0. YOLOv10简介
YOLOv10是清华大学最近开源的一个实时端到端的目标检测算法,解决了以往版本YOLO系列目标检测算法在后处理和模型架构方面的不足。通过消除非极大值抑制(NMS)操作和优化模型架构,YOLOv10在显著降低计算开销的同时还实现了最先进的性能。
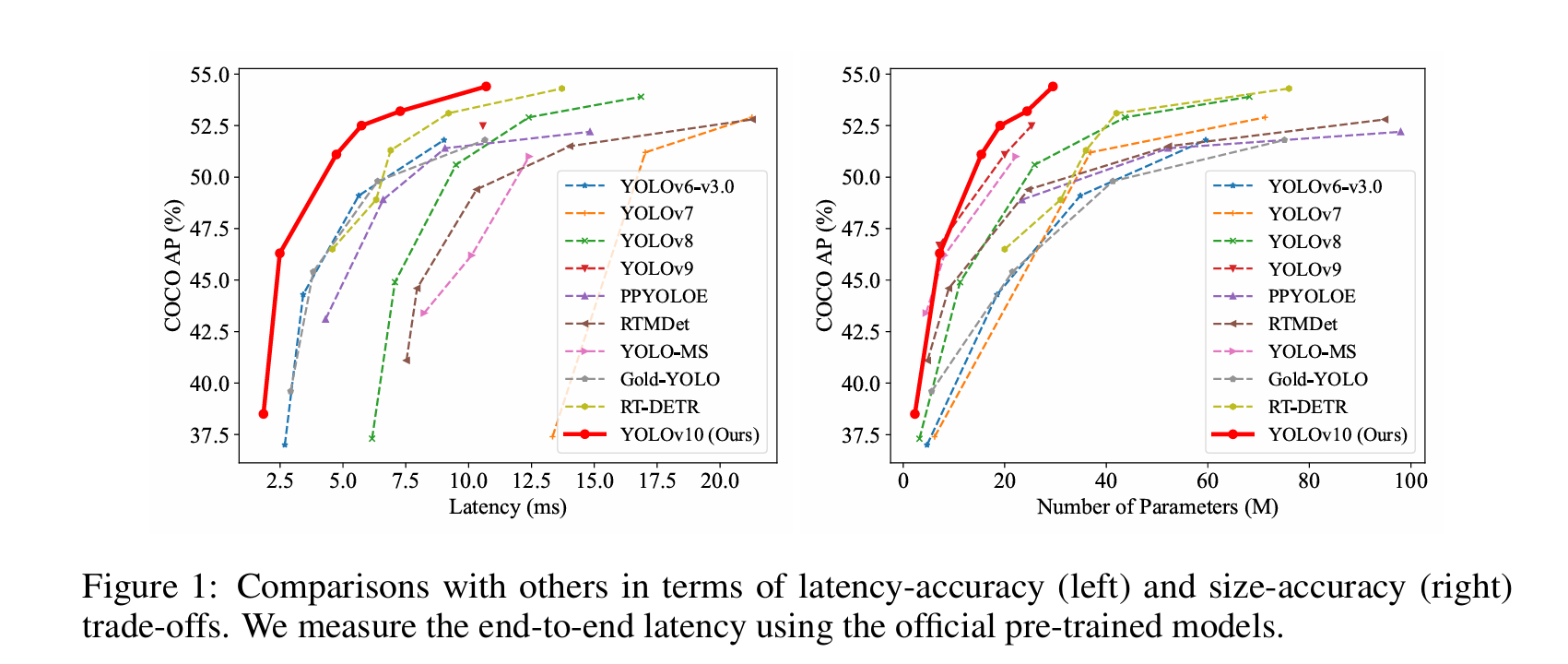
YOLOv10的模型架构由以下几个部分组成:
- 主干网络:使用增强版的
CSPNet来提取图像特征,它能改善梯度流并减少计算量。 - 颈部:采用
PAN结构汇聚不同尺度的特征,有效地实现多尺度特征融合。 - 一对多预测头:在训练过程中为每个对象生成多个预测,用来提供丰富的监督信号从而提高学习的准确性;在推理阶段不生效,从而减少计算量。
- 一对一预测头:在推理过程中为每个对象生成一个最佳预测,无需
NMS操作,从而减少延迟并提高推理效率。
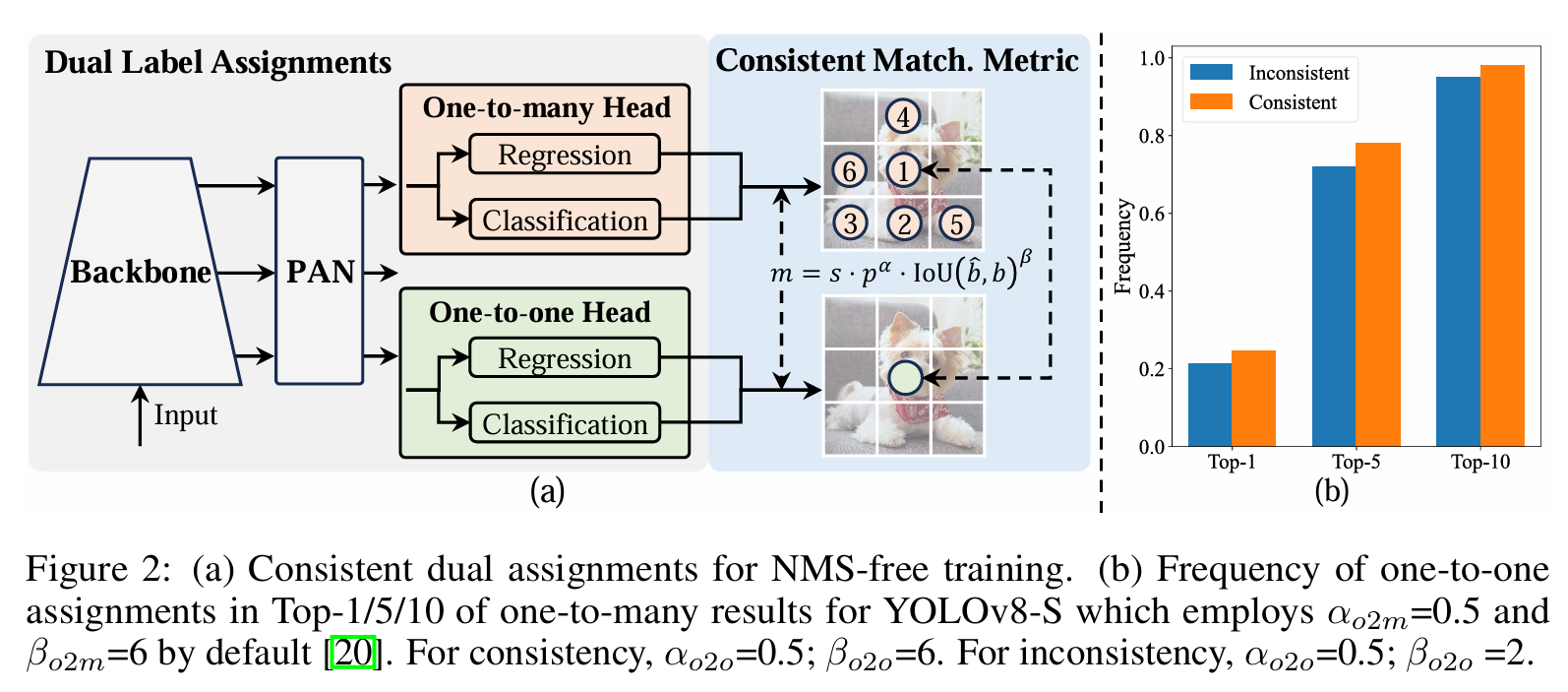
YOLOv10的主要特点如下:
- 利用一致的双重分配来消除对
NMS的需求,从而减少推理延迟。 - 从推理效率和准确性的角度出发全面优化各种组件,包括轻量级分类头、空间通道去耦下采样和等级引导块设计。
- 引入大核卷积和部分自注意模块,在不增加大量计算成本的情况下提高性能。
官方发布了从N到X各种型号的模型,以满足不同应用的需求:
YOLOv10-N:用于资源极其有限环境的超小型版本。YOLOv10-S:兼顾速度和精度的小型版本。YOLOv10-M:通用的中型版本。YOLOv10-B:平衡型,宽度增加,精度更高。YOLOv10-L:大型版本,精度更高,但计算资源增加。YOLOv10-X:超大型版本,可实现最高的精度和性能。
本文主要介绍如何基于ONNXRuntime框架部署onnx格式的YOLOv10模型,以及YOLOv10与RT-DETR等算法的性能对比。
1. 准备工作
首先把代码从GitHub上clone下来
shell
git clone https://github.com/THU-MIG/yolov10.git然后执行下面的命令用conda创建Python环境并安装相关的依赖库和YOLOv10
shell
conda create -n yolov10 python=3.9
