摘要
提示调整(Prompt Tuning)是一种针对特定任务的学习提示向量的调节,已成为一种数据高效和参数高效的方法,用于使大型预训练的视觉语言模型适应多个下游任务。然而,现有的方法通常是从头开始独立地学习每个任务的提示向量,从而无法利用不同视觉语言任务之间丰富的可共享知识。在本文中,我们提出了多任务视觉语言提示调优(MVLPT),它将跨任务知识融入到视觉语言模型的提示调优中。具体来说,(i)我们证明了从多个源任务中学习单个可转移提示以初始化每个目标任务的提示的有效性;(ii)我们证明了许多目标任务可以通过共享提示向量而相互受益,因此可以通过多任务提示调优来共同学习。我们使用文本提示调优、视觉提示调优和统一视觉语言提示调优三种具有代表性的提示调优方法对所提出的MVLPT进行了基准测试。20个视觉任务的结果表明,所提出的方法优于所有单任务基线提示调优方法,在少量的ELEVATER基准和跨任务泛化基准上设置了最新的技术。为了了解跨任务知识最有效的地方,我们还对每种提示调整方法的400种组合的20个视觉任务进行了大规模的任务可转移性研究。结果表明,对于每种提示调优方法,性能最好的MVLPT更倾向于不同的任务组合,并且许多任务可以相互受益,这取决于它们的视觉相似性和标签相似性。
1. 介绍
最近的大规模视觉语言模型,在自然语言监督下对各种各样的图像进行预训练(即CLIP 67, ALIGN38和Florence 96)在野外图像分类50,67和开放词汇检测29方面表现出较强的开放集识别能力。尽管具有令人印象深刻的zero-shot传输能力,但将这些大规模视觉语言模型应用于下游任务存在自身的挑战。由于巨大的参数大小和众所周知的过拟合问题,对整个模型进行微调通常是令人望而却步的。
