hbase学习
hbase概述:
HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,用于存储海量的结构化或者半结构化,非结构化的数据(底层是字节数组做存储的)
HBase是Hadoop的生态系统之一,是建立在Hadoop文件系统(HDFS)之上的分布式、面向列的数据库,通过利用Hadoop的文件系统提供容错能力。如果需要进行实时读写或者随机访问大规模的数据集的时候,会考虑使用HBase。
Hbase处理数据
虽然Hadoop是一个高容错、高延时的分布式文件系统和高并发的批处理系统,但是它不适用于提供实时计算;
HBase是可以提供实时计算的分布式数据库,数据被保存在HDFS分布式文件系统上,由HDFS保证期高容错性;
但是再生产环境中,HBase是如何基于hadoop提供实时性呢?
HBase上的数据是以StoreFile(HFile)二进制流的形式存储在HDFS上block块儿中;
但是HDFS并不知道的HBase用于存储什么,它只把存储文件认为是二进制文件,也就是说,HBase的存储数据对于HDFS文件系统是透明的。
理解稀疏(rowkey)
HBase中需要根据行键、列族、列限定符和时间戳来确定一个单元格,因此,可以视为一个"四维坐标",即**行键, 列族, 列限定符, 时间戳**
Hbase与HDFS
| HDFS | HBase |
|---|---|
| HDFS适于存储大容量文件的分布式文件系统。 | HBase是建立在HDFS之上的数据库。 |
| HDFS不支持快速单独记录查找。 | HBase提供在较大的表快速查找 |
| HDFS提供了高延迟批量处理;没有批处理概念。 | HBase提供了数十亿条记录低延迟访问单个行记录(随机存取)。 |
| HDFS提供的数据只能顺序访问。 | HBase内部使用哈希表和提供随机接入,并且其存储索引,可将在HDFS文件中的数据进行快速查找。**** |
Hbase数据模型
HBase通过表格的模式存储数据,每个表格由列和行组成,其中,每个列又被划分为若干个列族(colnum family)
**表:**HBase的数据同样是用表来组织的,表由行和列组成,列分为若干个列族,行和列的坐标交叉决定了一个单元格。
**行:**每个表由若干行组成,每个行有一个行键作为这一行的唯一标识。访问表中的行只有三种方式:通过单个行键进行查询、通过一个行键的区间来访问、全表扫描。
**列簇:**一个HBase表被分组成许多"列族"的集合,它是基本的访问控制单元。
**列修饰符(列限定符):**列族里的数据通过列限定符(或列)来定位
**单元格:**在HBase表中,通过行、列族和列限定符确定一个"单元格"(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte\[\]
**时间戳:**每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引
Hbase数据模型
HBase将数据存放在带有标签的表 中,表由行和列 组成,行和列交叉确定一个单元格 ,单元格有版本号 ,版本号自动分配,为数据插入该单元格时的时间戳 。单元格的内容没有数据类型,所有数据都被视为未解释的字节数组。
表格中每一行有一个行键 (也是字节数组,任何形式的数据都可以表示成字符串,比如数据结构进行序列化之后),整个表根据行键的字节序来排序,所有对表的访问必须通过行键。
表中的列又划分为多个列族 (column family),同一个列族的所有成员具有相同的前缀,具体的列由列修饰符标识,因此,列族和列修饰符合起来才可以表示某一列,比如:info:format、cotents:image
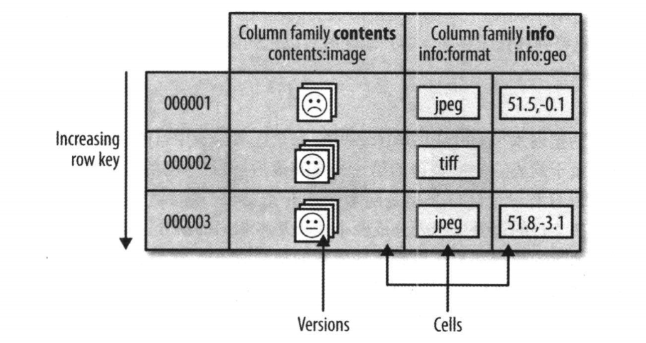
在创建一个表的时候,列族必须作为模式定义的一部分预先给出,而列族是支持动态扩展的 ,也就是列族成员可以随后按需加入。物理上,所有的列族成员一起存放在文件系统上,所以实际上说HBase是面向列的数据库,更准确的应该是面向列族,调优和存储都是在列族这个层次上进行的。一般情况下,同一个列族的成员最后具有相同的访问模式和大小特征。
总结起来,HBase表和我们熟知的RDBMS的表很像,不同之处在于:行按行键排序,列划分为列族,单元格有版本号,没有数据类型。
Hbase数据坐标
HBase中需要根据行键、列族、列限定符和时间戳来确定一个单元格(cell) ,cell中的数据是没有类型的,全部是字节码 形式存贮。,因此,可以视为一个"四维坐标",即**行键, 列族, 列限定符, 时间戳**。
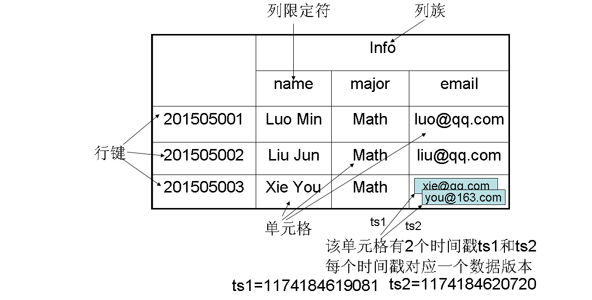
对于上图这样一个HBase表,其数据坐标举例如下:
| 键 | 值 |
|---|---|
| "201505003", "Info", "email", 1174184619081 | "xie@qq.com" |
| "201505003", "Info", "email", 1174184620720 | "you@163.com" |
HBase区域
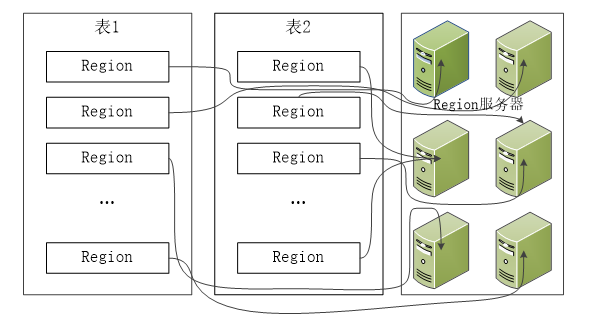
HBase自动把表水平划分为区域(Region),每个区域都是有若干连续行构成的,一个区域由**所属的表、起始行、终止行(不包括这行)**三个要素来表示。
一开始,一个表只有一个区域,但是随着数据的增加,区域逐渐变大,等到它超出设定的阈值(128M)大小,就会在某行的边界上进行拆分,分成两个大小基本相同 的区域。然后随着数据的再增加,区域就不断的增加,如果超出了单台服务器的容量,就可以把一些区域放到其他节点上去,构成一个集群。也就是说:集群中的每个节点(Region Server)管理整个表的若干个区域 。所以,我们说:区域是HBase集群上分布数据的最小单位。
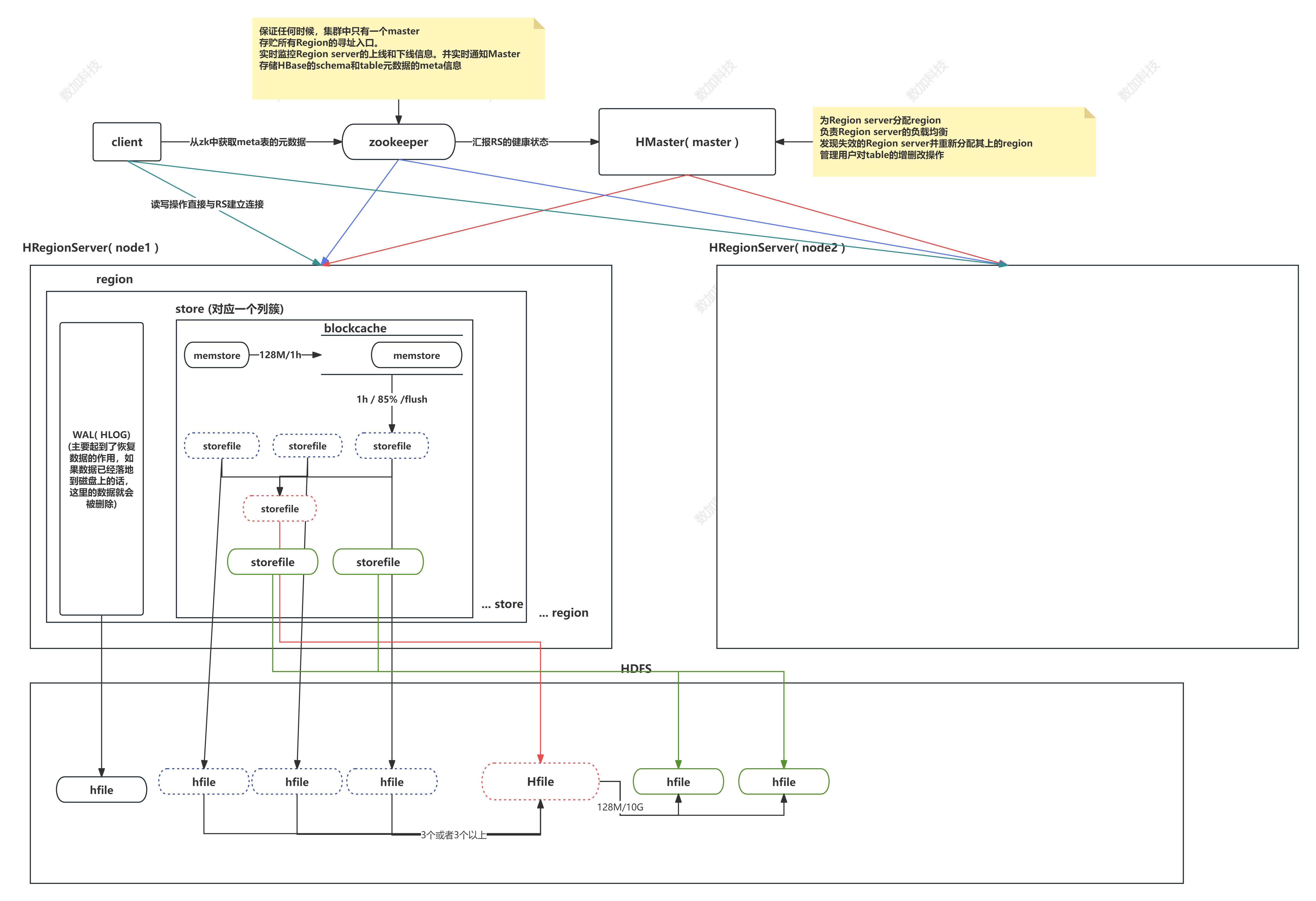
Hbase架构
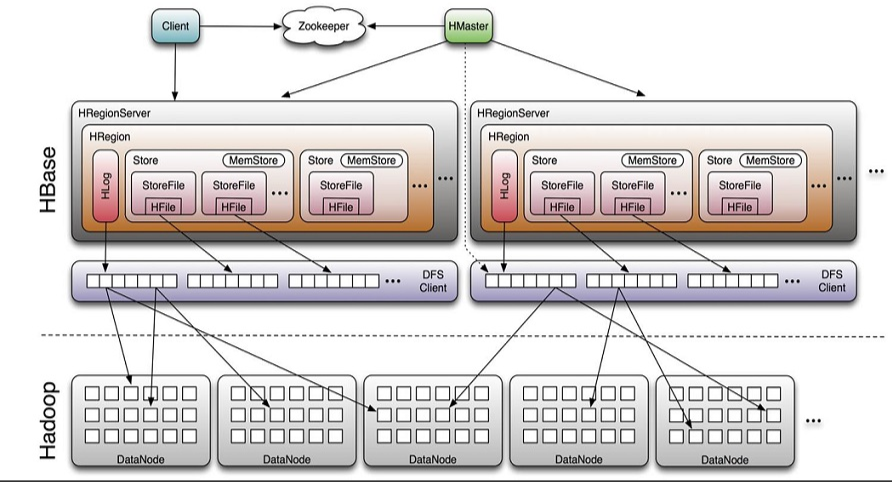
组件介绍
HBase由三种类型的服务器以主从模式构成:
- Region Server:负责数据的读写服务,用户通过与Region server交互来实现对数据的访问。
- HBase HMaster:负责Region的分配及数据库的创建和删除等操作。
- ZooKeeper:负责维护集群的状态(某台服务器是否在线,服务器之间数据的同步操作及master的选举等)。
HDFS的DataNode负责存储所有Region Server所管理的数据,即HBase中的所有数据都是以HDFS文件的形式存储的。出于使Region server所管理的数据更加本地化的考虑,Region server是根据DataNode分布的。HBase的数据在写入的时候都存储在本地。但当某一个region被移除或被重新分配的时候,就可能产生数据不在本地的情况。这种情况只有在所谓的compaction之后才能解决。
Client
包含访问HBase的接口并维护cache来加快对HBase的访问
Zookeeper
保证任何时候,集群中只有一个master
存贮所有Region的寻址入口。
实时监控Region server的上线和下线信息。并实时通知Master
存储HBase的schema和table元数据的meta信息
Master
为Region server分配region
负责Region server的负载均衡
发现失效的Region server并重新分配其上的region
管理用户对table的增删改操作
RegionServer
Region server维护region,处理对这些region的IO请求
Region server负责切分在运行过程中变得过大的region
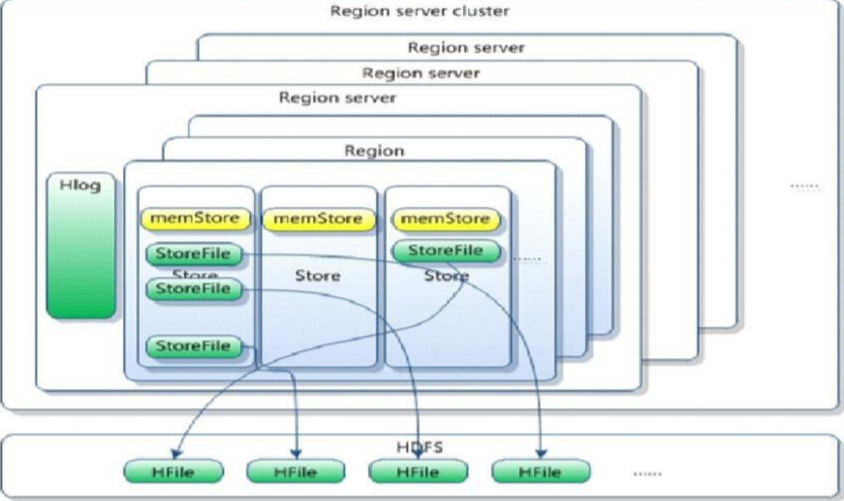
HLog(WAL log)(预写日志):
HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是 HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和 region名字外,同时还包括sequence number和timestamp,timestamp是" 写入时间",sequence number的起始值为0,或者是最近一次存入文件系 统sequence number。
HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的 KeyValue
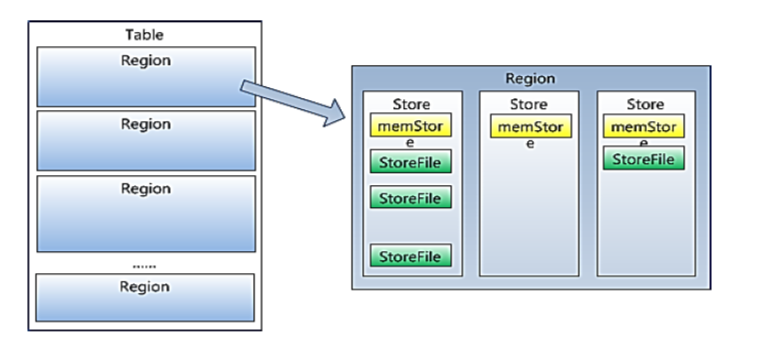
Region
HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据;每个表一开始只有一个region,随着数据不断插 入表,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region(裂变);
当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Regionserver上。
Memstore(缓冲思想) 与 storefile
一个region由多个store组成,一个store对应一个CF(列簇)
store包括位于内存中的memstore和位于磁盘的storefile写操作先写入 memstore,当memstore中的数据达到某个阈值,hregionserver会启动 flashcache进程写入storefile(先写入blockcache中,满了之后再写入storefile),每次写入形成单独的一个storefile
当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、 major compaction),在合并过程中会进行版本合并和删除工作 (majar),形成更大的storefile。
当一个region所有storefile的大小和超过一定阈值后,会把当前的region 分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡。
客户端检索数据,先在memstore找,找不到再找storefile
HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表 示不同的HRegion可以分布在不同的HRegion server上。
HRegion由一个或者多个Store组成,每个store保存一个columns family。
每个Strore又由一个memStore和0至多个StoreFile组成。
如图:StoreFile 以HFile格式保存在HDFS上。
理解难点
1、flush刷新在HDFS上呈现究竟是怎么刷新的呢??
我们目前刚刚学习的时候,添加数据,都是一条一条的put进去,而我们在put的数据比较少(小于128M)的时候,我们put完去HDFS上并未查看到我们put的文件,这是因为数据还在内存中,也就是还在memStore中,所以要想在HDFS中查看到,我们必须手动刷新到磁盘中,这是将memStore的数据刷新到StoreFile中去,这样我们在HDFS中就可以查看到了。
2、为什么Hbase不可以使用像Mysql那样进行查询??
首先,我们应该可以感受到,我们在插入的时候,每行数据,有多少列,列名叫什么完全是我们自己定义的,之所以不支持像MySql那样对列进行查询和操作,因为不确定列的个数和名称。
3、数据最后存在HDFS上的,HDFS不支持删改,为什么Hbase就可以呢??
这里有个思想误区,的确,数据是以HFile形式存在HDFS上的,而且HDFS的确是不支持删改的,但是为什么Hbase就支持呢?首先,这里的删除并不是真正意义上的对数据进行删除,而是对数据进行打上标记,我们再去查的时,就不会查到这个打过标记的数据,这个数据Hmaster会每隔1小时清理。修改是put两次,Hbase会取最新的数据,过期数据也是这个方式被清理。Hbase搭建
1、上传解压配置环境变量
shell
# 1、解压
tar -xvf hbase-2.2.7-bin.tar.gz.gz
# 2、配置环境变量
vim /etc/profile
# 3、在最后增加配置
export HBASE_HOME=/usr/local/soft/hbase-2.2.7
export PATH=$PATH:$HBASE_HOME/bin
# 4、使环境变量剩下
source /etc/profile2、修改配置文件
shell
#1、修改hbase-site.xml文件
vim hbase-site.xml
# 增加以下配置
<!--指定 zookeeper 服务器 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,node1,node2</value>
</property>
<!--指定 hbase 根路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<!--将 hbase 设置为分布式部署。 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 避免出现启动错误。 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
#2、修改hbase-env.sh文件
vim hbase-env.sh
# 增加配置
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
#3、修改regionservers文件
vim regionservers
# 增加配
node1
node2同步到所有节点(如果是伪分布式不需要同步)
scp -r hbase-2.2.7 node1:`pwd`
scp -r hbase-2.2.7 node2:`pwd`3、启动Hbase集群
shell
hbase启动顺序:
zk-->hadoop-->hbase
hbase关闭顺序:
hbase-->hadoop-->zk
# 启动
start-hbase.sh
# hbase web ui
http://master:16010
# 关闭hbase启动
#stop-hbase.sh
# 关不掉直接杀死
# 进入hbase客户端
hbase shell解决 log4j 兼容性问题
警告信息,不影响使用
LF4J: Class path contains multiple SLF4J bindings.
