在日常的数据分析和业务报表中,TopN 查询几乎无处不在:无论是寻找销量最高的前十件商品,还是筛选访问量最多的前几条日志,开发者和数据分析师都在频繁处理"前 N 条数据"。然而,当表的列数达到百余或更多时,一个看似简单的 SELECT * ... ORDER BY ... LIMIT N 查询,背后可能隐藏着巨大的性能瓶颈。尽管我们只关心某一列的前 N 条结果,数据库依然可能扫描整张表的所有列,从而导致 IO 读放大(Read Amplification),拖慢查询速度。在大数据场景下,这种低效不仅浪费存储带宽,还直接影响业务决策的实时性。
为了帮助用户快速获取目标数据,Apache Doris针对 TopN 类型查询进行了全局优化,可将此类查询的性能提升约 5 倍;同时,优化范围也从单表进一步拓展至数据湖场景与多表关联查询,显著扩大了适用范围。
TopN 查询优化思路
为直观说明 TopN 查询的性能瓶颈,我们不妨将其简化为列式存储文件的读取场景,比如访问 Apache Doris 内部 Segment 文件,或访问数据湖中常见的 Parquet / ORC 文件。
假设需要找"第二列"中,数值最大的那条记录:SELECT * FROM table ORDER BY col2 LIMIT 1。由于查询需要返回整行,传统做法通常是先扫描表的所有列,排序后再定位到对应记录。
而 Apache Doris 原生列式存储的物理布局能够提供更优解:由于各列独立存放,因此可先仅读取第二列 的数据,快速计算出最大值所在的行号;再利用文件元数据,直接按行号提取该行的完整记录,无需扫描无关列。相比传统方式,这种方法显著减少 IO 读放大并降低内存占用。
这一优化对于湖仓分析场景尤为关键,因其直接关乎成本及性能 。 对于 Iceberg、Paimon 等开放湖格式,数据通常存放在 S3 等对象存储中,其 IO 性能普遍低于本地磁盘,且常按访问流量或请求次数计费。数据扫描次数的减少,意味着更低的延迟与更少的费用。特别是在数据量庞大、查询频繁的分析业务中,TopN 的优化不仅能大幅提升响应速度,更能带来切实的成本节约,实现性能与经济的双重收益。
全局 TopN 优化实现
基于上述思路指引,Apache Doris 完成了对 TopN 的全局优化 。对于单表的 TopN,利用单节点内的 Runtime Filter 对内部表查询进行动态过滤,有效减少 IO 并提升执行性能。在前不久不发的 4.0 版本中,也进一步提升了 TopN 查询性能,通过引入 MaterializeNode,实现了两阶段数据访问机制,并将优化范围从单表进一步拓展至数据湖场景与多表关联查询,显著扩大了其适用范围。
接下来,我们将深入解析 TopN Runtime Filter、单表两阶段 TopN 以及多表关联 TopN 的具体优化实现。
01 采用 Runtime Filter
Runtime Filter 是一种运行时数据裁剪技术。Doris 在执行 SQL 时动态生成过滤条件,并将这些条件下推到后续数据处理环节,利用运行时信息进行数据裁剪,从而降低 IO 开销并提升性能。在两表 Join 场景中,这一技术的典型应用是将 build 侧的 key 集合通过 IN-list、Bloom Filter 等形式下推到 probe 侧,尽早过滤掉无关数据,减少扫描和传输。
