最近遇到一个跨库查询性能问题,查询耗时从 24 秒优化到 0.6 秒,提升了 40 倍。这篇文章记录一下整个排查和解决过程,涉及 Superset、PostgreSQL FDW、微服务架构下的数据聚合问题。
背景
先介绍一下涉及的技术栈。
我们用 Apache Superset 做 BI 看板,数据分散在多个微服务数据库里:
为什么选 Superset:开源免费、功能够用、支持跨库查询(Meta Database)、社区活跃。
什么是 PostgreSQL FDW:Foreign Data Wrapper,PostgreSQL 的一个核心特性,可以在一个数据库里直接访问另一个数据库的数据,就像访问本地表一样。
FDW 的工作流程大概是这样的:
FDW 为什么快:数据库间直接通信,JOIN 操作在数据库引擎层执行(C 语言优化),只传输最终结果。
微服务的数据聚合问题
我们的微服务架构长这样:
数据库隔离的好处大家都知道:服务独立部署、故障隔离、技术栈灵活。
但有个现实问题:运营报表需要聚合多个库的数据。比如我们要做一个消息评价看板,评价数据在业务库,用户名在用户库,需要 JOIN 才能出报表。
问题:Superset Meta Database 太慢了
一开始我们用 Superset 的 Meta Database 功能做跨库查询。这是个实验性功能,工作原理是这样的:
看出问题了吗?它把每个库的全量数据 都拉到 Superset 内存里,然后用 Python 做 JOIN。
配置其实很简单:
python
# superset_config.py
FEATURE_FLAGS = {
"ENABLE_SUPERSET_META_DB": True,
}
SUPERSET_META_DB_LIMIT = 10000 # 每表最大读取行数跨库查询语法:
sql
-- 整个表路径放在双引号里
SELECT * FROM "biz_db.public.users" LIMIT 10;
-- 跨库 JOIN
SELECT
r.rating_type,
u.username
FROM "biz_db.public.message_ratings" r
LEFT JOIN "users_db.public.users" u
ON r.user_id = u.id;实测数据:
| 查询类型 | 数据量 | 耗时 |
|---|---|---|
| 单表查询 | 100 行 | 12s |
| 跨库 JOIN | 13 行 | 21-24s |
| 复杂 JOIN | 50 行 | 超时(>30s) |
24 秒查 13 行数据,这没法用。
瓶颈分析:
根本原因:
- 多次网络往返:每个库单独查询,结果传回 Superset
- 全量数据传输:即使只需要 JOIN 后的少量数据,也要先传输全量
- Python 执行 JOIN:效率远低于数据库引擎
方案选择
调研了几个方案:
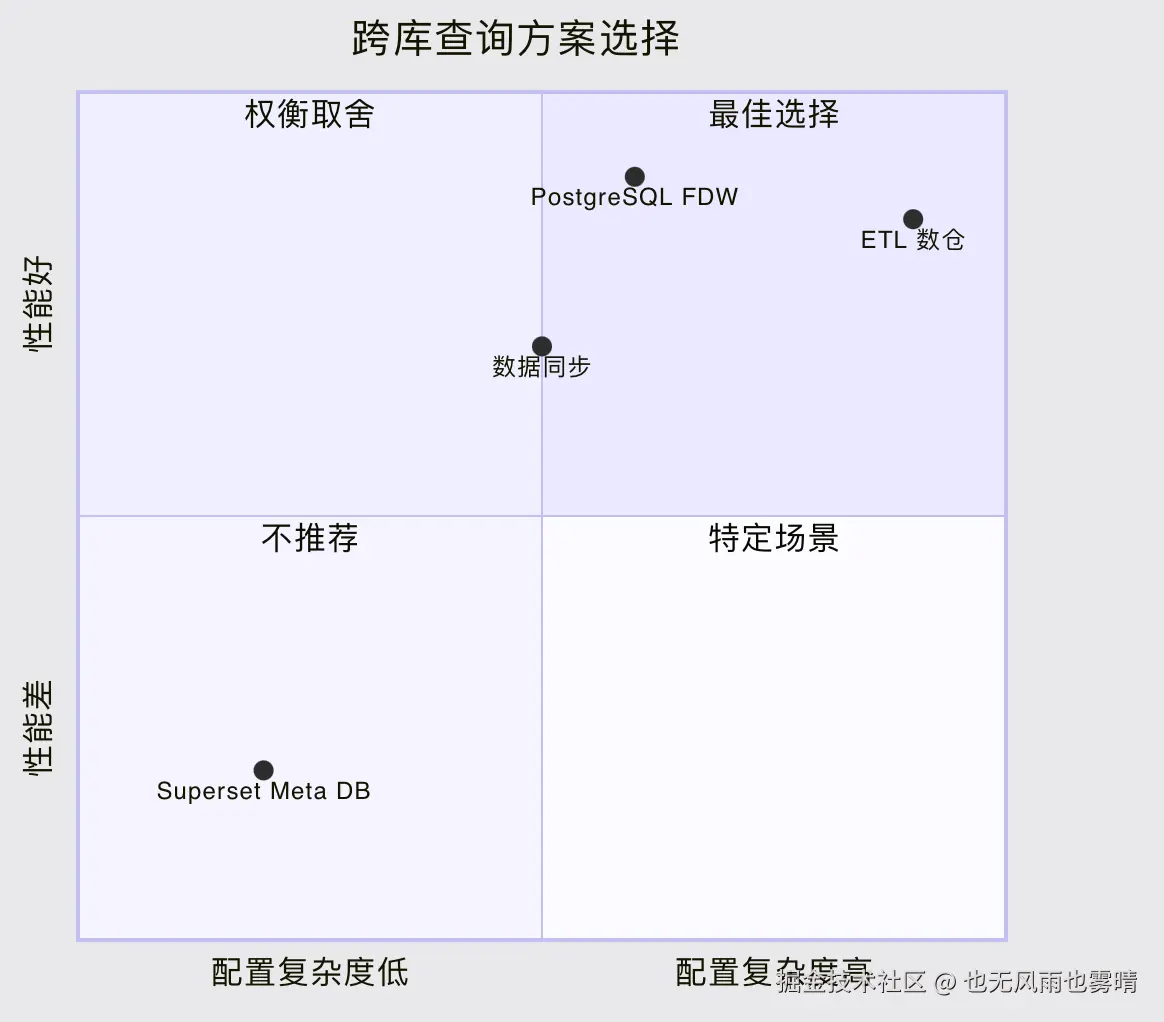
| 方案 | 性能 | 实时性 | 配置复杂度 | 维护成本 | 适用场景 |
|---|---|---|---|---|---|
| Superset Meta DB | ❌ 差 (24s) | ✅ 实时 | ✅ 简单 | ✅ 零 | 数据量小,不频繁查询 |
| PostgreSQL FDW | ✅ 好 (<1s) | ✅ 实时 | ⚠️ 中等 | ✅ 零 | 推荐:实时跨库查询 |
| 数据同步 | ✅ 好 | ⚠️ 有延迟 | ⚠️ 中等 | ⚠️ 定时任务 | 可接受延迟的场景 |
| ETL 数仓 | ✅ 好 | ❌ T+1 | ❌ 复杂 | ❌ 高 | 大规模数据分析 |
选 FDW 的理由:
- 性能是硬性需求:24 秒没法用
- 实时性要求:用户名变更需要立即生效
- 团队能力:有 DBA 支持
- 成本:FDW 是 PostgreSQL 内置功能,无额外成本
权衡取舍:接受需要 DBA 权限配置的复杂度,换取 40 倍性能提升。
FDW 架构设计
最终架构长这样:
核心组件:
- Foreign Server:远程数据库连接信息
- User Mapping:认证凭证
- Foreign Table:映射远程表到本地
- View:封装 JOIN 查询
数据流对比,一目了然:
Before(Meta Database):
After(FDW):
实现步骤
FDW 配置涉及四个组件:
步骤 1:启用 FDW 扩展
sql
-- 需要超级用户权限
CREATE EXTENSION IF NOT EXISTS postgres_fdw;postgres_fdw 是 PostgreSQL 官方提供的 FDW 扩展,专门用于连接其他 PostgreSQL 数据库,只需要在本地库执行一次。
步骤 2:创建外部服务器
sql
CREATE SERVER users_server
