简介
一般来说,聚合函数 aggr(expr) 会处理每个聚合键在传入记录中找到的所有匹配行(键使用等价性进行比较)。
在常规聚合(即形式为 aggr(expr) 的情况下),聚合值列表是候选值列表,其中所有空值都被移除。
初始数据
sqlCopy code
SELECT * FROM cypher('graph_name', $$
CREATE (a:Person {name: 'A', age: 13}),
(b:Person {name: 'B', age: 33, eyes: "blue"}),
(c:Person {name: 'C', age: 44, eyes: "blue"}),
(d1:Person {name: 'D', eyes: "brown"}),
(d2:Person {name: 'D'}),
(a)-[:KNOWS]->(b),
(a)-[:KNOWS]->(c),
(a)-[:KNOWS]->(d1),
(b)-[:KNOWS]->(d2),
(c)-[:KNOWS]->(d2)
$$) as (a agtype);自动分组
为了计算聚合数据,Cypher 提供了与 SQL 的 GROUP BY 相类似的聚合功能。
聚合函数接受一组值并计算它们的聚合值。例如,avg() 计算多个数值的平均值,或者 min() 在一组值中找到最小的数值或字符串值。当我们说下面一个聚合函数在一组值上操作时,我们指的是这些值是对相同聚合组内所有记录应用内部表达式(例如 n.age)的结果。
聚合可以在所有匹配的子图上计算,也可以通过引入分组键进一步分割。这些是非聚合表达式,用于对进入聚合函数的值进行分组。
假设我们有以下返回语句:
sqlCopy code
SELECT * FROM cypher('graph_name', $$
MATCH (v:Person)
RETURN v.name, count(*)
$$) as (grouping_key agtype, count agtype);我们有两个返回表达式:grouping_key 和 count()。第一个 grouping_key 不是一个聚合函数,因此它将成为分组键。后者 count() 是一个聚合表达式。匹配的子图将被划分为不同的桶,具体取决于分组键。然后将在这些桶上运行聚合函数,为每个桶计算一个聚合值。
在聚合函数上进行排序
要使用聚合函数对结果集进行排序,聚合必须包含在 RETURN 中以便在 ORDER BY 中使用。
sqlCopy code
SELECT *
FROM cypher('graph_name', $$
MATCH (me:Person)-[]->(friend:Person)
RETURN count(friend), me
ORDER BY count(friend)
$$) as (friends agtype, me agtype);唯一聚合
在唯一聚合(即形式为 aggr(DISTINCT expr) 的情况下),聚合值列表是候选值列表,其中所有空值都被移除。此外,在唯一聚合中,只有所有等价候选值中的一个被包含在聚合值列表中,即等价性下的重复项被移除。
