概述
论文地址:https://arxiv.org/pdf/2403.10506
仿人机器人具有类似人类的外形,有望在各种环境和任务中为人类提供支持。然而,昂贵且易碎的硬件是这项研究面临的挑战。因此,本研究开发了使用先进模拟技术的 HumanoidBench。该基准利用仿人机器人评估不同算法的性能,其中包括各种任务,如灵巧的双手和复杂的全身操纵。研究结果表明,最先进的强化学习算法在许多任务上都很吃力,而分层学习算法在行走和触摸物体等基本动作上表现更好。HumanoidBench 是机器人界应对仿人机器人所面临挑战的重要工具,为算法和想法的快速验证提供了平台。
介绍
仿人机器人有望无缝融入我们的日常生活。然而,它们的控制装置是为特定任务手动设计的,而新任务则需要大量的工程设计工作。为了解决这个问题,我们开发了一个名为 HumanoidBench 的基准,以促进仿人机器人的学习。这涉及一系列挑战,包括复杂的控制、身体协调和长期任务。该平台为测试机器人学习算法提供了一个安全、廉价的环境,并包含与人类日常任务相关的各种任务。HumanoidBench 可以轻松纳入各种仿人机器人和末端执行器、15 项全身操纵任务和 12 项运动任务。这使得最先进的 RL 算法能够控制仿人机器人的复杂动态,并为未来的研究提供了一个方向。
相关研究
随着标准化模拟基准的出现,深度强化学习(RL)正在迅速发展。然而,现有的机器人操作模拟环境主要关注静态、短期技能,并不涉及复杂操作。相比之下,已经提出的基准则侧重于各种长期操作。不过,大多数基准都是针对特定任务设计的,而且很多都使用了简化模型。这就需要基于真实硬件的综合基准。
模拟环境
主要机器人代理是一个拥有两只灵巧影子手2 的 Unitree H1 人形机器人。该机器人通过 MuJoCo 进行模拟。模拟环境支持一系列观察,包括机器人状态、物体状态、视觉观察和全身触觉感应。人形机器人还可通过位置控制进行控制。
HumanoidBench
要执行与人类类似的任务,机器人必须能够理解其所处的环境并采取适当的行动。然而,出于成本和安全考虑,在现实世界中测试机器人是很困难的。因此,模拟环境是学习和控制机器人的重要工具。
HumanoidBench 包括 27 项任务,具有高维运动空间(多达 61 个执行器)。运动任务包括行走和跑步等基本动作。操纵任务则包括推、拉、举和抓物体等高级任务。

