约 (Lease) 的作用:](#1. 租约 (Lease) 的作用:)
- [2. 节点宕机后的感知与调整流程:](#2. 节点宕机后的感知与调整流程:)
- [10. 项目选择了 gRPC 作为节点间的通信协议,相比于更常见的 RESTful API,gRPC 和 Protobuf 有哪些优势?](#10. 项目选择了 gRPC 作为节点间的通信协议,相比于更常见的 RESTful API,gRPC 和 Protobuf 有哪些优势?)
- [11. 缓存的并发安全需要锁或原子操作来保证,解释一下互斥锁 (Mutex) 和原子操作 (Atomic) 的区别,以及它们各自的适用场景](#11. 缓存的并发安全需要锁或原子操作来保证,解释一下互斥锁 (Mutex) 和原子操作 (Atomic) 的区别,以及它们各自的适用场景)
-
- [互斥锁 (Mutex/RWMutex):](#互斥锁 (Mutex/RWMutex):)
- [原子操作 (Atomic):](#原子操作 (Atomic):)
- [GoCache 中如何使用的:](#GoCache 中如何使用的:)
- [12. 谈谈你对 CAP 理论的理解,etcd 是如何做取舍的?](#12. 谈谈你对 CAP 理论的理解,etcd 是如何做取舍的?)
- [etcd 如何保证的一致性?介绍下它使用的协议](#etcd 如何保证的一致性?介绍下它使用的协议)
【简历写法】
项目: 分布式缓存系统 LCache
项目描述: 基于GO语言实现的高性能分布式缓存系统 ,支持多种缓存淘汰策略和分布式协调机制。项目设计注重系统的可扩展性、高并发性和容错性,实现了在分布式环境下的高效数据共享和访问。
个人工作:
• 实现了LRU和LRU2缓存淘汰算法 ,针对不同访问模式优化缓存命中率;
• 设计实现了自适应一致性哈希算法,支持虚拟节点和动态负载均衡,确保数据均匀分布 ;
• 实现了分段锁和两级缓存结构,有效减少锁争用,提升高并发场景下的系统吞吐量
• 实现了基于SingleFlight的请求合并机制,防止缓存击穿,降低后端服务压力 ;
• 基于etcd设计实现了服务注册发现模块,支持自动节点管理和健康检查 ;
• 实现了基于gRPC的高性能节点间通信协议,保证分布式环境下的数据一致性 ;
• 设计实现了优雅关闭和资源回收机制,确保系统稳定性和资源释放。
项目难点:
- 分布式一致性保证: 设计并实现节点间数据同步协议,确保在节点增删和网络分区情况下的数据一致性;
- 高并发设计: 通过分段锁、原子操作和无锁数据结构,优化高并发下的系统性能;
- 缓存穿透和击穿防护: 设计实现请求合并和过期策略,防止缓存失效导致的系统压力;
- 动态负载均衡: 实现自适应一致性哈希算法,在保证数据分布均匀的同时支持动态节点管理;
- 高效内存管理: 通过预分配内存和双层缓存结构,减少GC压力并提高内存利用率。
个人收获:
- 深入理解了分布式系统设计原则和最佳实践,特别是在数据一致性和可用性方面;
- 掌握了高并发编程技术,包括细粒度锁设计、原子操作和无锁编程;
- 提升了Go语言在系统级编程中的应用能力,特别是在协程和通道管理方面;
- 学习了各种缓存淘汰策略的实现和优化方法,以及在实际场景中的应用;
- 掌握了基于etcd的分布式协调技术和服务发现机制;
- 增强了对系统性能分析和优化的能力,能够识别瓶颈并进行有针对性的改进。
【常见面试题】
1. 什么是缓存?

