摘 要 : 目的 光场相机可以通过单次曝光同时从多个视角采样单个场景,在深度估计领域具有独特优势。消除遮挡的影响是光场深度估计的难点之一。现有方法基于2D场景模型检测各视角遮挡状态,但是遮挡取决于所采样场景的3D立体模型,仅利用2D模型无法精确检测,不精确的遮挡检测结果将降低后续深度估计精度。针对这一问题,提出了3D遮挡模型引导的光场图像深度获取方法。方法 向2D模型中的不同物体之间添加前后景关系和深度差信息,得到场景的立体模型,之后在立体模型中根据光线的传输路径推断所有视角的遮挡情况并记录在遮挡图(occlusionmap)中。在遮挡图引导下,在遮挡和非遮挡区域分别使用不同成本量进行深度估计。在遮挡区域,通过遮挡图屏蔽被遮挡视角,基于剩余视角的成像一致性计算深度;在非遮挡区域,根据该区域深度连续特性设计了新型离焦网格匹配成本量,相比传统成本量,该成本量能够感知更广范围的色彩纹理,以此估计更平滑的深度图。为了进一步提升深度估计的精度,根据遮挡检测和深度估计的依赖关系设计了基于最大期望(exception maximization,EM)算法的联合优化框架,在该框架下,遮挡图和深度图通过互相引导的方式相继提升彼此精度。结果 实验结果表明,本文方法在大部分实验场景中,对于单遮挡、多遮挡和低对比度遮挡在遮挡检测和深度估计方面均能达到最优结果。均方误差(mean square error,MSE)对比次优结果平均降低约19.75%。结论针对遮挡场景的深度估计,通过理论分析和实验验证,表明3D遮挡模型相比传统2D遮挡模型在遮挡检测方面具有一定优越性,本文方法更适用于复杂遮挡场景的深度估计。
**关键词:**光场;深度估计;3D遮挡模型;抗遮挡;最大期望(EM)
o引言
光场相机通过对单个场景进行多视角密集采样,使得高精度深度信息的挖掘成为可能,在深度传感器中不论在便携性还是深度精确性方面都具有显著优势,适用于电影游戏特效、增强现实和人机交互等多种应用场景。
利用光场的各种特性可以挖掘深度信息,基于极平面图像(epipolarplaneimages,EPIs)(Bolles等,1987)的方法(Wanner和Goldluecke,2012)、多视角立体匹配(multi-viewstereo,MVS)方法(Chen等,2014;Jeon等,2015)和基于焦堆栈的方法(Lin等,2015;Strecke等,2017)都取得了一定成果,但对于光场深度估计领域的遮挡、噪声和无纹理等问题依然很难解决。在这些问题中,遮挡是最常见且难以避免的 。对一个郎伯面上未遮挡的空间点 ,若光场聚焦在正确深度,则与该点对应的多视角图(angularpatch)将呈现成像一致性(photo-consistency)(Wang等,2015;Williem和Park,2016),该性质是光场深度估计的重要前提。
图1是基于场景的2D模型和3D模型的估计遮挡图。可以看出,基于2D模型估计遮挡的遮挡检测算法(Sheng等,2017;Zhang等,2018)无法保证估计遮挡图的精确性(图1(a))。基于采样场景的3D立体模型估计遮挡时,遮挡物的存在使部分采样光线无法到达目标点,导致成像一致性无法成立(图1(b)),强行基于成像一致性建立成本量将导致遮挡边界附近的深度估计不精确。
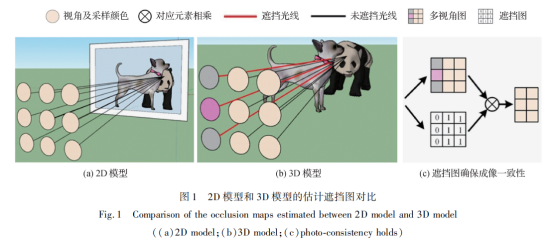
