本篇通过拆解一段很简单的汇编代码来快速认识汇编,为读懂鸿蒙汇编打基础.系列篇后续将逐个剖析鸿蒙的汇编文件.
汇编很简单
-
第一: 要认定汇编语言一定是简单的,没有高深的东西,无非就是数据的搬来搬去,运行时数据主要待在两个地方:内存和寄存器。寄存器是CPU内部存储器,离运算器最近,所以最快.
-
第二: 运行空间(栈空间)就是CPU打卡上班的地方,内核设计者规定谁请CPU上班由谁提供场地,用户程序提供的场地叫用户栈,敏感工作CPU要带回公司做,公司提供的场地叫内核栈,敏感工作叫系统调用,系统调用的本质理解是CPU要切换工作模式即切换办公场地。
-
第三:CPU的工作顺序是流水线的,它只认指令,而且只去一个地方(指向代码段的PC寄存器)拿指令运算消化。指令集是告诉外界我CPU能干什么活并提供对话指令,汇编语言是人和CPU能愉快沟通不拧巴的共识语言。一一对应了CPU指令,又能确保记性不好的人类能模块化的设计idea, 先看一段C编译成汇编代码再来说模块化。
square(c -> 汇编)
//编译器: armv7-a clang (trunk)
//++++++++++++ square(c -> 汇编)++++++++++++++++++++++++
int square(int a,int b){
return a*b;
}
square(int, int):
sub sp, sp, #8 @sp减去8,意思为给square分配栈空间,只用2个栈空间完成计算
str r0, [sp, #4] @第一个参数入栈
str r1, [sp] @第二个参数入栈
ldr r1, [sp, #4] @取出第一个参数给r1
ldr r2, [sp] @取出第二个参数给r2
mul r0, r1, r2 @执行a*b给R0,返回值的工作一直是交给R0的
add sp, sp, #8 @函数执行完了,要释放申请的栈空间
bx lr @子程序返回,等同于mov pc,lr,即跳到调用处fp(c -> 汇编)
//++++++++++++ fp(c -> 汇编)++++++++++++++++++++++++
int fp(int b)
{
int a = 1;
return square(a+b,a+b);
}
fp(int):
push {r11, lr} @r11(fp)/lr入栈,保存调用者main的位置
mov r11, sp @r11用于保存sp值,函数栈开始位置
sub sp, sp, #8 @sp减去8,意思为给fp分配栈空间,只用2个栈空间完成计算
str r0, [sp, #4] @先保存参数值,放在SP+4,此时r0中存放的是参数
mov r0, #1 @r0=1
str r0, [sp] @再把1也保存在SP的位置
ldr r0, [sp] @把SP的值给R0
ldr r1, [sp, #4] @把SP+4的值给R1
add r1, r0, r1 @执行r1=a+b
mov r0, r1 @r0=r1,用r0,r1传参
bl square(int, int)@先mov lr, pc 再mov pc square(int, int)
mov sp, r11 @函数执行完了,要释放申请的栈空间
pop {r11, lr} @弹出r11和lr,lr是专用标签,弹出就自动复制给lr寄存器
bx lr @子程序返回,等同于mov pc,lr,即跳到调用处main(c -> 汇编)
//++++++++++++ main(c -> 汇编)++++++++++++++++++++++++
int main()
{
int sum = 0;
for(int a = 0;a < 100; a++){
sum = sum + fp(a);
}
return sum;
}
main:
push {r11, lr} @r11(fp)/lr入栈,保存调用者的位置
mov r11, sp @r11用于保存sp值,函数栈开始位置
sub sp, sp, #16 @sp减去16,意思为给main分配栈空间,只用4个栈空间完成计算
mov r0, #0 @初始化r0
str r0, [r11, #-4] @执行sum = 0
str r0, [sp, #8] @sum将始终占用SP+8的位置
str r0, [sp, #4] @a将始终占用SP+4的位置
b .LBB1_1 @跳到循环开始位置
.LBB1_1: @循环开始位置入口
ldr r0, [sp, #4] @取出a的值给r0