2. 请说说有哪些缓存算法?是否能手写一下LRU代码的实现?

go
package main
import (
"container/list"
"fmt"
)
type CacheNode struct {
key int
value int
}
type LRUCache struct {
capacity int
cacheList *list.List // 双向链表,存储缓存数据
cacheMap map[int]*list.Element // 哈希表,存储键和对应在双向链表中的元素指针
}
func NewLRUCache(capacity int) *LRUCache {
return &LRUCache{
capacity: capacity,
cacheList: list.New(),
cacheMap: make(map[int]*list.Element),
}
}
func (cache *LRUCache) Get(key int) int {
element, ok := cache.cacheMap[key]
if !ok {
return -1 // 未找到
}
// 将访问的节点移动到双向链表的头部
cache.cacheList.MoveToFront(element)
return element.Value.(*CacheNode).value
}
func (cache *LRUCache) Put(key int, value int) {
element, ok := cache.cacheMap[key]
if ok {
// 如果键已存在,更新值,并将其移动到双向链表的头部
element.Value.(*CacheNode).value = value
cache.cacheList.MoveToFront(element)
return
}
if len(cache.cacheMap) == cache.capacity {
// 如果缓存已满,移除双向链表的尾节点
back := cache.cacheList.Back()
if back != nil {
delete(cache.cacheMap, back.Value.(*CacheNode).key)
cache.cacheList.Remove(back)
}
}
// 添加新节点到双向链表的头部
node := &CacheNode{key: key, value: value}
element = cache.cacheList.PushFront(node)
cache.cacheMap[key] = element
}
func main() {
cache := NewLRUCache(2)
cache.Put(1, 1)
cache.Put(2, 2)
fmt.Println(cache.Get(1)) // 返回 1
cache.Put(3, 3) // 淘汰键2
fmt.Println(cache.Get(2)) // 返回 -1 (未找到)
cache.Put(4, 4) // 淘汰键1
fmt.Println(cache.Get(1)) // 返回 -1 (未找到)
fmt.Println(cache.Get(3)) // 返回 3
fmt.Println(cache.Get(4)) // 返回 4
}3. 请简述一下项目整体架构。举个例子说明下数据流转过程


把它想成:A 先自己找;找不到就问"通讯录/路由器";知道该问谁就打电话去要;拿到后顺手自己也缓存一份。


bash
参与者:
App(A) = 节点A上的业务代码
Group(A) = A节点的 Group("test")
Cache(A) = A节点的 mainCache
Picker(A) = A节点的 peers(ClientPicker)
PeerClient = A节点里指向B节点的 gRPC Client (实现 Peer 接口)
Server(B) = B节点的 gRPC Server
Group(B) = B节点的 Group("test")
Cache(B) = B节点的 mainCache
Getter(A) = A节点的数据源 getter(只有远程失败才走)
------------------------------------------------------------
App(A)
|
| 1) group.Get(ctx, "key_B")
v
Group(A).Get(ctx, key_B)
|-- (可选) atomic.LoadInt32(&g.closed) 检查是否关闭
|
| 2) 本地查缓存
|----> Cache(A).Get(ctx, "key_B")
| |
| | 2.1) 未命中 (miss)
| v
| return (ByteView{}, false)
|
| 3) 本地 miss -> 进入 load
v
Group(A).load(ctx, "key_B")
|
| 4) singleflight 合并并发:同一个 key 同一时刻只会真的加载一次
|----> g.loader.Do("key_B", fn)
| |
| | fn = g.loadData(ctx, "key_B")
| v
| Group(A).loadData(ctx, "key_B")
| |
| | 5) 选负责该 key 的节点 (一致性哈希)
| |----> Picker(A).PickPeer("key_B")
| | |
| | | 5.1) consistenthash.Map.Get("key_B") => 返回 B 的地址
| | v
| | return (PeerClient->B, ok=true, isSelf=false)
| |
| | 6) 远程拉取
| |----> Group(A).getFromPeer(ctx, PeerClient->B, "key_B")
| | |
| | | 6.1) PeerClient->B.Get(group="test", key="key_B")
| | | (gRPC 请求:pb.Request{Group:"test", Key:"key_B"})
| | v
| | ---- gRPC -----> Server(B).Get(ctx, req)
| | |
| | | 7) B侧处理:找到 Group
| | |----> GetGroup("test") => Group(B)
| | |
| | | 8) B侧再走一遍 Group.Get(但这次本地会命中)
| | |----> Group(B).Get(ctx, "key_B")
| | | |
| | | | 8.1) Cache(B).Get(ctx, "key_B") => hit
| | | v
| | | return ByteView("这是节点B的数据"), nil
| | |
| | | 9) B返回 gRPC 响应 pb.ResponseForGet{Value:...}
| | <---- gRPC ----- v
| | return []byte("这是节点B的数据"), nil
| |
| | 10) A侧 loadData 收到远程数据 -> 返回 ByteView
| v
| return ByteView{b: bytes}, nil
|
| 11) singleflight.Do 返回 viewi
| 12) A侧把结果写回本地缓存(加速下次)
|----> Cache(A).Add / AddWithExpiration("key_B", view)
|
v
return ByteView("这是节点B的数据"), nil
|
v
App(A) 拿到结果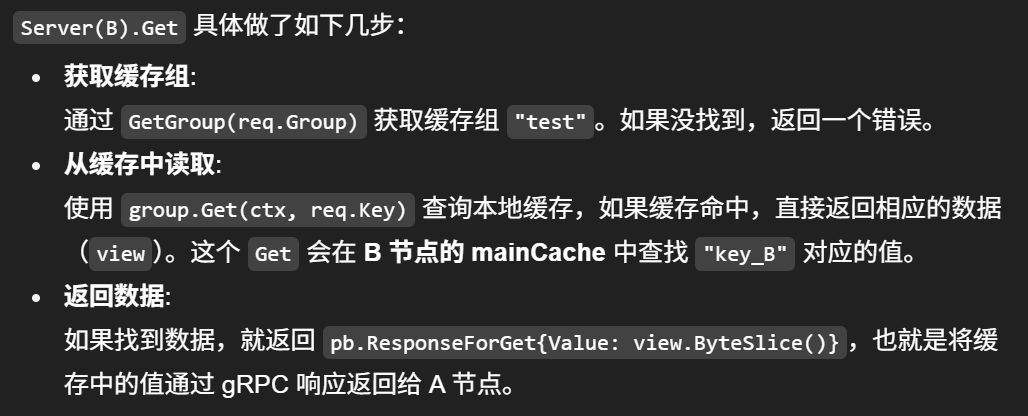
4. 项目中为什么选择使用一致性哈希?它相比普通的哈希取模方式有什么优势