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'your-db-host.internal.local',
dbname 'users_db',
port '5432'
);步骤 3:创建用户映射
sql
CREATE USER MAPPING FOR your_user
SERVER users_server
OPTIONS (
user 'your_user',
password 'your_password'
);用户映射告诉 FDW:当本地用户查询外部表时,用什么凭证连接远程库。
常见问题:报错 user mapping not found 说明当前用户没有映射,需要为每个要使用 FDW 的本地用户创建映射,或者用 FOR PUBLIC 允许所有用户。
步骤 4:导入外部表
自动导入(推荐):
sql
IMPORT FOREIGN SCHEMA public
LIMIT TO (users)
FROM SERVER users_server
INTO fdw_users; -- 导入到 fdw_users schema手动创建:
sql
CREATE FOREIGN TABLE fdw_users.users (
id uuid,
realm_id uuid,
username varchar(255),
firstname varchar(255),
lastname varchar(255),
email varchar(255),
enabled boolean,
created_at timestamp,
updated_at timestamp
)
SERVER users_server
OPTIONS (schema_name 'public', table_name 'users');步骤 5:创建视图
sql
CREATE OR REPLACE VIEW v_ratings_with_username AS
SELECT
r.created_at AS 评价时间,
r.rating_type AS 评价类型,
u.username AS 用户名,
SUBSTR(m.content, 1, 200) AS 消息内容,
CASE
WHEN m.references IS NOT NULL
AND m.references::text != '[]'
THEN '是'
ELSE '否'
END AS 使用知识库
FROM message_ratings r
LEFT JOIN task_messages m ON r.message_id = m.id
LEFT JOIN fdw_users.users u ON r.user_id::uuid = u.id
WHERE m.role = 'assistant';视图的好处:封装 JOIN 逻辑,用户只需 SELECT * FROM v_ratings_with_username,底层表结构变化时只改视图定义。
完整配置脚本
sql
-- ========================================
-- FDW 跨库查询配置脚本
-- 在 biz_db 数据库执行
-- 需要超级用户权限
-- ========================================
-- 1. 启用 FDW 扩展
CREATE EXTENSION IF NOT EXISTS postgres_fdw;
-- 2. 创建外部服务器
CREATE SERVER IF NOT EXISTS users_server
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'your-db-host.internal.local',
dbname 'users_db'
);
-- 3. 创建用户映射
CREATE USER MAPPING FOR your_user
SERVER users_server
OPTIONS (user 'your_user', password 'your_password');
-- 4. 创建 schema 存放外部表
CREATE SCHEMA IF NOT EXISTS fdw_users;
-- 5. 导入外部表
IMPORT FOREIGN SCHEMA public
LIMIT TO (users)
FROM SERVER users_server
INTO fdw_users;
-- 6. 创建业务视图
CREATE OR REPLACE VIEW v_ratings_with_username AS
SELECT
r.created_at AS 评价时间,
r.rating_type AS 评价类型,
u.username AS 用户名,
SUBSTR(m.content, 1, 200) AS 消息内容,
CASE
WHEN m.references IS NOT NULL
AND m.references::text != '[]'