shell
cd /usr/local/soft/hbase-2.2.7/lib/client-facing-thirdparty
# HBase 与 Hadoop 在运行时会出现 log4j 兼容性问题,这是因为 HBase 的 log4j 版本与 Hadoop 的产生了冲突,我们这里将 HBase 的 log4j 设置为备份。
mv slf4j-log4j12-1.7.25.jar slf4j-log4j12-1.7.25.jar.bakHbase shell
| 命名 | 描述 | 语法 |
|---|---|---|
| help '命名名' | 查看命令的使用描述 | help '命令名' |
| whoami | 我是谁 | whoami |
| version | 返回hbase版本信息 | version |
| status | 返回hbase集群的状态信息 | status |
| table_help | 查看如何操作表 | table_help |
| create | 创建表 | create '表名', '列族名1', '列族名2', '列族名N' |
| alter | 修改列族 | 添加一个列族:alter '表名', '列族名' 删除列族:alter '表名', {NAME=> '列族名', METHOD=> 'delete'} |
| describe | 显示表相关的详细信息 | describe '表名' |
| list | 列出hbase中存在的所有表 | list |
| exists | 测试表是否存在 | exists '表名' |
| put | 添加或修改的表的值 | put '表名', '行键', '列族名', '列值' put '表名', '行键', '列族名:列名', '列值' |
| scan | 通过对表的扫描来获取对用的值 | scan '表名' 扫描某个列族: scan '表名', {COLUMN=>'列族名'} 扫描某个列族的某个列: scan '表名', {COLUMN=>'列族名:列名'} 查询同一个列族的多个列: scan '表名', {COLUMNS => '列族名1:列名1', '列族名1:列名2', ...} |
| get | 获取行或单元(cell)的值 | get '表名', '行键' get '表名', '行键', '列族名' |
| count | 统计表中行的数量 | count '表名' |
| incr | 增加指定表行或列的值 | incr '表名', '行键', '列族:列名', 步长值 |
| get_counter | 获取计数器 | get_counter '表名', '行键', '列族:列名' |
| delete | 删除指定对象的值(可以为表,行,列对应的值,另外也可以指定时间戳的值) | 删除列族的某个列: delete '表名', '行键', '列族名:列名' |
| deleteall | 删除指定行的所有元素值 | deleteall '表名', '行键' |
| truncate | 重新创建指定表 | truncate '表名' |
| enable | 使表有效 | enable '表名' |
| is_enabled | 是否启用 | is_enabled '表名' |
| disable | 使表无效 | disable '表名' |
| is_disabled | 是否无效 | is_disabled '表名' |
| drop | 删除表 | drop的表必须是disable的 disable '表名' drop '表名' |
| shutdown | 关闭hbase集群(与exit不同) | |
| tools | 列出hbase所支持的工具 | |
| exit | 退出hbase shell |
HBase Shell 是官方提供的一组命令,用于操作HBase。如果配置了HBase的环境变量了,就可以知己在命令行中输入hbase shell 命令进入命令行。
sql
# 进入Hbase客户端
hbase shell
#help命令 1. 查看hbase支持的所有命令 2.help'命令名称' 查看命令行的具体使用,包括命令的作用和用法。
help
help'list'
sql
# general 类
#显示集群状态
status
#查询数据库版本
version
#显示当前用户与组
whoami
#查看操作表的命令
table_help
#退出HBase Shell
exit
sql
# DDL
-- 创建表create 注意:创建表时只需要指定列族名称,不需要指定列名。
# 语法 必须大写
create '表名', {NAME => '列族名1'}, {NAME => '列族名2'}, {NAME => '列族名3'}
# 此种方式是上上面的简写方式,使用上面方式可以为列族指定更多的属性,如VERSIONS、TTL、BLOCKCACHE、CONFIGURATION等属性
create '表名', '列族名1', '列族名2', '列族名3'
create '表名', {NAME => '列族名1', VERSIONS => 版本号, TTL => 过期时间, BLOCKCACHE => true}
# TTl time to live
create 'test'{NAME =>'info',VERSIONS => 2} # 后两个较少使用
# 示例 简写看情况使用
create 'tbl_user', 'info', 'detail'
create 't1', {NAME => 'f1', VERSIONS => 1, TTL => 2592000, BLOCKCACHE => true},{NAME => 'f2',..}
-- 修改(添加、删除)表结构Schema
#alter
#添加一个列簇
# 语法
alter '表名', '列族名'
# 示例
alter 'tbl_user', 'address'
-- 删除一个列簇
# 语法
alter '表名', {NAME=> '列族名', METHOD=> 'delete'}
alter 't1',{NAME => 'cf2', METHOD => 'delete'}
# 示例
alter 'tbl_user', {NAME=> 'address', METHOD=> 'delete'}
-- 修改列族的属性 可以修改列族的VERSIONS、IN_MEMORY (暂时不知如何修改列簇名)
# 修改f1列族的版本为5
alter 't1', NAME => 'f1', VERSIONS => 5
# 修改多个列族,修改f2为内存,版本号为5
alter 't1', 'f1', {NAME => 'f2', IN_MEMORY => true}, {NAME => 'f3', VERSIONS => 5}
# 也可以修改table-scope属性,例如MAX_FILESIZE, READONLY,MEMSTORE_FLUSHSIZE, DEFERRED_LOG_FLUSH等。
# 例如,修改region的最大大小为128MB:
alter 't1', MAX_FILESIZE => '134217728'
-- 获取表的描述describe
# 语法
describe '表名'
# 示例
describe 'tbl_user'
-- 列举所有表
list
-- 表是否存在exists
# 语法
exists '表名'
# 示例
exists 'tbl_user'
-- 启用表enable和禁用表disable,通过enable和disable来启用/禁用这个表,相应的可以通过is_enabled和is_disabled来检查表是否被禁用
# 语法
enable '表名'
is_enabled '表名'
disable '表名'
is_disabled '表名'
# 示例
disable 'tbl_user'
is_disabled 'tbl_user'
enable 'tbl_user'
is_enabled 'tbl_user'
-- 禁用满足正则表达式的所有表disable_all (- `.`匹配除"\n"和"\r"之外的任何单个字符
-- `*`匹配前面的子表达式任意次)
# 匹配以t开头的表名
disable_all 't.*'
# 匹配指定命名空间ns下的以t开头的所有表
disable_all 'ns:t.*'
# 匹配ns命名空间下的所有表
disable_all 'ns:.*'
-- 启用满足正则表达式的所有表enable_all
enable_all 't.*'
enable_all 'ns:t.*'
enable_all 'ns:.*'
-- 删除表drop
# 注意 直接删除会报错 (只能删除被禁用的表) 所以先禁用再删除
# 语法
disable '表名'
drop '表名'
# 示例
disable 'tbl_user'
drop 'tbl_user'
-- 删除满足正则表达式的所有表drop_all
drop_all 't.*'
drop_all 'ns:t.*'
drop_all 'ns:.*'
-- namespace hbase中没有数据库的概念 , 可以使用namespace来达到数据库分类别管理表的作用
#列举命名空间
list_namespace
#获取命名空间描述 describe_namespace
describe_namespace 'default'
#查看命名空间下的所有表 list_namespace_tables
list_namespace_tables 'default'
list_namespace_tables 'hbase'
# 创建命名空间create_namespace
create_namespace 'bigdata30'
# 在bigdata30下创建一张表
create 'bigdata30:demo1','info'
# 删除命名空间drop_namespace
drop_namespace '命名空间名称'
-- 获取某个表赋值给一个变量 get_table
#通过 var = get_table '表名' 赋值给一个变量对象,然后对象.来调用,就像面向对象编程一样,通过对象.方法来调用,这种方式在操作某个表时就不必每次列举表名了。
t1 = get_table 'student'
t1.describe
-- 获取rowKey所在的区 locate_region
locate_region '表名', '行键'
-- 显示hbase所支持的所有过滤器show_filters
# 过滤器用于get和scan命令中作为筛选数据的条件,类型关系型数据库中的where的作用DML

sql
-- DML
-- 插入或者修改数据put 一列一列的插入
# 语法
# 当列族中只有一个列时'列族名:列名'使用'列族名'
put '表名', '行键', '列族名', '列值'
put '表名', '行键', '列族名:列名', '列值'
# 示例(改了行键)
# 创建表
create 'users', 'info', 'detail', 'address'
# 第一行数据
put 'users', '1003', 'info:id', '1'
put 'users', '1003', 'info:name', '张三'
put 'users', '1003', 'info:age', '28'
put 'users', '1003', 'detail:birthday', '1990-06-26'
put 'users', '1003', 'detail:email', 'abc@163.com'
put 'users', '1003', 'detail:create_time', '2019-03-04 14:26:10'
put 'users', '1003', 'address', '上海市'
# 第二行数据
put 'users', '1002', 'info:id', '2'
put 'users', '1002', 'info:name', '李四'
put 'users', '1002', 'info:age', '27'
put 'users', '1002', 'detail:birthday', '1990-06-27'
put 'users', '1002', 'detail:email', 'xxx@gmail.com'
put 'users', '1002', 'detail:create_time', '2019-03-05 14:26:10'
put 'users', '1002', 'address', '北京市'
# 第三行数据
put 'users', '1001', 'info:id', '3'
put 'users', '1001', 'info:name', '王五'
put 'users', '1001', 'info:age', '26'
put 'users', '1001', 'detail:birthday', '1990-06-28'
put 'users', '1001', 'detail:email', 'xyz@qq.com'
put 'users', '1001', 'detail:create_time', '2019-03-06 14:26:10'
put 'users', '1001', 'address', '杭州市'
-- 全表扫描scan
# 语法
scan '表名'
# 示例
scan 'users' // 效果类似于sql语句中select * from users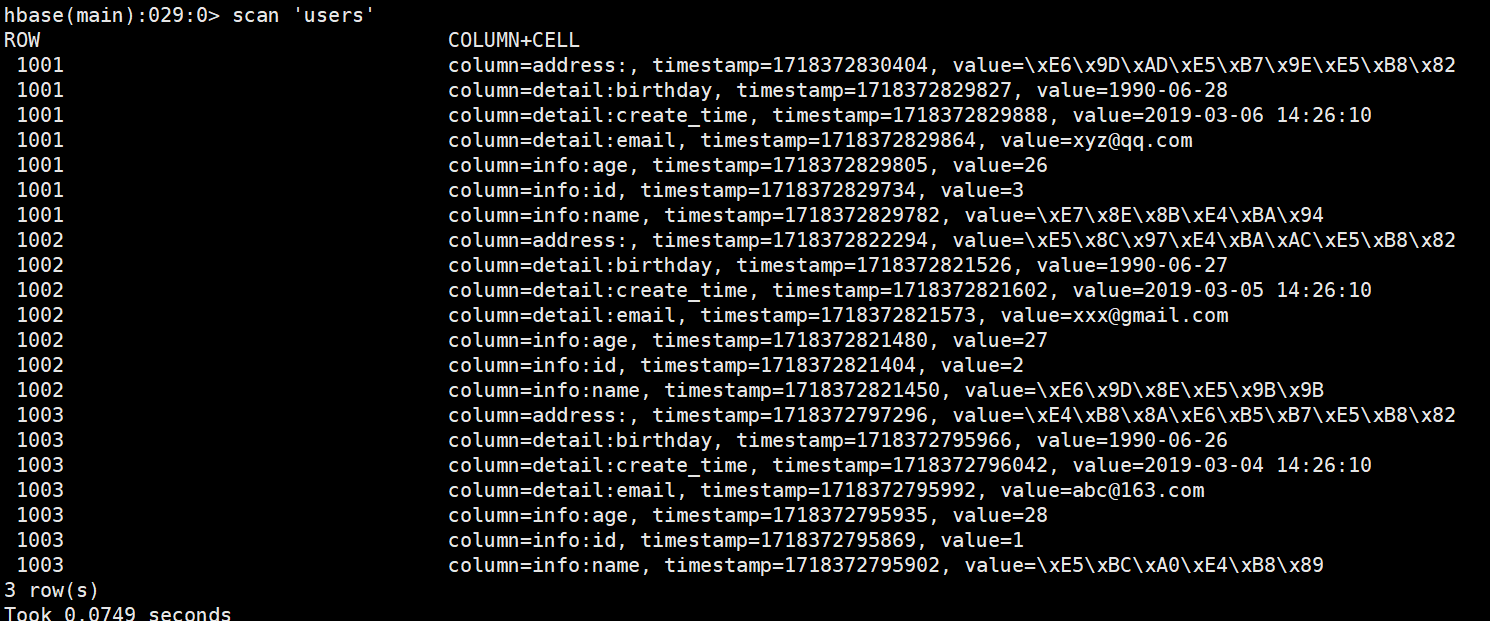 可以看到,先添加的行键为'1003'的数据还是排在最后,验证了行是按照字典序来排序的
可以看到,先添加的行键为'1003'的数据还是排在最后,验证了行是按照字典序来排序的
'name'这一列的值为 存储格式为byte\[\] 一个汉字对应三个字符
sql
-- 扫描整个列簇
# 语法
scan '表名', {COLUMN=>'列族名'}
# 示例
scan 'users', {COLUMN=>'info'}
-- 扫描整个列簇的某个列
# 语法
scan '表名', {COLUMN=>'列族名:列名'}
# 示例
scan 'users', {COLUMN=>'info:age'}
-- 获取数据get
# 语法
get '表名', '行键'
# 示例
get 'users', '1001'
-- 获取某一行某列族的数据
# 语法
get '表名', '行键', '列族名'
# 示例
get 'users', '1001', 'info'
-- 删除某个列族中的某个列delete
# 语法
delete '表名', '行键', '列族名:列名'
delete 'users','1001','info:age'
create 'tbl_test', 'columnFamily1'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value1'
put 'tbl_test', 'rowKey1', 'columnFamily1:column2', 'value2'
delete 'tbl_test', 'rowKey1', 'columnFamily1:column1'
-- 删除某行数据deleteall
# 语法
deleteall '表名', '行键'
# 示例
deleteall 'users', '1001'
-- 空整个表的数据truncate
# 先disable表,然后再drop表,最后重新create表
truncate '表名'
-- 自增incr 对于某个数值的使用
# 语法
incr '表名', '行键', '列族:列名', 步长值
# 示例
# 注意:incr 可以对不存的行键操作,如果行键已经存在会报错,如果使用put修改了incr的值再使用incr也会报错
# ERROR: org.apache.hadoop.hbase.DoNotRetryIOException: Field is not a long, it's 2 bytes wide
incr 'users', '1001', 'info:age', 1
# 如何解决?
-- 计数器get_counter
# 点击量:日、周、月
create 'counters', 'daily', 'weekly', 'monthly'
incr 'counters', '20240415', 'daily:hits', 1
incr 'counters', '20110101', 'daily:hits', 1
get_counter 'counters', '20110101', 'daily:hits'
# 解决上诉问题 c1这样的列事先不存在
incr 'users', '1001', 'info:c1', 1
get_counter 'users', '1001', 'info:c1'
## COUNTER VALUE =1
incr 'users', '1001', 'info:c1', 11
## COUNTER VALUE =12
-- 修饰词
# 修饰词
# 语法
scan '表名', {COLUMNS => [ '列族名1:列名1', '列族名1:列名2', ...]}
# 示例
scan 'tbl_user', {COLUMNS => [ 'info:id', 'info:age']}
#TIMESTAMP 指定时间戳
# 语法
scan '表名',{TIMERANGE=>[timestamp1, timestamp2]}
# 示例
scan 'tbl_user',{TIMERANGE=>[1551938004321, 1551938036450]}
#VERSIONS
# 默认情况下一个列只能存储一个数据,后面如果修改数据就会将原来的覆盖掉,可以通过指定VERSIONS时HBase一列能存储多个值。
create 'tbl_test', 'columnFamily1'
describe 'tbl_test'
# 修改列族版本号
alter 'tbl_test', { NAME=>'columnFamily1', VERSIONS=>3 }
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value1'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value2'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value3'
# 默认返回最新的一条数据
get 'tbl_test','rowKey1','columnFamily1:column1'
# 返回3个
get 'tbl_test','rowKey1',{COLUMN=>'columnFamily1:column1', VERSIONS=>3}
# 返回2个
get 'tbl_test','rowKey1',{COLUMN=>'columnFamily1:column1', VERSIONS=>2}
-- STARTROW
# ROWKEY起始行。会先根据这个key定位到region,再向后扫描
# 语法
scan '表名', { STARTROW => '行键名'}
# 示例
scan 'users', { STARTROW => '1001'}
##### STOPROW :截止到STOPROW行,STOPROW行之前的数据,不包括STOPROW这行数据
-- STOPROW :截止到STOPROW行,STOPROW行之前的数据,不包括STOPROW这行数据
# 语法
scan '表名', { STOPROW => '行键名'}
# 示例
scan 'users', { STOPROW => '1002'}
-- LIMIT 返回的行数
# 语法
scan '表名', { LIMIT => 行数}
# 示例 字典顺序 可以简写
scan 'users', { LIMIT => 2 }
sql
-- 版本的使用
# 创建表,c1版本为4, 元数据mykey=myvalue
hbase(main):009:0> create 'test1', {NAME => 'cf1', VERSIONS => 4}
0 row(s) in 2.2810 seconds
=> Hbase::Table - t1
# 添加列族c2, c3
hbase(main):010:0> alter 't1', 'c2', 'c3'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 3.8320 seconds
# 出入数据,c1 插入4个版本的值
hbase(main):011:0> put 't1', 'r1', 'c1', 'v1'
0 row(s) in 0.1000 seconds
hbase(main):012:0> put 't1', 'r1', 'c1', 'v11'
0 row(s) in 0.0180 seconds
hbase(main):013:0> put 't1', 'r1', 'c1', 'v111'
0 row(s) in 0.0140 seconds
hbase(main):014:0> put 't1', 'r1', 'c1', 'v1111'
0 row(s) in 0.0140 seconds
# 插入c2、c3的值
hbase(main):015:0> put 't1', 'r1', 'c2', 'v2'
0 row(s) in 0.0140 seconds
hbase(main):016:0> put 't1', 'r1', 'c3', 'v3'
0 row(s) in 0.0210 seconds
# 获取rowKey=r1的一行记录
hbase(main):017:0> get 't1', 'r1'
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
c2: timestamp=1552819392398, value=v2
c3: timestamp=1552819398244, value=v3
3 row(s) in 0.0550 seconds
# 获取rowKey=r1并且 1552819392398 <= 时间戳范围 < 1552819398244
hbase(main):018:0> get 't1', 'r1', {TIMERANGE => [1552819392398, 1552819398244]}
COLUMN CELL
c2: timestamp=1552819392398, value=v2
1 row(s) in 0.0090 seconds
# 获取指定列的值
hbase(main):019:0> get 't1', 'r1', {COLUMN => 'c1'}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
1 row(s) in 0.0160 seconds
# 获取指定列的值,多个值使用数组表示
hbase(main):020:0> get 't1', 'r1', {COLUMN => ['c1', 'c2', 'c3']}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
c2: timestamp=1552819392398, value=v2
c3: timestamp=1552819398244, value=v3
3 row(s) in 0.0170 seconds
# 获取c1的值,获取4个版本的值,默认是按照时间戳降续排序的
hbase(main):021:0> get 't1', 'r1', {COLUMN => 'c1', VERSIONS => 4}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
c1: timestamp=1552819376343, value=v111
c1: timestamp=1552819368993, value=v11
c1: timestamp=1552819362975, value=v1
4 row(s) in 0.0180 seconds
# 获取c1的3个版本值
hbase(main):027:0* get 't1', 'r1', {COLUMN => 'c1', VERSIONS => 3}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
c1: timestamp=1552819376343, value=v111
c1: timestamp=1552819368993, value=v11
3 row(s) in 0.0090 seconds
# 获取指定时间戳版本的列
hbase(main):022:0> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => 1552819376343}
COLUMN CELL
c1: timestamp=1552819376343, value=v111
1 row(s) in 0.0170 seconds
hbase(main):023:0> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => 1552819376343, VERSIONS => 4}
COLUMN CELL
c1: timestamp=1552819376343, value=v111
1 row(s) in 0.0130 seconds
# 获取rowKey=r1中的值等于v2的所有列
hbase(main):024:0> get 't1', 'r1', {FILTER => "ValueFilter(=, 'binary:v2')"}
COLUMN CELL
c2: timestamp=1552819392398, value=v2
1 row(s) in 0.0510 seconds
hbase(main):025:0> get 't1', 'r1', {COLUMN => 'c1', ATTRIBUTES => {'mykey'=>'myvalue'}}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
1 row(s) in 0.0100 secondsFILTER条件过滤器(后面用代码解决)
过滤器之间可以使用AND、OR连接多个过滤器。
1、ValueFilter 值过滤器
sql
# 语法:binary 等于某个值
scan '表名', FILTER=>"ValueFilter(=,'binary:列值')"
# 语法 substring:包含某个值
scan '表名', FILTER=>"ValueFilter(=,'substring:列值')"
# 示例
scan 'tbl_user', FILTER=>"ValueFilter(=, 'binary:26')"
scan 'tbl_user', FILTER=>"ValueFilter(=, 'substring:6')"2、ColumnPrefixFilter 列名前缀过滤器
# 语法 substring:包含某个值
scan '表名', FILTER=>"ColumnPrefixFilter('列名前缀')"
# 示例
scan 'tbl_user', FILTER=>"ColumnPrefixFilter('birth')"
# 通过括号、AND和OR的条件组合多个过滤器
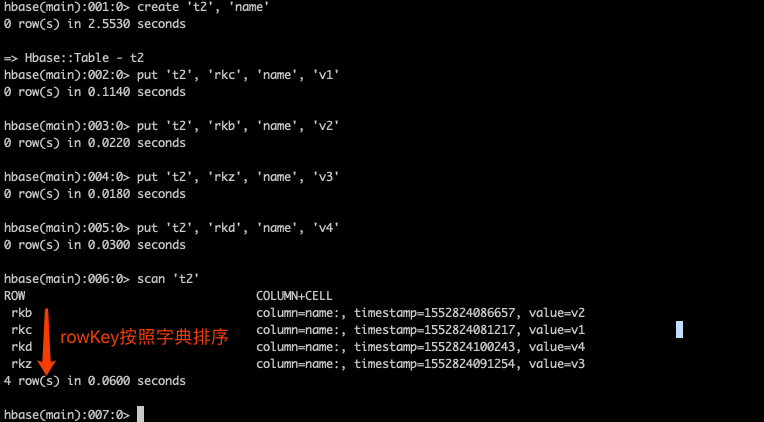
scan 'tbl_user', FILTER=>"ColumnPrefixFilter('birth') AND ValueFilter(=,'substring:26')"3、rowKey字典排序
Table中的所有行都是按照row key的字典排序的
Hbase shell 进阶
1.Region信息观察
sql
-- 创建表指定命名空间
create 'bigdata30:t1','info'
-- 只看bigdata30这个命名空间中的表
list_namespace_tables 'bigdata30'
-- 查看region中的某列簇数据 (在linux中运行 不是在hbase中使用)
hbase hfile -p -f /hbase/data/default/tbl_user/92994712513a45baaa12b72117dda5e5/info/d84e2013791845968917d876e2b438a5
# eg
create 'students_test1','info'
# 行键的设计在hbase中有三大设计原则:唯一性 长度不宜过长 散列性
put 'students_test1','1500100001','info:name','施笑槐'
put 'students_test1','1500100001','info:age','22'
put 'students_test1','1500100001','info:gender','女'
put 'students_test1','1500100001','info:clazz','文科六班'
put 'students_test1','1500100002','info:name','吕金鹏'
put 'students_test1','1500100002','info:age','24'
put 'students_test1','1500100002','info:gender','男'
put 'students_test1','1500100002','info:clazz','文科六班'
put 'students_test1','1500100003','info:name','单乐蕊'
put 'students_test1','1500100003','info:age','22'
put 'students_test1','1500100003','info:gender','女'
put 'students_test1','1500100003','info:clazz','理科六班'
put 'students_test1','1500100004','info:name','葛德曜'
put 'students_test1','1500100004','info:age','24'
put 'students_test1','1500100004','info:gender','男'
put 'students_test1','1500100004','info:clazz','理科三班'
# 在HDFS上的hbase文件夹中data目录下存放着hbase中的命名空间,刚才创建的students_test1在default命名空间下,点进去可以看到一长串的字符 那就是region的编号。
# 进入master:16010可以看到所有信息,并发现两者的region编号相同。
#进一步查看 发现storefile下并没有数据,同时HDFS中的region下的列簇(info)中也没有数据,联想到数据是先写入内存中的。如果想要立刻看到数据
#刷新数据:
flush 'tb'
# 查看数据
hbase hfile -p -f ...
