固件库: canmv_yahboom_v2.1.1.bin
本地训练 Mx_yolo3
这里就简单地提示一下下载安装哪些软件,然后主要是使用Mx_yolo3****进行本地训练模型的......
本文不用浪费时间看了! 这次对本地训练出的模型的部署是失败的,
不知道为何,也许是亚博智能固件库对模型的处理导入函数写的与Mx_yolo3生成的模型不适配???
文章提供测试代码讲解、完整代码贴出、测试效果图、完整工程下载
目录
配置要求:
win10电脑,最好有显卡GPU,我的配置如下:

下载安装的软件:
这里制作提示要安装哪些软件环境啥的,具体细节省略,下方网上查阅资料标出的文章有具体细节
Mx_yolov3的安装并使用GPU训练_mx yolov3 3.0下载-CSDN博客
1、Mx_yolov32.CUDA和CUDNN
3、Python3.7.3
Mx_yolov3本地训练自己的模型
这里详细讲一下如何使用 Mx_yolov3本地训练自己的模型
就以识别鼠标为例,从获取数据集、标注处理数据集、训练模型、导入模型为顺序讲·
采集图片数据集:
这里说明必须使用K210来拍摄采集数据图片,并尽可能多的图片
这次我对着鼠标拍摄了58张不同角度的图片,实际为了准确率,这点数据集明显是不够的,
实际最好需要几百张
标注处理数据集:
打开文件夹可以打开采集好的所有数据图片(放在一个文件夹中)
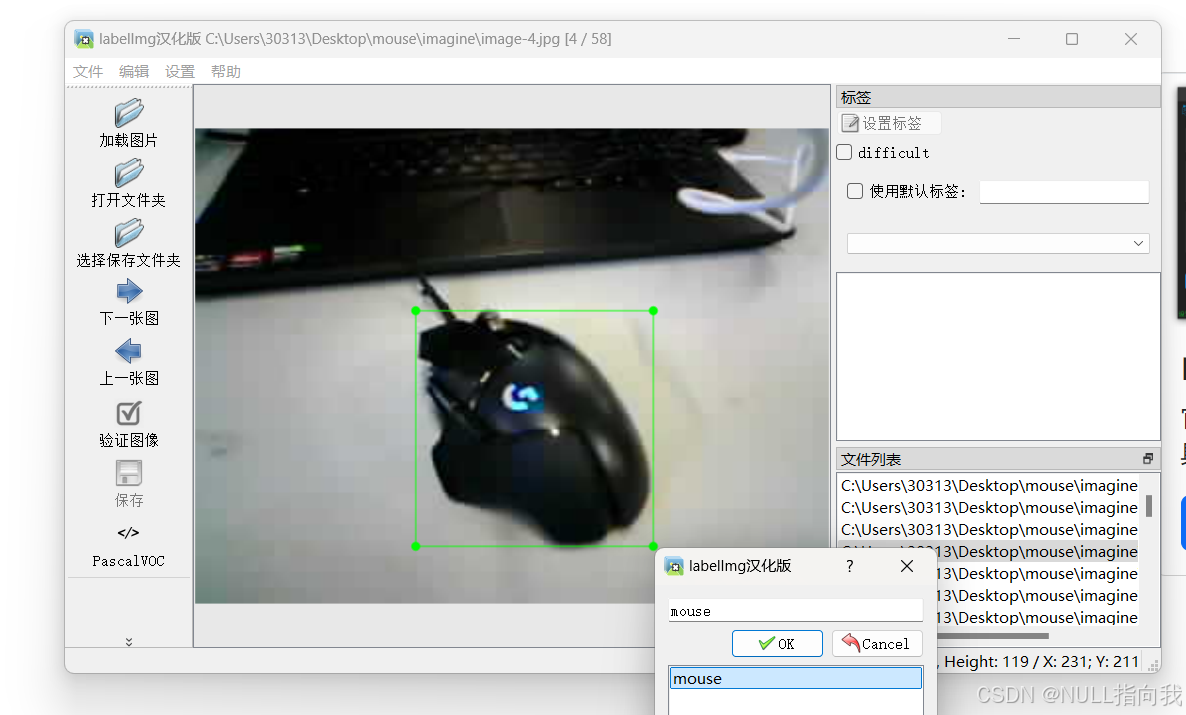
英文输入法下,按'W'可以与鼠标配合开始绘制标注框图
选择保存文件夹可以将标注好的xml文件选择地方保存好
这里我将所有图片放在了imagine文件夹中,将标注好的xml文件放在xml文件夹:


训练模型:
将训练图片与标注的俩个文件夹地址选择好,填好参数啥的就能训练了:
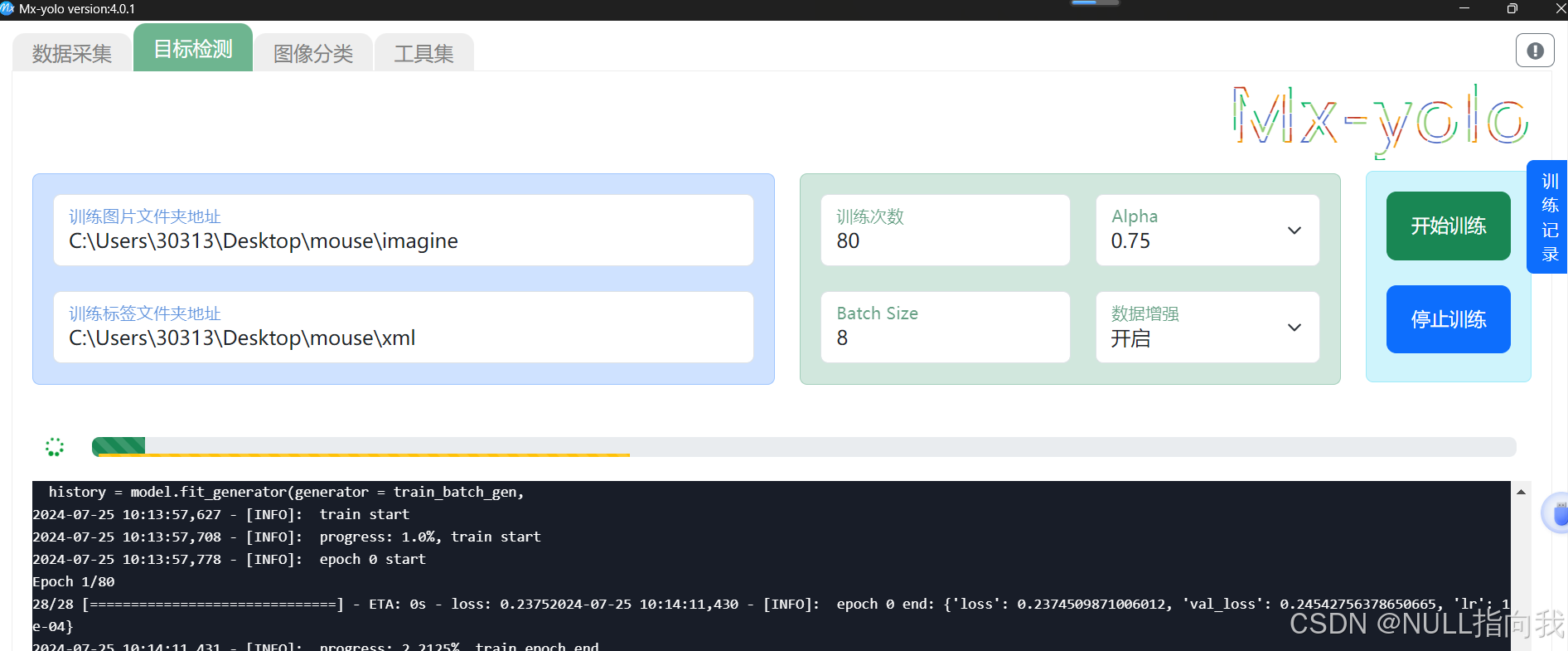
等待训练完成后就能导出模型了:

编程导入模型
解压导出的模型压缩包后,只有一个komdel、label是我们需要用到的:
先将mx.kmodel文件复制到SD卡
因为固件库的原因,它的boot代码我们无法使用,但需要打开boot来复制它的anchor内容:
这里我们之前在mixhub网站训练模型的代码来导入使用它的模型:
源代码如下:
pythonimport sensor, image, time, lcd, gc, cmath from maix import KPU lcd.init() # Init lcd display lcd.clear(lcd.RED) # Clear lcd screen. # sensor.reset(dual_buff=True) # improve fps sensor.reset() # Reset and initialize the sensor. sensor.set_pixformat(sensor.RGB565) # Set pixel format to RGB565 (or GRAYSCALE) sensor.set_framesize(sensor.QVGA) # Set frame size to QVGA (320x240) #sensor.set_vflip(True) # 翻转摄像头 #sensor.set_hmirror(True) # 镜像摄像头 sensor.skip_frames(time = 1000) # Wait for settings take effect. clock = time.clock() # Create a clock object to track the FPS. print("ready load model") labels = ["six"] #类名称,按照label.txt顺序填写 anchor = (1.06, 1.22, 1.36, 1.56, 1.75, 2.03, 2.41, 2.88, 3.58, 4.45) # anchors,使用anchor.txt中第二行的值 kpu = KPU() # 从sd或flash加载模型 kpu.load_kmodel('/sd/det.kmodel') #kpu.load_kmodel(0x300000, 584744) kpu.init_yolo2(anchor, anchor_num=(int)(len(anchor)/2), img_w=320, img_h=240, net_w=320 , net_h=240 ,layer_w=10 ,layer_h=8, threshold=0.6, nms_value=0.3, classes=len(labels)) while(True): gc.collect() clock.tick() img = sensor.snapshot() kpu.run_with_output(img) dect = kpu.regionlayer_yolo2() fps = clock.fps() if len(dect) > 0: for l in dect : a = img.draw_rectangle(l[0],l[1],l[2],l[3],color=(0,255,0)) info = "%s %.3f" % (labels[l[4]], l[5]) a = img.draw_string(l[0],l[1],info,color=(255,0,0),scale=2.0) print(info) del info a = img.draw_string(0, 0, "%2.1ffps" %(fps),color=(0,60,255),scale=2.0) lcd.display(img)修改步骤如下:
根据上面提供的源代码进行修改:
先修改导入模型的名称为刚才训练好的kmodel的名称:
在复制软件训练好的boot.py文件中的anchor数据到代码中
最后复制label的类名称到代码中:




修改后的代码如下:
pythonimport sensor, image, time, lcd, gc, cmath from maix import KPU lcd.init() # Init lcd display lcd.clear(lcd.RED) # Clear lcd screen. # sensor.reset(dual_buff=True) # improve fps sensor.reset() # Reset and initialize the sensor. sensor.set_pixformat(sensor.RGB565) # Set pixel format to RGB565 (or GRAYSCALE) sensor.set_framesize(sensor.QVGA) # Set frame size to QVGA (320x240) #sensor.set_vflip(True) # 翻转摄像头 #sensor.set_hmirror(True) # 镜像摄像头 sensor.skip_frames(time = 1000) # Wait for settings take effect. clock = time.clock() # Create a clock object to track the FPS. print("ready load model") labels = ["mouse"] #类名称,按照label.txt顺序填写 anchor = (2.71875, 3.578124999999999, 3.1875, 5.125, 2.46875, 3.125, 2.90625, 3.96875, 2.28125, 4.40625) # anchors,使用anchor.txt中第二行的值 kpu = KPU() # 从sd或flash加载模型 kpu.load_kmodel('/sd/mx.kmodel') #kpu.load_kmodel(0x300000, 584744) kpu.init_yolo2(anchor, anchor_num=(int)(len(anchor)/2), img_w=320, img_h=240, net_w=320 , net_h=240 ,layer_w=10 ,layer_h=8, threshold=0.4, nms_value=0.3, classes=len(labels)) while(True): gc.collect() clock.tick() img = sensor.snapshot() kpu.run_with_output(img) dect = kpu.regionlayer_yolo2() fps = clock.fps() if len(dect) > 0: for l in dect : if l[5]>0.7: a = img.draw_rectangle(l[0],l[1],l[2],l[3],color=(0,255,0)) info = "%s %.3f" % (labels[l[4]], l[5]) a = img.draw_string(l[0],l[1],info,color=(255,0,0),scale=2.0) print(info) del info a = img.draw_string(0, 0, "%2.1ffps" %(fps),color=(0,60,255),scale=2.0) lcd.display(img)测试识别效果:
惨不忍睹的识别效果....不知道是亚博智能有关anchor以及yolov固件库不兼容问题还是什么..
将限制不限制置信度L5>0.7的语句删除掉,它甚至能全屏都是mouse:


网上查阅资料贴出:
关于Mx_yolo3的模型训练详细教程保姆式教程 DF创客社区
Mx-yolov3+Maixpy+ K210进行本地模型训练和目标检测-CSDN博客
k210部署自行训练的口罩识别模型_k210固件和亚博固件-CSDN博客