你还记得某个周五下午5点半,本来准备愉快下班的你,突然被运营小姐姐的一个问题给拉回了现实:"技术哥哥,为什么我们的用户ID会重复啊?数据看起来好乱,这个月的报表没法做了...",你当时心里一紧,赶紧打开数据库一看,好家伙!用户表分了100张后,每张表的ID都从1开始自增,现在确实是一团糟:
makefile
-- 用户表分片情况
user_table_001: 用户ID 1, 2, 3, 4...
user_table_002: 用户ID 1, 2, 3, 4... ← 这不是重复了吗?
user_table_003: 用户ID 1, 2, 3, 4... ← 完全分不清谁是谁!这下可好,原本想通过分库分表提升性能,结果把自己给坑了。运营同学要做用户画像分析,结果发现同一个ID对应了100个不同的用户,这还怎么玩?看着运营小姐姐幽怨的眼神,我知道这个周末要加班了...
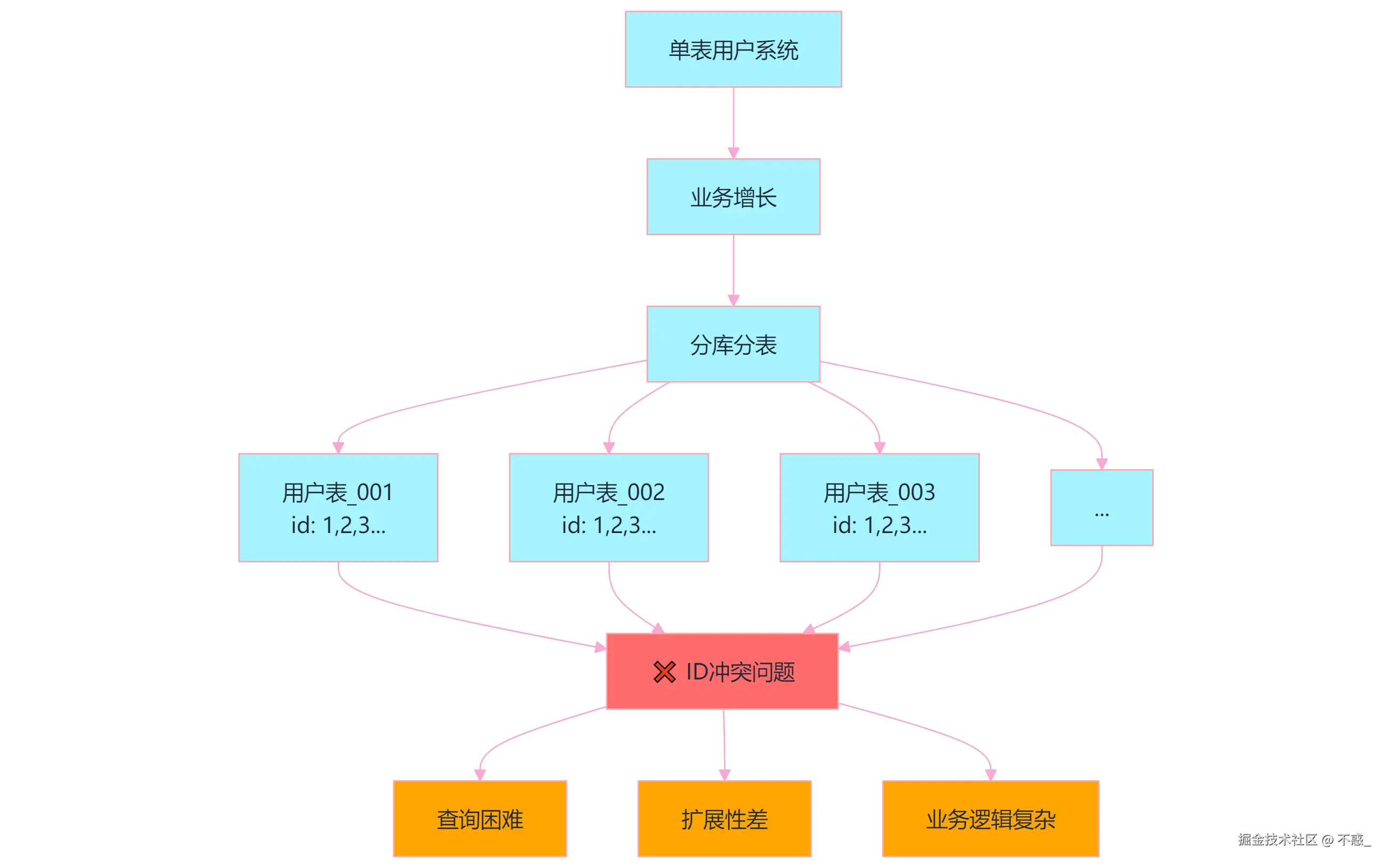
分库分表的甜蜜陷阱
说起分库分表,这可是每个后端工程师都会遇到的"成长烦恼"。刚开始做项目的时候,一张用户表走天下,简单粗暴,自增ID用得那叫一个爽:
ID从1开始,2、3、4...一路递增,多么美好的时光啊!但是好景不长,随着业务发展,用户量从1万变成10万,从10万变成100万,再从100万变成1000万...
