目录
[思考:为什么计算机不能直接设计为 输入设备-CPU运算-输出设备 的结构?](#思考:为什么计算机不能直接设计为 输入设备-CPU运算-输出设备 的结构?)
[2、操作系统(Operator System)](#2、操作系统(Operator System))
[进程 ID (PID):](#进程 ID (PID):)
[父进程 ID (PPID):](#父进程 ID (PPID):)
[fork() 系统调用:](#fork() 系统调用:)
[示例1:使用 fork() 创建新进程,并通过返回值区分父子进程](#示例1:使用 fork() 创建新进程,并通过返回值区分父子进程)
[示例2:使用 fork() 创建新进程,并打印相关信息](#示例2:使用 fork() 创建新进程,并打印相关信息)
[PRI 和 NI](#PRI 和 NI)
示例3:通过getenv()和putenv()接口操作单个环境变量
Linux进程
在现代计算机系统中,Linux操作系统以其开源、灵活和强大的特性,成为服务器和嵌入式系统的首选。了解Linux的进程管理机制对于系统管理员和开发者来说至关重要。
1、从计算机组成原理到冯诺依曼架构
计算机系统的组成
计算机组成原理告诉我们,所有的计算机系统都由以下结构组成:
- 输入设备:如键盘和鼠标,用于向计算机输入信息。
- 中央处理器(CPU):计算机的大脑,负责处理数据和执行命令。
CPU分为:运算器和控制器
运算器------算数运算、逻辑运算
控制器------响应外部事件、如拷贝磁盘数据到内存当中
3.存储器:内存(RAM)用于临时存储程序和数据。
4.输出设备:如显示器和打印机,用于展示信息和打印文档。

冯诺依曼体系
冯·诺依曼架构的最关键特点是程序指令和数据都存储在内存中 ,并且CPU可以直接访问内存来读取指令和数据。所有的输入和输出操作都是通过内存来进行的,即数据首先被写入内存,然后CPU从内存中读取数据进行处理,处理结果再写回内存,最后通过输出设备显示或打印出来。通俗的说,CPU大脑只和内存打交道,不和其它设备直接沟通。内存在冯诺依曼架构中充当中间件的作用。
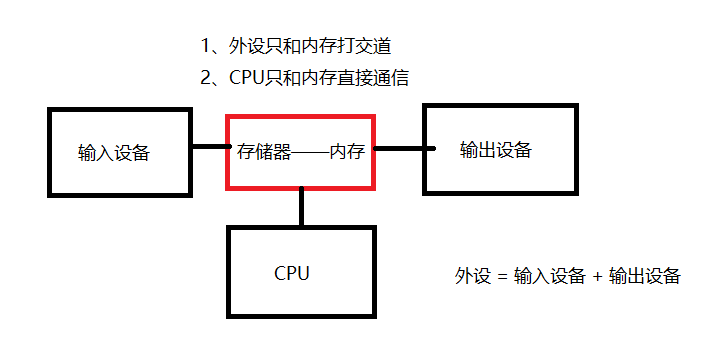
笔记:我们常说的IO流是指内存和外设之间的通信!
思考:为什么计算机不能直接设计为 输入设备-CPU运算-输出设备 的结构?