1500100005,宣谷芹,22,女,理科五班
# 增加数据
put 'students_test1','1500100005','info:name','宣谷芹'
put 'students_test1','1500100005','info:age','22'
put 'students_test1','1500100005','info:gender','女'
put 'students_test1','1500100005','info:clazz','理科五班'
# 刷进去 之后出现两个数据文件 ---> 每刷一次多一个文件--->导致太多小文件
#解决 合并小文件
major_compact 'tb'
# 合并后出现3个小文件 不用慌 过一会自动删除 保留合并后的文件查看表的所有region
shell
list_regions '表名'
强制将表切分出来一个region
shell
split '表名','行键'
但是在页面上可以看到三个:过一会会自动的把原来的删除
查看某一行在哪个region中
shell
locate_region '表名','行键'
可以hbase hfile -p -f xxxx 查看一下
2、预分region解决热点问题(面试题)
面试题:如何解决hbase中遇到的热点问题?
row设计的一个关键点是查询维度(在建表的时候根据具体的查询业务 设计rowkey 预拆分)
在默认的拆分策略中 ,region的大小达到一定的阈值以后才会进行拆分,并且拆分的region在同一个regionserver中 ,只有达到负载均衡的时机时才会进行region重分配!并且开始如果有大量的数据进行插入操作,那么并发就会集中在单个RS中, 形成热点问题,所以如果有并发插入的时候尽量避免热点问题 ,应当预划分 Region的rowkeyRange范围 ,在建表的时候就指定预region范围
查看命令使用(指定4个切割点,就会有5个region)
shell
help 'create'
shell
create 'tb_split','cf',SPLITS => ['e','h','l','r'] # 5个region
shell
list_regions 'tb_split'
添加数据试试
shell
put 'tb_split','c001','cf:name','first'
put 'tb_split','f001','cf:name','second'
put 'tb_split','z001','cf:name','last'hbase hfile -p --f xxxx 查看数据
如果没有数据,因为数据还在内存中,需要手动刷新内存到HDFS中,以HFile的形式存储
总结:什么是region热点问题?
大批量的数据都前往一个region上进行处理,导致请求数量过多
可以预分region数量,使大批量的请求分散到不同的region上处理。
若某一个行键还是很多,导致某个region请求还是过多,则在添加region之前给这些数据打上前缀,使他们前往不同的region中,可以查出来。
3、日志查看
试试不启动hdfs 就启动hbase
日志目录:
/usr/local/soft/hbase-2.2.7/logs
start-all.sh发现HMaster没启动,hbase shell客户端也可以正常访问
再启动hbase就好了
5、scan进阶使用
查看所有的命名空间
shell
list_namespace查看某个命名空间下的所有表
shell
list_namespace_tables 'default'修改命名空间,设置一个属性
shell
alter_namespace 'bigdata25',{METHOD=>'set','author'=>'wyh'}查看命名空间属性
shell
describe_namespace 'bigdata17'删除一个属性
shell
alter_namespace 'bigdata17',{METHOD=>'unset', NAME=>'author'}删除一个命名空间
shell
drop_namespace 'bigdata17'创建一张表
sh
create 'teacher','cf'添加数据
shell
put 'teacher','tid0001','cf:tid',1
put 'teacher','tid0002','cf:tid',2
put 'teacher','tid0003','cf:tid',3
put 'teacher','tid0004','cf:tid',4
put 'teacher','tid0005','cf:tid',5
put 'teacher','tid0006','cf:tid',6显示三行数据
shell
scan 'teacher',{LIMIT=>3}
shell
put 'teacher','tid00001','cf:name','wyh'
scan 'teacher',{LIMIT=>3}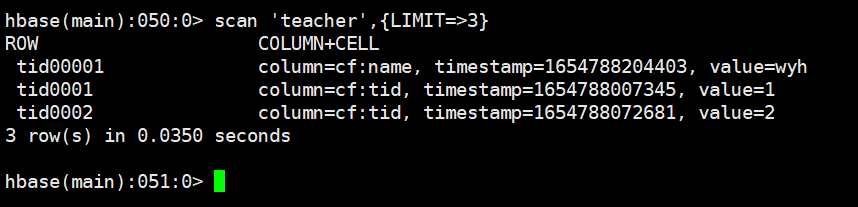
从后查三行
shell
scan 'teacher',{LIMIT=>3,REVERSED=>true}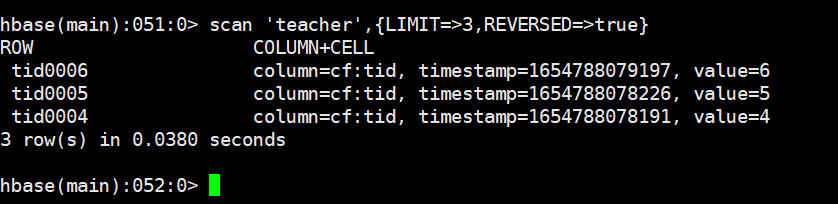
查看包含指定列的行
shell
scan 'teacher',{LIMIT=>3,COLUMNS=>['cf:name']}
简化写法:
shell
scan 'teacher',LIMIT=>3,COLUMNS=>['cf:name']在已有的值后面追加值
shell
append 'teacher','tid0001','cf:name','123'6、get进阶使用
简单使用,获取某一行数据
shell
get 'teacher','tid0001'获取某一行的某个列簇
shell
get 'teacher','tid0001','cf'获取某一行的某一列(属性 )
shell
get 'teacher','tid0001','cf:name'可以新增一个列簇数据测试
查看历史版本1、修改表可以存储多个版本
shell
alter 'teacher',NAME=>'cf',VERSIONS=>32、put四次相同rowkey和列的数据
shell
put 'teacher','tid0001','cf:name','xiaohu1'
put 'teacher','tid0001','cf:name','xiaohu2'
put 'teacher','tid0001','cf:name','xiaohu3'
put 'teacher','tid0001','cf:name','xiaohu4'3、查看历史数据,默认是最新的
shell
get 'teacher','tid0001',COLUMN=>'cf:name',VERSIONS=>2修改列簇的过期时间 TTL单位是秒,这个时间是与插入的时间比较,而不是现在开始60s
shell
alter 'teacher',{NAME=>'cf2',TTL=>'10'}7、插入时间指定时间戳
shell
put 'teacher','tid0007','info:clazz','bigdata30',1718356919312数据时间:数据产生那一刻的时间
事务时间(操作时间):接收到数据并处理的那一刻时间
8、delete(只能删除一个单元格,不能删除列簇)
删除某一列
shell
delete 'teacher','tid0004','cf:tid'9、deleteall(删除不了某个列簇,但是可以删除多个单元格)
删除一行,如果不指定列簇,删除的是一行中的所有列簇
shell
deleteall 'teacher','tid0006'删除单元格
shell
deleteall 'teacher','tid0006','cf:name','cf2:job'10、incr和counter
统计表有多少行(统计的是行键的个数)
shell
count 'teacher'新建一个自增的一列
shell
incr 'teacher','tid0001','cf:cnt',1每操作一次,自增1
shell
incr 'teacher','tid0001','cf:cnt',1
incr 'teacher','tid0001','cf:cnt',10
incr 'teacher','tid0001','cf:cnt',100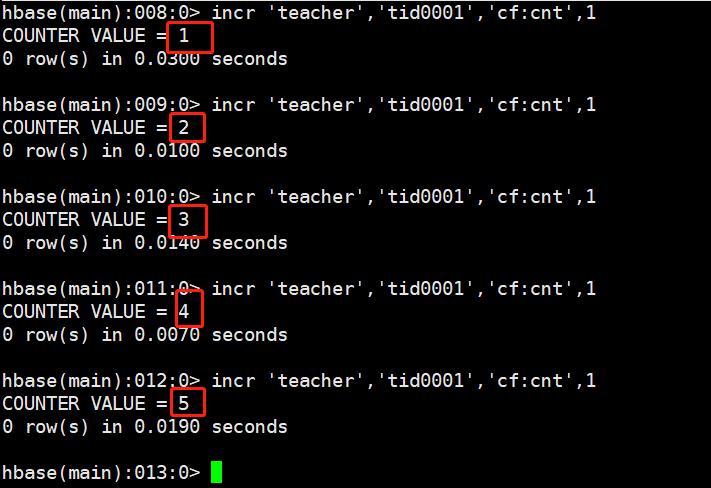
配合counter取出数据,只能去incr字段
shell
get_counter 'teacher','tid0001','cf:cnt'11、获取region的分割点,清除数据,快照
获取region的分割点
shell
get_splits 'tb_split'清除表数据
shell
truncate 'teacher'拍摄快照
shell
snapshot 'teacher','teacher_20240614'列出所有快照
shell
list_table_snapshots 'tb_split'再添加一些数据
shell
put 'tb_split','k001','cf:name','wyh'恢复快照(先禁用)
shell
disable 'tb_split'
shell
restore_snapshot 'teacher_20240614'
shell
enable 'tb_split'JAVA API
添加pom文件
xml
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.6</version>
</dependency>hbase基础操作
java
/**
* 单元测试的注解:
*
* @Before 在Test方法执行之前执行
* @Test 在方法上定义,可以不用main方法,单独运行
* @After 在Test方法执行之后执行
* 使用java操作数据库,被称之为jdbc
* 1、注册驱动
* 2、创建与数据库的连接对象
* 3、创建操作数据库的对象
* 4、执行方法
* 5、分析结果
* 6、释放资源
* hbase基础中要做的需求:
* 1、如何创建一张表
* 2、如何删除一张表
* 3、如何向一张表中添加一条数据
* 4、如何向一张表中同时添加一批数据
* 5、如何获取一条数据
* 6、如果获取一批数据
* 7、如何创建预分region表
*/
public class HbaseAPI {
//成员变量
private Connection conn;
private Admin admin;
@Before
public void connection() {
try {
//创建hbase的运行环境对象
//旧版本的写法,已弃用
// HBaseConfiguration conf = new HBaseConfiguration();
//新版本创建配置文件对象的方式
Configuration conf = HBaseConfiguration.create();
//设置zookeeper的节点信息
conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
//创建hbase连接对象
conn = ConnectionFactory.createConnection(conf);
//创建数据库操作对象
// HBaseAdmin hBaseAdmin = new HBaseAdmin(conn);
admin = conn.getAdmin();
System.out.println("成功获取数据库连接对象:" + conn);
System.out.println("成功获取数据库操作对象:" + admin);
System.out.println("=================================================");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 如何创建一张表
* 在hbase中创建一张表的必要因素是表名和列簇
* create 'test2','info'
*/
@Test
public void createOneTable() {
/**在hbase中,表和列簇需要分开创建并设置,然后再将列簇对象添加到表中
* 1、创建一个表的描述对象
*/
//将表名封装成TableName的对象
TableName name = TableName.valueOf("students");
//在老版本中创建表描述器对象的方式 在2.0.0之后被弃用,将来会在3.0.0之后删除
//public HTableDescriptor(final TableName name)
// HTableDescriptor test2 = new HTableDescriptor(name);
//新版本:推荐使用TableDescriptorBuilder来创建表描述器对象
//public static TableDescriptorBuilder newBuilder(final TableName name)
TableDescriptorBuilder test2 = TableDescriptorBuilder.newBuilder(name);
try {
/**
* 2、创建一个列簇描述器对象
*/
//旧版本的写法:public HColumnDescriptor(final String familyName) 在2.0.0之后被弃用,将来会在3.0.0之后删除
// HColumnDescriptor info = new HColumnDescriptor("info");
//新版本写法: ColumnFamilyDescriptorBuilder.of(String).
ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.of("info");
/**
* 3、将列簇添加到表中
*/
//旧版本的写法
// test2.addColumnFamily(info);
//新版本写法
test2.setColumnFamily(info);
/**
* 判断表是否存在
*/
if (admin.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表已经存在!");
return;
}
/**
* 4、admin对象调用方法创建一张表
*/
//void createTable(TableDescriptor desc)
//TableDescriptorBuilder:
//public TableDescriptor build() {
// return new ModifyableTableDescriptor(desc);
// }
admin.createTable(test2.build());
System.out.println(Bytes.toString(test2.build().getTableName().getName()) + "表创建 成功 SUCCEED!");
} catch (Exception e) {
System.out.println(Bytes.toString(test2.build().getTableName().getName()) + "表创建 失败!FAILED!");
e.printStackTrace();
}
}
/**
* 2、如何删除一张表
*/
@Test
public void deleteOneTable() {
try {
//将表名封装成一个TableName对象
TableName name = TableName.valueOf("test2");
/**
* 判断表是否存在
*/
if (!admin.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表不存在!无法删除!");
return;
}
//禁用表
admin.disableTable(name);
//删除表
admin.deleteTable(name);
System.out.println(Bytes.toString(name.getName()) + "表删除 成功 SUCCEED!");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 3、如何向一张表中添加一列数据
* 1500100001,施笑槐,22,女,文科六班
* <p>
* put 'students','1500100001','info:name','施笑槐'
* put 'students','1500100001','info:age','22'
* put 'students','1500100001','info:gender','女'
* put 'students','1500100001','info:clazz','文科六班'
*/
@Test
public void putOneColData() {
try {
//将表名封装成一个TableName对象
TableName name = TableName.valueOf("students");
/**
* 判断表是否存在
*/
if (!admin.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表不存在!无法添加数据!");
return;
}
//获取表实例对象
Table test2 = conn.getTable(name);
//将一列数据封装成一个Put对象,传入一个行键,需要将行键变成一个字节数组的格式
Put put = new Put(Bytes.toBytes("1500100001"));
//设置列簇列名和列值
//public Put addColumn(byte [] family, byte [] qualifier, byte [] value)
//设置的方式1:
// put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes("施笑槐"));
//设置的方式2:
// public Put add(Cell cell)
//KeyValue类是Cell接口的实现类
//public KeyValue(final byte [] row, final byte [] family, final byte [] qualifier, final byte [] value)
KeyValue keyValue = new KeyValue(Bytes.toBytes("1500100001"),
Bytes.toBytes("info"),
Bytes.toBytes("age"),
Bytes.toBytes("22"));
put.add(keyValue);
//表对象调用put方法将一列或多列数据添加到表中
//default void put(Put put)
test2.put(put);
System.out.println("一列数据添加完毕!");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 4、如何向一张表中同时添加一批数据
*/
@Test
public void putMoreData() {
ArrayList<Put> puts = new ArrayList<>();
try {
//将表名封装成一个TableName对象
TableName tableName = TableName.valueOf("students");
/**
* 判断表是否存在
*/
if (!admin.tableExists(tableName)) {
System.out.println(Bytes.toString(tableName.getName()) + " 表不存在!无法添加数据!");
return;
}
//获取表实例对象
Table students = conn.getTable(tableName);
//InputStreamReader
//FileReader
//BufferedReader
//创建字符缓冲输入流对象
BufferedReader br = new BufferedReader(new FileReader("data/students.txt"));
String line = null;
Put put = null;
while ((line = br.readLine()) != null) {
//1500100001,施笑槐,22,女,文科六班
String[] infos = line.split(",");
byte[] rk = Bytes.toBytes(infos[0]);
byte[] name = Bytes.toBytes(infos[1]);
put = new Put(rk);
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), name);
puts.add(put);
byte[] age = Bytes.toBytes(infos[2]);
put = new Put(rk);
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("age"), age);
puts.add(put);
byte[] gender = Bytes.toBytes(infos[3]);
put = new Put(rk);
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("gender"), gender);
puts.add(put);
byte[] clazz = Bytes.toBytes(infos[4]);
put = new Put(rk);
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("clazz"), clazz);
puts.add(put);
}
students.put(puts);
System.out.println(Bytes.toString(tableName.getName()) + " 表所有列数据添加完毕!!");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 5、如何获取一条数据
* get 'students','1500100001','info:name'
*/
@Test
public void getOneData() {
try {
//将表名封装成一个TableName对象
TableName tableName = TableName.valueOf("students");
/**
* 判断表是否存在
*/
if (!admin.tableExists(tableName)) {
System.out.println(Bytes.toString(tableName.getName()) + " 表不存在!无法添加数据!");
return;
}
//获取表实例对象
Table students = conn.getTable(tableName);
//创建一个Get对象
Get get = new Get(Bytes.toBytes("1500100001"));
//default Result get(Get get)
Result result = students.get(get);
/**
* Hbase中Result类常用的方法:
* getRow() 获取行键的字节数组形式
* getValue(byte [] family, byte [] qualifier) 获取某一列值的字节数组形式
* listCells() 获取所有列单元格组成的List集合
*/
//result中封装了许多的单元格,每一个单元格都是一个列
//第一种获取数据的方式:列单独获取,getValue 获取一列数据的前提是要知道列簇和列名
// String id = Bytes.toString(result.getRow());
// String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
// String age = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")));
// String gender = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("gender")));
// String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));
// System.out.println("学号:" + id + ", 姓名:" + name + ", 年龄:" + age + ", 性别:" + gender + ", 班级:" + clazz);
//第二种获取数据的方式:listCells()
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
//Hbase中提供了一个专门解析Cell单元格的工具类 CellUtil
String id = Bytes.toString(CellUtil.cloneRow(cell));
String cf = Bytes.toString(CellUtil.cloneFamily(cell));
String colName = Bytes.toString(CellUtil.cloneQualifier(cell));
String colValue = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println("行键:" + id + ", 列簇:" + cf + ", 列名:" + colName + ", 列值:" + colValue);
System.out.println("--------------------------------------------");
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 6、如果获取一批数据
* <p>
* scan 'students'
* scan 'students',LIMIT=>5
* scan 'students', STARTROW=>'1500100013', STOPROW=>'1500100021'
*/
@Test
public void scanMoreData() {
try {
//将表名封装成一个TableName对象
TableName tableName = TableName.valueOf("students");
/**
* 判断表是否存在
*/
if (!admin.tableExists(tableName)) {
System.out.println(Bytes.toString(tableName.getName()) + " 表不存在!无法添加数据!");
return;
}
//获取表实例对象
Table students = conn.getTable(tableName);
//创建一个Scan对象
Scan scan = new Scan(); //默认是查询所有行数据
//可以对scan进行一些设置
// scan.setLimit(5); //只查询前5行所有列数据
//旧版本设置开始行行键和结束行键
// scan.setStartRow(Bytes.toBytes("1500100013"));
// scan.setStopRow(Bytes.toBytes("1500100021"));
//新版本设置开始行行键和结束行键
scan.withStartRow(Bytes.toBytes("1500100013"));
//新版本中可以设置是否包含边界行
scan.withStopRow(Bytes.toBytes("1500100021"), true);
ResultScanner resultScanner = students.getScanner(scan);
//获取一个迭代器对象,存放的是所有行的数据
Iterator<Result> resultIterator = resultScanner.iterator();
StringBuilder sb = null;
while (resultIterator.hasNext()) {
Result result = resultIterator.next();
String id = Bytes.toString(result.getRow());
// String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
// String age = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")));
// String gender = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("gender")));
// String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));
// System.out.println("学号:" + id + ", 姓名:" + name + ", 年龄:" + age + ", 性别:" + gender + ", 班级:" + clazz);
List<Cell> cells = result.listCells();
sb = new StringBuilder();
sb.append("id:").append(id).append(", ");
for (int i = 0; i < cells.size(); i++) {
//Hbase中提供了一个专门解析Cell单元格的工具类 CellUtil
String colName = Bytes.toString(CellUtil.cloneQualifier(cells.get(i)));
String colValue = Bytes.toString(CellUtil.cloneValue(cells.get(i)));
if (i != cells.size() - 1) {
sb.append(colName).append(":").append(colValue).append(", ");
} else {
sb.append(colName).append(":").append(colValue);
}
}
System.out.println(sb);
System.out.println("--------------------------------------------");
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 7、如何创建预分region表
*/
@Test
public void createSplitTable(){
TableName name = TableName.valueOf("tb_split2");
TableDescriptorBuilder test2 = TableDescriptorBuilder.newBuilder(name);
try {
ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.of("info");
test2.setColumnFamily(info);
if (admin.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表已经存在!");
return;
}
byte[][] splitKeys = {
Bytes.toBytes("e"),
Bytes.toBytes("h"),
Bytes.toBytes("l"),
Bytes.toBytes("r")
};
//createTable(TableDescriptor desc, byte[][] splitKeys)
//指定分割键创建预分region表 'e','h','l','r'
admin.createTable(test2.build(),splitKeys);
System.out.println(Bytes.toString(test2.build().getTableName().getName()) + "表创建 成功 SUCCEED!");
} catch (Exception e) {
System.out.println(Bytes.toString(test2.build().getTableName().getName()) + "表创建 失败!FAILED!");
e.printStackTrace();
}
}
@After
public void close() {
if (admin != null) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}Hbase之过滤器
过滤器可以根据列族、列、版本等更多的条件来对数据进行过滤,
基于 HBase 本身提供的三维有序(行键,列,版本有序),这些过滤器可以高效地完成查询过滤的任务,带有过滤器条件的 RPC 查询请求会把过滤器分发到各个 RegionServer(这是一个服务端过滤器),这样也可以降低网络传输的压力。
使用过滤器至少需要两类参数:
一类是抽象的操作符,另一类是比较器
过滤器的作用
过滤器的作用是在服务端 判断数据是否满足条件,然后只将满足条件的数据返回给客户端
过滤器的类型
三类:
- 比较过滤器:可应用于rowkey、列簇、列、列值过滤器
- 专用过滤器:只能适用于特定的过滤器
- 包装过滤器:包装过滤器就是通过包装其他过滤器以实现某些拓展的功能。
撰写工具类 封装打印一行数据的代码:
java
public class HbaseParameters {
private static Connection conn = null;
private static Admin admin = null;
public static Connection getConnection(){
try {
//新版本创建配置文件对象的方式
Configuration conf = HBaseConfiguration.create();
//设置zookeeper的节点信息
conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
//创建hbase连接对象
conn = ConnectionFactory.createConnection(conf);
} catch (Exception e) {
e.printStackTrace();
}
return conn;
}
public static Admin getAdmin(){
try {
admin = conn.getAdmin();
}catch (Exception e){
e.printStackTrace();
}
return admin;
}
}
java
/**
* 工具类的编写步骤:
* 1、构造方法私有化
* 2、方法要是静态的,将可以通过类名的方式调用
*
*/
public class HbaseUtil {
//成员变量
public static final Connection CONN = HbaseParameters.getConnection();
public static final Admin ADMIN = HbaseParameters.getAdmin();
private HbaseUtil(){}
/**
* 传入表名和若干个列簇创建Hbase一张表
*/
public static void createOneTable(String tableName, String ... familyNames){
TableName name = TableName.valueOf(tableName);
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(name);
try {
for (String familyName : familyNames) {
// ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.of(familyName);
ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(familyName))
.setBloomFilterType(BloomType.ROW) // 设置布隆过滤器
.build();
tableDescriptorBuilder.setColumnFamily(info);
}
if (ADMIN.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表已经存在!");
return;
}
ADMIN.createTable(tableDescriptorBuilder.build());
System.out.println(Bytes.toString(tableDescriptorBuilder.build().getTableName().getName()) + "表创建 成功 SUCCEED!");
} catch (Exception e) {
System.out.println(Bytes.toString(tableDescriptorBuilder.build().getTableName().getName()) + "表创建 失败!FAILED!");
e.printStackTrace();
}
}
/**
* 删除表
*/
public static void dropTable(String tableName){
try {
//将表名封装成一个TableName对象
TableName name = TableName.valueOf(tableName);
/**
* 判断表是否存在
*/
if (!ADMIN.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表不存在!无法删除!");
return;
}
//禁用表
ADMIN.disableTable(name);
//删除表
ADMIN.deleteTable(name);
System.out.println(Bytes.toString(name.getName()) + "表删除 成功 SUCCEED!");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 清空表数据
*/
public static void truncateTable(String tableName){
try {
//将表名封装成一个TableName对象
TableName name = TableName.valueOf(tableName);
/**
* 判断表是否存在
*/
if (!ADMIN.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表不存在!无法删除!");
return;
}
//注意:如果是使用程序清空数据,需要手动设置禁用
ADMIN.disableTable(name);
ADMIN.truncateTable(name,true);
System.out.println(Bytes.toString(name.getName()) + "表数据清除 成功 SUCCEED!");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取一张表
*/
public static Table getOneTable(String tableName){
Table table = null;
try {
//将表名封装成一个TableName对象
TableName name = TableName.valueOf(tableName);
/**
* 判断表是否存在
*/
if (!ADMIN.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表不存在!");
}
//获取表实例对象
table = CONN.getTable(name);
}catch (Exception e){
e.printStackTrace();
}
return table;
}
/**
* 添加一列数据
*/
public static void putOneColData(String tableName, String rowKey, String familyName, String colName, String colValue){
try {
//将表名封装成一个TableName对象
TableName name = TableName.valueOf(tableName);
/**
* 判断表是否存在
*/
if (!ADMIN.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表不存在!无法添加数据!");
return;
}
//获取表实例对象
Table table = CONN.getTable(name);
//将一列数据封装成一个Put对象,传入一个行键,需要将行键变成一个字节数组的格式
Put put = new Put(Bytes.toBytes(rowKey));
KeyValue keyValue = new KeyValue(Bytes.toBytes(rowKey),
Bytes.toBytes(familyName),
Bytes.toBytes(colName),
Bytes.toBytes(colValue));
put.add(keyValue);
table.put(put);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 打印一行多列数据
*/
public static void printResult(Result result){
String rk = Bytes.toString(result.getRow());
List<Cell> cells = result.listCells();
StringBuilder sb = new StringBuilder();
sb.append("行键:").append(rk).append(", ");
for (int i = 0; i < cells.size(); i++) {
//Hbase中提供了一个专门解析Cell单元格的工具类 CellUtil
String colName = Bytes.toString(CellUtil.cloneQualifier(cells.get(i)));
String colValue = Bytes.toString(CellUtil.cloneValue(cells.get(i)));
if (i != cells.size() - 1) {
sb.append(colName).append(":").append(colValue).append(", ");
} else {
sb.append(colName).append(":").append(colValue);
}
}
System.out.println(sb);
