ubuntu20.04系统下安装SlowFast行为检测项目并跑通训练
- 前言
- 一、GitHub源码下载
- 二、环境配置
-
- [1.1 查看linux系统配置](#1.1 查看linux系统配置)
- [2.2 查看合适的pytorch版本:](#2.2 查看合适的pytorch版本:)
- [3.3 新建anoconda环境并配置](#3.3 新建anoconda环境并配置)
- [4.4 安装detectron2](#4.4 安装detectron2)
- [5.5 配置SlowFast中的python路径到环境变量](#5.5 配置SlowFast中的python路径到环境变量)
- [6.6 安装SlowFast:](#6.6 安装SlowFast:)
- 三、下载预训练好的模型文件并做预测
-
- [1.1 在模型Zoo里面下载一个预训练好的模型](#1.1 在模型Zoo里面下载一个预训练好的模型)
- [2.2 准备好类别文件](#2.2 准备好类别文件)
- [3.3 配置yaml文件](#3.3 配置yaml文件)
- [4.4 修改源码两处导包报错](#4.4 修改源码两处导包报错)
- [5.5 终端执行,得到预测的MP4文件](#5.5 终端执行,得到预测的MP4文件)
- [6.6 预测效果](#6.6 预测效果)
- 四、下载官方数据集并训练
-
- [1.1 训练数据准备](#1.1 训练数据准备)
-
- [1.1.1 下载视频](#1.1.1 下载视频)
- [1.1.2 下载的视频切取15-30分钟](#1.1.2 下载的视频切取15-30分钟)
- [1.1.3 对切取的15分钟视频,提取视频帧](#1.1.3 对切取的15分钟视频,提取视频帧)
- [1.1.4 下载标注文件](#1.1.4 下载标注文件)
- [1.1.5 整理我们需要的训练文件](#1.1.5 整理我们需要的训练文件)
- [2.2 下载预训练权重](#2.2 下载预训练权重)
- [3.3 配置yaml文件](#3.3 配置yaml文件)
- [4.4 训练](#4.4 训练)
- [5.5 用自己训练的模型预测](#5.5 用自己训练的模型预测)
前言
1、因个人电脑配置不一样,python环境配置这一块可以参考下文进行配置
2、训练用到的文件及数据集已全部上传 ,可以下载使用
把以下资源全部下载
下载后如下:

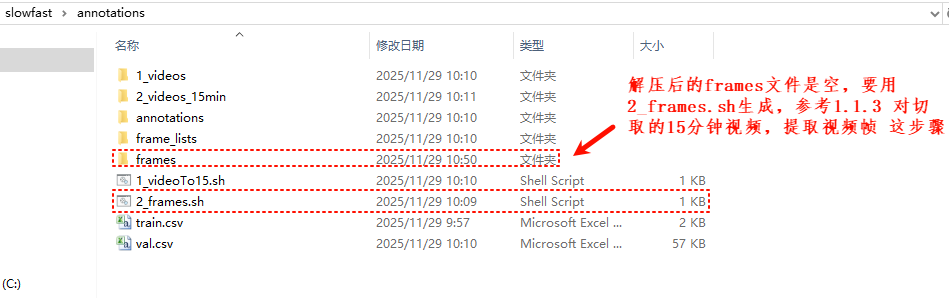
全部解压后将模型文件里面的两个预训练模型放入SlowFast文件夹中

参考1.1.3步骤重新生成frames文件夹
最终配置好的训练文件如下:
一、GitHub源码下载
1、下载SlowFast地址:https://github.com/facebookresearch/SlowFast
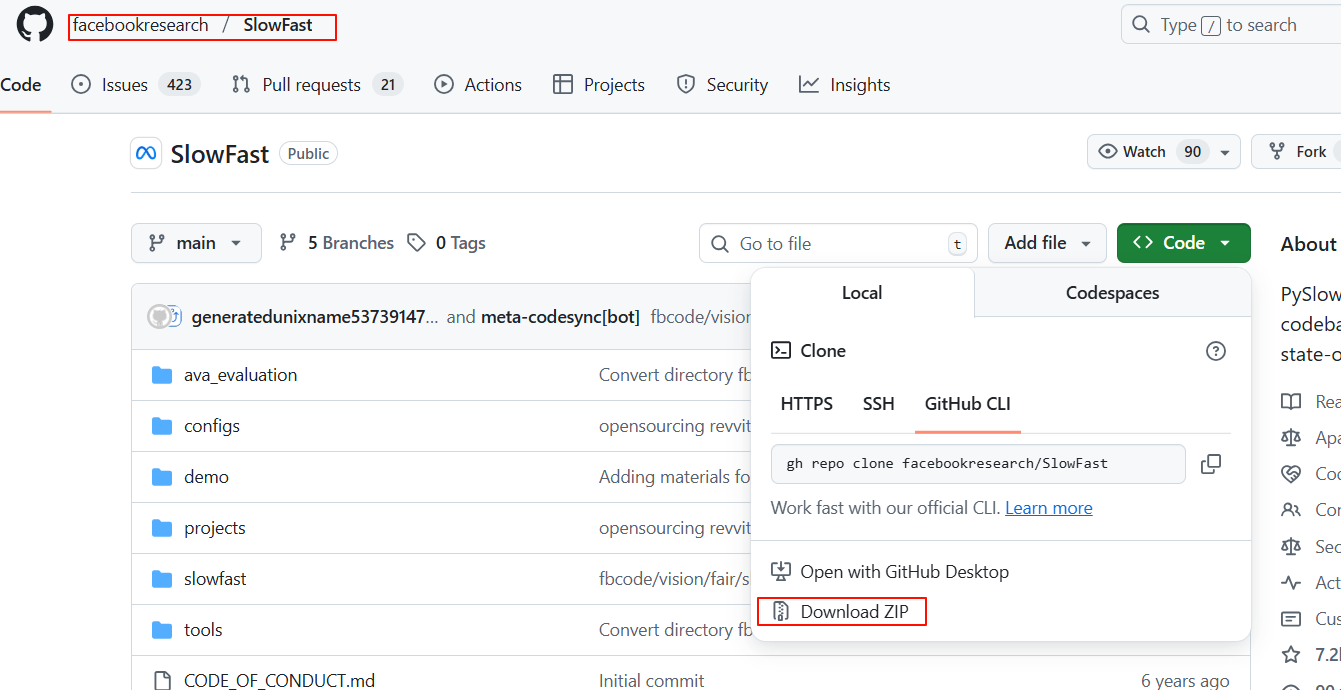
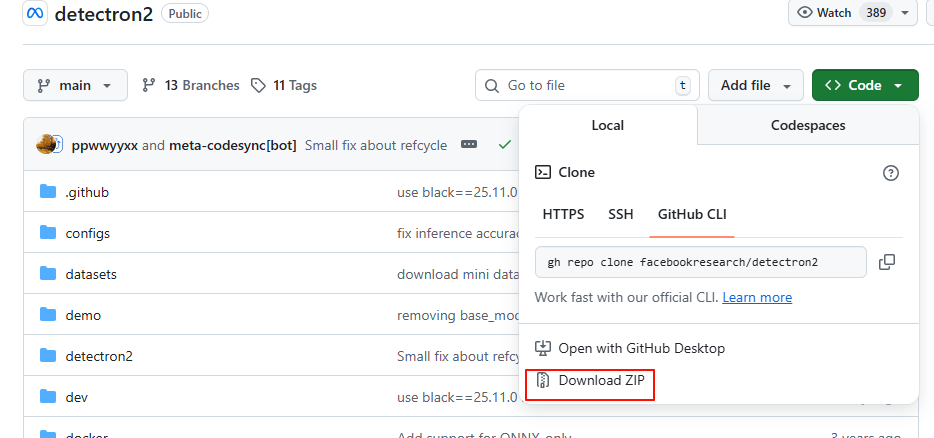
2、下载detectron2地址:
https://github.com/facebookresearch/detectron2
下载后重命名两个文件夹
二、环境配置
1.1 查看linux系统配置
装有4090显卡
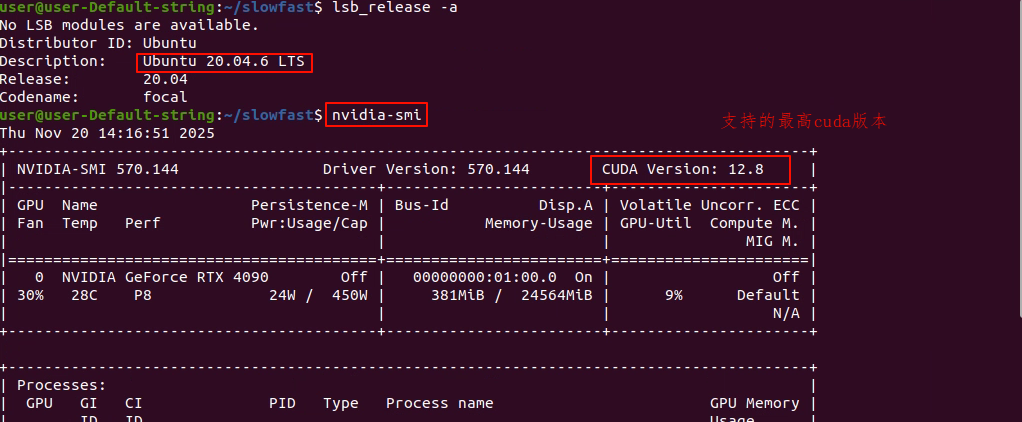
2.2 查看合适的pytorch版本:
地址:https://pytorch.org/get-started/locally/

pytorch安装指令:
python版本>=3.10
cuda支持最高12.8,这里安装12.6
bash
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu1263.3 新建anoconda环境并配置
步骤1: conda create -n slowfast python=3.10 -y (注意python版本)

步骤2:安装pytorch
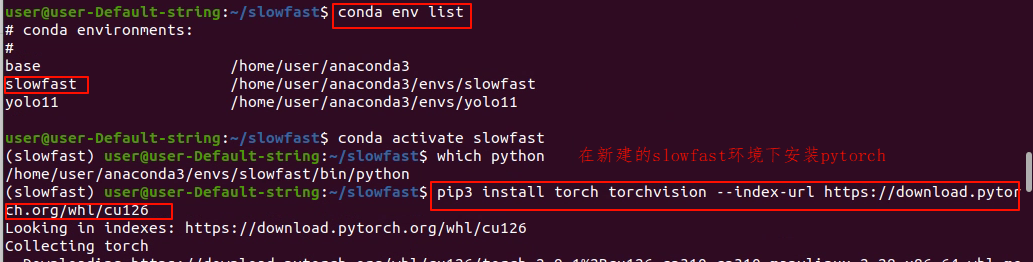
步骤3:在slowfast环境下依次安装以下依赖
sudo apt update && sudo apt install -y git (安装git)
pip install -U cython -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install setuptools==65.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
conda install av -c conda-forge
pip install -U fvcore pycocotools -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install -U 'git+https://github.com/facebookresearch/fairscale' -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install -U matplotlib opencv-python pandas psutil simplejson scikit-learn tensorboard -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install git+https://github.com/facebookresearch/pytorchvideo.git -i https://pypi.tuna.tsinghua.edu.cn/simple/