conda activate yolov10
pip install -r requirements.txt
pip install -e .这里需要注意的是,如果使用的是低版本的pip,可能会报类似下面的错误:
shell
ERROR: File "setup.py" or "setup.cfg" not found. Directory cannot be installed in editable mode: /path/to/yolov10
(A "pyproject.toml" file was found, but editable mode currently requires a setuptools-based build.)这种情况需要升级pip的版本,最新版本24.0实测是没有问题的。
shell
pip install --upgrade pip安装成功后,从GitHub的release中下载PyTorch格式的模型权重,然后执行下面的命令就可以导出onnx模型了。
shell
yolo export model=yolov10n/s/m/b/l/x.pt format=onnx opset=13 simplify2. onnx模型部署
2.1 加载onnx模型
首先导入onnxruntime包,然后调用其API加载模型即可:
python
import onnxruntime as ort
session = ort.InferenceSession("yolov10m.onnx", providers=["CUDAExecutionProvider"])这里的providers参数根据自己的实际情况设置,我使用的是GPU所以设置的是"CUDAExecutionProvider"。如果用CPU进行推理,则需设置为"CPUExecutionProvider";如果有TensorRT的环境,还可以设置为"TensorrtExecutionProvider"。
模型加载成功后,我们可以查看一下模型的输入、输出层的属性:
python
for input in session.get_inputs():
print("input name: ", input.name)
