任务描述
知识点:安装配置Hadoop
重 点: 安装配置Hadoop
难 点:无
内 容:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
任务主要内容:
- 下载安装Hadoop包
- 配置系统环境变量
- 配置Hadoop集群
- HDFS相关配置
任务指导
安装配置Hadoop集群的主要步骤:
1、安装配置Hadoop
2、配置用户环境变量
3、配置Hadoop
- 配置core-site.xml文件
- 配置hdfs-site.xml文件
- 配置mapred-site.xml文件
- 配置yarn-site.xml文件
- 配置slaves文件
- 配置hadoop-env.sh文件
更多配置文件的配置信息请参见官方网站的解释。
4、启动集群并测试
任务实现
在node1服务器解压并配置完成后,再复制到其他的slave服务器。
1、安装配置Hadoop
-
在node1节点上,进入/opt/software目录(此目录是为实验提供的安装软件所在目录,如果没有请自行到官方网站下载)
[root@node1 ~]# cd /opt/software
-
将hadoop解压到/opt/module目录
[root@node1 software]# tar -xzf hadoop.tar.gz -C /opt/module/
2、配置Hadoop环境变量。
-
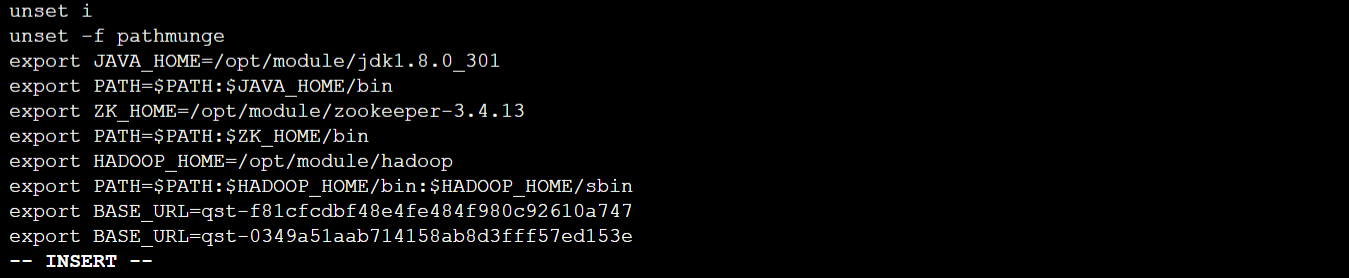
输入【vi /etc/profile】命令编辑文件,添加如下内容:
export HADOOP_HOME=/opt/module/hadoop
export PATH=PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
-
使用【source /etc/profile】使配置文件生效。
[root@node1 software]# source /etc/profile
-
将/etc/profile拷贝到其它所有机器上
[root@node1 software]# scp /etc/profile node2:/etc/
[root@node1 software]# scp /etc/profile node3:/etc/
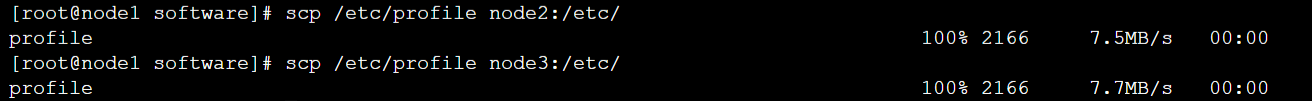
3、修改Hadoop配置文件
1)进入hadoop 配置文件夹。
[root@node1 software]# cd $HADOOP_HOME/etc/hadoop2)配置core-site.xml文件:
-
使用【vi】命令,编辑core-site.xml文件
[root@node1 hadoop]# vi core-site.xml
-
修改<configuration>标签及其内容如下:
fs.defaultFS hdfs://node1:9000 io.file.buffer.size 131072 hadoop.tmp.dir /data/hadoop/tmp
3)配置 hdfs-site.xml 文件:
-
使用【vi】命令,编辑 hdfs-site.xml文件
[root@node1 hadoop]# vi hdfs-site.xml
-
修改<configuration>标签及其内容如下:
dfs.namenode.http-address node1:50070 dfs.namenode.secondary.http-address node2:50090 dfs.replication 1 dfs.namenode.name.dir /data/hadoop/hdfs/nn dfs.namenode.checkpoint.dir /data/hadoop/hdfs/snn dfs.namenode.checkpoint.edits.dir /data/hadoop/hdfs/snn dfs.datanode.data.dir /data/hadoop/hdfs/dn
4)配置 mapred-site.xml 文件。
-
首先,输入【cp mapred-site.xml.template mapred-site.xml】命令,从mapred-site.xml.template模板文件复制一个新的文件,命名为mapred-site.xml。
cp mapred-site.xml.template mapred-site.xml
-
使用【vi】命令,编辑 mapred-site.xml文件
[root@node1 hadoop]# vi mapred-site.xml
-
修改<configuration>标签及其内容如下:
mapreduce.framework.name yarn dfs.permissions false mapreduce.jobhistory.address node1:10020 mapreduce.jobhistory.webapp.address node1:19888
5)配置yarn-site.xml文件:
-
使用【vi】命令,编辑 yarn-site.xml文件
[root@node1 hadoop]# vi yarn-site.xml
-
修改<configuration>标签及其内容如下:
yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.address node1:8032 yarn.resourcemanager.scheduler.address node1:8030 yarn.resourcemanager.resource-tracker.address node1:8031 yarn.resourcemanager.admin.address node1:8033 yarn.resourcemanager.webapp.address node1:8088
6)配置hadoop-env.sh、yarn-env.sh、mapred-env.sh文件的JAVA_HOME变量。如果不设置,可能会无法正常启动集群。
-
输入【vi hadoop-env.sh】打开配置文件,加入JAVA_HOME环境变量。
......
The java implementation to use.
export JAVA_HOME=/opt/module/jdk1.8.0_301
The jsvc implementation to use. Jsvc is required to run secure datanodes
that bind to privileged ports to provide authentication of data transfer
-
输入【vi yarn-env.sh】打开配置文件,加入JAVA_HOME环境变量。