性能问题接踵而至:
- 单表查询越来越慢,特别是分页查询
- 写入开始排队,TPS直线下降
- 数据库CPU经常飙到100%
- 备份和恢复时间越来越长
- 索引文件巨大,内存占用严重
这时候老板走过来拍拍你的肩膀:"小张啊,咱们这个系统能不能再快点?用户都在抱怨了..."于是,分库分表就成了救命稻草。我们把一张大表拆成了100张小表:
ini
-- 分表策略:按用户ID取模
user_00, user_01, user_02, ... user_99
-- 分表路由逻辑
table_suffix = user_id % 100;
table_name = "user_" + String.format("%02d", table_suffix);理论上,每张表只有原来1/100的数据量,查询速度嗖嗖的!但是等等,ID怎么办?
ID的三重困境
困境一:重复ID
最直接的问题就是ID重复。每张表都从1开始自增,结果就是:
scss
// 用户分布情况
User zhangsan = User.builder().id(1L).username("zhangsan").build(); // 在user_01表
User lisi = User.builder().id(1L).username("lisi").build(); // 在user_02表
User wangwu = User.builder().id(1L).username("wangwu").build(); // 在user_03表这下好了,当我们要根据ID查询用户信息时,完全不知道该去哪张表找!更要命的是,如果有关联表(比如订单表),外键都是user_id,现在一个user_id对应100个用户,这数据还有啥意义?
困境二:全局查询
假设产品经理走过来说:"我想看看ID为1000的用户的详细信息。"在单表时代,这个需求简单得不能再简单:
less
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT u FROM User u WHERE u.id = :id")
Optional<User> findById(@Param("id") Long id);
}
@Service
@Transactional(readOnly = true)
public class UserService {
@Autowired
private UserRepository userRepository;
public User findById(Long id) {
return userRepository.findById(id).orElse(null);
}
}但是在分表后,你需要这样做:
typescript
@Service
public class ShardedUserService {
@Autowired
private JdbcTemplate jdbcTemplate;
public User findById(Long id) {
// 天哪,要查100张表!
for (int i = 0; i < 100; i++) {
String tableName = "user_" + String.format("%02d", i);
String sql = "SELECT * FROM " + tableName + " WHERE id = ?";
try {
List<User> users = jdbcTemplate.query(sql,
new Object[]{id},
new BeanPropertyRowMapper<>(User.class));
if (!users.isEmpty()) {
return users.get(0);
}
} catch (DataAccessException e) {
// 这张表没有,继续找下一张
log.debug("表 {} 中未找到ID为 {} 的用户", tableName, id);
}
}
return null; // 找了100张表都没有
}
}想想就头皮发麻对不对?而且性能还贼差!
困境三:数据迁移
更可怕的是数据迁移。假设我们要把两张表合并,或者重新分片,ID冲突问题会让你想哭
diff
-- 原来的表
user_01: 1, 2, 3, 4, 5...
user_02: 1, 2, 3, 4, 5...
-- 要合并成一张表?ID全冲突!
-- 要重新分片?所有关联表的外键都要更新!难道要写个复杂的数据迁移脚本,手动重新分配ID?那关联表的外键怎么办?订单表、评论表、收藏表...想想就是一个噩梦...