5. 你对一致性哈希的实现有什么优化么
优化一:虚拟节点

优化二:动态负载均衡

6. 请解释一下缓存穿透、缓存击穿和缓存雪崩,你在项目中是如何应对这些问题的
1. 缓存穿透 (Cache Penetration)
-
定义 :指查询一个绝对不存在 的数据。由于缓存中没有(缓存的是已存在的数据),请求会直接打到后端的数据库。如果有人恶意利用这个漏洞,用大量不存在的 key 进行攻击,就会给数据库带来巨大压力。
-
GoCache 的应对:
- 现有机制 :当前代码实现没有直接处理缓存穿透。当 getter(数据源加载函数)返回错误(例如数据库查不到记录)时,这个错误会直接返回给调用方。
- 改进方案(虽然没实现,但面试时方案该说还得说) :
- 缓存空值(Cache Nulls):当数据库查询不到数据时,我们仍然在缓存中为这个 key 存一个特殊的值(例如一个空对象或约定的字符串),并设置一个较短的过期时间。这样后续对该 key 的查询会直接命中缓存里的"空值",而不会再访问数据库。
- 布隆过滤器(Bloom Filter) :在访问缓存之前,使用布隆过滤器快速判断一个 key 是否可能存在。布隆过滤器可以高效地判断一个元素肯定不存在,但判断存在时有小概率的误判。将全量或热点数据 key 存入布隆过滤器,查询时先过一遍过滤器,如果 key 不存在,直接返回,避免了后续对缓存和数据库的查询。
2. 缓存击穿 (Cache Breakdown)
-
定义 :指一个热点数据 key 刚刚过期失效,此时瞬时有大量的并发请求访问这个 key。由于缓存未命中,这些请求会同时穿透到后端数据库,导致数据库压力剧增。
-
GoCache 的应对:
- 核心机制:SingleFlight。
- 实现分析 :在
group.go的load方法中,所有的数据加载逻辑(包括远程获取和本地回源)都被包裹在g.loader.Do()中。singleflight.Group保证了对于同一个 key,在fn函数(即实际的加载逻辑)执行完成前,后续的Do调用都会阻塞等待,直到第一个请求完成,然后所有等待者共享这唯一一次的执行结果。 - 效果 :即使成千上万个请求同时访问一个刚过期的热点 key,最终也只会有一个请求去执行
loadData(访问远程节点或数据库),其他请求全部等待。这有效地防止了大量请求同时冲击后端数据源。
3. 缓存雪崩 (Cache Avalanche)
-
定义:指在某一瞬间,缓存中大量的 key 同时过期,或者缓存服务自身宕机,导致海量的请求直接涌向数据库,造成数据库崩溃。
-
GoCache 的应对:
- 针对大量 key 同时过期 :
- 现有机制 :
WithExpiration选项可以为 Group 内的所有 key 设置一个统一的过期时间。可以在设置过期时间时引入一个随机扰动(Jitter),避免集中失效。
- 现有机制 :
- 针对缓存服务宕机 :
- 高可用架构:GoCache 本身是一个分布式系统,单个节点的宕机不会导致整个缓存服务不可用。
- 一致性哈希:当某个节点宕机后,etcd 的租约(lease)会过期,服务发现机制会将其从节点列表中移除。根据一致性哈希的特性,只有原先由该宕机节点负责的那些 key 会失效并需要重新映射到其他节点,而其他节点上的缓存数据不受影响。这大大降低了单点故障带来的影响范围,避免了全局性的缓存雪崩。
- 针对大量 key 同时过期 :
7. singleflight 的实现中为什么使用sync.Map而不是map+sync.RWMutex,它们的适用场景有什么不同
map + sync.RWMutex

