阿里云人工智能平台(PAI)自研开源的视频生成项目EasyAnimate正式发布v3版本:
-
支持 图片(可配合文字) 生成视频
-
支持 上传两张图片作为起止画面 生成视频
-
最大支持720p(960*960分辨率) 144帧视频生成
-
最低支持 12G 显存使用(3060 12G可用)
-
视频续写生成无限时长视频
项目主页:https://easyanimate.github.io
技术报告:https://arxiv.org/abs/2405.18991
PAI平台上快速体验:阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台
效果展示
EasyAnimate-v3

上图展示图生视频和文生视频的输入参考图、Prompt(提示词)及生成结果。
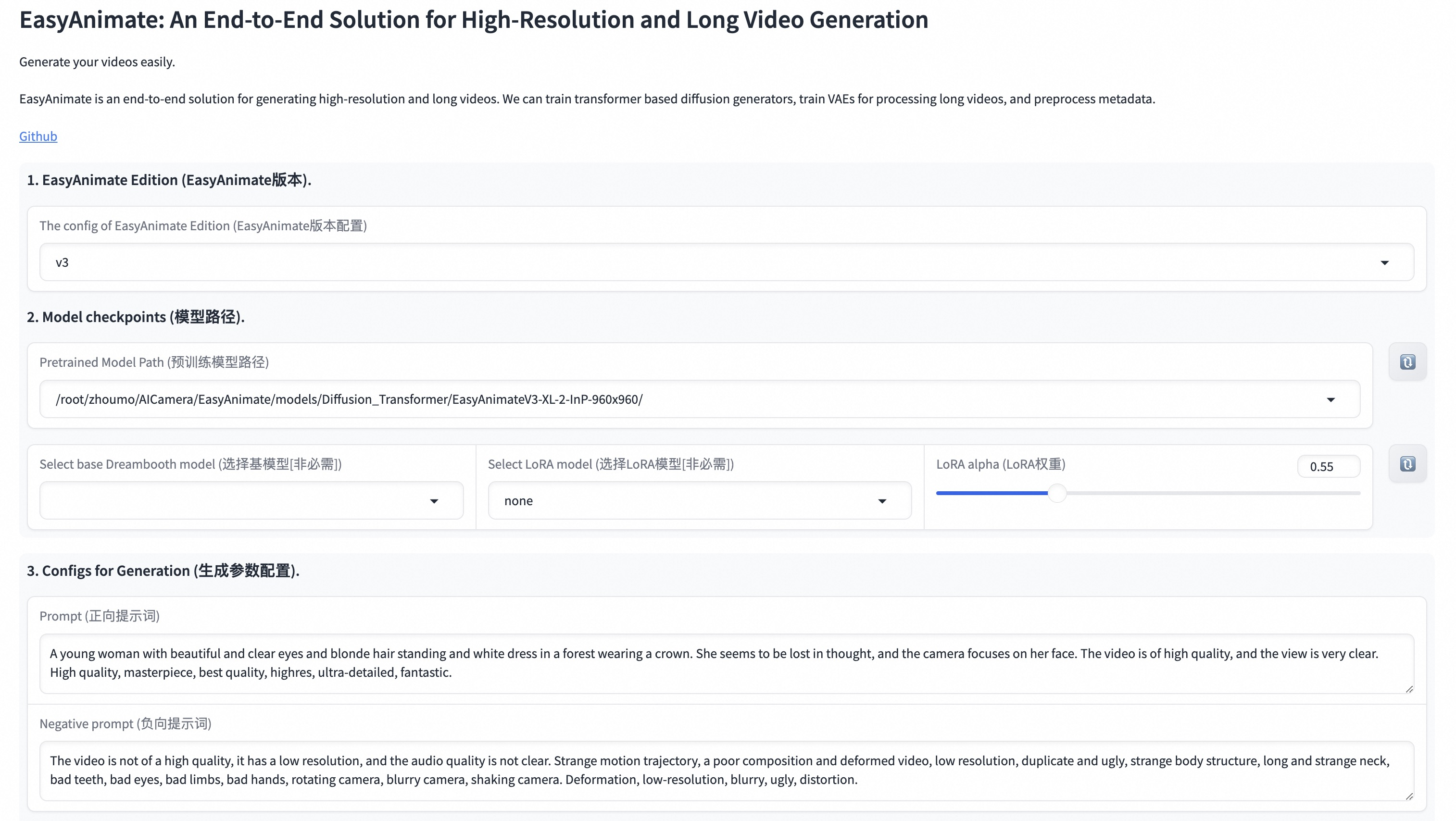
项目提供基于Gradio搭建的WebUI界面,上手非常方便。
模型结构
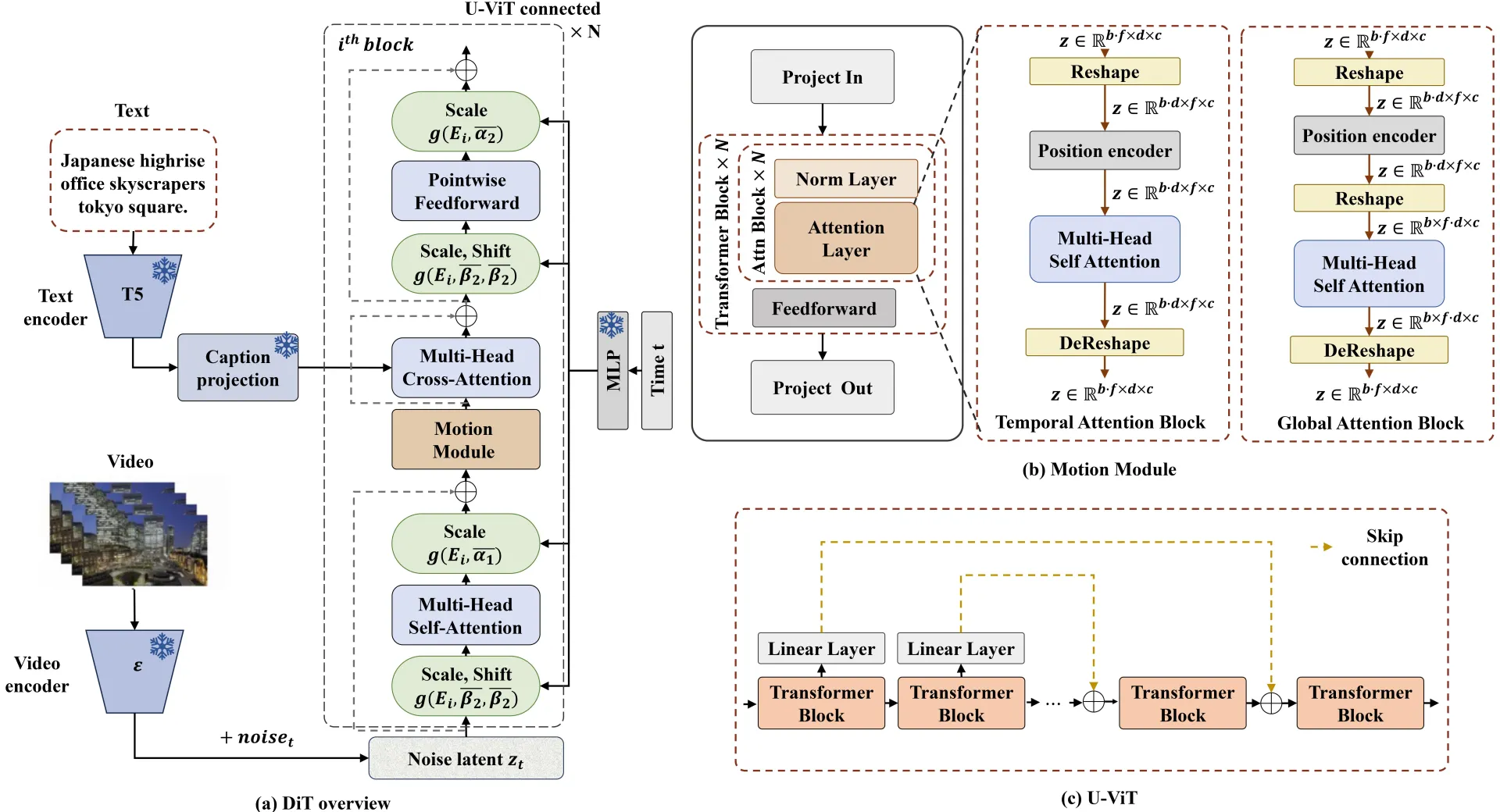
-