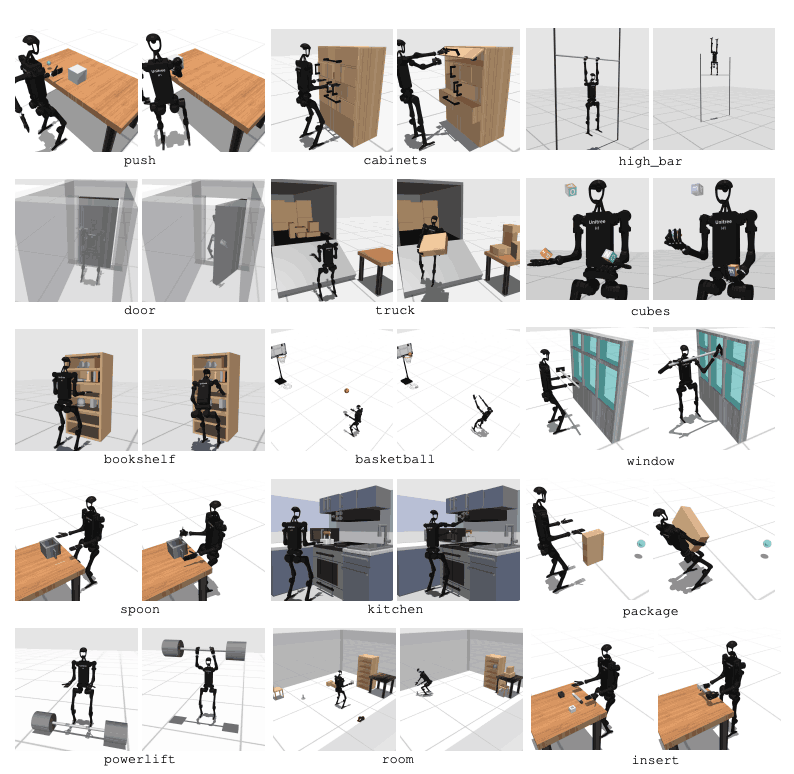
基准测试的目的是评估现代算法能够在多大程度上完成这些任务。机器人需要观察环境状态,并据此选择适当的行动。通过奖励功能,机器人可以学习执行任务的最佳策略。
例如,在行走任务中,机器人需要在保持前进速度的同时不摔倒。在这类任务中,优化平衡和步态非常重要。另一方面,在操纵任务中,机器人需要精确地操纵物体。这就需要了解物体的位置和方向,并进行适当的力控制。
HumanoidBench 的目标是通过这些任务促进机器人学习和控制领域的进步。利用模拟环境,研究人员可以安全地进行实验,评估机器人在许多不同场景中的性能。这将有助于开发更好的控制算法和学习方法,从而促进仿人机器人未来在现实世界中的应用。
试验
对强化学习(RL)算法的性能进行了评估,以确定仿人机器人在学习任务中面临的挑战。为此使用了四种主要的强化学习方法,包括 DreamerV3、TD-MPC2、SAC 和 PPO。结果显示,基线算法在许多任务中都低于成功阈值。
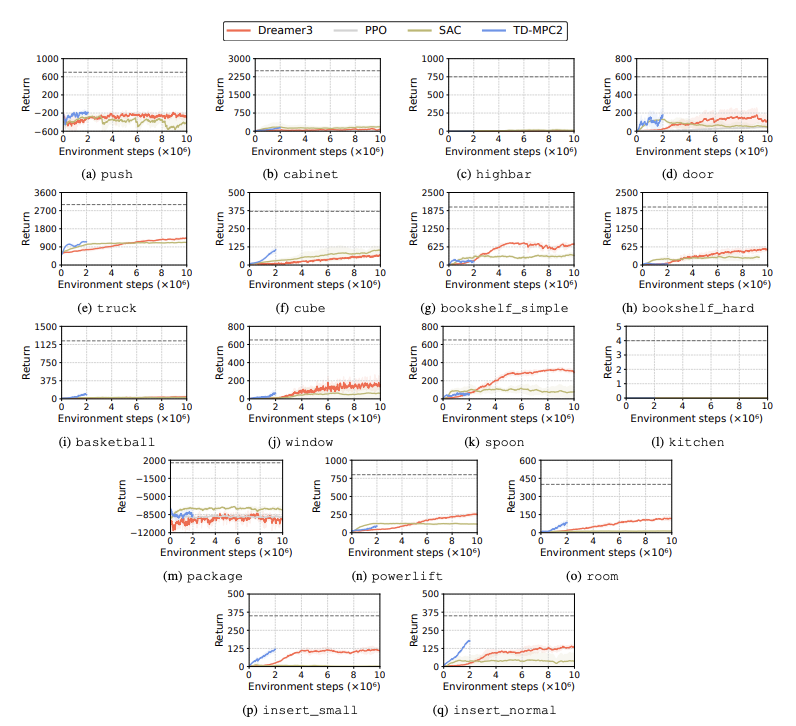
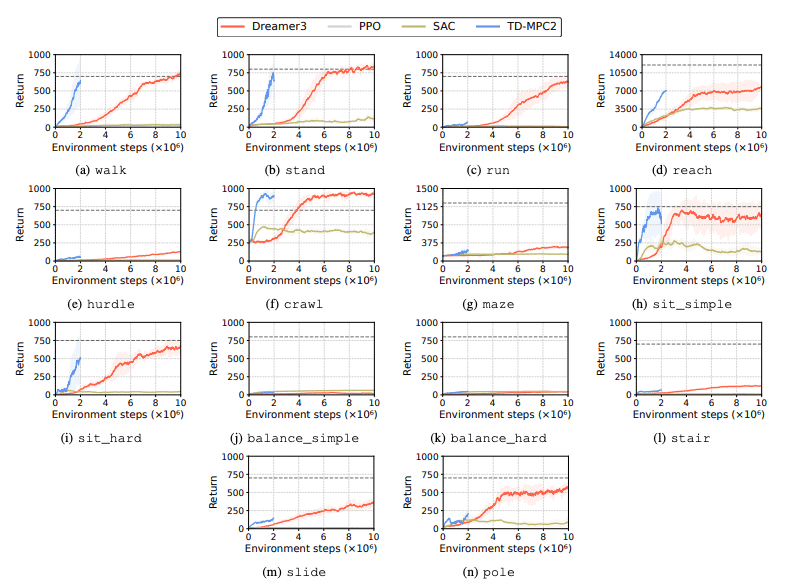
特别是,当前的 RL 算法在处理高维动作空间和复杂任务时非常吃力。仿人机器人在执行需要灵巧双手和复杂身体协调的任务时尤其困难。除此之外,操纵任务也特别具有挑战性,而且奖励往往较低。
一个常见的失败是,仿人基准难以学习机器人在高栏、门和障碍等任务中的预期行为。这是因为很难找到适合复杂行为的策略。
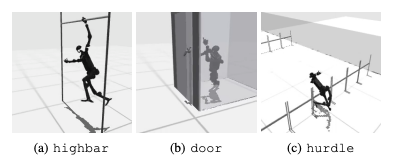
为应对这些挑战,正在考虑采用一种分层的 RL 方法。训练低级技能并通过高级规划策略将其结合起来,可以促进任务的解决。不过,目前的算法仍有改进的余地。
结论
该研究引入了一个名为 HumanoidBench 的高维仿人机器人控制基准。该基准提供了一个全面的仿人环境,包括从玩具到实际应用的各种运动和操纵任务。论文作者希望它能挑战此类复杂任务,促进仿人机器人全身算法的开发。
在未来的研究中,研究不同传感模式之间的相互作用非常重要。此外,还将考虑将更逼真的物体和环境与现实世界的多样性和高质量的渲染结合起来。此外,还将重点研究在难以收集实物演示的环境中引导学习的其他手段。