在网络应用开发中,Cookie、Session 和 Token 是常见的用于管理用户状态和身份验证的机制。
Cookie、Session、Token 的区别
这三个概念的产生与 HTTP 是一种无状态协议密切相关。在 HTTP 中,每次客户端与服务器之间进行通信时,服务器无法直接识别客户端的身份或记住先前的请求。这意味着每个 HTTP 请求都是相互独立的,服务器无法从先前的请求中推断出客户端的状态或身份信息。
**注意项:**HTTP 无状态,TCP 有状态,UDP 无状态,HTTP 又基于 TCP,但为什么一个无状态,一个有状态?
HTTP 是无状态的主要是因为它本身并不保持任何关于客户端或服务器状态的信息。每个 HTTP 请求都是独立的,服务器不会记住之前的请求,因此无法直接推断客户端的状态。这种设计有助于简化服务器的设计和扩展,使得服务器可以更容易地处理大量的请求。
TCP 是一种面向连接的协议,它在通信过程中会维护连接的状态信息,包括连接的建立、终止、数据传输等。TCP 使用三次握手来建立连接,并使用序列号和确认号来确保数据的可靠传输和顺序传递。由于 TCP 要维护连接状态信息,因此它是有状态的。
三者之间的区别
1)Cookie: Cookie 是一种在客户端存储的数据,通过在客户端和服务器之间传输的 HTTP 头部中进行交换。当客户端第一次请求服务器时,服务器可以在响应头部中设置一个 Cookie,并在之后的每次请求中将该 Cookie 自动发送回服务器。服务器可以使用 Cookie 存储会话标识、用户偏好设置等信息,以便在用户多次访问网站时保持状态。因此,Cookie 提供了一种在客户端持久存储状态信息的机制。
2)Session: 会话(Session)是在服务器端维护的一种状态信息。当客户端第一次访问服务器时,服务器会创建一个唯一的会话标识(Session ID),并将该 Session ID 保存在服务器端的存储中,同时将该 Session ID 发送给客户端。客户端在后续的请求中通过 Cookie 或 URL 参数的方式将 Session ID 发送回服务器,服务器则根据该 Session ID 来识别客户端,并在会话中保存相关状态信息。会话的生命周期通常由服务器控制,可以设置过期时间或在用户注销或关闭浏览器时结束。
3)Token: Token 是一种无状态的身份验证机制,通常用于实现无状态的分布式身份验证。当客户端进行身份验证时,服务器可以颁发一个包含用户身份信息和其他元数据的 Token,并将该 Token 发送给客户端。客户端在后续的请求中将 Token 包含在请求头部或其他位置中发送给服务器,服务器则使用密钥或其他验证方式来验证 Token 的有效性,并从中提取用户身份信息。Token 通常被用于实现无状态的身份验证和授权,适用于分布式系统和跨域请求。
其他补充
-
跨域支持:
-
Token:由于 Token 是在客户端和服务器之间传递的一种标识符,因此它可以轻松地跨域传输,适用于分布式系统和跨域请求。
-
Cookie 和 Session:Cookie 和 Session 的机制通常与同源策略相关联,跨域传输需要特殊处理或者受到限制,不太适用于跨域场景。
-
-
无状态性:
-
Token:Token 是无状态的,服务器不需要在自己的存储中保存任何关于用户状态的信息,这样可以减轻服务器的负担,并使其更容易扩展和水平扩展。
-
Cookie 和 Session:Cookie 和 Session 都需要服务器在自己的存储中维护会话信息,这增加了服务器的负担,特别是在高并发环境下。
-
-
可扩展性:
-
Token:Token 可以灵活地包含任意类型的信息,并且可以通过签名或加密来保护其完整性和安全性。这使得 Token 在实现身份验证和授权方面具有更大的灵活性和可扩展性。
-
Cookie 和 Session:Cookie 和 Session 的信息通常是与特定的会话或用户相关联的,因此扩展它们的功能可能会受到限制,需要考虑到对现有会话的影响。
-
-
移动应用支持:
-
Token:Token 可以轻松地用于移动应用程序中,因为它可以存储在移动设备的本地存储中,并且可以在移动应用程序和后端服务器之间进行传输。
-
Cookie 和 Session:在移动应用程序中使用 Cookie 和 Session 可能会面临一些挑战,因为它们通常与浏览器相关联,而移动应用程序可能没有直接的浏览器环境。
-
-
安全性:
-
Token:Token 可以通过加密或签名来保护其内容的安全性,防止被篡改或伪造。
-
Cookie 和 Session:Cookie 和 Session 的安全性取决于其在传输过程中的保护机制,如 HTTPS 的加密传输和对会话标识符的安全管理。
-
1)确保 Token 安全性的措施:
使用 HTTPS:通过 HTTPS 协议传输 Token,可以防止中间人攻击和数据被截取。
签名 Token:使用 HMAC 算法或 RSA、ECDSA 等非对称加密算法对 Token 进行签名,确保 Token 在传输过程中未被篡改。
设置有效期:为 Token 设置合理的过期时间,减少 Token 被盗用的风险。
存储安全:在客户端,Token 应存储在安全的存储位置,如 HTTPOnly Cookie 或本地安全存储;在服务器端,应使用安全的存储方式,如加密存储。
验证机制:服务器端接收到 Token 后,应验证其签名、有效期等信息,确保 Token 的合法性。
使用权限控制:Token 应包含最小必要的权限信息,避免权限泄露。
避免在 URL 中暴露 Token:Token 不应出现在 URL 中,以防止被日志、浏览器历史记录等泄露。
2)移动应用开发中 Token 与 Cookie/Session 的考虑因素和区别:状态管理:Cookie/Session 通常用于服务器端状态管理,而 Token 可以用于无状态的身份验证。
安全性:Token 可以通过签名和加密提高安全性,而 Cookie 需要依赖 HTTPS。
可扩展性:Token 更适合分布式系统和微服务架构,因为它们不依赖于中心化的会话管理。
性能:Token 可以减少服务器的存储压力,因为不需要存储会话信息。
适应性:Token 更适合移动应用和单页应用(SPA),因为它们可以在不同域之间轻松传递。
用户体验:Cookie 可以在用户关闭浏览器后仍然保持登录状态,而 Token 通常需要用户重新登录。
3)高并发请求下的用户状态管理机制选择:Token:在处理高并发请求时,Token 通常更为合适。因为 Token 自身包含了用户状态信息,不需要服务器存储会话信息,从而减轻了服务器的负担。此外,Token 可以通过分布式缓存或数据库来验证,更容易进行水平扩展。
Cookie/Session:虽然 Cookie/Session 可以通过使用分布式会话管理来处理高并发,但它们通常需要服务器来维护会话状态,这可能会导致服务器的性能瓶颈。因此,在高并发系统中,Token 通常是一个更好的选择,尤其是在需要横向扩展的场景下。
JVM内存溢出
1.堆内存溢出
JVM堆是用于存储对象实例的内存区域,当应用程序创建了太多的对象并且堆空间不足时,就会出现堆内存溢出错误。比如:
List<Integer> list = new ArrayList<>();while (true) { list.add(new Integer(1));}这段代码会不断地向List中添加Integer对象,导致堆空间不足,最终导致堆JVM内存溢出。
堆内存溢出解决方案:
-
增加堆空间大小,可以通过JVM参数-Xmx和-Xms来设置初始堆大小和最大堆大小;
-
优化代码,减少对象的创建和存储;
-
对于一些大对象,可以考虑使用分段加载或分页加载的方式。
2.栈内存溢出
Java虚拟机中的每个线程都有一个私有的栈,用于存储方法调用和本地变量。
如果递归调用层数过多或者栈空间不足时,就会出现栈内存溢出错误,示例:
public void recursiveMethod(int i) { recursiveMethod(i + 1);}这段代码中的递归调用会不断地创建新的栈帧,导致栈空间不足,最终导致栈内存溢出。
栈内存溢出解决方案:
-
增加栈空间大小,可以通过JVM参数-Xss来设置;
-
优化代码,减少递归调用;
-
对于需要进行大量递归计算的场景,可以使用尾递归或迭代的方式。
3.永久代内存溢出
JVM的永久代用于存储类信息、方法信息和静态变量等数据,当应用程序创建太多的类或者字符串并且永久代空间不足时,就会出现永久代内存溢出错误。比如:
public class Test { public static void main(String[] args) { String str = "Test"; while (true) { str += str + new Random().nextInt(99999999); } }}这段代码中的字符串不断地进行拼接并创建新的字符串对象,导致永久代空间不足,最终导致永久代内存溢出。
永久代内存溢出解决方案:
-
增加永久代空间大小(可以通过JVM参数-XX:MaxPermSize来设置);
-
优化代码,减少字符串拼接操作;
-
对于需要进行大量字符串拼接的场景,可以使用StringBuilder或StringBuffer。
4.方法区内存溢出
Java方法区用于存储类信息、方法信息和静态变量等数据,当应用程序创建太多的类或者字符串并且方法区空间不足时,就会出现方法区内存溢出错误。比如:
public class Test { public static void main(String[] args) { for (int i = 0; i < 1000000; i++) { String className = "TestClass" + i; byte[] byteCode = generateByteCode(className); Class clazz = defineClass(className, byteCode, 0, byteCode.length); clazz.newInstance(); } } public static byte[] generateByteCode(String className) { String classDef = "public class " + className + " { public void test() {} }"; return classDef.getBytes(); }}这段代码会不断地创建新的类,并加载到方法区中,导致方法区空间不足,最终导致方法区内存溢出。
方法区内存溢出解决方案:
-
增加方法区空间大小(可以通过JVM参数-XX:MaxMetaspaceSize来设置);
-
优化代码,减少动态生成类的数量;
-
对于需要动态生成类的场景,可以使用CGLIB或Javassist等工具,避免大量类的动态生成。
CPU 升高问题

