目录
一,grep
1,grep介绍
grep是Linux上的一个文本搜索工具,是用来查找文本文件内的一些符合grep定义模式的文本文件的。格式:grep OPTIONS... PATTERN FILE...
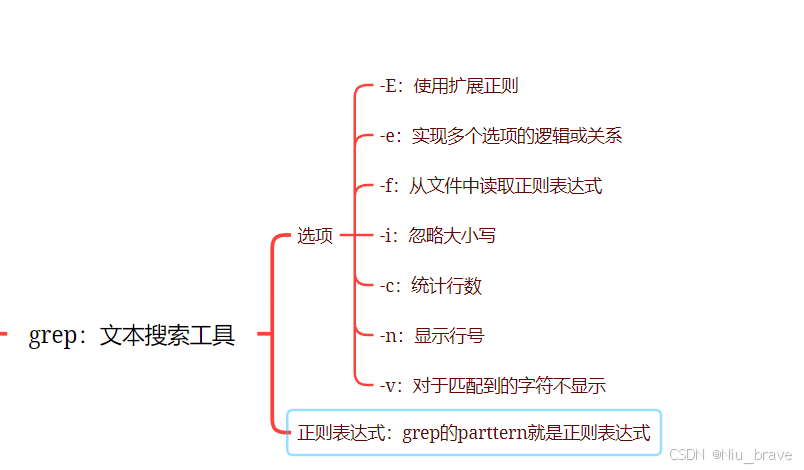
2,grep的常用选项
3,grep使用演示
1,基本使用
直接查找字符串:
grep "字符串" 文件

使用选项
只显示第一行
grep "字符串" -m 1 文件

查找并显示行号
grep "字符串" -n 文件

只显示查找到的字符串
grep -o "字符" 文件

剔除查找的内容后显示别的内容
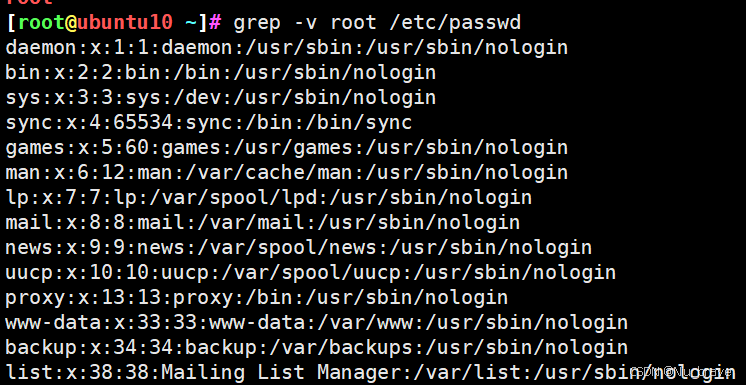
grep -v "字符" 文件
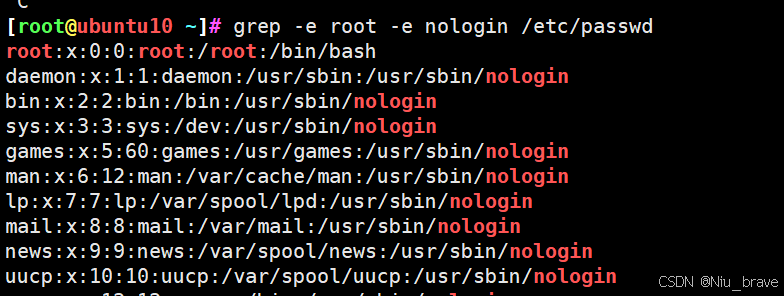
使用多个条件查找字符:满足两个条件之一便可以查找
grep -e "字符" -e "字符"
显示匹配到字符条件的行的行号
grep -c 字符 文件

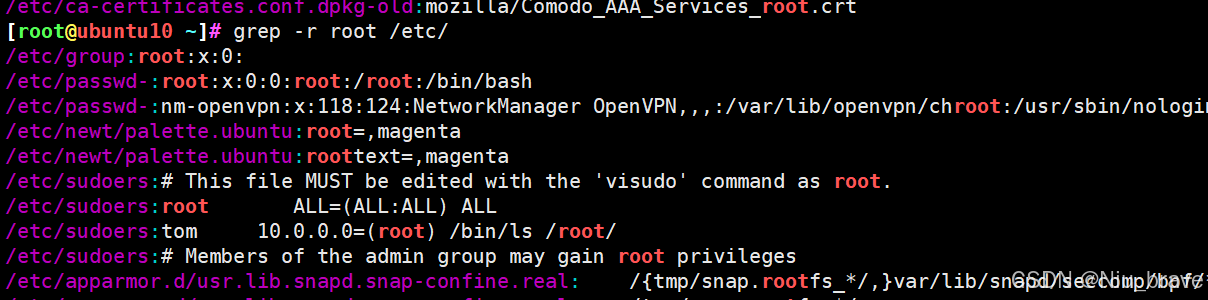
递归条件搜索
1,不管软连接文件
grep -r 字符 文件
2,管软连接
grep -R 字符 文件
不区分大小写
grep -i 字符串 文件

