在数字化转型的浪潮中,工业大数据正成为推动制造业革新的核心动力。它不仅重塑了生产流程,还为企业带来了前所未有的洞察力和竞争优势。本文将深入探讨工业大数据的类别、价值实现方式,以及在实施过程中存在的挑战和解决方案。
更多详细内容,推荐下载《制造数字化解决方案》
分享行业真实的数字化转型案例,提供完整数字化解决方案!
一、工业大数据有什么类别
1、按照数据产生频度角度分类
工业大数据的产生频度可归纳为三种类型:
- 静态数据
静态数据包括企业信息、资料数据、经验公式和专家知识等,它们相对稳定,变化不大。
- 动态数据
动态数据由设计模型、库存管理、用户反馈等组成,通常由个人或团队维护,其更新频率一般低于计算机处理的速度。
- 实时数据
实时数据由产品、设备、传感器等产生的模拟或数字信息构成,具有较高的产生频度。
2、按照企业经营角度分类
从企业经营的角度来看,工业大数据同样可以分为三个类别:
- 经营性数据
经营性数据数据体现了企业的管理资源和经营成果,涵盖了企业内部的人力、财力、物力以及与企业经营紧密相关的供应商、客户和合作伙伴等基础信息。
- 生产性数据
生产性数据反映了企业的生产能力,覆盖了产品从研发设计到售后服务的整个生命周期,包括了工艺流程、产品生产等各个环节的基础数据。
- 环境类数据
环境类数据数据体现了生产保障能力、质量控制和合规性,涉及设备运行环境、温湿度、噪音、空气质量、废水废气排放和能源消耗等。环境数据的实时监控对于确保产品质量至关重要,它们可以反映生产过程是否符合国家或行业的标准,是否处于正常运行状态。
目前,经营性数据在企业中的应用较为广泛,其利用率超过了生产性和环境类数据。但随着工业互联网的深入应用,人们开始更加重视协同设计、协同制造和供应链管理带来的效益。这些领域的发展预示着,涉及产品全生命周期及质量与能效控制的数据应用将日益普及。
二、 工业大数据价值实现方式
1、累计数据量
工业大数据价值的实现,始于数据量的积累。随着制造业的转型升级,中国将迎来工业2.0、工业3.0和工业4.0的并行发展。这一过程中,庞大的生产规模、国产机器的自主研发推广以及智能化生产的应用,将产生海量的产品数据、运营数据和价值链数据。