真实案例
问题如下:这是一个比较大项目改动,改造的过程中涉及到了相当多下游接口的改动和相当多的依赖包。今天在上线发布后经过接口和功能验证,需求发布成功。
但是接着,我发布完成后才发现机器的平均 CPU 负载升高,平均 CPU 负载几乎升高了有 5-8 %,最高负载更是超过了 CPU 安全水位线。如此多的改动,到底是什么导致了 CPU 负载的上升?
快速处理: 我先快速对比了一下 CPU 负载升高的时间点,和发布时间基本对应,基本可以判断是本次发布引起的。虽然并没有影响到业务,但是发现问题后,我还是第一时间做了回滚处理。
注意:发布过程中出现任何问题不要想排查问题原因,直接回滚,血泪教训的铁律
排查问题
-
由于想到本次变更有很多新接口的引入,也有一些接口的对比代码,会带来额外的性能消耗,所以我先对比了发布前后的接口远程调用情况,结果是调用量没有明显变化,RT 也正常。
-
服务也有 kafka 消息处理,同样检查消息组件情况,调用量没有变化。
-
会不会是 GC 太多导致?检查 JVM 情况,依旧正常,甚至还因为重启机器表现要比之前好。
-
因为用到了线程池,会不会是因为使用线程池不合理,或者有什么死循环之类的。检查活跃线程情况,依旧和发布前相似。
-
那只能考虑是因为引入的某个依赖引起的了,他导致了预期外的变化。
Async-profiler
Arthas 使用 async-profiler 生成 CPU/内存火焰图进行性能分析,弥补了之前内存分析的不足。
async-profiler 是一款开源的 Java 性能分析工具,原理是基于 HotSpot 的 API,以微乎其微的性能开销收集程序运行中的堆栈信息、内存分配等信息进行分析。
官网:https://github.com/async-profiler/async-profiler
我们常用的是 CPU 性能分析和 Heap 内存分配分析。在进行 CPU 性能分析时,仅需要非常低的性能开销就可以进行分析。
在进行 Heap 分配分析时,async-profiler 工具会收集内存分配信息,而不是去检测占用 CPU 的代码。async-profiler 不使用侵入性的技术,例如字节码检测工具或者探针检测等,这也说明 async-profiler 的内存分配分析像 CPU 性能分析一样,不会产生太大的性能开销,同时也不用写出庞大的堆栈文件再去进行进一步处理。
async-profiler 工具在采样后可以生成采样结果的日志报告,也可以生成 SVG 格式的火焰图。

使用 async-profiler 排查问题
进入测试服务器控制台,使用 JPS 命令查看 PID 信息。
➜ develop jps
2800 Jps
528 TestCode
2450 Launcher假设运行程序的名是 TestCode,可以看到对应的 PID 是 528。
使用下面命令:
./profiler.sh -d 20 -f 528.svg 528对 528 号进程采样20秒,然后得到生成的 528.svg 文件,然后我们使用浏览器打开这个文件,可以看到 CPU 的使用火焰图,如下(这里用网络图片代替):
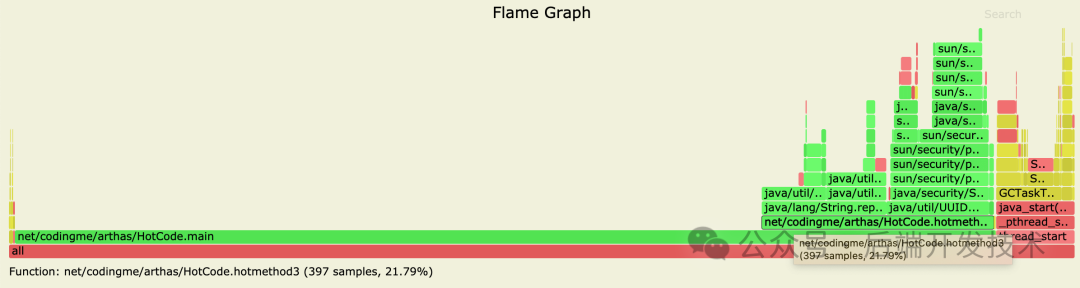
关于火焰图怎么看,一言以蔽之:火焰图里,横条越长,代表使用的越多,从下到上是调用堆栈信息。 在这个图里可以看到 main 方法上面的调用中 hotmethod3 方法的 CPU 使用是最多的,点击这个方法。还可能看到更详细的信息。
那么我们现在只需要查找 hotmethod3 使用的地方在哪里,就可以定位到问题代码。
当然,上面的是个代替 case,告诉你怎么看这个火焰图。真实的 case 要比这个更难排查。如下图,问题代码是个线程,是由某个类调用的:

排查问题依赖引入
问题代码是一个 Thread 的 run 方法引起的,那么是谁调用的他呢?这个类的信息我打码了,假设为 ClassA。
但是排查代码,ClassA 根本没有被项目代码直接的调用,于是我找到了这个 CalssA 所属的依赖包 dep-demoA,看他是谁引入的。
./gradlew :项目名:dependencyInsight --dependency dep-demoA这个命令会打出一个项目的依赖树,结果如下:
+--- com.ali:dep-demoA:1.0.0 (*)
\--- com.ali:dep-demoB:1.0.0
\--- com.ali:dep-demoC:1.0.0如上结果,项目中我是用的是 dep-demoC,结果他同时引入了 dep-demoB,我看了下这个 demoB,他很可能会跟 arthas 类似,通过 Java Agent技术和字节码增强技术以实现一定的功能,这对程序是非常有损耗的。(所以线上不能开 arthas)
尝试排除 demoB,代码如下:
all*.exclude group: "com.ali", module: "dep-demoB"然后重启项目,CPU 负载下降,回归到正常水平,问题解决。

分布式事务实现方案
常见的分布式事务实现方案有以下几种:两阶段提交(2PC)、两阶段提交(2PC)、补偿事务(Saga)、MQ事务消息等。RocketMQ 的事务消息,是一种非常特殊的分布式事务实现方案,基于半消息(Half Message)机制实现的。
实现原理
RocketMQ事务消息执行流程如下:
-
生产者将消息发送至RocketMQ服务端。
-
RocketMQ服务端将消息持久化成功之后,向生产者返回Ack确认消息已经发送成功,此时消息被标记为"暂不能投递",这种状态下的消息即为半事务消息(Half Message)。
-
生产者开始执行本地事务逻辑。
-
生产者根据本地事务执行结果向服务端提交二次确认结果(Commit或是Rollback),服务端收到确认结果后处理逻辑如下:
-
二次确认结果为Commit:服务端将半事务消息标记为可投递,并投递给消费者。
-
二次确认结果为Rollback:服务端将回滚事务,不会将半事务消息投递给消费者。
-
-
在断网或者是生产者应用重启的特殊情况下,若服务端未收到发送者提交的二次确认结果,或服务端收到的二次确认结果为Unknown未知状态,经过固定时间后,服务端将对消息生产者即生产者集群中任一生产者实例发起消息回查。
-
生产者收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
-
生产者根据检查到的本地事务的最终状态再次提交二次确认,服务端仍按照步骤4对半事务消息进行处理。