System.out.println("--------------------------------------------");
}
}前期准备
java
private Connection conn;
private Admin admin;
public void connection() {
try {
//新版本创建配置文件对象的方式
Configuration conf = HBaseConfiguration.create();
//设置zookeeper的节点信息
conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
//创建hbase连接对象
conn = ConnectionFactory.createConnection(conf);
//创建数据库操作对象
admin = conn.getAdmin();
System.out.println("成功获取数据库连接对象:" + conn);
System.out.println("成功获取数据库操作对象:" + admin);
System.out.println("=================================================");
} catch (Exception e) {
e.printStackTrace();
}
}
... // 代码撰写处
public void close() {
if (admin != null) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}比较过滤器
所有比较过滤器均继承自
CompareFilter。创建一个比较过滤器需要两个参数,分别是比较运算符 和比较器实例。
比较运算符
-
LESS <
-
LESS_OR_EQUAL <=
-
EQUAL =
-
NOT_EQUAL <>
-
GREATER_OR_EQUAL >=
-
GREATER >
-
NO_OP 排除所有
六大比较器
txt
BinaryComparator
> 按字节索引顺序比较指定字节数组,采用Bytes.compareTo(byte[])
BinaryPrefixComparator
> 通BinaryComparator,只是比较左端前缀的数据是否相同
NullComparator
> 判断给定的是否为空
BitComparator
> 按位比较
RegexStringComparator
> 提供一个正则的比较器,仅支持 EQUAL 和非EQUAL
SubstringComparator
> 判断提供的子串是否出现在中代码演示
rowKey过滤器:RowFilter 行键过滤器
java
/**
* 需求1:通过RowFilter与BinaryComparator过滤比rowKey 1500100010小的所有值出来
*/
@Test
public void rowFilterWithBinaryComparator(){
try {
//将表名封装成一个TableName对象
TableName tableName = TableName.valueOf("students");
/**
* 判断表是否存在
*/
if (!admin.tableExists(tableName)) {
System.out.println(Bytes.toString(tableName.getName()) + " 表不存在!无法查询数据!");
return;
}
//获取表实例对象
Table students = conn.getTable(tableName);
//创建一个Scan对象
Scan scan = new Scan(); //默认是查询所有行数据
//创建BinaryComparator比较器
//public BinaryComparator(byte[] value)
BinaryComparator binaryComparator = new BinaryComparator(Bytes.toBytes("1500100010"));
//创建行键过滤器对象
//旧版本写法:public RowFilter(final CompareOp rowCompareOp, final ByteArrayComparable rowComparator)
// RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.LESS_OR_EQUAL, binaryComparator);
//新版本写法:public RowFilter(final CompareOperator op, final ByteArrayComparable rowComparator)
RowFilter rowFilter = new RowFilter(CompareOperator.LESS, binaryComparator);
//public Scan setFilter(Filter filter)
scan.setFilter(rowFilter);
//表调用方法查询数据
ResultScanner studentsScanner = students.getScanner(scan);
Iterator<Result> resultIterator = studentsScanner.iterator();
while (resultIterator.hasNext()) {
Result result = resultIterator.next();
HbaseUtil.printResult(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}列簇过滤器:FamilyFilter
java
/**
* 需求2:通过FamilyFilter与SubstringComparator查询列簇名包含in的所有列簇下面的数据
*/
@Test
public void familyFilterWithSubstringComparator(){
try {
//将表名封装成一个TableName对象
TableName tableName = TableName.valueOf("users");
/**
* 判断表是否存在
*/
if (!admin.tableExists(tableName)) {
System.out.println(Bytes.toString(tableName.getName()) + " 表不存在!无法查询数据!");
return;
}
//获取表实例对象
Table students = conn.getTable(tableName);
//创建一个Scan对象
Scan scan = new Scan(); //默认是查询所有行数据
//创建包含比较器
SubstringComparator substringComparator = new SubstringComparator("in");
//创建列簇过滤器
//public FamilyFilter(final CompareOperator op,final ByteArrayComparable familyComparator)
FamilyFilter familyFilter = new FamilyFilter(CompareOperator.EQUAL, substringComparator);
scan.setFilter(familyFilter);
//表调用方法查询数据
ResultScanner studentsScanner = students.getScanner(scan);
Iterator<Result> resultIterator = studentsScanner.iterator();
while (resultIterator.hasNext()) {
Result result = resultIterator.next();
HbaseUtil.printResult(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}列名过滤器:QualifierFilter
java
/**
* 需求3:通过QualifierFilter与SubstringComparator查询列名包含ge的列的值
*/
@Test
public void qualifierFilterWithSubstringComparator(){
try {
//将表名封装成一个TableName对象
TableName tableName = TableName.valueOf("students");
/**
* 判断表是否存在
*/
if (!admin.tableExists(tableName)) {
System.out.println(Bytes.toString(tableName.getName()) + " 表不存在!无法查询数据!");
return;
}
//获取表实例对象
Table students = conn.getTable(tableName);
//创建一个Scan对象
Scan scan = new Scan(); //默认是查询所有行数据
//创建包含比较器
SubstringComparator substringComparator = new SubstringComparator("ge");
//创建列名过滤器
//注意:只会过滤出符合条件的列
//public QualifierFilter(final CompareOperator op, final ByteArrayComparable qualifierComparator)
QualifierFilter qualifierFilter = new QualifierFilter(CompareOperator.EQUAL, substringComparator);
scan.setFilter(qualifierFilter);
//表调用方法查询数据
ResultScanner studentsScanner = students.getScanner(scan);
Iterator<Result> resultIterator = studentsScanner.iterator();
while (resultIterator.hasNext()) {
Result result = resultIterator.next();
HbaseUtil.printResult(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}列值过滤器:ValueFilter 只会查询出列值是'张'前缀的这一列,其他列不查
java
/**
* 需求4:通过ValueFilter与BinaryPrefixComparator过滤出所有的cell中值以 "张" 开头的学生
*/
@Test
public void valueFilterWithBinaryPrefixComparator(){
try {
//将表名封装成一个TableName对象
TableName tableName = TableName.valueOf("students");
/**
* 判断表是否存在
*/
if (!admin.tableExists(tableName)) {
System.out.println(Bytes.toString(tableName.getName()) + " 表不存在!无法查询数据!");
return;
}
//获取表实例对象
Table students = conn.getTable(tableName);
//创建一个Scan对象
Scan scan = new Scan(); //默认是查询所有行数据
//创建二进制前缀比较器
BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator(Bytes.toBytes("张"));
//创建列值过滤器
//public ValueFilter(final CompareOperator valueCompareOp, final ByteArrayComparable valueComparator)
ValueFilter valueFilter = new ValueFilter(CompareOperator.EQUAL, binaryPrefixComparator);
scan.setFilter(valueFilter);
//表调用方法查询数据
ResultScanner studentsScanner = students.getScanner(scan);
Iterator<Result> resultIterator = studentsScanner.iterator();
while (resultIterator.hasNext()) {
Result result = resultIterator.next();
HbaseUtil.printResult(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}专用过滤器
单列值过滤器:SingleColumnValueFilter
SingleColumnValueFilter会返回满足条件的cell所在行的所有cell的值(即会返回一行数据)
通过SingleColumnValueFilter与查询文科班所有学生信息
java
/**
* 专用过滤器:单列值过滤器 返回的符合条件一行所有列数据
* 需求1:通过SingleColumnValueFilter与查询文科班所有学生信息
*/
@Test
public void singleColumnValueFilterWithBinaryPrefixComparator(){
try {
//将表名封装成一个TableName对象
TableName tableName = TableName.valueOf("students");
/**
* 判断表是否存在
*/
if (!admin.tableExists(tableName)) {
System.out.println(Bytes.toString(tableName.getName()) + " 表不存在!无法查询数据!");
return;
}
//获取表实例对象
Table students = conn.getTable(tableName);
//创建一个Scan对象
Scan scan = new Scan(); //默认是查询所有行数据
//创建二进制前缀比较器
BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator(Bytes.toBytes("文科"));
//创建单列值过滤器
//public SingleColumnValueFilter(final byte [] family, final byte [] qualifier,
// final CompareOperator op,
// final org.apache.hadoop.hbase.filter.ByteArrayComparable comparator)
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(Bytes.toBytes("info"),
Bytes.toBytes("clazz"),
CompareOperator.EQUAL,
binaryPrefixComparator);
scan.setFilter(singleColumnValueFilter);
//表调用方法查询数据
ResultScanner studentsScanner = students.getScanner(scan);
Iterator<Result> resultIterator = studentsScanner.iterator();
while (resultIterator.hasNext()) {
Result result = resultIterator.next();
HbaseUtil.printResult(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}列值排除过滤器:SingleColumnValueExcludeFilter
与SingleColumnValueFilter相反,会排除掉指定的列,其他的列全部返回
通过SingleColumnValueExcludeFilter与BinaryComparator查询文科一班所有学生信息,最终不返回clazz列
java
/**
* 需求2:使用单列值排除过滤器
* 通过SingleColumnValueExcludeFilter与BinaryComparator查询文科一班所有学生信息
*/
@Test
public void singleColumnValueExcludeFilterWithBinaryPrefixComparator(){
try {
//将表名封装成一个TableName对象
TableName tableName = TableName.valueOf("students");
/**
* 判断表是否存在
*/
if (!admin.tableExists(tableName)) {
System.out.println(Bytes.toString(tableName.getName()) + " 表不存在!无法查询数据!");
return;
}
//获取表实例对象
Table students = conn.getTable(tableName);
//创建一个Scan对象
Scan scan = new Scan(); //默认是查询所有行数据
//创建二进制前缀比较器
BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator(Bytes.toBytes("文科一班"));
//创建单列值过滤器
//public SingleColumnValueFilter(final byte [] family, final byte [] qualifier,
// final CompareOperator op,
// final org.apache.hadoop.hbase.filter.ByteArrayComparable comparator)
SingleColumnValueExcludeFilter singleColumnValueExcludeFilter = new SingleColumnValueExcludeFilter(Bytes.toBytes("info"),
Bytes.toBytes("clazz"),
CompareOperator.EQUAL,
binaryPrefixComparator);
scan.setFilter(singleColumnValueExcludeFilter);
//表调用方法查询数据
ResultScanner studentsScanner = students.getScanner(scan);
Iterator<Result> resultIterator = studentsScanner.iterator();
while (resultIterator.hasNext()) {
Result result = resultIterator.next();
HbaseUtil.printResult(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}rowkey前缀过滤器:PrefixFilter
通过PrefixFilter查询以15001001开头的所有前缀的rowkey
java
/**
* 需求3:通过PrefixFilter查询以15001001开头的所有前缀的rowkey
*/
@Test
public void prefixFilter(){
try {
//将表名封装成一个TableName对象
TableName tableName = TableName.valueOf("students");
/**
* 判断表是否存在
*/
if (!admin.tableExists(tableName)) {
System.out.println(Bytes.toString(tableName.getName()) + " 表不存在!无法查询数据!");
return;
}
//获取表实例对象
Table students = conn.getTable(tableName);
//创建一个Scan对象
Scan scan = new Scan(); //默认是查询所有行数据
//创建前缀过滤器
PrefixFilter prefixFilter = new PrefixFilter(Bytes.toBytes("150010002"));
scan.setFilter(prefixFilter);
//表调用方法查询数据
ResultScanner studentsScanner = students.getScanner(scan);
Iterator<Result> resultIterator = studentsScanner.iterator();
while (resultIterator.hasNext()) {
Result result = resultIterator.next();
HbaseUtil.printResult(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}分页过滤器PageFilter
通过PageFilter查询三页的数据,每页10条
使用PageFilter分页效率比较低,每次都需要扫描前面的数据,直到扫描到所需要查的数据
可设计一个合理的rowkey来实现分页需求
注意事项:客户端进行分页查询,需要传递 startRow(起始 RowKey),知道起始 startRow 后,就可以返回对应的 pageSize 行数据。这里唯一的问题就是,对于第一次查询,显然 startRow 就是表格的第一行数据,但是之后第二次、第三次查询我们并不知道 startRow,只能知道上一次查询的最后一条数据的 RowKey(简单称之为 lastRow)。
我们不能将 lastRow 作为新一次查询的 startRow 传入,因为 scan 的查询区间是[startRow,endRow) ,即前开后闭区间,这样 startRow 在新的查询也会被返回,这条数据就重复了。
同时在不使用第三方数据库存储 RowKey 的情况下,我们是无法通过知道 lastRow 的下一个 RowKey 的,因为 RowKey 的设计可能是连续的也有可能是不连续的。
由于 Hbase 的 RowKey 是按照字典序进行排序的。这种情况下,就可以在 lastRow 后面加上 0 ,作为 startRow 传入,因为按照字典序的规则,某个值加上 0 后的新值,在字典序上一定是这个值的下一个值,对于 HBase 来说下一个 RowKey 在字典序上一定也是等于或者大于这个新值的。
所以最后传入 lastRow+0,如果等于这个值的 RowKey 存在就从这个值开始 scan,否则从字典序的下一个 RowKey 开始 scan。
25 个字母以及数字字符,字典排序如下:
''<'0' < '1' < '2' < ... < '9' < 'a' < 'b' < ... < 'z'
需要注意的是在多台 Regin Services 上执行分页过滤的时候,由于并行执行的过滤器不能共享它们的状态和边界,所以有可能每个过滤器都会在完成扫描前获取了 PageCount 行的结果,这种情况下会返回比分页条数更多的数据,分页过滤器就有失效的可能。
java
/**
* PageFilter 分页过滤器
* 需求:查询5页数据,每页10条
*/
@Test
public void PageFilter() {
try {
//将表名封装成TableName的对象
TableName tableName = TableName.valueOf("students");
//获取表
Table students = conn.getTable(tableName);
//定义一些变量
//定义查询的页数
int pageNumber = 5;
//定义每一页的条数
int pageDataNumber = 10;
//设置最开始的行
Scan scan = new Scan();
scan.withStartRow(Bytes.toBytes(""));
//创建一个分页过滤器
PageFilter pageFilter = new PageFilter(pageDataNumber);
scan.setFilter(pageFilter);
for (int i = 1; i <= pageNumber;i++) {
System.out.println("==================当前是第 "+i+" 页数据======================");
ResultScanner resultScanner = students.getScanner(scan);
Iterator<Result> iterator = resultScanner.iterator();
while (iterator.hasNext()){
Result result = iterator.next();
/**
* 关键代码
*/
//TODO: 关键代码,查找下一条数据的关键
//上一页最后一条数据的行键加上0 作为下一页的开始行
scan.withStartRow(Bytes.toBytes(Bytes.toString(result.getRow())+"0"));
HbaseUtil.printResult(result);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}包装过滤器
SkipFilter过滤器
SkipFilter包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,则拓展过滤整行数据。下面是一个使用示例:
java
/**
* SkipFiler
* 跳过带有"施笑槐"的一行数据
*/
@Test
public void SkipFiler(){
try {
//将表名封装成TableName的对象
TableName tableName = TableName.valueOf("students");
//获取表
Table students = conn.getTable(tableName);
//创建列值过滤器
ValueFilter valueFilter = new ValueFilter(CompareOperator.NOT_EQUAL, new BinaryComparator(Bytes.toBytes("施笑槐")));
//创建Skip过滤器 包装列值过滤器
SkipFilter skipFilter = new SkipFilter(valueFilter);
//设置最开始的行
Scan scan = new Scan();
scan.setFilter(skipFilter);
ResultScanner resultScanner = students.getScanner(scan);
Iterator<Result> iterator = resultScanner.iterator();
while (iterator.hasNext()){
Result result = iterator.next();
HbaseUtil.printResult(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}WhileMatchFilter过滤器
WhileMatchFilter 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时 ,WhileMatchFilter 则结束本次扫描,返回已经扫描到的结果。下面是其使用示例:
java
/**
* WhileMatchFilter
* 遇到带有'边昂雄'这一行数据时,结束本次查询
*/
@Test
public void WhileMatchFilter(){
try {
//将表名封装成TableName的对象
TableName tableName = TableName.valueOf("students");
//获取表
Table students = conn.getTable(tableName);
//创建列值过滤器
ValueFilter valueFilter = new ValueFilter(CompareOperator.NOT_EQUAL, new BinaryComparator(Bytes.toBytes("边昂雄")));
//创建WhileMatchFilter过滤器
WhileMatchFilter whileMatchFilter = new WhileMatchFilter(valueFilter);
//设置最开始的行
Scan scan = new Scan();
scan.setFilter(whileMatchFilter);
ResultScanner resultScanner = students.getScanner(scan);
Iterator<Result> iterator = resultScanner.iterator();
while (iterator.hasNext()){
Result result = iterator.next();
HbaseUtil.printResult(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}多过滤器综合查询
以上都是讲解单个过滤器的作用,当需要多个过滤器共同作用于一次查询的时候,就需要使用 FilterList。FilterList 支持通过构造器或者 addFilter 方法传入多个过滤器。
java
/**
* 需求:过滤出姓田,男生,年龄大于21,文科
* 组合过滤器的使用
*/
@Test
public void groupFilter() {
try {
//将表名封装成一个TableName对象
TableName tableName = TableName.valueOf("students");
/**
* 判断表是否存在
*/
if (!admin.tableExists(tableName)) {
System.out.println(Bytes.toString(tableName.getName()) + " 表不存在!无法查询数据!");
return;
}
//获取表实例对象
Table students = conn.getTable(tableName);
//创建一个Scan对象
Scan scan = new Scan(); //默认是查询所有行数据
//创建一个存储Filter对象的集合
ArrayList<Filter> filters = new ArrayList<>();
//过滤出姓田
//创建单列值过滤器
SingleColumnValueFilter filter1 = new SingleColumnValueFilter(Bytes.toBytes("info"),
Bytes.toBytes("name"),
CompareOperator.EQUAL,
new BinaryPrefixComparator(Bytes.toBytes("丁")));
filters.add(filter1);
//男生
SingleColumnValueFilter filter2 = new SingleColumnValueFilter(Bytes.toBytes("info"),
Bytes.toBytes("gender"),
CompareOperator.EQUAL,
new BinaryComparator(Bytes.toBytes("男")));
filters.add(filter2);
//年龄大于21
SingleColumnValueFilter filter3 = new SingleColumnValueFilter(Bytes.toBytes("info"),
Bytes.toBytes("age"),
CompareOperator.GREATER,
new BinaryComparator(Bytes.toBytes("21")));
filters.add(filter3);
//文科
SingleColumnValueFilter filter4 = new SingleColumnValueFilter(Bytes.toBytes("info"),
Bytes.toBytes("clazz"),
CompareOperator.EQUAL,
new BinaryPrefixComparator(Bytes.toBytes("文科")));
filters.add(filter4);
//如果以一次设置一个过滤器来做的话,只有最后一个过滤器生效
// scan.setFilter(filter1);
// scan.setFilter(filter2);
// scan.setFilter(filter3);
// scan.setFilter(filter4);
//如果要使用组合过滤器的话,使用FilterList类来实现
FilterList filterList = new FilterList();
// filterList.addFilter(filter1);
// filterList.addFilter(filter2);
// filterList.addFilter(filter3);
// filterList.addFilter(filter4);
filterList.addFilter(filters);
scan.setFilter(filterList);
//表调用方法查询数据
ResultScanner studentsScanner = students.getScanner(scan);
Iterator<Result> resultIterator = studentsScanner.iterator();
while (resultIterator.hasNext()) {
Result result = resultIterator.next();
HbaseUtil.printResult(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}案例:查询文科一班学生总分排名前10的学生(输出:学号,姓名,班级,总分)结果写到hbase
java
/**
* 查询文科一班学生总分排名前10的学生(输出:学号,姓名,班级,总分)结果写到hbase
*/
public class HbaseTest {
public static void main(String[] args) throws Exception {
/**
* 将学生成绩数据添加到hbase表中
*/
// putScoreData();
/**
* 读取成绩表,计算每个人的总分,写入到hbase另一张表中
*/
// HbaseUtil.truncateTable("sumScore");
// getSumScoreStudents();
/**
* 获取前几的学生数据 学号,姓名,班级,总分
*/
getTopNStudents();
}
public static void getTopNStudents() {
try {
Scanner sc = new Scanner(System.in);
System.out.print("请输入要查询的前topN个数:");
int topN = sc.nextInt();
//TODO:学号,姓名,班级,总分
//获取要查询的表
Table sumScore = HbaseUtil.getOneTable("sumScore");
Table students = HbaseUtil.getOneTable("students");
//创建sumScore表的Scan对象,并设置limit的个数
Scan scoreScan = new Scan();
scoreScan.setLimit(topN);
//创建集合存储查询的结果
TreeMap<String, String> sumScoreMap = new TreeMap<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
//显示条件
return (o2.compareTo(o1) == 0) ? -1 : o2.compareTo(o1);
}
});
//查询数据得到结果
ResultScanner resultScanner = sumScore.getScanner(scoreScan);
for (Result result : resultScanner) {
String id = Bytes.toString(result.getRow()).split("_")[1];
String score = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sum_score")));
sumScoreMap.put(score, id);
}
//拿着第一张表查询的结果查询学生的详细信息
//使用获取所有键值对的方式遍历map集合
// Set<Map.Entry<String, String>> entries = sumScoreMap.entrySet();
// for (Map.Entry<String, String> entry : entries) {
// String id = entry.getKey();
// String score = entry.getValue();
// }
//使用获取所有键,然后根据键获取值的方式遍历map集合
//使用lambda表达式,消费型接口遍历map集合
sumScoreMap.forEach((k, v) -> {
try {
Get get = new Get(Bytes.toBytes(v));
Result result = students.get(get);
//获取姓名
String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));
System.out.println("学号:" + v + ", 姓名:" + name + ", 班级:" + clazz + ", 总分:" + k);
System.out.println("-----------------------------------------------------[");
} catch (Exception e) {
e.printStackTrace();
}
});
} catch (Exception e) {
e.printStackTrace();
}
}
public static void getSumScoreStudents() throws Exception {
Table scores = HbaseUtil.getOneTable("scores");
Scan scan = new Scan();
ResultScanner resultScanner = scores.getScanner(scan);
//创建Map集合存储学号和总分的关系
HashMap<String, Integer> scoreMap = new HashMap<>();
//遍历每一行数据
for (Result result : resultScanner) {
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
//获取行键
String id = Bytes.toString(CellUtil.cloneRow(cell)).split("-")[0];
int score = Integer.parseInt(Bytes.toString(CellUtil.cloneValue(cell)));
if (!scoreMap.containsKey(id)) {
scoreMap.put(id, score);
} else {
scoreMap.put(id, scoreMap.get(id) + score);
}
}
}
// scoreMap.forEach((k, v) -> System.out.println("学号: " + k + ", 总分: " + v));
HbaseUtil.createOneTable("sumScore", "info");
// 设计rowKey 使得按照总分排序 利用大-小=大 大-大=小 小按字典序排在前
scoreMap.forEach((k, v) -> HbaseUtil.putOneColData("sumScore", (1000 - v) + "_" + k, "info", "sum_score", v.toString()));
}
// 添加数据
public static void putScoreData() throws Exception {
HbaseUtil.createOneTable("scores", "info");
BufferedReader br = new BufferedReader(new FileReader("hbase/data/score.txt"));
String line = null;
while ((line = br.readLine()) != null) {
String[] infos = line.split(",");
/**
* hbase中行键的设计原则:
* 1、唯一性
* 2、散列性
* 3、长度不宜过长
*/
// 改变rowKey 将id与科目编号 拼在一起 行键就不会重复 数据不会被覆盖
HbaseUtil.putOneColData("scores", infos[0] + "-" + infos[1], "info", "subject_score", infos[2]);
}
}
}布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 "某样东西一定不存在或者可能存在"。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
实际上,布隆过滤器广泛应用于网页黑名单系统 、垃圾邮件过滤系统 、爬虫网址判重系统等,Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的 IO 次数,Google Chrome 浏览器使用了布隆过滤器加速安全浏览服务。
在很多 Key-Value 系统中也使用了布隆过滤器来加快查询过程,如 Hbase,Accumulo,Leveldb,一般而言,Value 保存在磁盘中,访问磁盘需要花费大量时间,然而使用布隆过滤器可以快速判断某个 Key 对应的 Value 是否存在,因此可以避免很多不必要的磁盘 IO 操作。
通过一个 Hash 函数将一个元素映射成一个位阵列(Bit Array)中的一个点。这样一来,我们只要看看这个点是不是 1 就知道可以集合中有没有它了。这就是布隆过滤器的基本思想。
运用场景
1、目前有 10 亿数量的自然数,乱序排列,需要对其排序。限制条件在 32 位机器上面完成,内存限制为 2G。如何完成?