cmp r0, #99 @跟99比较
bgt .LBB1_4 @大于99,跳出循环 mov pc .LBB1_4
b .LBB1_2 @继续循环,直接 mov pc .LBB1_2
.LBB1_2: @符合循环条件入口
ldr r0, [sp, #8] @取出sum的值给r0,sp+8用于写SUM的值
str r0, [sp] @先保存SUM的值,SP的位置用于读SUM值
ldr r0, [sp, #4] @r0用于传参,取出A的值给r0作为fp的参数
bl fp(int) @先mov lr, pc再mov pc fp(int)
mov r1, r0 @fp的返回值为r0,保存到r1
ldr r0, [sp] @取出SUM的值
add r0, r0, r1 @计算新sum的值,由R0保存
str r0, [sp, #8] @将新sum保存到SP+8的位置
b .LBB1_3 @无条件跳转,直接 mov pc .LBB1_3
.LBB1_3: @完成a++操作入口
ldr r0, [sp, #4] @SP+4中记录是a的值,赋给r0
add r0, r0, #1 @r0增加1
str r0, [sp, #4] @把新的a值放回SP+4里去
b .LBB1_1 @跳转到比较 a < 100 处
.LBB1_4: @循环结束入口
ldr r0, [sp, #8] @最后SUM的结果给R0,返回值的工作一直是交给R0的
mov sp, r11 @函数执行完了,要释放申请的栈空间
pop {r11, lr} @弹出r11和lr,lr是专用标签,弹出就自动复制给lr寄存器
bx lr @子程序返回,跳转到lr处等同于 MOV PC, LR代码有点长,都加了注释,如果能直接看懂那么恭喜你,鸿蒙内核的6个汇编文件基于也就懂了。这是以下C文件全貌
文件全貌
#include <stdio.h>
#include <math.h>
int square(int a,int b){
return a*b;
}
int fp(int b)
{
int a = 1;
return square(a+b,a+b);
}
int main()
{
int sum = 0;
for(int a = 0;a < 100; a++){
sum = sum + fp(a);
}
return sum;
}代码很简单谁都能看懂,代码很典型,具有代表性,有循环,有判断,有运算,有多级函数调用。编译后的汇编代码基本和C语言的结构差不太多,区别是对循环的实现用了四个模块,四个模块也好理解:
一个是开始块(LBB1_1), 一个符合条件的处理块(LBB1_2),一个条件发生变化块(LBB1_3),最后收尾块(LBB1_4).
按块逐一剖析.
先看最短的那个
int square(int a,int b){
return a*b;
}
//编译成
square(int, int):
sub sp, sp, #8 @sp减去8,意思为给square分配栈空间,只用2个栈空间完成计算
str r0, [sp, #4] @第一个参数入栈
str r1, [sp] @第二个参数入栈
ldr r1, [sp, #4] @取出第一个参数给r1
ldr r2, [sp] @取出第二个参数给r2
mul r0, r1, r2 @执行a*b给R0,返回值的工作一直是交给R0的
add sp, sp, #8 @函数执行完了,要释放申请的栈空间
bx lr @子程序返回,等同于mov pc,lr,即跳到调用处首先上来一句 sub sp, sp, #8 等同于 sp = sp - 8 ,CPU运行需要场地,这个场地就是栈 ,SP是指向栈的指针,表示此时用栈的刻度. 代码和鸿蒙内核用栈方式一样,都采用了递减满栈的方式(FD).
什么是递减满栈? 递减指的是栈底地址高于栈顶地址,栈的生长方向是递减的, 满栈指的是SP指针永远指向栈顶. 每个函数都有自己独立的栈底和栈顶,之间的空间统称栈帧.可以理解为分配了一块
区域给函数运行,sub sp, sp, #8 代表申请2个栈空间,一个栈空间按四个字节算.
用完要不要释放?当然要,add sp, sp, #8 就是释放栈空间. 是一对的,减了又加回去,空间就归还了.
ldr r1, sp, #4 的意思是取出SP+4这个虚拟地址的值给r1寄存器,而SP的指向并没有改变的,还是在栈顶, 为什么要+呢, +就是往回数, 定位到分配的栈空间上.
一定要理解递减满栈,这是关键! 否则读不懂内核汇编代码.