代码实现
RocketMQ事务消息示例如下:
//演示demo,模拟订单表查询服务,用来确认订单事务是否提交成功。
private static boolean checkOrderById(String orderId) {
return true;
}
//演示demo,模拟本地事务的执行结果。
private static boolean doLocalTransaction() {
return true;
}
public static void main(String[] args) throws ClientException {
ClientServiceProvider provider = new ClientServiceProvider();
MessageBuilder messageBuilder = new MessageBuilderImpl();
//构造事务生产者:事务消息需要生产者构建一个事务检查器,用于检查确认异常半事务的中间状态。
Producer producer = provider.newProducerBuilder()
.setTransactionChecker(messageView -> {
/**
* 事务检查器一般是根据业务的ID去检查本地事务是否正确提交还是回滚,此处以订单ID属性为例。
* 在订单表找到了这个订单,说明本地事务插入订单的操作已经正确提交;如果订单表没有订单,说明本地事务已经回滚。
*/
final String orderId = messageView.getProperties().get("OrderId");
if (Strings.isNullOrEmpty(orderId)) {
// 错误的消息,直接返回Rollback。
return TransactionResolution.ROLLBACK;
}
return checkOrderById(orderId) ? TransactionResolution.COMMIT : TransactionResolution.ROLLBACK;
})
.build();
//开启事务
final Transaction transaction;
try {
transaction = producer.beginTransaction();
} catch (ClientException e) {
e.printStackTrace();
//事务开启失败,直接退出。
return;
}
Message message = messageBuilder.setTopic("topic")
//设置消息索引键,可根据关键字精确查找某条消息。
.setKeys("messageKey")
//设置消息Tag,用于消费端根据指定Tag过滤消息。
.setTag("messageTag")
//一般事务消息都会设置一个本地事务关联的唯一ID,用来做本地事务回查的校验。
.addProperty("OrderId", "xxx")
//消息体。
.setBody("messageBody".getBytes())
.build();
//发送半事务消息
final SendReceipt sendReceipt;
try {
sendReceipt = producer.send(message, transaction);
} catch (ClientException e) {
//半事务消息发送失败,事务可以直接退出并回滚。
return;
}
/**
* 执行本地事务,并确定本地事务结果。
* 1. 如果本地事务提交成功,则提交消息事务。
* 2. 如果本地事务提交失败,则回滚消息事务。
* 3. 如果本地事务未知异常,则不处理,等待事务消息回查。
*
*/
boolean localTransactionOk = doLocalTransaction();
if (localTransactionOk) {
try {
transaction.commit();
} catch (ClientException e) {
// 业务可以自身对实时性的要求选择是否重试,如果放弃重试,可以依赖事务消息回查机制进行事务状态的提交。
e.printStackTrace();
}
} else {
try {
transaction.rollback();
} catch (ClientException e) {
// 建议记录异常信息,回滚异常时可以无需重试,依赖事务消息回查机制进行事务状态的提交。
e.printStackTrace();
}
}
}注意事项
-
幂等性: 消费者处理消息时需要确保业务逻辑的幂等性,以应对消息可能的重复消费。
-
超时和监控: 设置合理的超时时间,并监控事务消息的性能
总结
RocketMQ 事务消息是分布式事务中一种常见的实现方案,只是把发送消息和本地事务放在一个事务中,并且只保证最终一致性,无法保证强一致性。 原因有两点:
-
执行完成本地事务后,在commit事务消息之前,这段时间内数据是不一致的,所以只是保证了发送消息和本地事务的最终一致性。
-
在commit事务消息之后,然后把消息投递给消费者。至于消费者是否消费消息,什么时候消费?也都是不可控的,所以也只能尽量保证数据最终一致性。
解决线上消息队列积压问题
提到消息队列,最常问到的问题就是消息积压,真实线上环境该怎么解决消息积压的问题?真实情况并不是网上说的把积压的消息投递到一个新Topic中,然后慢慢消费。这样做,成本太高、流程复杂、操作麻烦,而且还是一次性操作,不可持续,下次再出现这种问题,还要手动操作。
消息积压的原因
消息积压是指消息在队列中等待处理的数量不断增加。这种情况会导致系统性能下降,影响整个应用的响应时间和可靠性。 常用原因如下:
- 生产者发送速度过快
在某些情况下,生产者可能会突然增加发送速率,或者持续发送大量消息,超出了系统的处理能力。
-
**流量高峰:**特定事件或情况可能导致消息量暴增,如促销活动、日志收集系统在错误发生时的突增等。
-
**生产者配置不当:**生产者配置错误可能导致发送过多的消息到队列。
- 消费者处理速度慢
最常见的原因是消费者处理消息的速度跟不上生产者生产消息的速度。这可能是由于:
-
**消费者处理逻辑复杂或效率低:**如果每条消息的处理时间过长,会导致处理队列中的消息堆积。
-
**消费者数量不足:**消费者的数量可能不足以处理入队消息的数量,尤其是在高峰时间。
-
**消费者处理能力预估不足:**针对消费者的处理能力没有做好压测和限流。
-
消费端存在业务逻辑bug,导致消费速度低于平常速度。
- 资源限制
服务器或网络的资源限制也可能导致消息处理能力受限,从而引起消息积压:
-
**服务器性能限制:**CPU、内存或I/O性能不足,无法高效处理消息。
-
**网络问题:**网络延迟或带宽不足也会影响消息的发送和接收速度。
- 错误和异常处理
错误处理机制不当也可能导致消息积压:
-
**失败重试:**消费者在处理某些消息失败后进行重试,但如果重试策略不当或错误频发,会导致处理速度降低。
-
**死信消息:**处理失败的消息过多,导致死信队列中的消息堆积。
- 设计和配置问题
系统设计不合理或配置不当也可能导致消息积压:
-
**错误的分区策略:**在 Kafka 等系统中,分区策略不合理可能导致部分分区过载。
-
**不合理的消息大小:**消息太大或太小都可能影响系统的处理性能。
解决方案
针对消息队列中消息积压的问题,常用的解决方案如下:
- 增加消费者数量或优化消费者性能
-
水平扩展消费者:增加消费者的数量,以提高并行处理能力。在一个消费者组里增加更多的消费者,可以提高该组的消息处理能力。
-
优化消费逻辑:减少每条消息处理所需的时间。例如,通过减少不必要的数据库访问、缓存常用数据、或优化算法等方式。
-
多线程消费:如果消费者支持多线程处理,并且是非顺序性消息,可通过增加线程数来提升消费速率。
- 控制消息生产速率
-
限流措施:对生产者实施限流措施,确保其生产速率不会超过消费者的处理能力。
-
批量发送:调整生产者的发送策略,使用批量发送减少网络请求次数,提高系统吞吐量。
- 资源优化和网络增强
-
服务器升级:提升处理能力,例如增加 CPU、扩大内存,或提高 I/O 性能。
-
网络优化:确保网络带宽和稳定性,避免网络延迟和故障成为瓶颈。
- 改进错误和异常处理机制
-
错误处理策略:合理设置消息的重试次数和重试间隔,避免过多无效重试造成的额外负担。
-
死信队列管理:对于无法处理的消息,移动到死信队列,并定期分析和处理这些消息。
- 系统和配置优化
-
消息分区策略优化:合理配置消息队列的分区数和分区策略,确保负载均衡。
-
消息大小控制:控制消息的大小,避免因单个消息过大而影响系统性能。
- 实施有效的监控与告警
-
实时监控:实施实时监控系统,监控关键性能指标如消息积压数、处理延迟等。
-
告警系统:设定阈值,一旦发现异常立即触发告警,快速响应可能的问题。
- 消费者和生产者配置调整
-
调整消费者拉取策略 :例如,调整
max.poll.records和fetch.min.bytes等参数,根据实际情况优化拉取数据的量和频率。 -
生产者发送策略优化 :调整
linger.ms和batch.size,使生产者在发送消息前进行更有效的批处理。
Kafka消息积压
具体到解决 Kafka 消息积压问题,有以下调优策略解决 Kafka 消息积压问题:
- 增加分区数量
在增加消费者之前,确保 Topic 有足够的分区来支持更多的消费者。如果一个 Topic 的分区数量较少,即使增加了消费者数量,也无法实现更高的并行度。你可以通过修改 Topic 的配置来增加分区数:
# 使用 Kafka 命令行工具增加分区
kafka-topics.sh --bootstrap-server <broker-list> --alter --topic <topic-name> --partitions <new-number-of-partitions>- 增加消费者数量
在 Kafka 中,一个 Partition 只能由消费者组中的一个消费者消费,因此增加消费者数量是可以提高并发处理能力的。具体操作就是启动多个消费者,并加入到同一个消费者组里,同时确保这些消费者拥有相同的group.id(消费者组ID)。
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.util.Collections;
import java.util.Properties;
public class Consumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "consumer-group"); // group.id必须相同
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("your-topic"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
} finally {
consumer.close();
}
}
}- 修改消费者配置
通过修改下面的消费者配置,可以提高消费者处理速度:
-
fetch.min.bytes 消费者每次从服务器拉取最小数据量,增加这个值,可以减少消费者请求次数,降低网络消耗,提升消费者处理性能。
-
fetch.max.bytes 与上面配置相对应,这是消费者每次从服务器拉取最大数据量,增加这个值,也有同样的效果。
-
fetch.max.wait.ms 这个配置指定了消费者在读取到 fetch.min.bytes 设置的数据量之前,最多可以等待的时间。增加这个值,也有同样的效果。
-
max.poll.records 消费者每次可以拉取的最大记录数,增加这个值,也有同样的效果,不过会增加每次消息处理的时间。
-
max.partition.fetch.bytes 消费者从每个分区里拉取的最大数据量
RocketMQ消息积压
具体到解决 RocketMQ 消息积压问题,有以下调优策略解决 RocketMQ 消息积压问题:1. 增加消费者数量可以通过简单地启动更多的消费者实例来实现,并配置为相同的消费者组。
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.common.message.MessageExt;
import java.util.List;
public class Consumer {
public static void main(String[] args) throws Exception {
// 创建消费者实例,指定消费者组名
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("consumerGroup1");
// 指定 NameServer 地址
consumer.setNamesrvAddr("localhost:9876");
// 订阅一个或多个主题
consumer.subscribe("TopicTest", "*");
// 注册回调实现类来处理从 brokers 拉取回来的消息
consumer.registerMessageListener(new MessageListenerConcurrently() {
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
for (MessageExt msg : msgs) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), new String(msg.getBody()));
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
// 启动消费者实例
consumer.start();
System.out.printf("Consumer Started.%n");
}
}- 修改消费者配置
可以在消费者配置中调整消费线程的数量来提高并行处理能力。
// 设置消费者最小线程数
consumer.setConsumeThreadMin(20);
// 设置消费者最大线程数
consumer.setConsumeThreadMax(40);增加消费者每次拉取消息的数量
// 设置每次拉取消息的数量,默认是32条
consumer.setPullBatchSize(32);增加消费者监听器每次处理消息的最大数量
// 设置每批最多消费10条消息,默认是1
consumer.setConsumeMessageBatchMaxSize(10);- 修改生产者失败重试配置
减少生产者发送消息失败重试次数,也可以减少消息积压问题。
DefaultMQProducer producer = new DefaultMQProducer("ProducerGroupName");
producer.setNamesrvAddr("localhost:9876");
producer.setRetryTimesWhenSendFailed(0); // 设置发送失败时的重试次数,默认是2
producer.start();- 修改消费者失败重试配置
减少消费者处理消息失败重试次数,也可以减少消息积压问题。
// 设置最大重试次数,普通消息默认是16次,顺序消息默认是Integer最大值
consumer.setMaxReconsumeTimes(3);- 增加消费者分区数量
可以使用 RocketMQ 的命令行工具 mqadmin 来更新 Topic 的配置。需要注意的是,增加分区是一个重要操作,它可能会影响现有的消息平衡和消费者的消费行为。
mqadmin updateTopic -n {nameServerAddress} -c {clusterName} -t {topicName} -w {writeQueueNums} -r {readQueueNums}-
{nameServerAddress}: NameServer 的地址。
-
{clusterName}: RocketMQ 集群名称。
-
{topicName}: 需要增加分区的 Topic 名称。
-
{writeQueueNums} 和 {readQueueNums}: 新的分区(MessageQueue)数量。这通常是一个比当前更高的数字。
4大主流分布式算法
分布式场景下困扰我们的3个核心问题(CAP):一致性、可用性、分区容错性。
1、一致性(Consistency):无论服务如何拆分,所有实例节点同一时间看到是相同的数据
2、可用性(Availability):不管是否成功,确保每一个请求都能接收到响应
3、分区容错性(Partition Tolerance):系统任意分区后,在网络故障时,仍能操作