从2D模型重建3D模型需要场景的深度信息,但其隐含在光场数据中且无法直接使用。针对这一问题,本文提出基于伪立体模型的遮挡检测方法,通过向2D模型添加深度差信息和不确定的前后景关系对场景进行立体建模,本文将得到的模型定义为伪立体模型。之后基于伪立体模型直接判断每个空 间点对应的多视角图的遮挡状态,记录在遮挡图中。得益于遮挡图,场景可根据遮挡状态划分为遮挡区 域和非遮挡区域,以在不同区域采取更加适合区域 特性的成本量 。对于遮挡区域 ,若能利用遮挡图准确屏蔽多视角图中的被遮挡视角,在郎伯假设下,剩余视角依然可满足成像一致性(图1(c)),并可以基于剩余视角在聚焦状态的成像一致性建立成本量,因此如何识别多视角图的遮挡部分对于遮挡感知深度估计至关重要。对于非遮挡区域,提出离焦网格匹配成本量,该成本量通过对聚焦状态进行微小偏移,使其能够捕获更广泛区域的色彩纹理,进而增加算法鲁棒性。最后,基于遮挡检测和深度估计的依赖关系(深度图可为遮挡检测提供高精度3D模型,遮挡图可帮助成本量屏蔽被遮挡的视角)设立了基于最大期望(exception maximization,EM)算法的联合优化框架,在该框架下,遮挡图和深度图将通过互相引导的方式来提升彼此精度。
本文的主要贡献如下:1)提出基于伪立体模型的遮挡检测方法,在遮挡检测前首先重建场景的3D模型。相比传统基于2D模型的遮挡检测算法,生成的遮挡图精确度更高。2)提出离焦网格匹配算法,对传统正对焦状态进行小距离偏移,成本量将能够感受更广范围的色彩纹理。3)基于遮挡检测和深度估计的依赖关系设计基于EM的联合优化框架,利用估计的深度图更新场景立体模型,继而完成遮挡图的更新。更新后的遮挡图将引导成本量获取更高精度的深度图。
1 相关工作
光场的多视角采样特性使深度信息的挖掘成为可能,然而受遮挡影响,部分视角与空间点之间的光路被切断,这部分被拦截视角将影响该空间点的深度估计精度。因此,为了获得精确的深度图,正确的遮挡处理十分必要。常用的遮挡处理方法包括空间约束和色彩约束两类。色彩约束将像素映射到直方图,可以忽略遮挡模式,将复杂的遮挡抑制问题转换为离群值约束问题,极大减少了算法复杂度。空间约束借助场景几何结构检测并抑制遮挡影响的视角,具有优秀的遮挡处理能力。由于色彩约束算法的性能受遮挡区域的色彩对比度影响,遮挡抑制效果往往弱于空间约束(Johannsen等,2017)。本文提出的遮挡处理方法旨在提升遮挡场景的深度估计质量,基于空间约束展开,因此仅对基于空间约束的相关工作进行介绍。
空间约束即通过场景几何结构获取多视角图遮挡模式或深度正则化先验信息,借此提升遮挡边界附近的深度估计精度。Wang等人(2015)利用子孔径图像与多视角图中遮挡方向的一致性,使用与子孔径图像边界斜率一致的直线将多视角图划分为大小相等的两个区域,视方差较小的区域为不包含遮挡视角的区域,有效避免了单遮挡。然而当遮挡物的边界不规则或存在多个遮挡物时,多视角图的两个区域无法通过一条直线分隔,因此无法排除所有遮挡影响的视角。为了解决这一问题,Sheng等人(2017)将边界引导改为图像块引导,从中心图像提取更加详细的遮挡信息建立积分引导滤波器(inte-gral guided filter,IGF)以抑制多视角图中可能遮挡的视角,提升了多遮挡情况的深度估计精度。但这种引导方式对平面色彩纹理具有很强的响应,可能会造成有用信息的丢失。为了提升遮挡检测的鲁棒性,Zhang等人(2018)从多视角图中提取遮挡信息并集成于基于微透镜(micro-lens-based,MLB)的深度估计框架。相比于中心图像,多视角图包含的信息更能还原真实遮挡分布,因此更能提高算法的抗遮挡能力,但效果受目标点的视差影响,过大或过小的视差均会降低遮挡约束能力。Chen等人(2018)通过基于超像素正则化检测部分遮挡的边界区域(partially occluded border regions,PROB),并通过遮挡感知正则项将正确的深度标签传播到PROB。遮挡感知正则项可以在保持锐利遮挡边缘的同时平滑深度图,但其正则化能力取决于聚类结果的准确性,边界拟合较差的超像素将加剧混淆趋势。Guo等人(2019)改变了遮挡处理思路,提出无需检测遮挡的遮挡处理算法,设计了一系列视角掩膜分别计算不同掩膜下的成像一致性,并经过最小池化筛选最佳匹配成本,缺陷是遮挡抑制能力受掩膜与遮挡模式的契合程度制约,并且过多的掩膜会引入大量计算成本。