这些数据的记录、传输、加工和存储,不仅规模庞大,增长速度惊人,而且为工业大数据的深度挖掘和价值发现提供了丰富的素材和目标。
2、通过深入的数据分析创造商业价值
工业大数据的真正价值,不仅在于其规模的庞大,更在于通过深入分析创造实质性的商业价值。虽然大数据能为企业提供对用户需求的洞察、提升生产效率、革新生产营销模式等优势,但面对来源多样、类型复杂、表现不一的数据,数据的存储、清洗、挖掘和提取工作充满挑战。
要充分挖掘这些数据的潜力,必须综合运用计算机科学、统计模型、机器学习、专家系统等先进分析技术,快速解析数据、提取关键信息、建立数据间的联系,从而获得对企业决策有价值的洞察。经过精心分析和价值挖掘的数据,甚至可以转化为数据产品,实现其商业价值。
3、通过提高数据质量、优化数据管理来加强数据治理
进一步发挥工业大数据的潜力,除了需要积累大量数据和提升数据分析技术外,数据治理同样重要。数据质量的高低和数据管理的优劣直接影响大数据价值的实现。我国工业数据规模庞大,但在数据质量和管理上与发达国家相比仍有不小差距。
造成这一现象的原因包括:我国制造业虽大却不强,多数制造还集中在产业链低端的组装环节,存在低端产品产能过剩和高端产品生产能力不足的问题;生产工艺和流程与国际先进水平相比仍有较大差距。
此外,在工业4.0和工业互联网概念普及之前,我国制造业主要依靠低成本劳动力获得竞争优势,对先进机械设备的依赖相对较弱。制造企业内部的现代化管理水平不高,产业链协同效应较差,数据孤岛现象普遍,数据应用基础薄弱。产业链低端环节、生产流程的简单性、对人工的依赖以及生产流程和产业链的孤立性,都导致了数据质量差、管理不善、数据关联度低和管理意识薄弱,这些问题都限制了大数据价值的有效发挥。
三、 工业大数据实施存在的问题
1、数据质量不足
数据质量是企业在大数据时代获得竞争优势的关键。企业对自身数据资产的重视程度日益提升,但数据的价值在很大程度上取决于其质量。采用相同的数据采集和加工技术,不同质量的原始数据可能导致截然不同的结果,劣质数据不仅增加了处理难度,还可能造成误导。
