1. 概述
ODS层在数据仓库中代表操作数据存储层(Operational Data Store),它是数据仓库架构的最底层,主要负责从源系统(如数据库、消息队列等)直接接入和存储原始数据,并进行初步清洗、格式转换和质量保证。
1.1 ODS层核心特点
原始性 :保留源系统数据的原始状态,仅进行必要的技术处理(如编码转换、字段重命名)。
时效性 :通常按天分区存储增量或全量数据,支持T+1或近实时同步。
非易失性 :数据一旦写入ODS层,通常不删除或修改,仅追加更新。
轻量清洗:仅处理基础脏数据(如NULL值填充、格式标准化),不涉及业务逻辑加工。
1.2 ODS层设计要点
表命名规范
- 统一前缀标识(如
ods_或ods.),例如:ods_order_info。 - 分区字段通常为日期(
dt=yyyyMMdd),便于增量同步和管理。
数据同步方式
- 全量同步:每日覆盖或保留多版本,适用于小表或变化缓慢的维度表。
- 增量同步:通过时间戳、日志解析(如CDC)捕获变更,适合大表。
字段处理原则
- 保留源系统所有字段,即使当前未使用。
- 添加技术字段(如
etl_time、data_source)用于追溯。
注意事项
- 数据量控制:合理设置保留周期(如7天热数据+1年冷备份),避免存储膨胀。
- 监控机制:校验数据同步的完整性(如记录数波动、字段缺失)。
- 权限隔离:限制直接访问ODS层的权限,防止误操作影响下游。
1.3 本项目中ODS层内容
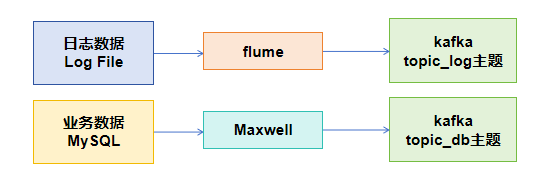
将++日志数据++ 和++业务数据++采集到 Kafka 的 topic_log 和 topic_db 主题
1. 电商系统的日志数据
电商系统的日志数据主要用于记录系统运行状态、用户行为以及异常情况,帮助进行故障排查、性能优化和用户行为分析。常见的日志数据类型包括:
访问日志
记录用户访问电商系统的行为,如页面浏览、点击、搜索等。包含IP地址、访问时间、请求URL、HTTP状态码、用户代理等信息。
交易日志
记录用户下单、支付、退款等交易行为。包含订单ID、用户ID、交易金额、支付方式、交易时间等字段。
错误日志
记录系统运行时出现的异常或错误,如数据库连接失败、服务超时等。包含错误级别、错误信息、堆栈跟踪、发生时间等。
性能日志
记录系统响应时间、吞吐量、资源占用率等性能指标,用于监控系统健康状态。
API调用日志
记录第三方服务或内部微服务之间的API调用情况,包括请求参数、响应结果、调用耗时等。
2. 电商系统的业务数据
电商系统的业务数据是核心运营数据,直接反映平台的运营状况和用户行为。主要包括以下几类:
用户数据
包括用户基本信息(如ID、姓名、联系方式)、注册时间、登录记录、会员等级、积分等。
商品数据
包括商品ID、名称、分类、价格、库存、上下架状态、销量、评价等。
订单数据
包括订单ID、用户ID、商品列表、订单金额、支付状态、配送状态、收货地址、创建时间等。
营销数据
包括优惠券、促销活动、折扣规则、用户参与记录等。
库存数据
记录商品库存变动,包括入库、出库、调拨、盘点等操作。
支付数据
记录支付流水,包括支付方式、交易金额、手续费、支付状态、对账信息等。
物流数据
记录配送信息,如物流公司、运单号、发货时间、签收状态等。
评价数据
包括用户对商品和服务的评分、评论内容、回复等。
2. 日志数据采集
2.1 模拟数据生成
在/opt/module下创建applog文件夹,上传模拟电商数据的相关文件

注意:未建立MySQL业务数据库之前,直接运行jar包会报错,可用test模式
bash