TopN Runtime Filter 同样采用这一思路,在运行时维护排序列的值范围,并生成 Runtime Filter 以裁剪后续扫描,从而提升单节点上的 TopN 查询性能。

在单机测试中,基于 Runtime Filter 优化后的 TopN 查询耗时从 3 秒降到 1 秒,性能提升约 3 倍:
vbnet
SELECT * FROM lineitem ORDER BY l_orderkey LIMIT 1000;02 两阶段数据访问机制
基于 Runtime Filter 的方法虽然能够在运行时动态过滤数据,但仍需读取所有列,无法彻底消除读放大。为此,我们引入了两阶段数据访问机制,进一步减少列的读取与 IO 开销。其执行流程示意图如下:
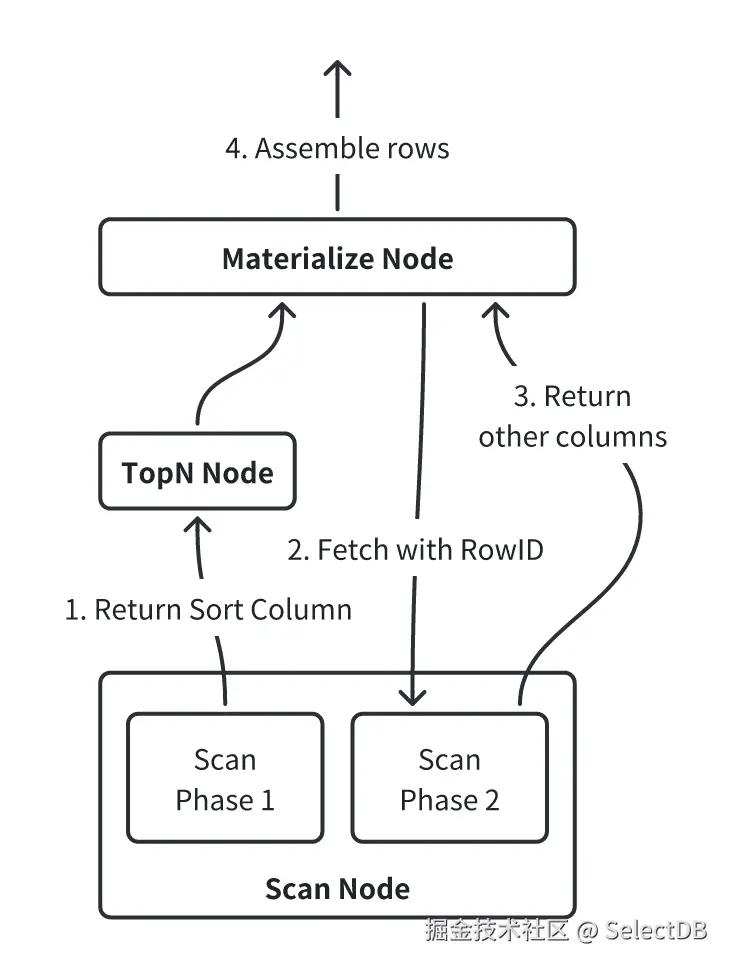
以如下 SQL 为例:
sql
SELECT * FROM table ORDER BY colA LIMIT 10;第 1 阶段:只读取排序列
在该阶段的 Scan 任务中,系统只读取排序列colA,并增加一个辅助列 __DORIS_ROWID_COL__。相当于执行:
sql
SELECT colA, __DORIS_ROWID_COL__ FROM table ORDER BY colA LIMIT 10;该方法跳过了非排序列的读取,仅扫描与排序相关的数据并记录其位置信息。DORIS_ROWID_COL 用于唯一标识数据所在文件与行号,其具体编码设计将在后续章节详细说明。
第 2 阶段:基于 RowID 的完整数据获取
新增的 MaterializeNode 接收第一阶段的结果后,会根据 __DORIS_ROWID_COL__ 向对应 Backend 发起基于行号(RowID)的数据拉取请求。借助文件中记录的位置信息,Doris 可以快速定位并读取对应记录;由于已完成 TopN 计算,第二阶段通常只需读取有限行(例如示例中的 10 行)。
得益于该阶段可通过 RPC 跨节点执行,打破了单节点执行限制,两阶段访问机制也自然扩展至多表关联的 TopN 场景,例如:
vbnet
SELECT * FROM
lineitem JOIN orders
ON l_orderkey = o_orderkey
WHERE o_orderdate < DATE '1995-03-15'
ORDER BY l_partkey LIMIT 100;其执行规划示意如下:
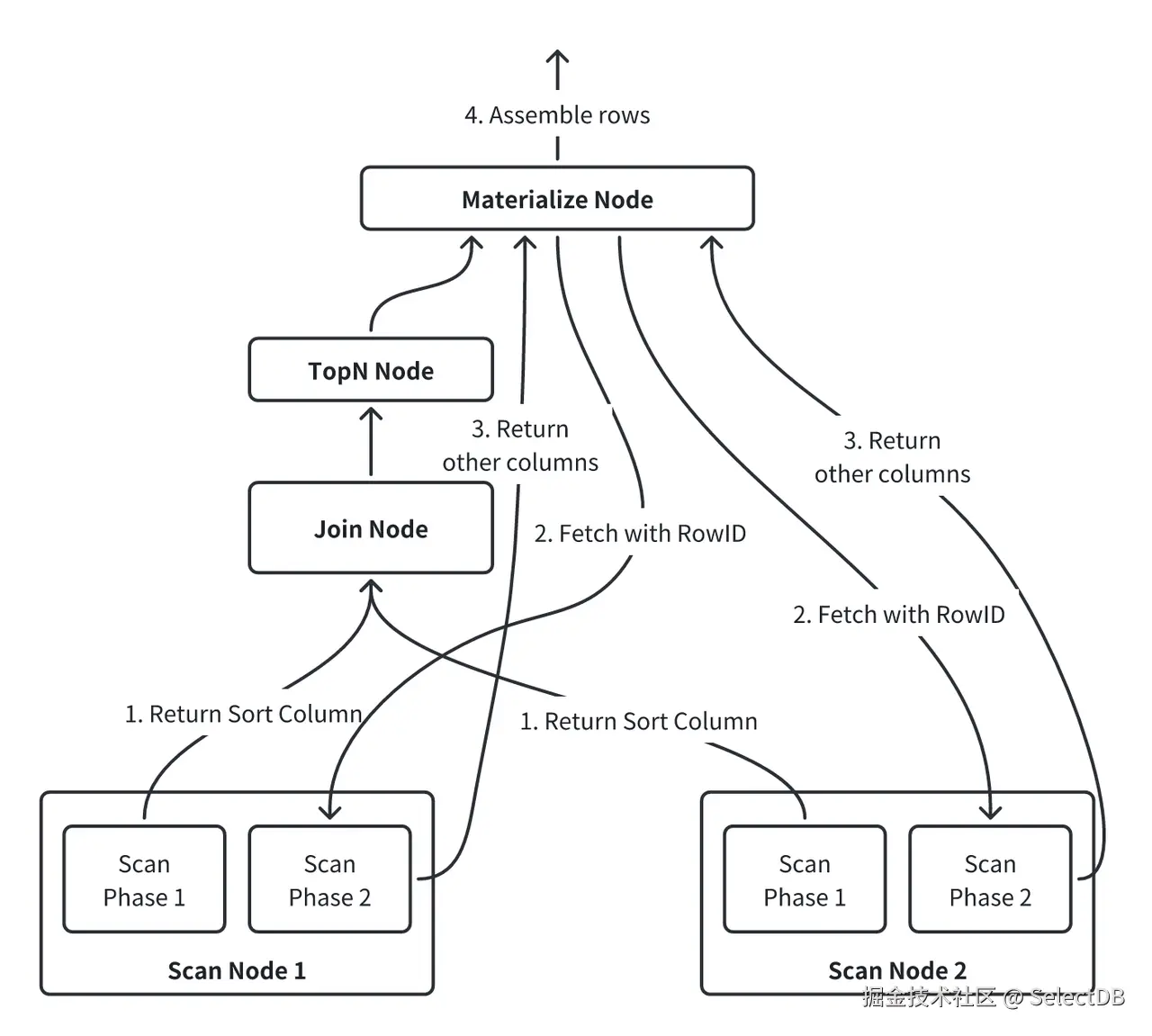
执行计划中,MaterializeNode 在第二阶段可以穿透 Join 节点,从扫描节点获取最终数据。
优化前后性能表现
Apache Doris 对于 TopN 的优化已在多种场景上得到验证。我们在 Doris 内表、Parquet 及 ORC 格式的 Hive 表上,基于 TPCH 100G 标准数据集中的 lineitem 表,分别构建了单表 与多表 TopN 查询场景,系统对比了优化前后的性能表现。
-
单表 TopN 查询示例(选取不同排序列):
vbnet-- Q1 - Q3: select * from lineitem order by l_orderkey limit 1000; select * from lineitem order by l_partkey limit 1000; select * from lineitem order by l_comment limit 1000; -