各种解决方案的江湖恩怨
面对这个问题,江湖上出现了各种门派的解决方案:
UUID简单粗暴派
UUID就像是一个直男,虽然能解决问题,但是一点都不优雅。
less
@Entity
@Table(name = "user")
@Data
public class User {
@Id
@Column(name = "id", columnDefinition = "VARCHAR(36)")
private String id = UUID.randomUUID().toString();
private String username;
private String email;
}
@Service
@Transactional
public class UserService {
@Autowired
private UserRepository userRepository;
public User createUser(String username, String email) {
User user = User.builder()
.id(UUID.randomUUID().toString()) // 每次都生成新的UUID
.username(username)
.email(email)
.build();
return userRepository.save(user);
}
}优点:
- 全局唯一,绝对不会重复
- 生成简单,Spring Boot原生支持
- 分布式友好
- 无需额外配置
缺点:
- 36字符字符串,存储空间大(36字节 vs 8字节)
- 完全无序,数据库索引效率低
- 对用户不友好(谁能记住这么长的ID?)
- 作为外键时,关联查询性能差
- URL不美观
全局自增表中央集权派
这就像是皇帝制度,虽然管理简单,但是皇帝一挂,整个国家就乱了。
less
@Entity
@Table(name = "id_generator")
@Data
public class IdGenerator {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "business_type", length = 50)
private String businessType; // 'user', 'order', 'product'等
@Column(name = "stub", length = 1)
private String stub = ""; // 占位符
@CreationTimestamp
private LocalDateTime createdTime;
}
@Service
@Transactional
public class IdGeneratorService {
@Autowired
private IdGeneratorRepository idGeneratorRepository;
public Long generateId(String businessType) {
IdGenerator generator = IdGenerator.builder()
.businessType(businessType)
.stub("")
.build();
generator = idGeneratorRepository.save(generator);
return generator.getId();
}
}优点:
- ID简短、有序
- 全局唯一
- 实现简单
- 可以按业务类型分别生成
缺点:
- 单点故障风险
- 性能瓶颈(所有服务都要来这里获取ID)
- 高并发时容易成为系统瓶颈
- 数据库压力大
- 网络开销
号段模式批发零售派
这就像是批发商模式,虽然效率提高了,但是架构复杂度也上去了。
java
@Component
@Slf4j
public class SegmentIdGenerator {
private static final int DEFAULT_SEGMENT_SIZE = 1000;
private volatile long currentId;
private volatile long maxId;
private final Object lock = new Object();
@Autowired
private IdSegmentRepository segmentRepository;
public long generateId(String businessType) {
synchronized (lock) {
if (currentId >= maxId) {
// 获取新的号段
IdSegment segment = segmentRepository.getNextSegment(businessType, DEFAULT_SEGMENT_SIZE);
currentId = segment.getMinId();
maxId = segment.getMaxId();
log.info("获取新号段: [{}, {}] for {}", currentId, maxId, businessType);
}
return ++currentId;
}
}
}
@Repository
public class IdSegmentRepository {
@Autowired
private JdbcTemplate jdbcTemplate;
@Transactional
public IdSegment getNextSegment(String businessType, int segmentSize) {
// 原子性地获取号段
String updateSql = "UPDATE id_segment SET current_value = current_value + ? WHERE business_type = ?";
int updated = jdbcTemplate.update(updateSql, segmentSize, businessType);
if (updated == 0) {
// 首次使用,插入记录
String insertSql = "INSERT INTO id_segment (business_type, current_value) VALUES (?, ?)";
jdbcTemplate.update(insertSql, businessType, segmentSize);
}
String selectSql = "SELECT current_value FROM id_segment WHERE business_type = ?";
Long maxId = jdbcTemplate.queryForObject(selectSql, Long.class, businessType);
return IdSegment.builder()
.minId(maxId - segmentSize + 1)
.maxId(maxId)
.build();
}
}优点:
- 减少数据库访问次数
- ID有序
- 一定程度上解决了性能问题
- 可以根据业务压力调整号段大小
缺点:
- 实现复杂
- 服务重启会浪费号段
- 仍然依赖中央服务
- 需要预估号段大小
Redis自增内存加速派
优点: 性能极高,内存操作,实现简单,支持过期时间,原子性操作,Spring Boot集成方便
缺点: 依赖Redis,增加了系统复杂度,Redis宕机会导致ID生成失败,重启后ID可能不连续,需要考虑Redis持久化
typescript
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
return template;
}
}
@Component
@Slf4j
public class RedisIdGenerator {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public long generateId(String businessType) {
String key = "id_generator:" + businessType;
Long id = redisTemplate.opsForValue().increment(key);
if (id == null) {
throw new RuntimeException("Redis生成ID失败");
}
return id;
}
public long generateIdWithExpire(String businessType, Duration expireTime) {
String key = "id_generator:" + businessType;
Long id = redisTemplate.opsForValue().increment(key);
redisTemplate.expire(key, expireTime);
return id != null ? id : 0L;
}
}王者归来
就在大家为ID问题焦头烂额的时候,Twitter开源了一个叫Snowflake的算法,一下子就征服了整个技术圈。为什么这么牛?因为它完美解决了所有痛点:
✅ 全局唯一 - 绝对不会重复
✅ 趋势递增 - 对数据库索引友好
✅ 高性能 - 单机每秒400万个ID
✅ 分布式 - 不依赖中央服务
✅ 信息丰富 - 可以解析出时间等信息
✅ 长度适中 - 64位长整型,存储高效
✅ Spring Boot友好 - 易于集成
这简直就是ID生成界的"六边形战士"!