上述算法除了Guo等人(2019)的算法,对遮挡的处理均基于场景的2D模型,缺乏对场景的立体分析。而本文算法的遮挡检测直接基于场景立体模型,得到的遮挡图更加贴近真实遮挡模式,在利用遮挡图的基础上,针对不同区域设计更加契合区域特性的成本量。其中针对非遮挡区域设计的离焦网格匹配成本量,相比传统匹配算法能够感知更广范围的色彩纹理。
2 本文方法
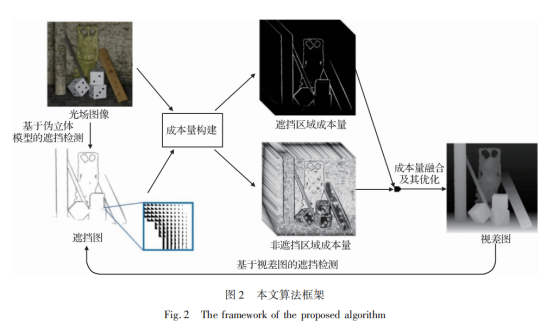
针对光场深度估计的遮挡问题,本文算法首先从光场图像中提取初始遮挡图,之后在遮挡图的引导下对遮挡区域和非遮挡区域分别构建成本量,初始视差图由合并后成本量求解得到,最后采用EM思想,逐步提升视差图的精度,直至收敛。算法框图如图2所示,具体步骤如下:
1)提取初始遮挡图。利用提出的基于伪立体模型的遮挡检测算法,完成3D模型的重建,并基于3D模型生成高精度遮挡图。
2)构造成本量。基于高精度遮挡图,分别在遮挡区域和非遮挡区域构建成本量。
3)成本量融合及求解。采用滤波方法对成本量进行融合并计算视差图。
4)迭代。采用EM思想,交替更新遮挡图和视差图,直至收敛。
对光场捕获的光线,本文使用多目成像的表述方式描述,记作L(s,p),其中s=(u,v)为采样到该光线的视角在视角平面内的坐标,p=(x,y)为该光线在视角s成像中的坐标。特别地,使用sc=(uc,vc)表示中心视角对应的视角平面内的坐标,并将其作为参考视角。
2.1基于伪立体模型的遮挡检测
检测物体的遮挡状态需要物体之间的3D位置关系,但相机拍摄的2维图像只能得到平面两个维度的位置关系,丢失了深度维。为此,本文在缺乏真实深度信息的情况下利用伪立体模型进行高精度遮挡检测。
2.1.1伪立体模型的建立
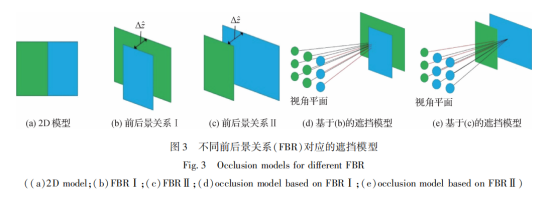
深度不同的两个物体之间的遮挡边界(occlu-sionboundaries)在2维图像中往往以色彩边界的形式呈现,如图3(a)所示。本文方法在检测遮挡前,通过向色彩边界两侧加入前后景关系(foreground-background relation,FBR)和深度差
对场景完整建模。图3(b)(c)为边界两侧区域两种可能的前后景关系。其中,蓝色和绿色物体轮流作为前景。图3(b)为蓝色物体作为前景的情况,深度比绿色物体小
,图3(c)反之。图3(d)(e)为与图3(b)(c)对应的遮挡模型。因无法确切判定场景的2D采样(图3(a))具体对应哪种前后景关系,为了达到遮挡检测的目的,采用同时包含两种前后景关系的立体模型。当检测绿色区域目标点的遮挡状态时,采用图3(b)的前后景关系Ⅰ;反之,使用图3(c)的前后景关系Ⅱ,即默认目标点始终来自背景。本文将这种同时包含两种前后景关系的立体模型定义为伪立体模型。虽然伪立体模型的逻辑假设不符合物理规律,但是这种假设能将边界两侧所有遮挡情况同时合并为一个模型,在缺失前后景信息的情况下包含所有遮挡情况。
2.1.2伪立体模型的有效性分析
由于场景中两个点之间的真实深度差无法直接获取,因此伪立体模型采用的深度差
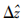
也难以直接确定。
与真实深度差不匹配将造成遮挡图计算不精确。加入的深度差满足条件
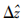
>Δz时,基于伪立体模型的遮挡检测将能准确估计所有遮挡视角,其中Δz为边界两侧区域的真实深度差。