print("input shape: ", input.shape)
print("input type: ", input.type)
for output in session.get_outputs():
print("output name: ", output.name)
print("output shape: ", output.shape)
print("output type: ", output.type)结果如下:
shell
input name: images
input shape: [1, 3, 640, 640]
input type: tensor(float)
output name: output0
output shape: [1, 300, 6]
output type: tensor(float)从上面的打印信息可以知道,模型有一个尺寸为[1, 3, 640, 640]的输入层和一个尺寸分别为[1, 300, 6]的输出层。
2.2 数据预处理
用OpenCV读入图片后,首先需要对图片做预处理:
python
image = cv2.imread("soccer.jpg")
print("image shape: ", image.shape)
image_height, image_width, _ = image.shape
_, _, model_height, model_width = session.get_inputs()[0].shape
input_tensor, ratio, x_offset, y_offset = preprocess(image,
image_width, image_height, model_width, model_height)YOLOv10在做数据预处理的时候是对原始图像做等比例缩放的,如果缩放后的图像某个维度上比目标值小,那么就需要进行填充。举个例子:假设输入图像尺寸为1920x1058,模型输入尺寸为640x640,按照等比例缩放的原则缩放后的图像尺寸为640x352,那么在y方向上还需要填充640-352=288,即分别在图像的顶部和底部各填充144行像素。最终实现的效果如下:

整个数据预处理的流程如下:
- 把