目前,我国工业数据在一致性、完整性、准确性和及时性方面存在诸多挑战,例如物料管理中的编码不一致和生产过程中的时间标记混乱等问题。因此,确保数据质量是提高分析结果质量的前提,实施大数据项目时必须从源头抓起,强调数据质量控制,以确保大数据应用的有效性。
2、多数据源关联困难
工业数据的积累因其来源多样而呈现出高噪声、异构性和大规模的特点,为数据分析和应用带来了不小的挑战。建立有效的数据关联模型,从多源异构数据中挖掘数据间的联系,对于实现大数据的集成应用至关重要。
例如,中性BOM模型通过向前关联设计和制造,向后关联服务和保障,构建了一个星型BOM结构,这不仅简化了数据关联的复杂性,还解决了产品生命周期管理中BOM结构失配的问题。通过这样的方法,我们可以更好地整合和应用来自不同源头的数据,从而充分发挥大数据的潜力。
3、 大数据系统集成问题
大数据的系统集成是发挥数据潜力的另一关键所在。通过重新构建数据支撑平台,我们能够消除企业内部各部门之间以及生产各环节的数据壁垒,同时实现企业内部数据与外部互联网数据、半结构化数据与结构化数据的无缝连接。这样的集成不仅能够降低数据收集的成本,还能使数据的真正价值得以充分展现。
通过这种集成,企业能够构建起一个统一的数据视图,使得决策者能够基于全面的数据信息做出更加明智的决策。此外,集成的数据系统也为数据分析和业务流程优化提供了坚实的基础,有助于企业在激烈的市场竞争中保持领先。因此,实现多源数据的有效集成,是降低成本、提升效率、发掘数据深层价值的重要一步。
鉴于制造企业在实施工业大数据时存在的问题, 帆软软件有限公司为广大客户提供了包括解决方案以及工业大数据分析平台在内的等多种工具,为制造企业挖掘工业大数据价值、破解工业大数据实施存在的问题提供多种选择。
帆软是国内领先的数据软件服务商,深耕数字行业十八年,能够依托于自身数字化产品,为各行业企业提供数字化转型解决方案。为协助制造企业迈向数字化转型,帆软成立了数字制造事业部,专注于制造业领域的数据分析与数据规划。