(pytorchvideo包一定要和代码中使用的一致,这样安装才不会报错)
pip install cloudpickle -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install omegaconf==2.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
sudo apt update && sudo apt install -y gcc g++ cmake libgl1-mesa-glx libglib2.0-0
4.4 安装detectron2
python setup.py develop
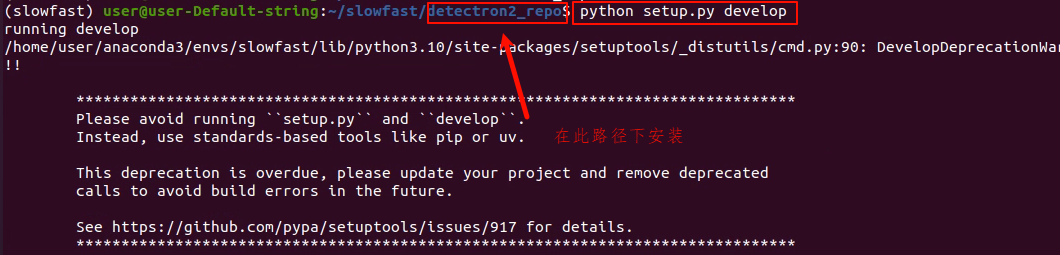
验证安装:
python -c "import detectron2; print('Detectron2 安装成功!版本:', detectron2.version )"

5.5 配置SlowFast中的python路径到环境变量
cd到SlowFast文件路径下:

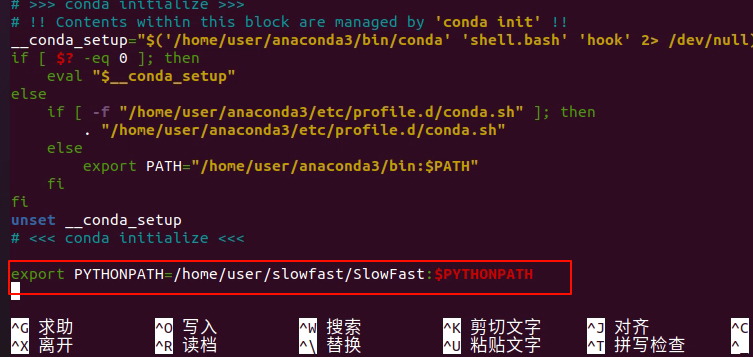
按 Ctrl + O(字母 O,不是数字 0)保存文件,按回车确认;
按 Ctrl + X 退出编辑模式;
source ~/.bashrc 立即生效
echo $PYTHONPATH 验证


6.6 安装SlowFast:
cd 到SlowFast:
python setup.py build develop

验证安装:
python -c "import slowfast; import detectron2; print('SlowFast 导入成功!'); print('Detectron2 导入成功!')"

三、下载预训练好的模型文件并做预测
1.1 在模型Zoo里面下载一个预训练好的模型
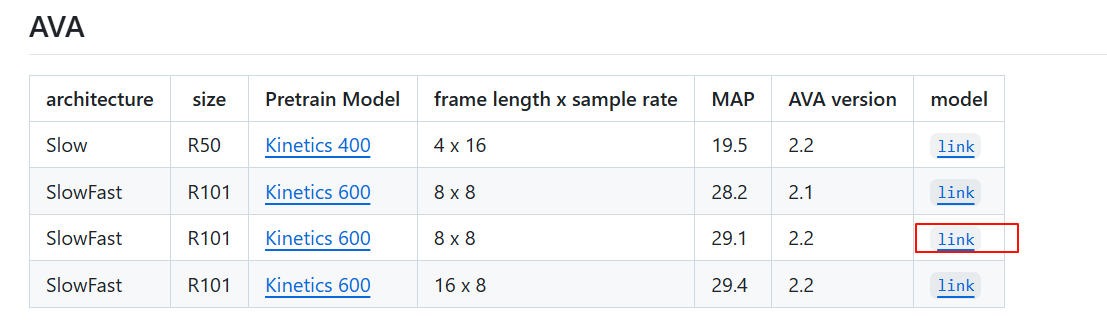
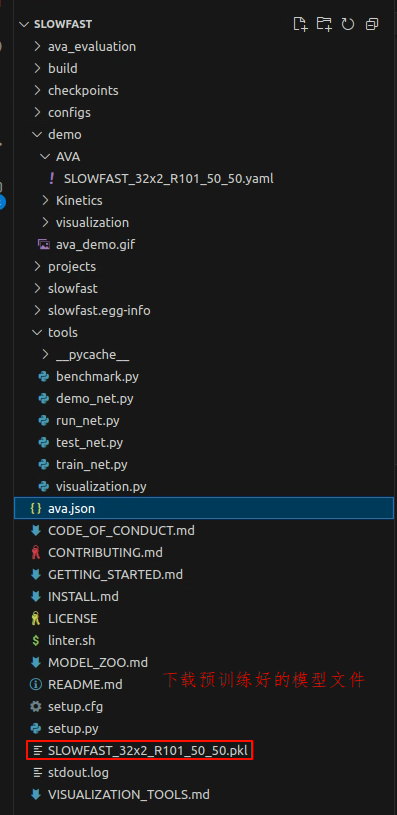
下载好的权重文件是:SLOWFAST_32x2_R101_50_50.pkl
2.2 准备好类别文件
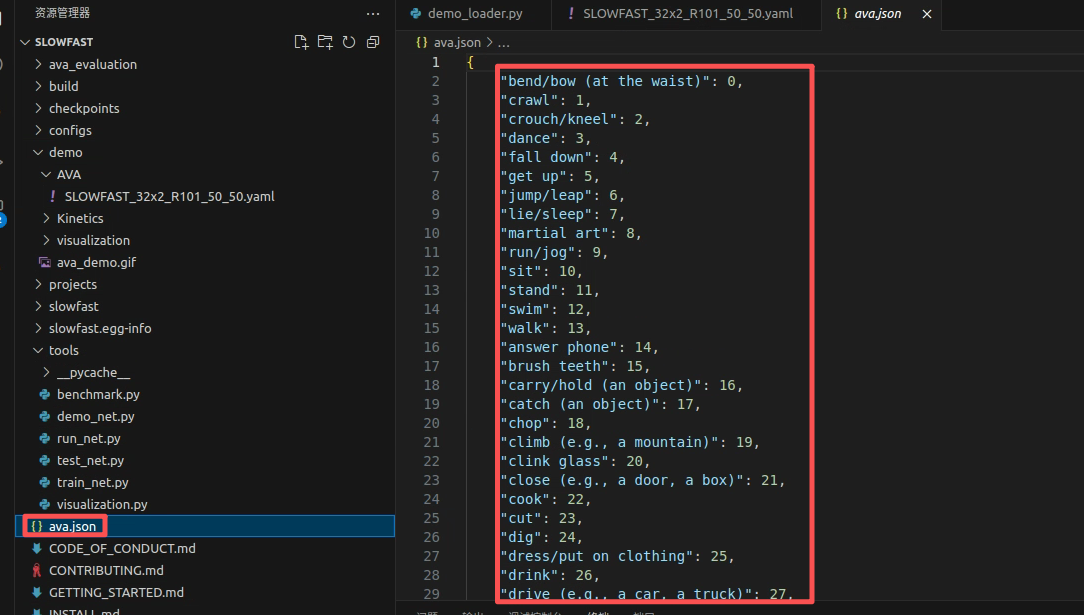
python
{
"bend/bow (at the waist)": 0,
"crawl": 1,
"crouch/kneel": 2,
"dance": 3,
"fall down": 4,
"get up": 5,
"jump/leap": 6,
"lie/sleep": 7,
"martial art": 8,
"run/jog": 9,
"sit": 10,