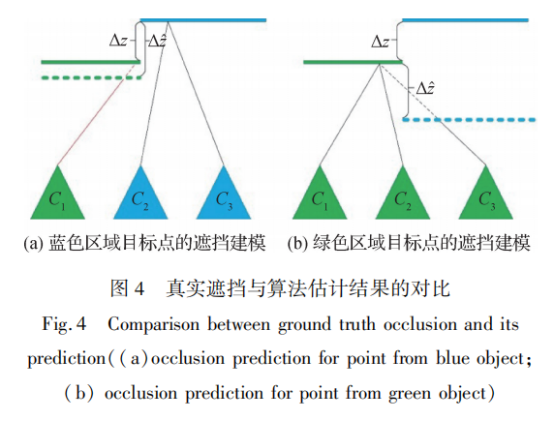
图4展示了边界两侧区域的遮挡检测过程。为了方便描述,此处将2维平面映射到1维,其中绿色和蓝色实线为边界两侧区域的真实位置,绿色和蓝色虚线表示伪立体模型对前景的预测位置,C1~ C3表示视角,填充色为采样真实位置(即实线位置)处的颜色。图4(a)为蓝色实线目标点的遮挡检测,当满足条件
>Δz时,若视角被真实前景(绿色实线)遮挡,其必然也会被模型预测前景(绿色虚线)遮挡,如视角C1的采样光线在到达真实前景前必然经过预测前景,因此真实遮挡视角始终是模型估计结果的子集。图4(b)为绿色实线目标点的遮挡检测,由于真实遮挡视角为空集,可被任意集合包含,因此也必然是模型估计结果的子集。由此可推出当满足条件
>Δz时,伪立体模型是有效的。
2.1.3基于伪立体模型的遮挡检测公式化表示
假设模型有效性前提
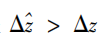
已满足,给定中心图像的边界图edge,光线L(s,p)的遮挡状态可由下式获取

式中,occ为0表示对应光线遮挡,occ为1表示未遮挡。
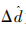
为伪立体模型向边界两侧区域添加的视差的差值。occ(s,p)=0对应的条件表示在中心图像的目标点p和点p+(s-sc)×
之间存在边界点。
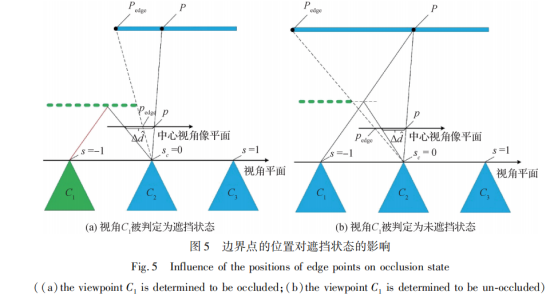
图5展示了边界点的位置对遮挡状态的影响,为方便描述,此外将视角平面坐标s和sc、空间图像坐标p压缩为1维,分别对应于s、sc和p,L压缩为2维光场。图5中P和Pedge分别表示空间点P和边界点Pedge在中心视角像平面内的坐标。因模型有效性已验证,故遮挡状态由模型直接确定。以s=-1为例,若在点p和点p+(s-sc)×
检测到边界点pedge,根据伪立体模型定义可知,以pedge为分界线,p所在的一侧将建模为背景,另一侧为前景,建模结果表明光线L(s,p)被遮挡,如图5(a)所示,相反,若点p和点p+(s-sc)×
之间不存在边界点,则L(s,p)将不被遮挡,如图5(b)所示。
根据深度---视差映射函数的单调特性(Wanner和Goldluecke,2012),若使式(1)满足伪立体模型的有效性,
的取值范围可直接由有效性前提
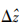
>Δz转换得到,转换结果为

式中,Δd为边界两侧区域真实视差的差值。虽然Δd无法直接计算,但其有上界Δdmax,Δdmax表示待估计场景的视差跨度,场景内任意两区域的视差跨度均小于此值。Δdmax的大小取决于相机基线以及场景的深度跨度,可固定为一个较大值或根据拍摄设备和应用场景进行调整。在实验部分,对于合成场景,使用数据集提供的视差范围设置Δdmax,对于LytroIllum拍摄的真实场景,Δdmax固定为1.5。考虑到精确率和召回率的平衡,实验设置
=cΔdmax,其中c=⅔。图6(c)为使用式(1)对光场数据进行遮挡检测的结果。与有效性分析一致,基于伪立体模型的遮挡检测可估计出所有遮挡视角,但由于伪立体模型同时包含两种前后景关系,会误将部分非遮挡区域判定为遮挡区域,继而导致信息丢失,该问题可通过加入视差信息解决。

2.2 深度估计基于伪立体模型的遮挡检测
在遮挡检测完成后,利用遮挡图将场景分为遮 挡区域和非遮挡区域,并为两个区域分别设计成本 量 。多视角图包含遮挡视角的像素划入遮挡区域 Ωocc ,其余像素划入非遮挡区域Ωflat。
- 2.1 遮挡区域深度估计