帆软为制造业提供了包括经营、财务、生产以及供应链等在内的解决方案与工业大数据分析平台。
- 制造业经营组织管控解决方案
帆软结合企业调研结果,搭建符合各经营组织战略定位的核心指标监控平台,打通数据壁垒,统一数据标准与口径,实现中高层决策可视化、即时化,同时直观展示企业经营管理水平和企业实力,打造企业数字化形象,助力制造业数字转型。
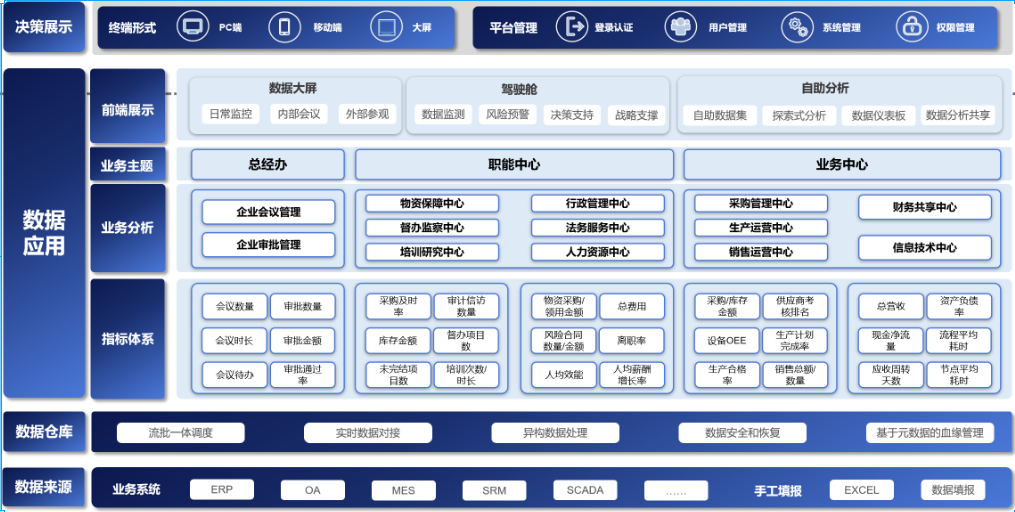

- 制造业财务战略决策分析平台
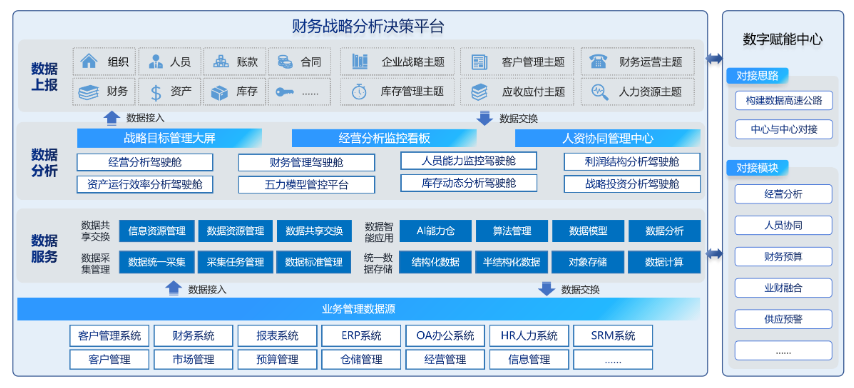
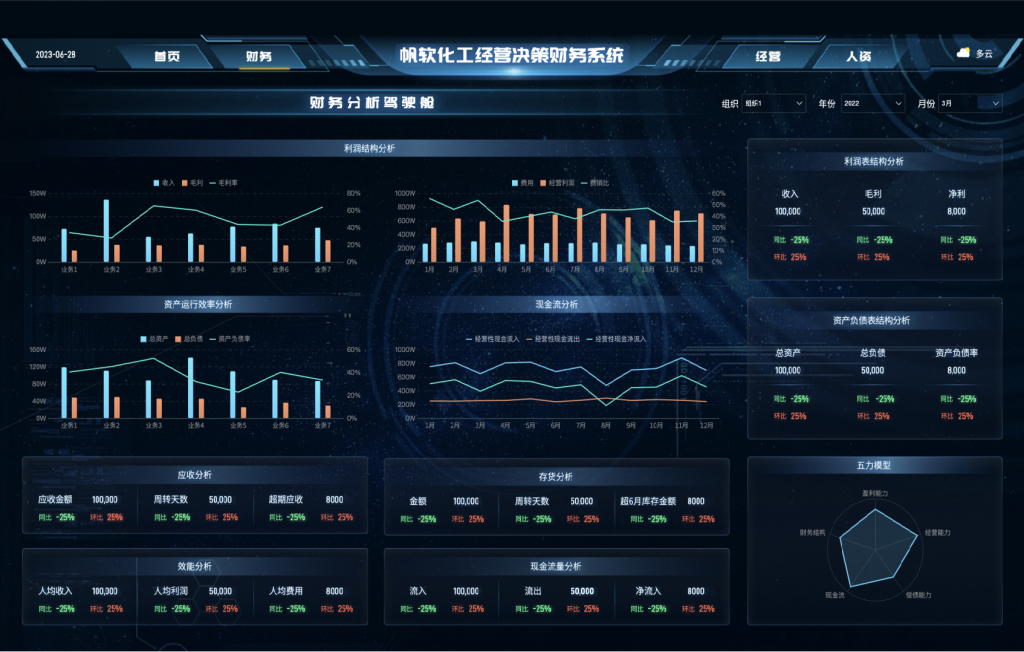
帆软以集团企业战略规划局为导向,以集团绩效管理为基础,根据各管理层的管理职责及关注点进行定制化设计,从财务盈利能力、偿债能力、营运能力等财务五力角度丰富分析内容,通过多维度的灵活分析及重点单项的管理,全面助力企业财务数字化管理。
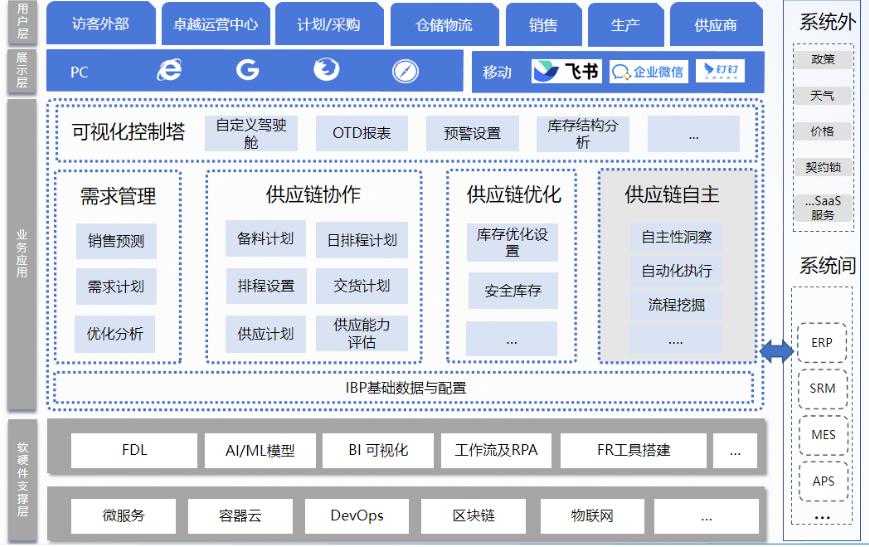
帆软基于SCOR的预设指标体系,提供可视化的数据分析工具来对OTD整体供应链进行分析、预测、预警与决策管理;
实现供应链流程中各业务部门、各业务流程的可视化,也实现供应链内外部的高效协作与快速响应。
四、 总结
本文我们深入探讨了工业大数据的多样化类别、价值实现方式,以及在实施过程中所面临的挑战。通过分析,我们认识到工业大数据不仅是企业转型升级的催化剂,也是推动制造业数字化转型的关键资源。从静态的企业信息到动态的库存管理,再到实时的产品和设备数据,每一种数据类型都承载着独特的价值和潜力。
尽管我国在工业数据的规模上具有优势,但在数据质量和管理上仍有很大的提升空间。数据质量不足、多数据源关联困难、大数据系统集成问题等,都是我们在挖掘工业大数据价值时需要克服的难题。
更多详细内容,推荐下载《制造数字化解决方案》
分享行业真实的数字化转型案例,提供完整数字化解决方案!