当前的问题:Base-New Tradeoff(BNT)困境
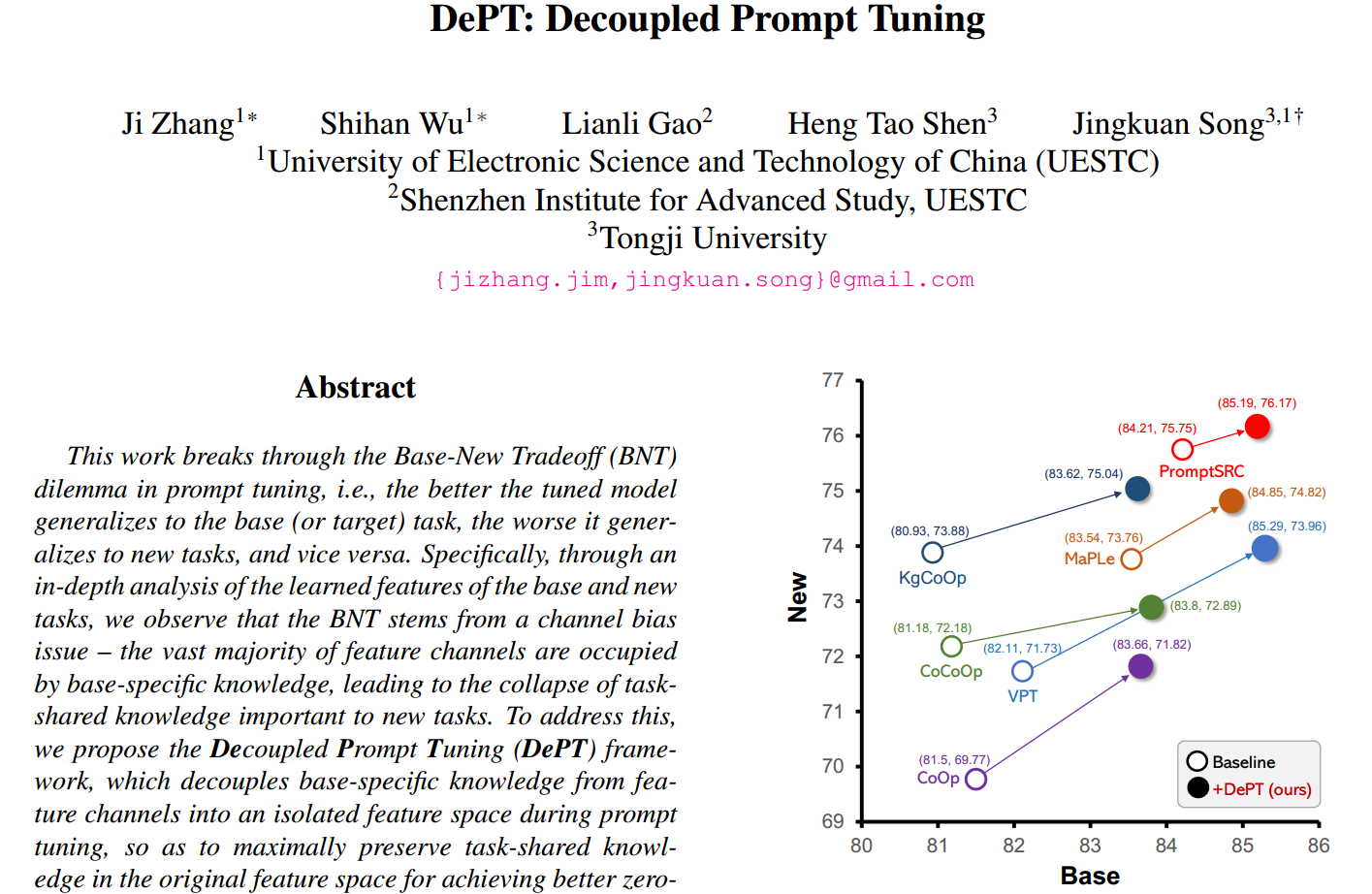
现有的提示调优方法通常无法摆脱Base-New Tradeoff(BNT)困境,即调优/调整的模型对基本任务的泛化效果越好,对新任务的泛化效果就越差(包含不可见的类),反之新任务的泛化效果越好,所需要的代价便是基本任务的泛化效果越差。
作者最终达到的结果便是:Base和New的准确率上同时得到提升
什么原因导致了Base-New Tradeoff(BNT)
Base和New联合训练Oracle
为了训练一个近乎BNT问题的模型,作者使用base task τ b a s e \tau_{base} τbase和new task τ n e w \tau_{new} τnew来联合派生模型Oracle。按我理解,应该是Oracle这个模型利用上了base和new上的数据,所以自然而然地不存在上述的Base-New Tradeoff(BNT)问题。
通道重要性(CI)的计算
第 r ( r = 1 , ... , d ) r(r=1,\ldots,d) r(r=1,...,d)个通道重要性计算如下:
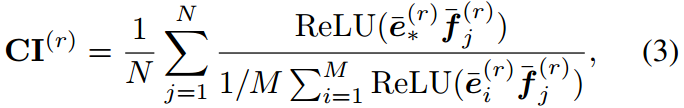