2、如何快速在亿级黑名单中快速定位 URL 地址是否在黑名单中?(每条 URL 平均 64 字节)
3、需要进行用户登陆行为分析,来确定用户的活跃情况?
4、网络爬虫-如何判断 URL 是否被爬过?
5、快速定位用户属性(黑名单、白名单等)?
6、数据存储在磁盘中,如何避免大量的无效 IO?
7、判断一个元素在亿级数据中是否存在?
8、缓存穿透。
实现原理
假设我们有个集合 A,A 中有 n 个元素。利用k个哈希散列 函数,将A中的每个元素映射 到一个长度为 a 位的数组 B中的不同位置上,这些位置上的二进制数均设置为 1。如果待检查的元素,经过这 k个哈希散列函数的映射后,发现其 k 个位置上的二进制数全部为 1 ,这个元素很可能属于集合A,反之,一定不属于集合A。
比如我们有 3 个 URL
{URL1,URL2,URL3},通过一个hash 函数把它们映射到一个长度为 16 的数组上,如下:
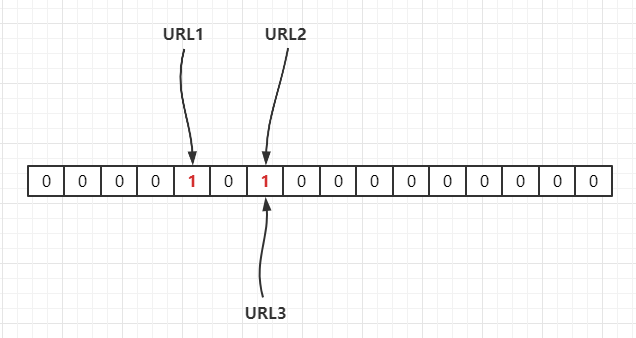
若当前哈希函数为
Hash1(),通过哈希运算映射到数组中,假设Hash1(URL1) = 4,Hash1(URL2) = 6,Hash1(URL3) = 6,如下:
因此,如果我们需要判断
URL1是否在这个集合中,则通过Hash(urL1)计算出其下标,并得到其值若为 1 则说明存在。由于 Hash 存在哈希冲突,如上面
URL2,URL3都定位到一个位置上,假设 Hash 函数是良好的,如果我们的数组长度为 m 个点,那么如果我们想将冲突率降低到例如 1% , 这个散列表就只能容纳m/100个元素,显然空间利用率就变低了,也就是没法做到空间有效(space-efficient)。解决方法也简单,就是使用多个 Hash 算法,如果它们有一个说元素不在集合中,那肯定就不在,如下:
shell
Hash1(URL1) = 3,Hash2(URL1) = 5,Hash3(URL1) = 6
Hash1(URL2) = 5,Hash2(URL2) = 7,Hash3(URL2) = 13
Hash1(URL3) = 4,Hash2(URL3) = 7,Hash3(URL3) = 10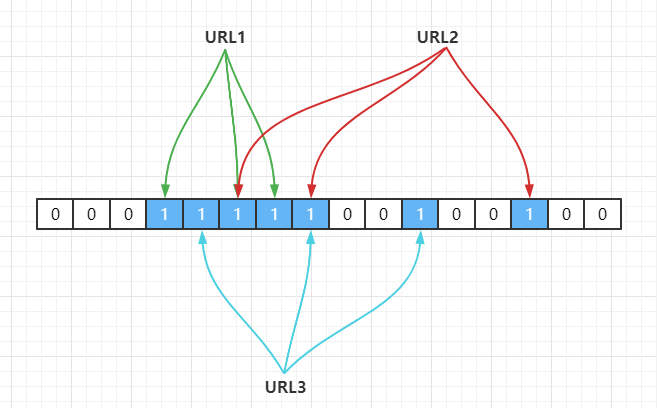
以上就是布隆过滤器做法,使用了k个哈希函数,每个字符串跟 k 个 bit 对应,从而降低了冲突的概率。
误判现象
上面的做法同样存在问题,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断这个值存在。比如此时来一个不存在的
URL1000,经过哈希计算后,发现 bit 位为下:
shell
Hash1(URL1000) = 7,Hash2(URL1000) = 8,Hash3(URL1000) = 14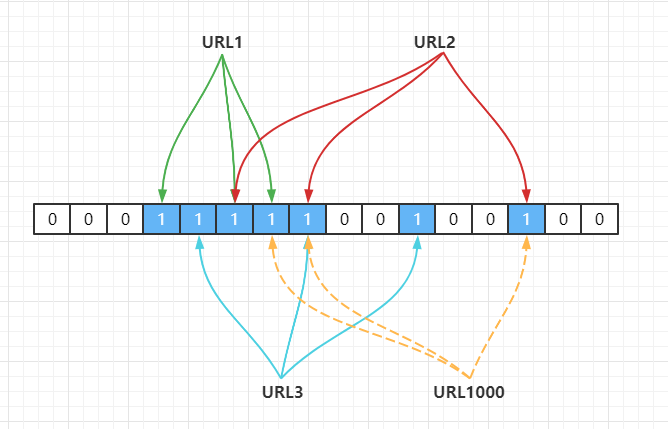
但是上面这些 bit 位已经被
URL1,URL2,URL3置为 1 了,此时程序就会判断URL1000值存在。这就是布隆过滤器的误判现象,所以,布隆过滤器判断存在的不一定存在,但是,判断不存在的一定不存在。
布隆过滤器可精确的代表一个集合,可精确判断某一元素是否在此集合中,精确程度由用户的具体设计决定,达到 100% 的正确是不可能的。但是布隆过滤器的优势在于,利用很少的空间可以达到较高的精确率。
控制粒度
a)ROW
根据KeyValue中的行来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v),kv2(r2 cf:q1 v)
sf2包含kv3(r3 cf:q1 v),kv4(r4 cf:q1 v)
若是设置了CF属性中的bloomfilter为ROW,那么得(r1)时就会过滤sf2,get(r3)就会过滤sf1
b)ROWCOL根据KeyValue中的行+限定符来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v),kv2(r2 cf:q1 v)
sf2包含kv3(r1 cf:q2 v),kv4(r2 cf:q2 v)
若是设置了CF属性中的布隆过滤器为ROW,不管获得(R1,Q1)仍是获得(R1,Q2),都会读取SF1 + SF2;而若是设置了CF属性中的布隆过滤器为 ROWCOL,那么GET(R1, q1)就会过滤sf2,get(r1,q2)就会过滤sf1
c)NO默认的值,默认不开启布隆过滤器
实现:在建表时设置
java
try {
for (String familyName : familyNames) {
// ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.of(familyName);
ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(familyName))
.setBloomFilterType(BloomType.ROW) // 设置布隆过滤器
.build();
tableDescriptorBuilder.setColumnFamily(info);
}
if (ADMIN.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表已经存在!");
return;
}
ADMIN.createTable(tableDescriptorBuilder.build());
System.out.println(Bytes.toString(tableDescriptorBuilder.build().getTableName().getName()) + "表创建 成功 SUCCEED!");
} catch (Exception e) {
System.out.println(Bytes.toString(tableDescriptorBuilder.build().getTableName().getName()) + "表创建 失败!FAILED!");
e.printStackTrace();
}
}HBase的读写流程
HBase读流程:
Hbase读取数据的流程:
1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接
2)从zookeeper中获取一个hbase:meta表位置信息,被哪一个regionserver所管理着
hbase:meta表:hbase的元数据表,在这个表中存储了自定义表相关的元数据,包括表名,表有哪些列簇,表有哪些region,每个region存储的位置,每个region被哪个regionserver所管理,这个表也是存储在某一个region上的,并且这个meta表只会被一个regionserver所管理。这个表的位置信息只有zookeeper知道。
3)连接这个meta表对应的regionserver,从meta表中获取当前你要读取的这个表对应的regionsever是谁。
当一个表多个region怎么办呢?
如果我们获取数据是以get的方式,只会返回一个regionserver
如果我们获取数据是以scan的方式,会将所有的region对应的regionserver的地址全部返回。
4)连接要读取表的对应的regionserver,从regionserver上的开始读取数据:
读取顺序:memstore-->blockcache-->storefile-->Hfile中
注意:如果是scan操作,就不仅仅去blockcache了,而是所有都会去找。
HBase写流程:
--------------------------1-4步是客户端写入数据的流程-----------------
Hbase的写入数据流程:
1)由客户端发起写数据请求,首先会与zookeeper建立连接
2)从zookeeper中获取hbase:meta表被哪一个regionserver所管理
3)连接hbase:meta表中获取对应的regionserver地址 (从meta表中获取当前要写入数据的表对应的region所管理的regionserver) 只会返回一个regionserver地址
4)与要写入数据的regionserver建立连接,然后开始写入数据,将数据首先会写入到HLog,然后将数据写入到对应store模块中的memstore中
(可能会写多个),当这两个地方都写入完成之后,表示数据写入完成。
-------------------------后面的步骤是服务器内部的操作-----------------
异步操作
5)随着客户端不断地写入数据,memstore中的数据会越来多,当内存中的数据达到阈值(128M/1h)的时候,放入到blockchache中,生成新的memstore接收用户过来的数据,然后当blockcache的大小达到一定阈值(0.85)的时候,开始触发flush机制,将数据最终刷新到HDFS中形成小的Hfile文件。
6)随着不断地刷新,storefile不断地在HDFS上生成小HFIle文件,当小的HFile文件达到阈值的时候(3个及3个以上),就会触发Compaction机制,将小的HFile合并成一个大的HFile.
7)随着不断地合并,大的HFile文件会越来越大,当达到一定阈值(2.0版本之后最终10G)的时候,会触发分裂机制(split),将大的HFile文件进行一分为二,同时管理这个大的HFile的region也会被一分为二,形成两个新的region和两个新的HFile文件,一对一的进行管理,将原来旧的region和分裂之前大的HFile文件慢慢地就会下线处理。
Region的分裂策略
region中存储的是一张表的数据,当region中的数据条数过多的时候,会直接影响查询效率。当region过大的时候,region会被拆分为两个region,HMaster会将分裂的region分配到不同的regionserver上,这样可以让请求分散到不同的RegionServer上,已达到负载均衡 , 这也是HBase的一个优点 。
-
ConstantSizeRegionSplitPolicy
0.94版本前,HBase region的默认切分策略
当region中最大的store大小超过某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region。
但是在生产线上这种切分策略却有相当大的弊端(切分策略对于大表和小表没有明显的区分):
- 阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,形成热点,这对业务来说并不是什么好事。
- 如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的region,这对于集群的管理、资源使用、failover来说都不是一件好事。
-
IncreasingToUpperBoundRegionSplitPolicy
0.94版本~2.0版本默认切分策略
总体看和ConstantSizeRegionSplitPolicy思路相同,一个region中最大的store大小大于设置阈值就会触发切分。
但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系.
region split阈值的计算公式是:
-
设regioncount:是region所属表在当前regionserver上的region的个数
-
阈值 = regioncount^3 * 128M * 2,当然阈值并不会无限增长,最大不超过MaxRegionFileSize(10G),当region中最大的store的大小达到该阈值的时候进行region split
例如:
- 第一次split阈值 = 1^3 * 256 = 256MB
- 第二次split阈值 = 2^3 * 256 = 2048MB
- 第三次split阈值 = 3^3 * 256 = 6912MB
- 第四次split阈值 = 4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
- 后面每次split的size都是10GB了
特点
- 相比ConstantSizeRegionSplitPolicy,可以自适应大表、小表;
- 在集群规模比较大的情况下,对大表的表现比较优秀
- 对小表不友好,小表可能产生大量的小region,分散在各regionserver上
- 小表达不到多次切分条件,导致每个split都很小,所以分散在各个regionServer上
-
-
SteppingSplitPolicy
2.0版本默认切分策略
相比 IncreasingToUpperBoundRegionSplitPolicy 简单了一些
region切分的阈值依然和待分裂region所属表在当前regionserver上的region个数有关系
- 如果region个数等于1,切分阈值为flush size 128M
- 否则为MaxRegionFileSize。
这种切分策略对于大集群中的大表、小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小region,而是适可而止。
-
KeyPrefixRegionSplitPolicy
根据rowKey的前缀对数据进行分区,这里是指定rowKey的前多少位作为前缀,比如rowKey都是16位的,指定前5位是前缀,那么前5位相同的rowKey在相同的region中。
-
DelimitedKeyPrefixRegionSplitPolicy
保证相同前缀的数据在同一个region中,例如rowKey的格式为:userid_eventtype_eventid,指定的delimiter为 _ ,则split的的时候会确保userid相同的数据在同一个region中。
按照分隔符进行切分,而KeyPrefixRegionSplitPolicy是按照指定位数切分。
-
BusyRegionSplitPolicy
按照一定的策略判断Region是不是Busy状态,如果是即进行切分
如果你的系统常常会出现热点Region,而你对性能有很高的追求,那么这种策略可能会比较适合你。它会通过拆分热点Region来缓解热点Region的压力,但是根据热点来拆分Region也会带来很多不确定性因素,因为你也不知道下一个被拆分的Region是哪个。
-
DisabledRegionSplitPolicy
不启用自动拆分, 需要指定手动拆分
Compaction合并操作
Minor Compaction:
- 指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次 Minor Compaction 的结果是更少并且更大的StoreFile。
Major Compaction:
- 指将所有的StoreFile 合并成一个StoreFile,这个过程会清理三类没有意义的数据:被删除的数据 、TTL过期数据 、版本号超过设定版本号的数据。另外,一般情况下,major compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此线上业务都会将关闭自动触发major compaction功能,改为手动在业务低峰期触发。
面对百亿数据,HBase为什么查询速度依然非常快?(重要!!!)
第1步:
项目有100亿业务数据,存储在一个HBase集群上(由多个服务器数据节点构成),每个数据节点上有若干个Region(区域),每个Region实际上就是HBase中一批数据的集合(一段连续范围rowkey的数据)。
我们现在开始根据主键RowKey来查询对应的记录,通过meta表可以帮我们迅速定位到该记录所在的数据节点,以及数据节点中的Region,目前我们有100亿条记录,占空间10TB。所有记录被切分成5000个Region,那么现在,每个Region就是2G。
由于记录在1个Region中,所以现在我们只要查询这2G的记录文件(其他的4999个不用查),就能找到对应记录。
第2步:
由于HBase存储数据是按照列族存储的。比如一条记录有400个字段,前100个字段是人员信息相关,这是一个列簇(列的集合);中间100个字段是公司信息相关,是一个列簇。另外100个字段是人员交易信息相关,也是一个列簇;最后还有100个字段是其他信息,也是一个列簇
这四个列簇是分开存储的,这时,假设2G的Region文件中,分为4个列族,那么每个列族就是500M。
到这里,我们只需要遍历这500M(一个)的列簇就可以找到对应的记录。
第3步:
如果要查询的记录在其中1个列族上,1个列族在HDFS中会包含1个或者多个HFile。
如果一个HFile一般的大小为100M,那么该列族包含5个HFile在磁盘上或内存中。
由于HBase的内存进入磁盘中的数据是排好序(字典顺序)的,要查询的记录有可能在最前面,也有可能在最后面,按平均来算,我们只需遍历2.5个HFile共250M,即可找到对应的记录。
第4步:
每个HFile中,是以键值对(key/value)方式存储,只要遍历文件中的key位置并判断符合条件即可
一般key是有限的长度,假设key/value比是1:24,最终只需要10M的数据量(只找行键),就可获取的对应的记录。
如果数据在机械磁盘上,按其访问速度100M/S,只需0.1秒即可查到。
如果是SSD的话,0.01秒即可查到。
当然,扫描HFile时还可以通过布隆过滤器 快速定位到对应的HFile,以及HBase是有内存缓存机制的,如果数据在内存中,效率会更高。
总结
正因为以上大致的查询思路,层层降维,保证了HBase即使随着数据量的剧增,也不会导致查询性能的下降。
同时,HBase是一个面向列存储的数据库(列簇机制),当表字段非常多时,可以把其中一些字段独立出来放在一部分机器上,而另外一些字段放到另一部分机器上,分散存储,分散列查询。
正由于这样复杂的存储结构和分布式的存储方式,保证了HBase海量数据下的查询效率。
HBase与Hive的集成
为什么?
hbase查询速度快,但是无法做一些复杂的数据分析,比如分组聚合,切分等
hive有许多复杂的函数可以处理
它两的最终结果都会在hdfs上,不过hbase的是以hfile的形式
将hive底层的mr的输入,输出的类改为hbase文件读写的类 hive就可以读写Hfile文件...
HBase与Hive的对比
hive:
数据仓库:Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
用于数据分析、清洗:Hive适用于离线的数据分析和清洗,延迟较高(底层是MR导致的)。
基于HDFS、MapReduce:Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。
HBase
数据库:是一种面向列族存储的非关系型数据库。
用于存储结构化和非结构化的数据:适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
基于HDFS:数据持久化存储的体现形式是HFile,存放于DataNode中,被ResionServer以region的形式进行管理。
延迟较低,接入在线业务使用:面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
在 hive-site.xml 中添加zookeeper的属性
xml
<property>
<name>hive.zookeeper.quorum</name>
<value>master,node1,node2</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>在hive中建表
sql
create external table students_hbase
(
id string,
name string,
age string,
gender string,
clazz string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" = "
:key,
info:name,
info:age,
info:gender,
info:clazz
")
tblproperties("hbase.table.name" = "default:students");表中直接出现hbase表中的数据:
关联后就可以使用Hive函数进行一些分析操作了。
Phoenix
hoenix 基于Hbase给面向业务的开发人员提供了以标准SQL的方式对Hbase进行查询操作,并支持标准SQL中大部分特性:条件运算,分组,分页,等高级查询语法
Phoenix搭建
1.关闭hbase集群
2.上传解压配置环境变量
shell
tar -zxvf phoenix-hbase-2.2-5.1.3-bin.tar.gz
# 修改名称
mv phoenix-hbase-2.2-5.1.3-bin/ phoenix-5.1.3
#配置环境变量
PHOENIX_HOME=/usr/local/soft/phoenix-5.1.3
export PATH=$PHOENIX_HOME/bin:$PATH
#source生效
source /etc/profile3.将phoenix-server-hbase-2.2-5.1.3.jar复制到所有节点的hbase lib目录下
shell
scp phoenix-server-hbase-2.2-5.1.3.jar master:/usr/local/soft/hbase-2.2.7/lib/
scp phoenix-server-hbase-2.2-5.1.3.jar node1:/usr/local/soft/hbase-2.2.7/lib/
scp phoenix-server-hbase-2.2-5.1.3.jar node2:/usr/local/soft/hbase-2.2.7/lib/4.启动hbase
Phoenix的使用
连接sqlline
shell
sqlline.py master,node1,node2
phoenix语法
1、在phoneix内部创建表的时候,表名最后可以使用!table或者show tables命令查看,并且以大写的形式展示给我们,但是我们在使用sql语句查询的时候既可以用大写也可以用小写。(列名和表名大小写无所谓)
2 、直接在phoneix内部创建的表,在hbase中可以以大写的方式查看到,但是在hbase中建的表,在phoneix中看不到。
3、如何在phoneix中使用hbase原本的数据表呢?