多表 TopN 查询示例(不同的表数、JOIN 方式与 SELECT 列数):
ini-- Q4: SELECT * FROM lineitem JOIN orders ON l_orderkey = o_orderkey WHERE o_orderdate < DATE '1995-03-15' ORDER BY l_partkey LIMIT 100; -- Q5: SELECT * FROM customer, orders, lineitem WHERE c_mktsegment = 'BUILDING' AND c_custkey = o_custkey AND l_orderkey = o_orderkey AND o_orderdate < DATE '1995-03-15' AND l_shipdate > DATE '1995-03-15' ORDER BY o_orderdate LIMIT 10; -- Q6: SELECT lineitem.* FROM customer, orders, lineitem WHERE c_mktsegment = 'BUILDING' AND c_custkey = o_custkey AND l_orderkey = o_orderkey AND o_orderdate < DATE '1995-03-15' AND l_shipdate > DATE '1995-03-15' ORDER BY o_orderdate LIMIT 10; -- Q7: SELECT l_shipdate, l_orderkey, l_linenumber FROM customer, orders, lineitem WHERE c_mktsegment = 'BUILDING' AND c_custkey = o_custkey AND l_orderkey = o_orderkey AND o_orderdate < DATE '1995-03-15' AND l_shipdate > DATE '1995-03-15' ORDER BY o_orderdate LIMIT 10; -- Q8: SELECT * FROM supplier, lineitem l1, orders, nation WHERE s_suppkey = l1.l_suppkey AND o_orderkey = l1.l_orderkey AND o_orderstatus = 'F' AND l1.l_receiptdate > l1.l_commitdate AND EXISTS (SELECT * FROM lineitem l2 WHERE l2.l_orderkey = l1.l_orderkey AND l2.l_suppkey <> l1.l_suppkey) AND NOT EXISTS (SELECT * FROM lineitem l3 WHERE l3.l_orderkey = l1.l_orderkey AND l3.l_suppkey <> l1.l_suppkey AND