其中 f j , e ∗ f_j,e_* fj,e∗分别为 x j x_j xj学习到的 d d d维图像和文本特征。 N N N为任务中的示例数。ReLU1用于避免分母等于0。
将Oracle与CoOp进行比较
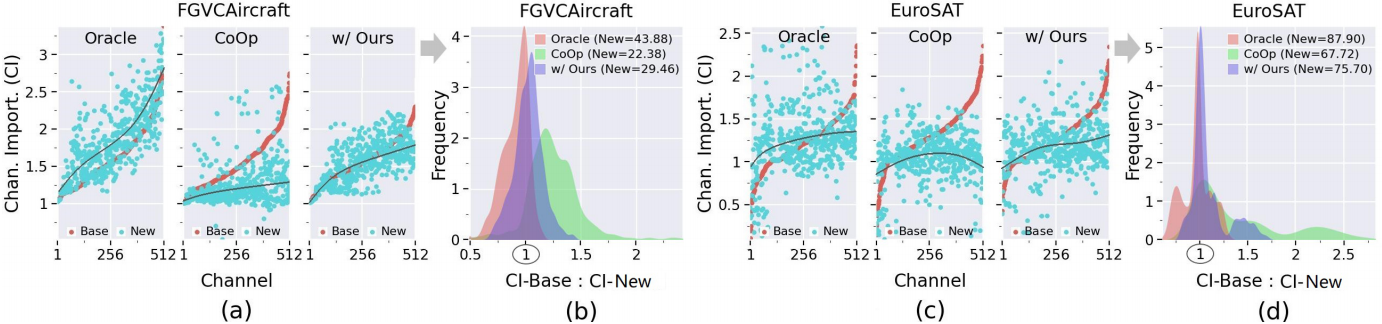
在(a)©中, x x x轴是对分别base task τ b a s e \tau_{base} τbase和new task τ n e w \tau_{new} τnew根据通道重要性(CI)进行排序后的索引( x x x越小,CI得分越低, x x x越大,CI得分越高), y y y轴即为通道重要性(CI)大小。从图中可以看出,oracle模型得到的base task和new task的CI分布比CoOp模型得到的CI分布具有更大的一致性 。
在(a)©中,oracle的准确率确实比CoOp高。
提出的idea
oracle模型在很大程度上优于CoOp,这表明oracle模型产生的大多数特征通道包含任务共享知识,这对新任务的泛化很有价值 。简而言之,在提示调优之后,绝大多数学习到的特征通道被特定于基础的知识所占据,导致对新任务很重要的任务共享知识的崩溃(或灾难性遗忘)------我们在本工作中将其称为通道偏差问题。
我们能否在特征通道中同时保留特定于base-task共享的知识 ,以克服提示调优中的BNT问题?