EasyAnimate-v3采用**Diffusion Transformer(DiT)**结构,T5作为Text Encoder,整体框架如上图a所示。
-
图b是我们设计的混合运动模块(Hybrid Motion Module):
-
偶数层:时间序列上集成注意力机制,模型学习时序信息。
-
奇数层:全局序列(空间+时间)上进行全局注意力学习(Global Attention),提高模型全局感受野。
-
参考图c的U-ViT,为了提高训练稳定性,我们引入跳连接结构(Skip Connection),引入的浅层特征进一步优化深层特征,并且在每个Skip Connection额外增加一个零初始化(Zero Initialize)的全连接层(Linear Layer),使其可以作为一个可插入模块应用到已经训练好的DiT结构中。
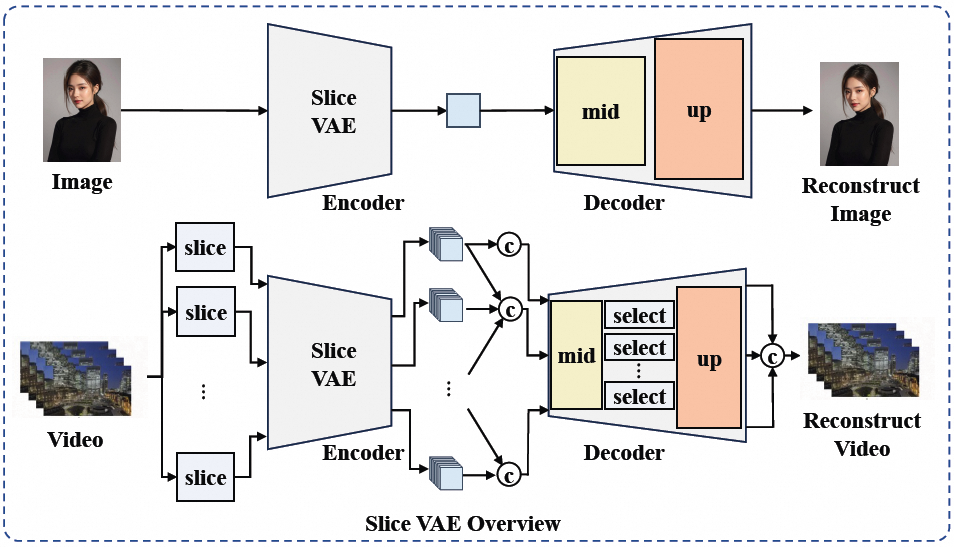
EasyAnimate-v3中的Slice VAE(Variational Auto Encoder)结构如上,不仅有1/4的时序压缩率,还支持对不同输入使用不同的处理策略:
-
输入视频帧时:在高宽与时间轴上进行压缩,例如当输入为512512分辨率 8帧的视频帧时,将其压缩为64642的Latent向量。
