目录
[存入一个 String 类型的数据](#存入一个 String 类型的数据)
[优化 -- 手动序列化](#优化 -- 手动序列化)
概述
SpringData 是 Spring 中数据操作的模块 ,包含对各种数据库 的集成,其中对 Redis 的集成模块就叫做 SpringDataRedis,
官网地址 :Spring Data Redis
- 提供了对不同 Redis 客户端的整合(Lettuce 和 Jedis)。
- 提供了 RedisTemplate 统一 API 来操作 Redis。
- 支持 Redis 的 发布订阅模型。
- 支持 Redis 哨兵和 Redis 集群。
- 支持基于Lettuce 的响应式编程。
- 支持基于 JDK.JSON 字符串Spring 对象的数据序列化及反序列化。
- 支持基于Redis 的 JDKCollection 实现。
SpringDataRedis 中提供了 RedisTemplate 工具类 ,其中封装了各种对 Redis 的操作。并且将不同数据类型的操作 API 封装到了不同的类型中:

创建项目

引入依赖
java
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>配置文件
java
spring:
redis:
host: 192.168.50.130
port: 6379
password: 123456
database: 1 # 选择了1号库
lettuce:
pool:
max-active: 8 #最大连接
max-idle: 8 #最大空闲连接
min-idle: 0 #最小空闲连接
max-wait: 100ms #连接等待时间测试代码
java
@Autowired
private RedisTemplate redisTemplate;
@Test
void testString() {
// 写入一条String数据
redisTemplate.opsForValue().set("name","luyuan");
// 获取String数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name == " + name);
}测试结果