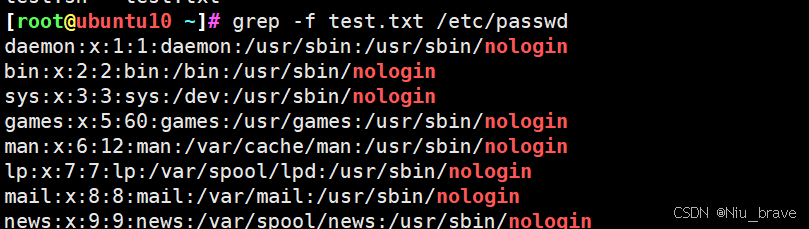
从文件中读取pattern再匹配
先创建文件:

使用-f选项读取文件的pattern内容进行匹配:
2,使用正则表达式进行匹配
1,正则表达式介绍
正则表达式的使用方式可以再网上查询,也可以使用man 7 regex再Linux上查看。
2,使用范例
分区利用率最大的值
bash
df | grep "^/dev/sd"|tr -s " " |cut -d% -f1|cut -d " " -f5|head -1指令解释:
df:显示显示文件系统资源的信息。
grep "^/dev/sd":将df里面以/dev/sd开头的内容截取出来。
tr -s " ":将重复的空格去掉仅保留一个空格。
cut -d% -f1:以%为分隔符分为左右两边,取-f1表示左边。
cut -d " " -f5:以" "为分隔符取第五个。
head -1:只要最上面的第一行。
哪个IP和当前主机连接数最多
bash
ss -nt |grep "^ESTAB"|tr -s " "|cut -d " " -f5|cut -d : -f1指令解释:
ss -nt:
ss是一个用于检查套接字的工具,它可以显示类似于netstat的信息,但比netstat更快。-n选项表示以数字形式显示地址和端口号,不尝试解析服务名称。-t选项指定只显示TCP连接。
|(管道):这个符号用于将前一个命令的输出作为后一个命令的输入。
grep "^ESTAB":
grep是一个强大的文本搜索工具。"^ESTAB"是一个正则表达式,匹配以"ESTAB"开头的行。这里实际上是匹配"ESTABLISHED"状态的连接,但假设是为了简化而只写了"ESTAB"的一部分。然而,注意这样可能不准确匹配到所有ESTABLISHED状态的行,因为完整的状态通常是"ESTABLISHED"。正确的正则表达式应该是"^ESTABLISHED"。