"stand": 11,
"swim": 12,
"walk": 13,
"answer phone": 14,
"brush teeth": 15,
"carry/hold (an object)": 16,
"catch (an object)": 17,
"chop": 18,
"climb (e.g., a mountain)": 19,
"clink glass": 20,
"close (e.g., a door, a box)": 21,
"cook": 22,
"cut": 23,
"dig": 24,
"dress/put on clothing": 25,
"drink": 26,
"drive (e.g., a car, a truck)": 27,
"eat": 28,
"enter": 29,
"exit": 30,
"extract": 31,
"fishing": 32,
"hit (an object)": 33,
"kick (an object)": 34,
"lift/pick up": 35,
"listen (e.g., to music)": 36,
"open (e.g., a window, a box)": 37,
"paint": 38,
"play board game": 39,
"play musical instrument": 40,
"play with pets": 41,
"point to (an object)": 42,
"press": 43,
"pull (an object)": 44,
"push (an object)": 45,
"put down": 46,
"read": 47,
"ride (e.g., a bike, a horse)": 48,
"row boat": 49,
"sail boat": 50,
"shoot": 51,
"shovel": 52,
"smoke": 53,
"stir": 54,
"take a photo": 55,
"text on/look at a cellphone": 56,
"throw": 57,
"touch (an object)": 58,
"turn (e.g., a screwdriver)": 59,
"watch (e.g., TV)": 60,
"work on a computer": 61,
"write": 62,
"fight/hit (a person)": 63,
"give/serve (an object) to (a person)": 64,
"grab (a person)": 65,
"hand clap": 66,
"hand shake": 67,
"hand wave": 68,
"hug (a person)": 69,