使用遮挡图屏蔽遮挡区域像素的遮挡视角后,剩余视角存在局部成像一致性。传统衡量一致性的方式大致分为两类:以中心视角为基准的MVS成本量(Chen等,2014)和基于多视角图(methods based on angular patches,MAP)的成本量(Tao等,2013)。MVS对中心视角赋予了较大权重,因此对其他视角的少数离群值有较强鲁棒性。MAP对每个视角赋予一致的权重,对整体视角灰度值的轻微波动有较强鲁棒性。
为提高算法稳定性,算法默认遮挡检测始终具 有一定的漏判率,即遮挡图无法排除所有遮挡视角。MVS与MAP相比有更加出色的抗遮挡性能,因此 采用MVS成本量形式,并集成遮挡图,具体为
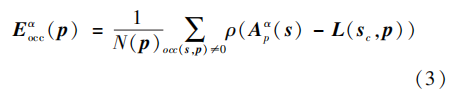
式中, Apα(s) 表示重聚焦(Ng 等 ,2005)标签为α 时像素 p 处的多视角图 统计各个像素处未遮挡的视角数目, σ 表示控制函数对颜色差异的敏感程度。
- 2.2 非遮挡区域深度估计
非遮挡区域与遮挡区域相比有更缓慢的深度变化,并且不会发生深度跳变。在设计数据成本时,传统的 MAP或 MVS算法都没有很好地利用非遮挡区域的深度连续特性,均使用成像一致性寻找使多视角图颜色最一致的深度标签。但是,若目标像素和周围像素之间的颜色距离较近,则存在大量深度标签可使多视角图均呈现高度一致性,标签的混淆将影响估计深度的精确性。
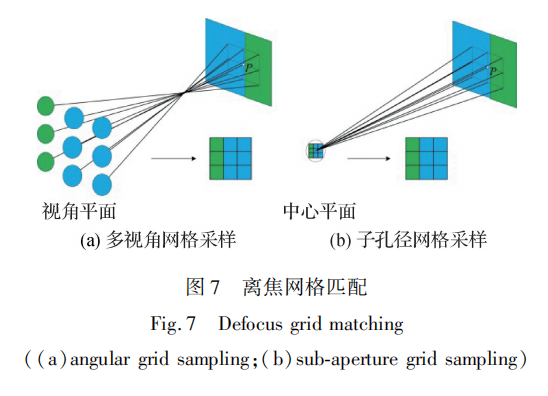
为了充分利用深度连续特性 ,设计了离焦网格匹配(defocusgridmatching,DGM)成本量。成本量示意图如图7(a)所示,此时焦点和目标点P所在平面之间存在一定距离,多视角图中各个视角均采样不同空间位置。假设目标点 P所在平面为前平行面(front-parallelplane),在相邻视角之间基线相等的情况下,这些采样点将对应以 P为中心的网格的顶点,该采样模式定义为多视角网格采样。如果利用中心视角对该平面等间距采样,其采样点也将对应于网格的顶点,本文将此采样模式定义为子孔径网格采样,如图 7(b)所示。DGM成本量基于两种采样模式的采样结果的差异构建而成,其中子孔径网格采样使用固定的采样间隔,多视角网格采样通过改变聚焦参数来调整其采样间隔。若两种采样模式的采样间隔相等,将得到相同的采样结果。DGM 成本量函数为
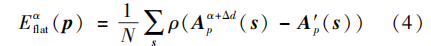
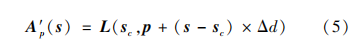
式中,N表示多视角图包含视角的数量,Δd表示子孔径采样间隔,Apα+Δd为像素p处重聚焦标签为α+Δd时的多视角网格采样点,A′p为p处的子孔径网格采样点。
与传统匹配方法相比,DGM具有更分散的采样点,因此可捕获更广范围的纹理。当目标点处于无纹理区域时,DGM分散的采样点将能够感知各自位置处的色彩变化,有效减少标签的混淆。
2.3成本量融合及其优化
遮挡区域和非遮挡区域成本量均根据参与匹配的视角数目进行归一化处理,最终成本量将由两者拼接而成,具体为
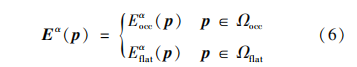
为了使高置信度点的有效信息传播到低置信度区域,需要利用光场中心图像作为引导图对成本量进行逐标签引导滤波优化(Rhemann等,2011;Sheng等,2017)。引导滤波能够在传播信息的同时有效保持遮挡边界处的深度不连续性。与基于图割(Boykov等,2001)的优化算法相比,基于滤波的方法具有更低的时间复杂度,且能够并行处理多个标签。而且由于遮挡图的引导作用,成本量已具备较高可靠性,基于滤波的信息传播算法足以应对大部分实验场景,最终视差标签直接由滤波后的成本量通过赢者通吃策略(winner-takes-all)生成。