入参方式
一般都是通过寄存器(r0...r10)传参,fp调用square之前会先将参数给(r0...r10)
add r1, r0, r1 @执行r1=a+b
mov r0, r1 @r0=r1,用r0,r1传参
bl square(int, int)@先mov lr, pc 再mov pc square(int, int) 到了square中后,先让 r0,r1入栈,目的是保存参数值, 因为 square中要用r0,r1 ,
str r0, [sp, #4] @先入栈保存第一个参数
str r1, [sp] @再入栈保存第二个参数
ldr r1, [sp, #4] @再取出第一个参数给r1,(a*b)中a值
ldr r2, [sp] @再取出第二个参数给r2,用于计算 (a*b)中b值是不是感觉这段汇编很傻,直接不保存计算不就完了吗,这个是流程问题,编译器统一先保存参数,至于你想怎么用它不管,也管不了.
另外返回值都是默认统一给r0保存. square中将(a*b)的结果给了r0,回到fp中取出R0对fp来说这就是square的返回值,这是规定.
函数调用
main 和 fp 中都需要调用其他函数,所以都出现了
push {r11, lr}
//....
pop {r11, lr}这哥俩也是成对出现的,这是函数调用的必备装备,作用是保存和恢复调用者的现场,例如 main -> fp, fp要保存main的栈帧范围和指令位置, lr保存的是main函数执行到哪个指令的位置, r11的作用是指向main的栈顶位置,如此fp执行完后return回main的时候,先mov pc,lr, PC寄存器的值一变, 表示执行的代码就变了,又回到了main的指令和栈帧继续未完成的事业.
内存和寄存器数据怎么搬?
数据主要待在两个地方:内存和寄存器. 寄存器<->寄存器 , 内存<->寄存器 , 内存<->内存 搬运指令都不一样.
str r1, [sp] @ 寄存器->内存
ldr r1, [sp, #4] @ 内存->寄存器这又是一对,用于 内存<->寄存器之间,熟知的 mov r0, r1 用于 寄存器<->寄存器
追问三个问题
第一:如果是可变参数怎么办? 100个参数怎么整, 通过寄存器总共就12个,不够传参啊
第二:返回值可以有多个吗?
第三:数据搬运可以不经过CPU吗?
经常有很多小伙伴抱怨说:不知道学习鸿蒙开发哪些技术?不知道需要重点掌握哪些鸿蒙应用开发知识点?
为了能够帮助到大家能够有规划的学习,这里特别整理了一套纯血版鸿蒙(HarmonyOS Next)全栈开发技术的学习路线,包含了鸿蒙开发必掌握的核心知识要点,内容有(ArkTS、ArkUI开发组件、Stage模型、多端部署、分布式应用开发、WebGL、元服务、OpenHarmony多媒体技术、Napi组件、OpenHarmony内核、OpenHarmony驱动开发、系统定制移植等等)鸿蒙(HarmonyOS NEXT)技术知识点。
《鸿蒙 (Harmony OS)开发学习手册》(共计892页)
如何快速入门?
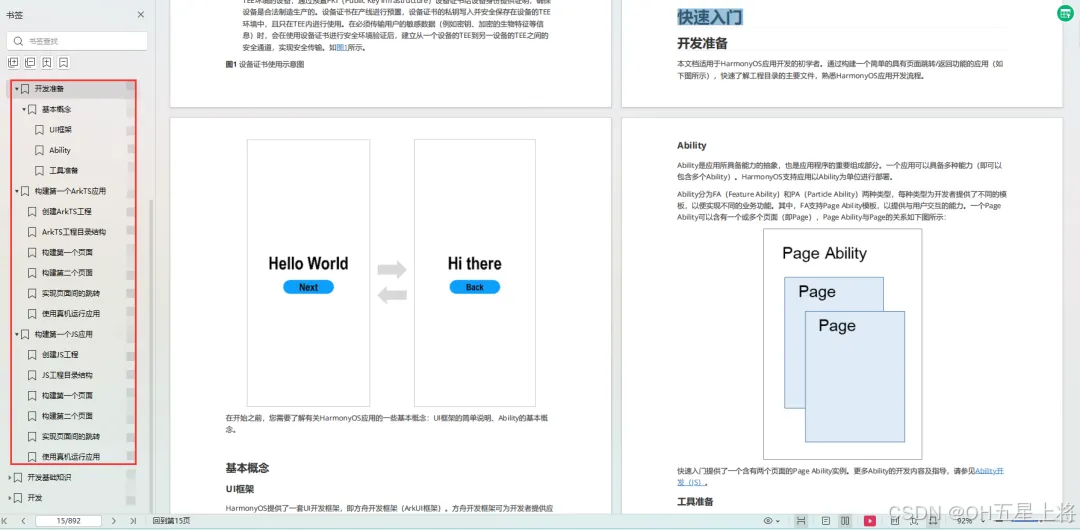
1.基本概念
2.构建第一个ArkTS应用
3.......