其中一个原因是,计算机需要存储程序和数据。如果没有存储器,CPU将无法记住程序指令和处理的数据。但更本质的原因是CPU的运算速度远远超过大多数输入和输出设备,如果没有内存作为数据缓冲区,CPU在等待慢速的输入设备(如键盘或鼠标)提供数据或等待输出设备(如打印机或显示器)处理数据时,将会浪费大量计算资源。 (CPU的执行过程也是流水线 木桶原理告诉我们 计算总时间取决于木桶的短板~)
2、操作系统(Operator System)
操作系统(Operating System,简称OS)是计算机系统中最基本的系统软件,它负责管理和控制计算机硬件和软件资源。操作系统在整个计算机软硬件架构中,定位为"管理"的软件,它处于应用软件和硬件之间的中间层,使用面向对象的思想,先描述资源,再管理资源,使得用户能够方便地使用计算机。
概念
操作系统是一组程序,它提供了计算机硬件和用户应用程序之间的接口。操作系统的主要功能包括:
- 内核:操作系统的核心部分,负责进程管理、内存管理、文件系统管理和设备驱动程序管理等。
- 其他程序:如函数库、Shell(命令行界面)、图形用户界面(GUI)等,这些程序为用户提供了与操作系统交互的接口。
设计OS的目的
- 与硬件交互:操作系统是计算机硬件的直接管理者,它通过内核与硬件进行交互,实现对硬件资源的控制。
- 管理软硬件资源:操作系统负责分配和管理CPU时间、内存、存储设备和输入输出设备等资源。
- 提供执行环境:为用户程序(应用程序)提供执行所需的环境,包括文件系统、网络通信、安全机制等。
描述和组织被管理对象
- 硬件资源:CPU、内存、存储设备、输入输出设备等。
- 软件资源:用户程序、系统程序、库文件等。
3、进程
基本概念
- 课本概念:进程是程序的一个执行实例,是正在执行的程序。
- 内核观点:进程是分配系统资源(如CPU时间和内存)的实体。
进程id和父进程id
进程 ID(Process ID,PID)和父进程 ID(Parent Process ID,PPID)是操作系统中用于标识和管理进程的关键属性
进程 ID (PID):
- 每个运行中的进程都有一个唯一的数字标识符,称为 PID。
- PID 是由操作系统分配的,用于区分系统中的每个进程。
- 它通常从1开始递增,但操作系统重启后会重置。
- 可以通过命令如
ps来查看系统中所有进程的 PID。
父进程 ID (PPID):
- 每个进程都有一个父进程,除了初始进程(通常 PID 为1 的进程,如 init 进程)。
- PPID 是指启动当前进程的父进程的 PID。
- 父进程可以控制子进程的执行,例如发送信号、终止子进程等。
- 当父进程终止时,子进程通常会被 init 进程接管,init 进程的 PID 通常为 1.
C语言利用系统调用接口获取PID、PPID:
getpid():这是一个系统调用,用于获取调用进程的 PID。getppid():这也是一个系统调用,用于获取调用进程的父进程的 PID。
cpp
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
printf("pid: %d\n", getpid());
printf("ppid: %d\n", getppid());
return 0;
}进程描述-PCB进程控制块
- PCB是存储进程信息的数据,结构进程的属性集合被存储在PCB中。
- 在Linux操作系统中,描述进程的结构体是
task_struct。 - 在Linux内核源代码中,所有进程以
task_struct双向链表的形式被组织起来
task_struct内容分类
- 标示符:进程的唯一标识符。
- 状态:包括任务状态、退出代码、退出信号等。
- 优先级:进程相对于其他进程的优先级。
- 程序计数器:指向程序中即将执行的下一条指令的地址。
- 内存指针:指向程序代码、进程数据以及共享内存的指针。
- 上下文数据:处理器寄存器中的数据,用于进程切换时保存和恢复状态。
- I/O状态信息:包括I/O请求、分配的I/O设备和使用的文件列表。
- 记账信息:可能包括处理器时间、使用的时钟数、时间限制和账号信息。
- other...
查看进程
- 目录 /proc********下存在进程的相关信息(进程产生时创建、销毁时删除,目录名为进程PID) ,进程信息可以通过
/proc系统文件夹查看,例如/proc/1包含PID为1的进程信息。 - 用户级工具如
top和ps也可以用来获取进程信息。
🔔
常用命令解释: ps axj | head -1 && ps axj | grep ...
