TL;DR
- 场景:高并发读多写少业务,数据库顶不住,需要提升吞吐与稳定性。
- 结论:本地缓存做极致读性能,分布式缓存做共享与扩展,多级缓存兼顾一致性与成本。
- 产出:可对照的版本矩阵与错误速查卡,直接用于评审与排障。

版本矩阵
| 组件/能力 | 版本/年份 | 已验证 | 说明 |
|---|---|---|---|
| 本地缓存:Guava Cache | 32.x(2025) | 是 | 文中含示例与特性(容量/过期/并发/统计/刷新);适合高频读、低变化数据。 |
| 本地缓存:Ehcache | 3.x(2025) | 否 | 仅概述特性,暂无代码/配置展示;如上生产需补充示例与基准。 |
| 分布式缓存:Redis | 7.2(2024--2025) | 是 | 覆盖旁路/穿透/写回与分布式锁(SETNX+过期/续期);建议与本地缓存做多级组合。 |
| 会话:Spring Session + Redis | 3.x(2025) | 部分 | 方案被提及,未给出配置与失效策略细节;上线需补 TTL/索引与压测报告。 |
| 分布式锁实现 | SETNX + 过期(2025) | 是 | 已给注意点(续期/死锁);若需更稳妥可评估 Redisson watchdog(未在正文引入)。 |
| 语言/运行时 | Java 17(2025) | 部分 | 示例可在 JDK17 编译运行;如生产用需结合 GC/堆大小评审本地缓存容量。 |
| 架构形态 | 多级缓存(Local + Redis) | 是 | 已提出"多级"思路;建议补充一致性与失效广播策略(如消息/订阅)。 |
| 数据库分片/读写分离 | MySQL(2025) | 部分 | 原则已覆盖;细节如路由/热点 Key 需结合实际库表/索引策略完善。 |
缓存使用
使用场景
互联网时代数据爆发式增长,用户规模不断扩大,系统面临着越来越高的并发量和吞吐量需求。在这样的背景下,传统数据库架构面临着严峻挑战:
- 数据库存储优化方案
- 分库分表:当单表数据量超过500万条时,查询性能显著下降。采用水平分表(按ID范围或哈希)、垂直分表(按业务字段)等方式拆分数据
- 读写分离:主库负责写操作,多个从库分担读请求,典型配置是1主3从
- 但这些方案仍存在瓶颈,特别是在高并发场景下
- 缓存系统的关键作用
- 减轻数据库压力:将热点数据(如电商商品详情、社交平台用户信息)存储在Redis等内存数据库中,TPS(每秒事务数)可从数据库的2000提升至缓存的50000+
- 典型缓存策略:
- 旁路缓存模式(Cache Aside)
- 读写穿透模式(Read/Write Through)
- 写回模式(Write Behind)
- 临时数据存储场景
- 短时效数据:验证码(通常5分钟过期)、临时会话数据
- 计算中间结果:大数据分析的MapReduce中间数据
- 去重处理:使用Redis的Set结构存储最近1小时访问用户ID
- 其他重要应用场景
-
Session分离:
- 在集群环境中将会话数据集中存储
- 典型实现:Spring Session + Redis
- 支持水平扩展,避免粘性会话问题
-
分布式锁:
- 解决跨进程资源竞争问题
- Redis实现方式:SETNX+过期时间
- 注意事项:锁续期、避免死锁
- 应用场景:秒杀系统库存扣减、定时任务调度
- 性能对比数据
- MySQL单机QPS:约2000-4000
- Redis单机QPS:约10万
- 缓存命中率建议维持在80%-95%之间
本地缓存(Local Cache)