DISTINCT 操作符与聚合一起使用。它用于使所有值在通过聚合函数之前变得唯一。
sqlCopy code
SELECT *
FROM cypher('graph_name', $$
MATCH (v:Person)
RETURN count(DISTINCT v.eyes), count(v.eyes)
$$) as (distinct_eyes agtype, eyes agtype);模糊的分组语句
不要求用户为查询指定其分组键的这个特性可能导致 Cypher 应将什么视为其分组键的模糊性。点击此处了解更多详细信息。
数据设置
sqlCopy code
SELECT * FROM cypher('graph_name', $$
CREATE (:L {a: 1, b: 2, c: 3}),
(:L {a: 2, b: 3, c: 1}),
(:L {a: 3, b: 1, c: 2})
$$) as (a agtype);在 AGE 中的无效查询
AGE 对这个问题的解决方案是不允许 WITH 或 RETURN 列结合不在相同 WITH 或 RETURN 子句的另一列中明确列出的变量与聚合函数相结合。
查询:
sqlCopy code
SELECT * FROM cypher('graph_name', $$
MATCH (x:L)
RETURN x.a + count(*) + x.b + count(*) + x.c
$$) as (a agtype);结果:
sqlCopy code
ERROR: "x" must be either part of an explicitly listed key or used inside an aggregate function
LINE 3: RETURN x.a + count(*) + x.b + count(*) + x.cAGE 中的有效查询
在 AGE 中不包括聚合函数的列被视为该 WITH 或 RETURN 子句的分组键。
对于上述查询,用户可以以多种方式重写查询以返回结果。
查询:
sqlCopy code
SELECT * FROM cypher('graph_name', $$
MATCH (x:L)
RETURN (x.a + x.b + x.c) + count(*) + count(*), x.a + x.b + x.c
$$) as (count agtype, key agtype);x.a + x.b + x.c 是分组键。这样创建的分组键必须包含括号。
结果
sqlCopy code
count key
12 6
1 row查询
sqlCopy code
SELECT * FROM cypher('graph_name', $$
MATCH (x:L)
RETURN x.a + count(*) + x.b + count(*) + x.c, x.a, x.b, x.c
$$) as (count agtype, a agtype, b agtype, c agtype);x.a、x.b 和 x.c 将被视为不同的分组键
结果:
sqlCopy code
abc
count
8 3 1 2