ps axj:
ps:进程状态命令。ax:显示所有进程,包括其他用户的进程。a表示显示其他用户的进程,x表示显示没有控制终端的进程。j:使用 jobs 格式来显示进程信息,这种格式将进程的相关信息以易于阅读的方式展示,包括进程的父子关系。
head -1:
head:一个命令,用于显示文件的开始部分,默认情况下显示前10行。-1:选项,表示只显示一行。在这个上下文中,它与ps axj结合使用,只显示进程列表的第一行,这通常是列标题。- ps axj | head -1********用于打印ps命令字段含义。
&&:
- 逻辑与操作符。用来执行
&&前后两条命令则执行后面的命令。
grep ...:
grep:一个文本搜索工具,用于搜索包含指定模式的行。...:需要搜索的进程名称。- ****ps axj | grep ...****用于打印ps命令经过grep命令筛选后特定的字段内容。
首先显示所有进程的标题行,如果成功显示,则继续执行第二个命令,即显示所有进程的列表,并过滤出包含特定模式的进程。
简单的进程监控脚本
在****ps axj | head -1 && ps axj | grep ...****的基础上可以设计一个循环shell脚本,一秒钟查询一次进程状态。
cpp
while :; do ps axj | head -1 && ps axj | grep ...; echo ""; sleep 1; done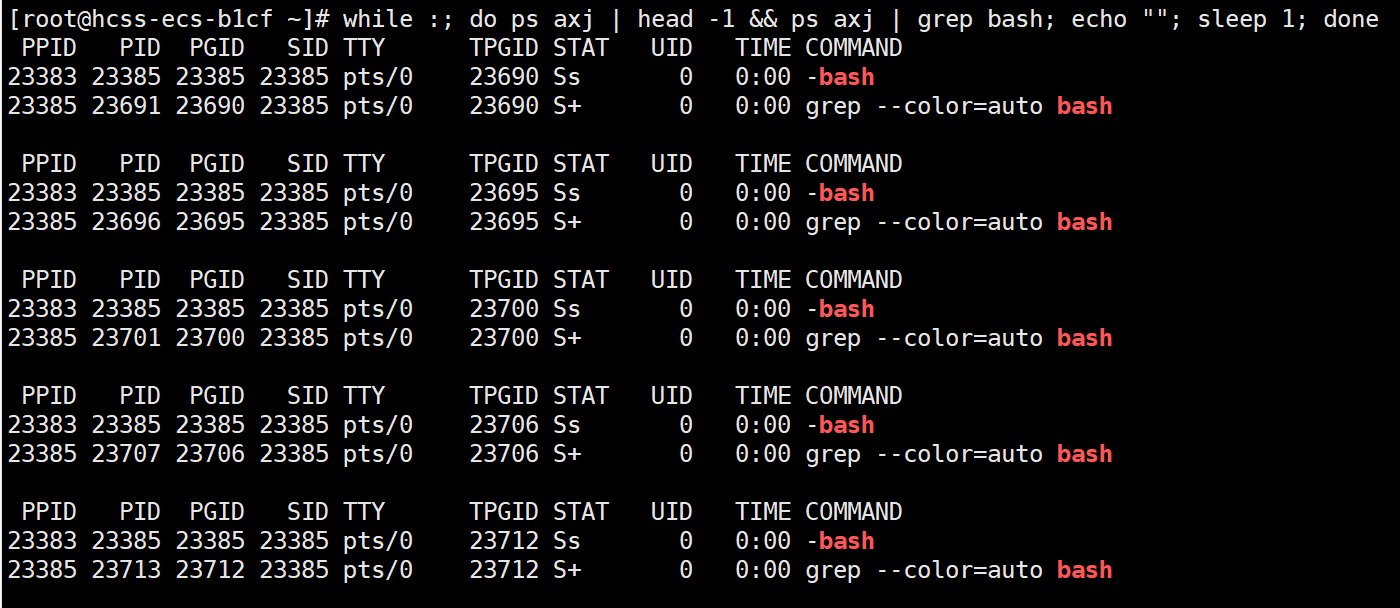
在C语言中通过系统调用fork函数创建进程
fork() 是一个在 Unix 和类 Unix 操作系统中创建新进程的系统调用。它是进程创建的基础,并且是多任务和多线程编程中非常重要的一部分。
****fork()****系统调用:
fork()创建一个新的进程,这个新进程是调用进程的一个副本。fork()返回两次:一次在父进程中(返回子进程的 PID),一次在子进程中(返回 0)。- 如果
fork()调用失败,它会在父进程中返回-1,并且设置全局变量errno以指示错误。 fork()之后,父进程和子进程将从fork()调用之后的代码点继续执行,这可能导致代码的重复执行。通常使用if语句来区分父进程和子进程的行为。- 子进程继承了父进程的所有资源,但是它们拥有不同的 PID 和 PPID。
- 在使用
fork()创建大量子进程时,需要考虑资源限制和僵尸进程问题(后续进程状态介绍)。
示例1:使用 fork() 创建新进程,并通过返回值区分父子进程
cpp
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
int ret = fork();
if (ret < 0) {
perror("fork");
return 1;
} else if (ret == 0) { // 子进程
printf("I am child : %d!, ret: %d\n", getpid(), ret);
} else { // 父进程
printf("I am father : %d!, ret: %d\n", getpid(), ret);
}
sleep(1);
return 0;
}示例2:使用 fork() 创建新进程,并打印相关信息
cpp
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
int ret = fork();
printf("hello proc : %d!, ret: %d\n", getpid(), ret);
sleep(1);
return 0;
}4、进程状态
Linux 系统中的进程管理是操作系统的核心功能之一。Linux内核定义了多种进程状态,包括运行(R)、睡眠(S)、不可中断睡眠(D)、停止(T)、追踪停止(t)、死亡(X)和僵尸(Z)。
进程状态概览
在 Linux 内核中,进程(或称为任务)可以处于以下状态:
- 运行状态 (R - Running) :
- 进程正在使用 CPU,或者在 CPU 运行队列中等待被调度。
- 睡眠状态 (S - Sleeping) :
- 进程正在等待某个事件发生,如网络响应或文件 I/O 完成。这种睡眠是可中断的,进程可以被唤醒。
- 磁盘休眠状态 (D - Disk Sleep) :
- 进程正在进行 I/O 操作,如磁盘读写,但无法被中断。这种状态也称为不可中断睡眠状态。
- 停止状态 (T - Stopped) :
- 进程被
SIGSTOP信号停止,通常用于调试或系统管理。进程可以通过SIGCONT信号恢复运行。- 追踪停止状态 (t - Tracing Stop) :
- 进程因为某些原因被系统调用或工具追踪并停止,通常用于系统分析和监控。
- 死亡状态 (X - Dead) :
- 进程已经结束其执行,但尚未从进程表中完全移除。这是一个过渡状态,系统将很快回收其资源。
- 僵尸状态 (Z - Zombie) :
- 进程已经结束,但父进程尚未读取其退出状态。僵尸进程占用系统资源,尤其是进程 ID,直到父进程调用
wait()或waitpid()函数。
cpp
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};僵尸状态(子进程结束却没被父进程回收)
僵尸进程(Zombie Process)是 Linux 和类 Unix 系统中一种特殊的进程状态。在这种状态下,进程已经完成其执行,但它的进程描述符(PCB)仍然保留在系统中。这种状态的进程不占用 CPU 资源,但它们仍然占用一个进程 ID(PID)和其他一些资源。
形成僵尸进程的条件
- 子进程退出 :子进程完成其任务后调用
exit()或者返回从main()函数,这会导致子进程退出。 - 父进程未读取状态 :如果父进程没有调用
wait()或waitpid()来读取子进程的退出状态,子进程就会变成僵尸状态。
僵尸进程的危害
- 占用进程 ID:僵尸进程继续占用一个进程 ID,这在系统资源有限的情况下可能是个问题。
- 内存泄漏:虽然僵尸进程不占用 CPU 资源,但它们仍然保留在进程表中,进程表本质是一个结构体,也需要占用系统内存资源,造成了内存泄露
示例代码:创建并观察僵尸进程
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
pid_t id = fork();
if (id < 0) {
perror("fork");
return 1;