这一趋势凸显了研究不同适应方法的必要性36,37,55,其中提示调谐48,105已被证明是最有效的策略之一。通常,Prompt Tuning只对模型输入空间(提示向量)中的每个任务的少量参数进行调整,同时保持预训练模型不变。它最初是在NLP社区中引入的48,55,61,最近在视觉语言模型中展示了优越的小样本自适应性能39,105,106。CoOp105和VPT39是两种具有代表性的视觉语言提示调优方法,前者使用文本提示,后者利用视觉提示。
然而,一方面,大部分视觉语言模型提示调优方法(即CoOp、VPT)侧重于独立学习每个下游任务的提示,在适应各种下游任务时未能纳入跨任务知识。另一方面,多任务学习在视觉方面有着丰富的文献8,80,84,102。将多任务提示调优应用于语言模型也呈现出令人印象深刻的few-shot4,58或zero-shot泛化能力13,71。这促使我们研究这样一个问题:视觉语言模型是否也能通过适应过程中的提示微调从多任务知识共享中受益?
为此,我们提出了多任务视觉语言提示调优(multitask visionlanguage prompt tuning, MVLPT),据我们所知,这是第一个将跨任务知识整合到视觉语言提示调优中的方法。MVLPT是一种在多个任务之间实现信息共享的简单而有效的方法。MVLPT包括两个阶段:多任务源提示初始化和多任务目标提示自适应。具体来说,多任务提示初始化首先从各种源任务中学习共享提示向量。然后,共享提示符可以初始化目标任务的提示符。为了适应目标任务,多任务提示自适应将把相关任务分组在一起,然后在所选组中执行多任务提示调优。我们注意到,我们也可以在设置组大小为1的情况下执行单任务适应。这个简单的方案可以通过多任务提示初始化将源任务的跨任务知识传递给目标任务,并通过多任务提示适应进一步利用目标任务内的可共享知识。
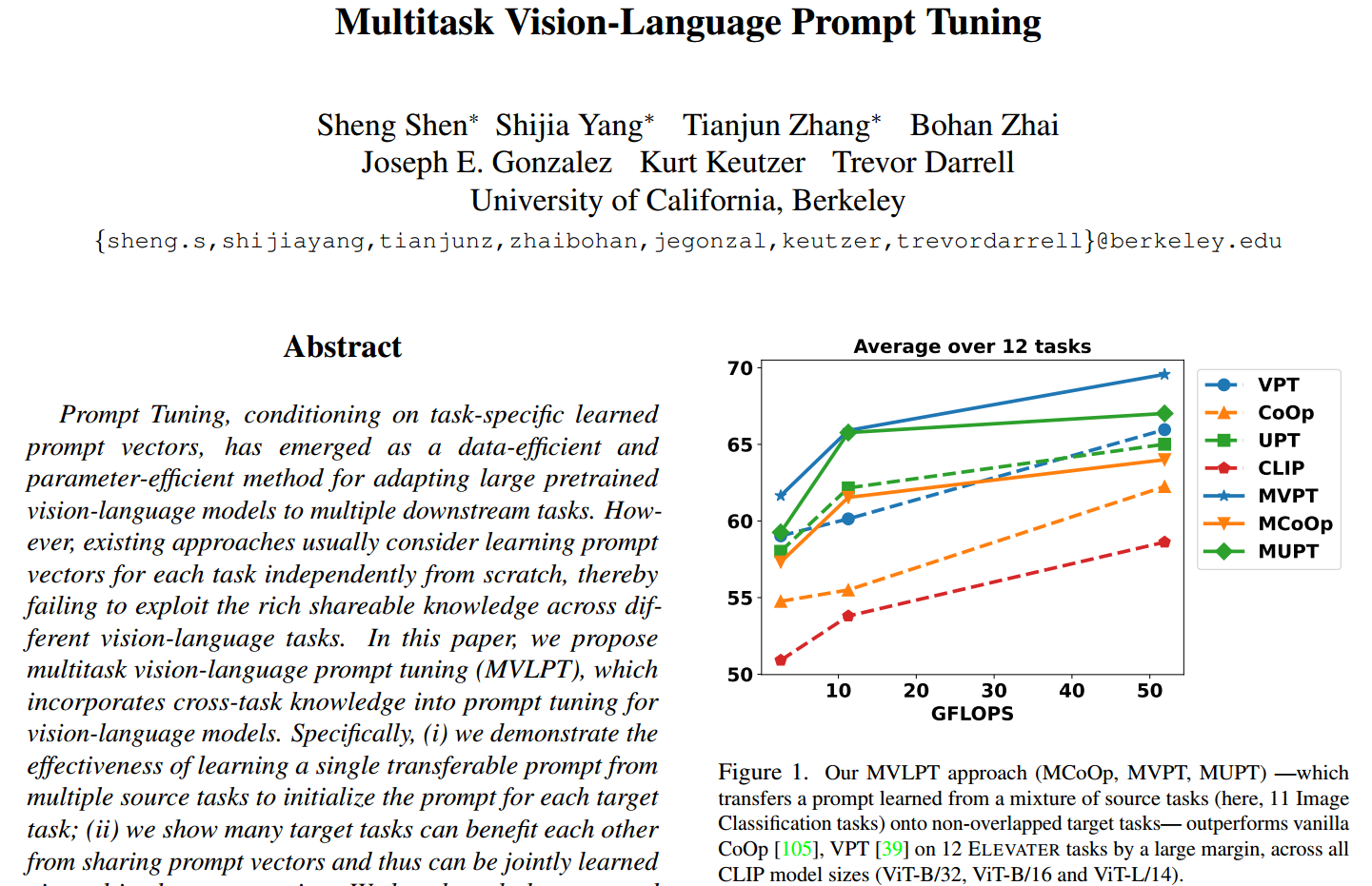