java -jar gmall-remake-mock-2023-05-15-3.jar test 100 2025-8-20 # 第一个参数表示test模式,此种模式下不会读取application.yml文件,第二个参数表示生成100个用户会话,第三个参数表示生成的日志的日期运行后产生的日志文件在applog/log/中

以json的格式保存

2.2 flume传输日志数据
2.2.1 flume的作用
Flume在这一流程中扮演数据采集、聚合与传输的核心角色,具体功能体现在以下方面:
数据源适配与采集
Flume通过配置Source组件(如ExecSource或SpoolingDirectorySource)监听本地磁盘的日志文件变化,实时捕获新增日志内容。支持文件滚动(如Log4j生成的日志)、断点续传等场景,避免数据丢失。
数据缓冲与可靠性保证
Channel组件(如MemoryChannel或FileChannel)提供临时存储,在Kafka不可用时缓存数据,平衡生产者和消费者的速度差异。通过事务机制确保数据在传输过程中不重复、不丢失。
数据格式化与路由
Sink组件(如KafkaSink)将日志按预设格式(如JSON、Avro)序列化,并根据配置的规则(如正则匹配、拦截器)将数据路由到Kafka的特定Topic,实现数据分类。
灵活的动态扩展
通过拦截器(Interceptor)可对日志进行实时过滤(如脱敏)、添加元数据(如时间戳、主机名)。多级Flume Agent可组成复杂拓扑,适应高吞吐或跨网络传输需求。
与直接写入Kafka的对比优势
- 可靠性:Flume的Channel机制避免Kafka集群不可用时的数据丢失,而直接写入需自行处理重试逻辑。
- 易用性:内置支持多种日志格式(如CSV、Syslog),无需在生产者端硬编码解析逻辑。
- 资源隔离:将文件监听、解析等消耗资源的操作与Kafka生产解耦,降低Kafka客户端的压力。
2.2.2 配置flume
在/opt/module/flume/目录下创建job文件夹,在job文件夹中创建file_to_kafka.conf配置文件
html
cd /opt/module/flume/
mkdir job
cd job
touch file_to_kafka.conf
在file_to_kafka.conf文件中添加一下内容
html
# 定义Agent组件
a1.sources = r1
a1.channels = c1
# 配置Source(监听目录新增文件)
a1.sources.r1.type = TAILDIR # 支持断电续传
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json # 记录日志文件的偏移量
# 配置Channel(内存缓冲)
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false # 如果 Flume 源正在写入通道,则应为 true,如果其他生产者正在写入通道正在使用的主题,则应为 false。
# 组装
a1.sources.r1.channels = c1不同source,sink,channel的具体配置详见官方文档:Flume 1.11.0 User Guide --- Apache Flume
2.2.3 flume启停脚本
bash
#!/bin/bash
echo "========== hadoop102 生成日志数据 =========="
ssh hadoop102 "cd /opt/module/applog/; nohup java -jar gmall-remake-mock-2023-05-15-3.jar $1 $2 $3 >/dev/null 2>&1 &"
bash
#!/bin/bash
case $1 in
"start"){
echo " ========== 启动 hadoop102 采集 flume =========="