} else if (id > 0) { // 父进程
printf("Parent[%d] is sleeping...\n", getpid());
sleep(30); // 父进程睡眠,不读取子进程状态,形成僵尸进程
} else if(id == 0){ // 子进程
printf("Child[%d] is beginning...\n", getpid());
sleep(5);
exit(0);
}
return 0;
}- 程序开始时,父进程被创建。
- 父进程通过
fork()创建子进程。 - 子进程打印开始消息,休眠5秒,然后退出。
- 父进程打印正在睡眠的消息,然后休眠30秒。由于父进程在sleep时间内不检查子进程的状态,子进程在退出后会变成僵尸进程。
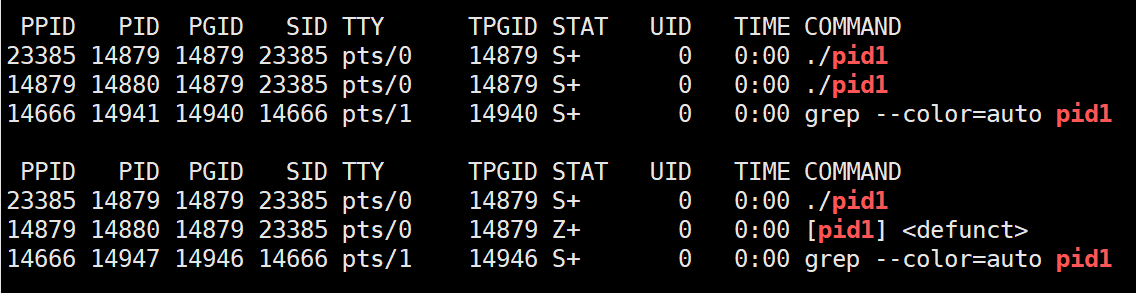
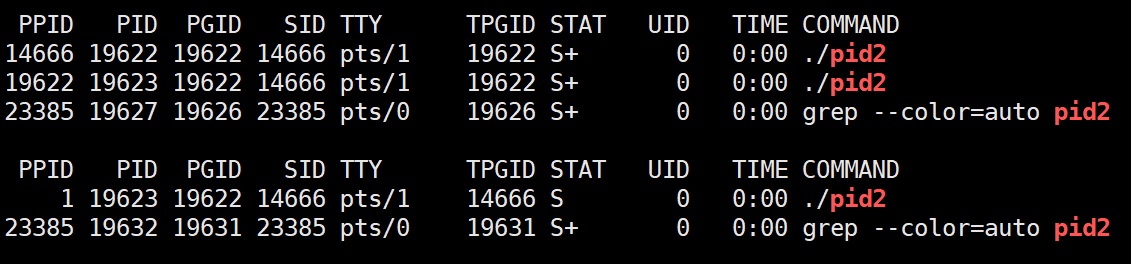
孤儿状态(父进程结束子进程还在)
孤儿进程(Orphan Process)是其父进程已终止,但子进程仍在运行的进程。在类 Unix 系统中,孤儿进程会被 init 进程(通常是 PID 为 1 的进程)领养,并最终由 init 进程回收。
孤儿进程的形成:
- 父进程退出:父进程由于某种原因(如正常退出、被终止等)而结束运行。
- 子进程仍在运行:在父进程退出时,如果有任何子进程仍在运行,这些子进程就会变成孤儿进程。
孤儿进程的处理:
- init********进程领养 :系统会自动将孤儿进程的父进程设置为
init进程(PID 为 1)。 - 状态变更 :孤儿进程在结束运行后,会进入僵尸状态(Zombie State),等待
init进程读取其退出状态。 - 资源回收 :
init进程会周期性地检查并回收孤儿进程的资源,包括其进程描述符等。
示例:孤儿进程的形成和处理:
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
int main() {
pid_t pid = fork(); // 创建子进程
if (pid < 0) {
perror("fork failed");
exit(EXIT_FAILURE);
}
if (pid == 0) {
// 子进程
printf("Child process, PID: %d, PPID: %d\n", getpid(), getppid());
// 子进程继续运行,模拟父进程退出后的场景
sleep(10);
} else {
// 父进程退出,子进程成为孤儿进程
printf("Parent process, PID: %d, exiting and leaving child orphaned.\n", getpid());
sleep(3);
_exit(0);
}
// 子进程代码不会被执行,因为父进程已经退出
return 0;
}在这个示例中,父进程创建了一个子进程,然后立即退出。这导致子进程成为孤儿进程。在实际系统中,init 进程会接管这个孤儿进程,并在其退出后回收资源。
5、进程调度与优先级
在 Linux 系统中,进程优先级决定了 CPU 资源的分配顺序。进程优先级可以通过nice值调整,nice值的范围是-20至19,nice值越小进程优先级越高。进程调度是操作系统的核心功能之一,它决定了进程执行的顺序。