"kick (a person)": 70,
"kiss (a person)": 71,
"lift (a person)": 72,
"listen to (a person)": 73,
"play with kids": 74,
"push (another person)": 75,
"sing to (e.g., self, a person, a group)": 76,
"take (an object) from (a person)": 77,
"talk to (e.g., self, a person, a group)": 78,
"watch (a person)": 79
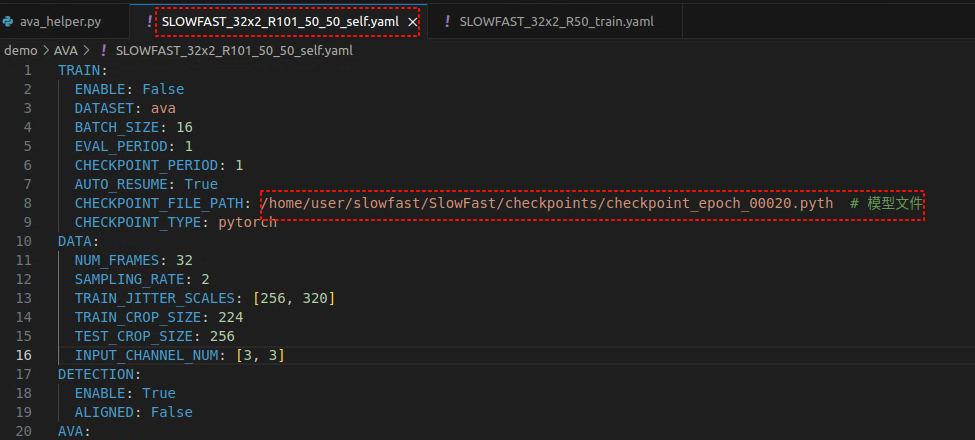
}3.3 配置yaml文件
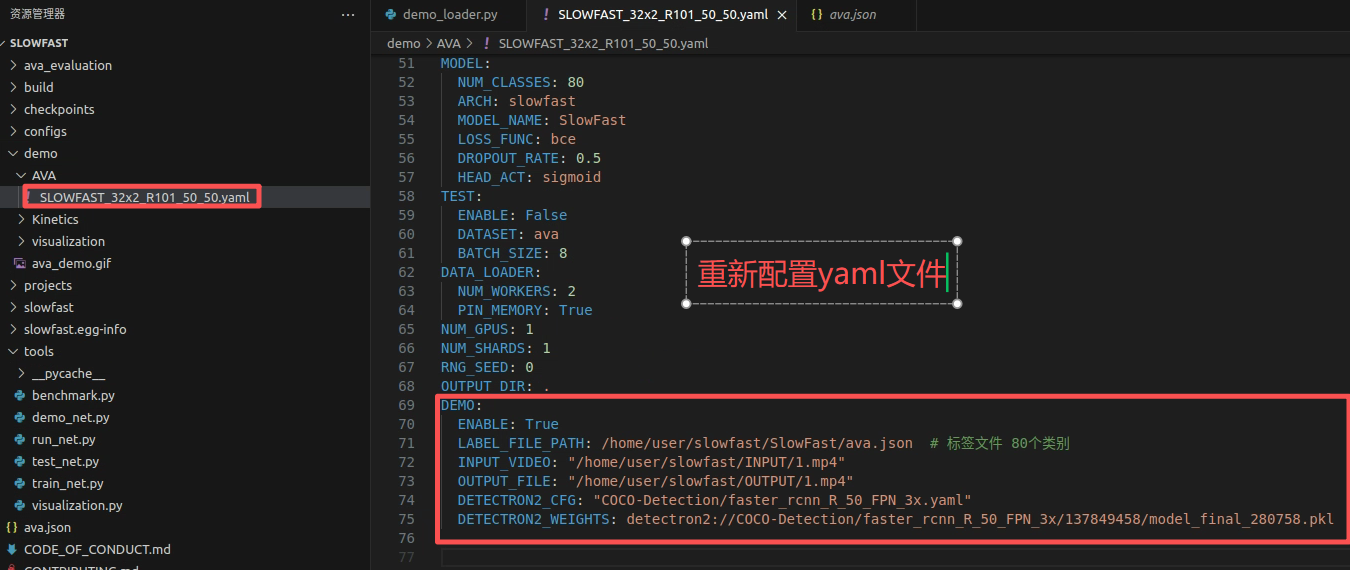
完整的yaml文件如下:
yaml
TRAIN:
ENABLE: False
DATASET: ava
BATCH_SIZE: 16
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: /home/user/slowfast/SlowFast/SLOWFAST_32x2_R101_50_50.pkl # 模型文件
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
DETECTION:
ENABLE: True
ALIGNED: False
AVA:
BGR: False
DETECTION_SCORE_THRESH: 0.8
TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 5
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 101
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[6, 13, 20], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 80
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 8
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
DEMO:
ENABLE: True
LABEL_FILE_PATH: /home/user/slowfast/SlowFast/ava.json # 标签文件 80个类别
INPUT_VIDEO: "/home/user/slowfast/INPUT/1.mp4"
OUTPUT_FILE: "/home/user/slowfast/OUTPUT/1.mp4"
DETECTRON2_CFG: "COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"
DETECTRON2_WEIGHTS: detectron2://COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/model_final_280758.pkl4.4 修改源码两处导包报错
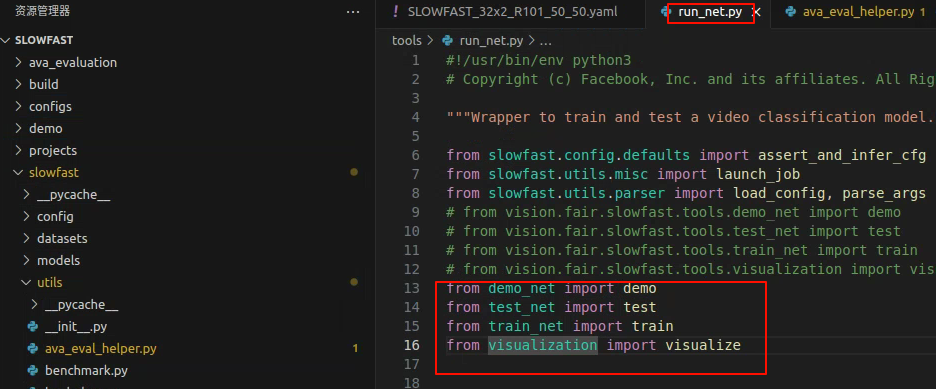
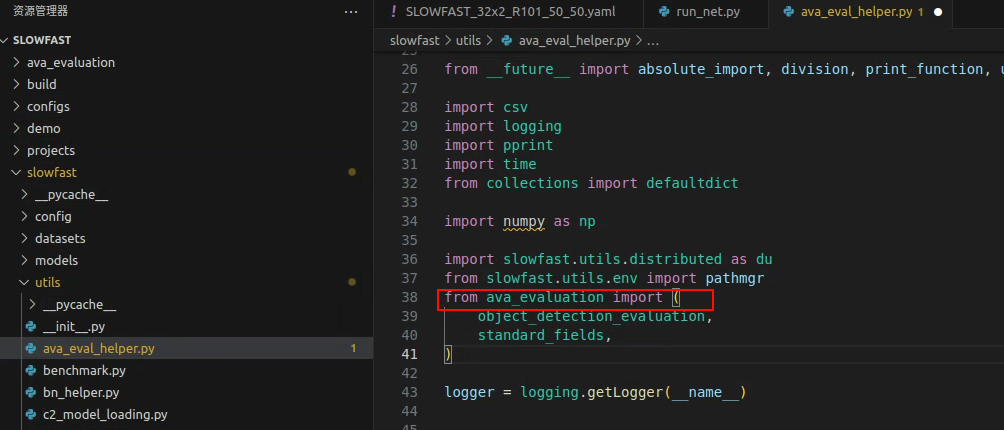
5.5 终端执行,得到预测的MP4文件
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50.yaml

6.6 预测效果

四、下载官方数据集并训练
1.1 训练数据准备
1.1.1 下载视频
1、下载视频名称文件,里面包含各种视频的名称
https://s3.amazonaws.com/ava-dataset/annotations/ava_file_names_trainval_v2.1.txt
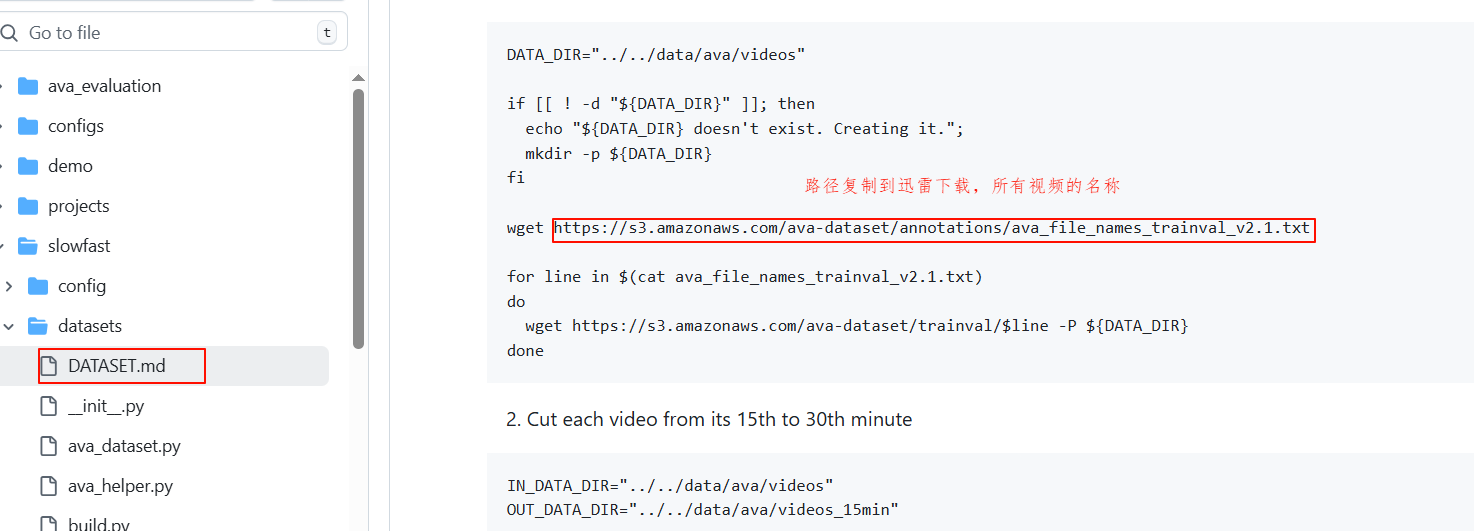
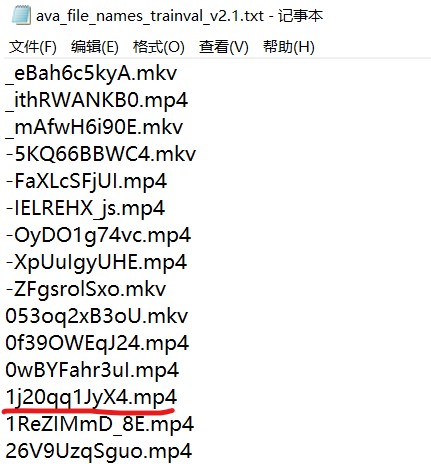
2、根据名称文件下载2个视频,
https://s3.amazonaws.com/ava-dataset/trainval/1j20qq1JyX4.mp4
https://s3.amazonaws.com/ava-dataset/trainval/-5KQ66BBWC4.mkv
3、下载好的视频放在1_videos文件夹
1.1.2 下载的视频切取15-30分钟
运行 sh 1_videoTo15.sh
bash
IN_DATA_DIR="./1_videos"
OUT_DATA_DIR="./2_videos_15min"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
do
out_name="${OUT_DATA_DIR}/${video##*/}"
if [ ! -f "${out_name}" ]; then
ffmpeg -ss 900 -t 901 -i "${video}" "${out_name}"
fi
done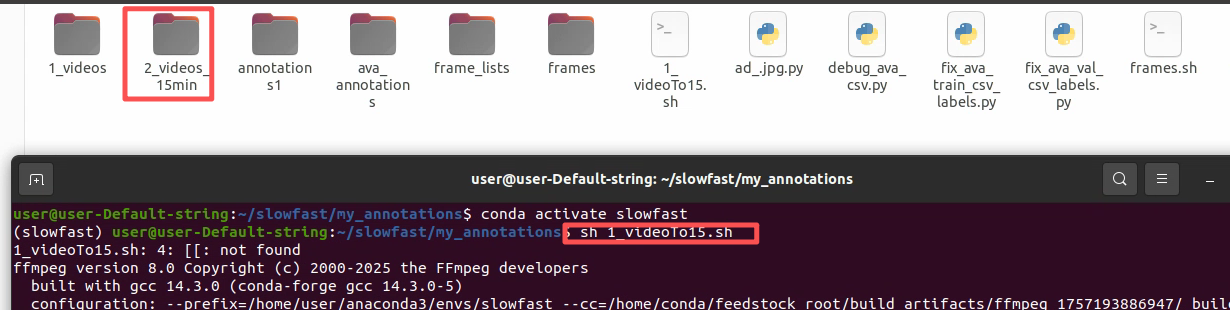
1.1.3 对切取的15分钟视频,提取视频帧
运行 bash 2_frames.sh 每秒截取30帧图片
bash
IN_DATA_DIR="./2_videos_15min"