2.4基于EM的联合优化框架
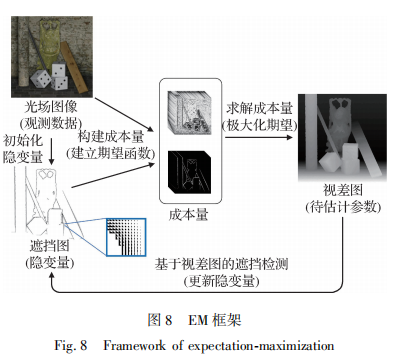
视差图可以为遮挡检测提供高精度3D模型,而基于精确3D模型生成的遮挡图将能够有效提升成本量的抗遮挡性能,进而生成更高精度的视差图。 基于此特性,设计基于EM的联合优化框架来交替提高遮挡图和视差图的精度。
2.4.1基于视差图的遮挡检测
光场图像、遮挡图和视差图可分别作为观测数据、隐变量和待估计参数融入EM框架,通过基于伪立体模型的遮挡检测、深度估计和成本量融合及其优化构成了光场图像和遮挡图到视差图的单向估计。为了形成回路,使用视差图估算高精度遮挡图。 如图8所示。
对于视差图中的像素p,设其视差值为d(p)。 当像素p周围存在视差值较大的另一像素q,p处多视角图中的部分视角将可能被q遮挡。基于这一性质筛选可能被遮挡的像素,具体为
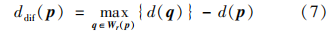
式中,Wr(p)为以p为中心、r为边长的矩形窗。当ddif(p)>0,则将p标记为待检测像素。式(7)可以有效分辨边界两侧的前景和背景,当像素p来自视差较小的背景时,ddif(p)>0;反之,ddif(p)=0。 为了避免将斜平面和曲面误判为遮挡场景,为ddif(p)设置略微大于零的阈值dthred,若ddif(p)>dthred,则p为待检测像素。
使用上述操作筛选出场景所有待检测像素之后,再利用伪立体模型对所有筛选出的待检测像素进行遮挡检测。由于RGB图像边界定位遮挡边界的能力较差,构建伪立体模型时将视差图的边界图作为遮挡边界图输入式(1)。同时,为了进一步利用视差信息,使用ddif(p)代替伪立体模型的预设值Δd^。基于视差图引导的遮挡检测结果如图6(d)所示,与图6(c)未使用视差引导的检测结果相比,在伪立体模型中使用视差信息引导,能够有效地去除被误判的遮挡区域,进一步提高了遮挡检测精度。
2.4.2构建联合优化框架
融入基于EM的联合优化框架后,整体深度估计流程如下:
1)遮挡图(隐变量)的初始值由基于伪立体模型的遮挡检测生成。
2)E(exception)步:在遮挡图的引导下建立成本量(期望函数)。
3)M(maximization)步:最小化成本(最大化期望)计算视差图。之后通过基于视差图的遮挡检测生成更准确的遮挡图(更新隐变量)。
在基于EM的联合优化框架下,算法具有较快的收敛速度。这是由于:1)在参数初始化部分,伪立体模型生成的遮挡图已经具有较高精度,精确的初始化将大幅减少算法迭代次数;2)在设计成本量时充分考虑了算法稳定性,降低了其对输入遮挡图的精度要求。
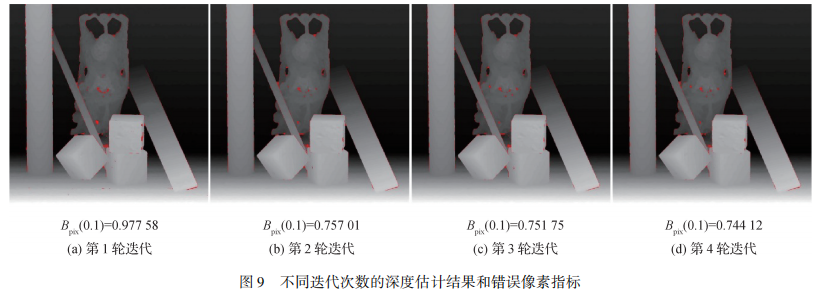
图9为算法在不同迭代次数时的视差估计结果。其中第2轮之后迭代结果已趋于平稳,过多的迭代次数将极大提高计算成本。综合考虑,实验将迭代次数iters固定为2。
3 实验结果与分析
实验在Light Field Benchmark(Wanner等,2013;Honauer等,2016)合成数据集和StanfordLytroIllum真实场景数据集上进行。为确保公正性,所有参与评比的算法均以75为标签数目。定量评估利用错误像素比例Bpix(t)和均方误差MSE来衡量算法的优劣,具体为
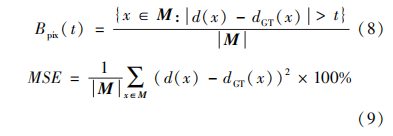
式中,d(x)为算法生成视差,dGT(x)为真实视差,M为视差图像素集合。
3.1参数选择
在式(3)和式(4)中,参数σ决定着ρ(x)对颜色差异x的敏感程度,如图10所示,σ越小越会放大相似像素之间的距离,而离群值的能量贡献将会因为饱和变为常数,从而有效避免多视角图中遮挡像素的影响,提供清晰的视差边界。大部分实验中遮挡区域的σ设为0.08,非遮挡区域的σ设为0.15。