l3.l_receiptdate > l3.l_commitdate) AND s_nationkey = n_nationkey AND n_name = 'SAUDI ARABIA' ORDER BY s_name LIMIT 100; -- Q9: SELECT s_name, s_address, s_phone, s_acctbal, l_shipdate, l_quantity, l_extendedprice, l_discount, l_tax, l_returnflag, l_linestatus, l_shipinstruct, o_orderdate, o_totalprice, o_orderpriority, n_name FROM supplier, lineitem l1, orders, nation WHERE s_suppkey = l1.l_suppkey AND o_orderkey = l1.l_orderkey AND o_orderstatus = 'F' AND l1.l_receiptdate > l1.l_commitdate AND EXISTS (SELECT * FROM lineitem l2 WHERE l2.l_orderkey = l1.l_orderkey AND l2.l_suppkey <> l1.l_suppkey) AND NOT EXISTS (SELECT * FROM lineitem l3 WHERE l3.l_orderkey = l1.l_orderkey AND l3.l_suppkey <> l1.l_suppkey AND l3.l_receiptdate > l3.l_commitdate) AND s_nationkey = n_nationkey AND n_name = 'SAUDI ARABIA' ORDER BY s_name LIMIT 100; -- Q10: SELECT s_name, s_nationkey, l_orderkey, o_orderstatus, n_name FROM supplier, lineitem l1, orders, nation WHERE s_suppkey = l1.l_suppkey AND o_orderkey = l1.l_orderkey AND o_orderstatus = 'F' AND l1.l_receiptdate > l1.l_commitdate AND EXISTS (SELECT * FROM lineitem l2 WHERE l2.l_orderkey = l1.l_orderkey AND l2.l_suppkey <> l1.l_suppkey) AND NOT EXISTS (SELECT * FROM lineitem l3 WHERE l3.l_orderkey = l1.l_orderkey AND l3.l_suppkey <> l1.l_suppkey AND l3.l_receiptdate > l3.l_commitdate) AND s_nationkey = n_nationkey AND n_name = 'SAUDI ARABIA' ORDER BY s_name LIMIT 100;
下表汇总了优化带来的平均性能提升(查询时间缩短的百分比区间):
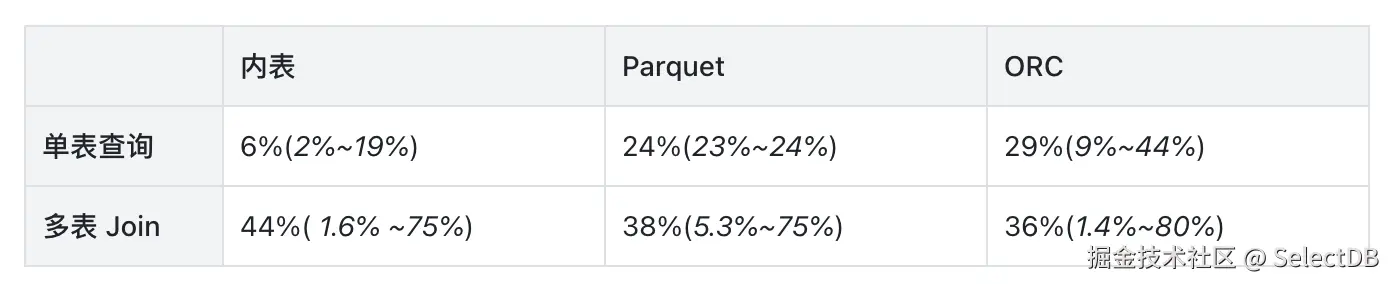
数据表明,TopN 优化在多种数据格式与查询模式下均能显著提升性能。平均可降低查询时间 30% 至 40% ,在部分多表关联场景中,性能提升幅度最高可达 80% ,效果尤为突出。这证明了两阶段访问机制有效减少了不必要的 IO,在不同存储格式和复杂查询中均能带来可观的收益。
TopN 执行逻辑解析
前文简要介绍了 TopN 的两阶段执行逻辑,在实际实现中,该流程面临几项核心挑战:
- Pipeline 执行线程的阻塞:第二阶段数据拉取涉及网络 IO,若在 Pipeline 执行线程中同步进行,会导致线程被阻塞,降低系统整体吞吐。
- 多表查询的支持:Join 算子涉及多张表的物化,需要准确识别对应需要物化的列。
- 内外表格式的统一:Doris 内表与 Parquet、ORC 等开放格式在行号管理上机制不同,需设计统一的行标识抽象,以确保内外表逻辑一致。
- 资源隔离管控:延迟物化阶段的 IO 操作需纳入 Workload Group 进行统一资源管控,避免干扰线上其他查询,保证系统稳定性。
针对上述挑战,Doris 通过混合任务调度器、全局行标识编码 与 智能优化器规则 协同工作,系统性地解决了这些问题。以下我们将逐一展开其设计实现。
01 混合调度器
为解决 Pipeline 执行线程在网络 IO 场景下易被阻塞的问题,我们重构了 Doris 的 Pipeline 执行框架,引入了混合任务调度器(HybridTaskScheduler),从调度层面分离阻塞与非阻塞任务,显著降低了 IO 等待对执行效率的影响。其核心设计如下图所示:

具体实现上,原有统一的 TaskScheduler 被拆分为两类调度器,共同构成新的 HybridTaskScheduler:
- NonBlockingScheduler:专门调度非阻塞型任务(如纯计算操作)。调度器线程数量跟 CPU 核数相等。能够确保充分利用 CPU 资源。
- BlockingScheduler:用于调度可能阻塞的任务,如涉及磁盘 IO、网络 IO 等操作。该调度器线程数可动态调整,默认为 CPU 核数的两倍,以更好地容纳 IO 等待。
通过将任务按是否阻塞分类调度,系统有效避免了阻塞型任务对计算密集型任务的资源抢占。例如,TopN 查询第二阶段中的 Materialization Node 会被自动提交至 BlockingScheduler 执行,从而大幅减少 IO 阻塞对全局 Pipeline 执行线程的占用。
02 全局 ID 编码与资源管控
上文提到的 __DORIS_ROWID_COL__用于在第二阶段精确定位数据行,其编码设计兼顾了效率、跨格式一致性与资源管控。编码格式如下:
go
编码格式: [version:uint8] + [backend_id:uint64] + [file_id:uint32] + [row_id:uint32]-
version:标识编码格式版本,用于后续扩展与兼容。
-
backend_id:BE 节点 ID。该字段实现了精准的 RPC 定向------第二阶段请求可直接发送至对应节点,避免广播开销。同时,接收请求的节点会将数据读取任务提交至该查询所属的 Workload Group,从而确保资源隔离与统一管控。
-
file_id:系统为查询涉及到的每个文件生成唯一 ID,并在内存中维护 ID 到实际文件路径的映射。通过唯一 ID 可以减少第二阶段发送文件信息的请求大小,减少网络资源开销。
- 对于内表,文件名编码为:
tabet_id-rowset_id-segment_id - 对于 Parquet/ORC,文件名编码为:
filename-rowgroup_id
- 对于内表,文件名编码为:
-
row_id :用于标识数据在对应文件中的行号。同时,针对 OUTER JOIN 等可能会生成 NULL 值的场景,
row_id可以编码为 NULL,从而在第二阶段直接跳过请求,进一步提升效率。
03 全局延迟物化算法
为系统支持两阶段数据访问,Doris 优化器引入了全新的全局延迟物化算法 。该算法在编译阶段自动识别可延迟读取的列,从而在保证语义正确的前提下,最大限度减少第一阶段的数据扫描量。其执行流程可概括如下:
- 列集合划分:优化器将需要访问的列分为关键列集 K 和 延迟列集 D。K 列是在第一阶段需要读取的列,D 列是需要在第二阶段延迟读取的列。
- 自顶向下遍历:算法自顶向下遍历执行计划数的每个算子,将需要参与计算的列(如条件过滤列,Join 列等)加入到 K 集合中,其余列加入到 D 集合中。
- 字段转换:如遇到投影节点(Projection Operator)或集合操作节点(Set Operator)等产生字段变化的节点,则会将 K 中相应的字段转换成下层节点的字段。
- 结果推导:最终推导出 Scan 节点需读取的 K 集合,以及上游各算子对应的 D 集合。
以如下执行计划片段为例:
scss
FILTER(x > 10) --> PROJECT(a+b as x) --> SCAN(T)FILTER节点依赖列x,因此将x加入 K。PROJECT节点将x映射为底层表达式a + b,因此从 K 中移除x,并加入a和b。- 最终传递至
SCAN的 K 集合为{a, b},即仅需在第一阶段读取列a与b。
该算法在语法树层面实现了列读取的智能推迟,为高效的两阶段执行奠定了编译基础。
结束语
TopN 优化极大地强化了从海量数据中高效提取核心信息的能力,可广泛应用于实时排行榜、热点分析、销量统计、告警排序等高价值业务场景。
在方案设计过程中,我们也研究了业界其他系统的实现思路。以 DuckDB 为例,其在处理单表 TopN 时,会将其转换为一个特殊的semi Join 操作:左节点去扫描整表,右节点在扫描排序列后取出其 TopN 行,并且会借助 Runtime Filter 减少左表扫描数据量。该方案的优势在于复用了成熟的 Join 框架,但在某些场景下------例如排序列不是主键,或面对 Parquet 等格式的 Row Group 时------过滤效率可能受到影响,适用性存在一定边界。
未来我们计划进一步进行深度开发,包括:
- 集合运算(UNION/EXCEPT/INTERSECT)等复杂算子的 TopN 支持。
- 动态自适应物化阈值调整。
我们将持续追踪数据查询领域的前沿技术,并不断探索其在真实业务场景中的落地实践,致力于为用户提供持续领先的查询性能体验。
"秀干终成栋,精钢不作钩", 在"极致性能"的探索路上,Apache Doris 永不止步。