视图映射:视图并不是真正意义上的表,而是在phoneix创建一个映射关系,以表的形式将hbase中原本数据映射过来,可以在基础之上编写sql语句进行分析,需要注意的是,我们在视图上sql分析的时候,表名和列名需要加双引号。删除视图不会影响原本hbase中的数据,视图无法做修改,只能查询,视图在phoneix中被看作成一个只读表。
表映射:建表的语法来说与视图映射相差一个单词,其他的没啥区别。使用上,表映射可以直接在phoneix中对表数据进行增删改查。将phoneix中表映射删了,原来hbase中的表也对应删除。
4、映射查询的时候,主键可以不用加双引号,非主键的列必须加双引号
phoneix数据类型
sql
# 1、创建表
CREATE TABLE IF NOT EXISTS students_p1 (
id VARCHAR NOT NULL PRIMARY KEY,
name VARCHAR,
age BIGINT,
gender VARCHAR ,
clazz VARCHAR
);
# 2、显示所有表
!table
# 3、插入数据
upsert into students_p1 values('1500101001','小虎',22,'男','理科一班');
upsert into students_p1 values('1500101002','三虎',23,'女','理科一班');
upsert into students_p1 values('1500101003','二虎',24,'男','理科二班');
upsert into students_p1 values('1500101004','大虎',25,'女','理科二班');
# 4、查询数据,支持大部分sql语法,
select * from students_p1 ;
select * from students_p1 where age=24;
select gender ,count(*) from students_p1 group by gender;
select * from students_p1 order by gender;
#注意 如果在hbase浏览这张表时,表名要大写
scan 'STUDENTS_P1'
# 5、删除数据
delete from students_p1 where id='1500100004';
# 6、删除表
drop table students_p1;
# 7、退出命令行
!quit
更多语法参照官网
https://phoenix.apache.org/language/index.html#如果使用上述方式 插入数据 太慢太麻烦了 可以使用映射的方式
phoenix表映射
默认情况下,直接在hbase中创建的表,通过phoenix是查看不到的
如果需要在phoenix中操作直接在hbase中创建的表,则需要在phoenix中进行表的映射。映射方式有两种:视图映射和表映射
视图映射
Phoenix创建的视图是只读的,所以只能用来做查询,无法通过视图对源数据进行增删改等操作
sql
# 创建hbase表
create 'test','name','company'
# 插入数据
put 'test','001','name:firstname','zhangsan1'
put 'test','001','name:lastname','zhangsan2'
put 'test','001','company:name','Riot'
put 'test','001','company:address','合肥'
# 在phoenix创建视图, primary key 对应到hbase中的rowkey 视图的表名必须加双引号
create view "test"(
empid varchar primary key,
"name"."firstname" varchar,
"name"."lastname" varchar,
"company"."name" varchar,
"company"."address" varchar
);
CREATE view "students" (
id VARCHAR NOT NULL PRIMARY KEY,
"info"."name" VARCHAR,
"info"."age" VARCHAR,
"info"."gender" VARCHAR,
"info"."clazz" VARCHAR
);
# 在phoenix查询数据,表名通过双引号引起来
select * from "test";
select "name" from "test";
select * from "students"
# 查询主键不需要加双引号
#不能增删改数据 但是在hbase里操作会影响phoenix的视图
# 删除视图 不会影响原表
drop view "test";表映射
使用Phoenix创建对HBase的表映射,有两类:
1) 当HBase中已经存在表时,可以以类似创建视图的方式创建关联表,只需要将create view改为create table即可。
2)当HBase中不存在表时,可以直接使用create table指令创建需要的表,并且在创建指令中可以根据需要对HBase表结构进行显示的说明。
第1)种情况下,如在之前的基础上已经存在了test表,则表映射的语句如下
sql
create table "test" (
empid varchar primary key,
"name"."firstname" varchar,
"name"."lastname"varchar,
"company"."name" varchar,
"company"."address" varchar
)column_encoded_bytes=0;
# 表映射 可以增删改查数据 会影响hbase中的原表
upsert into "test" values('002','xiaohu','xiaoxiao','hhh','上海');
delete from "test" where empid='003';
drop table "test"
CREATE table "students" (
id VARCHAR NOT NULL PRIMARY KEY,
"info"."name" VARCHAR,
"info"."age" VARCHAR,
"info"."gender" VARCHAR,
"info"."clazz" VARCHAR
) column_encoded_bytes=0;
CREATE table "scores" (
id VARCHAR NOT NULL PRIMARY KEY,
"info"."subject_score" VARCHAR
) column_encoded_bytes=0;
# 查询成绩前10名的学生
SELECT t1.id,
t1."name",
t1."age",
t1."gender",
t1."clazz",
to_char(t2.sumScore) AS new_sumScore
FROM "students" t1
JOIN
(SELECT t1.sid AS new_sid,
sum(to_number(t1."subject_score")) AS sumScore
FROM
(SELECT regexp_split(id,
'-')[1] AS sid,regexp_split(id,'-')[2] AS subject_id,"subject_score"
FROM "scores") t1
GROUP BY t1.sid
ORDER BY sumScore DESC limit 10 ) t2
ON (t1.id=t2.new_sid)
ORDER BY new_sumScore desc;通过这个例子遇到的注意点:
1、切分字符串的函数不是split,而是regexp_split
2、Phoenix中,数组的索引是从1开始的
3、给字段起别名之后的嵌套查询,就不需要再加双引号了,主键本身就可以不用加
4、sum函数中的数据类型必须是数值类型,如果是10的整数倍,会以科学计数法进行标识 580->5.8E+2(5.8*10^2)
5、to_number()转数值 to_char()转字符串
bulkLoad实现批量导入
优点:
-
如果我们一次性入库hbase巨量数据,处理速度慢不说,还特别占用Region资源, 一个比较高效便捷的方法就是使用 "Bulk Loading"方法,即HBase提供的HFileOutputFormat类。
-
它是利用hbase的数据信息按照特定格式存储在hdfs内这一原理,直接生成这种hdfs内存储的数据格式文件,然后上传至合适位置,即完成巨量数据快速入库的办法。配合mapreduce完成,高效便捷,而且不占用region资源,增添负载。
限制:
- 仅适合初次数据导入,即表内数据为空,或者每次入库表内都无数据的情况。
- HBase集群与Hadoop集群为同一集群,即HBase所基于的HDFS为生成HFile的MR的集群.
代码:
提前在Hbase中创建好表
生成Hfile基本流程:
设置Mapper的输出KV类型:
K: ImmutableBytesWritable(代表行键)
V: KeyValue (代表cell)
2.开发Mapper
读取你的原始数据,按你的需求做处理
输出rowkey作为K,输出一些KeyValue(Put)作为V
3. 配置job参数
a. Zookeeper的连接地址
b. 配置输出的OutputFormat为HFileOutputFormat2,并为其设置参数
4. 提交job
导入HFile到RegionServer的流程
构建一个表描述对象
构建一个region定位工具
然后用LoadIncrementalHFiles来doBulkload操作
添加pom依赖
xml
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-mapreduce -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.1.3</version>
</dependency>
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.2</version>
</dependency>
java
/**
* 手机号,网格编号,城市编号,区县编号,停留时间,进入时间,离开时间,时间分区
* D55433A437AEC8D8D3DB2BCA56E9E64392A9D93C,117210031795040,83401,8340104,301,20180503190539,20180503233517,20180503
*/
class MyBulkLoadMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, KeyValue> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, ImmutableBytesWritable, KeyValue>.Context context) throws IOException, InterruptedException {
//转成java的String类型
String line = value.toString();
//==> tl_hefei_shushan_503.txt <== 第一行数据 \N 脏数据
if (!line.contains("shushan") && !line.contains("\\N")) {
String[] infos = line.split("\t");
//0 5
String rowkey = infos[0] + "-" + infos[5];
String[] colNameArray = {"","wg","city","qx","stayTime","","leaveTime","day"};
for (int i = 1; i < infos.length; i++) {
if(i==5){
continue;
}
//封装成一个KeyValue的对象
// public KeyValue(final byte [] row, final byte [] family, final byte [] qualifier, final byte [] value)
KeyValue keyValue = new KeyValue(Bytes.toBytes(rowkey),
Bytes.toBytes("info"),
Bytes.toBytes(colNameArray[i]),
Bytes.toBytes(infos[i]));
context.write(new ImmutableBytesWritable(Bytes.toBytes(rowkey)),keyValue);
}
}
}
}
public class BulkLoadingDianXin {
public static void main(String[] args) throws Exception {
//获取集群配置文件对象(既然都使用了bulkload方式,就说明hbase集群和hdfs集群是同一个)
//所以这里获取hadoop中的hdfs集群或者是hbase集群对象
Configuration conf = HBaseConfiguration.create();
//设置zookeeper的集群信息
conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
//创建一个Job作业实例
Job job = Job.getInstance(conf);
//给job作业起一个名字
job.setJobName("hbase使用bulkloading方式批量加载数据作业");
//设置主类
job.setJarByClass(BulkLoadingDianXin.class);
//设置map类
job.setMapperClass(MyBulkLoadMapper.class);
//无需设置自定义reduce类,使用hbase中的reduce类
//设置最后输出类
job.setOutputFormatClass(HFileOutputFormat2.class);
//设置map的输出key和value类型
//key -- 行键
//value -- 单元格(列)
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(KeyValue.class);
//如果就只是按照我们读取的顺序写入hbase表,是有问题的,顺序的问题
//没有经历region中字典排序的过程,要想最终呈现排序的过程与hbase对应的话
//就需要我们在生成hfile文件的同时进行字典顺序排序
job.setPartitionerClass(SimpleTotalOrderPartitioner.class);
job.setReducerClass(KeyValueSortReducer.class); // CellSortReducer
//设置文件的输入路径
FileInputFormat.setInputPaths(job, new Path("/bigdata30/data/dianxin_data"));
//设置hfile文件
FileOutputFormat.setOutputPath(job, new Path("/bigdata30/hbase/out1"));
//获取数据库连接对象
Connection conn = ConnectionFactory.createConnection(conf);
//获取数据库操作对象
Admin admin = conn.getAdmin();
TableName dianxinDataBulk = TableName.valueOf("dianxin_data_bulk");
Table dianxinBulkTable = conn.getTable(dianxinDataBulk);
//获取hbase表的region信息
RegionLocator regionLocator = conn.getRegionLocator(dianxinDataBulk);
//使用HFileOutputFormat2类创建Hfile文件
HFileOutputFormat2.configureIncrementalLoad(job, dianxinBulkTable, regionLocator);
//提交作业并执行
boolean b = job.waitForCompletion(true);
if (b) {
System.out.println("====================== Hfile文件生成成功!! 在/bigdata30/hbase/out4目录下 ================================");
LoadIncrementalHFiles loadIncrementalHFiles = new LoadIncrementalHFiles(conf);
loadIncrementalHFiles.doBulkLoad(new Path("/bigdata30/hbase/out1"), admin, dianxinBulkTable, regionLocator);
} else {
System.out.println("============= Hfile文件生成失败!! ==================");
}
}
}
1. 最终输出结果,无论是map还是reduce,输出部分key和value的类型必须是: < ImmutableBytesWritable, KeyValue>或者< ImmutableBytesWritable, Put>。
2. 最终输出部分,Value类型是KeyValue 或Put,对应的Sorter分别是KeyValueSortReducer或PutSortReducer。
3. MR例子中HFileOutputFormat2.configureIncrementalLoad(job, dianxin_bulk, regionLocator);自动对job进行配置。SimpleTotalOrderPartitioner是需要先对key进行整体排序,然后划分到每个reduce中,保证每一个reducer中的的key最小最大值区间范围,是不会有交集的。因为入库到HBase的时候,作为一个整体的Region,key是绝对有序的。
4. MR例子中最后生成HFile存储在HDFS上,输出路径下的子目录是各个列族。如果对HFile进行入库HBase,相当于move HFile到HBase的Region中,HFile子目录的列族内容没有了,但不能直接使用mv命令移动,因为直接移动不能更新HBase的元数据。
5. HFile入库到HBase通过HBase中 LoadIncrementalHFiles的doBulkLoad方法,对生成的HFile文件入库上传dianxin_data 数据
创建输入目录
sh
hdfs dfs -mkdir /bigdata30/data
#上传 dianxin_data 至该目录下
hdfs dfs -put dianxin_data /bigdata30/data/在hbase中建表
sql
create 'dianxin_data_bulk','info'将代码打包上传 运行
sh
hadoop jar Hbase-1.0-SNAPSHOT-jar-with-dependencies.jar com.shujia.jinjie.BulkLoadingDianXin报错:
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.hadoop.hdfs.client.HdfsDataInputStream.getReadStatistics()Lorg/apache/hadoop/hdfs/DFSInputStream$ReadStatistics;
但是Hfile文件成功生成了
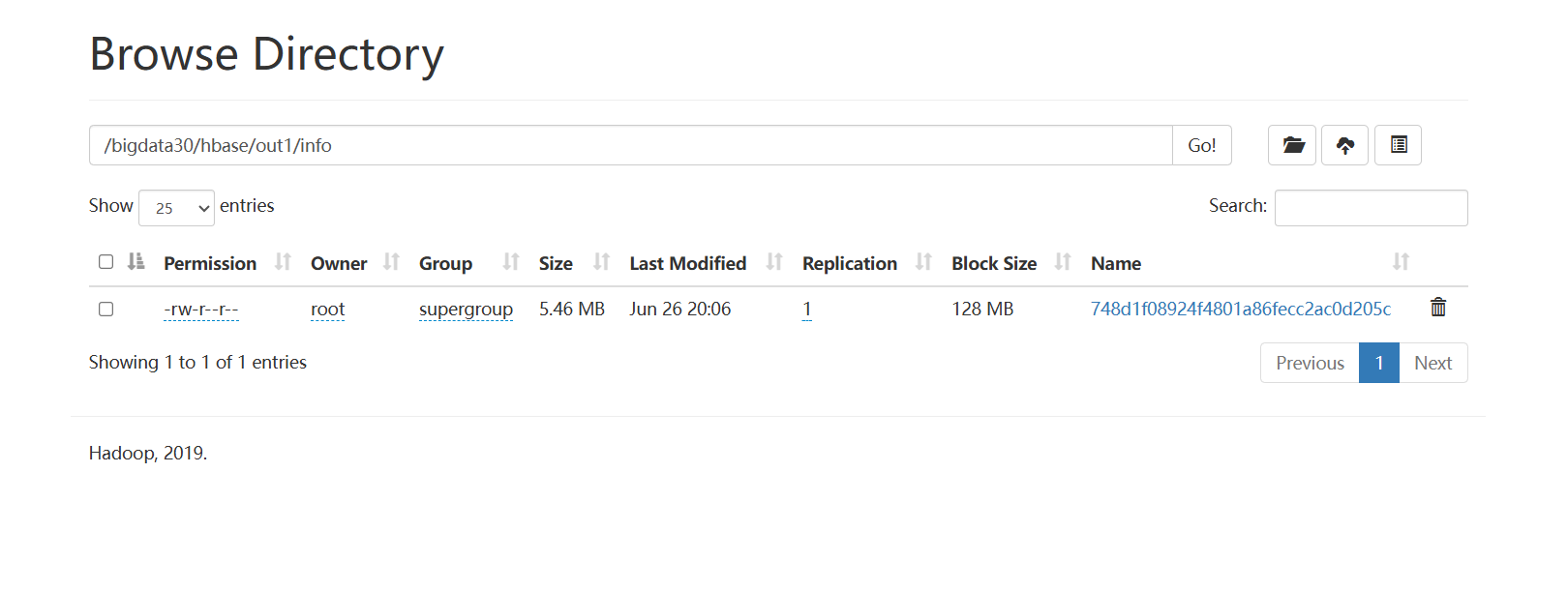
但hbase dianxin_data_bulk表中无数据 说明没有关联

报错原因
代码中:
LoadIncrementalHFiles loadIncrementalHFiles = new LoadIncrementalHFiles(conf);
loadIncrementalHFiles.doBulkLoad(new Path("/bigdata30/hbase/out1"), admin, dianxinBulkTable, regionLocator);
LoadIncrementalHFiles没有生效
报错:NoSuchMethodError 应该想到是版本冲突的问题
在hadoop-hdfs-client-3.1.3.jar 中寻找org/apache/hadoop/hdfs/DFSInputStream$ReadStatistics 可以找到这个类 说明不是类的问题
搜寻发现:
hbase的lib目录下的 hadoop-hdfs-client-2.8.5.jar 与hadoop中的版本不一样 如果将此包删除,使用hadoop的包 可能会解决
这里使用命令的方式来将数据关联 指定类 输出路径 表名
sh
hbase org.apache.hadoop.hbase.tool.LoadIncrementalHFiles /bigdata30/hbase/out1 dianxin_data_bulk查询表 有数据了
sql
scan 'dianxin_data_bulk',LIMIT=>5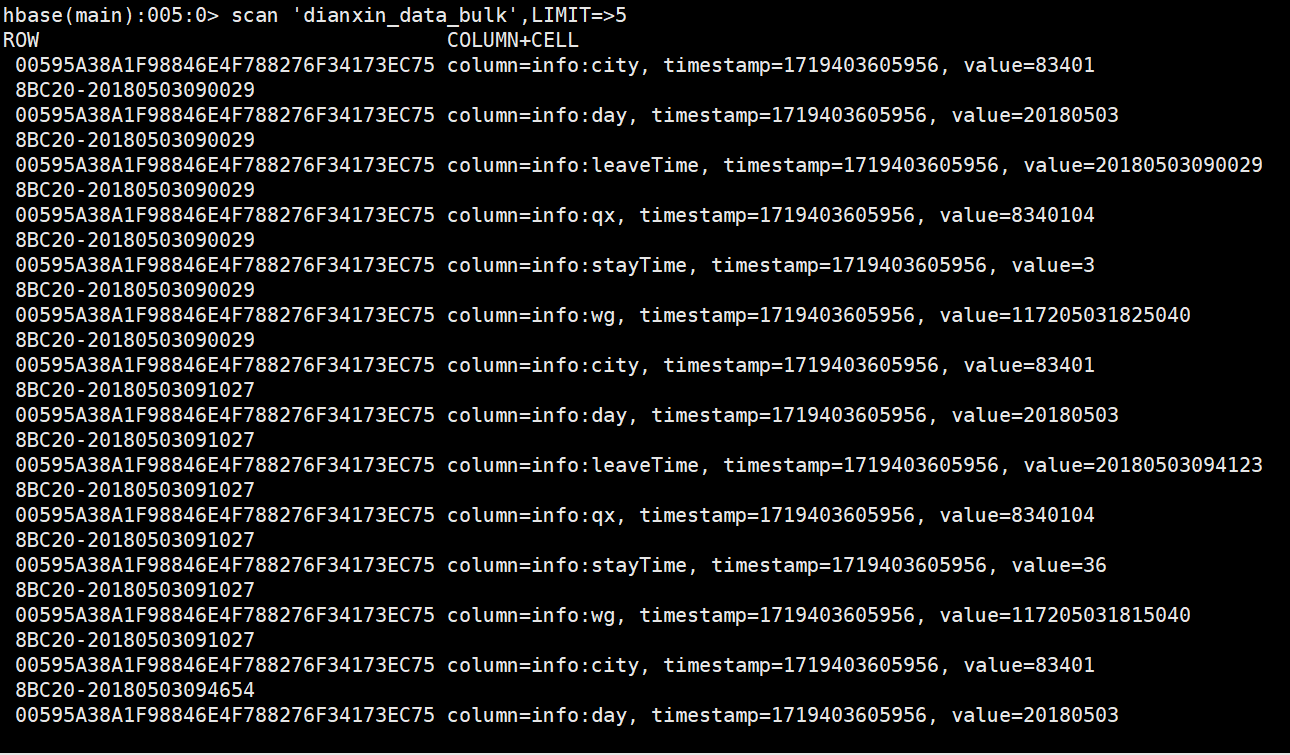
HDFS:有文件了
为了方便 可以将生成hfile命令和关联命令写入脚本 用一个命令解决
HBase中rowkey的设计(重点)
HBase是三维有序存储的,通过rowkey(行键),column key(column family和qualifier)和TimeStamp(时间戳)这个三个维度可以对HBase中的数据进行快速定位。
HBase中rowkey可以唯一标识一行记录,在HBase查询的时候,有两种方式:
通过get方式,指定rowkey获取唯一一条记录
通过scan方式,设置startRow和stopRow参数进行范围匹配
全表扫描,即直接扫描整张表中所有行记录
rowkey长度原则
不宜过长
rowkey是一个二进制码流,可以是任意字符串,最大长度 64kb ,实际应用中一般为10-100bytes,以 byte\[\] 形式保存,一般设计成定长。
建议越短越好,不要超过16个字节,原因如下:
数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
rowkey散列原则
如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
rowkey唯一原则
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
什么是热点
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。 热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,由于主机无法服务其他region的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。
为了避免写热点,设计rowkey使得不同行在同一个region,但是在更多数据情况下,数据应该被写入集群的多个region,而不是一个。
预分region可以有效的解决热点问题
下面是一些常见的避免热点的方法以及它们的优缺点:
加盐
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据
反转
第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题 173...--->...371
时间戳反转
一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用 Long.Max_Value - timestamp 追加到key的末尾,例如 keyreverse_timestamp , key 的最新值可以通过scan key获得key的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。
比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey的时候,可以这样设计
userId反转Long.Max_Value - timestamp,在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow是userId反转000000000000,stopRow是userId反转Long.Max_Value - timestamp
如果需要查询某段时间的操作记录,startRow是user反转Long.Max_Value - 起始时间,stopRow是userId反转Long.Max_Value - 结束时间
其他一些建议
尽量减少行和列的大小在HBase中,value永远和它的key一起传输的。当具体的值在系统间传输时,它的rowkey,列名,时间戳也会一起传输。如果你的rowkey和列名很大,甚至可以和具体的值相比较,那么你将会遇到一些有趣的问题。HBase storefiles中的索引(有助于随机访问)最终占据了HBase分配的大量内存,因为具体的值和它的key很大。可以增加block大小使得storefiles索引再更大的时间间隔增加,或者修改表的模式以减小rowkey和列名的大小。压缩也有助于更大的索引。