概念与定义
本地缓存(Local Cache)是指将数据存储在应用程序所在服务器的内存中,通过内存直接访问数据的缓存机制。它属于进程内缓存,与应用程序运行在同一个JVM进程中。
常见实现方式
- 基础实现 :
- 使用Java集合框架中的
ConcurrentHashMap作为简单的键值存储 - 示例代码:
- 使用Java集合框架中的
java
ConcurrentHashMap<String, Object> cache = new ConcurrentHashMap<>();
cache.put("key", "value");- 专业缓存框架 :
- Ehcache :成熟的Java缓存框架,支持内存和磁盘存储
- 特性:LRU淘汰策略、缓存持久化、分布式支持
- Guava Cache :Google提供的轻量级缓存工具
- 特性:自动加载、过期策略、缓存回收监听
- Ehcache :成熟的Java缓存框架,支持内存和磁盘存储
存储位置与特点
- 存储位置:JVM堆内存中(可通过配置使用堆外内存)
- 生命周期:与应用程序进程绑定,重启后数据丢失
- 数据冗余:在集群环境下,每个应用实例都维护自己的缓存副本
性能优势
-
访问速度快:
- 内存级访问速度(纳秒级)
- 无网络I/O开销
- 示例:相比Redis的毫秒级访问,本地缓存快100-1000倍
-
降低外部依赖:
- 减少对远程缓存服务(如Redis)的调用
- 在网络隔离时仍可提供服务
局限性
-
容量限制:
- 受JVM堆内存大小制约(通常GB级别)
- 大容量缓存可能导致GC压力
-
一致性问题:
- 集群环境下数据同步困难
- 示例:商品库存缓存,不同节点可能显示不一致
-
功能局限:
- 缺乏专业的持久化机制
- 分布式能力较弱(需借助额外组件)
典型应用场景
-
高频读取的低变化数据:
- 系统配置信息
- 静态字典数据
-
性能敏感场景:
- 实时交易系统的参考数据缓存
- 算法计算的中间结果缓存
-
临时数据存储:
- 用户会话信息
- 页面片段缓存
最佳实践建议
- 设置合理的过期时间
- 实现缓存预热机制
- 监控缓存命中率
- 对大对象考虑序列化存储
- 在分布式环境中配合使用广播机制更新缓存
分布式缓存
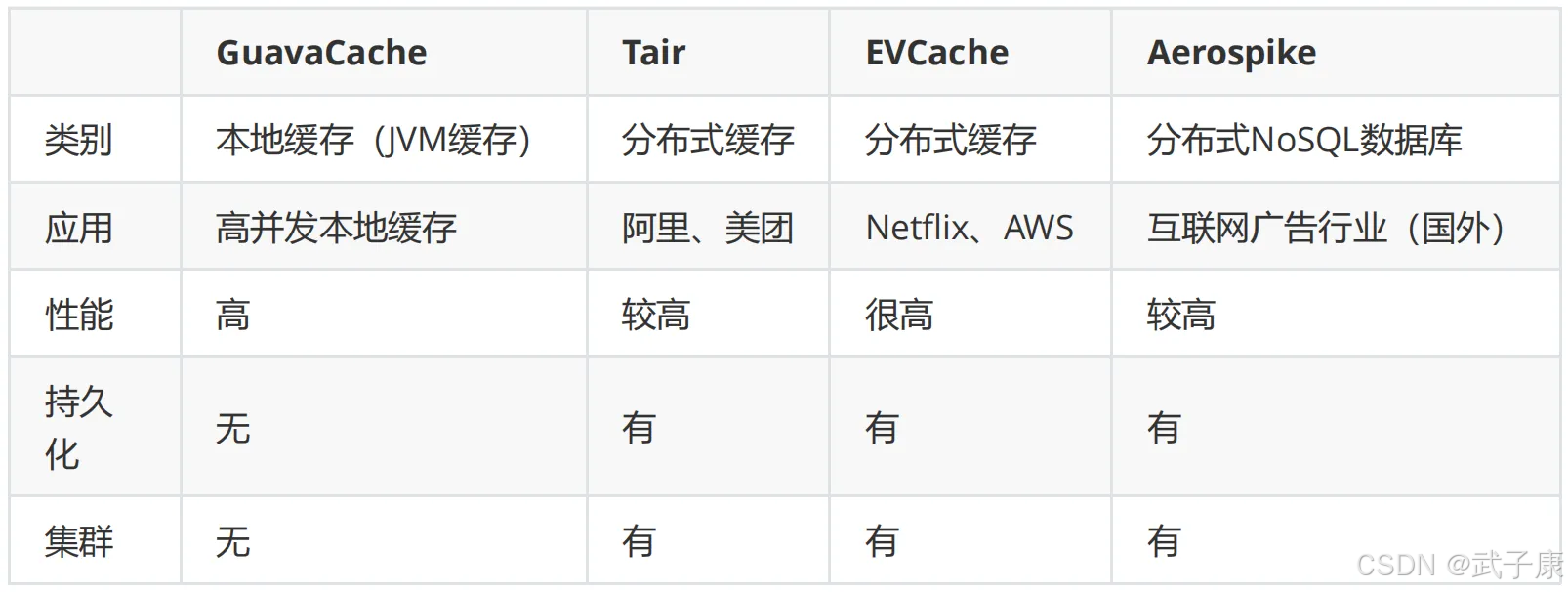
主流分布式缓存系统
- Redis:支持多种数据结构(字符串、哈希、列表等),提供持久化功能
- Memcached:简单高效的键值存储,专注于缓存场景
- Tair:阿里和美团开发的分布式KV存储系统,支持多种引擎
- EVCache:AWS提供的分布式缓存服务,专为云环境优化
- Aerospike:高性能NoSQL数据库,具有强一致性和低延迟特性
核心优势
-
空间优势:
- 内存存储提供纳秒级访问速度
- 示例:电商平台商品详情页缓存可降低数据库查询压力
-
数据共享:
- 跨应用共享数据(如用户Session)
- 实现方案:通过统一缓存层实现多服务间的状态共享
-
高可用性:
- 主从复制架构(如Redis Sentinel)
- 自动故障转移机制保障服务连续性
-
高扩展性:
- 分区(Sharding)技术实现水平扩展
- 动态扩容能力应对业务增长
潜在挑战
-
资源成本:
- 内存资源相对昂贵
- 需要权衡缓存大小与成本效益
-
网络开销:
- 跨节点通信引入额外延迟
- 解决方案:采用本地缓存+分布式缓存的多级架构
-
数据一致性:
- BASE理论下的最终一致性(AP系统)
- 典型场景:缓存与数据库双写可能产生短暂不一致