THEN '是'
ELSE '否'
END AS 使用知识库
FROM message_ratings r
LEFT JOIN task_messages m ON r.message_id = m.id
LEFT JOIN fdw_users.users u ON r.user_id::uuid = u.id
WHERE m.role = 'assistant';
-- 7. 授权
GRANT USAGE ON FOREIGN SERVER users_server TO your_user;
GRANT SELECT ON v_ratings_with_username TO your_user;
-- 验证
SELECT * FROM v_ratings_with_username LIMIT 5;Superset 配置调整
配置 FDW 后,Superset 的查询方式要改一下。
Before(Meta Database):
sql
-- 使用 Superset Meta Database
-- Database: Superset meta database
SELECT * FROM "biz_db.public.message_ratings" LIMIT 10;After(直连 + 视图):
sql
-- 直接连接 biz_db
-- Database: biz_db
SELECT * FROM v_ratings_with_username LIMIT 10;就是选 biz_db 数据库(不是 Meta Database),直接查视图。
错误排查
遇到问题可以按这个顺序排查:
排查清单:
| 步骤 | 检查命令 | 预期结果 |
|---|---|---|
| 1. 检查扩展 | SELECT * FROM pg_extension WHERE extname='postgres_fdw'; |
有记录 |
| 2. 检查服务器 | SELECT * FROM pg_foreign_server; |
有 users_server |
| 3. 检查用户映射 | SELECT * FROM pg_user_mappings; |
当前用户有映射 |
| 4. 检查外部表 | SELECT * FROM information_schema.foreign_tables; |
有 users 表 |
| 5. 测试连接 | SELECT * FROM fdw_users.users LIMIT 1; |
返回数据 |
性能监控:
sql
-- 查看执行计划
EXPLAIN ANALYZE
SELECT * FROM v_ratings_with_username LIMIT 50;
-- 关注:
-- 1. Foreign Scan 的 actual time
-- 2. 远程查询的行数
-- 3. 总执行时间健康指标:单次查询 < 1 秒,Foreign Scan 时间 < 100ms,大表上有索引。
测试结果
| 方案 | 查询耗时 | 数据库耗时 | 性能提升 |
|---|---|---|---|
| Superset Meta DB | 21-24s | 12ms | 基准 |
| PostgreSQL FDW | 0.5-0.8s | 0.5s | 40x |
执行计划对比:
Superset Meta DB 的数据库层只需 12ms:
sql
Limit (cost=1635.43..1635.56 rows=50) (actual time=12.550..12.554 rows=13)问题在应用层的 Python JOIN。
FDW 整体都快:
sql
Foreign Scan on users (cost=0.00..8.16 rows=2) (actual time=0.020..0.027 rows=2)常用查询
配置完成后,在 Superset 里这样用:
sql
-- 选择数据库: biz_db
SELECT * FROM v_ratings_with_username
ORDER BY 评价时间 DESC
LIMIT 100;按日期过滤:
sql
SELECT * FROM v_ratings_with_username
WHERE 评价时间 > NOW() - INTERVAL '7 days'
ORDER BY 评价时间 DESC;统计评价分布:
sql
SELECT
评价类型,
COUNT(*) as 数量
FROM v_ratings_with_username
GROUP BY 评价类型;统计知识库使用率:
sql
SELECT
使用知识库,
COUNT(*) as 数量,
ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER (), 2) as 百分比
FROM v_ratings_with_username
GROUP BY 使用知识库;FAQ
Q: 用户名变更后,视图会自动更新吗?
