我们的目标是:按照这一套资料学习下来,大家可以独立完成自动化测试的任务。
之前有一篇我们讨论了使用模块化测试来优化我们的测试脚本,今天我们试着进一步深入学习数据驱动。
本篇文章我们讨论一下数据驱动思想,如何将数据和脚本分离出来,更便于维护数据。
现在我们首先讨论一下如何读取文件。
1、准备知识
1)引入数据驱动
我们先看一下之前的测试脚本,登录的这部分:
#输入正确的密码登录成功测试
def test_login_Y(self):username ="standard_user"
password ="secret_sauce"
print("登录的用户名是:%s,密码是:%s"%(username,password))
driver=login.Login(username,password).login()
time.sleep(3)
#加入断言 //*[@id="header_container"]/div[1]/div[2]/div
# 验证有显示:Products
UIResult =driver.find_element_by_xpath('//*[@id="header_container"]/div[2]/span').text
self.assertEqual("Products", UIResult, "密码正确登录验证失败,fail")
self.driver=driver
# 输入错误的密码登录失败测试
def test_login_N(self):username ="standard_user"
password ="secret_NG"
print("登录的用户名是:%s,密码是:%s" % (username, password))
driver =login.Login(username,password).login()
time.sleep(3)
# 加入断言 //*[@id="header_container"]/div[1]/div[2]/div
# 验证有报错显示:
UIResult =driver.find_element_by_xpath('//*[@id="login_button_container"]/div/form/div[3]/h3').text
self.assertEqual("Epic sadface: Username and password do not match any user in this service", UIResult,
"密码错误登录验证失败,fail")
self.driver=driver如上所示,我们都用到登录的操作,但是黄色背景部分用户名和密码可能不一致。这里的数据就维护起来就比较麻烦,若是更多时就有很明显的弊端。
2)数据驱动的一般步骤
编写脚本>准备测试数据到文件或者数据库等外部介质>获取数据>代入数据执行测试,
由以上步骤不难看出,我们首先要学会如何读取文件。如读取Excel文件的内容。
2、读取Excel文件
1)引入xlrd 库
python 读取Excel文件,需要先安装xlrd 库,可以直接在命令行输入:pip install xlrd
上面的提示说明我们之前已经安装了。
2)编写读取Excel 文件函数
需求:如下图Excel表。通过Excel来获取数据,希望返回字典组成的列表:[{"username":" standard_user","password":"secret_sauce"},
{"username":" visual_user","password":"secret_sauce"},{"username":" error_user","password":"password_NG"}]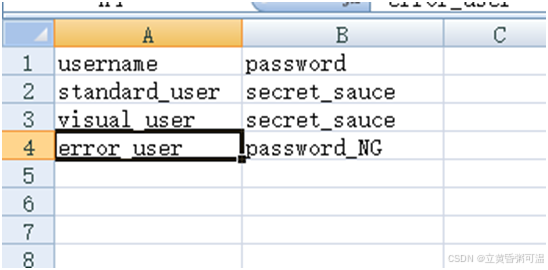
编写函数实现如下:
def get_excel_data(filename,sheetnum):path ='login_data.xlsx'
book_data =xlrd.open_workbook(path) #打开文档
book_sheet=book_data.sheet_by_index(0) #打开Excel中第一个表
rows_num =book_sheet.nrows #sheet1 行数,row:行
rows0 =book_sheet.row_values(0) #第一行的各个名称作为字典的键,列表
rows0_num =len(rows0) #第一行列表的长度即为数据的列数
data_list =[ ] #存放读取的数据
for i inrange(1,rows_num):rows_data =book_sheet.row_values(i) #取出每一行的值作为列表,列表的每一项为一个字典
rows_dir ={ }
fory inrange(0,rows0_num):#将每一列的值与每一行对应起来
rows_dir[rows0[y]] =rows_data[y] #键值对应
data_list.append(rows_dir) #每个字典插入到列表中
return data_list输出结果如下,方便后面使用。这里的难点主要是对字典和列表的理解和操作。不熟悉的可以先练习一下这部分再学习编写脚本。
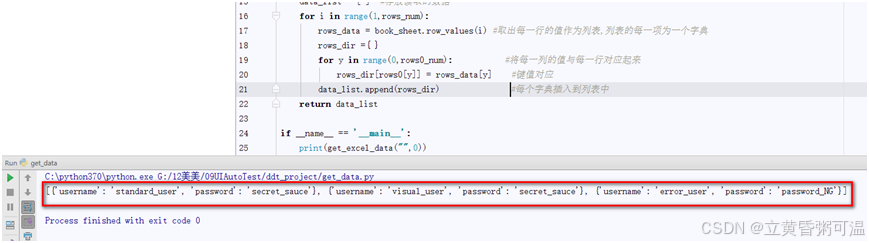
今天就先学习到这里吧。
每天进步一点点,加油!