而我们最为关注的是如何在高并发下保障 Data Consistency(数据一致性),因为在很多核心金融业务场景(如 支付、下单、跨行转账)中,为了避免资金问题,是需要强一致性结果的。而分布式一致性算法就是保障 Data Consistency的强大利刃,它的目标是确保分布式系统中多个节点在读取或修改同一份数据时,产生相同结果的关键机制。这些算法对于保证分布式系统的一致性和可靠性至关重要。
-
Paxos算法
-
Raft算法
-
ZAB(ZooKeeper Atomic Broadcast)算法
3.1 Paxos算法
Paxos算法是一种用于分布式系统中保障一致性的算法,由Leslie Lamport于1990年提出,被广泛应用于分布式系统中的一致性问题,如分布式数据库、分布式存储系统等。
该算法的主要目标是在一个由多个节点组成的分布式系统中,协调某个数据值并达成一致性,典型的少数服从多数的案例。
3.1.1 基本概念
1. 提案: 由提案号(id)和提案内容(value)组成,其中id主要用于实现Paxos算法,而value对应在实际的分布式系统中为所需要修改数据的命令 或者 log信息。
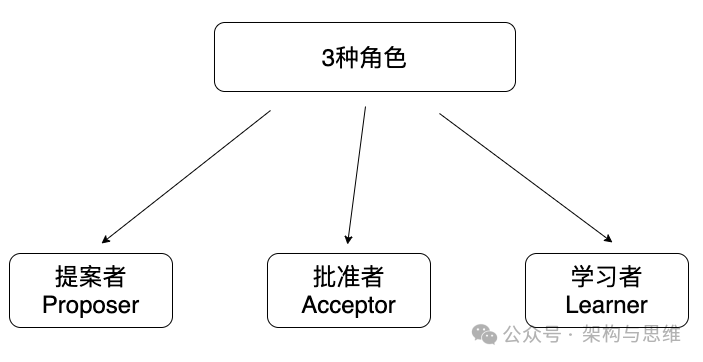
2. 角色: Paxos算法中抽象出来的概念,对应着实际分布式环境中的不同分工。主要角色包括提议者(Proposer)、批准者(Acceptor)和学习者(Learner)。
-
提议者负责提出值的提案
-
接受者负责接受提案并投票
-
学习者负责学习已经达成一致的值
Proposer 提案者
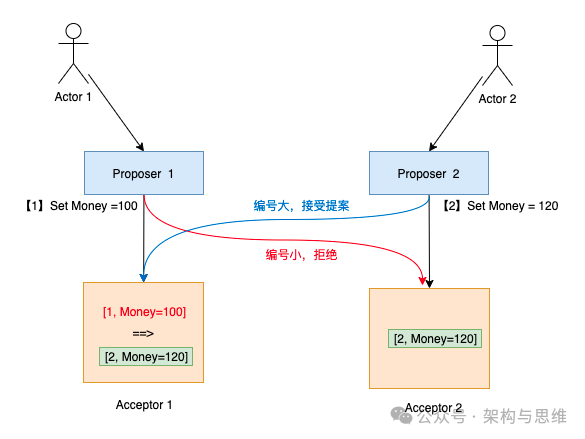
提案者负责提出提案 (Proposal),Proposal信息包括提案编号 (Proposal ID) 和提议的值 (Value)。提案的value,可以是任何行为或者操作,比如传统转账场景,将用户的账号余额从0改为100,Paxos 协议统一抽象为value。 Proposer可以有多个,不同的Proposer可以提出不同的甚至互斥的value,比如提案者A消费(将变量Money-100),提案者B也消费(将变量Money-200),但对同一轮Paxose而言,最多只有一个value可以被批准,否则就乱套了。
Acceptor 批准者
Acceptor 从含义上来说就是除了当前Proposer以外的其他机器,他们之间完全平等和独立,Proposer需要争取超过半数(N/2+1)的 Acceptor 批准后,其提案才能通过,它倡导的"value"操作才能被所有机器(包括Proposer、Acceptor、Learner)所接受。
Learner 学习者
Learner 不参与选举,而是学习被批准的 value,在Paxos中,Learner主要参与相关的状态机同步流程。这里Leaner的流程就参考了Quorum议会机制,某个value需要获得超过半数的Acceptor 批准,才能真正被Learner学习到。
3.1.2 算法流程
1. 准备阶段(Prepare阶段):提议者(Proposer)向所有Acceptor节点发起Prepare请求,携带全局唯一且递增的提案编号N,要求它们告诉提议者已经接受的最高提议号。如果接受者接受了轮次小于当前轮次的提案,那么它会更新自己的状态,拒绝当前轮次的提案。
2. 承诺阶段(Promise阶段) :Acceptor节点接收到prepare请求后,会检查该请求的提议号是否比它已经接受的提议号更高。如果是,那么节点会更新自己的状态,承诺不再接受轮次小于当前轮次的提案。
Acceptor收到Prepare请求后,有两种情况:
-
如果Acceptor首次接收Prepare请求, 设置MaxN=N, 同时响应ok
-
果Acceptor不是首次接收Prepare请求,则:
-
若请求过来的提案编号N小于等于上次持久化的提案编号ResN,则不响应或者响应error。
-
若请求过来的提案编号N大于上次持久化的提案编号MaxN, 则更新MaxN=N,同时给出正确的响应。
-
3. 承诺响应阶段(Acknowledge阶段) :在这个阶段,接受者会检查自己是否接受了当前提案。如果是,那么接受者会返回一个承诺响应,告诉提议者当前提案已经被接受。
4. 提议的接受与决策 :当Acceptor节点接收到一个提议请求时,它会检查该提议的值是否比它已经接受的值更高。如果是,那么它会接受该提议,并向其他节点发送接受消息。当一个提议被大多数节点接受后,该提议就成为了决策,并被所有节点执行。
Proposer 获得 Accept 回复的信息之后,做如下判断:
-
回复数量 > Acceptor 数量的1/2时,代表提交 value 成功,发送广播给所有的 Proposer、Learner,通知它们已提交的 value。
-
回复数量 <= Acceptor 数量的1/2时,则重新开始,更新生成更大的提案号,跳转到准备阶段执行。
-
收到响应error时,同样更新生成更大的提案号,转到准备阶段执行。

5. 学习阶段(Learn阶段) :学习者会向所有接受者发送一个学习请求,接受者会返回已经接受的最大提案,使学习者能够学习到已经达成一致的值。
3.1.3 应用
Paxos算法具有高度容错特性,可以在某个节点宕机、网络异常、消息延迟等问题的情况下,快速且正确地在集群内部对某个数据达成一致。所以在很多业务场景中得到应用。比如:
-
Zookeeper使用一个类Multi-Paxos的共识算法作为底层存储协同的机制。
-
Google公司在其分布式锁中应用了Multi-Paxos算法。
3.2 Raft算法
3.2.1 基本概念
Raft 算法是一致性算的一种,用来解决分布式一致性问题。它提供了一种在计算系统集群中分布状态机的通用方法,确保集群中的每个节点都同意一系列相同的状态转换。
其主要目标是解决分布式系统中的领导者选举、日志复制和安全性等关键问题。
3.2.2 领导者选举与超时机制
在Raft算法中,服务器可以处于三种状态:领导者(leader)、跟随者(follower)和候选者(candidate)。正常情况下,集群中只包含一个 leader ,其余服务器都是 follower 。
跟随者通过投票选出领导者,只有得到"大多数"跟随者投票的服务器能成为领导者;领导者负责将命令同步给跟随者,只有被"大多数"跟随者确认的命令才能提交。
1. 跟随者(Follower)
Fllower是所有节点的初始状态,内部都会有一个随机超时时间。这个超时时间,规定了在倒计时结束后仍然收不到Leader的心跳,Follower就会转变为Candidate。
2. 候选者(candidate)
Follower在转变为Candidate后,超时时间重置,倒计时结束时就会向其他节点提名自己的实,拉取选票。
如果能获得半数以上(1/2以上,包含自己投给自己的)的选票,则当选为Leader,这个过程就叫做Leader选举。
所以节点最好是单数,避免极端情况下出现一个集群选举出两个Leader的脑裂问题。
3 .领导者(leader)
Raft集群通过Leader与客户端进行交互,Leader不断处理写请求与发送心跳给Follower,Follower在收到Leader的心跳后,其超时时间会重置,即重新开始倒计时。
正常工作期间只有 Leader 和 Follower,且Leader至多只能有一个。
角色状态转换过程

3.3 ZAB(ZooKeeper Atomic Broadcast)算法
3.3.1 基本概念
ZAB(Zookeeper Atomic Broadcast)是Zookeeper原子消息广播协议,是Zookeeper保证数据一致性的核心算法。该算法借鉴了Paxos算法,但又不像Paxos那样是一种通用的分布式一致性算法,而是特别为Zookeeper设计的支持崩溃恢复的原子广播协议。
在Zookeeper中,主要依赖ZAB协议来实现数据一致性。基于该协议,Zookeeper实现了一种主备模型(即Leader和Follower模型)的系统架构,保证集群中各个副本之间数据的一致性。通过一台主进程(Leader)负责处理外部的写事务请求,然后将数据同步到其他Follower节点,如果超过半数成功ACK,则主进程执行 Commit操作。
3.3.2 广播流程

ZAB 协议的消息广播过程使用的是一个原子广播协议,类似一个 二阶段(2PC) 提交过程。
对于客户端发送的写请求,全部由 Leader 接收,Leader 将请求封装成一个事务 Proposal,将其发送给所有 Follwer ,
然后,根据所有 Follwer 的反馈,如果超过半数成功响应,则执行 Commit 操作(先提交自己,再发送 Commit 给所有 Follwer)
总结
分布式一致性算法是确保分布式系统中多个节点在读取或修改同一份数据时,产生相同结果的关键机制。这些算法对于保证分布式系统的一致性和可靠性至关重要。
目前常见以下是一些常用的分布式一致性算法:
-
Paxos算法:由Lamport宗师提出,是一种基于消息传递的分布式一致性算法。它旨在解决在一个可能发生故障的分布式系统中,如何快速正确地在集群内对某个值达成一致,并保证整个系统的一致性。
-
Raft算法:一种相对易于理解的分布式一致性算法,它将一致性问题的复杂性分解为若干个相对独立的子问题。Raft通过选举和日志复制的方式确保数据的一致性。
-
ZAB(ZooKeeper Atomic Broadcast)算法:是ZooKeeper中使用的原子广播协议,用于实现分布式系统中的状态同步。ZAB协议包括恢复模式和广播模式,确保ZooKeeper集群中的各个节点能够保持数据的一致性。
此外,还有其他分布式一致性算法,如Gossip协议等,这些算法在不同的分布式系统场景中有各自的应用和优势。
在选择分布式一致性算法时,需要考虑系统的规模、节点的数量、通信开销、数据一致性要求以及容错性等因素。不同的算法可能适用于不同的场景,因此需要根据具体情况进行选择和调整。
高并发下的数据一致性保障
分布式场景下困扰我们的3个核心需求(CAP):一致性、可用性、分区容错性,以及在实际场景中的业务折衷。
1、一致性(Consistency): 再分布,所有实例节点同一时间看到是相同的数据
2、可用性(Availability): 不管是否成功,确保每一个请求都能接收到响应
3、分区容错性(Partition Tolerance): 系统任意分区后,在网络故障时,仍能操作

而本文我们聚焦高并发下如何保障 Data Consistency(数据一致性)。
2.1 典型支付场景
这是最经典的场景。支付过程,要先查询买家的账户余额,然后计算商品价格,最后对买家进行进行扣款,像这类的分布式操作,如果是并发量低的情况下完全没有问题的,但如果是并发扣款,那可能就有一致性问题。。在高并发的分布式业务场景中,类似这种 "查询+修改" 的操作很可能导致数据的不一致性。

2.2 在线下单场景
同理,买家在电商平台下单,往往会涉及到两个动作,一个是扣库存,第二个是更新订单状态,库存和订单一般属于不同的数据库,需要使用分布式事务保证数据一致性。

2.3 跨行转账场景
跨行转账问题也是一个典型的分布式事务,用户A同学向B同学的账户转账500,要先进行A同学的账户-500,然后B同学的账户+500,既然是 不同的银行,涉及不同的业务平台,为了保证这两个操作步骤的一致,数据一致性方案必然要被引入。