ssh hadoop102 "nohup /opt/module/flume/bin/flume-ng agent --conf /opt/module/flume/conf --conf-file /opt/module/flume/job/file_to_kafka.conf --name a1 >/dev/null 2>&1 &"
};;
"stop"){
echo " ========== 停止 hadoop102 采集 flume =========="
ssh hadoop102 "ps -ef | grep file_to_kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9"
};;
esac2.2.4 启动flume
数据流向kafka,所以要先启动kafka,kafka需要Zookeeper进行协调,所以要先启动Zookeeper
bash
zk.sh start
kf.sh start
f1.sh start
报错:-bash: /home/jale/bin/f1.sh: /bin/bash^M: 坏的解释器: 没有那个文件或目录错误原因分析
该错误通常发生在Windows系统编辑的脚本文件在Linux环境下运行时。文件中的换行符为
\r\n(Windows格式),而Linux系统只识别\n作为换行符。^M是\r的可见字符形式,导致解释器路径被错误识别为/bin/bash^M。解决方法1:使用dos2unix工具转换
安装dos2unix工具后执行转换:
bashsudo apt-get install dos2unix # Debian/Ubuntu sudo yum install dos2unix # CentOS/RHEL dos2unix /home/jale/bin/f1.sh解决方法2:sed命令去除\r
通过流编辑器直接修改文件:
bashsed -i 's/\r$//' /home/jale/bin/f1.sh解决方法3:vim编辑器处理
用vim打开文件后执行转换:
bashvim /home/jale/bin/f1.sh :set ff=unix :wq解决方法4:tr命令过滤
使用管道过滤文件内容:
bashtr -d '\r' < /home/jale/bin/f1.sh > fixed.sh chmod +x fixed.sh mv fixed.sh f1.sh预防措施
- 在Windows下编辑时使用跨平台编辑器(如VS Code、Notepad++)
- 设置Git自动转换换行符:
bashgit config --global core.autocrlf input
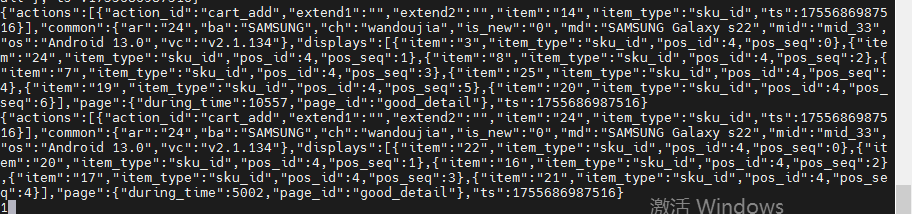
开启kafka消费者进程消费topic_log主题的数据,查看数据采集的结果
bash
/opt/module/kafka/bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_log启动日志生成脚本
bash
lg.sh test观察命令行 Kafka 消费者是否消费到数据。
3. 业务数据采集
**数据通路:**模拟生成业务数据存储在MySQL的业务数据库中,用binlog记录数据库的变化,Maxwell实现捕捉业务数据的变化,将数据传输到kafka的topic_db主题中。
3.1 创建业务数据库
创建业务数据库(我用navicat17连接hadoop102上的MySQL数据库)
连接成功后,创建业务数据库
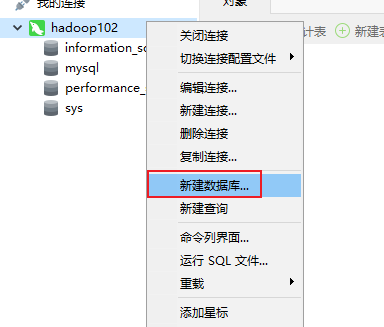
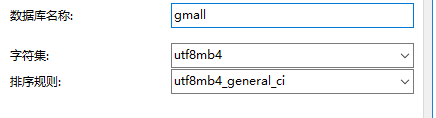
运行初始化建表语句
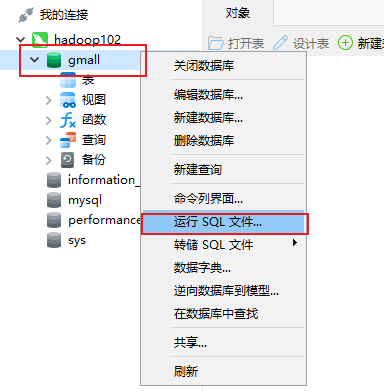
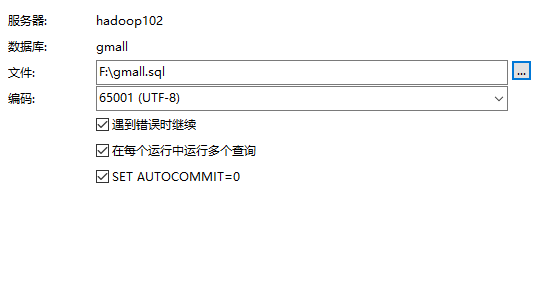
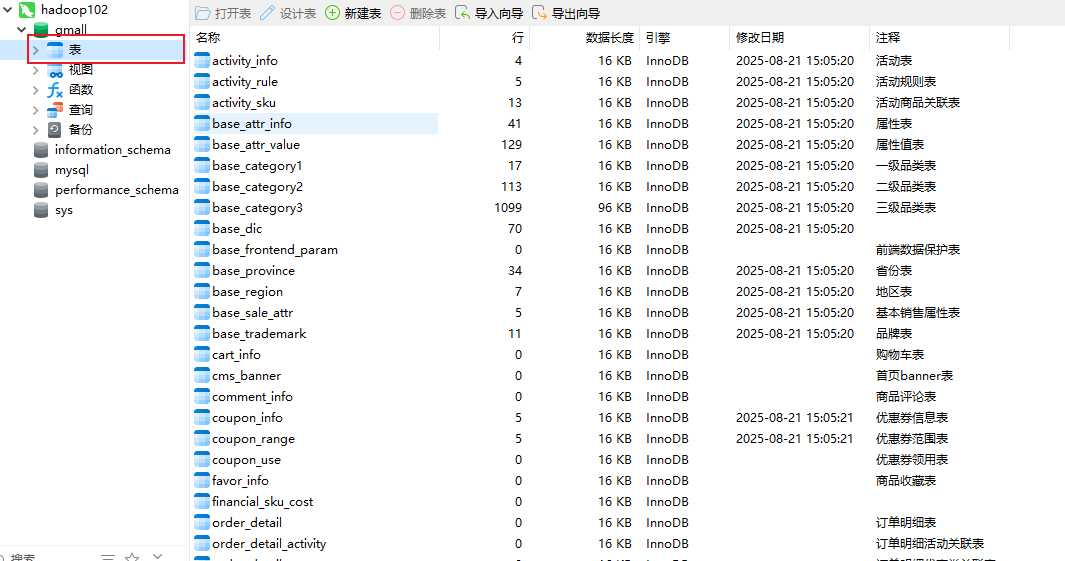
数据库中已经有表了
(建表语句中已经加入数据记录的表为活动表,商品品类表,属性等改动频率较低,相对固定的内容,模拟生成的数据主要为用户下单过程中涉及的各类数据内容,便于模拟电商系统的实时数据)
3.2 配置binlog记录业务数据变化
修改applog中的application.yml文件



查看MySQL数据存放路径,修改/etc/my.cnf文件
bash
sudo vim /etc/my.cnf
重启MySQL,使配置生效
bash
sudo systemctl restart mysqld
运行lg.sh 脚本,生成模拟数据(生成数据后,mysql-bin的文件大小变大,初始是157字节,说明记录了gmall数据库的变化)

3.3 配置Maxwell
Maxwell是一个开源的变更数据捕获(CDC)工具,专注于MySQL数据库的实时数据变更捕获。它通过解析MySQL的binlog日志,将数据库的变更事件(如插入、更新、删除)转换为JSON格式的消息,并发送到Kafka、RabbitMQ等消息队列或直接输出到标准输出。支持断点续传(元数据库记录数据位置偏移量)和历史数据处理(特定脚本对数据库做全表扫描)。
核心功能
- 实时捕获MySQL变更:Maxwell监控MySQL的binlog,实时捕获数据变更事件。
- 多种输出支持:支持将变更事件输出到Kafka、RabbitMQ、Redis或标准输出。
- 轻量级设计:作为独立进程运行,无需复杂的中间件依赖。
- 配置灵活:支持过滤表、字段映射等配置,适应不同业务需求。
工作原理
Maxwell作为MySQL的从库(slave),连接到MySQL服务器并请求binlog事件。它解析binlog中的行级变更,生成JSON格式的消息。消息包含表名、操作类型(insert/update/delete)、变更前后的数据以及时间戳等信息。
与其他CDC工具的对比
- Debezium:支持多种数据库(MySQL、PostgreSQL、MongoDB等),但部署相对复杂。
- Canal:阿里开源的MySQL CDC工具,主要针对阿里云生态优化。
- Maxwell:轻量级,适合简单场景,但对非MySQL数据库支持有限。
Maxwell适合需要快速实现MySQL CDC且对轻量级解决方案有需求的场景。
3.3.1 创建Maxwell元数据库
创建元数据库
sql
mysql> create database maxwell;调整 MySQL 的密码验证策略,降低密码复杂度要求。
sql
mysql> set global validate_password.length=4; # 将密码的最小长度限制设置为 4 个字符。默认值通常为 8。
mysql> set global validate_password.policy=0; # 将密码策略级别设置为最低(0)。可选策略包括:0 或 LOW:仅检查密码长度;1 或 MEDIUM:需包含数字、大小写字母和特殊字符;2 或 STRONG:在 MEDIUM 基础上增加字典文件检查创建maxwell用户并赋予必要权限
sql
create user 'maxwell'@'%' identified by '123456'; # 密码自行决定
grant all on maxwell.* to 'maxwell'@'%'; # 授予在Maxwell元数据库上的所有权限,%通配符允许从任何主机连接
grant select,replication client,replication slave on *.* to 'maxwell'@'%'; # 授予maxwell用户必要的全局权限,以支持MySQL binlog复制修改后需重启 MySQL 服务或重新加载权限使变更生效
sql
FLUSH PRIVILEGES;3.3.2 配置Maxwell
复制配置文件
sql
cd /opt/module/maxwell/
cp config.properties.example config.properties修改配置文件
sql
# MySQL相关(主机名称和密码仅为示例)
host=hadoop102
user=maxwell
password=123456
# kafka相关
producer=kafka
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
kafka_topic=topic_db
# 分区策略(Maxwell的数据要传递到kafka的哪一个分区中去)
producer_partition_by= primary_key # 选用主键,根据主键哈希分区,降低数据倾斜可能
# jdbc设置
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
# 需要添加 后续初始化会用
client_id=maxwell_1
# 过滤z_log表数据,该表是日志数据的备份,无须采集
filter=exclude:gmall.z_log修改kafka每个主题的分区数(根据flink设置的并行度而定,这里设置为4,否则会对后续事件时间窗口产生影响)
sql
vim /opt/module/kafka/config/server.properties
3.3.3 Maxwell启停脚本
sql
vim ~/bin/maxwell.sh
sql
/opt/module/maxwell/bin/maxwell --config /opt/module/maxwell/config.properties >/dev/null 2>&1 &授予执行权限
sql
sudo chmod +x maxwell.sh运行maxwell
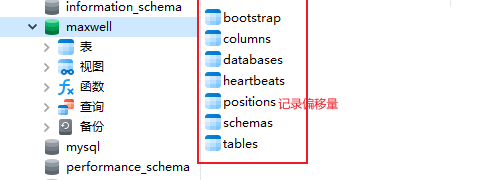
第一次启动maxwell后会元数据库maxwell会自动加载以下表格
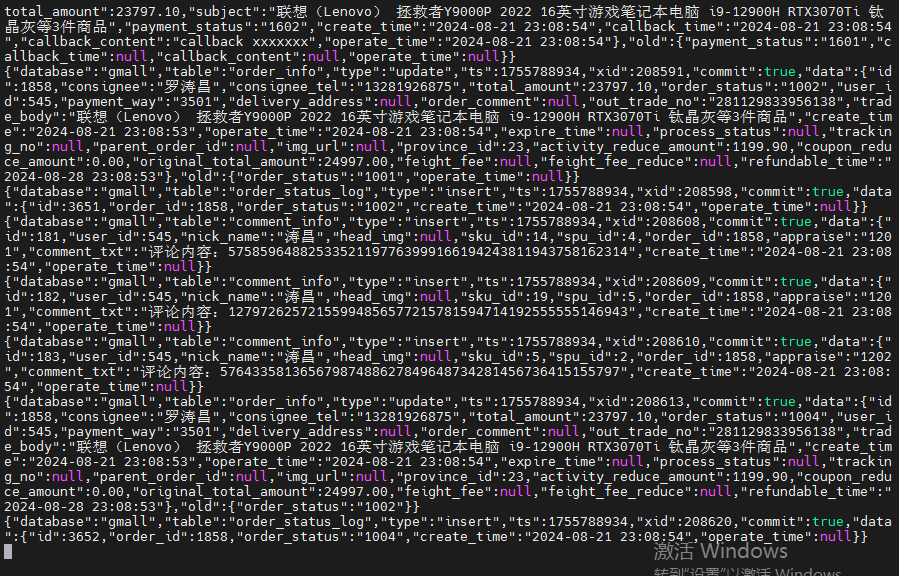
启动kafka消费者客户端,观察结果
sql
{
"database":"gmall",
"table":"order_status_log",
"type":"insert",
"ts":1755788934,
"xid":208598,
"commit":true,
"data":{
"id":3651,
"order_id":1858,
"order_status":"1002",
"create_time":"2024-08-21 23:08:54",
"operate_time":null
}
}
3.4 同步维度历史数据
实时计算不考虑历史的事实数据,但要考虑历史维度数据。因此要对维度相关的业务表做一次全量同步。
与维度相关的业务表如下
activity_info # 活动表
activity_rule # 活动规则表
activity_sku # 活动商品关联表
base_category1 # 一级品类表
base_category2 # 二级品类表
base_category3 # 三级品类表
base_dic # 订单状态表
base_province # 省份表
base_region # 地区表
base_trademark # 品牌表
coupon_info # 优惠券信息表
coupon_range # 优惠券范围表
financial_sku_cost
sku_info # sku表
spu_info # spu表
user_info # 用户表切换到 /home/atguigu/bin 目录,创建 mysql_to_kafka_init.sh 文件
bash
#!/bin/bash
# 该脚本的作用是初始化所有业务数据,只需要执行一次
MAXWELL_HOME=/opt/module/maxwell
import_data(){
$MAXWELL_HOME/bin/maxwell-bootstrap --database gmall --table $1 --config $MAXWELL_HOME/config.properties
}
case $1 in
"activity_info")
import_data activity_info
;;
"activity_rule")
import_data activity_rule
;;
"activity_sku")
import_data activity_sku
;;
"base_category1")
import_data base_category1
;;
"base_category2")
import_data base_category2
;;
"base_category3")
import_data base_category3
;;
"base_dic")
import_data base_dic
;;
"base_province")
import_data base_province
;;
"base_region")
import_data base_region
;;
"base_trademark")
import_data base_trademark
;;
"coupon_info")
import_data coupon_info
;;
"coupon_range")
import_data coupon_range
;;
"financial_sku_cost")
import_data financial_sku_cost
;;
"sku_info")
import_data sku_info
;;
"spu_info")
import_data spu_info
;;
"user_info")
import_data user_info
;;
"all")
import_data activity_info
import_data activity_rule
import_data activity_sku
import_data base_category1
import_data base_category2
import_data base_category3
import_data base_dic
import_data base_province
import_data base_region
import_data base_trademark
import_data coupon_info
import_data coupon_range
import_data financial_sku_cost
import_data sku_info
import_data spu_info
import_data user_info
;;
esac启动脚本
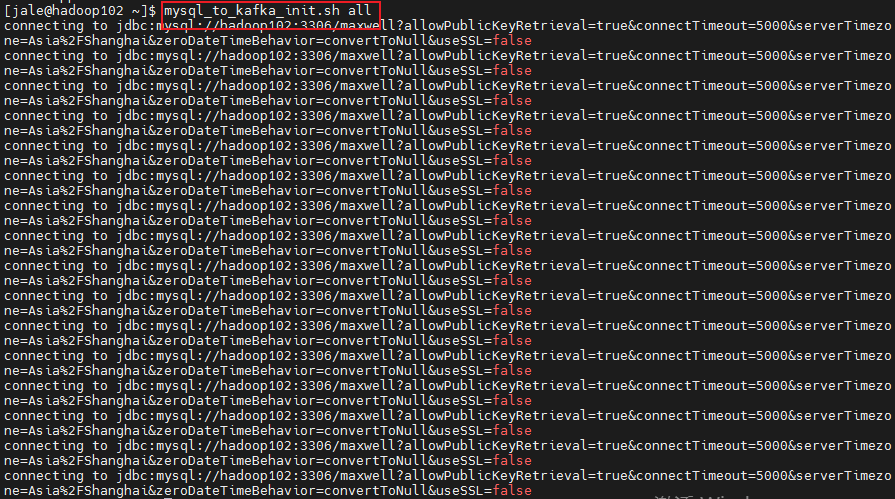
maxwell输出
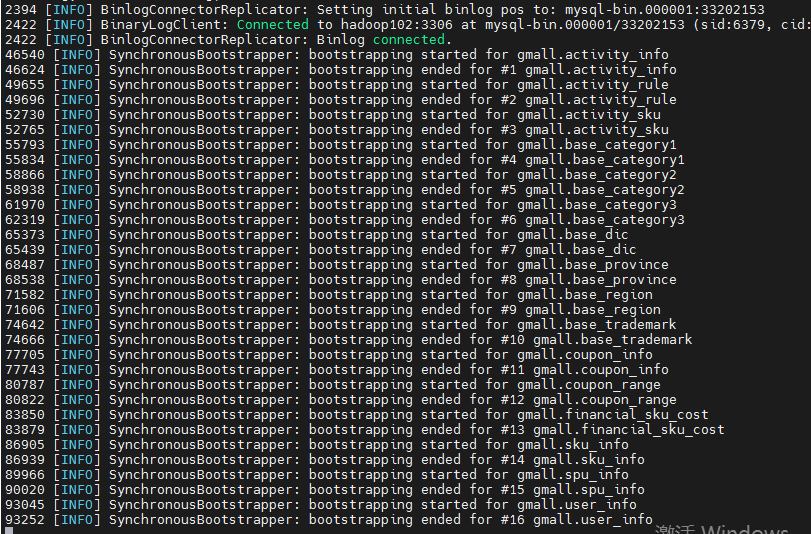
kafka消费者客户端界面
注意:所有在~/bin/目录下的脚本创建完成后都需要授予执行权限
bash
chmod +x 脚本名称