数据序列化器
但是可视化软件里面显示的值是一长串 -- 这是因为序列化的问题,

这是Redis的几个序列化器

我们debug一下刚刚的程序
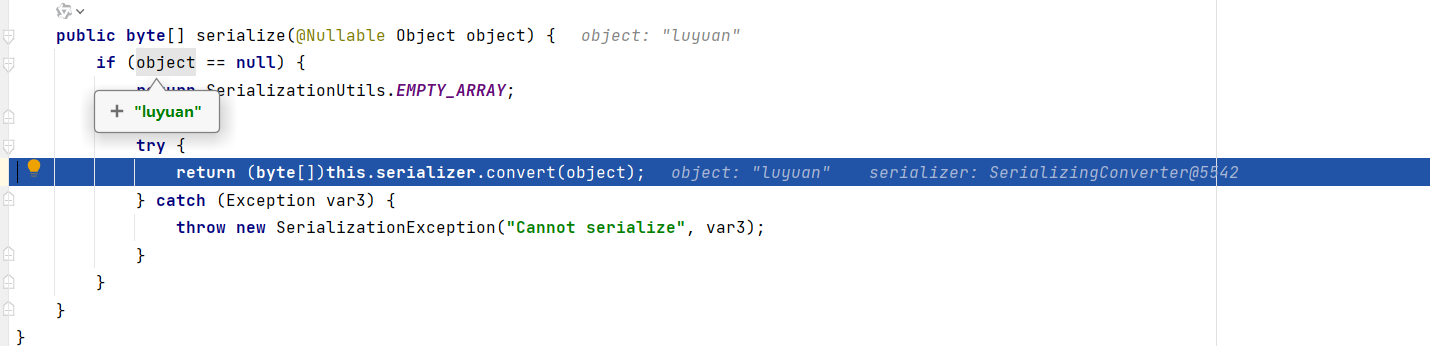
F7 步入

F7 步入
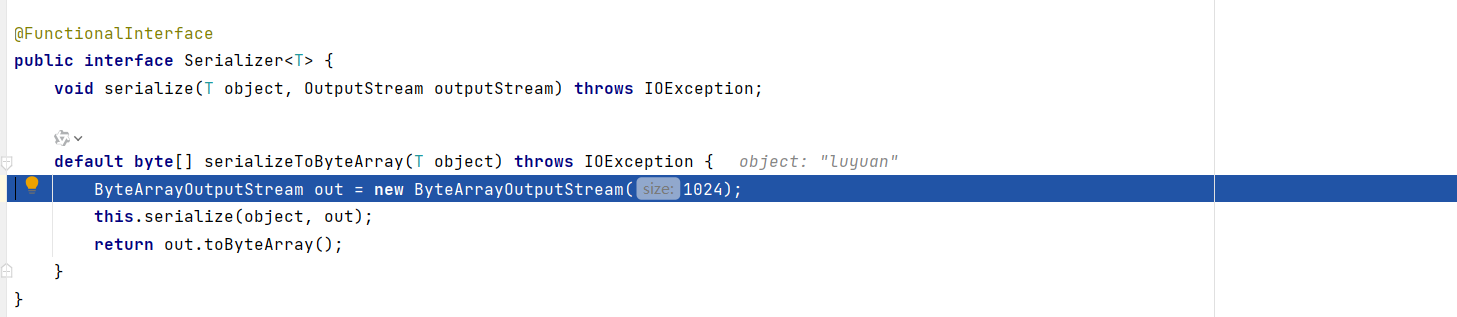