OpenCV读取的BGR格式图片转换为RGB格式; - 计算缩放比例和需要填充的区域,把原始图片进行等比例缩放,对不足的区域进行填充让输入图片的尺寸匹配模型的输入尺寸;
- 对像素值除以
255做归一化操作; - 把图像数据的通道顺序由
HWC调整为CHW; - 扩展数据维度,将数据的维度调整为
NCHW。
实现上述功能的预处理函数preprocess的代码如下:
python
def preprocess(bgr_image, src_w, src_h, dst_w, dst_h):
image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2RGB)
ratio = min(dst_w/src_w, dst_h/src_h)
border_w = int(round(src_w * ratio / 2) * 2)
border_h = int(round(src_h * ratio / 2) * 2)
x_offset = (dst_w - border_w ) // 2
y_offset = (dst_h - border_h ) // 2
image = cv2.resize(image, (border_w, border_h))
image = cv2.copyMakeBorder(
image, y_offset, y_offset, x_offset, x_offset,
cv2.BORDER_CONSTANT, value=(114, 114, 114)
)
image = image.astype(np.float32) / 255.0
image = np.transpose(image, (2, 0, 1))
input_tensor = np.expand_dims(image, axis=0)
return input_tensor, ratio, x_offset, y_offset经过预处理后,输入数据input_tensor的维度变为[1, 3, 640, 640],与模型要求的输入尺寸一致。
2.3 模型推理
准备好输入数据以后,就可以送入模型进行推理:
scss
outputs = session.run(None, {session.get_inputs()[0].name: input_tensor})