tr -s " ":
tr是一个用于转换或删除字符的工具。-s选项表示压缩序列中的重复字符,但在这个命令中,它实际上对空格进行压缩,因为指定了" "(一个空格)作为要压缩的字符。然而,由于grep的输出通常不包含连续的空格,这个选项可能在这个具体命令中并不必要。
cut -d " " -f5:
cut是一个用于按列提取文本的工具。-d " "指定空格作为字段分隔符。-f5表示提取第五个字段。在ss -nt的输出中,第五个字段通常是本地地址和端口(例如,192.168.1.1:80)。
cut -d : -f1:
- 这个
cut命令再次使用,但这次是以:作为字段分隔符。
-f1表示提取第一个字段,即IP地址部分
连接状态的统计
bash
ss -nat|grep -v "^State"|cut -d " " -f1|sort -u指令解释:
ss -nat:将所有的tcp连接以数字的方式显示出来。
grep -v "^State":不显示以State开头的行。
cut -d " " -f1:以空格为分隔符并取第一列。
sort -u:排序并去掉重复的状态。
过滤掉文件的注释(包括#号的行)和空行
bash
grep -v "^#|$" /etc/passwd二,sed
1,sed介绍
sed也是一个文本处理工具,特点是可以一行一行的读取文件内容并处理。相比于vim等文本编辑器更加高效。
格式:sed OPTION... {script-only-if-no-other-script} input-file...
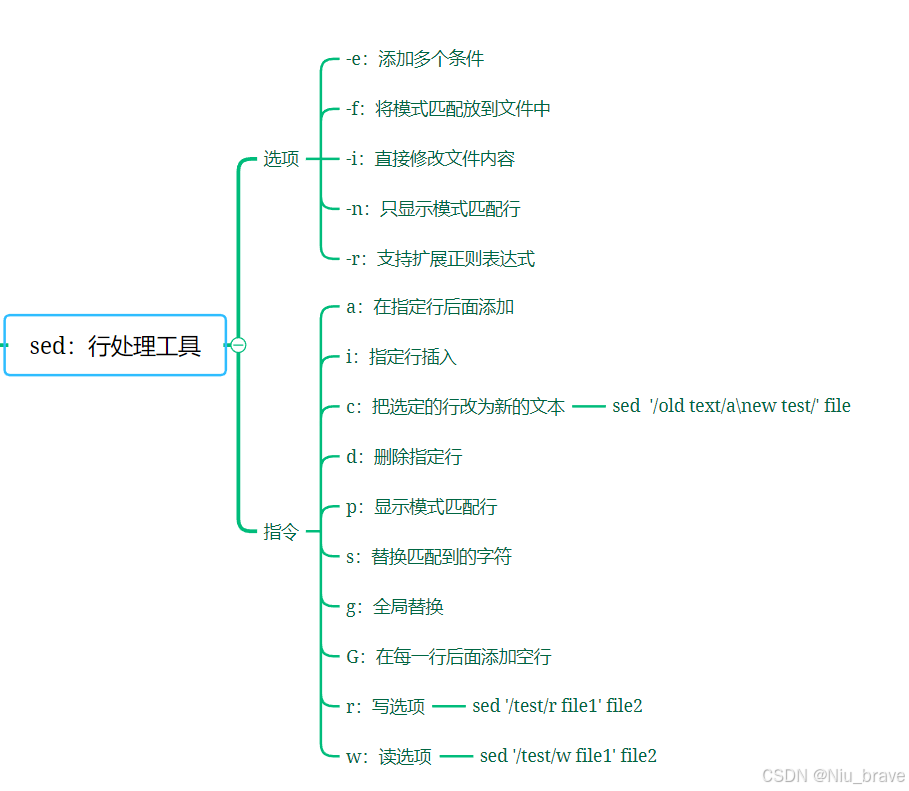
2,sed常用选项和指令
3,sed使用实例
1,简单实例
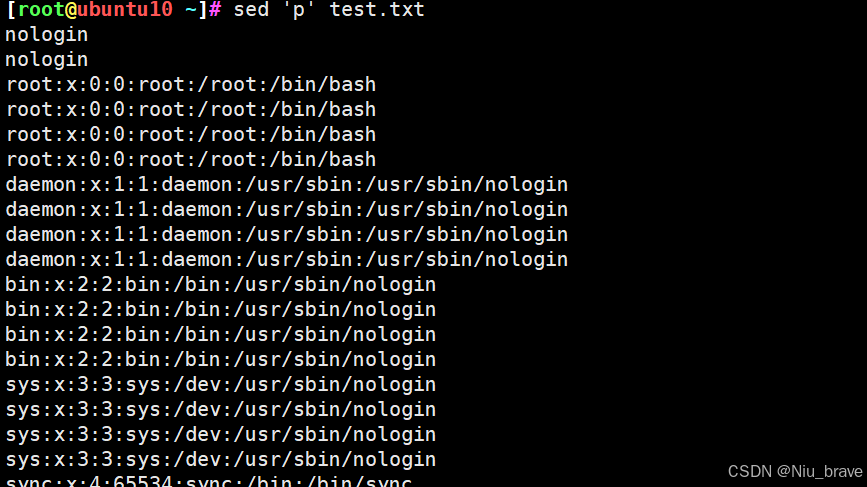
打印文件内容
sed 'p' 文件
仅显示与查找匹配的内容
sed -n '/字符串/p' 文件