sync.Map



go
func (g *Group) Do(key string, fn func() (any, error)) (any, error) {
// 先准备一个"占位 call",可能会被存进去,也可能不用
c := &call{}
c.wg.Add(1)
// 原子操作:要么我把 c 放进去成为"第一个",要么拿到别人放进去的 call
actual, loaded := g.m.LoadOrStore(key, c)
if loaded {
// 已经有人在跑这个 key 了,我等它跑完,直接复用它的结果
c2 := actual.(*call)
c2.wg.Wait()
return c2.val, c2.err
}
// 走到这里说明:我是第一个(actual==c),我负责执行 fn
// 关键:用 defer 保证不管 fn 正常返回/报错/甚至 panic,都能 Done + Delete,避免别人永远卡住
defer func() {
// 先唤醒所有等待者
c.wg.Done()
// 再清理 key,允许下次请求重新触发 fn
g.m.Delete(key)
// 如果 fn panic,把 panic 继续抛出去(也可以选择转成 error)
// recover() 是 Go 提供的"抓 panic 的网"
/*
如果 fn() 里发生 panic(比如数组越界、nil 指针),那 Done() 永远执行不到:
所有 Wait() 的 goroutine 会永久阻塞
key 也不会被 Delete,后续请求还会一直 Wait(相当于"死锁")
*/
if r := recover(); r != nil {
panic(r)
}
}()
c.val, c.err = fn()
return c.val, c.err
}
8. 请简述 LRU 算法的原理,你这里的 LRU2 相比普通 LRU 有什么优势


9. 使用 etcd 做服务注册时有租约机制,请解释一下租约的作用是什么?如果某个缓存节点突然宕机,整个集群是如何感知到这个变化并调整工作状态的?
1. 租约 (Lease) 的作用:

2. 节点宕机后的感知与调整流程:

10. 项目选择了 gRPC 作为节点间的通信协议,相比于更常见的 RESTful API,gRPC 和 Protobuf 有哪些优势?

"联调事故"就是:客户端和服务端一起对接(联合调试)的时候,因为接口理解不一致导致的各种问题。
通俗点说:两个人约好"按这个格式说话",结果一方说的和另一方理解的不一样,于是就出 bug 了。
11. 缓存的并发安全需要锁或原子操作来保证,解释一下互斥锁 (Mutex) 和原子操作 (Atomic) 的区别,以及它们各自的适用场景
互斥锁 (Mutex/RWMutex):

原子操作 (Atomic):

GoCache 中如何使用的:

12. 谈谈你对 CAP 理论的理解,etcd 是如何做取舍的?

etcd 如何保证的一致性?介绍下它使用的协议

工作流程简述:

安全性:Raft 通过一系列严格的规则(如选举限制、日志匹配等)来确保系统的安全,例如:一个已经被提交的日志条目永远不会被覆盖或删除,保证了数据的一致性。
之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!