springboot集成链路追踪
- springboot版本
xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>- 添加链路追踪sleuth依赖
链路追踪有很多优秀的中间件,比如skywalking等,但是skywalking需要部署oap服务生成追踪id,为了减少架构复杂度,决定采用sleuth。
xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>3.1.1</version>
</dependency>想进一步减少架构复杂度,也可以自定义生成traceId,可以参考之前的文章实现
https://blog.csdn.net/qq_41633199/article/details/127482748?spm=1001.2014.3001.5502
kafka2.7.1设置
- windows下载kafka
https://archive.apache.org/dist/kafka/2.7.1/kafka_2.13-2.7.1.tgz - zk设置
- 修改数据存储路径


- 启动zk
kafka安装目录执行以下命令
- 修改数据存储路径
bash
bin\windows\zookeeper-server-start.bat config\zookeeper.properties- kafka设置
- 配置数据存储


- 配置zk连接

- 启动
- 配置数据存储
bash
## 启动kafka
bin\windows\kafka-server-start.bat config\server.properties
## 创建主题
bin\windows\kafka-topics.bat --zookeeper localhost:2181 --create --replication-factor 1 --partitions 1 --topic app_log
## 查看主题
bin\windows\kafka-topics.bat --list --zookeeper localhost:2181
# 生产消息
bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic app_log
# 消息消费
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic app_log --group app_log --from-beginning应用日志logback配置
由于java异常日志输出堆栈的换行符会影响kafka engine日志解析(会当成多条日志分别解析导致报错),因此在FILE_FORMAT配置输出到日志文件的时候去除换行符。
xml
<property name="CONSOLE_FORMAT" value="%highlight(%d{yyyy-MM-dd HH:mm:ss.SSS})|%highlight(%-5level{FATAL=Bright Red, ERROR=Bright Magenta, WARN=Bright Yellow, INFO=Bright Green, DEBUG=Bright Cyan, TRACE=Bright White})|%boldMagenta(%X{traceId})|%yellow(%thread)|%boldMagenta(%logger{36})|%green(%file#%method:%line)|%cyan(%msg%n)"/>
<property name="FILE_FORMAT" value="%d{yyyy-MM-dd HH:mm:ss.SSS}|%level|%X{traceId}|%thread|%logger{36}|%file#%method:%line|%msg %replace(%ex){'[\r\n]+', ''}%nopex%n"/>
<appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 日志文件输出的文件名 -->
<FileNamePattern>${LOG_HOME}/info/bill_log.%d{yyyy-MM-dd_HH}.log</FileNamePattern>
<!-- 日志文件保留个数 -->
<maxHistory>168</maxHistory>
<cleanHistoryOnStart>true</cleanHistoryOnStart>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>${FILE_FORMAT}</pattern>
</encoder>
</appender>
<!-- 开发环境 -->
<springProfile name="dev">
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${CONSOLE_FORMAT}</pattern>
</encoder>
</appender>
<root level="DEBUG">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="INFO_FILE"/>
</root>
</springProfile>filebeat7.16.2收集应用日志推送kafka
- 下载
bash
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.16.2-windows-x86_64.zip- 修改配置
kafka配置官网参考地址
bash
https://www.elastic.co/guide/en/beats/filebeat/7.16/kafka-output.html

设置传输kafka
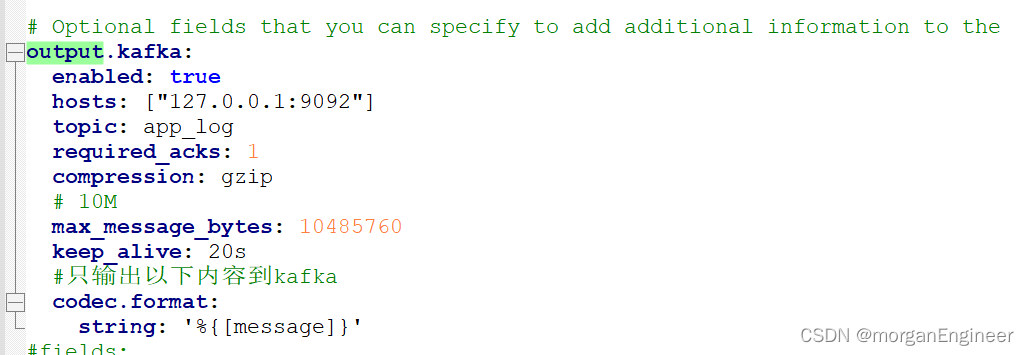 确保output只有一个
确保output只有一个
- 启动filebeat
在安装目录执行启动命令
powershell
filebeat -e -c filebeat.yml访问应用查看kafka消费效果


clickhouse设置
- 宿主机配置host
bash
172.27.x.x host.docker.internal由于clickhouse容器需访问本机kafka,需要解决通信问题
- 启动
powershell
docker run -d --network=bridge -p 8123:8123 -p 9000:9000 -p 9009:9009 --name clickhouse-svr --add-host="host.docker.internal:172.27.xx.x" clickhouse/clickhouse-server:24.4.3.25- 进入容器,执行命令设置分隔符保存到users.xml配置文件,以便重启容器后也能生效
这里的设置主要取决于日志格式,我的项目是|号作为字段分隔符
bash
set format_csv_delimiter = '|';- 连接clickhouse,设置允许查询引擎表
bash
clickhouse-client --stream_like_engine_allow_direct_select 1- 选择数据库
bash
use log;- 创建kafka引擎表
sql
CREATE TABLE LOG_KAFKA
(
time DateTime64(3, 'Asia/Shanghai'),
level String,
trace_id String,
thread String,
logger String,
method String,
msg String
)
ENGINE = Kafka()
SETTINGS kafka_broker_list = 'host.docker.internal:9092',
kafka_topic_list = 'app_log',
kafka_group_name = 'app_log',
kafka_num_consumers = 1,
kafka_format = 'CSV',
format_csv_delimiter = '|';- 创建分区日志表,存储日志消息
bash
create table APP_LOG(
time DateTime64(3, 'Asia/Shanghai'),
level String,
trace_id String,
thread String,
logger String,
method String,
msg String
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(time)
ORDER BY time;
## 创建Metrialized View 抓取数据到日志表
CREATE MATERIALIZED VIEW vw_app_log TO APP_LOG AS
SELECT time,level,trace_id,thread,logger,method,msg FROM LOG_KAFKA;- 访问应用生产日志消息并查看clickhouse日志

配置ClickVisual
-
windows docker安装
官方文档地址
https://clickvisual.net/zh/clickvisual/02install/docker-installation.html -
下载配置文件到本地
https://github.com/clickvisual/clickvisual/tree/master/data/all-in-one/clickvisual/config -
配置mysq数据库连接

 *允许mysql用户通过ip连接
*允许mysql用户通过ip连接

-
指定数据卷创建容器
bash
docker run --name clickvisual -e EGO_CONFIG_PATH=/clickvisual/config/docker.toml -e EGO_LOG_WRITER=stderr -p 19001:19001 -v D:\download\clickvisual\config:/clickvisual/config -d clickvisual/clickvisual:latest- 配置数据连接
用初始账号与密码clickvisual/clickvisual登录管理台http://localhost:19001
点击初始化数据库后进入日志库配置页
 clickhouse数据源连接格式clickhouse://username:password@host1:9000,host2:9000/database?dial_timeout=200ms&max_execution_time=60,因为我未给clickhouse设置权限认证,因此username:password@可以省略
clickhouse数据源连接格式clickhouse://username:password@host1:9000,host2:9000/database?dial_timeout=200ms&max_execution_time=60,因为我未给clickhouse设置权限认证,因此username:password@可以省略
 创建好实例后回到日志页面,选择刚创建的实例右键接入已有日志库,配置日志数据表
创建好实例后回到日志页面,选择刚创建的实例右键接入已有日志库,配置日志数据表

查看效果
访问前面写的空指针异常接口,再刷新ClickVisual页面

通过链路id查询效果