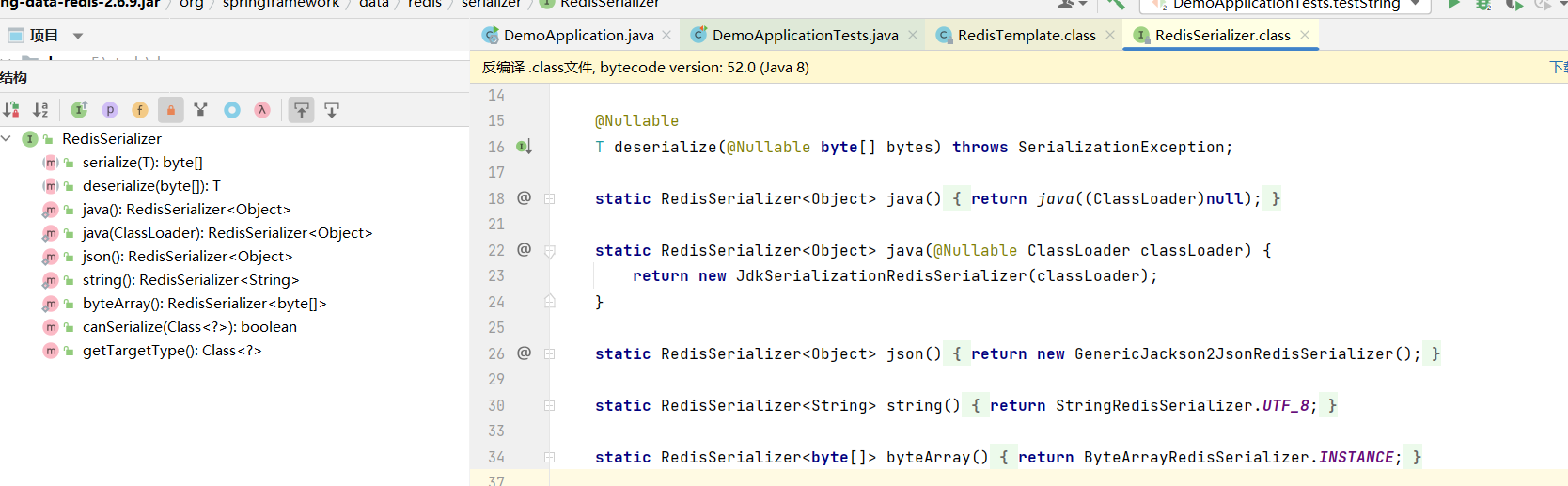
可以见到这个是默认的 JdkSerializationRedisSerializer
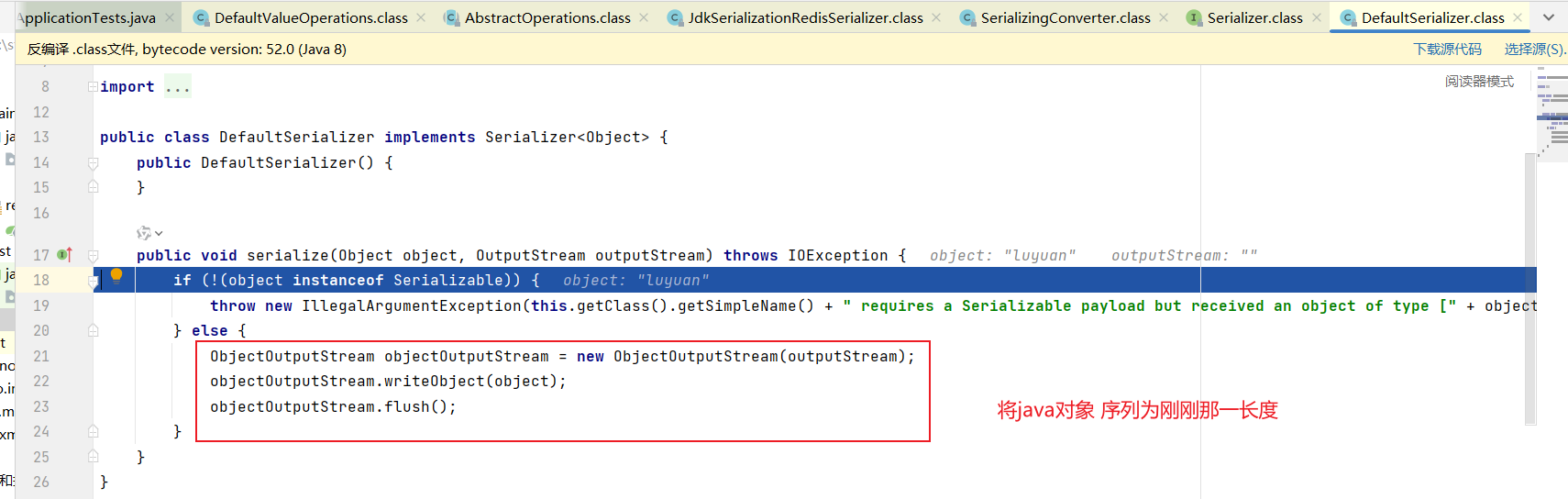
使用 JdkSerializationRedisSerializer 缺点:
- 可读性差
- 内存占用较大 --- 很长一大段