个人理解:既然BNT问题与CI分布紧密相关,那么我们接下来的改进可以围绕着特征通道这一角度着手。
解决办法
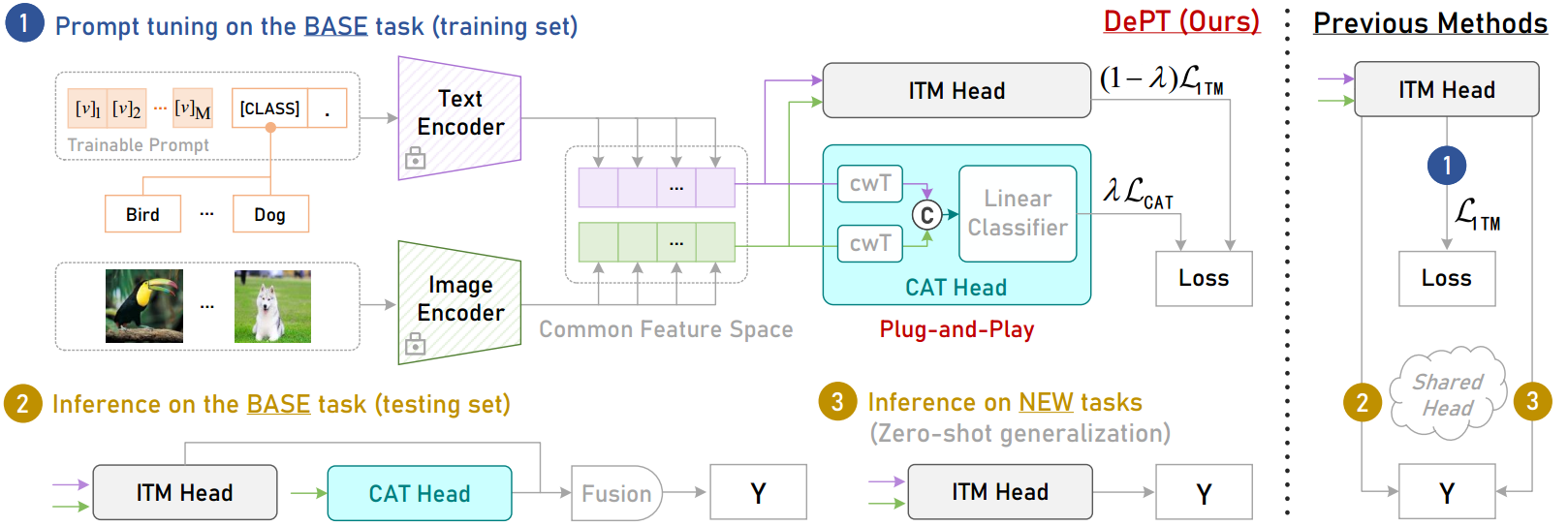
解决办法非常简单,仅仅只是加了一个即插即用(Plug-and-Play)的CAT Head。
CAT Head
对于Image Encoder和Text Encoder的输出 S i m g = { f j } j = 1 J , S t e x t = { e j } j = 1 J S_{img}=\{\bm f_j\}^J_{j=1},S_{text}=\{e_j\}_{j=1}^J Simg={fj}j=1J,Stext={ej}j=1J,CAT Head利用通道转换层(cwT)将Simg和Stext转换为新的特征空间,即
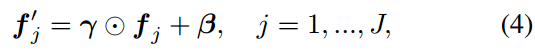
类似地,得到 S i m g ′ = { f j ′ } j = 1 J , S t e x t ′ = { e j ′ } j = 1 J S'{img}=\{\bm f'j\}^J{j=1},S'{text}=\{e'j\}{j=1}^J Simg′={fj′}j=1J,Stext′={ej′}j=1J
再将 S i m g ′ , S t e x t ′ S'{img},S'{text} Simg′,Stext′拼接在一起,即 S ∪ = S i m g ′ ∪ S t e x t ′ = { s j } j = 1 2 J , Y ∪ = { y j } j = 1 2 J S_{\cup}=S'{img}\cup S'{text}=\{s_j\}^{2J}{j=1}, \mathcal{Y} {\cup}=\{\bm y_j\}^{2J}_{j=1} S∪=Simg′∪Stext′={sj}j=12J,Y∪={yj}j=12J
其中 y j ∈ R M \bm y_j\in \mathbb{R}^M yj∈RM是 s j s_j sj的on-hot标签。
对于每一对 ( s , y ) (s, \bm y) (s,y), CAT头最小化以下交叉熵损失:
L CAT = − ∑ i y i log P CAT ( c i ∣ x ) \mathcal{L}{\text{CAT}}= -\sum{i}{\bm y_i \text{log}\mathcal{P}_{\text{CAT}}(\bm c_i|\bm x)} LCAT=−∑iyilogPCAT(ci∣x)
其中
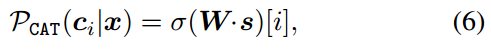
总损失与推理
总损失如下:
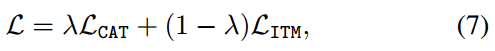
Base与New上的推理

对于基本任务,我们的CAT头直接将测试样例的图像特征作为输入,使用线性分类器预测分布内类标签。
在推理时,使用标准ITM头来实现对原始特征空间中新任务的zero-shot泛化/预测。
参考资料
论文下载(2024 CVPR)
https://arxiv.org/abs/2309.07439