3.1 分布式锁
分布式锁的实现,比较常见的方案有3种:
1、基于数据库实现分布式锁
2、基于缓存(Redis或其他类型缓存)实现分布式锁
3、基于Zookeeper实现分布式锁
这3种方案,从实现的复杂度上来看,从1到3难度依次递增。而且并不是每种解决方案都是完美的,它们都有各自的特性,还是需要根据实际的场景进行抉择的。
| 能力组件 | 实现复杂度 | 性能 | 可靠性 |
|---|---|---|---|
| 数据库 | 高 | 低 | 低 |
| 缓存 | 中 | 高 | 中 |
| zookeeper | 低 | 中 | 高 |
《分布式锁方案分析》
缓存方案是采用频率最高的
3.1.1 基于缓存实现分布式锁
相比较于基于数据库实现分布式锁的方案来说,基于缓存来实现在性能方面会表现的更好一点。类似Redis可以多集群部署的,解决单点问题。基于Redis实现的锁机制,主要是依赖redis自身的原子操作,例如 :
# 判断是否存在,不存在设值,并提供自动过期时间SET key value NX PX millisecond
# 删除某个keyDEL key [key ...]NX:只在在键不存在时,才对键进行设置操作,SET key value NX 效果等同于 SETNX key value
PX millisecond:设置键的过期时间为millisecond毫秒,当超过这个时间后,设置的键会自动失效
如果需要把上面的支付业务实现,则需要改写如下:
# 设置账户Id为17124的账号的值为1,如果不存在的情况下,并设置过期时间为500msSET pay_id_17124 1 NX PX 500
# 进行删除DEL pay_id_17124上述代码示例是指,当redis中不存在pay_key这个键的时候,才会去设置一个pay_key键,键的值为 1,且这个键的存活时间为500ms。当某个进程设置成功之后,就可以去执行业务逻辑了,等业务逻辑执行完毕之后,再去进行解锁。而解锁之前或者自动过期之前,其他进程是进不来的。
实现锁机制的原理是:这个命令是只有在某个key不存在的时候,才会执行成功。那么当多个进程同时并发的去设置同一个key的时候,就永远只会有一个进程成功。解锁很简单,只需要删除这个key就可以了。
另外,针对redis集群模式的分布式锁,可以采用redis的Redlock机制。
3.1.2 缓存实现分布式锁的优缺点
优点:Redis相比于MySQL和Zookeeper性能好,实现起来较为方便。
缺点:通过超时时间来控制锁的失效时间并不是十分的靠谱;这种阻塞的方式实际是一种悲观锁方案,引入额外的依赖(Redis/Zookeeper/MySQL 等),降低了系统吞吐能力。
3.2 乐观模式
对于概率性的不一致的处理,需要乐观锁方案,让你的系统更具健壮性。分布式CAS(Compare-and-Swap)模式就是一种无锁化思想的应用,它通过无锁算法实现线程间对共享资源的无冲突访问。CAS模式包含三个基本操作数:内存地址V、旧的预期值A和要修改的新值B。在更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B。
以 2.1节 的 典型支付场景 作为例子分析:
-
初始余额为 800
-
业务1和业务2同时查询余额为800
-
业务1执行购买操作,扣减去100,结果是700,这是新的余额。理论上只有在原余额为800时,扣减的Action才能执行成功。
-
业务2执行生活缴费操作(比如自动交电费),原余额800,扣减去200,结果是600,这是新的余额。理论上只有在原余额为800时,扣减的Action才能执行成功。可实际上,这个时候数据库中的金额已经变为600了,所以业务2的并发扣减不应该成功。
根据上面的CAS原理,在Swap更新余额的时候,加上Compare条件,跟初始读取的余额比较,只有初始余额不变时,才允许Swap成功,这是一种常见的降低读写锁冲突,保证数据一致性的方法。

go 代码示例(使用Baidu Comate AI 生成,已调试):
package main import ( "fmt" "sync/atomic" ) // Compare 函数比较当前值与预期值是否相等 func Compare(addr *uint32, expect uint32) bool { return atomic.LoadUint32(addr) == expect } func main() { var value uint32 = 0 // 共享变量 // 假设我们期望的初始值是0 oldValue := uint32(0) // 使用Compare函数比较当前值与期望值 if Compare(&value, oldValue) { fmt.Println("Value matches the expected old value.") // 在这里,你可以执行实际的交换操作,但请注意, // 在并发环境中,你应该使用atomic.CompareAndSwapUint32来确保原子性。 // 例如: // newValue := uint32(1) // if atomic.CompareAndSwapUint32(&value, oldValue, newValue) { // fmt.Println("CAS succeeded, value is now", newValue) // } else { // fmt.Println("CAS failed, value was changed by another goroutine") // } } else { fmt.Println("Value does not match the expected old value.") } // 修改value的值以演示Compare函数的行为变化 atomic.AddUint32(&value, 1) // 再次比较,此时应该不匹配 if Compare(&value, oldValue) { fmt.Println("Value still matches the expected old value, but this shouldn't happen.") } else { fmt.Println("Value no longer matches the expected old value.") } }3.3 解决CAS模式下的ABA问题
3.3.1 什么是ABA问题?
在CAS(Compare-and-Swap)操作中,ABA问题是一个常见的挑战。ABA问题是指一个值原来是A,被另一个线程改为B,然后又被改回A,当前线程使用CAS Compare检查时发现值仍然是A,从而误认为它没有被其他线程修改过。