列族尽可能越短越好,最好是一个字符
冗长的属性名虽然可读性好,但是更短的属性名存储在HBase中会更好
txt
# 原数据:以时间戳_user_id作为rowkey
# 时间戳高位变化不大,太连续,最终可能会导致热点问题
1638584124_user_id
1638584135_user_id
1638584146_user_id
1638584157_user_id
1638584168_user_id
1638584179_user_id
# 解决方案:加盐、反转、哈希
# 加盐
# 加上随即前缀,随机的打散
# 该过程无法预测 前缀时随机的
00_1638584124_user_id
05_1638584135_user_id
03_1638584146_user_id
04_1638584157_user_id
02_1638584168_user_id
06_1638584179_user_id
# 反转
# 适用于高位变化不大,低位变化大的rowkey
4214858361_user_id
5314858361_user_id
6414858361_user_id
7514858361_user_id
8614858361_user_id
9714858361_user_id
# 散列(加密) md5、sha1、sha256......
25531D7065AE158AAB6FA53379523979_user_id
60F9A0072C0BD06C92D768DACF2DFDC3_user_id
D2EFD883A6C0198DA3AF4FD8F82DEB57_user_id
A9A4C265D61E0801D163927DE1299C79_user_id
3F41251355E092D7D8A50130441B58A5_user_id
5E6043C773DA4CF991B389D200B77379_user_id
# 时间戳"反转"
# rowkey:时间戳_user_id
# rowkey是字典升序的,那么越新的记录会被排在最后面,不容易被获取到
# 需求:让最新的记录排在最前面
# 大数:9999999999
# 大数-小数
1638584124_user_id => 8361415875_user_id
1638584135_user_id => 8361415864_user_id
1638584146_user_id => 8361415853_user_id
1638584157_user_id => 8361415842_user_id
1638584168_user_id => 8361415831_user_id
1638584179_user_id => 8361415820_user_id
1638586193_user_id => 8361413806_user_id合理设计rowkey实战(电信)
手机号,网格编号,城市编号,区县编号,停留时间,进入时间,离开时间,时间分区
D55433A437AEC8D8D3DB2BCA56E9E64392A9D93C,117210031795040,83401,8340104,301,20180503190539,20180503233517,20180503
将用户位置数据保存到hbase
查询需求
1、通过手机号查询用户最近10条位置记录
怎么设计hbase表
1、rowkey
2、时间戳
java
/**
* 合理设计rowkey查找某个用户最近的10条记录
*/
public class DianXinDemo1 {
public static void main(String[] args) throws Exception {
//82044609CB65BA7139205E7808144D5C254C419F
putDianXinData();
getTop10Person();
}
// 手动查询一名用户的记录
public static void getTop10Person() throws Exception{
Table dianXinDemo1 = HbaseUtil.getOneTable("dianxin_demo1");
Scanner sc = new Scanner(System.in);
System.out.print("请输入您要查询最近10条记录的用户手机号:");
String phone = sc.next();
//只用前缀过滤器,过滤该用户的记录
PrefixFilter prefixFilter = new PrefixFilter(Bytes.toBytes(phone));
//创建Scan对象
Scan scan = new Scan();
scan.setFilter(prefixFilter);
scan.setLimit(10);
//查询数据
ResultScanner resultScanner = dianXinDemo1.getScanner(scan);
for (Result result : resultScanner) {
//"", "wg", "city", "qx", "stayTime", "startTime", "", "day"};
String wg = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("wg")));
String city = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("city")));
String qx = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("qx")));
String stayTime = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("stayTime")));
String startTime = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("startTime")));
String day = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("day")));
//获取行键 还原手机号
String rk = Bytes.toString(result.getRow());
String phoneNum = rk.split("-")[0];
long leaveTime = 20190000000000L - Long.parseLong(rk.split("-")[1]);
System.out.println("手机号:"+phoneNum+"网格编号:"+wg
+"城市编号:"+city
+"区县编号:"+qx
+"停留时长:"+stayTime
+"进入网格时间:"+startTime
+"离开网格时间:"+leaveTime
+"当天日期:"+day);
}
}
public static void putDianXinData() throws Exception{
// 利用写好的工具类创建表
HbaseUtil.createOneTable("dianxin_demo1", "info");
BufferedReader br = new BufferedReader(new FileReader("hbase/data/dianxin_data"));
String line = null;
while ((line = br.readLine()) != null) {
if (!line.contains("shushan") && !line.contains("\\N")) {
String[] infos = line.split("\t");
//将手机号与离开网格的时间戳拼接,较大的时间戳值减去离开网格的时间戳再进行拼接 没有比20190000000000大的时间戳
//20180503172154 -- (20190000000000-20180503172154)=> 最大
//20180503180350 --
//20180503233517 -- (20190000000000-20180503172154)=> 最小
String rowkey = infos[0] + "-" + (20190000000000L - Long.parseLong(infos[6]));
String[] colNameArray = {"", "wg", "city", "qx", "stayTime", "startTime", "", "day"};
for (int i = 1; i < infos.length; i++) {
if (i == 6) {
continue;
}
//封装成一个KeyValue的对象
// public KeyValue(final byte [] row, final byte [] family, final byte [] qualifier, final byte [] value)
KeyValue keyValue = new KeyValue(Bytes.toBytes(rowkey),
Bytes.toBytes("info"),
Bytes.toBytes(colNameArray[i]),
Bytes.toBytes(infos[i]));
// 使用工具类
HbaseUtil.putOneColData("dianxin_demo1", rowkey, "info", colNameArray[i], infos[i]);
}
}
}
}
}
HbaseUtil 工具类 不用在频繁的写这些代码 直接调用
java
public class HbaseUtil {
//成员变量
public static final Connection CONN = HbaseParameters.getConnection();
public static final Admin ADMIN = HbaseParameters.getAdmin();
private HbaseUtil(){}
/**
* 传入表名和若干个列簇创建Hbase一张表
*/
public static void createOneTable(String tableName, String ... familyNames){
TableName name = TableName.valueOf(tableName);
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(name);
try {
for (String familyName : familyNames) {
// ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.of(familyName);
ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(familyName))
.setBloomFilterType(BloomType.ROW) // 设置布隆过滤器
.build();
tableDescriptorBuilder.setColumnFamily(info);
}
if (ADMIN.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表已经存在!");
return;
}
ADMIN.createTable(tableDescriptorBuilder.build());
System.out.println(Bytes.toString(tableDescriptorBuilder.build().getTableName().getName()) + "表创建 成功 SUCCEED!");
} catch (Exception e) {
System.out.println(Bytes.toString(tableDescriptorBuilder.build().getTableName().getName()) + "表创建 失败!FAILED!");
e.printStackTrace();
}
}
/**
* 删除表
*/
public static void dropTable(String tableName){
try {
//将表名封装成一个TableName对象
TableName name = TableName.valueOf(tableName);
/**
* 判断表是否存在
*/
if (!ADMIN.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表不存在!无法删除!");
return;
}
//禁用表
ADMIN.disableTable(name);
//删除表
ADMIN.deleteTable(name);
System.out.println(Bytes.toString(name.getName()) + "表删除 成功 SUCCEED!");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 清空表数据
*/
public static void truncateTable(String tableName){
try {
//将表名封装成一个TableName对象
TableName name = TableName.valueOf(tableName);
/**
* 判断表是否存在
*/
if (!ADMIN.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表不存在!无法删除!");
return;
}
//注意:如果是使用程序清空数据,需要手动设置禁用
ADMIN.disableTable(name);
ADMIN.truncateTable(name,true);
System.out.println(Bytes.toString(name.getName()) + "表数据清除 成功 SUCCEED!");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取一张表
*/
public static Table getOneTable(String tableName){
Table table = null;
try {
//将表名封装成一个TableName对象
TableName name = TableName.valueOf(tableName);
/**
* 判断表是否存在
*/
if (!ADMIN.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表不存在!");
}
//获取表实例对象
table = CONN.getTable(name);
}catch (Exception e){
e.printStackTrace();
}
return table;
}
/**
* 添加一列数据
*/
public static void putOneColData(String tableName, String rowKey, String familyName, String colName, String colValue){
try {
//将表名封装成一个TableName对象
TableName name = TableName.valueOf(tableName);
/**
* 判断表是否存在
*/
if (!ADMIN.tableExists(name)) {
System.out.println(Bytes.toString(name.getName()) + " 表不存在!无法添加数据!");
return;
}
//获取表实例对象
Table table = CONN.getTable(name);
//将一列数据封装成一个Put对象,传入一个行键,需要将行键变成一个字节数组的格式
Put put = new Put(Bytes.toBytes(rowKey));
KeyValue keyValue = new KeyValue(Bytes.toBytes(rowKey),
Bytes.toBytes(familyName),
Bytes.toBytes(colName),
Bytes.toBytes(colValue));
put.add(keyValue);
table.put(put);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 打印一行多列数据
*/
public static void printResult(Result result){
String rk = Bytes.toString(result.getRow());
List<Cell> cells = result.listCells();
StringBuilder sb = new StringBuilder();
sb.append("行键:").append(rk).append(", ");
for (int i = 0; i < cells.size(); i++) {
//Hbase中提供了一个专门解析Cell单元格的工具类 CellUtil
String colName = Bytes.toString(CellUtil.cloneQualifier(cells.get(i)));
String colValue = Bytes.toString(CellUtil.cloneValue(cells.get(i)));
if (i != cells.size() - 1) {
sb.append(colName).append(":").append(colValue).append(", ");
} else {
sb.append(colName).append(":").append(colValue);
}
}
System.out.println(sb);
System.out.println("--------------------------------------------");
}
}二级索引
二级索引的本质就是建立各列值与行键之间的映射关系
Hbase的局限性:
HBase本身只提供基于行键和全表扫描的查询,而行键索引单一,对于多维度的查询困难。
常见的二级索引:
HBase的一级索引就是rowkey,我们只能通过rowkey进行检索。如果我们相对hbase里面列族的列列进行一些组合查询,就需要采用HBase的二级索引方案来进行多条件的查询。
- MapReduce方案
2. ITHBASE(Indexed-Transanctional HBase)方案
3. IHBASE(Index HBase)方案
4. Hbase Coprocessor(协处理器)方案
5. Solr+hbase方案 redis+hbase 方案
- CCIndex(complementalclustering index)方案
二级索引的种类
1、创建单列索引
2、同时创建多个单列索引
3、创建联合索引(最多同时支持3个列)
4、只根据rowkey创建索引
单表建立二级索引
1.首先disable '表名'
2.然后修改表
alter 'LogTable',METHOD=>'table_att','coprocessor'=>'hdfs:///写好的Hbase协处理器(coprocessor)的jar包名|类的绝对路径名|1001'
- enable '表名'
二级索引的设计思路
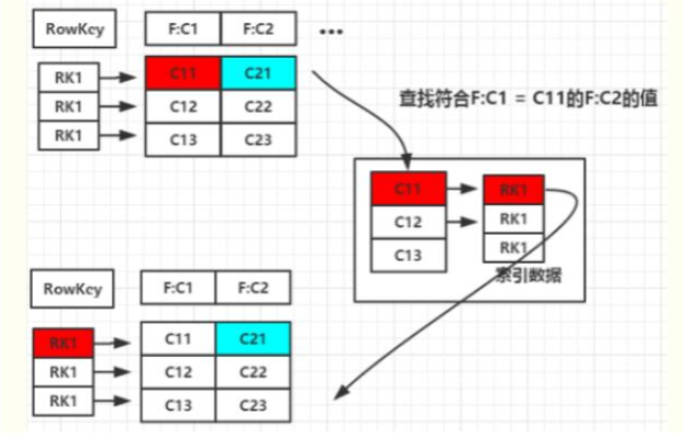 二级索引的本质就是建立各列值与行键之间的映射关系
二级索引的本质就是建立各列值与行键之间的映射关系
如上图1,当要对F:C1这列建立索引时,只需要建立F:C1各列值到其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询符合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值,图1青色部分)
其查询步骤如下:
根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1
得到RK1后就自然能根据RK1来查询C2的值了 这是构建二级索引大概思路,其他组合查询的联合索引的建立也类似。
Mapreduce方案
使用整合MapReduce的方式创建hbase索引。主要的流程如下:
扫描输入表,使用hbase继承类TableMapper
获取rowkey和指定字段名称和字段值
创建Put实例, value=" ", rowkey=班级,column=学号
使用IdentityTableReducer将数据写入索引表
java代码
java
class MyIndexMapper extends TableMapper<Text,NullWritable>{
@Override
protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, NullWritable>.Context context) throws IOException, InterruptedException {
// 获取原表的学号行键
String id = Bytes.toString(value.getRow());
// 获取列值姓名
String name = Bytes.toString(value.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
context.write(new Text(id+"-"+name),NullWritable.get());
}
}
class MyIndexReducer extends TableReducer<Text,NullWritable,NullWritable>{
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, NullWritable, Mutation>.Context context) throws IOException, InterruptedException {
String s = key.toString();
String id = s.split("-")[0];
String name = s.split("-")[1];
// put 对象
Put put = new Put(Bytes.toBytes(name));
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes(id),Bytes.toBytes(""));
context.write(NullWritable.get(),put);
}
}
public class hbaseIndexDemo1 {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = HBaseConfiguration.create();
//设置zookeeper的集群信息
conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
//创建一个Job作业实例
Job job = Job.getInstance(conf);
//给job作业起一个名字
job.setJobName("给学生表创建二级索引");
//设置主类
job.setJarByClass(hbaseIndexDemo1.class);
// scan扫描全表数据
Scan scan = new Scan();
scan.addFamily(Bytes.toBytes("info"));
//先将表名封装成一个TableName的对象
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
//先将表名封装成一个TableName的对象
TableName tn = TableName.valueOf("students_index");
if (!admin.tableExists(tn)) {
TableDescriptorBuilder studentsIndex = TableDescriptorBuilder.newBuilder(tn);
//使用另外一种方式创建列簇并设置布隆过滤器
ColumnFamilyDescriptor columnFamilyDescriptor = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info"))
.setBloomFilterType(BloomType.ROW).build();
studentsIndex.setColumnFamily(columnFamilyDescriptor);
admin.createTable(studentsIndex.build());
System.out.println(tn + "表创建成功!!!");
} else {
System.out.println(tn + "表已经存在!");
}
TableMapReduceUtil.initTableMapperJob("students", scan, MyIndexMapper.class, Text.class, NullWritable.class, job);
TableMapReduceUtil.initTableReducerJob("students_index", MyIndexReducer.class, job);
//提交作业到集群中允许
boolean b = job.waitForCompletion(true);
if (b) {
System.out.println("================== students索引表构建成功!!!============================");
} else {
System.out.println("================== students索引表构建失败!!!============================");
}
}
}1.打包并上传至hadoop
2.运行
shell
hadoop jar Hbase-1.0-SNAPSHOT-jar-with-dependencies.jar com.shujia.jinjie.hbaseIndexDemo1name列值成了行键
redis+hbase 方案
启动不同的端口号redis服务,意味着启动时指定不同的配置文件,要修改rendis.conf文件的路径
shell
# 在redis目录下创建
mkdir redis-ports
cd redis-ports/
mkdir 7000
#进入7000目录下 将redis.conf文件拷贝至此
cp /usr/local/soft/redis-7.0.0/redis.conf ./
# 修改文件
port 7000
daemonize yes #后台启动
# 若要客户端访问需修改
注释 bind 127.0.0.1 -::1
protected-mode no #关闭保护模式导入依赖
xml
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.1.3</version>
</dependency>java代码
java
public class HbaseIndexWithRedis {
public static void main(String[] args) throws IOException {
/**
* 借助redis来构建hbase表的列值与行键的映射关系,作为二级索引表
*/
createIndexToRedis();
Scanner sc = new Scanner(System.in);
System.out.print("请输入要查询班级的学生姓名: ");
String name = sc.next();
//查询农星泽所在的班级
String clazz = selectClazzWithName(name);
System.out.println("该学生所在班级为:"+clazz);
}
public static String selectClazzWithName(String name){
Jedis jedis = new Jedis("192.168.220.100", 7000);
String clazz = null;
try {
String id = jedis.get(name);
//再根据学号查班级这一列
Table students = HbaseUtil.getOneTable("students");
Result result = students.get(new Get(Bytes.toBytes(id)));
clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"),Bytes.toBytes("clazz")));
}catch (Exception e){
try {
throw new RedisKeyNotFoundException("redis中没有该学生的姓名作为键");
} catch (RedisKeyNotFoundException ex) {
ex.printStackTrace();
}
}
return clazz;
}
public static void createIndexToRedis() throws IOException {
Table students = HbaseUtil.getOneTable("students");
Scan scan = new Scan();
ResultScanner resultScanner = students.getScanner(scan);
// 创建redis连接对象
Jedis jedis = new Jedis("192.168.220.100", 7000);
for (Result result : resultScanner) {
// 取出姓名 学号
String id = Bytes.toString(result.getRow());
String name= Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
// 添加到redis中
jedis.set(name,id);
}
jedis.close();
}
}自定义异常RedisKeyNotFoundException
java
public class RedisKeyNotFoundException extends Throwable{
public RedisKeyNotFoundException(String info){
super(info);
}
}Phoenix二级索引
对于Hbase,如果想精确定位到某行记录,唯一的办法就是通过rowkey查询。如果不通过rowkey查找数据,就必须逐行比较每一行的值,对于较大的表,全表扫描的代价是不可接受的。
开启索引支持
xml
# 关闭hbase集群
stop-hbase.sh
# 在/usr/local/soft/hbase-2.2.7/conf/hbase-site.xml中增加如下配置
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.rpc.timeout</name>
<value>60000000</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>60000000</value>
</property>
<property>
<name>phoenix.query.timeoutMs</name>
<value>60000000</value>
</property>
# 同步到所有节点
scp hbase-site.xml node1:`pwd`
scp hbase-site.xml node2:`pwd`
# 修改phoenix目录下的bin目录中的hbase-site.xml
<property>
<name>hbase.rpc.timeout</name>
<value>60000000</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>60000000</value>
</property>
<property>
<name>phoenix.query.timeoutMs</name>
<value>60000000</value>
</property>
# 启动hbase
start-hbase.sh