output = np.squeeze(outputs[0])
print("output shape: ", output.shape)YOLOv10只有一个输出分支,所以只要取outputs[0]的数据进行处理,去掉batch这个维度后,模型输出的维度为300x6。
shell
output.shape: (300, 6)2.4 后处理
从前文知道模型输出的维度为300x6,其中300表示模型在一张图片上最多能检测的目标数量,6则表示每个目标包含4个坐标属性(xmin,ymin,xmax,ymax)和1个类别置信度以及1个类别索引。每个目标的坐标信息都是相对于模型的输入尺寸的,由于预处理的时候在边上做了填充,所以后处理的时候要把每个坐标值减掉对应的偏移值;如果要恢复到原始图像的尺寸,还需要除以预处理时使用的缩放比例系数。与RT-DETR一样,YOLOv10的检测结果不需要再做NMS这些额外的后处理操作,处理过程非常简单。后处理的代码如下:
python
for i in range(output.shape[0]):
# 读取类别置信度
confidence = output[i][4]
# 用阈值进行过滤
if confidence > 0.5:
# 读取类别索引
label = int(output[i][5])
# 读取类坐标值,把坐标还原到原始图像
xmin = int((output[i][0] - x_offset) / ratio)
ymin = int((output[i][1] - y_offset) / ratio)
xmax = int((output[i][2] - x_offset) / ratio)
ymax = int((output[i][3] - y_offset) / ratio)
# 可视化
class_name = COCO_CLASSES[label]
box_color = np.array(COLOR_LIST[label]) * 255
box_color = (int(box_color[0]), int(box_color[1]), int(box_color[2]))