在第4.2节中,我们对MVLPT在小样本ELEVATER中的20个视觉任务进行了广泛的评估50。与CoOp105、VPT39和UPT(章节3.1)相比,MVLPT分别将基线提高了0.72%、1.73%和0.99%,并将新技术设置在20枪ELEVATER基准上。我们还证明了MVLPT的强泛化性,其中MVLPT在4.1节的跨任务泛化基准上分别比CoOp、VPT和UPT提高了1.73%、4.75%和4.53%,在4.3节的20个视觉任务和每种提示方法的400个组合中提高了学习任务的可转移性。综上所述,我们做出了以下贡献:
•我们提出了多任务视觉语言提示调优(MVLPT)框架,包括多任务提示初始化和多任务提示自适应,并论证了每个组件的有效性。
•我们严格研究了每种提示调整方法的400种组合的20种视觉任务的任务可转移性,以了解MVLPT何时最有效。
•我们系统地评估了建议的MVLPT在few-shot ELEVATER和跨任务泛化基准上的性能,从而在20-shot ELEVATER基准上设置了最先进的新技术。
2. 相关工作
视觉语言模型 11,101使用图像和文本编码将图像和文本对齐到一个联合嵌入空间,并使用损失函数进行对齐。传统上,模型是为图像和文本独立设计和学习的,只通过一个损失模块连接。图像使用手工描述符19,77或神经网络23,47进行编码,而文本可以使用预训练的词向量23,77或基于频率的特征19,47进行编码。为了使这些模式对齐,我们使用了度量学习23、多标签分类28,41和n-gram语言学习49。随着大规模预训练的兴起,视觉语言模型24、44、51-54、56、74、75、81、83、88、90、93、98现在可以联合学习两个编码器,并使用更大的神经网络(如2中多达80B个参数)和数据集。正如哲等人25所讨论的那样,最近视觉语言模型的成功主要归功于transformer85的发展。对比表征学习10,31,35,95和webscale训练数据集38,67,96。CLIP67是一种代表性的方法,它使用对比损失来训练两个基于神经网络的编码器来匹配图像-文本对。在消耗了4亿对数据后,CLIP显示了卓越的zero-shot图像识别能力。
Prompt Tuning 起源于NLP社区48,59,旨在提高大规模预训练语言模型的实际适用性7,18,68,72,100。目标NLP任务被重新表述为"填空"填空测试,该测试查询语言模型以预测"I enjoyed the movie. It was MASK"中的掩码标记。是MASK。为"积极"或"消极"进行情绪分类。关键的部分在于以模型熟悉的格式设计"语言表达器"(掩码令牌的标签)和下划线部分(称为提示符(模板))。人们致力于开发基于提示的学习方法,如手工提示73、提示挖掘和释义40、基于梯度的搜索76和自动提示生成26。由于离散提示被发现是次优的,并且对提示的选择很敏感61,103,最近的工作转向了学习连续提示学习方法48,55,60,87,104,其主要思想是将提示转化为一组连续向量,可以针对目标函数进行端到端优化,这也是与我们的研究最相关的。在计算机视觉中,提示学习是一个新兴的研究方向5,9,17,39,42,62,70,94,99,105,106。我们的研究重点是将跨任务知识纳入提示调整过程,这与以往的视觉语言提示研究不同。
多任务提示调优最近在NLP社区得到了广泛的研究。其中一行研究13,64,71,89,91在大量的、人工制作的、(数千)提示格式的下游任务上对预训练模型进行微调,并发现最终模型对未见过的NLP任务表现出强大的泛化能力。另一项研究探索了多任务连续提示调谐4。例如,ATTEMPT3和SPoT87将源提示传递到目标任务,只结合多任务学习进行提示初始化,而我们的方法同时探索了多任务初始化和自适应。此外,我们提出了一种不同的任务分组方法,并与4.3节的相关工作进行了比较。
3. 方法
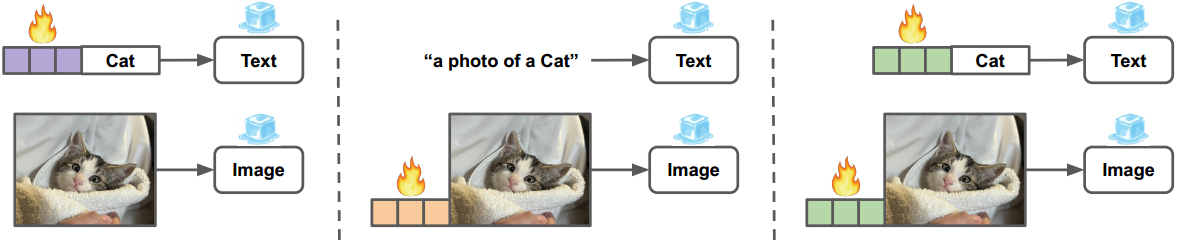
图3. The architecture of (a) CoOp (textual prompt tuning), (b) VPT (visual prompt tuning), and © UPT (unified prompt tuning).
我们首先回顾CLIP67,以及3.1节中用于视觉识别的文本、视觉和统一提示调优方法。然后,我们在第3.2节中介绍了我们提出的MVLPT学习的技术细节。
3.1. 准备知识
CLIP 67是一个同时训练图像编码器和文本编码器的模型,用于为图像-文本对创建相似的嵌入。它通过在预训练期间最小化对称对比损失来实现这一点,预训练可以预测一批图像-文本组合中的正样本:
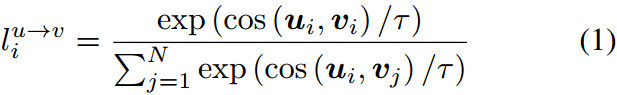
式中 u = ψ ( x ) ∈ R d u=\psi(x)\in R^d u=ψ(x)∈Rd,表示图像 x x x到 d d d维最终隐藏空间的投影; v = ϕ ( y ) ∈ R d v=\phi(y)\in R^d v=ϕ(y)∈Rd,表示文本 y y y的投影; c o s ( ⋅ , ⋅ ) cos(\cdot,\cdot) cos(⋅,⋅)为余弦相似度; τ \tau τ是一个可学习的温度值。在zero-shot预测中,CLIP取一张图像和一组目标类,为每个类构造一个固定的提示"a photo of a CLASS",并预测编码图像与提示集之间余弦相似度最高的类。
虽然"任务"的定义不明确,但我们借用了CLIP的定义。为了清楚起见,我们正式区分不同的任务:数据集 D D D上的K-way分类与不同数据集D '上的M-way分类是不同的任务,其中 K K K和 M M M是不同的。
文本提示调优 是一种用于使clipllike视觉语言模型适应下游任务的方法。这是一种比调整整个CLIP模型更有效的方法。CoOp105通过将提示符的上下文词替换为长度 n n n可调的可学习向量 P ∈ R d × n P\in R^{d\times n} P∈Rd×n提出了该方法。将文本输入修改为:
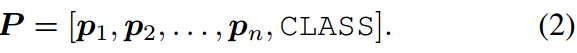
此修改允许冻结图像和文本编码器,同时仅使用特定于任务的目标函数优化 P P P。
CoCoOp106是一种较新的方法,它通过添加网络来获取输入条件令牌,性能优于CoOp。然而,它在训练中效率(训练速度和GPU内存)的局限性使其难以作为多任务基线进行比较,因此我们只在4.1节中包含它。
视觉提示调优 39类似于文本提示调优,但针对的是视觉模型。它将一个可调谐向量 V ∈ R d × n V\in R^{d\times n} V∈Rd×n添加到模型中每个第 i i i层transformer的输入。修改后的输入包括分类令牌 c i = C L S c^i =CLS ci=CLS,image tokens q 1 , q 2 , . . . , q m , V q_1,q_2,...,q_m,V q1,q2,...,qm,V:
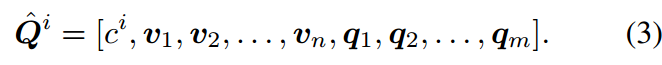
在微调过程中,图像编码器被冻结,只有视觉提示被优化。
统一提示调谐 (Unified Prompt Tuning, UPT)97是一种适应VL模型的方法。具体来说,UPT没有为文本和视觉编码器引入两组孤立的特定于模态的提示(即,Eq.(2)中的P和Eq.(3)中的V),而是考虑学习一组视觉语言模态无关的提示 来调整VL模型。UPT定义了一组长度为n的可学习提示符 U = U T , U V ∈ R d × n U=U_T,U_V\in R^{d\times n} U=UT,UV∈Rd×n,其中 U T ∈ R d × n T , U V ∈ R d × n V U_T\in R^{d\times n_T},U_V\in R^{d\times n_V} UT∈Rd×nT,UV∈Rd×nV分别作为文本提示符和视觉提示符。一个轻量级的Transformer层 θ \theta θ用于在将视觉语言提示符添加到文本和视觉编码器之前转换和交互视觉语言提示符 U U U:
3.2. 多任务视觉语言提示调整
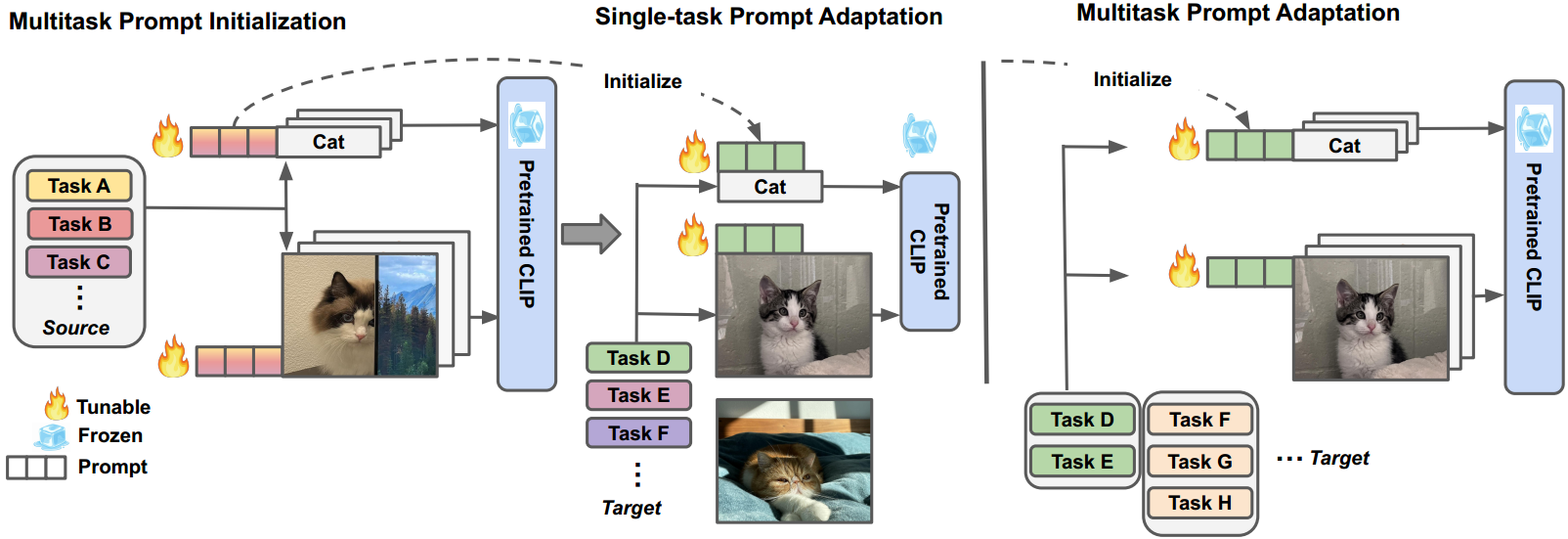
图2。MVLPT中多任务提示初始化(左)和多任务提示适应(右)方法的说明。左图:我们在各种源任务上学习单个通用源提示向量,然后将其用于初始化每个单个目标任务的提示。右:使用源提示向量进行初始化后。我们将相关的目标任务分组在一起,并在每个组中执行多任务提示调优。注意,将一个任务分组意味着单任务适应。(详见第3节)。
我们提出的框架MVLPT主要包括两个阶段,如图2所示,多任务源提示初始化和多任务目标提示自适应。
多任务提示初始化 。在此阶段,通过多任务提示调优,对所有源任务的可共享提示进行联合预训练。请注意,我们只使用来自源任务的少量训练集来执行预训练,而不是在NLP社区中使用整个集4,87。
多任务快速适应 。在这个阶段,我们将可共享的源代码提示符传递给目标任务。对于单任务目标提示自适应 ,我们直接使用学习到的源提示初始化目标提示,并利用每个任务上的常规任务损失(即交叉熵损失)进行优化 。对于多任务提示适应,我们首先将相关任务分组在一起,然后在来自同一多任务初始化源提示的选定组内执行多任务提示调优。分组策略将在第4.3节中进一步讨论。任务分组的理论依据见附录。
4. 实验
我们的方法主要在以下三个问题设置中进行评估:1)衡量多任务提示初始化效果的跨任务泛化(第4.1节);2)显示多任务提示适应有效性的小样本提升(第4.2节);3) zero-shot任务可转移性(第4.3节),基于升降机中的20个视觉任务。
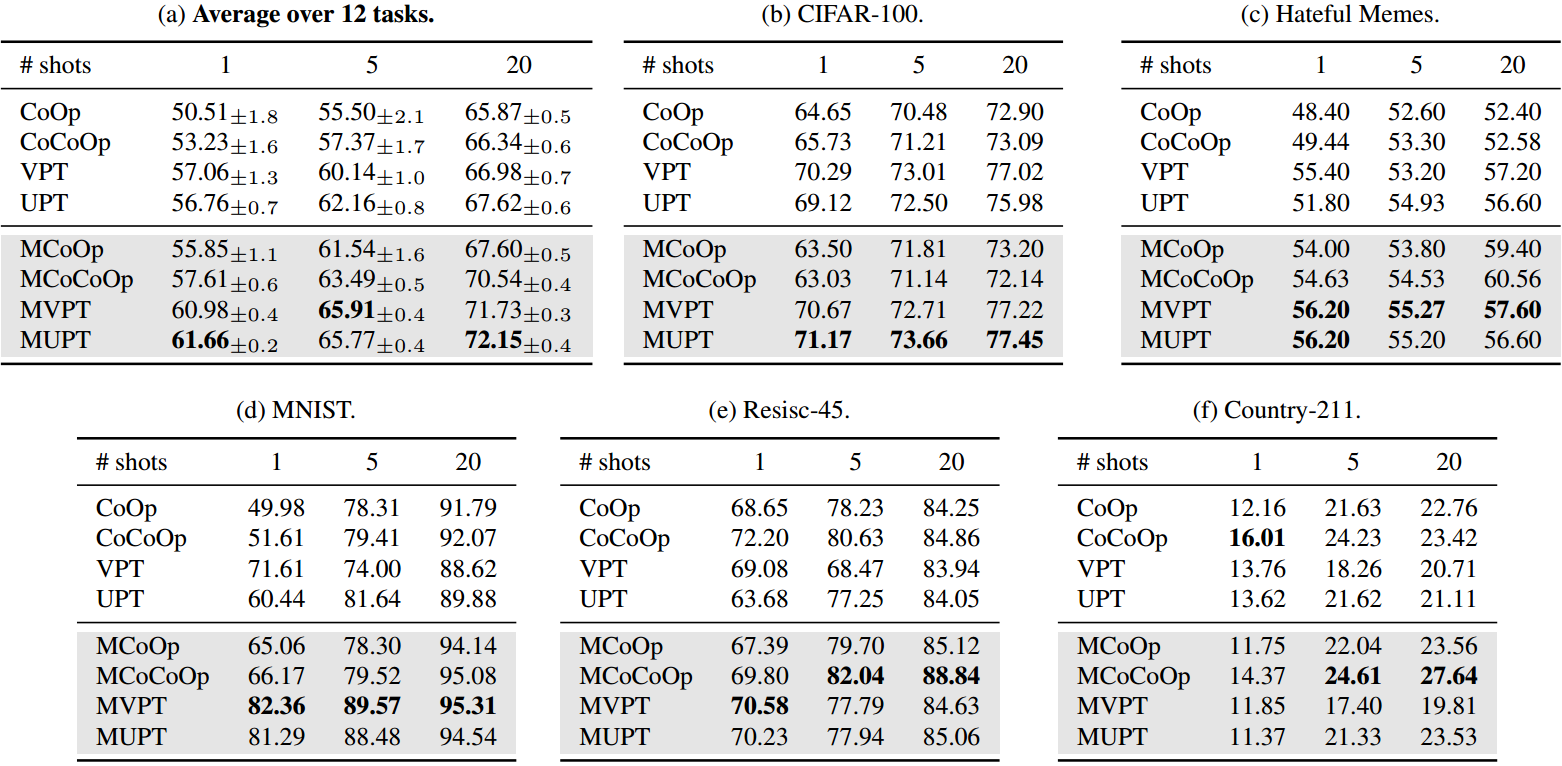
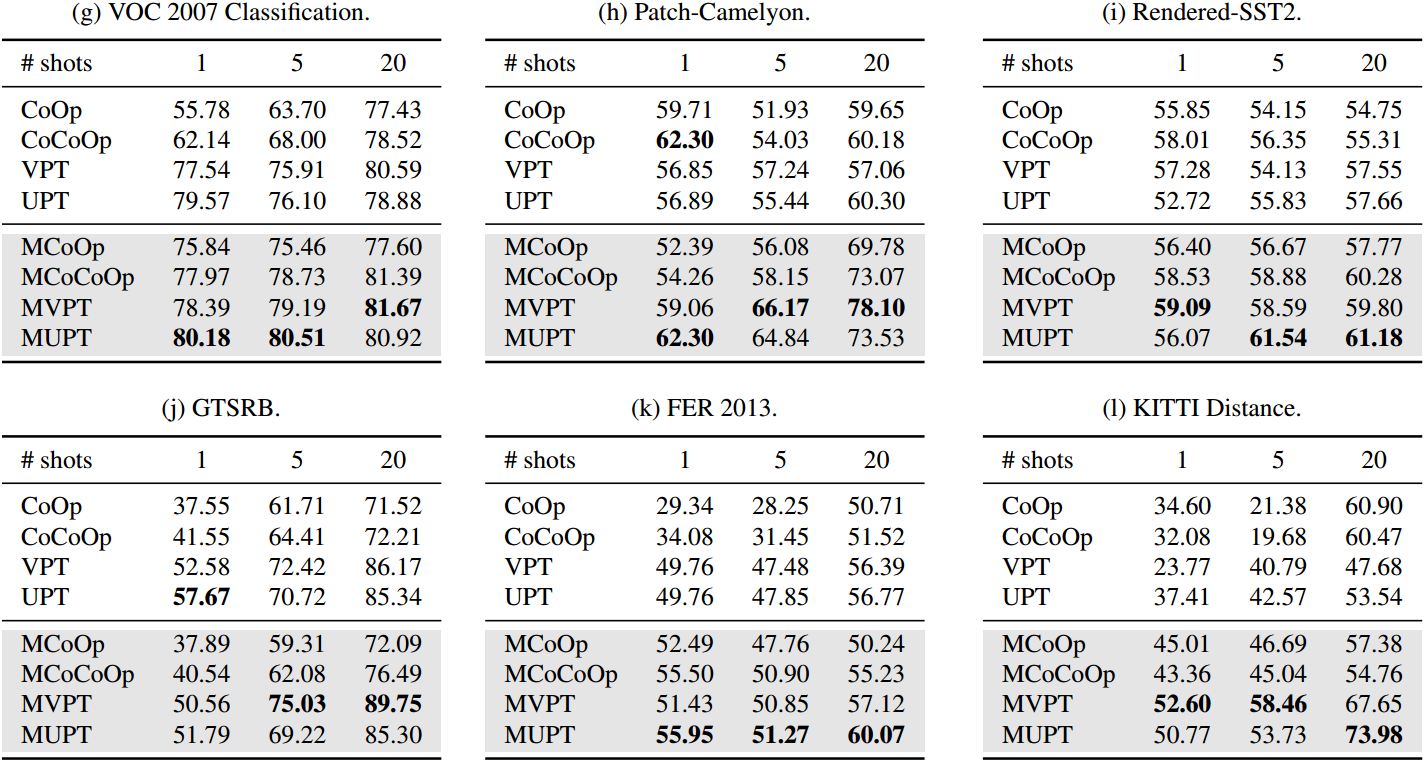