基本概念
- 进程优先权(Priority):决定了进程被 CPU 执行的先后顺序。优先权高的进程会优先获得 CPU 时间。
- 多任务环境:在多任务环境中,合理配置进程优先级可以显著改善系统性能。
查看系统进程
在 Linux 或 Unix 系统中,可以使用 ps -l 命令来查看系统进程列表。

输出将包括以下重要信息:
- UID:用户 ID,表示执行进程的用户身份。
- PID:进程 ID,是进程的唯一标识。
- PPID:父进程 ID,表示该进程是由哪个父进程创建的。
- PRI:进程的优先级。
- NI:nice 值,表示进程优先级的修正数值。
PRI 和 NI
- PRI:进程的原始优先级,数值越小表示优先级越高。
- NI :nice 值,用于调整进程的优先级。计算新的优先级公式为
PRI(new) = PRI(old) + NI。 - nice 值的范围:从 -20 到 19,共 40 个级别。正值表示降低进程优先级,负值表示提高进程优先级。
注意:nice 值不是进程的优先级,而是进程优先级允许调整的范围。可以将其视为对原始优先级的一个修正。通过调整 nice 值,可以控制进程的相对优先级,从而影响 CPU 资源的分配。
最终,操作系统根据PRI(new)的值,按从小到大的优先级执行。
操作:在bash中通过pid调整特定进程优先级
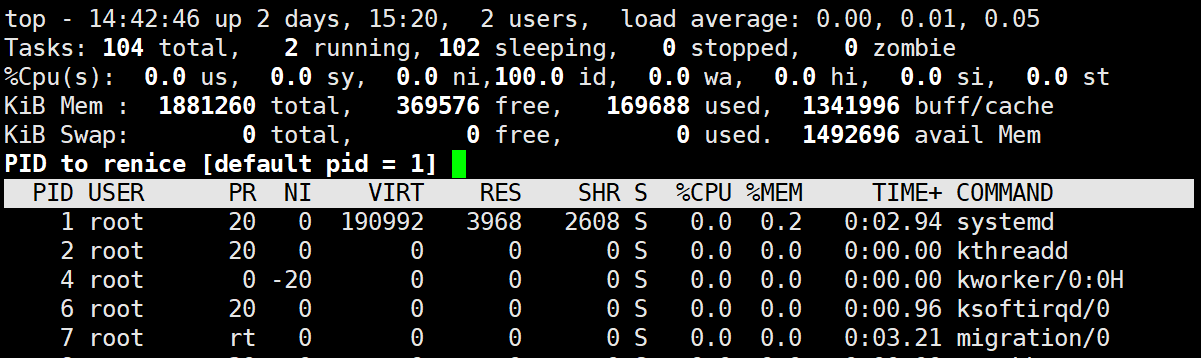
- 使用 top********命令可以动态查看进程优先级。
- 按 r********键来调整指定pid进程的 nice 值。
6、环境变量:操作系统的隐秘力量
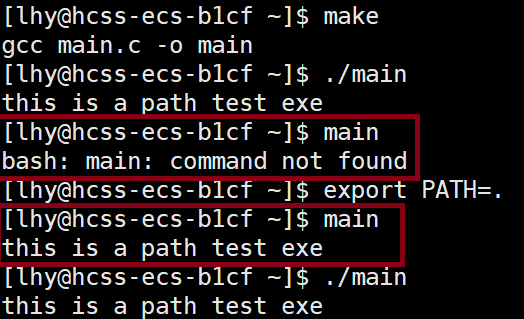
引入:我们知道,在 Linux 系统中,确实"一切皆文件 ",命令的本质是一个可执行程序(大部分是c语言编译而来的可执行程序),命令名其实就是文件名,命令可以不需要完整路径就能执行 。例如:只需要输入ls命令就可以执行对应的程序,获取目录内的文件。但是,为什么我们自己写的程序必须要带完整的文件路径才可以执行(./main),而命令程序只需要文件名即可? 这背后的原理涉及到 Linux 的文件系统和环境变量 ,尤其是 PATH 环境变量。
基本概念
环境变量为操作系统、系统上的应用程序和用户shell提供了一个传递配置信息的方法。它们可以告诉系统在哪里找到所需的文件,如何配置特定的程序,或者在shell中定义别名等。
常见环境变量
- PATH :定义了操作系统搜索可执行文件的目录顺序。例如,当你在终端输入一个命令时,系统会在PATH变量指定的目录中查找这个命令,发现相应文件就可以直接执行(相当于自动补全文件路径)。当我们把我们自己写的代码目录放入PATH环境变量之后,也能向命令一样只需要输入文件名即可执行。(相关的修改操作后半部分介绍~)
- HOME:指向用户的主目录。当你登录系统时,这是你的默认工作目录。
- SHELL :表示当前用户使用的shell类型,通常的值是
/bin/bash。
查看和设置环境变量
- 查看环境变量 :可以使用