自定义RedisTemplate的序列化方式
java
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory connectionFactory) {
// 创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 设置连接工厂
template.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 设置 Key 的序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 设置 Value 的序列化
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
return template;
}测试报错
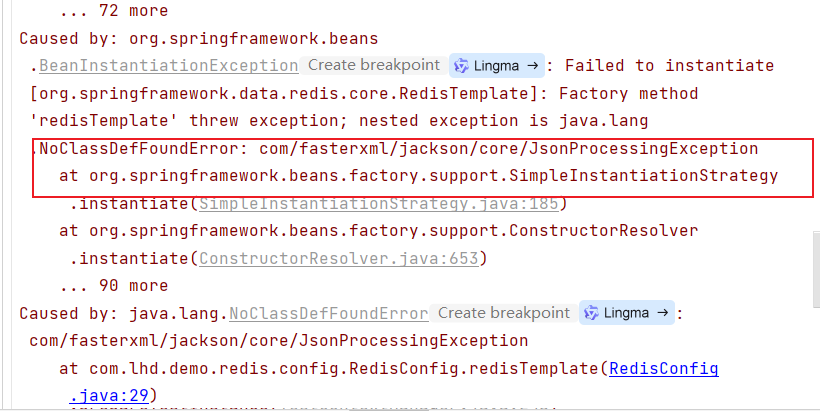
报错原因:少了一个jackson序列化的依赖,springmvc中会有这个依赖,但是本项目中没有添加
<!--Jackson依赖-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>添加依赖后测试
存入一个 String 类型的数据

