在大数据时代,数据仓库的重要性不言而喻。它不仅是企业数据存储与管理的核心,更是数据分析与决策支持的重要基础。而在数据仓库的各个层次中,ODS层(Operational Data Store,操作型数据存储)作为关键一环,起着承上启下的作用。但什么是ODS层?它又如何在企业的数据治理中发挥作用呢?本文将为您详细解答。
一 、 什么是ODS层?
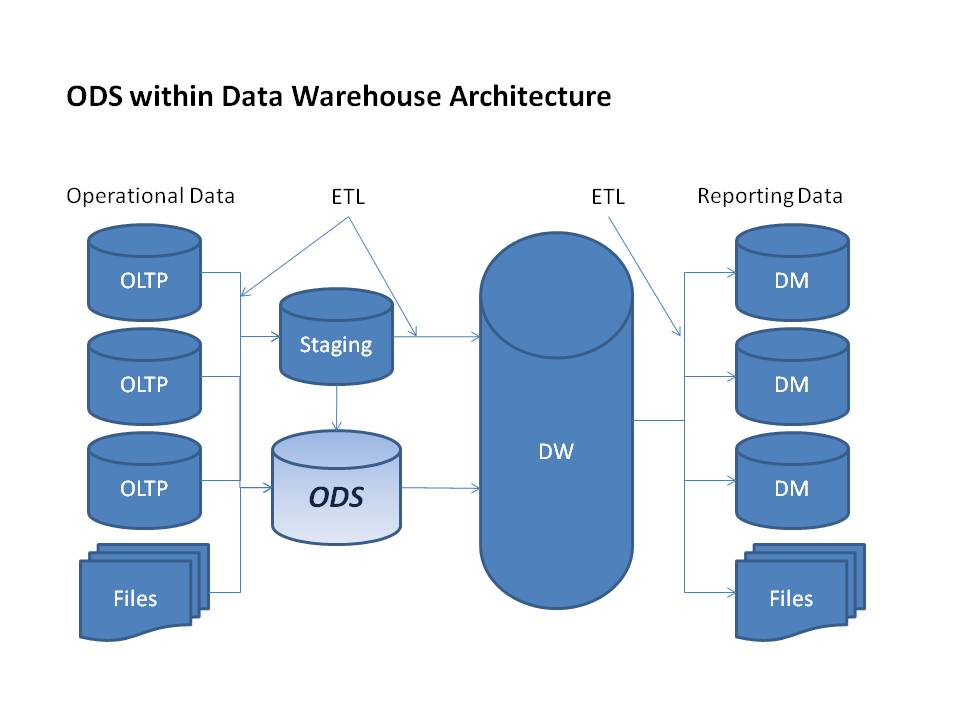
ODS层全称为操作型数据存储层,是一种特殊类型的数据存储,它位于数据仓库体系结构的最底层。ODS层主要用于存储来自不同业务系统的最新数据,并对这些数据进行初步处理。与传统的数据仓库不同,ODS层的数据是实时更新的,并且更贴近业务操作系统的数据格式。

二 、 为什么需要ODS层?
在企业信息化建设中,往往存在多个业务系统,这些系统的数据结构和数据格式各不相同,直接将这些数据加载到数据仓库中会产生许多问题。例如,数据一致性差、数据冗余度高、处理性能低下等。而ODS层的引入,正是为了解决这些问题。
1. 数据集成与清洗
ODS层可以对来自不同业务系统的数据进行集成与清洗,统一数据格式,去除冗余信息,确保数据的一致性和完整性。
2. 实时性支持
与传统数据仓库相比,ODS层的数据更新更为频繁,通常是实时或近实时的,这使得它能够更好地支持企业的日常运营和决策。
3. 缓冲作用
ODS层作为数据仓库的前置层,起到数据缓冲的作用,减少对上层数据仓库的直接冲击,确保数据仓库的稳定性和性能。
4. 业务需求驱动
ODS层的数据结构与业务系统相对接近,能够更好地满足业务部门对数据实时性、灵活性的需求,提升数据应用的效率。
三 、 ODS层的构建方法
构建ODS层并非一蹴而就,它需要结合企业的实际情况,遵循一定的原则与方法。
**数据采集:**ODS层的数据主要来自于各个业务系统。通过ETL(抽取、转换、加载)工具,ODS层可以从不同系统中抽取数据。这一过程中,需要确保数据的准确性和实时性,并根据业务需求进行必要的转换和清洗。
**数据存储:**在ODS层中,数据通常以关系型数据库的形式存储。这是因为关系型数据库具有强大的事务处理能力和良好的数据一致性支持,能够满足ODS层对数据更新频繁、查询性能要求高的需求。
**数据更新与同步:**ODS层的数据需要实时或准实时地更新,以保证其数据的时效性。因此,必须设计合理的更新策略,如增量更新、全量更新等,确保数据能够及时反映业务系统的最新变化。
**数据访问:**ODS层的数据主要面向企业的业务部门和中层管理人员,他们需要实时的数据支持来做出快速决策。为了提高数据访问的效率,ODS层通常会设计灵活的数据查询接口,并提供必要的数据分析工具。
四 、 ODS层的应用场景
ODS层在企业数据治理中的应用十分广泛,尤其适用于以下几种场景:
**实时业务分析:**企业在日常运营中,往往需要对最新的业务数据进行实时分析,如销售数据、库存数据等。ODS层的数据实时性强,能够满足这种实时分析的需求。
**数据集成与中转:**在一些大型企业中,业务系统繁多,直接将这些系统的数据加载到数据仓库中难度较大。ODS层可以作为数据集成的中转站,将不同系统的数据统一处理后,再加载到数据仓库中。
**报表系统支持:**很多企业的报表系统需要从多个业务系统中提取数据。ODS层可以为报表系统提供集成、清洗后的数据源,提升报表生成的速度和准确性。
总结来说,ODS层在数据仓库架构中起着至关重要的作用。它不仅能够提高数据处理的效率和一致性,还能为企业的实时决策提供坚实的数据基础。因此,在构建企业级数据仓库时,ODS层的设计与实现不可忽视。
综上所述,数仓建设是企业数据管理和决策支持的关键环节,在实践中,企业需要根据自身业务需求和数据规模,选择合适的数仓建设方案和技术方案,以提高企业数据资产的价值和利用效率。
FineDataLink------小到数据库对接、API对接、行列转换、参数设置,大到任务调度、运维监控、实时数据同步、数据服务API分享,另外它可以满足数据实时同步的场景,应有尽有,功能很强大。如果您需要进行数仓建设,帆软FDL会是您的最优解。
免费试用、获取更多信息,点击了解更多>>>************体验FDL功能****************
了解更多数据仓库与数据集成关干货内容请关注>>>************FineDataLink官网****************
往期推荐: