自然语言处理基本概念
所有学习循环神经网络的人都是看这一篇博客长大的:
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
python
import jieba
import torch
from torch import nn
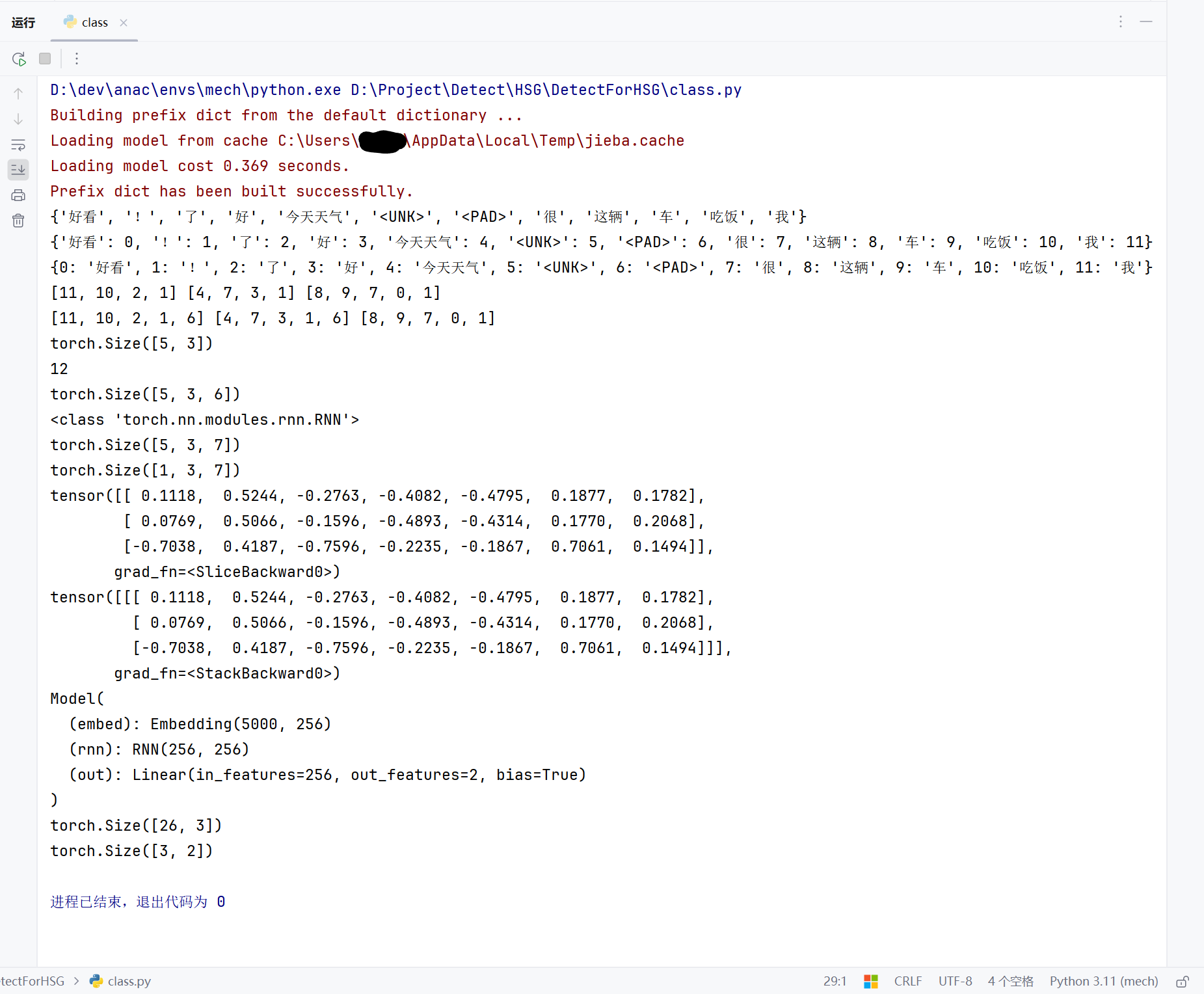
s1 = "我吃饭了!"
s2 = "今天天气很好!"
s3 = "这辆车很好看!"
jieba.lcut(s3)
words = {word for sentence in [s1, s2, s3] for word in jieba.lcut(sentence)}
words.add("<UNK>")
words.add("<PAD>")
print(words)
word2idx = {word: idx for idx, word in enumerate(words)}
idx2word = {idx: word for word, idx in word2idx.items()}
print(word2idx)
print(idx2word)
idx1 = [word2idx.get(word, word2idx.get("<UNK>")) for word in jieba.lcut(s1)]
idx2 = [word2idx.get(word, word2idx.get("<UNK>")) for word in jieba.lcut(s2)]
idx3 = [word2idx.get(word, word2idx.get("<UNK>")) for word in jieba.lcut(s3)]
print(idx1,idx2,idx3)
# 补 1 个 pad
idx1 += [word2idx.get("<PAD>")]
idx2 += [word2idx.get("<PAD>")]
print(idx1,idx2,idx3)
# 转张量
X = torch.tensor(data=[idx1, idx2, idx3], dtype=torch.long).T
# [seq_len, batch_size]
print(X.shape)
# word embedding
embed = nn.Embedding(num_embeddings=len(word2idx), embedding_dim=6)
print(len(word2idx))
# [3, 5, 12] --> [3, 5, 6]
# [batch_size, seq_len, embedding_dim]
print(embed(X).shape)
# [N, C, H, W]
# [N, Seq_len, Embedding_dim]
print(nn.RNN)
# $h_t = \tanh(x_t W_{ih}^T + b_{ih} + h_{t-1}W_{hh}^T + b_{hh})$
rnn = nn.RNN(input_size=6, hidden_size=7, batch_first=False)
X1 = embed(X)
out, hn = rnn(X1)
# 每一步的输出
print(out.shape)
# 最后一步的输出
print(hn.shape)
print(out[-1, :, :])
print(hn)
class Model(nn.Module):
def __init__(self, dict_len=5000, embedding_dim=256, n_classes=2):
super().__init__()
# 嵌入:词向量
self.embed = nn.Embedding(num_embeddings=dict_len,
embedding_dim=embedding_dim)
# 循环神经网络提取特征
self.rnn = nn.RNN(input_size=embedding_dim,
hidden_size=embedding_dim)
# 转换输出
self.out = nn.Linear(in_features=embedding_dim,
out_features=n_classes)
def forward(self, x):
# [seq_len, batch_size] --> [seq_len, batch_size, embedding_dim]
x = self.embed(x)
# out: [seq_len, batch_size, embedding_dim]
# hn: [1, batch_size, embedding_dim]
out, hn = self.rnn(x)
# [1, batch_size, embedding_dim] --> [batch_size, embedding_dim]
x = torch.squeeze(input=hn, dim=0)
# [batch_size, embedding_dim] --> [batch_size, n_classes]
x = self.out(x)
return x
model = Model(dict_len=5000, embedding_dim=256, n_classes=2)
print(model)
X = torch.randint(low=0, high=5000, size=(26, 3), dtype=torch.long)
# [seq_len, batch_size]
print(X.shape)
# [batch_size, n_classes]
print(model(X).shape)