只打印第一行的内容
sed -n '1p' 文件
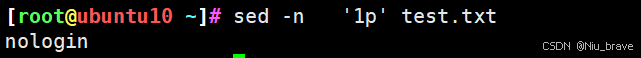
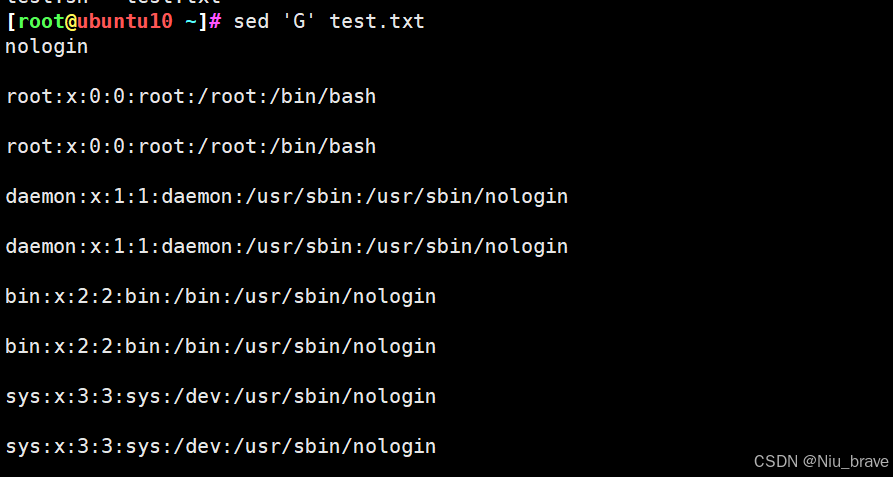
sed给每一行后面加上空格
sed 'G' 文件
2,综合实例
删除每行的第二个字符
bash
sed -r 's/(.)(.)(.*)/\1\3/' test.txt代码解释:
-r:使用扩展模式
s:启用搜索功能
(.)(.)(.*):匹配的字符模式,每一个括号代表一个匹配组。
\1\3:代表显示第一个和第三个捕获组的内容。
删除第二个单词
bash
sed -r 's/^([a-zA-Z]+[^a-zA-Z]+)[a-zA-Z]/\1/' test.txt 解释
sed -r:使用sed的扩展正则表达式模式。's/^([a-Z]+[^a-Z]+)[a-Z]+/\1/g':这是一个替换命令,其结构为s/pattern/replacement/flags。
^:匹配行的开始。([a-Z]+[^a-Z]+):这是一个捕获组,但其中的正则表达式可能不是您想要的。
[a-Z]+:匹配一个或多个字母(注意:[a-Z]实际上可能不是所有sed实现都支持的,因为标准 ASCII 字符集中没有Z到a的范围,但这里可能是想表达[a-zA-Z]的意思,即匹配任何大小写字母)。[^a-Z]+:紧接着尝试匹配一个或多个非字母字符,但由于前面的[a-Z]+已经消耗了尽可能多的字母,这个部分可能永远不会被匹配到(除非输入字符串以非字母字符开头,但这与^冲突)。[a-Z]+:这部分尝试匹配行中紧接着前面部分的又一个或多个字母,但由于前面的正则表达式可能存在的问题,这部分的匹配也可能不是你预期的。\1:在替换文本中,\1引用第一个捕获组的内容。
三,Find
1,find介绍
find是一个文件搜索工具,可以实时的查找文件。
2,常用选项
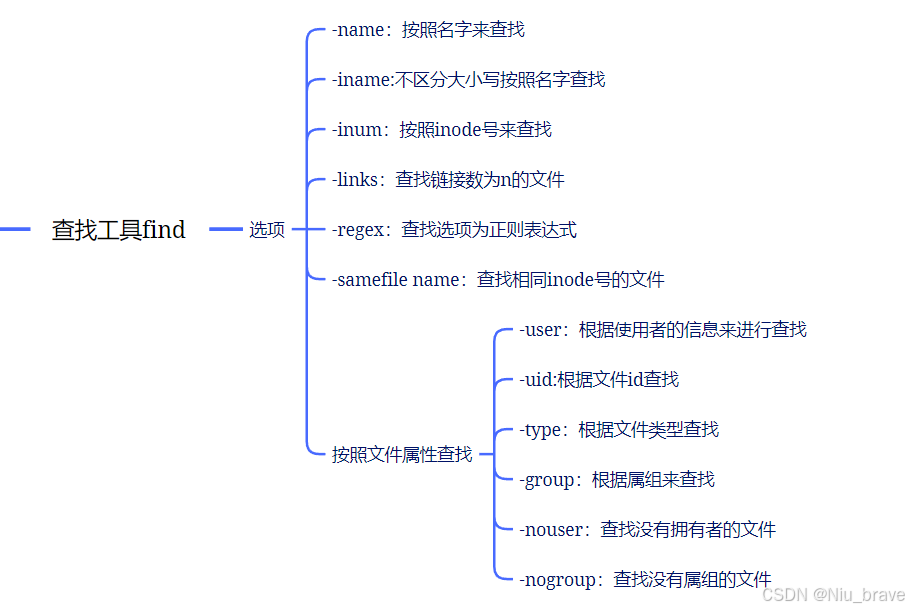
在使用find时可以指定文件路径进行查找。
指定在根目录下查找 :
bash
sudo find / -name passwd