表1。CoOp、CoOp、VPT、UPT和我们的MCoCoOp、MCoOp、MVPT和MUPT在跨任务泛化设置中的比较。结果有力地证明了多任务提示初始化的强泛化性。具体来说,在单个任务适应到12个目标任务之前,每个多任务变体从11个源任务中学习共享提示向量。镜头数(1,5,20)表示我们用于多任务提示初始化和单任务适应的镜头数。例如,1-shot意味着我们从每个源任务中使用1-shot进行多任务提示初始化,并将其用于1-shot学习以适应每个目标任务。黑体字表示该设置中的最佳性能。注意,我们将CIFAR-10包含在平均任务表中,CIFAR-10的性能在附录中。
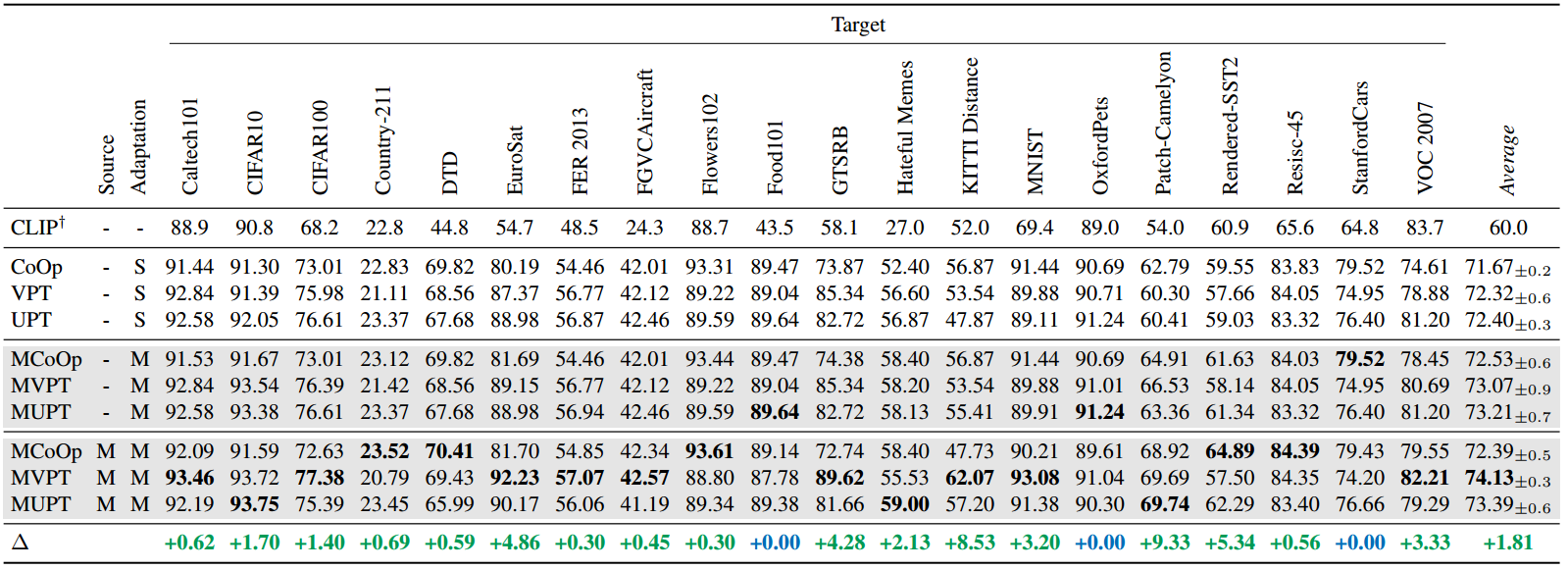
表2。小样本升降机提示学习方法的比较。每种情况下的小样本次数都设置为20次,除了zero-shot CLIP。结果表明,多任务提示初始化具有显著的通用性。†表示ELEVATER的零拍CLIP结果50,"Source"表示提示初始化源,其中"-"表示随机初始化,"M"表示使用所有20个ELEVATER任务进行提示初始化。"Adaptation"为目标任务提示适应方法,其中"S"为单目标任务提示适应,即每个目标任务将被独立适应;"M"为多任务提示适应,即某些任务(根据第4.3节的结果选择)将被一起学习。显然,MVLPT比单目标任务提示适应具有更好的可转移性。∆表示相对于各自基线方法的最佳m变量增益。
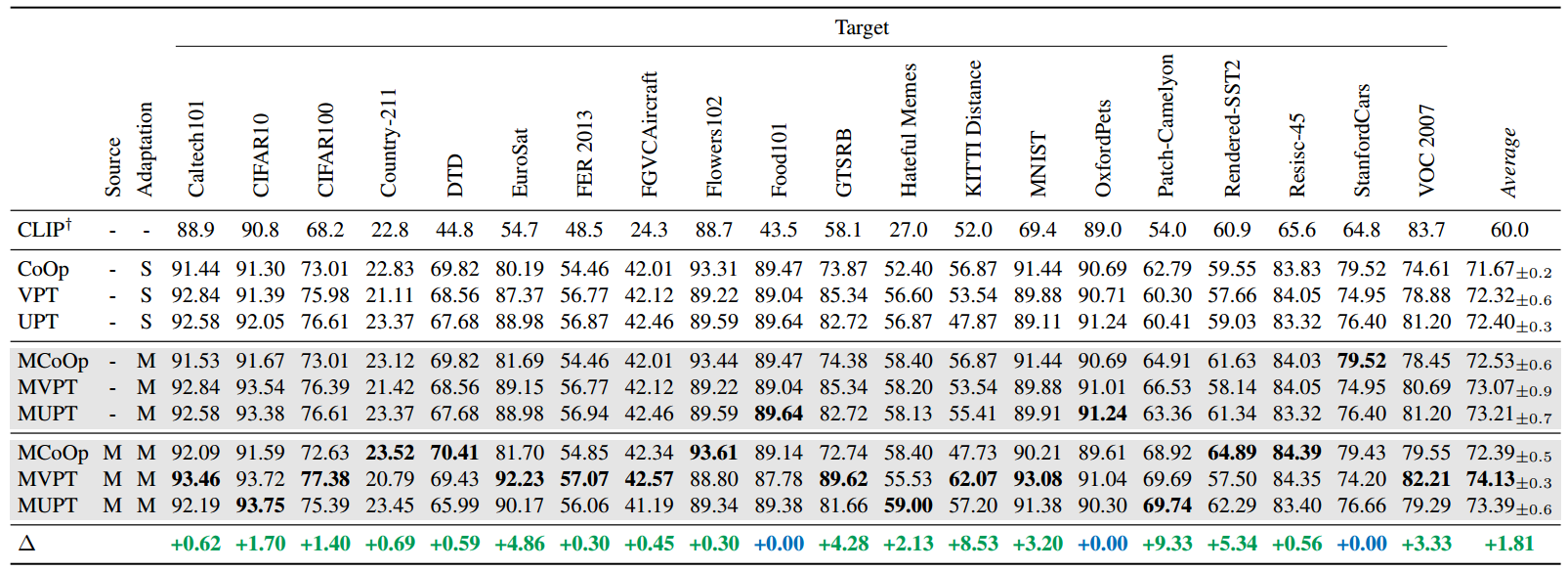
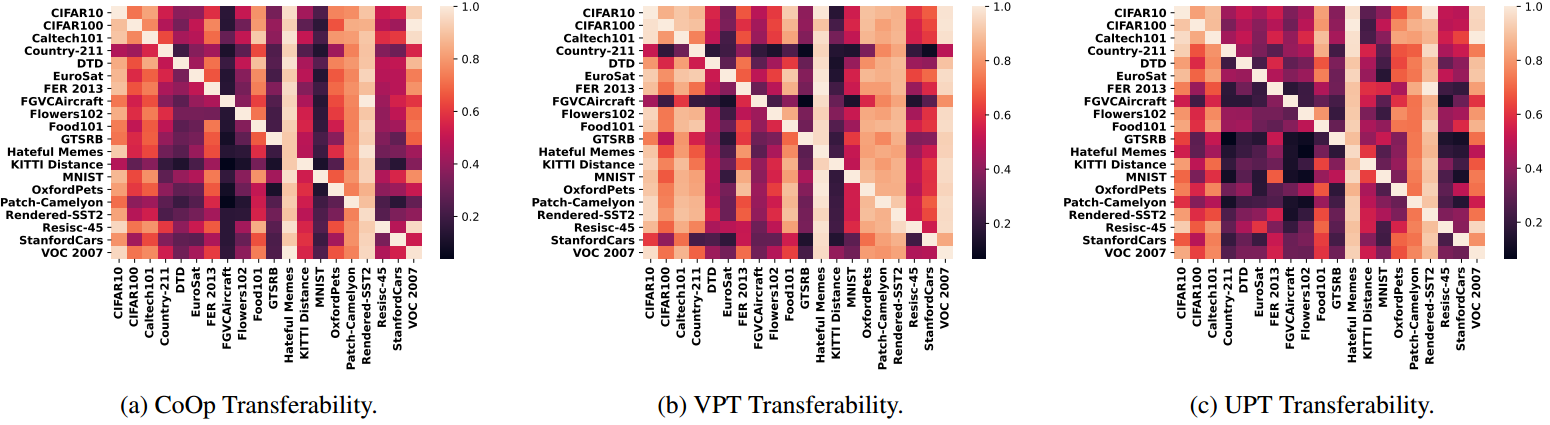
图4。我们的任务可转移性结果的热图。每个单元格显示从关联源任务(行)传输到关联目标任务(列)的提示符在目标任务上的相对性能。
6. 结论
在本文中,我们提出了多任务视觉语言提示调整(MVLPT)。我们证明了与基线提示学习方法相比,MVLPT具有较强的泛化性和小样本学习性能。性能最高的MVLPT在ELEVATER基准上设定了最新的最先进性能。我们还研究了20种视觉任务的任务可转移性,并为多任务提示学习提供了指导。
参考资料
论文下载(WACV CCF C)
https://arxiv.org/abs/2211.11720