8 2 3 1
8 1 2 3
3 rows在模糊分组中的顶点和边
或者,分组键可以是一个顶点或边,然后可以指定顶点或边的任何属性,而不需要在 WITH 或 RETURN 列中明确声明。
sqlCopy code
SELECT * FROM cypher('graph_name', $$
MATCH (x:L)
RETURN count(*) + count(*) + x.a + x.b + x.c, x
$$) as (count agtype, key agtype);结果将根据 x 分组,因为可以安全地假设属性被视为分组不明确。
结果
sqlCopy code
key
count
8 {"id": 1407374883553283, "label": "L", "properties": {"a": 3, "b": 1, "c": 2}}::vertex
8 {"id": 1407374883553281, "label": "L", "properties": {"a": 1, "b": 2, "c": 3}}::vertex
8 {"id": 1407374883553282, "label": "L", "properties": {"a": 2, "b": 3, "c": 1}}::vertex
3 rows隐藏不想要的分组键
如果认为分组键对查询输出无关紧要,则可以在 WITH 子句中进行聚合,然后将信息传递给 RETURN 子句。
sqlCopy code
SELECT * FROM cypher('graph_name', $$
MATCH (x:L)
WITH count(*) + count(*) + x.a + x.b + x.c as column, x
RETURN column
$$) as (a agtype);结果
sqlCopy code
a
8
8
8
3 rows 使用公有云服务
一些公有云的提供了免安装的数据库服务,无需自己部署。以MemFireCloud为例
直接连接
每个MemFire Cloud应用内置一个完整的Postgres数据库,你可以使用任何支持Postgres的工具来连接到数据库。你可以在控制台内的数据库设置中获取连接信息:
- 来到左侧菜单栏的
设置部分 - 点击
数据库 - 启用数据库直连
- 找到应用的
连接信息
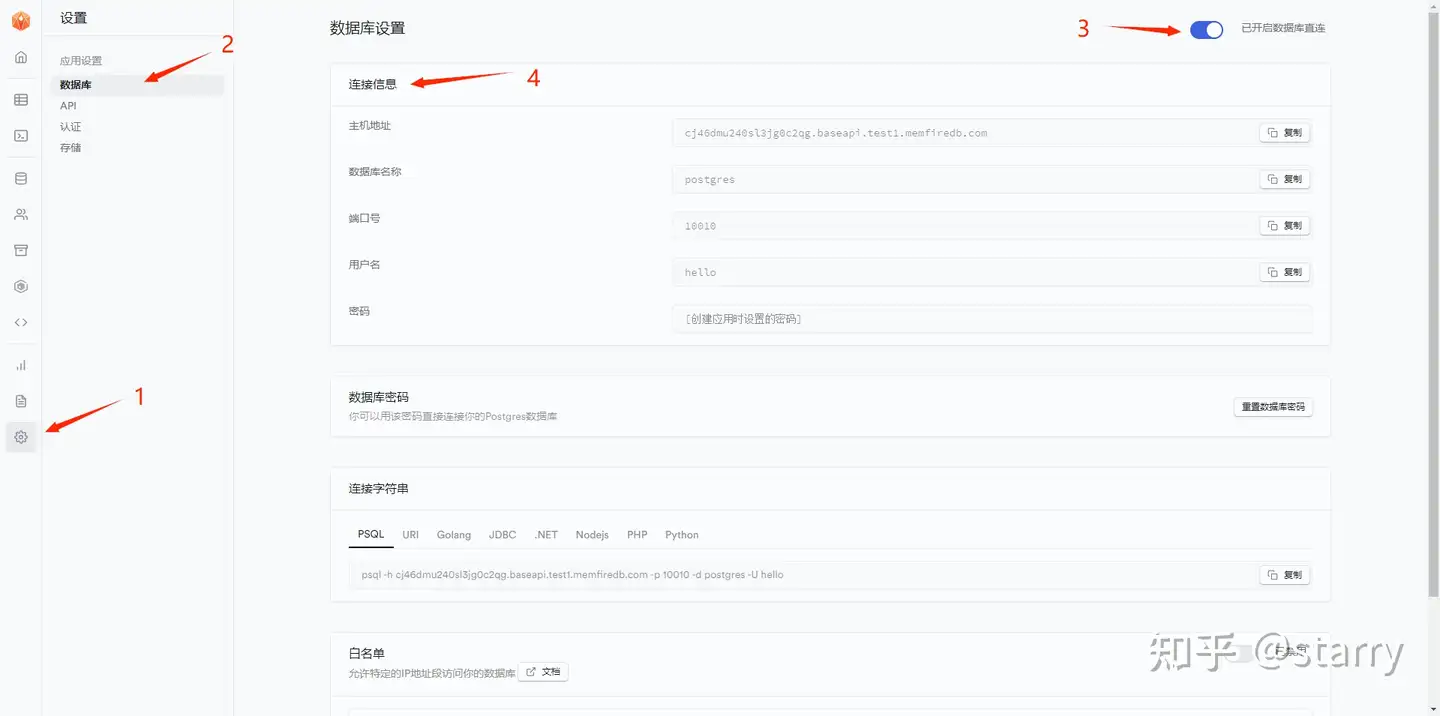
开启直连
白名单
MemFire Cloud内置白名单功能,开启白名单后,只允许白名单内的IP地址段访问你的数据库。关闭白名单后,访问你数据库的IP地址不受限制,即任何IP地址只要有连接信息都可以与你的数据库进行直连。 在进行白名单配置时,要遵循CIDR规则。MemFire Cloud中白名单功能 默认是关闭的,需用户手动开启。
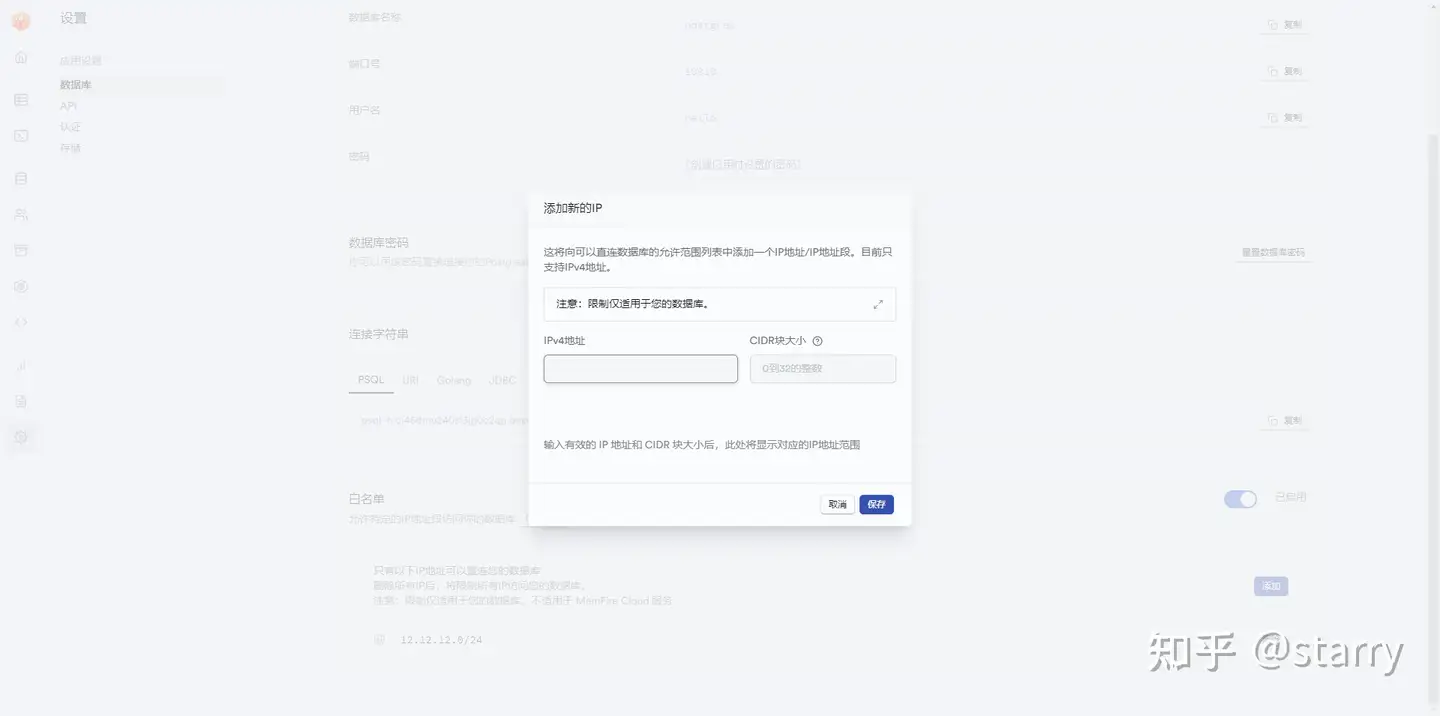
配置白名单
通过数据库客户端连接数据库,可以执行图操作
CREATE EXTENSION age;
LOAD 'age';
SET search_path = ag_catalog, "$user", public;