模型训练相关
思路:
- 导入数据集(对数据集转换为张量)
- 加载数据集(使数据集成为可以进行迭代)
- 搭建卷积模型
- 进行模型训练(每训练一轮查看一次在测试集上的准确率)
- 使用tensorboard进行可视化
- 保存训练后的模型
- 加载训练好的模型进行测试.
选择的模型结构
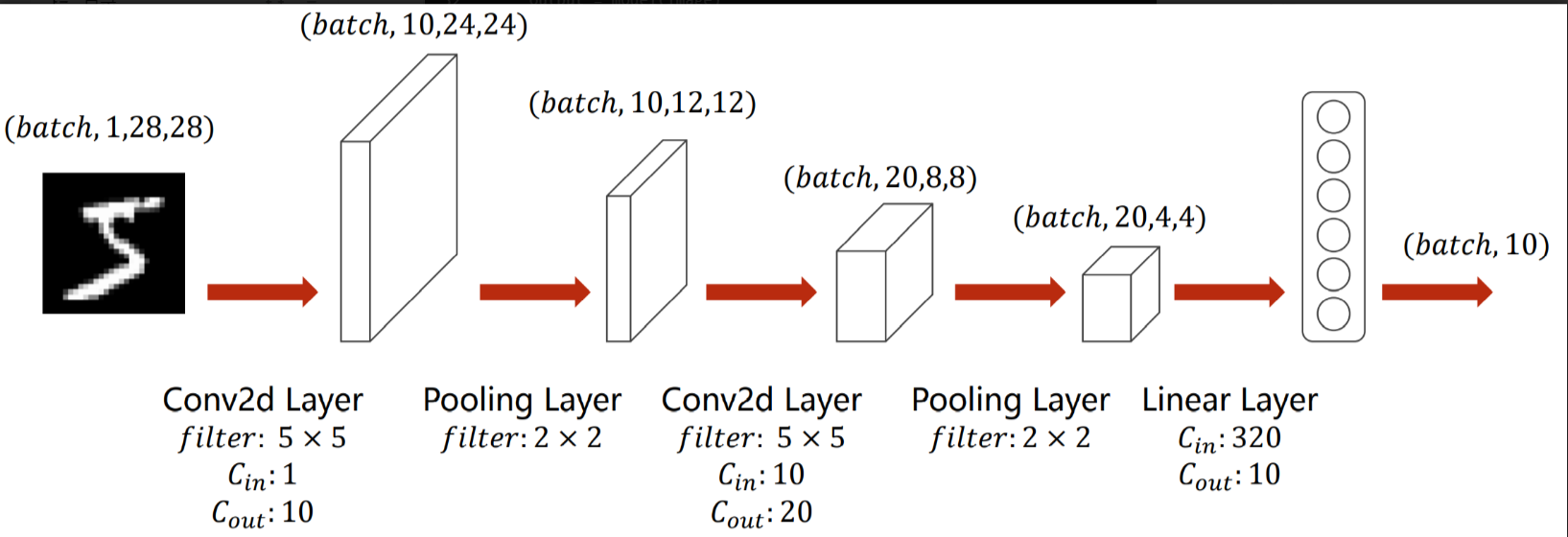
训练模型和评估模型
在conda命令行输入
tensorboard --logdir="tensorboard --logdir=D:\student\ai-study\02框架学习\logs\mnist"
打开可视化面板
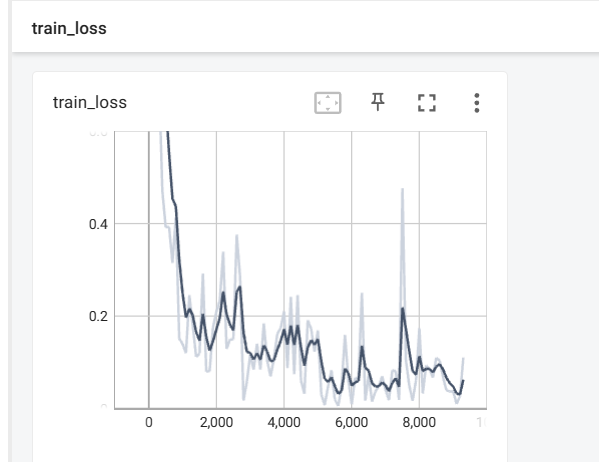
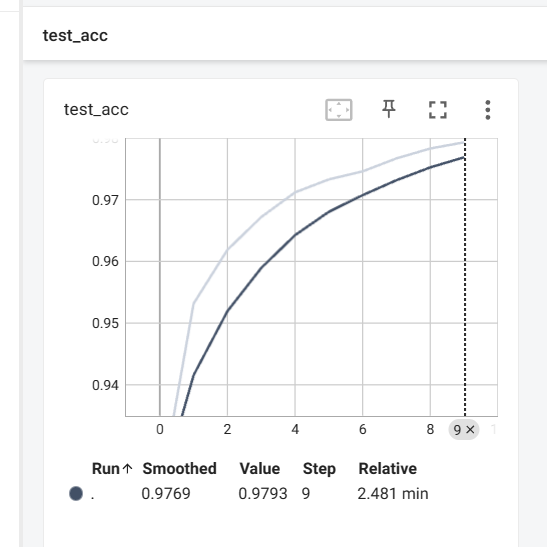
在测试集上的准确率不断上升
训练和评估完整代码
python
"""
@author:Lunau
@file:022_mnist.py
@time:2024/08/07
@任务:使用pytorch对mnist数据集进行训练和测试
"""
import torch
import torchvision
import time
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
"""
@root:存放数据集的目录
@train:为True表示是作为训练集
@transforms:导入数据集的同时进行预处理
@download:为True表示从网络下载模型
"""
# 导入数据集 这里没有归一化
train_data = torchvision.datasets.MNIST("./dataset/MNIST", train=True, transform=
torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.MNIST("./dataset/MNIST", train=False, transform=
torchvision.transforms.ToTensor(), download=True)
# # 加载数据集,方便进行迭代
train_dataloader = DataLoader(dataset=train_data, batch_size=64)
test_dataloader = DataLoader(dataset=test_data, batch_size=64)
# img, target = test_data[0]
# print(img)
# print(target)
# 构建卷积层
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5, padding=0, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5, padding=0, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=320, out_features=10)
)
def forward(self, x):
x = self.model(x)
return x
# 创建卷积模型
model = Model()
# 损失函数 交叉熵
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(params=model.parameters(), lr=learning_rate)
# 可视化
writer = SummaryWriter("./logs/mnist")
# 训练网络的参数
total_train_step = 0 # 训练次数
total_test_step = 0 # 测试次数
# 训练
def train():
# 训练步骤开始
model.train()
global total_train_step
for data in train_dataloader:
imgs, targets = data
outputs = model(imgs)
loss = loss_fn(outputs, targets) # 计算当前损失
# 优化器进行优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 ==0:
writer.add_scalar("train_loss", loss, total_train_step) # 可视化每轮的损失