Snowflake算法深度解析
64位ID的精妙设计
Snowflake的核心思想是把一个64位的长整型数字分成几个部分:
diff
Snowflake ID 结构 (64位)
+----------+----------+----------+----------+
| 1位符号位 | 41位时间戳 | 10位机器ID | 12位序列号 |
+----------+----------+----------+----------+
| 0 | 时间 | 机器 | 序列 |
+----------+----------+----------+----------+让我们逐个分析:
1位符号位:礼貌的保留
虽然不用,但是保留符号位,确保生成的ID永远是正数。这就像是给别人让座一样,虽然自己不坐,但是体现了良好的教养。
41位时间戳:时间就是金钱
存储毫秒级时间戳与起始时间的差值。41位能表示2^41 ≈ 2.2万亿毫秒,也就是约69年!
csharp
// 时间戳计算示例
public class SnowflakeTimeExample {
// 起始时间:2021-01-01 00:00:00
private static final long EPOCH = 1609459200000L;
public static void main(String[] args) {
long currentTime = System.currentTimeMillis();
long timestamp = currentTime - EPOCH;
// 41位最大值:2^41 - 1 = 2199023255551
long maxTimestamp = (1L << 41) - 1;
long maxYear = EPOCH + maxTimestamp;
System.out.println("当前时间: " + new Date(currentTime));
System.out.println("相对时间戳: " + timestamp);
System.out.println("可用到: " + new Date(maxYear)); // 2090年左右
}
}如果我们把起始时间设为2021年1月1日,那么可以用到2090年。等到那时候,要么我们已经退休享受人生,要么人类已经移民火星了,反正不用我们操心了😄
10位机器ID:分工合作
支持最多1024台机器同时生成ID。这个数量对于绝大多数公司来说都够用了。就算是BAT这种体量的公司,专门用来生成ID的机器也用不了这么多。
还可以进一步拆分成5位数据中心ID + 5位机器ID,支持32个数据中心,每个数据中心32台机器。
csharp
// 机器ID分配示例
public class WorkerIdExample {
public static void main(String[] args) {
int datacenterId = 1; // 数据中心ID (0-31)
int machineId = 1; // 机器ID (0-31)
int workerId = (datacenterId << 5) | machineId; // 组合成10位
System.out.println("数据中心ID: " + datacenterId);
System.out.println("机器ID: " + machineId);
System.out.println("组合WorkerID: " + workerId);
}
}12位序列号:争分夺秒
同一毫秒内可以生成4096个不同的ID。也就是说,单台机器的理论QPS是:
csharp
// 性能计算
public class PerformanceCalculation {
public static void main(String[] args) {
int maxSequence = (1 << 12) - 1; // 4095
int theoreticalQPS = maxSequence * 1000; // 4,095,000/秒
System.out.println("单毫秒最大序列号: " + maxSequence);
System.out.println("理论QPS: " + theoreticalQPS); // 409.5万/秒
System.out.println("这性能,说出去都没人敢信!");
}
}这个性能,说出去都没人敢信!