四.ElasticSearch 操作命令
4.1 集群信息操作命令
4.1.1 查询集群状态
(1)使用 Postman 客户端直接向 ES 服务器发 GET 请求
http://hlink1:9200/_cat/health?v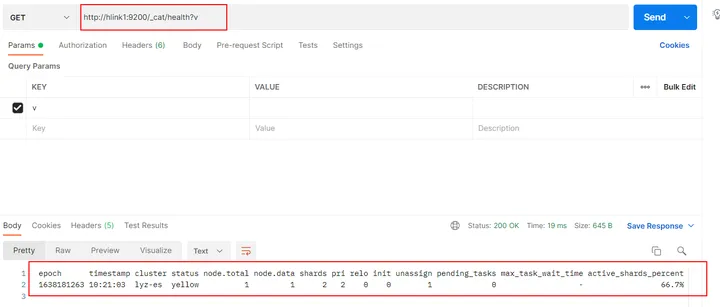
(2)使用服务端进行查询
curl -XGET "hlink1:9200/_cat/health?v"
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1638181746 10:29:06 lyz-es yellow 1 1 2 2 0 0 1 0 - 66.7%返回结果的主要字段意义:
- cluster:集群名,是在 ES 的配置文件中配置的 cluster.name 的值。
- status:集群状态。集群共有 green、yellow 或 red 中的三种状态。green 代表一切正常(集群功能齐全),yellow 意味着所有的数据都是可用的,但是某些复制没有被分配(集群功能齐全),red 则代表因为某些原因,某些数据不可用。如果是 red 状态,则要引起高度注意,数据很有可能已经丢失。
- node.total:集群中的节点数。
- node.data:集群中的数据节点数。
- shards:集群中总的分片数量。
- pri:主分片数量,英文全称为 private。
- relo:复制分片总数。
- unassign:未指定的分片数量,是应有分片数和现有的分片数的差值(包括主分片和复制分片)。
4.1.2 使用 help 参数查询
(1)使用 Postman 客户端查询
http://hlink1:9200/_cat/health?help在请求中添加 help 参数来查看每个操作返回结果字段的意义。

(2)使用 服务端 查询
curl -XGET "hlink1:9200/_cat/health?help"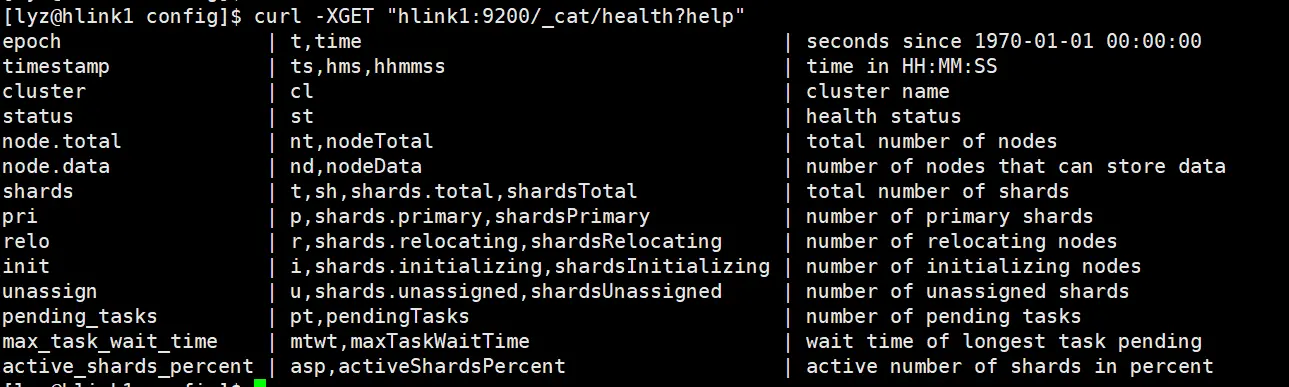
# 指定返回的参数
curl -XGET "hlink1:9200/_cat/health?h=cluster,pri,relo&v"4.1.3 查询集群中的节点信息
(1)使用 Postman 客户端查询
http://hlink1:9200/_cat/nodes?v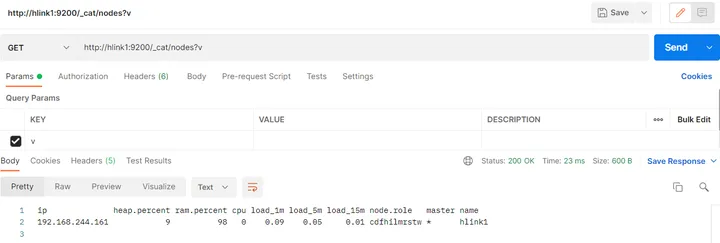
(2)使用服务端查询
curl -XGET "hlink1:9200/_cat/nodes?v"
4.1.4 查询集群索引信息
(1)使用 Postman 客户端查询
http://hlink1:9200/_cat/indices?v
(2)使用服务端查询
curl -XGET "hlink1:9200/_cat/indices?v"
4.2 index 操作命令
后面操作命令全部使用 Postman 客户端进行操作,想查看详细文档,在公众号:【3分钟秒懂大数据】,回复:【elasticsearch】,获取更详细文档。
4.2.1 创建索引
在 Postman 中,向 ES 服务器发 PUT 请求
http://hlink1:9200/study
{
"acknowledged"【响应结果】: true, # true 操作成功
"shards_acknowledged"【分片结果】: true, # 分片操作成功
"index"【索引名称】: "study"
}
4.2.2 查看索引
在 Postman 中,向 ES 服务器发 GET 请求
http://hlink1:9200/study
{
"study": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "study",
"creation_date": "1638183519598",
"number_of_replicas": "1", #分片数量
"uuid": "dg7HnAAiQEeDMJ7kMtA2Qw",
"version": {
"created": "7150299"
}
}
}
}
}4.2.3 删除索引
在 Postman 中,向 ES 服务器发 DELETE 请求
http://hlink1:9200/study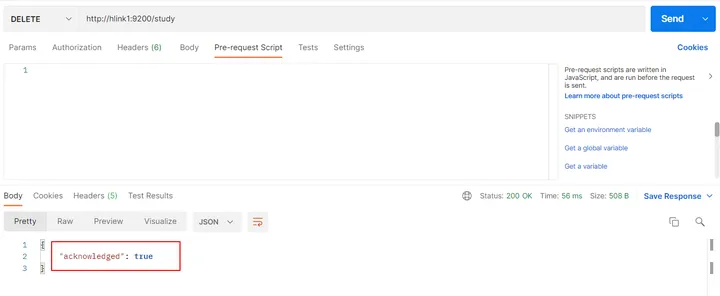
4.3 document 操作命令
4.3.1 创建文档
索引创建完成后,可以创建 document 文档,该文档对应数据库中 表的行数据
添加的数据格式为 JSON 内容
#请求体内容如下:
{
"name": "3分钟秒懂大数据",
"introduction": "专注于大数据技术研究"
}
# 向 ES 服务器发 POST 请求
http://hlink1:9200/study/_doc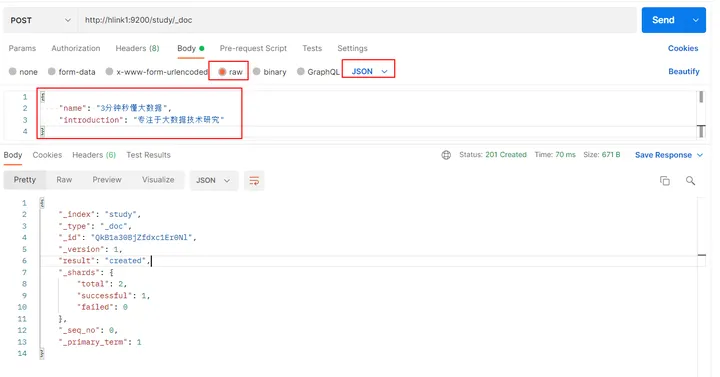
4.3.2 更新文档
上面的数据创建后,没有指定数据唯一性标识(ID),默认情况下,ES 服务器会随机生成一个。更新时可以指定唯一性标识
#请求体内容如下:
{
"name": "3分钟秒懂大数据",
"introduction": "专注于Hadoop、Kafka、Flink等多个组件的技术研究"
}
# 向 ES 服务器发 POST 请求
http://hlink1:9200/study/_doc/1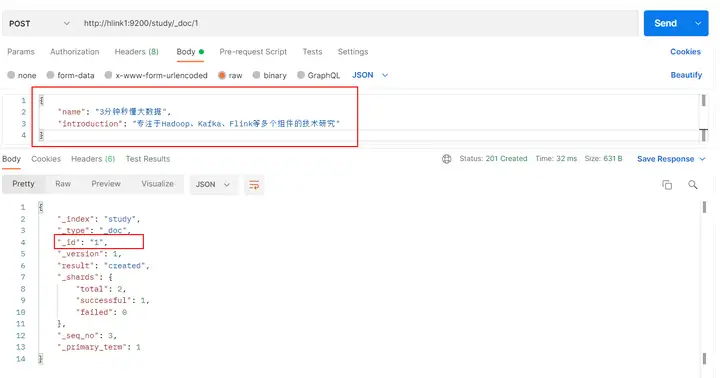
4.3.3 查询文档
查看文档时,需要指明文档的唯一性标识
http://hlink1:9200/study/_doc/1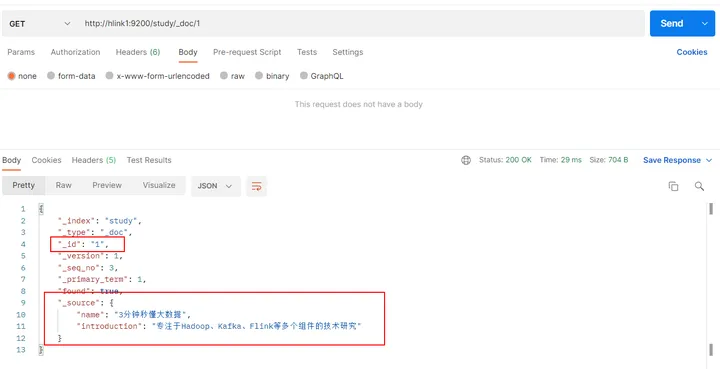
4.3.4 删除文档
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)
Postman 向服务器发送 delete 请求
http://hlink1:9200/study/_doc/1
五 ElasticSearch 读写原理
1、ES写人数据的过程
1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
2)coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
3)实际的node上的primary shard处理请求,然后将数据同步到replica node
4)coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端.
2、ES读取数据的过程
1)客户端发送请求到任意一个node,成为coordinate node
2)coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
3)接收请求的node返回document给coordinate node
4)coordinate node返回document给客户端
3、ES数据写入底层原理

(1)数据先写入内存 buffer,在 buffer 里的时候数据是搜索不到的;同时将数据写入 translog 日志文件。如果 buffer 快满了,或者到一定时间,就会将内存 buffer 数据 refresh 到一个新的 segment file 中,但是此时数据不是直接进入 segment file 磁盘文件,而是先进入 os cache 。这个过程就是 refresh。
(2)每隔 1 秒钟,es 将 buffer 中的数据写入一个新的 segment file,每秒钟会产生一个新的磁盘文件 segment file,这个 segment file 中就存储最近 1 秒内 buffer 中写入的数据。但是如果 buffer 里面此时没有数据,那当然不会执行 refresh 操作,如果 buffer 里面有数据,默认 1 秒钟执行一次 refresh 操作,刷入一个新的 segment file 中。
(3)操作系统里面,磁盘文件其实都有一个东西,叫做 os cache,即操作系统缓存,就是说数据写入磁盘文件之前,会先进入 os cache,先进入操作系统级别的一个内存缓存中去。只要 buffer中的数据被 refresh 操作刷入 os cache中,这个数据就可以被搜索到了。
(4)为什么叫 es 是准实时的? NRT,全称 near real-time。默认是每隔 1 秒 refresh 一次的,所以 es 是准实时的,因为写入的数据 1 秒之后才能被看到。可以通过 es 的 restful api 或者 java api,手动执行一次 refresh 操作,就是手动将 buffer 中的数据刷入 os cache中,让数据立马就可以被搜索到。只要数据被输入 os cache 中,buffer 就会被清空了,因为不需要保留 buffer 了,数据在 translog 里面已经持久化到磁盘去一份了。重复上面的步骤,新的数据不断进入 buffer 和 translog,不断将 buffer 数据写入一个又一个新的 segment file 中去,每次 refresh 完 buffer 清空,translog 保留。随着这个过程推进,translog 会变得越来越大。当 translog 达到一定长度的时候,就会触发 commit 操作。
(5)commit 操作发生第一步,就是将 buffer 中现有数据 refresh 到 os cache 中去,清空 buffer。然后,将一个 commit point写入磁盘文件,里面标识着这个 commit point 对应的所有 segment file,同时强行将 os cache 中目前所有的数据都 fsync 到磁盘文件中去。最后清空 现有 translog 日志文件,重启一个 translog,此时 commit 操作完成。
(6)这个 commit 操作叫做 flush。默认 30 分钟自动执行一次 flush,但如果 translog 过大,也会触发 flush。flush 操作就对应着 commit 的全过程,我们可以通过 es api,手动执行 flush 操作,手动将 os cache 中的数据 fsync 强刷到磁盘上去。
(7)translog 日志文件的作用是什么?你执行 commit 操作之前,数据要么是停留在 buffer 中,要么是停留在 os cache 中,无论是 buffer 还是 os cache 都是内存,一旦这台机器死了,内存中的数据就全丢了。所以需要将数据对应的操作写入一个专门的日志文件 translog 中,一旦此时机器宕机,再次重启的时候,es 会自动读取 translog 日志文件中的数据,恢复到内存 buffer 和 os cache 中去。
(8) translog 其实也是先写入 os cache 的,默认每隔 5 秒刷一次到磁盘中去,所以默认情况下,可能有 5 秒的数据会仅仅停留在 buffer 或者 translog 文件的 os cache 中,如果此时机器挂了,会丢失 5 秒钟的数据。但是这样性能比较好,最多丢 5 秒的数据。也可以将 translog 设置成每次写操作必须是直接 fsync 到磁盘,但是性能会差很多。
其实 es 第一是准实时的,数据写入 1 秒后可以搜索到;可能会丢失数据的。有 5 秒的数据,停留在 buffer、translog os cache、segment file os cache 中,而不在磁盘上,此时如果宕机,会导致 5 秒的数据丢失。
总结一下,数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到 os cache,到了 os cache 数据就能被搜索到(所以我们才说 es 从写入到能被搜索到,中间有 1s 的延迟)。每隔 5s,将数据写入 translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失),translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush 到 segment file 磁盘文件中。
数据写入 segment file 之后,同时就建立好了倒排索引。
4、ES删除/更新数据底层原理
(1) 如果是删除操作,commit 的时候会生成一个 .del 文件,里面将某个 doc 标识为 deleted 状态,那么搜索的时候根据 .del 文件就知道这个 doc 是否被删除了。
(2)如果是更新操作,就是将原来的 doc 标识为 deleted 状态,然后新写入一条数据。
(3)buffer 每 refresh 一次,就会产生一个 segment file,所以默认情况下是 1 秒钟一个 segment file,这样下来 segment file 会越来越多,此时会定期执行 merge。每次 merge 的时候,会将多个 segment file 合并成一个,同时这里会将标识为 deleted 的 doc 给物理删除掉,然后将新的 segment file 写入磁盘,这里会写一个 commit point,标识所有新的 segment file,然后打开 segment file 供搜索使用,同时删除旧的 segment file。
5.1 写操作(Write):针对文档的 CRUD 操作
索引新文档(Create)
当用户向一个节点提交了一个索引新文档的请求,节点会计算新文档应该加入到哪个分片(shard)中。每个节点都有每个分片存储在哪个节点的信息,因此协调节点会将请求发送给对应的节点。注意这个请求会发送给主分片,等主分片完成索引 ,会并行将请求发送到其所有副本分片,保证每个分片都持有最新数据。
每次写入新文档时,都会先写入 内存 中,并将这一操作写入一个 translog 文件(transaction log)中,此时如果执行搜索操作,这个新文档还不能被索引到。
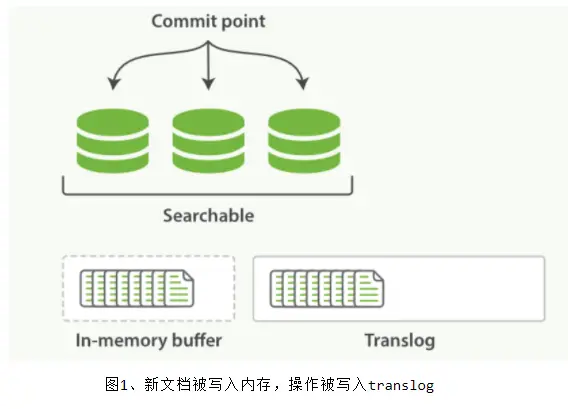
ES 会每隔 1 秒时间(这个时间可以修改)进行一次刷新操作(refresh),此时在这 1 秒时间内写入内存的新文档都会被写入一个文件系统缓存(filesystem cache)中,并构成一个分段(segment)。此时这个 segment 里的文档可以被搜索到,但是尚未写入硬盘,即如果此时发生断电,则这些文档可能会丢失。
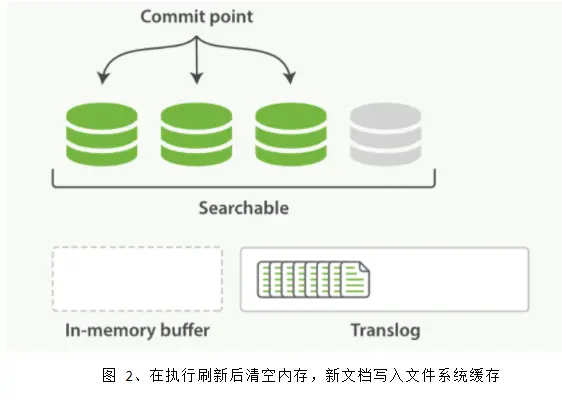
不断有新的文档写入,则这一过程将不断重复执行。每隔一秒将生成一个新的 segment,而 translog 文件将越来越大。

每隔 30 分钟或者 translog 文件变得很大,则执行一次 fsync 操作。此时所有在文件系统缓存中的 segment 将被写入磁盘,而 translog 将被删除(此后会生成新的 translog)
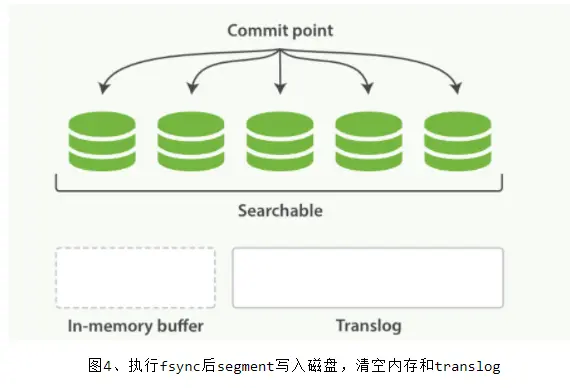
由上面的流程可以看出,在两次 fsync 操作之间,存储在内存 和 文件系统 缓存中的文档是不安全的,一旦出现断电这些文档就会丢失。所以 ES 引入了 translog 来记录两次 fsync 之间所有的操作,这样机器从故障中恢复或者重新启动,ES 便可以根据 translog 进行还原。
当然,translog 本身也是文件 ,存在于内存当中,如果发生断电一样会丢失。因此,ES 会在每隔 5 秒时间或是一次写入请求完成后将 translog 写入磁盘。可以认为一个对文档的操作一旦写入磁盘便是安全的可以复原的,因此只有在当前操作记录被写入磁盘,ES 才会将操作成功的结果返回发送此操作请求的客户端。
此外,由于每一秒就会生成一个新的 segment,很快将会有大量的 segment。对于一个分片进行查询请求,将会轮流查询分片中的所有 segment,这将降低搜索效率。因此 ES 会自动启动合并 segment 的工作,将一部分相似大小的 segment合并成一个新的大 segment。合并的过程实际上是创建了一个新的 segment,当新 segment 被写入磁盘,所有被合并的旧 segment 被清除。
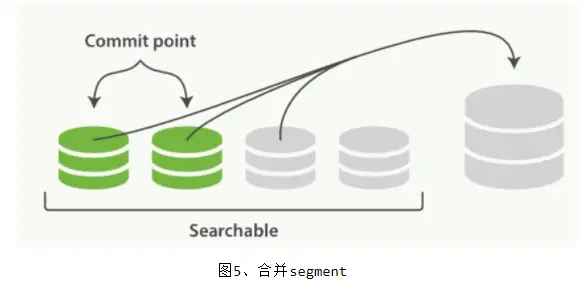

5.2 更新(Update)和删除(Delete)文档
ES 的索引是不能修改的,因此更新 和 删除 操作并不是直接在原索引上直接执行。
每一个磁盘上的 segment 都会维护一个 del 文件,用来记录被删除的文件。每当用户提出一个删除请求,文档并没有被真正删除 ,索引也没有发生改变,而是在 del 文件中标记该文档已被删除 。因此被删除的文档依然可以被检索到,只是在返回检索结果时被过滤掉了。每次在启动 segment 合并工作时,那些被标记为删除的文档才会被真正删除。
更新文档会首先查找原文档,得到该文档的版本号。然后将修改后的文档写入内存,此过程与写入一个新文档相同。同时,旧版本文档被标记为删除,同理,该文档可以被搜索到,只是最终被过滤掉。
读操作(Read):查询过程
查询的过程大体上分为查询(query)和取回(fetch)两个阶段。这个节点的任务是广播查询请求到所有相关分片,并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
查询阶段
当一个节点接收到一个搜索请求,则这个节点就变成了协调节点。
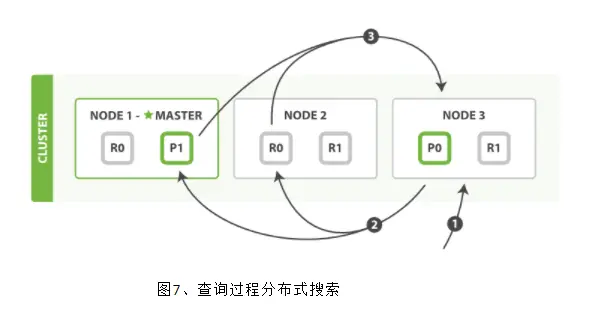
第一步是广播请求到索引中每一个节点的分片拷贝。 查询请求可以被某个主分片或某个副本分片处理,协调节点将在之后的请求中轮询所有的分片拷贝来分摊负载。
每个分片将会在本地构建一个优先级队列。如果客户端要求返回结果排序中从第 from 名开始的数量为 size 的结果集,则每个节点都需要生成一个 from+size 大小的结果集,因此优先级队列的大小也是 from+size。分片仅会返回一个轻量级的结果给协调节点,包含结果集中的每一个文档的 ID 和进行排序所需要的信息。
协调节点会将所有分片的结果汇总,并进行全局排序,得到最终的查询排序结果。此时查询阶段结束。
取回阶段
查询过程得到的是一个排序结果,标记出哪些文档是符合搜索要求的,此时仍然需要获取这些文档返回客户端。
协调节点会确定实际需要返回的文档,并向含有该文档的分片发送get请求;分片获取文档返回给协调节点;协调节点将结果返回给客户端。
六、Java应用使用ElasticSearch
Java应用连接ES建议使用ES的TCP的端口(默认9300),这是ES给java的特权,性能高,其它应用就只能通过http端口(9200)访问了。
springBoot项目建议使用ElasticsearchTemplate
引入jar包:
XML
<!-- ES -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>在yml配置文件中添加ES连接配置项
spring:
data:
elasticsearch:
cluster-name: my-application
cluster-nodes: 192.168.188.130:9300,192.168.188.53:9300
repositories:
enabled: true
增加ES配置类,不加有时查询会报错
java
package com.ypc.base.config;
import org.springframework.context.annotation.Configuration;
import javax.annotation.PostConstruct;
/**
* @Author: ypc
* @Date: 2018-06-30 11:27
* @Description:
* @Modified By:
*/
@Configuration
public class ElasticSearchConfig {
/**
* 防止netty的bug
* java.lang.IllegalStateException: availableProcessors is already set to [4], rejecting [4]
*/
@PostConstruct
void init() {
System.setProperty("es.set.netty.runtime.available.processors", "false");
}
}这样就可以直接注入ElasticsearchTemplate,对ES进行CRUD
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
springMvc项目不使用ElasticsearchTemplate
引入jar包
XML
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.1.1</version>
</dependency>XML配置文件里面配置ESUtils
java
package com.ypc.common.utils;
import com.alibaba.fastjson.JSONObject;
import com.jwd.test.es.DateUtils;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.springframework.beans.factory.InitializingBean;
import java.io.Serializable;
import java.net.InetAddress;
public class ESUtils implements InitializingBean, Serializable {
//服务器IP
private static String es_addr;
//端口号
private static int es_port;
//集群名称
private static String cluster_name;
private static Settings esSettings;
/**
* 嗅探
*/
private static String client_transport_sniff;
private static final long serialVersionUID = 1L;
public static TransportClient client;
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("elasticsearch连接");
try {
esSettings = Settings.builder()
.put("cluster.name", cluster_name) //设置ES实例的名称
.put("client.transport.sniff", client_transport_sniff) //自动嗅探整个集群的状态,把集群中其他ES节点的ip添加到本地的客户端列表中
.build();
client = new PreBuiltTransportClient(esSettings);
// 创建client
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(es_addr), es_port));
System.out.println("elasticsearch连接成功");
} catch (Exception e) {
e.printStackTrace();
System.out.println("elasticsearch连接失败");
}
}
public String getEs_addr() {
return es_addr;
}
public void setEs_addr(String es_addr) {
this.es_addr = es_addr;
}
public int getEs_port() {
return es_port;
}
public void setEs_port(int es_port) {
this.es_port = es_port;
}
public String getCluster_name() {
return cluster_name;
}
public void setCluster_name(String cluster_name) {
this.cluster_name = cluster_name;
}
public Settings getEsSettings() {
return esSettings;
}
public void setEsSettings(Settings esSettings) {
this.esSettings = esSettings;
}
public String getClient_transport_sniff() {
return client_transport_sniff;
}
public void setClient_transport_sniff(String client_transport_sniff) {
this.client_transport_sniff = client_transport_sniff;
}
public static void insertData(String userId, String userName, String content) {
String indexType = "info";
long operatedTime = com.jwd.common.utils.DateUtils.getCurrentMills();
JSONObject object = new JSONObject();
object.put("userId", userId);
object.put("userName", userName);
object.put("content", content);
object.put("operatedTime", operatedTime);
String dataStr = com.jwd.test.es.DateUtils.getDataStr(operatedTime, "yyyy-MM-dd HH:mm:ss");
IndexResponse indexResponse = client.prepareIndex(userId, indexType, dataStr).setSource(object).execute().actionGet();
System.out.println("操作数据已保存,时间:" + indexResponse.getId());
}
public static void queryData(String userId, String operatedTime) {
try {
QueryBuilder userIdConditon = QueryBuilders.termQuery("userId", userId);
long startMills = com.jwd.common.utils.DateUtils.startMills(operatedTime);
long endMills = com.jwd.common.utils.DateUtils.endMills(operatedTime);
QueryBuilder operatedTimeConditon = QueryBuilders.rangeQuery("operatedTime").from(startMills).to(endMills);
SearchResponse searchResponse = client.prepareSearch(userId)
.setTypes("info")
.setQuery(userIdConditon)
.setQuery(operatedTimeConditon)
.execute()
.actionGet();
SearchHits hits = searchResponse.getHits();
System.out.println("查到记录数:" + hits.getTotalHits());
SearchHit[] searchHists = hits.getHits();
if (searchHists.length > 0) {
for (SearchHit hit : searchHists) {
String uId = (String) hit.getSource().get("userId");
String uName = (String) hit.getSource().get("userName");
String content = (String) hit.getSource().get("content");
long oTime = (long) hit.getSource().get("operatedTime");
String dataStr = DateUtils.getDataStr(oTime, "yyyy-MM-dd HH:mm:ss");
System.out.println("用户名:" + uName + " 在" + dataStr + " 进行了:" + content);
}
}
} catch (Exception e) {
e.printStackTrace();
System.out.println("查询失败");
}
}
}七、ElasticSearch使用注意点
1、ES不适合做实时的复杂聚合,聚合很耗cpu
2、ES不支持高并发写入,可以把写入的数据先放入MQ中,再启消费者批量写入
3、ES集群内存要能存下集群所有数据的一半,才能达到ES最佳状态
4、一个索引数据量不宜太大,大索引影响数据的查询与写入
八、ElasticSearch工具
bash
连接ES的可视化工具
kibana ,可在ES官网下载
elasticsearch-head
node项目可在github下载
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
启动
npm run start
然后浏览器输入如下地址:
http://localhost:9100/
界面如下
主界面
查看所有索引信息
很好用,可以直观看到ES集群信息,可以简单筛选数据,也可自己写ES的DSL语法查询
elasticsearch-dump数据导入导出工具
也是node项目
github下载 https://github.com/taskrabbit/elasticsearch-dump
安装
(local)
npm install elasticdump
./bin/elasticdump
(global)
npm install elasticdump -g
elasticdump
从集群把数据导到json文件
elasticdump --input=http://211.159.183.169:9200/aps_job_schedule_index --output=C:/Users/lenovo/Desktop/data/aps_job_schedule_index.json type=data
从本地json文件导入ES集群
elasticdump --input=C:/Users/lenovo/Desktop/data/aps_job_schedule_index.json --output=http://211.159.183.169:9200/aps_job_schedule_index type=data
从一个ES集群导入另一个ES集群
elasticdump --input=http://211.159.183.169:9200/task_confirm_index --output=http://119.23.235.192:9200/task_confirm_index type=data
1
更多ES信息可查看官网
https://www.elastic.co/cn/elasticsearch/
还有中文说明文档
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html然后浏览器输入如下地址:
界面如下
主界面

查看所有索引信息

参考链接
https://www.jianshu.com/p/28fb017be7a7/
https://www.wenyuanblog.com/blogs/elasticsearch-forward-index-and-inverted-index.html