目录
[blob 和 text 有什么区别?](#blob 和 text 有什么区别?)
[DATETIME 和 TIMESTAMP 的异同?](#DATETIME 和 TIMESTAMP 的异同?)
[MySQL 中 in 和 exists 的区别?](#MySQL 中 in 和 exists 的区别?)
[MySQL 里记录货币用什么字段类型比较好?](#MySQL 里记录货币用什么字段类型比较好?)
[MySQL 怎么存储 emoji?](#MySQL 怎么存储 emoji?)
[用过哪些 MySQL 函数](#用过哪些 MySQL 函数)
[count(*) 和 count(1) 有什么区别?哪个性能最好?](#count(*) 和 count(1) 有什么区别?哪个性能最好?)
[MySQL 第 3-10 条记录怎么查?(补充)](#MySQL 第 3-10 条记录怎么查?(补充))
[联合查询中union和union all 的区别是什么?](#联合查询中union和union all 的区别是什么?)
[一条 SQL 查询语句的执行顺序?](#一条 SQL 查询语句的执行顺序?)
MySQL概念
MySQL 是一个开源的关系型数据库管理系统,现在隶属于 Oracle 旗下,也是我用得最多的一款关系型数据库。
与此同时,MySQL 也是我们国内使用频率最高的一种数据库,我在本地安装的是最新的 8.0 社区版。
数据库三大 范式 是什么?
- 第一 范式 : 保证每一列不可再分
- 第二 范式 : 前提是满足第一范式,要求数据库表中的每一列都和 主键 直接相关,而不能只与主键的某一部分相关(主要针对联合主键)。
- 第三 范式 : 前提是满足第一和第二范式,第三范式需要消除非 主键 列对主键的传递依赖,即 非主键列只依赖于主键列,不依赖于其他非主键列 。
blob 和 text 有什么区别?
- blob 用于存储二进制数据,而 text 用于存储大字符串。
- blob 没有字符集,text 有一个字符集,并且根据字符集的校对规则对值进行排序和比较
DATETIME 和 TIMESTAMP 的异同?
相同点:
- 两个数据类型存储时间的表现格式一致。均为
YYYY-MM-DD HH:MM:SS - 两个数据类型都包含「日期」和「时间」部分。
- 两个数据类型都可以存储微秒的小数秒(秒后 6 位小数秒)
区别:
DATETIME 和 TIMESTAMP 的区别
- 日期范围:DATETIME 的日期范围是
1000-01-01 00:00:00.000000到9999-12-31 23:59:59.999999;TIMESTAMP 的时间范围是1970-01-01 00:00:01.000000UTC到 ``2038-01-09 03:14:07.999999UTC - 存储空间:DATETIME 的存储空间为 8 字节;TIMESTAMP 的存储空间为 4 字节
- 时区相关:DATETIME 存储时间与时区无关;TIMESTAMP 存储时间与时区有关,显示的值也依赖于时区
- 默认值:DATETIME 的默认值为 null;TIMESTAMP 的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP)
MySQL 中 in 和 exists 的区别?
MySQL 中的 in 语句是把外表和内表作 hash 连接 ,而exists 语句是对外表作 loop 循环,每次 loop 循环再对内表进行查询。
我们可能认为 exists 比 in 语句的效率要高,这种说法其实是不准确的,要区分情景:
- 如果查询的两个表大小相当,那么用 in 和 exists 差别不大。
- 如果两个表中一个较小,一个是大表,则子查询表大的用 exists,子查询表小的用 in。
- not in 和 not exists:如果查询语句使用了 not in,那么内外表都进行全表扫描,没有用到索引;而 not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用 not exists 都比 not in 要快。
MySQL 里记录货币用什么字段类型比较好?
货币在数据库中 MySQL 常用 Decimal 和 Numric 类型表示,这两种类型被 MySQL 实现为同样的类型。他们被用于保存与货币有关的数据。
例如 salary DECIMAL(9,2),9(precision)代表将被用于存储值的总的小数位数,而 2(scale)代表将被用于存储小数点后的位数。存储在 salary 列中的值的范围是从-9999999.99 到 9999999.99。
DECIMAL 和 NUMERIC 值作为字符串存储,而不是作为二进制 浮点数 ,以便保存那些值的小数精度。
之所以不使用 float 或者 double 的原因:因为 float 和 double 是以二进制存储的,所以有一定的误差。
MySQL 怎么存储 emoji?
MySQL 的 utf8 字符集仅支持最多 3 个字节的 UTF-8 字符,但是 emoji 表情(😊)是 4 个字节的 UTF-8 字符,所以在 MySQL 中存储 emoji 表情时,需要使用 utf8mb4 字符集。
MySQL 8.0 已经默认支持 utf8mb4 字符集,可以通过 SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%'; 查看。
ALTER TABLE mytable CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;用过哪些 MySQL 函数
MySQL 支持很多内置函数,包括执行计算、格式转换、日期处理等。我说一些自己常用的。
用过哪些字符串函数来处理文本?
CONCAT(): 连接两个或多个字符串。LENGTH(): 返回字符串的长度。SUBSTRING(): 从字符串中提取子字符串。REPLACE(): 替换字符串中的某部分。LOWER()和UPPER(): 分别将字符串转换为小写或大写。TRIM(): 去除字符串两侧的空格或其他指定字符。
用过哪些数值函数?
ABS(): 返回一个数的绝对值。CEILING(): 返回大于或等于给定数值的最小整数。FLOOR(): 返回小于或等于给定数值的最大整数。ROUND(): 四舍五入到指定的小数位数。MOD(): 返回除法操作的余数。
用过哪些日期和时间函数?
NOW(): 返回当前的日期和时间。CURDATE(): 返回当前的日期。CURTIME(): 返回当前的时间。DATE_ADD()和DATE_SUB(): 在日期上加上或减去指定的时间间隔。DATEDIFF(): 返回两个日期之间的天数。DAY(),MONTH(),YEAR(): 分别返回日期的日、月、年部分。
用过哪些汇总函数?
SUM(): 计算数值列的总和。AVG(): 计算数值列的平均值。COUNT(): 计算某列的行数。MAX()和MIN(): 分别返回列中的最大值和最小值。GROUP_CONCAT(): 将多个行值连接为一个字符串。
用过哪些逻辑函数?
IF(): 如果条件为真,则返回一个值;否则返回另一个值。CASE: 根据一系列条件返回值。COALESCE(): 返回参数列表中的第一个非 NULL 值。
用过哪些格式化函数?
FORMAT(): 格式化数字为格式化的字符串,通常用于货币显示。
用过哪些类型转换函数?
CAST(): 将一个值转换为指定的数据类型。CONVERT(): 类似于CAST(),用于类型转换。
count(*) 和 count(1) 有什么区别?哪个性能最好?

- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为 NULL
- count(1)包括了所有列,用 1 代表代码行,在统计结果的时候,不会忽略列值为 NULL
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者 0,而是表示 null)的计数,即某个字段值为 NULL 时,不统计。
count()遍历顺序
count(1)、 count(*)、 count( 主键 字段)在执行的时候,如果表里存在二级索引, 优化器 就会选择二级索引进行扫描。
所以,如果要执行 count(1)、 count(*)、 count(主键字段) 时,尽量在数据表上建立二级索引,这样优化器会自动采用 key_len 最小的二级索引进行扫描,相比于扫描主键索引效率会高一些。
再来,就是不要使用 count(字段) 来统计记录个数,因为它的效率是最差的,会采用全表扫描的方式来统计。如果你非要统计表中该字段不为 NULL 的记录个数,建议给这个字段建立一个二级索引。
count 主键 和count非主键结果会不同吗?
主键是不能存NULL值的,所以count主键代表统计表中所有行数据的数量。
而非主键是可以存NULL值的,所以count非主键统计的是表中这个列的非NULL值的数量。
Mysql 内连接、外连接有什么区别
内连接和外连接都是用于连表查询。
内连接是只返回两个表匹配的数据行,外连接可以返回两个表匹配和不匹配的数据行,外连接主要分为左连接和右连接
- 左连接返回左表中的所有行和右表中匹配的行。如果右表中没有匹配的行,则用 NULL 值填充
- 右连接返回右表中的所有行和左表中匹配的行,如果左表中没有匹配的行,则用 NULL 值填充
- 交叉连接(cross join):返回第一个表中的每一行与第二个表中的每一行的组合,这种类型的连接通常用于生成笛卡尔积。
- 笛卡尔积:数学中的一个概念,例如集合 A={a,b},集合 B={0,1,2},那么 A✖️B=
{<a,0>,<a,1>,<a,2>,<b,0>,<b,1>,<b,2>,}。
外连接时on和where过滤条件区别?
ON条件用于连接的匹配 (在连接操作之前执行),WHERE条件用于对连接后的结果进行筛选
MySQL 第 3-10 条记录怎么查?
在 MySQL 中,要查询第 3 到第 10 条记录,可以使用 limit 语句,结合偏移量 offset 和行数 row_count 来实现。
limit 语句用于限制查询结果的数量,偏移量表示从哪条记录开始,行数表示返回的记录数量。
SELECT * FROM table_name LIMIT 2, 8;- 2:偏移量,表示跳过前两条记录,从第三条记录开始。
- 8:行数,表示从偏移量开始,返回 8 条记录。
偏移量是从 0 开始的,即第一条记录的偏移量是 0;如果想从第 3 条记录开始,偏移量就应该是 2。
having和where的区别?
在GROUP BY 分组查询过程中,Where 是工作在GROUP BY之前 ,Where 是对分组之前的数据进行筛选,无法使用 聚合函数
Having 是工作在GROUP BY之后,Having 主要对分组之后的数据进行筛选,可以使用 聚合函数
delete、drop、truncate有什么区别?
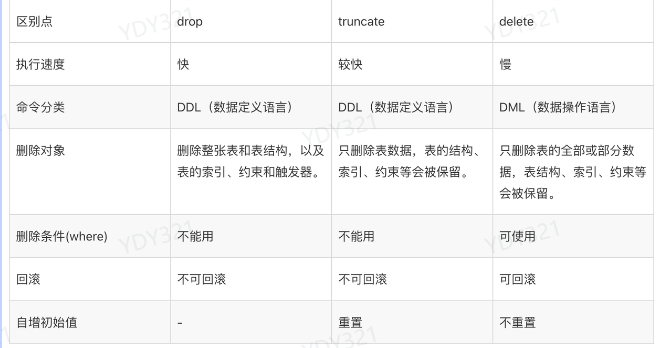
- delete 是删除表中的数据 ,我们可以选择删除部分数据或者全部数据,delete 删除的数据是可以回滚的, delete 操作并不是真的把数据删除掉了,而是给数据打上删除标记,目的是为了空间复用,所以 delete 删除表数据,磁盘文件的大小是不会缩减的。
- drop 是删除表结构和表中所有的数据 ,truncate 是只删除表中所有的记录,表结构并不会被删除,drop 和 truncate 删除的数据都是不可以回滚的,并且删除表会立刻释放磁盘空间
- 从删除表的性能来看,drop>truncate>delete
联合查询中union和union all 的区别是什么?
UNION:在合并结果集后会自动剔除重复的行
UNION ALL: 则会保留所有的重复行,不会进行去重操作
一条 SQL 查询语句的执行顺序?

自己整理,借鉴很多博主,感谢他们