# 重新进入phoenix客户端
sqlline.py master,node1,node2创建索引
1.全局索引
全局索引适合读多写少的场景。如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。数据表的添加、删除和修改都会更新相关的索引表(数据删除了,索引表中的数据也会删除;数据增加了,索引表的数据也会增加
注意: 对于全局索引在默认情况下,在查询语句中检索的列如果不在索引表中,Phoenix不会使用索引表将,除非使用hint(语法糖)。
sql
手机号 进入网格的时间 离开网格的时间 区县编码 经度 纬度 基站标识 网格编号 业务类型
# 创建DIANXIN.sql 脚本
CREATE TABLE IF NOT EXISTS DIANXIN (
mdn VARCHAR ,
start_date VARCHAR ,
end_date VARCHAR ,
county VARCHAR,
x DOUBLE ,
y DOUBLE,
bsid VARCHAR,
grid_id VARCHAR,
biz_type VARCHAR,
event_type VARCHAR ,
data_source VARCHAR ,
CONSTRAINT PK PRIMARY KEY (mdn,start_date)
) column_encoded_bytes=0;
# 上传数据DIANXIN.csv
# 导入数据
psql.py master,node1,node2 DIANXIN.sql /usr/local/soft/bigdata30/DIANXIN.csv
# 创建全局索引
CREATE INDEX DIANXIN_INDEX ON DIANXIN ( end_date );
# 查询数据 ( 索引未生效) 很慢
select * from DIANXIN where end_date = '20180503154014';
# 强制使用索引 (索引生效) hint 快
select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date = '20180503154014';
select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date = '20180503154014' and start_date = '20180503154614';
# 取索引列,(索引生效)
select end_date from DIANXIN where end_date = '20180503154014';
# 创建多列索引
CREATE INDEX DIANXIN_INDEX1 ON DIANXIN ( end_date,COUNTY );
# 多条件查询 (索引生效)
select end_date,MDN,COUNTY from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104';
# 查询所有列 (索引未生效)
select * from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104';
# 查询所有列 (索引生效)
select /*+ INDEX(DIANXIN DIANXIN_INDEX1) */ * from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104';
# 单条件 (索引未生效)(end_date,COUNTY是组合)
select end_date from DIANXIN where COUNTY = '8340103';
# 单条件 (索引生效) end_date 在前
select COUNTY from DIANXIN where end_date = '20180503154014';
# 删除索引
drop index DIANXIN_INDEX on DIANXIN;2.本地索引
本地索引适合写多读少的场景,或者存储空间有限的场景。和全局索引一样,Phoenix也会在查询的时候自动选择是否使用本地索引。本地索引因为索引数据和原数据存储在同一台机器上,避免网络数据传输的开销,所以更适合写多的场景。由于无法提前确定数据在哪个Region上,所以在读数据的时候,需要检查每个Region上的数据从而带来一些性能损耗。
注意:对于本地索引,查询中无论是否指定hint或者是查询的列是否都在索引表中,都会使用索引表。
sql
# 创建本地索引
CREATE LOCAL INDEX DIANXIN_LOCAL_IDEX ON DIANXIN(grid_id);
# 索引生效
select grid_id from dianxin where grid_id='117285031820040';
# 索引生效
select * from dianxin where grid_id='117285031820040';3.覆盖索引
覆盖索引是把原数据存储在索引数据表中,这样在查询时不需要再去HBase的原表获取数据就,直接返回查询结果。
注意:查询是 select 的列和 where 的列都需要在索引中出现。
sql
# 创建覆盖索引
CREATE INDEX DIANXIN_INDEX_COVER ON DIANXIN ( x,y ) INCLUDE ( county );
# 查询所有列 (索引未生效)
select * from DIANXIN where x=117.288 and y =31.822;
# 强制使用索引 (索引生效)
select /*+ INDEX(DIANXIN DIANXIN_INDEX_COVER) */ * from DIANXIN where x=117.288 and y =31.822;
# 查询索引中的列 (索引生效) mdn是DIANXIN表的RowKey中的一部分
select x,y,county from DIANXIN where x=117.288 and y =31.822;
select mdn,x,y,county from DIANXIN where x=117.288 and y =31.822;
# 查询条件必须放在索引中 select 中的列可以放在INCLUDE (将数据保存在索引中)
select /*+ INDEX(DIANXIN DIANXIN_INDEX_COVER) */ x,y,count(*) from DIANXIN group by x,y;Phoenix JDBC
xml
# 添加依赖
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-hbase-compat-2.2.5</artifactId>
<version>5.1.3</version>
</dependency>
java
package com.shujia.jdbc;
import java.sql.*;
public class Phoenix {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
// 注册驱动
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
// 创建数据库连接对象
Connection conn = DriverManager.getConnection("jdbc:phoenix:master,node1,node2:2181");
// 预编译对象
PreparedStatement prep = conn.prepareStatement("select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date = ? and start_date = ?");
//设置参数值
prep.setString(1, "20180503154014");
prep.setString(2, "20180503154614");
//执行sql语句
ResultSet resultSet = prep.executeQuery();
//遍历得到每一列
while (resultSet.next()) {
String mdn = resultSet.getString("mdn");
String county = resultSet.getString("county");
System.out.println("手机号:" + mdn + ", 城市编号:" + county);
}
//释放资源
prep.close();
conn.close();
}
}
Hbase调优
1.行键的设计(重点)
- 实际上底层存储是按列族线性地存储单元格
- 列包括了HBase特有的列族和列限定符,从而组成列键。
- 磁盘上一个列族下所有的单元格都存储在一个存储文件中,不同列族的
单元格不会出现在同一个存储文件中。
- 每个单元格在实际存储时保存了行键和列键,所以每个单元格都单独存
储了它在表中所处位置的相关信息。
- 单元格按时间戳降序排列。
- 含有结构信息的整个单元格在HBase中被叫做KeyValue。
从存储结构上看,列限定符开始就需要检查每个送到过滤器的KeyValue。值筛选性能会更差。
2.设计的时候,列不要太多(优先考虑高表,其次宽表)
HBase只能按行分片,因此高表更有优势。
3.部分键扫描
HBase的扫描功能和基于HTable的API更适合在高表上筛选数据,用户可以通过只包含部分键的扫描检索数据
行键是按字典序排序的,因此将行键进行设计,把每一个需要的字段都进
行补齐,可以利用这种机制。
4.不同方式解决顺序读的性能变化对比图
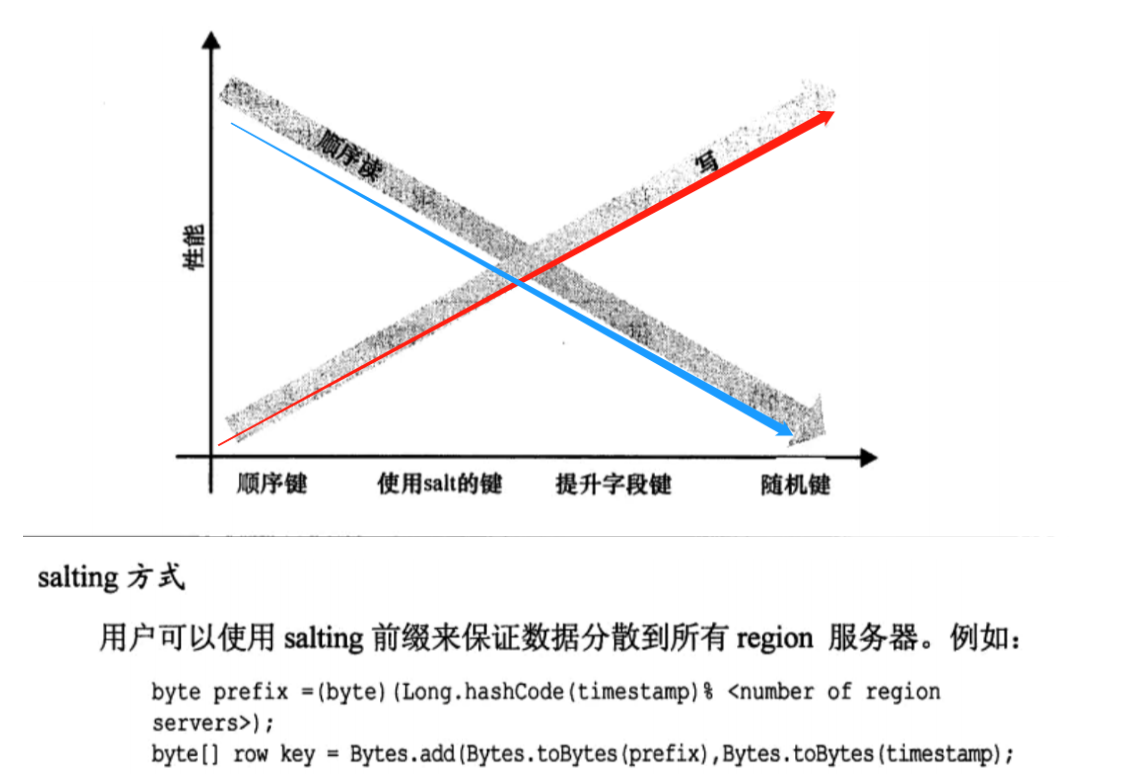
5.布隆过滤器(重点)
在读取数据时,hbase会首先在布隆过滤器中查询,根据布隆过滤器的结果,再在MemStore中查询,最后再在对应的HFile中查询。
当我们随机读get数据时,如果采用hbase的块索引机制,hbase会加载很多块文件。如果采用布隆过滤器后,它能够准确判断该HFile的所有数据块中,是否含有我们查询的数据,从而大大减少不必要的块加载,从而增加hbase集群的吞吐率。
6.选择合适的 GC 策略
Hbase是java开发的,也是运行在java虚拟机jvm中,所以也可以通过GC参数配置调优
主要调节的是RegionServer节点的JVM垃圾回收参数
垃圾回收策略:Parraller New Collector垃圾回收策略; PC
并行标记回收器(Concurrent Mark-Sweep Collector),避免GC停顿, CMS
使用:
shell
export HBASE_REGIONSERVER_OPTS="-Xmx8g -Xms8G -Xmn128m - XX:UseParNewGC -XX:UseConcMarkSweepGC - XX:CMSInitiatingOccupancyFraction=70 -verbose:gc - XX:+PrintGCDetails -XX:+PrintGCTimeStamps - Xloggc:$HBASE_HOME/logs/gc-${hostname}-hbase.log"7.HBase内存管理
HBase上的Regionserver的内存主要分为两部分,一部分作为Memstore,主要用来写;一部分作为BlockCache,主要用于读。
写请求会先写入Memstore,Regionserver会给每个region的store提供一个Memstore,当Memstore满128M(hbase.hregion.memstore.flush.size)以后,会启动flush刷新到磁盘,当Memstore的总大小超过限制时
(heapsizehbase.regionserver.global.memstore.upperLimit0.9),会强行启动flush进程,从最大的Memstore开始flush直到低于限制
读请求先到Memstore中查数据,查不到就到BlockCache中查,再查不到就会到磁盘上读,并把读的结果放入BlockCache。由于BlockCache采用的是LRU(最近最少使用)策略,因此BlockCache达到上限
(heapsizehfile.block.cache.size0.85)后,会启动淘汰机制,淘汰掉最老的一批数据。
在注重读响应时间的应用场景下,可以将BlockCache设置大些,Memstore设置小些,以加大缓存命中率。
如果不希望自动触发溢写,就将值调大
xml
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
一般在企业中这个参数是禁用的
xml
<name>hbase.hregion.majorcompaction</name>
<value>604800000</value>
直接将值设置为0就可以了,表示禁用
何时执行split <name>hbase.hregion.max.filesize</name>
<value>10737418240</value>
一般建议将值调大,在期间手动去触发splitMemstore刷写数据到磁盘时,造成RegionServer内存碎片增多,当生存时间较长的数据从堆的老年代空间刷写到磁盘,就会产生内存孔洞。由于碎片过多导致没有足够大的连续内存空间,JVM就会暂停工作进程,进行垃圾回收(GC),导致HBase的RegionServer对外服务停顿
本地Memstore缓存机制:启用本地memstore分配缓存区(Memstore- Local Allocation Buffers,MSLAB),也就是允许从堆中分配相同大小的对象,一旦这些对象分配并且最终被回收,就会在堆中留下固定大小的孔洞,这些孔洞可被重复利用,GC就无需使应用程序进程停顿来回收内存空间,配置参数hbase.hregion.memstore.mslab.enabled,默认为true。
8.预创建Region
创建HBase时,就预先根据可能的RowKey划分出多个Region而不是默认的一个,从而可以将后续的读写操作负载均衡到不同的Region上,避免热点现象;
HBase表的预分区需要紧密结合业务场景来选择分区的key值,每个region都有一个startKey和一个endKey来表示该region存储的rowKey范围;
java
//有以下四种创建方式:
create 'ns1:t1' , 'f1' , SPLITS => ['10','20','30','40'] ; create 't1','f1',SPLITS_FILE => 'splits.txt', OWNER=> 'johnode' ;
------其中splits.txt文件内容是每行一个rowkey值create 't1','f1',{NUMREGIONS => 15, SPLITALGO =>'HexStringSplit'}
JavaAPI
HTableDescriptor desc = new
HTableDescriptor(TableName.valueOf(weibo_content));
HColumnDescriptor family = new
HColumnDescriptor(Bytes.toBytes("cf"));
// 开启列簇 -- store的块缓存family.setBlockCacheEnabled(true); family.setBlocksize(1024 * 1024 * 2);
family.setCompressionType(Algorithm.SNAPPY);
family.setMaxVersions(1);
family.setMinVersions(1);
desc.addFamily(family);
// admin.createTable(desc);
byte[][] splitKeys = { Bytes.toBytes("100"),
Bytes.toBytes("200"), Bytes.toBytes("300") };
admin.createTable(desc, splitKeys);9.避免Region热点
热点现象:某个小的时段内,对HBase的读写请求集中到极少数的Region上,导致这些Region所在的RegionServer处理请求量骤增,负载量明显偏大,而其他的RegionServer明显空闲;
出现的原因:主要是因为Hbase表设计时,rowKey设计不合理造成的;解决办法:Rowkey的随机散列+创表预分区
RowKey设计原则:
1、总的原则:避免热点现象,提高读写性能;
2、长度原则:最大长度64KB,开发通常8个字节倍数,因为Hbase中每个单元格是以key-value进行存储的,因此每个value都会存储rowkey,所以rowkey越来越占空间;
3、散列原则:将时间上连续产生的rowkey散列化,以避免集中到极少数
Region上
4、唯一原则:必须在设计上保证rowkey的唯一性RowKey设计结合业务:
在满足rowkey设计原则的基础上,往往需要将经常用于查询的字段整合到rowkey上,以提高检索查询效率
10.Hbase参数调优
hbase.regionserver.handler.count
该设置决定了处理RPC的线程数量,默认值是10,通常可以调大,比如:150,当请求内容很大(上MB,比如大的put、使用缓存的scans)的时候,如果该值设置过大则会占用过多的内存,导致频繁的GC,或者出现OutOfMemory,因此该值不是越大越好。
hbase.hregion.max.filesize
配置region大小,默认是10G,region大小一般控制在几个G比较合适,可以在建表时规划好region数量,进行预分区,做到一定时间内,每个region的数据大小在一定的数据量之下,当发现有大的region,或者需要对整个表进行region扩充时再进行split操作,一般提供在线服务的hbase集群均会弃用hbase的自动split,转而自己管理split。
hbase.hregion.majorcompaction
配置major合并的间隔时间,默认值604800000,单位ms。表示major compaction默认7天调度一次,HBase 0.96.x及之前默认为1天调度一次,设置为 0 时表示禁用自动触发major compaction。一般major compaction持续时间较长、系统资源消耗较大,对上层业务也有比较大的影响,一般生产环境下为了避免影响读写请求,会禁用自动触发major compaction,可手动或者通过脚本定期进行major合并。
hbase.hstore.compaction.min
默认值 3,一个列族下的HFile数量超过该值就会触发Minor Compaction,这个参数默认值小了,一般情况下建议调大到5~10之间,注意相应调整下一个参数
hbase.hstore.compaction.max
默认值 10,一次Minor Compaction最多合并的HFile文件数量,这个参数基本控制着一次压缩即Compaction的耗时。这个参数要比上一个参数hbase.hstore.compaction.min值大,通常是其2~3倍。
hbase.hstore.blockingStoreFiles
默认值 10,一个列族下HFile数量达到该值,flush操作将会受到阻塞,阻塞时间为hbase.hstore.blockingWaitTime,默认90000,即1.5分钟,在这段时间内,如果compaction操作使得HFile下降到blockingStoreFiles配置值,则停止阻塞。另外阻塞超过时间后,也会恢复执行flush操作。这样做可以有效地控制大量写请求的速度,但同时这也是影响写请求速度的主要原因之一。生产环境中默认值太小了,一般建议设置大点比如100,避免出现阻塞更新的情况
hbase.regionserver.global.memstore.size
默认值0.4,RS所有memstore占用内存在总内存中的比例,当达到该值,则会从整个RS中找出最需要flush的region进行flush,直到总内存比例降至该数限制以下,并且在降至限制比例前,将阻塞所有的写memstore的操作,在以写为主的集群中,可以调大该配置项,不建议太大,因为block cache和memstore cache的总大小不会超过0.8,而且不建议这两个cache的大小总和达到或者接近0.8,避免OOM,在偏向写的业务时,可配置为0.45
hbase.regionserver.global.memstore.size.lower.limit
默认值0.95,相当于上一个参数的0.95如果有 16G 堆内存,默认情况下:
txt
\# 达到该值会触发刷写
16 * 0.4 * 0.95 = 6.08
\# 达到该值会触发阻塞
16 * 0.4 = 6.4| 新参数 | 老参数 |
|---|---|
| hbase.regionserver.global.memstore.size | hbase.regionserver.global.memstore.upperLimit |
| hbase.regionserver.global.memstore.size.lower.limit | hbase.regionserver.global.memstore.lowerLimit |
hfile.block.cache.size
RS的block cache的内存大小限制,默认值0.4,在偏向读的业务中,可以适当调大该值,具体配置时需试hbase集群服务的业务特征,结合memstore的内存占比进行综合考虑。
hbase.hregion.memstore.flush.size
默认值128M,单位字节,超过将被flush到hdfs,该值比较适中,一般不需要调整。
hbase.hregion.memstore.block.multiplier
默认值4,如果memstore的内存大小已经超过了hbase.hregion.memstore.flush.size的4倍,则会阻塞memstore的写操作,直到降至该值以下,为避免发生阻塞,最好调大该值,比如:6,不可太大,如果太大,则会增大导致整个RS的memstore内存超过global.memstore.size限制的可能性,进而增大阻塞整个RS的写的几率,如果region发生了阻塞会导致大量的线程被阻塞在到该region上,从而其它region的线程数会下降,影响整体的RS服务能力。
hbase.regionserver.regionSplitLimit
控制最大的region数量,超过则不可以进行split操作,默认是
Integer.MAX(2147483647),可设置为1,禁止自动的split,通过人工,或者写脚本在集群空闲时执行。如果不禁止自动的split,则当region大小超过hbase.hregion.max.filesize时会触发split操作(具体的split有一定的策略,不仅仅通过该参数控制,前期的split会考虑region数据量和memstore大小),每次flush或者compact之后,regionserver都会检查是否需要Split,split会先下线老region再上线split后的region,该过程会很快,但是会存在两个问题:1、老region下线后,新region上线前client访问会失败,在重试过程中会成功但是如果是提供实时服务的系统则响应时长会增加;2、split后的compact是一个比较耗资源的动作。
hbase.regionserver.maxlogs:默认值32,HLOG最大的数量
hbase.regionserver.hlog.blocksize :默认为 2 倍的HDFS block size(128MB),即256MB
JVM调整:
内存大小:master默认为1G,可增加到2G,regionserver默认1G,可调大到10G,或者更大,zk并不耗资源,可以不用调整,需要注意的是,调整了rs的内存大小后,需调整hbase.regionserver.maxlogs和hbase.regionserver.hlog.blocksize这两个参数,WAL的最大值由hbase.regionserver.maxlogs * hbase.regionserver.hlog.blocksize决定(默认322128M=8G),一旦达到这个值,就会被触发flush memstore,如果memstore的内存增大了,但是没有调整这两个参数,实际上对大量小文件没有任何改进,调整策略:hbase.regionserver.hlog.blocksize * hbase.regionserver.maxlogs 设置为略大于hbase.regionserver.global.memstore.size* HBASE_HEAPSIZE。
什么时候触发 MemStore Flush?
有很多情况会触发 MemStore 的 Flush 操作,主要有以下几种情况:
Region 中任意一个 MemStore 占用的内存超过相关阈值
当一个 Region 中所有 MemStore 占用的内存大小超过刷写阈值的时候会触发一次刷写,这个阈值由
hbase.hregion.memstore.flush.size 参数控制,默认为128MB。我们每次调用 put、delete 等操作都会检查的这个条件的。
但是如果我们的数据增加得很快,达到了hbase.hregion.memstore.flush.size * hbase.hregion.memstore.block.multiplier 的大小,hbase.hregion.memstore.block.multiplier 默认值为4,也就是128*4=512MB的时候,那么除了触发 MemStore 刷写之外,HBase还会在刷写的时候同时阻塞所有写入该 Store 的写请求!这时候如果你往对应的 Store 写数据,会出现 RegionTooBusyException 异常。
整个 RegionServer 的 MemStore 占用内存总和大于相关阈值
如果达到了 RegionServer 级别的 Flush,那么当前 RegionServer的所有写操作将会被阻塞,而且这个阻塞可能会持续到分钟级别。
WAL数量大于相关阈值或WAL的大小超过一定阈值
如果设置了 hbase.regionserver.maxlogs,那就是这个参数的值;否则是 max(32, hbase_heapsize *
hbase.regionserver.global.memstore.size * 2 / logRollSize)
什么操作会触发 MemStore 刷写?
常见的 put、delete、append、incr、调用 flush 命令、Region 分裂、Region Merge、bulkLoad HFiles 以及给表做快照操作都会对上面的相关条件做检查,以便判断要不要做刷写操作。
MemStore刷写策略(FlushPolicy)
在 HBase 1.1 之前,MemStore 刷写是 Region 级别的。就是说,如果要刷写某个 MemStore ,MemStore 所在的 Region 中其他 MemStore 也是会被一起刷写的!这会造成一定的问题,比如小文件问题。可以通过hbase.regionserver.flush.policy 参数选择不同的刷写策略。
目前 HBase 2.x 的刷写策略全部都是实现 FlushPolicy 抽象类的。并且自带三种刷写策略:FlushAllLargeStoresPolicy、FlushNonSloppyStoresFirstPolicy 以及 FlushAllStoresPolicy。
FlushAllStoresPolicy
这种刷写策略实现最简单,直接返回当前 Region 对应的所有MemStore。也就是每次刷写都是对 Region 里面所有的 MemStore 进行的,这个行为和 HBase 1.1 之前是一样的。
FlushAllLargeStoresPolicy
在 HBase 2.0 之前版本是 FlushLargeStoresPolicy,后面被拆分成分FlushAllLargeStoresPolicy 和FlushNonSloppyStoresFirstPolicy
这种策略会先判断 Region 中每个 MemStore 的使用内存是否大于某个阀值,大于这个阀值的 MemStore 将会被刷写
hbase.hregion.percolumnfamilyflush.size.lower.bound.min 默认值为 16MB
hbase.hregion.percolumnfamilyflush.size.lower.bound 没有默认值,计算规则如下:
比如当前表有3个列族,那么 flushSizeLowerBound = max((long)128 / 3, 16) = 42。
如果 Region 中没有 MemStore 的使用内存大于上面的阀值,FlushAllLargeStoresPolicy 策略就退化成 FlushAllStoresPolicy 策略了,也就是会对 Region 里面所有的 MemStore 进行 Flush。
FlushNonSloppyStoresFirstPolicy
(logRollSize 默认大小为:0.95 * HDFS block size)
如果某个 RegionServer 的 WAL 数量大于 maxLogs 就会触发MemStore 的刷写。
WAL的最大值由hbase.regionserver.maxlogs * hbase.regionserver.hlog.blocksize决定(默认322128M=8G),一旦达到这个值,就会被触发flush memstore,如果memstore的内存增大了,但是没有调整这两个参数,实际上对大量小文件没有任何改进,调整策略:hbase.regionserver.hlog.blocksize * hbase.regionserver.maxlogs 设置为略大于hbase.regionserver.global.memstore.size* HBASE_HEAPSIZE。
定期自动刷写
如果我们很久没有对 HBase 的数据进行更新,这时候就可以依赖定期刷写策略了。RegionServer 在启动的时候会启动一个线程PeriodicMemStoreFlusher 每隔
hbase.server.thread.wakefrequency 时间(服务线程的sleep时间,默认10000毫秒)去检查属于这个 RegionServer 的 Region 有没有超过一定时间都没有刷写,这个时间是由hbase.regionserver.optionalcacheflushinterval 参数控制的,默认是3600000,也就是1小时会进行一次刷写。如果设定为0,则意味着关闭定时自动刷写。
为了防止一次性有过多的 MemStore 刷写,定期自动刷写会有 0 ~
5 分钟的延迟
数据更新超过一定阈值
如果 HBase 的某个 Region 更新的很频繁,而且既没有达到自动刷写阀值,也没有达到内存的使用限制,但是内存中的更新数量已经足够多,比如超过 hbase.regionserver.flush.per.changes 参数配置,默认为30000000,那么也是会触发刷写的。
手动触发刷写
分别对某张表、某个 Region 进行刷写操作。可以在 Shell 中执行 flush 命令
可以在 Shell 中执行 flush 命令
HBase 2.0 引入了 in-memory compaction,如果我们对相关列族hbase.hregion.compacting.memstore.type 参数的值不是 NONE,那么这个 MemStore 的 isSloppyMemStore 值就是 true,否则就是false。
FlushNonSloppyStoresFirstPolicy 策略将 Region 中的 MemStore 按照 isSloppyMemStore 分到两个 HashSet 里面(sloppyStores 和regularStores)。然后
判断 regularStores 里面是否有 MemStore 内存占用大于相关阀值的 MemStore ,有的话就会对这些 MemStore 进行刷写,其他的不做处理,这个阀值计算和 FlushAllLargeStoresPolicy 的阀值计算逻辑一致。
如果 regularStores 里面没有 MemStore 内存占用大于相关阀值的MemStore,这时候就开始在 sloppyStores 里面寻找是否有MemStore 内存占用大于相关阀值的 MemStore,有的话就会对这些 MemStore 进行刷写,其他的不做处理。
如果上面 sloppyStores 和 regularStores 都没有满足条件的MemStore 需要刷写,这时候就FlushNonSloppyStoresFirstPolicy 策略久退化成FlushAllStoresPolicy 策略了。