3.3.2 如何解决?
为了避免ABA问题,可以采取以下策略:
1. 使用版本号或时间戳:
-
每当共享变量的值发生变化时,都递增一个与之关联的版本号或时间戳。
-
CAS操作在比较变量值时,同时也要比较版本号或时间戳。
-
只有当变量值和版本号或时间戳都匹配时,CAS操作才会成功。
2. 不同语言的自带方案:
-
Java中的
java.util.concurrent.atomic包提供了解决ABA问题的工具类。 -
在Go语言中,通常使用sync/atomic包提供的原子操作来处理并发问题,并引入版本号或时间戳的概念。
那么上面的代码就可以修改成:
type ValueWithVersion struct { Value int32 Version int32 } var sharedValue atomic.Value // 使用atomic.Value来存储ValueWithVersion的指针 func updateValue(newValue, newVersion int32) bool { current := sharedValue.Load().(*ValueWithVersion) if current.Value == newValue && current.Version == newVersion { // CAS操作:只有当前值和版本号都匹配时,才更新值 newValueWithVersion := &ValueWithVersion{Value: newValue, Version: newVersion + 1} sharedValue.Store(newValueWithVersion) return true } return false }3. 引入额外的状态信息:
-
除了共享变量的值本身,还可以引入额外的状态信息,如是否已被修改过。
-
线程在进行CAS操作前,会检查这个状态信息,以判断变量是否已被其他线程修改过。
需要注意的是,避免ABA问题通常会增加并发控制的复杂性,并可能带来性能开销。因此,在设计并发系统时,需要仔细权衡ABA问题的潜在影响与避免它所需的成本。在大多数情况下,如果ABA问题不会导致严重的数据不一致或逻辑错误,那么可能不需要专门解决它。
总结
在高并发环境下保证数据一致性是一个复杂而关键的问题,涉及到多个层面和策略。除了上面提到的方案外,还有一些常见的方法和原则,用于确保在高并发环境中保持数据一致性:
-
事务(Transactions):
-
使用数据库事务来确保数据操作的原子性、一致性、隔离性和持久性(ACID属性)。
-
通过锁机制(如行锁、表锁)来避免并发操作导致的冲突。
-
-
分布式锁:
-
当多个服务或节点需要同时访问共享资源时,使用分布式锁来协调这些访问。
-
例如,使用Redis的setnx命令或ZooKeeper的分布式锁机制。
-
-
乐观锁与悲观锁:
-
乐观锁假设冲突不太可能发生,通常在数据更新时检查版本号或时间戳。
-
悲观锁则假设冲突很可能发生,因此在数据访问时立即加锁。
-
-
数据一致性协议:
- 使用如Raft、Paxos等分布式一致性算法,确保多个副本之间的数据同步。
-
消息队列:
-
通过消息队列实现数据的异步处理,确保数据按照正确的顺序被处理。
-
使用消息队列的持久化、重试和顺序保证特性。
-
-
CAP定理与BASE理论:
-
理解CAP定理(一致性、可用性、分区容忍性)的权衡,并根据业务需求选择合适的策略。
-
BASE理论(Basically Available, Soft state, Eventually consistent)提供了一种弱化一致性要求的解决方案。
-
-
缓存一致性:
- 使用缓存失效策略(如LRU、LFU)和缓存同步机制(如缓存穿透、缓存击穿、缓存雪崩的应对策略),确保缓存与数据库之间的一致性。
-
读写分离读写:
- 使用主从复制、读写分离读写等技术,将读操作和写操作分散到不同的数据库实例上,提高并发处理能力。
-
数据校验与重试:
-
在数据传输和处理过程中加入校验机制,确保数据的完整性和准确性。
-
对于可能失败的操作,实施重试机制,确保数据最终的一致性。
-
-
监控与告警:
-
实时监控数据一致性相关的关键指标,如延迟、错误率等。
-
设置告警阈值,及时发现并处理可能导致数据不一致的问题。
-
在实际应用中,通常需要结合具体的业务场景和技术栈来选择合适的策略。
五种分布式事务解决方案
1.1 分布式系统的发展
我们早期的集中式系统都是单体架构的,整个系统作为一个单体粒度的应用存在,所有的模块聚合在一起。明显的弊端就是不易扩展、发布冗重、服务稳定性治理不好做。随着微服务架构的不断大规模应用,驱使我们把整个系统拆分成若干个具备独立运行能力的计算服务的集合,通过交互协作,完成庞大、复杂的业务流程,用户感知单一,但实际上,它是一个分布式服务的集合。
分布式系统主要从以下几个方面进行裂变:
1、应用可以从业务领域拆分成多个module,单个module再按项目结构分成接口层、业务层、数据访问层;也可以按照用户领域区分,如对移动、桌面、Web端访问的入口流量拆分不同类型接口服务。
2、数据存储层可以按业务类型拆分成多个数据库实例,还可以对单库或单表进行更细粒度的分库分表;
3、通过一些业务中间件的支撑来保证分布式系统的可用性,如分布式缓存、搜索服务、NoSQL数据库、文件服务、消息队列等中间件。
1.2 存在的优势和不足
分布式系统可以解决集中式不便扩展的弊端,提供了便捷的扩展性、独立的服务治理,并提高了安全可靠性。随着微服务技术(Spring Cloud、Dubbo) 以及容器技术(Kubernetes、Docker)的大热,分布式技术发展非常迅速。
不足的地方:分布式系统虽好,也给系统带来了复杂性,如分布式事务、分布式锁、分布式session、数据一致性等都是现在分布式系统中需要解决的难题,虽然已经有很多成熟的方案,但都不完美。
分布式系统的便利,其实是牺牲了一些开发、测试、发布、运维、资源 成本的,让工作量增加了,所以分布式系统管理不好反而会变成一种负担。
2.1 使用分布式事务解决问题
我们上面说了,分布式系统给业务带来了一些复杂性,所以,衍生出分布式事务来应对和解决这些问题。分布式事务是指允许多个独立的事务资源参与到一个全局的事务中,其参与者、支持事务的服务器、资源服务器以及事务管理器分别位于分布式系统的不同节点之上。这些节点属于同一个Action行为,如果有一个节点的结果不同步,就会造成整体的数据不一致。分布式事务需要保证这些action要么全部成功,要么全部失败,从而保证单个完整操作的原子性,也保证了各节点数据的一致性。
2.2 CAP定理
CAP 定理(也称为 Brewer 定理),指的是在分布式计算环境下,有3个核心的需求:
1、一致性(Consistency):再分布,所有实例节点同一时间看到是相同的数据
2、可用性(Availability):不管是否成功,确保每一个请求都能接收到响应
3、分区容错性(Partition Tolerance):系统任意分区后,在网络故障时,仍能操作
CAP理论告诉我们,分布式系统不可能同时满足以下三种。最多只能同时满足其中的两项,大多数分布式业务中P是必须的, 因此往往选择就在CP或者AP。
-
CA: 放弃分区容错性。非分布式架构,比如关系数据库,因为没有分区,但是在分布式系统下,CA组合就不建议了。
-
AP: 放弃强一致性。追求最终一致性,类似的场景比如转账,可以接受两小时后到账,Eureka的注册也是类似的做法。
-
CP: 放弃可用性。zookeeper在leader宕机后,选举期间是不提供服务的。类似的场景比如支付完成之后出订单,必须一进一出都完成才行。
说明:在分布式系统中AP运用的最多,因为他放弃的是强一致性,追求的是最终一致性,性价比最高
2.3 分布式事务应用场景
2.3.1 典型支付场景
这是最经典的场景。支付过程,要先对买家账户进行扣款,同时对卖家账户进行付款,像这类的操作,必须在一个事务中执行,保证原子性,要么都成功,要么都不成功。但是往往买家的支付平台和卖家的支付平台不一致,即使都在一个平台下,所属的业务服务和数据服务(归属不同表甚至不同库,比如卖家中心库、卖家中心库)也不是同一个。针对于不同的业务平台、不同的数据库做操作必然要引入分布式事务。
2.3.2 在线下单场景
同理,买家在电商平台下单,往往会涉及到两个动作,一个是扣库存,第二个是更新订单状态,库存和订单一般属于不同的数据库,需要使用分布式事务保证数据一致性。
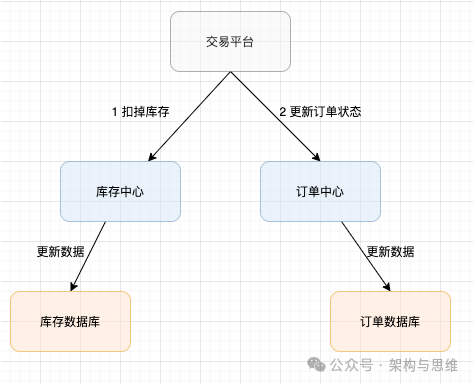
2.3.3 跨行转账场景
跨行转账问题也是一个典型的分布式事务,用户A同学向B同学的账户转账500,要先进行A同学的账户-500,然后B同学的账户+500,既然是不同的银行,涉及不同的业务平台,为了保证这两个操作步骤的一致,分布式事务必然要被引入。

常见的分布式一致性保障有如下方案
3.1 XA 两阶段提交协议
两阶段提交协议(Two-phase commit protocol,简称2PC)是一种分布式事务处理协议,旨在确保参与分布式事务的所有节点都能达成一致的结果。此协议被广泛应用于许多分布式关系型数据管理系统,以完成分布式事务。
它是一种强一致性设计,引入一个事务协调者的角色来协调管理各参与者的提交和回滚,二阶段分别指的是准备(投票)和提交两个阶段。
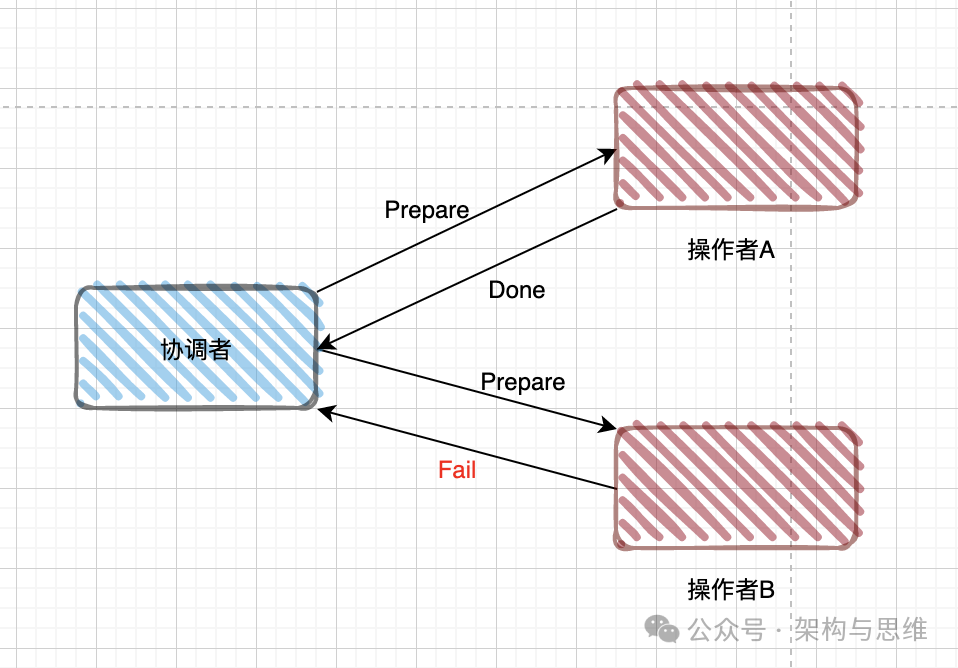
1、准备阶段(Prepare phase)
在此阶段,协调者询问所有参与者是否可以提交事务。如果参与者的事务操作实际执行成功,则返回一个"同意"消息;如果执行失败,则返回一个"终止"消息。
下面是两个参与者都执行成功的结果:

准备阶段只要有一个参与者返回失败,那么协调者就会向所有参与者发送回滚事务的请求,即分布式事务执行失败。如下图:
2、提交阶段(Commit phase)
协调者根据所有参与者的应答结果判定是否事务可以全局提交(Commit 请求),并通知所有参与者执行该决定。
如果所有参与者都同意提交,则协调者让所有参与者都提交事务,向事务协调者返回"完成"消息。整个分布式事务完成。
如果其中某个参与者终止提交,则协调者让所有参与者都回滚事务。