echo $NAME命令来打印特定的环境变量值,其中NAME是环境变量的名称。 - 设置环境变量 :
- 使用
export命令创建或修改环境变量,如export PATH=$PATH:/new/directory/path。 - 使用
env命令可以查看所有当前的环境变量。
- 使用
- 清除环境变量 :使用
unset命令可以删除一个环境变量。 - 显示所有本地变量 :使用
set命令可以显示当前shell会话中定义的所有本地变量和环境变量。
📌
- echo: 显示某个环境变量值
- export: 设置一个新的环境变量
- env: 显示所有环境变量
- unset: 清除环境变量
- set: 显示本地定义的shell变量和环境变量
环境变量的组织方式
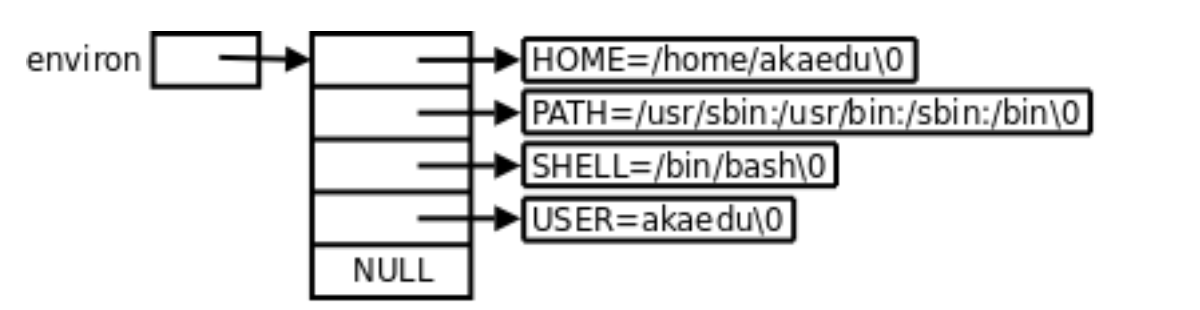
程序在运行时,main函数第三个参数(也是最后一个参数)会被转入一张环境变量表
示例1:通过main函数参数获取
cpp
#include<stdio.h>
int main(int argc, char* argv, char** env)
{
int i = 0;
while(env[i])
{
printf("env[%d]->%s\n",i,env[i]);
i++;
}
return 0;
}
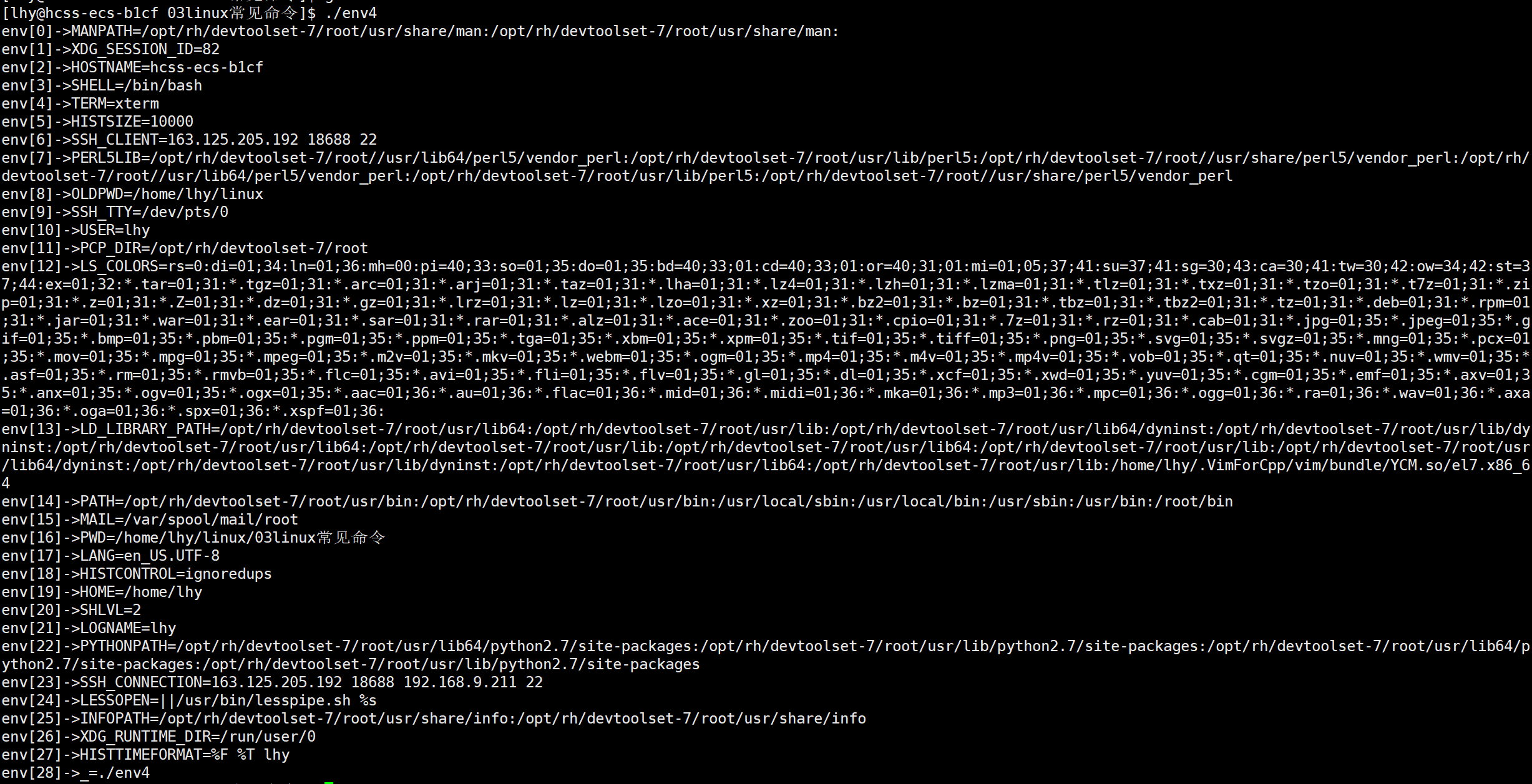
示例2:通过extern变量获取
cpp
#include <stdio.h>
int main()
{
extern char **environ;
int i = 0;
for(; environ[i]; i++)
{
printf("env[%d]->%s\n", i, environ[i]);
}
return 0;
}
示例3:通过getenv()和putenv()接口操作单个环境变量
getenv 和 putenv 是两种用于处理环境变量的函数,它们分别用于获取和设置环境变量的值。下面是对这两个函数的介绍,包括它们所属的头文件、函数原型、参数、返回值以及一些使用示例。
getenv
- 头文件 :
#include <stdlib.h> - 函数原型:
cpp
char *getenv(const char *name);- 参数 :
name:一个指向以 null 结尾的字符串的指针,指定要查询的环境变量名称。
- 返回值 :
- 如果环境变量存在,返回指向该环境变量值的指针。
- 如果环境变量不存在,返回
NULL。
cpp
#include <stdio.h>
#include <stdlib.h>
int main() {
const char *homeDir = getenv("HOME");
if (homeDir != NULL) {
printf("The HOME environment variable is set to: %s\n", homeDir);
} else {
printf("The HOME environment variable is not set.\n");
}
return 0;
}putenv
- 头文件 :
#include <stdlib.h>(在某些系统上可能需要#include <unistd.h>) - 函数原型:
cpp
int putenv(char *string);- 参数 :
string:一个指向以 null 结尾的字符串的指针,该字符串应该包含环境变量的名称和值,格式为name=value。
- 返回值 :
- 成功时返回 0。
- 失败时返回非零值。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
// 设置环境变量
const char *envVar = "MY_VAR=value";
if (putenv((char *)envVar) == 0) {
printf("Environment variable set successfully.\n");
} else {
perror("Failed to set environment variable");
}
// 验证设置是否成功
const char *value = getenv("MY_VAR");
if (value != NULL) {
printf("MY_VAR is now set to: %s\n", value);
} else {
printf("MY_VAR is not set.\n");
}
return 0;
}- 使用
putenv时,传入的字符串string必须以name=value的格式存在,并且string指向的内存在函数调用后不应被释放或修改,因为putenv可能会修改这个字符串。 - 在多线程环境中,使用
putenv可能不是线程安全的。在这种情况下,可以考虑使用setenv和unsetenv(如果可用),这些函数提供了线程安全的替代。 - 环境变量的更改通常只影响当前进程及其子进程,不会影响其他进程或父进程的环境变量。
环境变量和普通变量的区别:环境变量具有全局属性
环境变量具有全局属性,意味着它们可以在操作系统的不同进程之间共享。当一个程序运行时,它通常会从其父进程那里继承环境变量。这种继承机制允许程序访问由操作系统或其它程序设置的配置信息。
当你在命令行中设置一个环境变量,比如使用 export my_env ="lihongyu" 命令,实际上是在当前的shell会话中设置了这个变量。这个变量会立即在当前shell会话中可用,并且所有从这个shell启动的子进程也会继承这个变量。
如果你只设置环境变量而不使用 export 命令,比如 my_env="lihongyu",那么这个变量只会在当前的shell会话中存在,而不会被子进程继承。这是因为只有通过 export 命令,变量才会被标记为可导出,从而被子进程继承。
cpp
#include<stdio.h>
#include<stdlib.h>
int main()
{
const char* env = getenv("my_env");
if(env){
printf("%s\n", env);
}
return 0;
}
一个简单的实验,发现环境变量的继承和普通变量的区别在于:
- 作用域:普通变量只在当前shell会话中有效,而环境变量可以跨会话和进程边界。
- 继承:环境变量可以被子进程继承,而普通变量则不能。
- 生命周期:普通变量的生命周期仅限于当前shell会话,环境变量则可以持续存在于操作系统中,直到被显式地修改或删除。