在上篇文章中,我们介绍了状态、动作、策略和奖励这几个基本概念。
本文将继续讨论强化学习中另外四个重要概念:轨迹 、回报 、折扣因子 和回合。
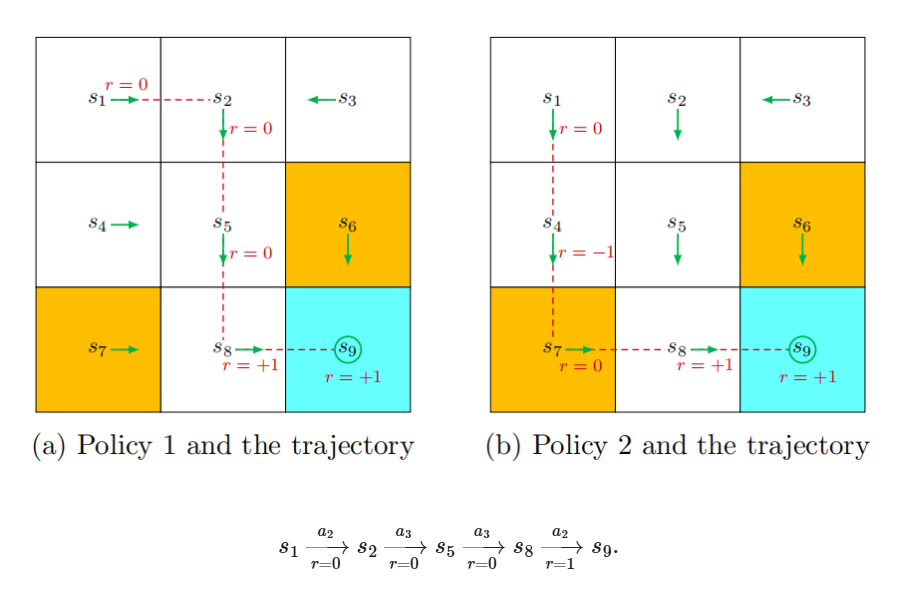
轨迹(Trajectory)
轨迹描述了智能体与环境交互过程中经历的状态、动作和奖励序列,通常表示为:
s0,a0,r1,s1,a1,r2,s2,…这是一个按时间顺序排列的"状态-动作-奖励"链。
回报(Return)
回报是指从某一时刻开始,轨迹上未来所有奖励的累积值,也称为累计奖励。
例如,某轨迹获得的奖励依次为 0, 0, 0, 1,则其回报为 0+0+0+1=1。
回报常被用来评估策略的好坏。需要注意的是,策略本身通常是一个概率分布,而非确定性的动作选择。
折扣因子(Discount Factor)
在计算回报时,如果直接对远期奖励进行简单累加,可能导致回报无限增长,不利于学习稳定。为此,我们引入折扣因子 γ∈(0,1),并定义折扣回报为:
Gt=rt+1+γrt+2+γ2rt+3+…例如,对应某轨迹的折扣回报可写作 0+0⋅γ+0⋅γ2+1⋅γ3+...。
折扣因子 γ的作用是调节智能体对近期奖励与远期奖励的重视程度:
-
若 γ接近 0,智能体更关注近期奖励,策略会趋于"短视";
-
若 γ接近 1,智能体更重视远期奖励,策略会更为"远视",甚至可能为长期收益接受短期的负奖励。
回合(Episode)
当智能体根据某个策略与环境交互,并在达到某个终止状态 时结束,这个过程称为一个回合 (或一次试验)。
如果环境或策略具有随机性,即使从同一初始状态出发,也可能得到不同的回合轨迹;反之,在完全确定性的环境中,每次从同一状态出发都将得到完全相同的回合。