OUT_DATA_DIR="./frames"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
do
video_name=${video##*/}
if [[ $video_name = *".webm" ]]; then
video_name=${video_name::-5}
else
video_name=${video_name::-4}
fi
out_video_dir=${OUT_DATA_DIR}/${video_name}/
mkdir -p "${out_video_dir}"
out_name="${out_video_dir}/${video_name}_%06d.jpg"
ffmpeg -i "${video}" -r 30 -q:v 1 "${out_name}"
done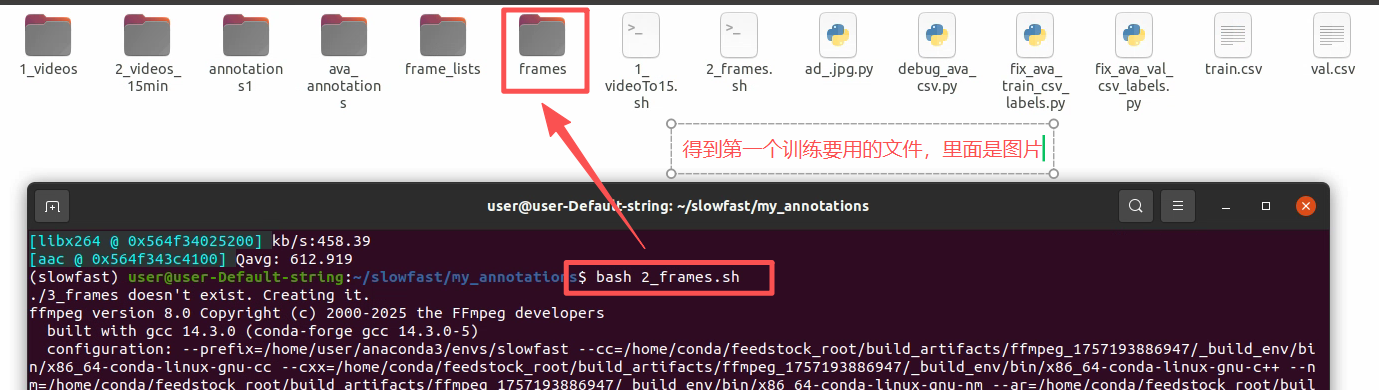
1.1.4 下载标注文件
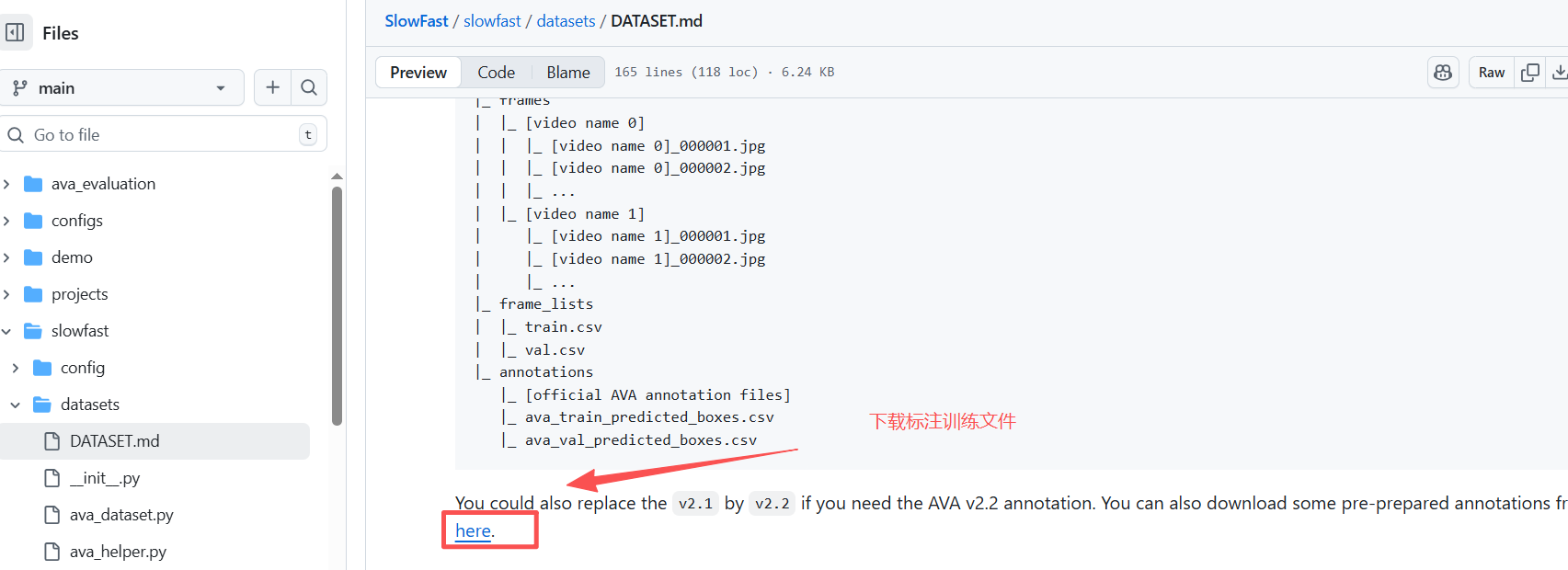
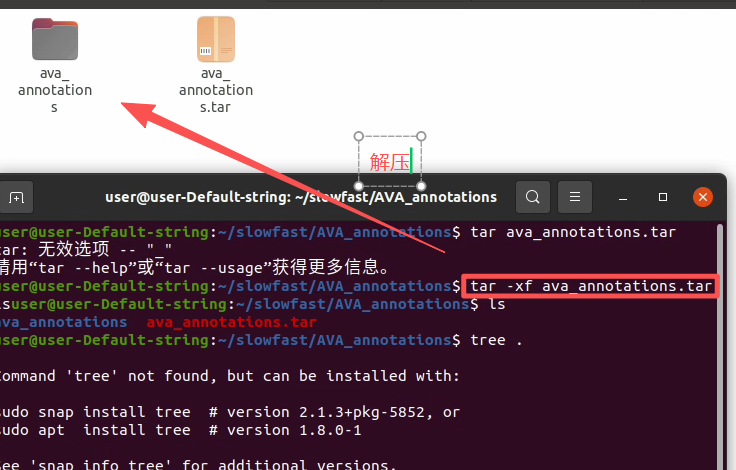
查看文件
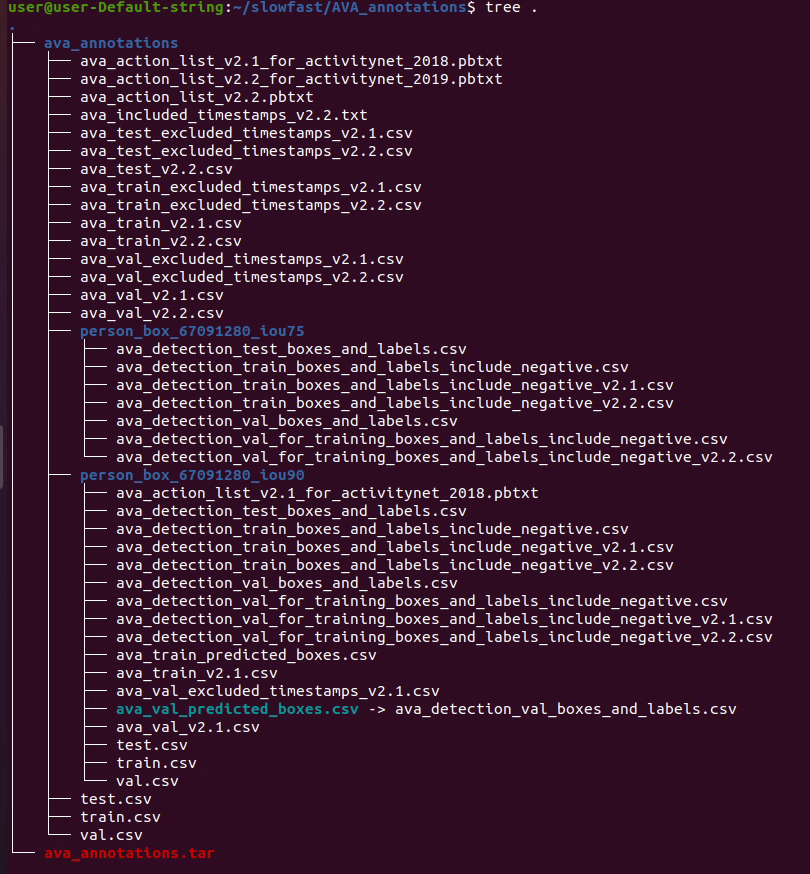
1.1.5 整理我们需要的训练文件
我们的训练视频为-5KQ66BBWC4.mkv(15-30分钟视频帧)
我们的验证视频为1j20qq1JyX4.mp4(15-30分钟视频帧)
1、最终整理需要的三个训练文件如下:

2、其中annotations文件内容如下
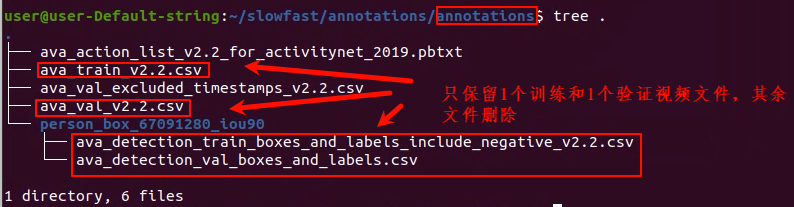
3、其中frame_lists如下
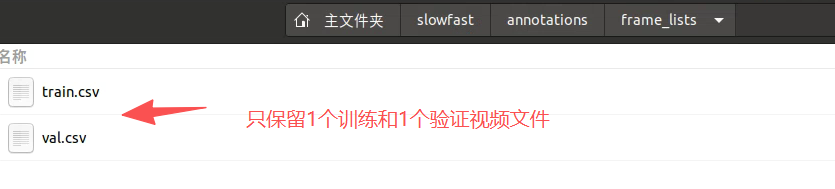
4、frames文件夹,我们上述已经准备好了
2.2 下载预训练权重
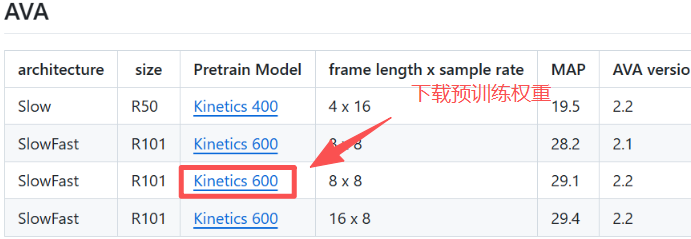
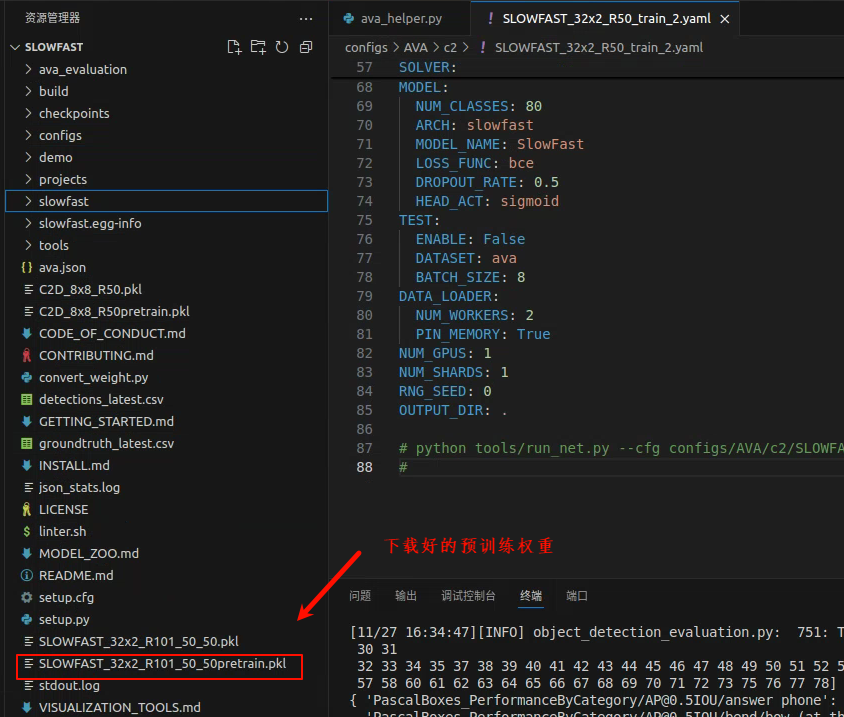
3.3 配置yaml文件
yaml
TRAIN:
ENABLE: True
DATASET: ava
BATCH_SIZE: 2 #64
EVAL_PERIOD: 5
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: '/home/user/slowfast/SlowFast/SLOWFAST_32x2_R101_50_50pretrain.pkl' #path to pretrain model
CHECKPOINT_TYPE: caffe2
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 224
INPUT_CHANNEL_NUM: [3, 3]