- 应对策略:设置合理的过期时间或采用缓存更新策略
典型应用场景
- 热点数据加速访问
- 会话状态管理
- 秒杀系统库存缓存
- 全页缓存(FPC)
- 分布式锁实现## 分布式缓存
缓存对比
Guava Cache
JVM缓存
JVM缓存,是堆缓存,其实就是创建一些全局容器,比如List、Map、Set等等,这些容器用来做数据存储。但是不能按照一定的规则淘汰数据,如 LRU、LFU、FIFO 等。
清除数据时的回调通知:并发处理能力差,针对并发的时候可以用 CurrentHashMap,但缓存的其他功能需要自行实现缓存过期处理,缓存数据加载刷新等都需要手工实现。
Guava Cache 详解
Guava 是 Google 提供的一套开源的 Java 核心工具库,包含了集合、缓存、并发、字符串处理、I/O 等众多实用工具。其中 Guava Cache 是一个功能完善的本地缓存实现,运行在 JVM 堆内存中。
核心特性
-
自动加载机制:
- 支持在缓存未命中时自动从数据源加载值
- 提供 CacheLoader 接口实现自动加载逻辑
- 示例:
LoadingCache<Key, Value> cache = CacheBuilder.newBuilder().build(new CacheLoader<Key, Value>() {...});
-
多种缓存回收策略:
- 基于容量:当缓存项数量超过指定值时回收
- 基于时间 :
- 访问过期(expireAfterAccess)
- 写入过期(expireAfterWrite)
- 基于引用:使用弱引用或软引用存储键或值
- 手动回收:支持显式调用 invalidate 方法
-
高性能并发支持:
- 采用类似 ConcurrentHashMap 的并发设计
- 细粒度的锁机制保证高并发读写性能
- 统计功能:支持命中率、加载时间等统计
使用场景
- 高频访问数据缓存:如数据库查询结果、API调用结果
- 计算成本高的数据:如复杂计算结果
- 临时数据存储:需要自动过期的临时数据
基础用法示例
java
LoadingCache<Key, Value> cache = CacheBuilder.newBuilder()
.maximumSize(1000) // 最大容量
.expireAfterWrite(10, TimeUnit.MINUTES) // 写入10分钟后过期
.recordStats() // 开启统计
.build(
new CacheLoader<Key, Value>() {
public Value load(Key key) throws Exception {
return createExpensiveValue(key); // 自动加载逻辑
}
});
// 获取缓存值
Value value = cache.get(key);高级功能
- 刷新机制:支持异步刷新缓存值
- 移除监听器:可以监听缓存项的移除事件
- 批量操作:支持 getAll 等批量操作方法
- 权重计算:支持自定义缓存项的权重计算方式
Guava Cache 通过灵活的配置选项和强大的功能,为 Java 应用提供了高效的本地缓存解决方案,特别适合需要精细控制缓存行为的应用场景。
应用场景
本地缓存的应用场景:
● 对性能有非常高的要求
● 不经常变化
● 占用内存不大
● 有访问整个集合的需求
● 数据允许不时时一致
● Guava:高并发,不需要持久化
● CurrentHashMap:高并发
● Ehcached:持久化,二级缓存
项目优势
缓存过期和淘汰机制