-
输入图片时:则仅仅在高宽上进行压缩,列入当输入为512512分辨率的图片时,将其压缩为6464*1的Latent向量。
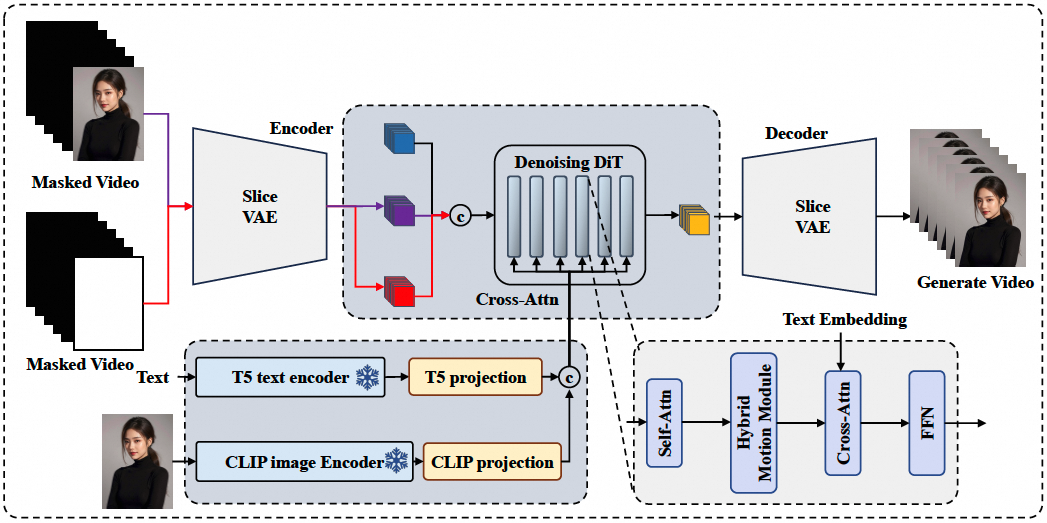
EasyAnimate-v3版本新增的图生视频Pipeline如上图所示,我们提供视觉-文本双流的信息注入:
-
需要重建的部分和重建的参考图分别通过Slice VAE进行编码(上图黑色的部分代表需要重建的部分,白色的部分代表首图),然后和随机初始化的Latent进行Concat合并。假设我们期待生成一个384672分辨率144帧的视频,此时的初始Latent就是4x36x48x84,需要重建的部分和重建的参考图编码后也是4x36x48x84,三个向量Concat合并到一起后便是12x36x48x84,传入DiT模型中进行噪声预测。
-
文本提示词这里,我们使用CLIP Image Encoder对输入图片编码后,使用一个CLIP Projection进行映射,然后将结果与T5编码后的文本进行Concat合并,二者在DiT中进行Cross Attention。