会的,FDW 是实时连接,每次查询都获取最新数据。
Q: 对线上数据库有性能影响吗?
影响很小。FDW 查询相当于普通的远程查询,查询量不大的话影响可以忽略。
Q: 远程库挂了会怎样?
查询会报错,但不影响本地库的其他功能。
Q: 如何添加新的跨库表?
sql
IMPORT FOREIGN SCHEMA public
LIMIT TO (新表名)
FROM SERVER users_server
INTO fdw_users;总结
几个关键收获:
技术层面:
- Superset Meta Database 的原理:应用层跨库,数据拉到内存 JOIN,适合小数据量低频查询
- PostgreSQL FDW 的优势:数据库层跨库,利用数据库引擎优化,适合需要高性能的跨库场景
- 性能分析方法:EXPLAIN ANALYZE 分析执行计划,区分数据库层和应用层的耗时
架构层面:
- 微服务的数据聚合挑战:数据分散是微服务的固有问题,需要根据场景选择跨库方案
- "数据在哪里处理"很重要:同样的 JOIN,在不同层执行性能差异巨大,尽量把计算下推到数据库层
方案选择象限图:
附录:SQL 参考
FDW 配置命令:
sql
-- 查看所有外部服务器
SELECT * FROM pg_foreign_server;
-- 查看所有用户映射
SELECT * FROM pg_user_mappings;
-- 查看所有外部表
SELECT * FROM information_schema.foreign_tables;
-- 删除 FDW 配置(回滚用)
DROP VIEW IF EXISTS v_ratings_with_username;
DROP USER MAPPING IF EXISTS FOR your_user SERVER users_server;
DROP SERVER IF EXISTS users_server CASCADE;常用查询模板:
sql
-- 带时间范围的评价查询
SELECT * FROM v_ratings_with_username
WHERE 评价时间 BETWEEN '2024-01-01' AND '2024-12-31'
ORDER BY 评价时间 DESC;
-- 用户评价统计
SELECT
用户名,
COUNT(*) as 评价次数,
SUM(CASE WHEN 评价类型 = 'like' THEN 1 ELSE 0 END) as 点赞数,
SUM(CASE WHEN 评价类型 = 'dislike' THEN 1 ELSE 0 END) as 点踩数
FROM v_ratings_with_username
GROUP BY 用户名
ORDER BY 评价次数 DESC;延伸阅读
如果你觉得这篇文章有帮助,欢迎关注我的 GitHub,下面是我的一些开源项目:
Claude Code Skills (按需加载,意图自动识别,不浪费 token,介绍文章):
- code-review-skill - 代码审查技能,覆盖 React 19、Vue 3、TypeScript、Rust 等约 9000 行规则(详细介绍)
- 5-whys-skill - 5 Whys 根因分析,说"找根因"自动激活
- first-principles-skill - 第一性原理思考,适合架构设计和技术选型
vibe coding 原理学习:
- coding-cli-guide(学习网站)- 学习 qwen-cli 时整理的笔记,40+ 交互式动画演示 AI CLI 内部机制
全栈项目(适合学习现代技术栈):
- prompt-vault - Prompt 管理器,用的都是最新的技术栈,适合用来学习了解最新的前端全栈开发范式:Next.js 15 + React 19 + tRPC 11 + Supabase 全栈示例,clone 下来配个免费 Supabase 就能跑
- chat_edit - 双模式 AI 应用(聊天+富文本编辑),Vue 3.5 + TypeScript + Vite 5 + Quill 2.0 + IndexedDB