在 Guava Cache中可以设置 Key 的过期时间,包括访问过期和创建过期
Guava Cache在缓存容量达到指定大小时,采用LRU的方式,将不常用使用键值从Cache中删除
并发处理能力
Guava Cache 类似 CurrentHashMap,是线程安全的,提供了设置并发级别的API,使得缓存支持并发的写入和读取,采用分离锁机制,分离锁能够减小锁力度,提升并发能力。
分离锁是分拆锁定,把一个集合看分成若干 partition,每个partition一把锁,CurrentHashMap就是分了16个区域,这16个区域是可以并发的,Guava Cache采用Segment做分区。
更新锁定
一般情况下,在缓存中查询某个key,如果不存在,则查源数据,并回填缓存(Cache Aside Pattern)
在高并发下会出现,多次查源并重复回填缓存,可能会造成源的宕机(DB),性能下降。
Guava Cache 可以在 Cache Loader 的 load 方法中加以控制,对同一个key,只让一个请求去读源并回填缓存,其他请求阻塞等待。
集成数据源
一般我们在业务中操作缓存,都会操作缓存和数据源两部分,而 Guava Cache 可以集成数据源,在从缓存中读取不到数据的时候,从数据源读取并回填。
监控情况
可以监控缓存加载/命中情况,统计
错误速查
| 症状 | 根因定位 | 修复方案 |
|---|---|---|
| 请求突增后 DB/Redis 抖动、RT 飙升 | 缓存击穿(热点 Key 失效瞬间大量回源) | 查看失效窗口内单 Key QPS、DB 慢查 热点 Key 逻辑过期 + 互斥重建/单飞(single flight)+ 预热 |
| 命中率低、后端被打穿 | 缓存穿透(大量不存在 Key) | 命中率跌至 <60%,后端 404/空结果多 布隆过滤器/负缓存(短 TTL)、参数校验、限流 |
| 大面积超时并发报错 | 缓存雪崩(同批 Key 同时过期) | TTL 同质化、相同时间点抖动 TTL 加随机抖动、分批失效、热点永不过期+异步刷新 |
| 某些节点数据"看起来不一致" | 本地缓存与分布式缓存失效不同步 | 节点间值差异、更新时间戳不一致 失效广播(Pub/Sub/消息队列)、版本戳/逻辑时钟、缩短 TTL |
| 频繁 Full GC、应用卡顿 | 本地缓存容量过大/大对象过多 | GC 日志停顿长、堆占用高 限制 maximumSize/weight、对象池化、分层放置(堆外/分布式) |
| Redis CPU 高、带宽打满 | 大 Key/Big Value 或热 Key 集中 | bigkey 分析、热点分布 拆分大 Key、压缩/二进制序列化、读写分摊/热点多副本 |
| 锁住却不释放/业务停摆 | 分布式锁未续期或时钟漂移 | 看到大量持锁超时/任务僵死 加 watchdog 续期、用 Lua 原子解锁、校准时钟、尽量短持锁 |
| 缓存与数据库"偶发不一致" | 双写竞争或失败重试不当 | 对账发现少量脏读 明确以 DB 为准、写后删缓存/延迟双删、事件驱动更新 |
| QPS 提升有限 | 序列化膨胀/网络往返过多 | 平均 payload 大、网延高 紧凑序列化(Kryo/Protostuff/JsonLite)、批量/管道/本地化 |
| 预热后仍冷启动慢 | 预热覆盖不足或启动顺序问题 | 启动阶段命中率低 扩大预热集合、启动后后台刷新、灰度逐步放量 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接