Redis可视化端查看数据正常插入,对比没有自定义序列化器 ,现在序列化正常。
未定义序列化器 使用默认的序列化器的结果
定义了序列化器 后的结果

测试存入一个对象
java
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Test
void testString() {
redisTemplate.opsForValue().set("user",new User("luyuan", 18));
User user = (User) redisTemplate.opsForValue().get("user");
System.out.println("user == " + user);
}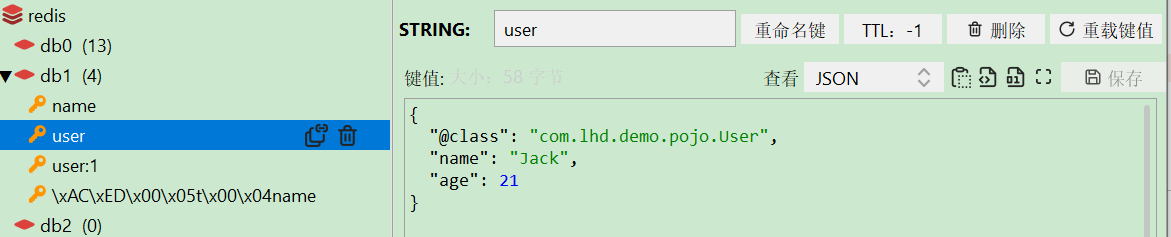
"@class": "com.lhd.demo.pojo.User" 这一段完全是多余的,如果数据量很大 ,那这个属性会占用很多额外空间,为了避免这个空间浪费,那我们可以做个优化!!!
优化 -- 手动序列化
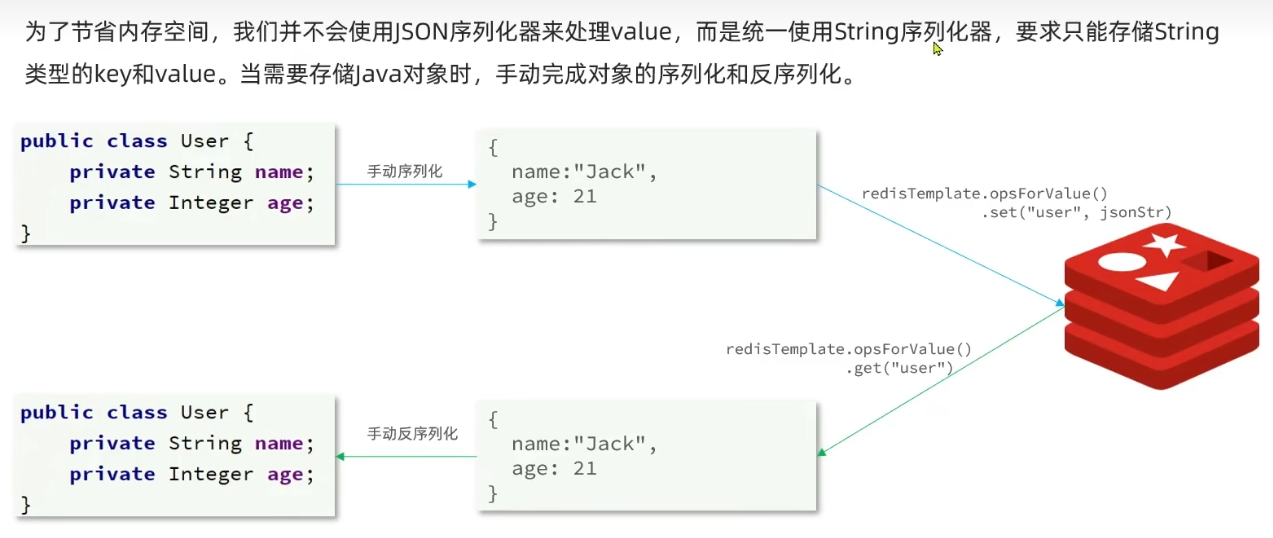
使用 RedisTemplate 自带的 StringRedisTemplate
java
@Autowired
private StringRedisTemplate stringRedisTemplate;
// 这个是SpringMVC自带的序列化工具 也可以使用fastJson Gson 来序列化
private static final ObjectMapper mapper = new ObjectMapper();
@Test
void testSaveUser() throws JsonProcessingException {
// 创建user对象
User user = new User("Marry", 22);
// 手动序列化
String json = mapper.writeValueAsString(user);
// 写入数据
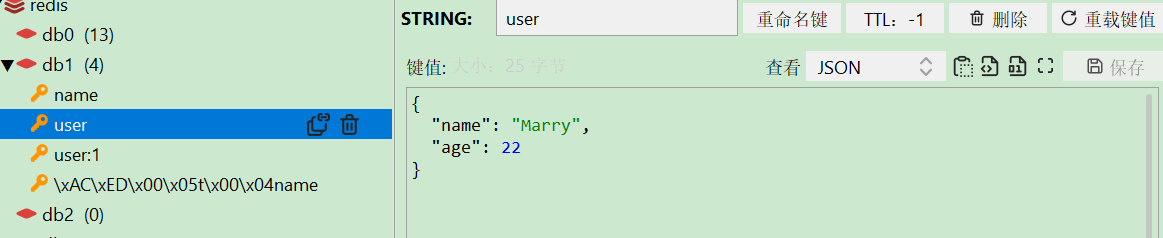
stringRedisTemplate.opsForValue().set("user", json);
// 获取数据
String json1 = stringRedisTemplate.opsForValue().get("user");
// 手动反序列化
User user1 = mapper.readValue(json1, User.class);
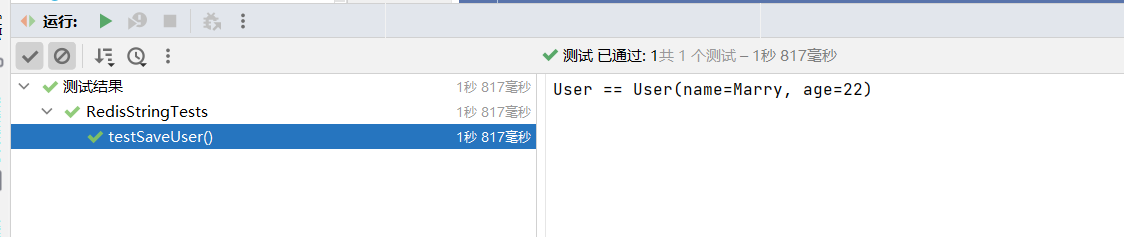
System.out.println("User == " + user1) ;
} 测试结果
可视化端:
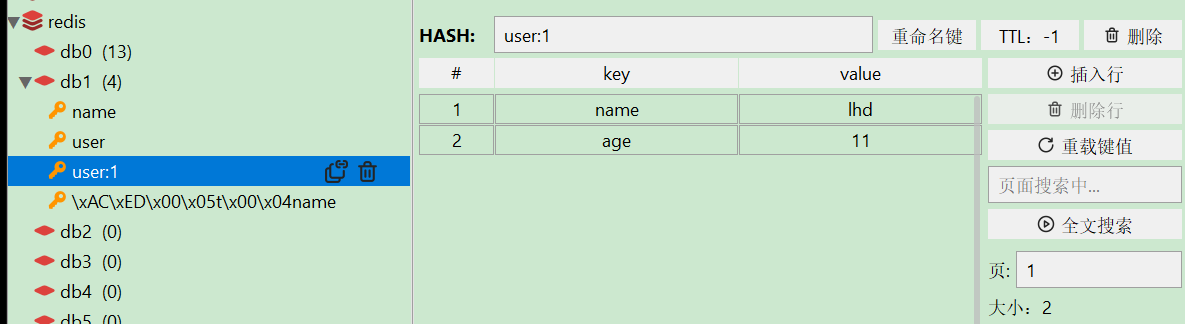
测试存入一个Hash
跟 Java 中的 map 有点像
java
@Test
void testHash(){
stringRedisTemplate.opsForHash().put("user:1","name","lhd");
stringRedisTemplate.opsForHash().put("user:1","age","11");
Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:1");
System.out.println("entries == " + entries);
}
总结:
RedisTemplate的两种序列化实践方案:
- 方案一:
- 自定义RedisTemplate
- 修改 RedisTemplate 的序列化器为 GenericJackson2JsonRedisSerializer
优点:更加方便
缺点:占用额外内存
- 方案二:
- 使用 StringRedisTemplate
- 写入 Redis 时,手动把对象序列化为JSON
- 读取 Redis 时,手动把读取到的JSON反序列化为对象
优点:不占用额外空间,数据更加纯正
缺点:需要手动操作
总的来说根据需求使用合适的方式是最好的。
干货满满的文章: