目前,扩散模型能够生成多样化且高质量的图像或视频。此前,视频扩散模型采用 U-Net 架构 ,主要侧重于合成有限时长(通常约为两秒)的视频,并且分辨率和纵横比受到固定限制。
Sora 的出现打破了这一限制,其采用 Diffusion Transformer(DiT)架构,不仅擅长制作 10 到 60 秒的高质量视频,而且还因其生成不同分辨率、各种纵横比、且遵守实际物理定律的能力而脱颖而出。
可以说 Sora 是 DiT 架构最有利的证明,然而,基于 Transformer 的扩散模型在有效生成可控动作视频方面还未被充分探索。
针对这一问题,来自阿里的研究者提出了 Tora,这是第一个面向轨迹的 DiT 架构,它将文本、视觉和轨迹条件同时集成在一起以生成视频。

Tora 的设计与 DiT 的可扩展性无缝契合,允许精确控制具有不同持续时间、宽高比和分辨率的视频内容。大量实验证明,Tora 在实现高运动保真度方面表现出色,同时还能细致模拟物理世界的运动。

-
论文标题:Tora: Trajectory-oriented Diffusion Transformer for Video Generation
一艘老式的木制帆船沿着规定好的路线在迷雾笼罩的河流上平稳地滑行,周围是茂密的绿色森林。

一条鲫鱼优雅地游过火星的红色岩石表面,鱼的轨迹向左,火星的轨迹向右。

热气球沿着不同的轨迹升入夜空,一个沿着规定的斜线,另一个沿着有弯度的轨迹。

两只可爱的小猫并排走在宁静的金色沙滩上。

气泡沿着轨迹轻轻地漂浮在盛开的野花中。

枫叶在清澈的湖面上颤动,映照着秋天的森林。

山间的瀑布倾泻而下,主题、背景的运动都可以按照不同的路线运动。

在 Tora 与其他方法的比较中,可以看出 Tora 生成的视频流畅度更高,更遵循轨迹,且物体不会存在变形的问题,保真度更好。


方法介绍
Tora 采用 OpenSora 作为其 DiT 架构的基础模型,包含一个轨迹提取器 (TE,Trajectory Extractor)、时空 DiT(Spatial-Temporal DiT )和一个运动引导融合器 (MGF,Motion-guidance Fuser) 。TE 使用 3D 视频压缩网络将任意轨迹编码为分层时空运动 patch。MGF 将运动 patch 集成到 DiT 块中,以生成遵循轨迹的一致视频。图 3 概述了 Tora 的工作流程。
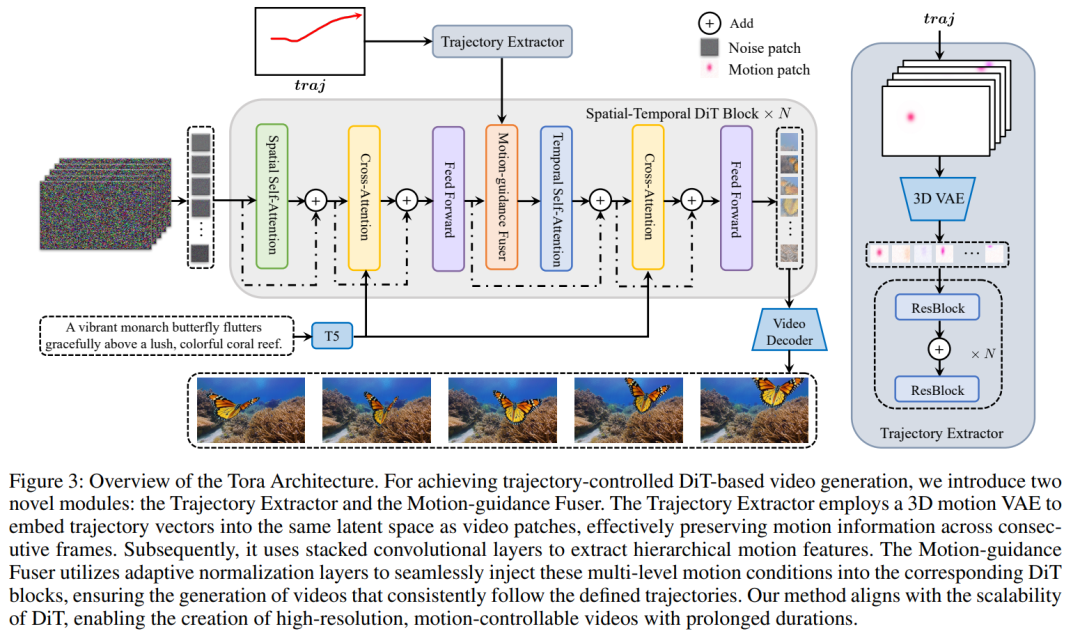
时空 DiT(ST-DiT)
ST-DiT 架构包含两种不同的块类型:空间 DiT 块 (S-DiT-B) 和时间 DiT 块 (T-DiT-B),它们交替排列。S-DiT-B 包含两个注意力层,每个层按顺序执行空间自注意力 (SSA) 和交叉注意力,后面跟着一个逐点前馈层,用于连接相邻的 T-DiT-B 块。T-DiT-B 仅通过用时间自注意力 (TSA) 替换 SSA 来修改此架构,从而保持架构一致性。在每个块中,输入在经过规范化后,通过跳跃连接连接回块的输出。通过利用处理可变长度序列的能力,去噪 ST-DiT 可以处理可变持续时间的视频。
轨迹提取器
轨迹已被证明是一种更加用户友好的方法来控制生成视频的运动。然而,DiT 模型采用视频自编码器和 patch 化过程将视频转换为视频 patch。在这里,每个 patch 都是跨多个帧导出,因此直接采用帧间偏移是不合适的。为了解决这个问题,本文提出的 TE 将轨迹转换为运动 patch,运动 patch 与视频 patch 位于相同的潜在空间。
运动引导融合器
为了将基于 DiT 的视频生成与轨迹结合起来,本文探索了三种融合架构变体,将运动 patch 注入每个 ST-DiT 块。这些设计如图 4 所示。

实验结果
在实现细节上,研究者基于 OpenSora v1.2 权重来训练 Tora。训练视频的分辨率由 144p 到 720p 不等。为了平衡训练 FLOP 以及每次迭代不同分辨率和帧数所需的内存,研究者相应地将批大小从 1 调整到 25。
至于训练基础设施,研究者使用了 4 块英伟达 A100 和 Adam 优化器,学习率为 2 × 10^−5。
研究者将 Tora 与流行的运动指导视频生成方法进行了比较。评估中使用了三种设置,分别为 16、64 和 128 帧,所有设置都是 512×512 的分辨率。
结果如下表 1 所示,在 U-Net 方法常用的 16 帧设置下,MotionCtrl 和 DragNUWA 能够更好地与所提供的轨迹实现对齐,但仍弱于 Tora。随着帧数增加,U-Net 方法在某些帧中出现明显偏差,并且错位误差传播会导致后续序列中出现变形、运动模糊或物体消失。
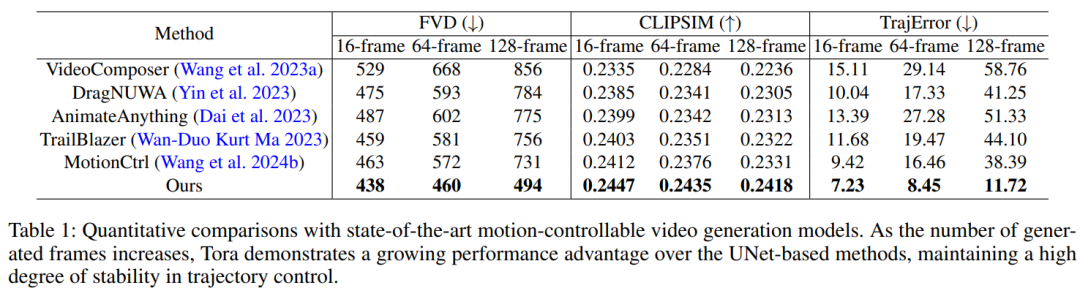
相比之下,得益于集成了 Transformer 的缩放能力,Tora 对帧数变化表现出很高的稳健性。Tora 产生的运动更加流畅,且更符合物理世界。对于 128 帧测试设置下的评估,Tora 的轨迹精度达到其他方法的 3 到 5 倍,展现出了卓越的运动控制能力。
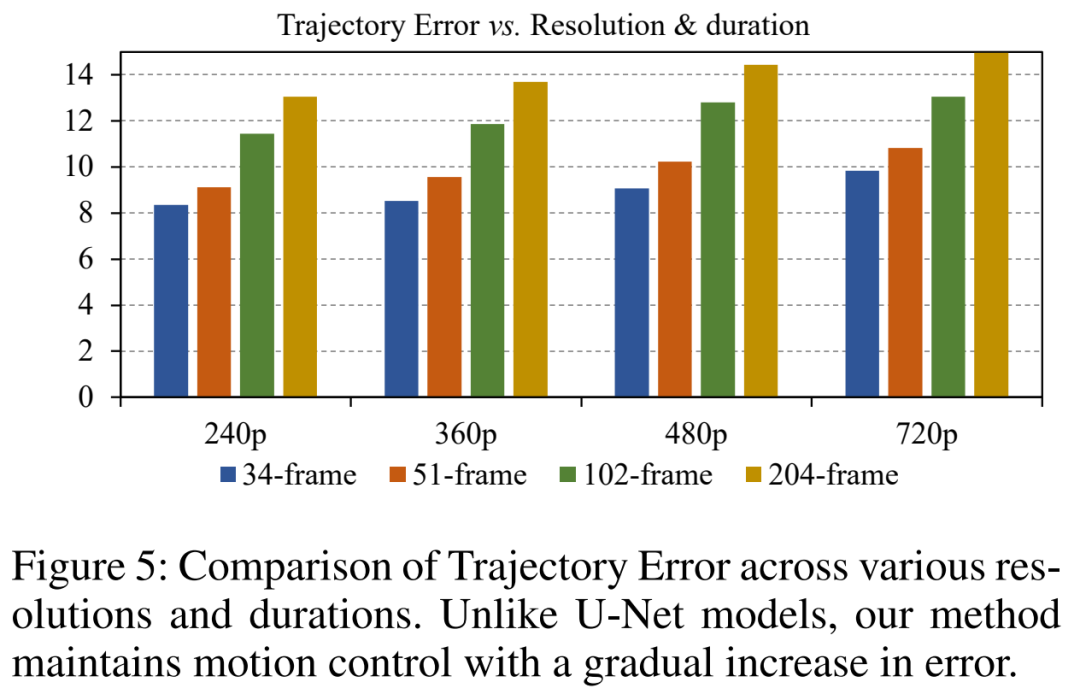
在下图 5 中,研究者对不同分辨率和持续时长的轨迹误差进行分析。结果显示,不同于 U-Net 随时间推移出现明显的轨迹误差,Tora 的轨迹误差随时间推移出现渐进增加。这与 DiT 模型中视频质量随时间增加而下降相一致。Tora 在更长的时间下保持了有效的轨迹控制。
下图 6 展示了 Tora 与主流运动控制方法的比较分析,在包含两人共同运动的场景中,所有方法都能生成相对准确的运动轨迹。不过,Tora 的视觉质量更好,这要归功于更长序列帧的使用,有助于实现更平滑的运动轨迹和更逼真的背景渲染。
可以看到,在 Tora 生成的自行车场景中,人的双腿表现出逼真的踩踏动作,而 DragNUWA 的双腿几乎水平漂浮,违反了物理真实性。此外,DragNUWA 和 MotionCtrl 在视频结尾处都出现了严重的运动模糊。
在另一个生成灯笼的场景中,DragNUWA 随着所提供轨迹的持续升降出现了严重的变形。MotionCtrl 的轨迹虽然相对准确,但生成的视频与两个灯笼的描述不相符。Tora 不仅严格地遵循了轨迹,而且最大程度地减少了物体变形,确保了更高保真度的动作表示。