- 输入【vi mapred-env.sh】打开配置文件,加入JAVA_HOME环境变量。

7)输入【vi slaves】配置slaves文件,删除默认的localhost,增加2个从节点的IP地址或host主机名。
node2
node38)将配置好的Hadoop复制到其他节点对应位置上,通过scp命令发送。
[root@node1 hadoop]# scp -rq /opt/module/hadoop node2:/opt/module/
[root@node1 hadoop]# scp -rq /opt/module/hadoop node3:/opt/module/
4、启动Hadoop集群并测试
-
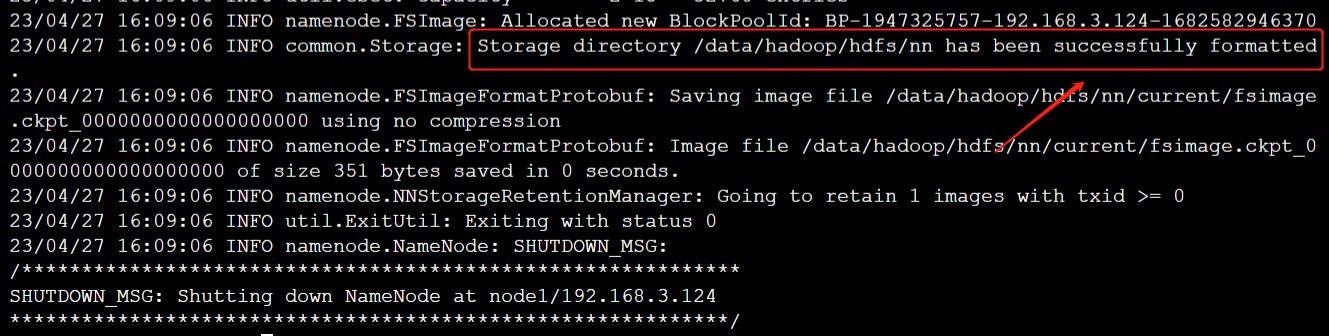
在node1上,格式化Hadoop的namenode
[root@node1 hadoop]# hdfs namenode -format
格式化完成后会显示"successfully formatted.",如下图所示:
-
在node1节点上,启动Hadoop
[root@node1 hadoop]# start-all.sh
启动后可以看到控制台打印信息显示在node1节点上启动了 namenode、resourcemanager两个进程,在node2节点上启动了 datanode、nodemanager、secondarynamenode三个进程,在node3节点上启动了 datanode、nodemanager两个进程。
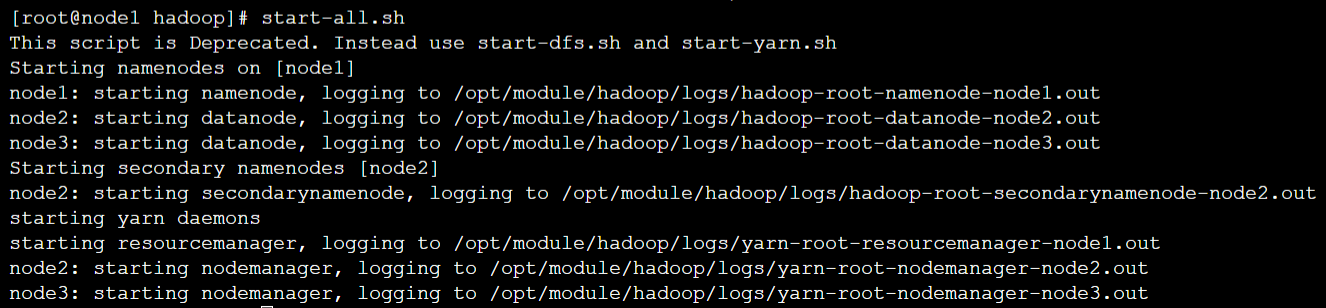
- 使用【jps】命令,在node1节点上可以看到namenode、ResourceManager进程