开发基础知识:
1.应用基础知识
2.配置文件
3.应用数据管理
4.应用安全管理
5.应用隐私保护
6.三方应用调用管控机制
7.资源分类与访问
8.学习ArkTS语言
9.......

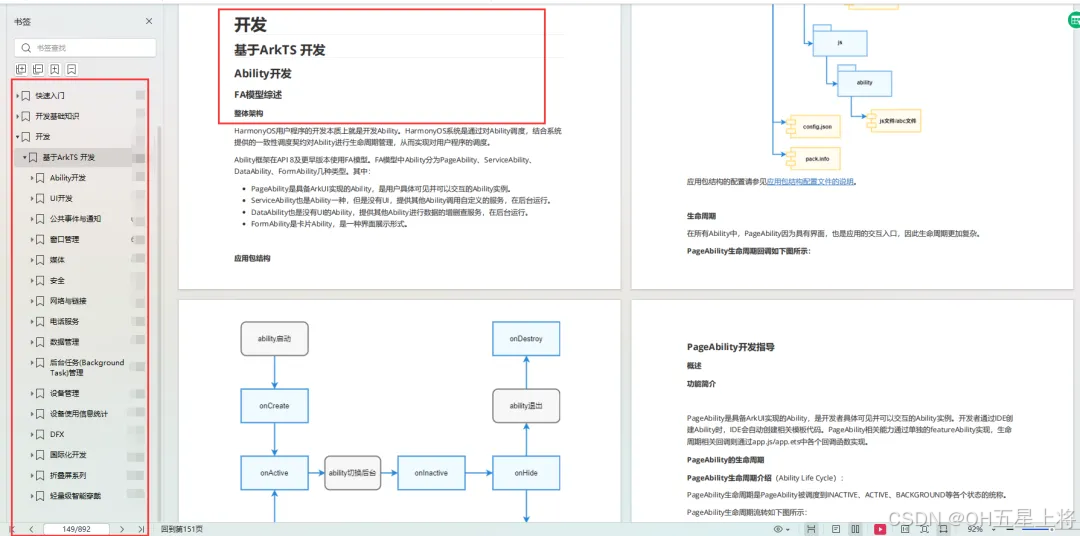
基于ArkTS 开发
1.Ability开发
2.UI开发
3.公共事件与通知
4.窗口管理
5.媒体
6.安全
7.网络与链接
8.电话服务
9.数据管理
10.后台任务(Background Task)管理
11.设备管理
12.设备使用信息统计
13.DFX
14.国际化开发
15.折叠屏系列
16.......
鸿蒙开发面试真题(含参考答案)
OpenHarmony 开发环境搭建
《OpenHarmony源码解析》
- 搭建开发环境
- Windows 开发环境的搭建
- Ubuntu 开发环境搭建
- Linux 与 Windows 之间的文件共享
- ......
- 系统架构分析
- 构建子系统
- 启动流程
- 子系统
- 分布式任务调度子系统
- 分布式通信子系统
- 驱动子系统
- ......

OpenHarmony 设备开发学习手册

写在最后
如果你觉得这篇内容对你还蛮有帮助,我想邀请你帮我三个小忙:
- 点赞,转发,有你们的 『点赞和评论』,才是我创造的动力。
- 关注小编,同时可以期待后续文章ing🚀,不定期分享原创知识。
- 想要获取更多完整鸿蒙最新学习资源,请移步前往