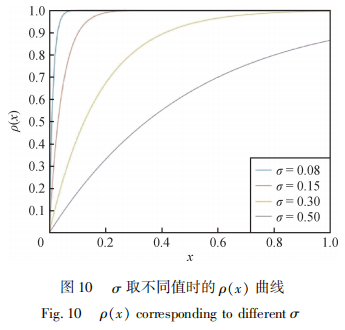
在噪声过高的场景,使用预设的σ值将导致较高的错误率,这是因为最佳参数往往与场景的信噪比相关。如果多视角图存在过多噪声干扰的像素,在σ较小的情况下,这些像素将因能量饱和造成信息丢失。因此需要增大σ以提高饱和区的阈值,使系统能够感知受轻微噪声影响的像素的颜色变化。 图11展示了在高噪情况下使用不同σ的深度估计情况,图中红色区域为Bpix(0.07)判定的错误像素。 使用预设σ值的结果存在大面积坏像素,但随着σ值的变大,坏像素的比例逐渐减少,最终维持在较低水平。对高噪场景,实验将σ设置为0.5。

3.2遮挡检测
判断视角的遮挡状态对深度估计至关重要。实验在不同遮挡模式下将本文方法与LF_OCC(light field occlusion)(Wang等,2015)和IGF(Sheng等,2017)方法进行对比。与单像素的遮挡图比较方式不同,实验着重考察算法对遮挡区域内所有多视角图的判断结果。这种考察方式需要算法能够对所有不同程度的遮挡做出正确响应。图12展示了不同遮挡模式下算法的遮挡检测结果,其中图像块IV的标记区域为对比度增强后的结果。

可以看出:
1)LF_OCC算法在单遮挡场景具有较好表现,但仅对位于遮挡边界处的像素做出响应。原因是LF_OCC算法假设遮挡仅发生在遮挡边界处。但通过全聚焦微透镜阵列可以看出,遮挡以遮挡边界为起点向背景扩散。在图像块IV的低对比度遮挡区域,由于边界检测失效而没有对遮挡做出响应。对不包含遮挡的图像块V和VI,由于该区域强纹理导致误判为遮挡区域。
2)IGF算法具备较好的遮挡边界定位能力,但估计的遮挡区域覆盖了较多非遮挡区域。原因是IGF算法在2D模型中根据目标点和周围点之间的颜色距离生成遮挡图,缺乏视差信息引导,因此无法分辨前景和背景。并且当目标点处于弱纹理区域时,例如图像块IV,由于遮挡场景的低对比度将无法生成正确遮挡图。与LF_OCC算法类似,由于缺乏视差信息的引导,在图像块V和VI中无法分辨强纹理和遮挡边界。
3)本文算法在各种遮挡模式下的表现均优于其他算法,尽管第1次迭代未对图像块IV的低对比度遮挡区域做出正确响应,但在第2次迭代中利用视差信息成功生成了较为精确的遮挡图。对图像块V和VI中的强纹理区域,第1次迭代误将一些未遮挡视角标记为遮挡视角,但是在第2次迭代中通过集成视差信息做出了正确响应。
3.3深度估计
本文方法与LF_OCC(Wang等,2015)、POBR(par-tially occluded border regions)(Chen等,2018)、MLB(Zhang等,2018)和LF_PAC(light field partial angular coherence)(Guo等,2019)方法的量化指标Bpix(0.1)和MSE(mean square error)的对比如表1和表2所示。
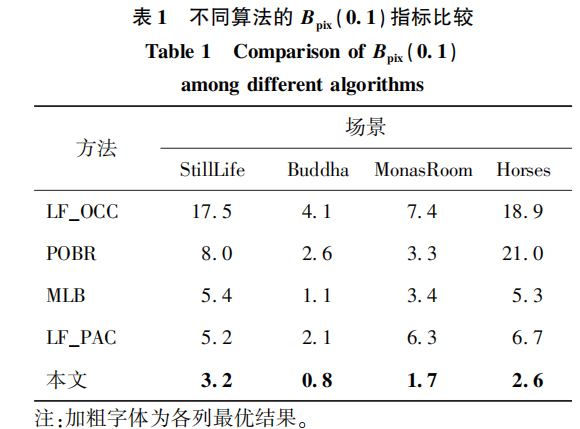
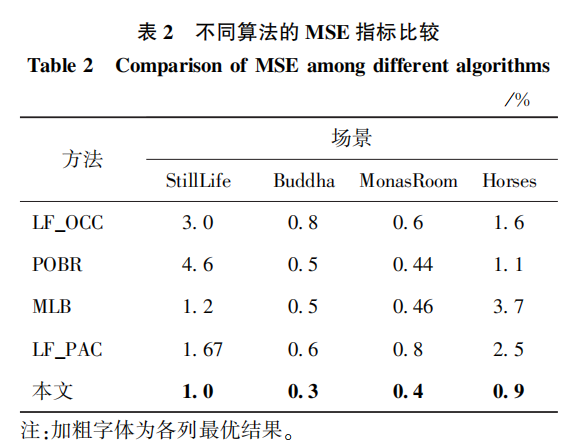
可以看出,本文算法在所有场景中的表现均优于其他算法。
- 3.1 遮挡区域表现
图13为使用Light Field Benchmark数据集的视差估计结果。可以看出,LF_OCC算法虽然进行了抗遮挡处理,但根据遮挡检测实验可知,其无法处理多遮挡和低对比度遮挡,因此造成了该类型区域的边界混淆。POBR聚类方法由于不能在狭窄多遮挡区域生成正确的超像素,因此造成了遮挡边界附近前后景的混淆。LF_PAC由于其优秀的视角掩膜算法,在单遮挡边界处表现良好,但对复杂遮挡情况,其视角掩膜无法与遮挡模型形成较好匹配,最终导致前后景混淆。本文算法能够较好地判断各种遮挡模式,因此在遮挡区域具有良好表现。

