6 月 24 日,我在北美湾区参与了一场线下的 Apache DataFusion 聚会活动。
其实我是 6 月 21 日才到的旧金山,6 月 18 日才发现湾区有这样一场线下活动。不过或许得益于我在今年在 DataFusion 做过几次贡献,GreptimeDB 是 DataFusion 在行业顶级的应用标杆,会议组织方很干脆的就增加了一个 Speaker 席位,让我能够做在聚会上做题为《Boosting a Time-Series Database With Apache DataFusion》的演讲。
会议风格
本次 Meetup 一共报名 80 人,实际到场超过 50 人,绝对算是小型 Meetup 里的大型聚会了。现场是一位联合主办人的办公室,堪堪容纳所有人或站或坐待在室内。

我印象最深的是海外 Meetup 更加注重 Get Together 的风格,与国内 Meetup 基本是讲师从头讲到尾的风格的差异。
一般来说,国内的 Meetup 一个主题可以讲 30-40 分钟,4-6 名讲师讲完一个下午也就结束了。往往参与者也不怎么听完主题,而是逮到相关的到场专家,或者听到感性的主题以后,就拉着专家或讲师直接另开小会去了。
我刚报上名参加湾区 DataFusion Meetup 的时候,得到的消息是演讲时长 15-20 分钟,临了又改成 12-15 分钟。基本上一共六名讲师,从六点开讲,到七点半就完全讲完了。剩下的时间留给现场的观众自由交流,当然也有人拉着看对眼的与会者出去开小会,但是总体所有人都听完了所有主题,并且也还毫不疲倦。
这是国内不少活动最近有在参考的一个趋势。不管是年初 OSPO Summit 的 unconforence 环节,还是接下来几场 Apache 软件基金会的国内会议筹备的形式,都更加注重 Get Together 与会者自由交流,而不再是发布会形式的讲师从头讲到尾。
此外,海外的组织者对这样的小型聚会明显更有热情,他们有 lu.ma 和 meetup.com 等等丰富的宣传渠道,也乐于在湾区举办各种会议交流前沿进展。这点是国内近几年来声音比较弱的方面。
活动预告
在进入演讲内容回顾之前,先预告将在未来两周举办的两场 Apache 生态线下活动。
第一场是在 7 月 21 日下午杭州蚂蚁 A 空间举办的 Apache DataFusion Meetup 活动。GreptimeDB 核心工程师,同时也是 DataFusion 社群 PMC 成员夏锐航将会做深入的技术分享;蚂蚁集团工程师和 eBay 工程师也都将分享他们基于 DataFusion 构建出来的多样系统,参与 DataFusion 社群的故事,以及对 DataFusion 未来的看法。
欢迎点击链接( https://www.huodongxing.com/event/5761971909400?td=1965290734055 )报名,或扫描以下二维码报名。
第二场从 7 月 26 日开始持续 7 月 28 日。Apache 软件基金会年度活动 Community Over Code Asia 2024 今年也将在杭州举办。我将作为 Community 分会场的出品人参与活动并做演讲。GreptimeDB 的核心工程师,同时也是 OpenDAL 社群 Committer 的徐文康也将在 IoT 分会场上做技术分享。GreptimeDB 在现场另有展位介绍,我会全程在场(たぶん)。
欢迎通过这个链接( https://asia.communityovercode.org/zh/ )报名。
演讲内容
聚会上一共有八名讲师做了六个主题演讲,分别是:
-
LanceDB 的 CEO Chang She 分享了他们利用 DataFusion 实现向量计算的实践;
-
Cube.js 的 CTO Pavel Tiuvov 分享了基于 DataFusion 实现的查询缓存层;
-
DataFusion 的现任 PMC Chair Andrew Lamb 介绍了社群发展的近况和未来展望;
-
Denormalized 的创始人 Matt Green 分享了使用 DataFusion 实现流计算引擎的实践;
-
DataFusion 的原作者 Andy Grove 和他的同事分享了在 Apple 实现了 DataFusion Comet 做 Spark 查询加速实践;
-
我介绍了 GreptimeDB 使用 DataFusion 和整个 FADOP 技术栈快速实现了一个高完成度的时序数据库的实践。
出于演讲时间限制,我的核心内容浓缩在了 GreptimeDB[1] 如何使用和定制化 DataFusion[2] 的实现上:
- 每位分享嘉宾介绍的实践,都包含了在 DataFusion 这个执行引擎库之上实现的一个分布式计算框架。虽然 DataFusion 自己有一个子项目 Ballista 某种程度完成了这项任务,但是无论是成熟度还是它为大数据生态做的许多特化设计,都不适合上面这些使用场景的具体需求。

GreptimeDB 的分布式计算框架
- GreptimeDB 从入口处直接重新实现的整套 PromQL 查询支持。DataFusion 主要支持的是 SQL 查询的解析、优化和执行,但是 GreptimeDB 为兼容 Prometheus 的生态,借助 DataFusion 封装的框架,将 PromQL 当做一种新的方言,通过实现 DataFusion 高度插件化的接口集成到了 DataFusion 的执行引擎当中。
值得一提的是,GreptimeDB 将 promql-parser[3] 完全开源之后,已经成为所有想要实现 Prometheus 接口的 Rust 项目的统一选择。

GreptimeDB 实现了超过 80% 的 PromQL 接口
- 另一项 GreptimeDB 突出的技术实现,是核心工程师钟镇炽主导开发的一个高度可扩展的索引框架。GreptimeDB 在此之上实现了 MinMax 索引和倒排索引的能力,并将在 0.9 版本里推出针对文本列的全文索引。我们计划将这一框架回馈给 DataFusion 上游,共同演进丰富查询引擎的共享代码。

GreptimeDB 强大的索引框架
- 演讲之初,我介绍了 GreptimeDB 在时序数据领域上的关键理念创新:时序数据不仅仅是指标(Metrics),同样带有时间戳和上下文信息的数据,例如事件(Events)、日志(Logs)和追踪(Traces),都可以统一在一个时序数据库下进行处理。不仅能够同时优化负载和性能,降低成本,还能通过联合分析获得更加丰富的数据洞察。
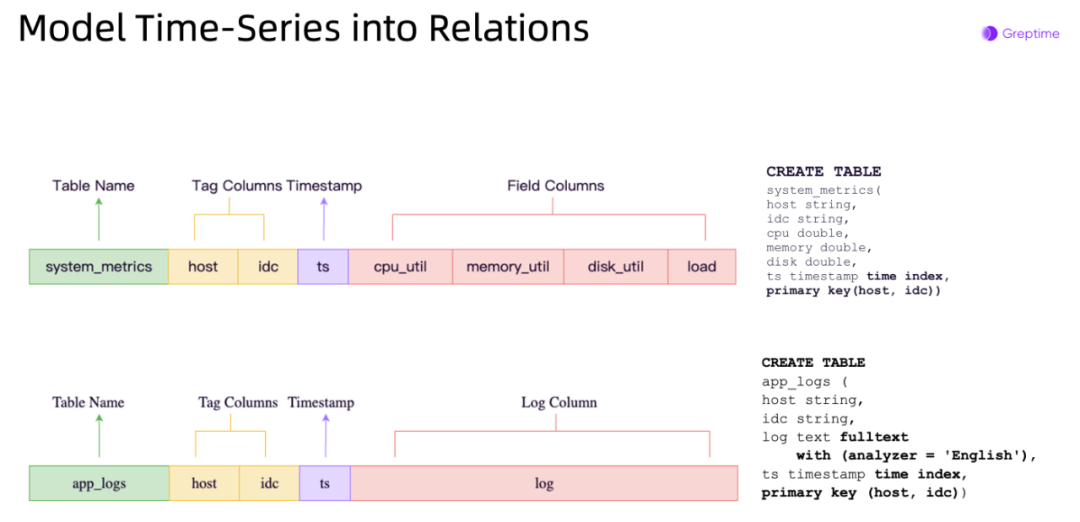
统一 MELT 的时序数据处理
- 最后,我实际超时了大概两分钟介绍了 GreptimeDB 得以快速实现一个高完成度时序数据库所依赖的技术栈:

FADOP Data Infra 技术栈
其中 FAD 都是原先 Apache Arrow 项目群的项目,分别是:
-
Apache Arrow
-
Apache Arrow Flight
-
Apache (Arrow) DataFusion
P 对应的是 Apache Parquet 项目,实际上大量的 Parquet 实现包括 Rust 实现,都包含在 Arrow 项目仓库里。
O 对应的是 Apache OpenDAL[4] 项目。这是由来自 Databend 的工程师漩涡实现的统一数据访问层。接上它,你的项目就可以无痛对接上百个存储后端,包括几乎所有主流云厂商的对象存储服务,都可以用统一的 API 进行读写:用过的都说好。
社群发展
其他讲师大体也介绍了如何应用 DataFusion 的故事,而 DataFusion PMC Chair Andrew Lamb 则站在社群角度分享了 DataFusion 过去一年的进展,包括:
-
超过 1000 个项目使用 DataFusion 构建自己的软件;
-
正式从 Apache Arrow 的一个子项目,成为 Apache 软件基金会的顶级项目;
-
遍布全球的用户会议,包括上面提到的杭州 Meetup 活动[5];
-
在 SIGMOD 2024 上发布了 DataFusion 的主题论文[6];
-
全球开发者合作实现的若干项功能,例如查询优化加速、索引加速和内存占用改进等等,其中不少功能是由中国开发者主导或参与实现的。

Andrew Lamb 确实是 10x 工程师
我在今年开始给 DataFusion 做一些实际的贡献,在此过程中深刻感受到了 Andrew Lamb 的热情和生产力。虽然他经常过分乐观的合并别人贡献的代码,导致一些回退(regression)跟接口需要重新适配,但是他 10x 甚至 100x 的生产力能够快速再次解决这些问题。我想这才是在开源社群协同当中真正 distinguished 的能力。正如 Linus 一样,他未必要独立写出 90% 的代码来推动项目前进,而是能每天合并来自全球各地的数十个 pull request 并保证它们相互之间没有实际冲突,也不会导致回退。
对于 DataFusion 这个项目,我的看法与其官方描述一致:
DataFusion is great for building projects such as domain specific query engines, new database platforms and data pipelines, query languages and more. It lets you start quickly from a fully working engine, and then customize those features specific to your use.
它有抽象层级非常高的 SQL 和 DataFrame 接口,能让你直接获得查询计算能力;对于数据库或其他查询系统而言,它也提供了高度可定制化的框架抽象。从纯粹技术理论上说,针对一个特定的数据系统,定制一个查询引擎总是能有最高的优化上限。但是很多时候,这未必是你的系统最核心的竞争力。
因此,就像 GreptimeDB 采用 DataFusion 的历史一样,我们发现这个软件库是一个很好的起点,扩展定制的旅程也很流畅。绝大部分情况下,我们对查询优化的投入程度和生产力是不如 DataFusion 上游的,我们会将这些时间和精力更多放在 GreptimeDB 作为一个统一时序数据库的业务逻辑实现,用户体验优化,以及从云到端的协同方案落地上。或许在未来的某一天,使用 DataFusion 的项目团队拥有足够多的开发者,能够针对自己的系统设计实现一个更加优秀的查询引擎;但是更有可能的是,终其软件一生,DataFusion 都是那个更好的框架和库实现。
参考资料
1
GreptimeDB: https://github.com/GreptimeTeam/greptimedb
2
DataFusion: https://github.com/apache/datafusion
3
promql-parser: https://github.com/GreptimeTeam/promql-parser
4
Apache OpenDAL: https://github.com/apache/opendal
5
杭州 Meetup 活动: https://www.huodongxing.com/event/5761971909400?td=1965290734055
6