print(f"训练次数:{total_train_step}, Loss:{loss}")
def test():
global total_test_step
model.eval()
total_test_loss = 0
total_accuracy = 0
test_data_len = len(test_data)
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
output = model(imgs)
loss = loss_fn(output, targets)
total_test_loss +=loss
accuracy = (output.argmax(1) == targets).sum().item() # 计算出正确的次数
total_accuracy+=accuracy
total_accuracy = total_accuracy / test_data_len
# 在整体测试集上的损失
print(f"整体测试损失Loss:{total_test_loss}")
# 整体测试的正确率
print(f"整体测试的正确率acc:{total_accuracy}")
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_acc", total_accuracy, total_test_step)
total_test_step +=1
return total_accuracy
if __name__ == '__main__':
epoch = 10 # 训练的轮数
for i in range(epoch):
print(f"第{i + 1}轮训练开始")
train()
test()
torch.save(model, "mnist1.pth")测试模型
测试的照片
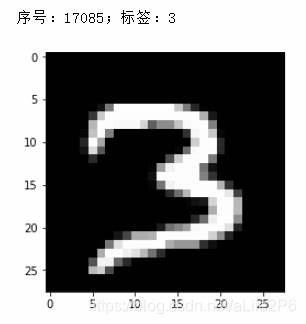

测试代码
python
"""
@author:Lunau
@file:023_mnist_test.py
@time:2024/08/07
"""
import cv2
import torch
import torchvision
import torchvision.transforms as transforms
from PIL import Image
from torch import nn
# 测试模型
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5, padding=0, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5, padding=0, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=320, out_features=10)
)
def forward(self, x):
x = self.model(x)
return x
# 测试单张照片
def test_one_image():
image_path = "./images/mnist_3.jpg"
image = Image.open(image_path)
print(image)
image = image.convert('L')
image.show()
# 图片进行转换
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((28, 28)),
torchvision.transforms.ToTensor()
])
image = transform(image)
print(image.shape)
# 加载模型 若模型是在gpu训练出来,需要在cpu上运行需要进行一个映射
model = torch.load("./mnist1.pth")
image = torch.reshape(image, (1, 1, 28, 28)) # 转换一下尺寸,为输入要求的尺寸
# 测试
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(f"手写数字是:{output.argmax(1).item()}")
test_one_image()