真实场景实验使用Stanford Lytro Illum数据集,并从中挑选了包含复杂遮挡情况的场景,视差估计结果如图14所示。可以看出,在场景Ⅰ和场景Ⅲ中LF_OCC和LF_PAC算法出现了不同程度的结构断裂,POBR和MLB算法虽然没有出现结构断裂,但是造成了前后景混叠,而本文方法很好地恢复了网格结构,在场景Ⅱ中,本文方法较好地恢复了狭窄的孔洞部分,而其他算法不同程度地将孔洞部分填平,导致信息丢失。

- 3.2 整体表现
图15为本文方法与SPO(spinningparallelogramoperator)(Zhang等,2016)、LF_OCC(Wang等,2015)、CAE(constrainedangularentropy)(Williem等,2018)、IGF(Sheng等,2017)和LF_PAC(Guo等,2019)方法在LightFieldBenchmark数据集Stratified系列场景中的视差估计结果对比,实验采用的度量标准包括stripes的Lowtexture度量(弱纹理区域的Bpix(0.07)度量),Backgammon和Dots的Bpix(0.07)度量和Pyramids的MSE度量。可以看出,SPO算法在低纹理区域存在较多错误像素,原因是其基于EPIs的方法只使用部分视角信息,无法捕捉更大范围的纹理。LF_OCC算法只能处理单遮挡情况,因此其无法重建Backgammon的狭窄缝隙。场景Pyramids包含大量强纹理,由于IGF算法的遮挡图屏蔽了较多未遮挡的视角,丢失了较多有用信息,因此即使在非遮挡区域也生成了错误像素。LF_PAC算法在stripes的低纹理区域存在大量错误像素,这是由于其掩膜集合在此区域均具有相近的响应,无法通过最小池化选出与遮挡匹配的视角掩膜。相比之下,在遮挡区域,本文算法在每个多视角图中均排除了几乎所有遮挡视角,取得了较好表现。在强纹理和噪声区域,在视差信息的引导下,本文算法成功避免了非遮挡区域纹理的干扰,充分利用光场每个视角提供信息。实验结果表明,本文算法在大多数场景均具有最好表现,与其他算法相比,可以实现更高的整体精度。
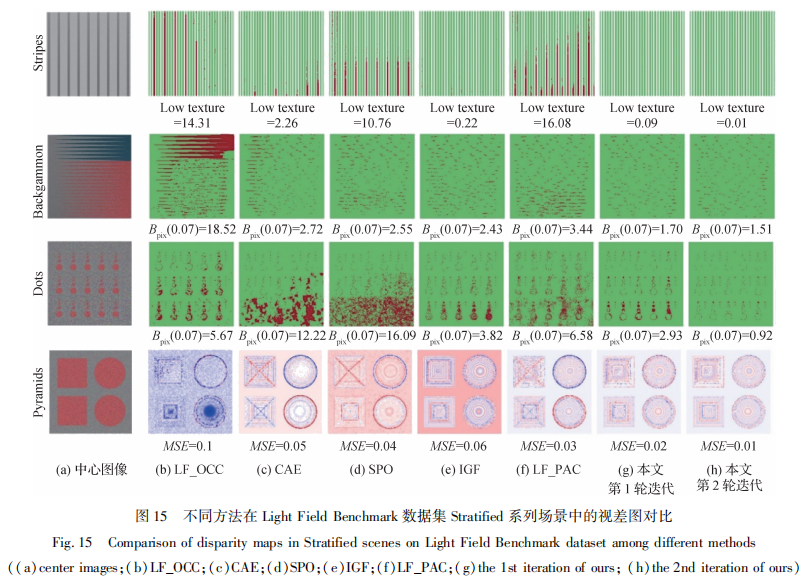
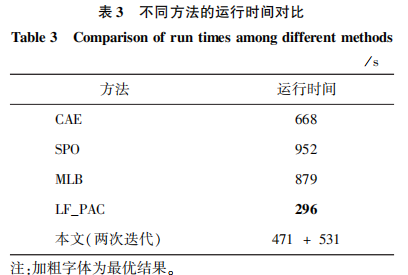
表3为本文算法与对比算法的运行时间对比,数据规格均采用512×512×9×9。可以看出,虽然本文算法在总迭代时间上不占优势,但图15表明,在深度估计方面本文算法的单次迭代比其他算法具有较大优势。对于单次迭代而言,本文算法的时间复杂度达到次优水准。
4 结论
针对复杂遮挡场景设计了3D遮挡模型引导的光场图像深度估计方法。首先基于伪立体模型生成高精度遮挡图 ,避免了遮挡视角对成本量的干扰,然后将遮挡检测和深度估计融入基于 EM 的联合优化框架,提升了深度估计精度。对比目前先进的基于2D模型的遮挡检测算法,本文算法能够更加准确地估计多种复杂遮挡模式,并且针对遮挡区域和非遮挡区域分别设计成本量的策略使本文方法对不同区域具有更好的适应性。本文方法的关键是遮挡图的构建,为此在初始化步骤中将伪立体模型添加的视差差值设置为较大值,此举虽可有效排除大部分遮挡视角,但后果是造成了部分有用信息丢失。下一步工作将通过利用低分辨率算法快速生成粗估计视差来解决初始视差差值不精确的问题,以进一步提升深度估计精度。
文章来源:中国图像图形学
文章作者:吴迪、张旭东、张骏、范之国、孙锐(合肥工业大学计算机与信息学院)
声明:转载此文目的在于传递更多信息,仅供读者学习、交流之目的。文章版权归原作者所有,如有侵权,请联系删除。