- 使用【jps】命令,在node2节点上可以看到DataNode、NodeManager、SecondaryNameNode进程

- 使用【jps】命令,在node3节点上可以看到DataNode、NodeManager进程

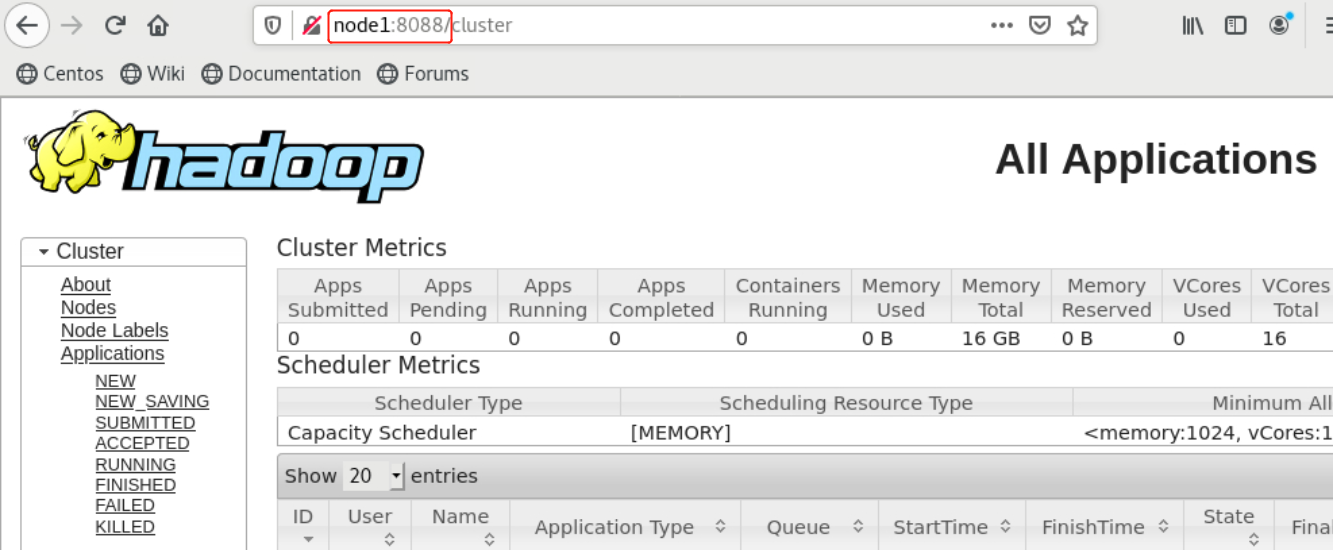
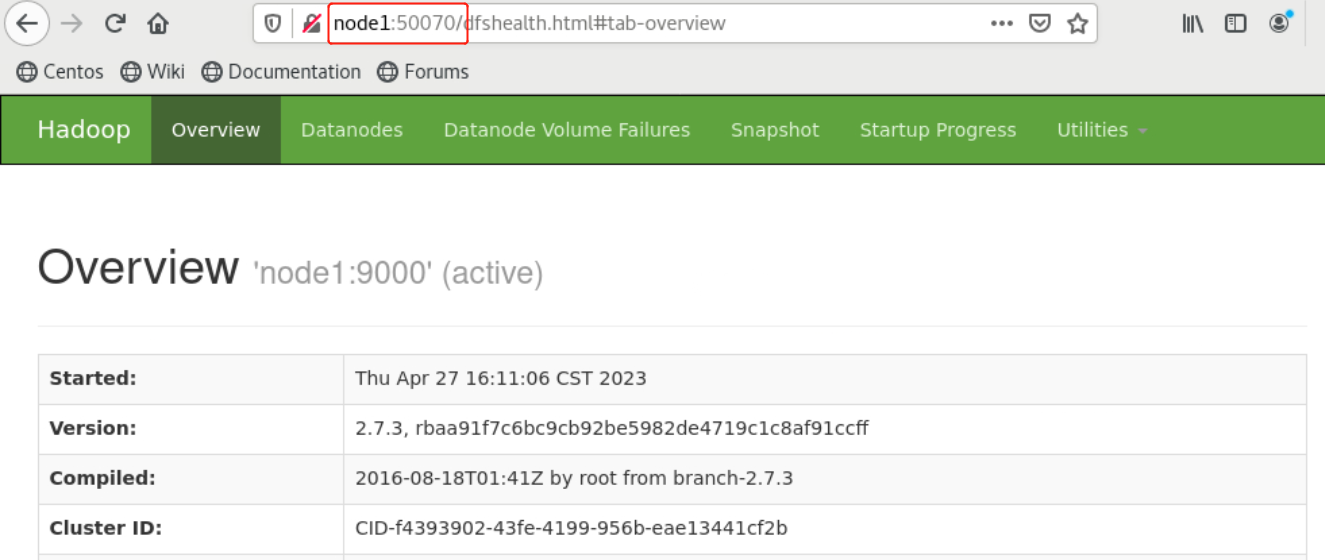
- 在client节点上,可以通过浏览器访问HDFS和YARN的Web监控页面,如已配置了hosts映射可直接通过机器名访问,未配置本机hosts映射需要通过IP地址访问,HDFS和YARN的Web监控页面端口如下:
HDFS:http://node1:50070
YARN:http://node1:8088