如果其中一个Commit 不成功,那其他的应该也是提交不成功的。
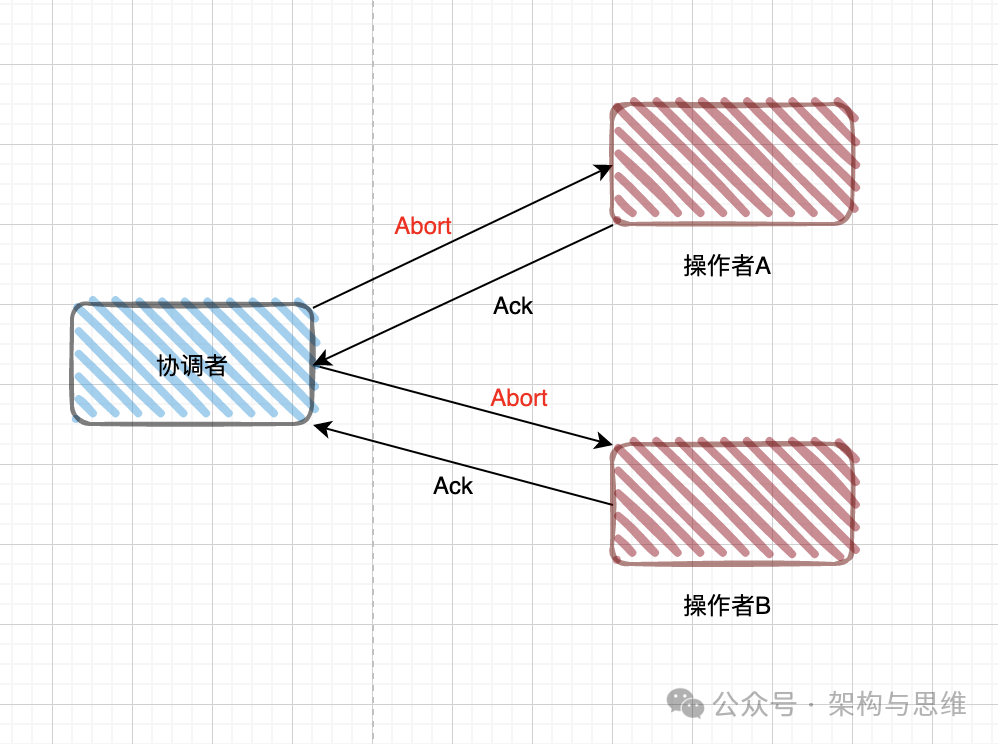
3.2 XA三阶段提交
三阶段提交:CanCommit 阶段、PreCommit 阶段、DoCommit 阶段,简称3PC
三阶段提交协议(Three-phase commit protocol,3PC),是二阶段提交(2PC)的改进版本。与两阶段提交不同的是,三阶段提交有两个改动点:在协调者和参与者中都引入超时机制,同时引入了预提交阶段。
在第一阶段和第二阶段中插入的预提交阶段,保证了在最后提交阶段之前各参与节点的状态是一致的。
即 3PC 把 2PC 的准备阶段再次一分为二,这样三阶段提交就有 CanCommit、PreCommit、DoCommit 三个阶段。当 CanCommit、PreCommit、DoCommit的任意一个步骤失败或者等待超时,执行RollBack。

通过引入PreCommit阶段,3PC在一定程度上解决了2PC中协调者单点故障的问题,因为即使协调者在PreCommit阶段后发生故障,参与者也可以根据自身的状态来决定是否提交事务。然而,3PC并不是完美的解决方案,它仍然有一些缺点,比如增加了协议的复杂性和可能的性能开销。因此,在选择是否使用3PC时,需要根据具体的业务场景和需求进行权衡。
3.3 MQ事务
利用消息中间件来异步完成事务的后半部分更新,实现系统的最终一致性。 这个方式避免了像XA协议那样的性能问题。
下面的图中,使用MQ完成事务在分布式的另外一个子系统上的操作,保证了动作一致性。所以整个消息的生产和消息的消费动作需要全部完成,才算一个事务结束。

3.4 TCC事务
TCC事务是Try、Confirm、Cancel三种指令的缩写,其逻辑模式类似于XA两阶段提交,但是实现方式是在代码层面人为实现。 2PC 和 3PC 都是数据库层面的,而 TCC 是业务层面的分布式事务。
这种事务模式特别适用于需要强一致性保证的分布式事务场景,除了上面提到的数据库层面的操作外,例如电商平台的订单系统、跨行转账、分布式资源预订系统以及金融交易处理等。
下图就是一个典型的分布式系统的原子性操作,涉及A、B、C三个服务的执行。 如果有一个服务 try 出问题,整个事务管理器就执行calcel,如果三个try都成功,才执行confirm做正式提交。

如图,TCC事务分为三个阶段执行:
-
Try阶段:主要是对业务系统做检测及资源预留。(执行2、3步骤)
-
Confirm阶段:确认执行业务操作。如果Try阶段成功,则执行Confirm操作,提交事务。(执行4、5步骤)
-
Cancel阶段:取消执行业务操作。如果Try阶段失败或超时,则执行Cancel操作,回滚事务。(执行4、5步骤)
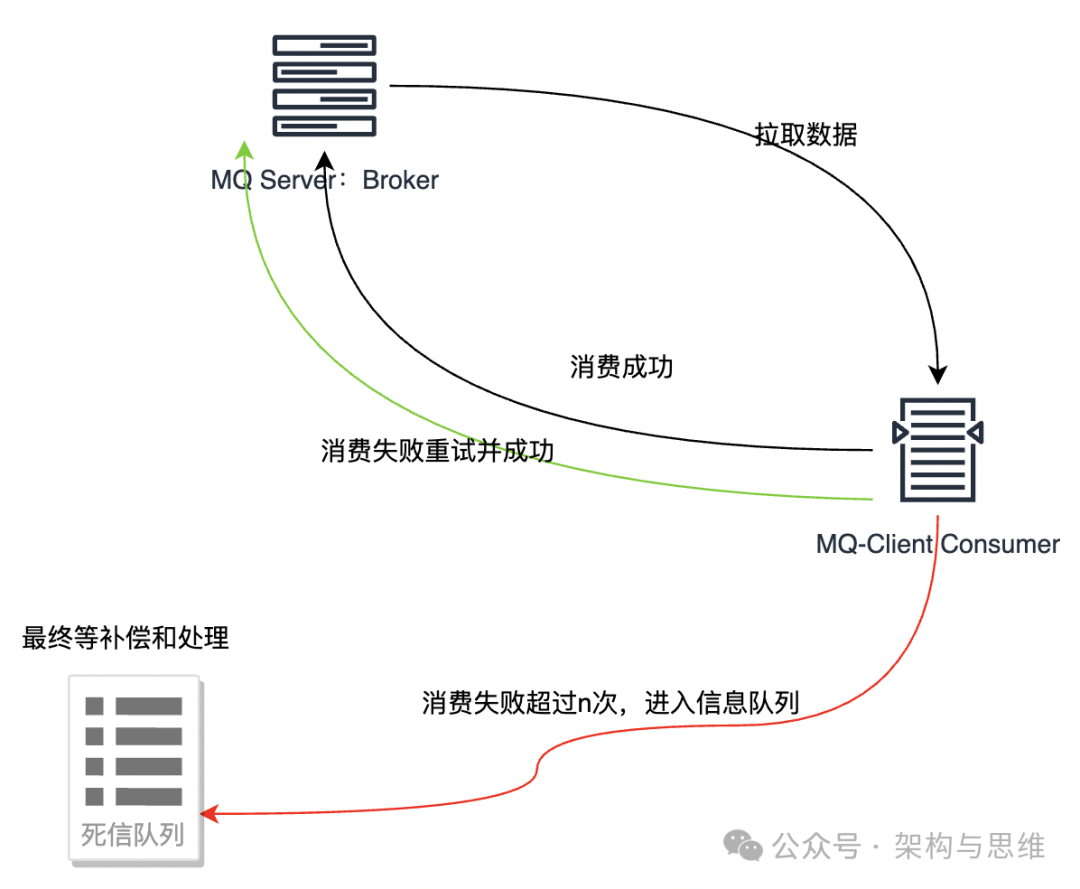
3.5 最终补偿机制,同MQ事务
最后使用补偿机制做最后的一致性保障,MQ方案尽量使用补偿机制进行保障。
如下图,对于发送成功,消费失败的消息,进入Dead-Letter Queu,使用单独的作业服务进行独立处理,比如重新发送死信消息进行消费,避免生产和消费的不一致,保证了最终的原子性、一致性。