PATH_TO_DATA_DIR: '/home/user/slowfast/annotations'
DETECTION:
ENABLE: True
ALIGNED: True
AVA:
FRAME_DIR: '/home/user/slowfast/annotations/frames'
FRAME_LIST_DIR: '/home/user/slowfast/annotations/frame_lists'
ANNOTATION_DIR: '/home/user/slowfast/annotations/annotations'
DETECTION_SCORE_THRESH: 0.8
TRAIN_PREDICT_BOX_LISTS: [
"ava_train_v2.2.csv",
"person_box_67091280_iou90/ava_detection_train_boxes_and_labels_include_negative_v2.2.csv",
]
TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 7
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 50
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
BASE_LR: 0.1
LR_POLICY: steps_with_relative_lrs
STEPS: [0, 10, 15, 20]
LRS: [1, 0.1, 0.01, 0.001]
MAX_EPOCH: 20
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
WARMUP_EPOCHS: 5.0
WARMUP_START_LR: 0.000125
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 80
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 8
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
# python tools/run_net.py --cfg configs/AVA/c2/SLOWFAST_32x2_R50_train.yaml
#4.4 训练
python tools/run_net.py --cfg configs/AVA/c2/SLOWFAST_32x2_R50_train.yaml
5.5 用自己训练的模型预测
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50_self.yaml