cv2.rectangle(image, (xmin, ymin), (xmax, ymax), box_color, 4)
# 省略.....来看一下检测效果:
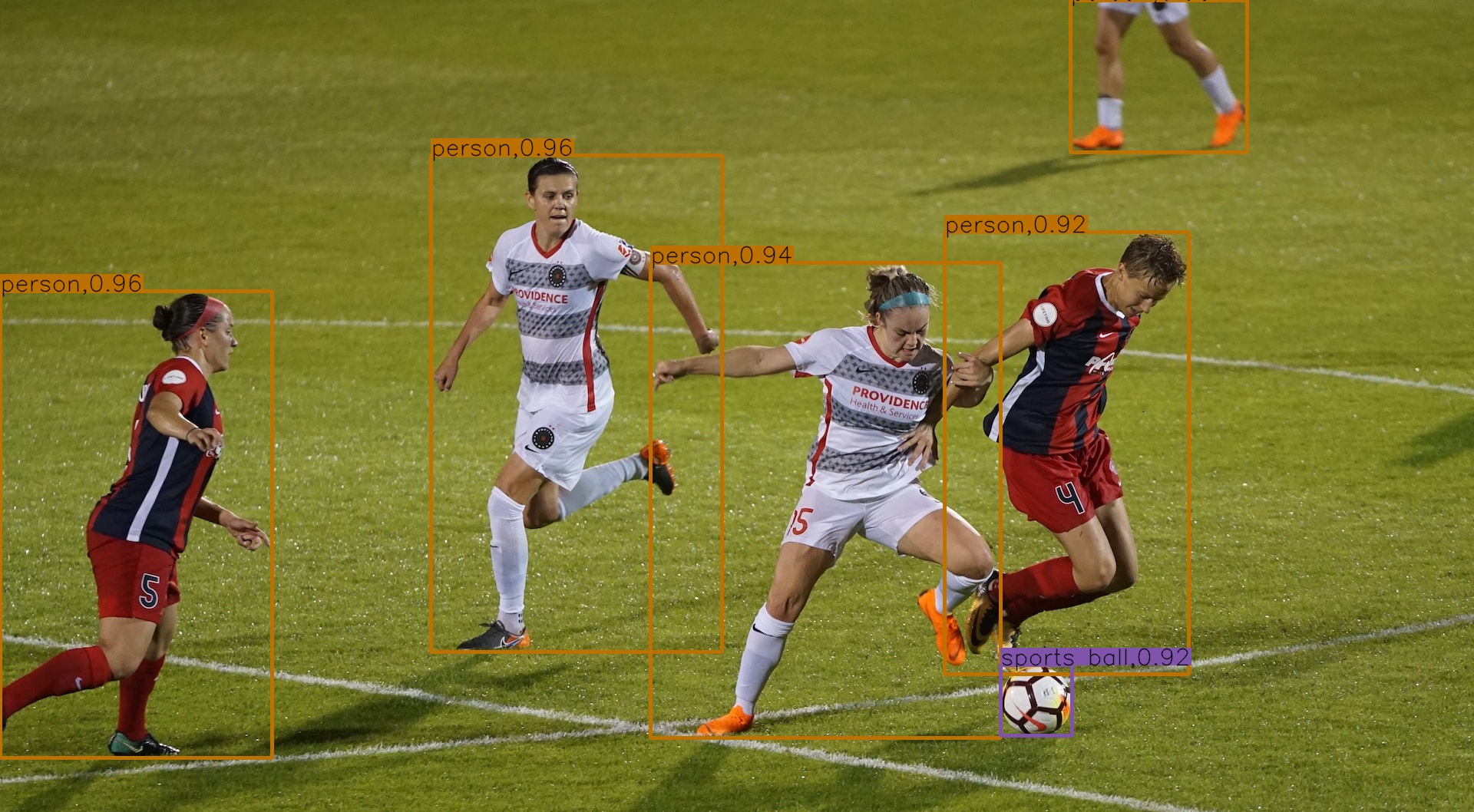
下面是用官方代码基于PyTorch推理的结果:
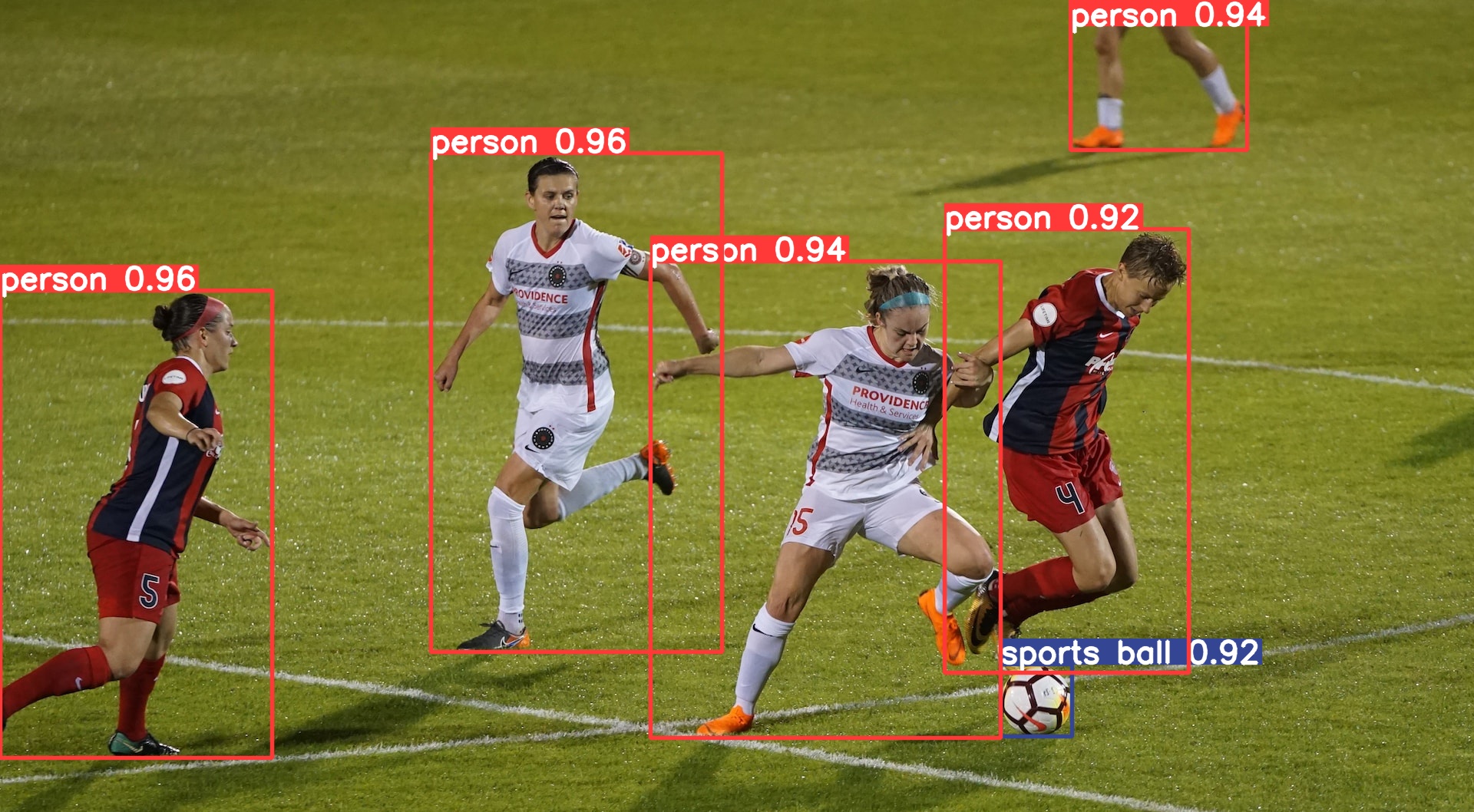
可以看到,ONNXRuntime和PyTorch推理的结果是一致的。
3. 推理耗时对比
这里的对比仅对比模型本身的推理耗时,不包含后处理操作。本文在GeForce GTX 1650 Ti显卡上,基于ONNXRuntime框架分别采用CUDA和TensorRT后端对YOLOv10、YOLOv9和RT-DETR的各个模型进行测试,数据精度统一采用FP32,模型输入尺���统一设置为640x640。各模型的推理耗时(单位为毫秒)测试结果如下:
| 模型 | CUDA | TensorRT |
|---|---|---|
| yolov10n | 10 | 7 |
| yolov10s | 17 | 13 |
| yolov10m | 34 | 27 |
| yolov10b | 44 | 37 |
| yolov10l | 55 | 46 |
| yolov10x | 80 | 64 |
| yolov9-c | 52 | 41 |
| yolov9-e | 106 | 82 |
| rtdetr_r18vd_6x | 52 | 26 |
| rtdetr_r34vd_6x | 66 | 36 |
| rtdetr_r50vd_6x | 94 | 52 |
| rtdetr_r50vd_m_6x | 66 | 40 |
| rtdetr_r101vd_6x | 133 | 89 |
YOLOv10的论文里说YOLOv10-S比RT-DETR-R18快1.8倍,YOLOv10-X比RT-DETR-R101快1.3倍,YOLOv10-B的推理延迟比YOLOv9-C减少了46%。从我测试的结果来看,YOLOv10-S/X不止比RT-DETR-R18/R101快一点几倍,YOLOv10-B则没有比YOLOv9-C快那么多。
总的来说,YOLOv10的性能确实比之前的模型要强一些,新一代卷王名不虚传。