特斯拉FSD软件进化史
01前言
特斯拉FSD自动驾驶是以摄像头为核心的纯视觉解决方案。
纯视觉方案的最初设计灵感来自对人类视觉的研究;即人眼睛搜集的信息到达视网膜后,经过大脑皮层的多个区域、神经层,最终形成生物视觉,并在脑中生成图像。特斯拉的目标就是通过算法、软件及硬件来设计汽车的视觉皮层,建立像人脑一样的、基于视觉的计算机神经网络系统。
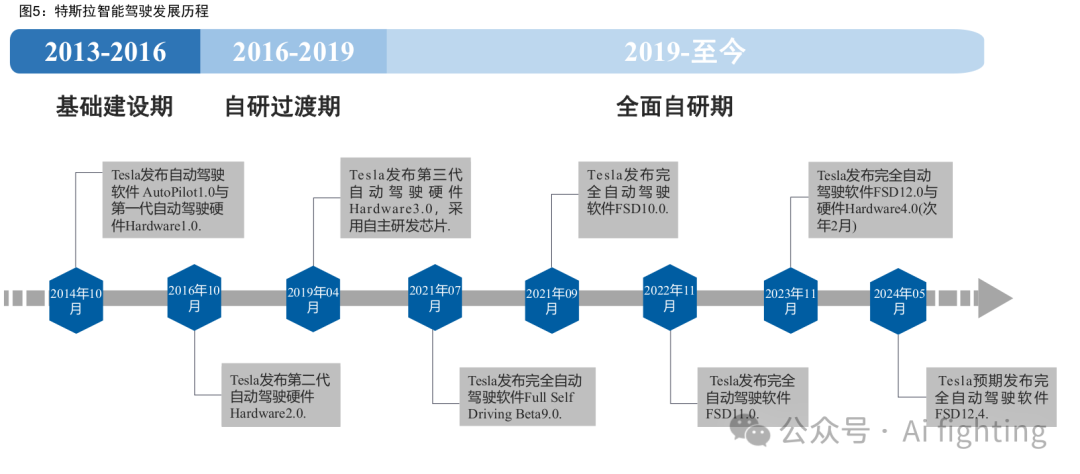
历经十年,特斯拉自动驾驶软硬件系统不断进化。
02软件
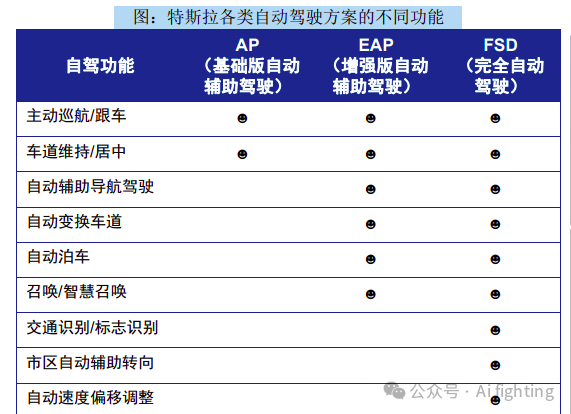
特斯拉的Autopilot自动驾驶软件目前主要分为三个层级,分别是BAP(基础版辅助驾驶)、EAP(增强版辅助驾驶)和FSD(完全自动驾驶)。这些产品对应不同的售价和功能,旨在提供不同程度的自动驾驶体验。
BAP(Basic Autopilot)是特斯拉车型的标准配置,提供基本的自动驾驶功能,如自适应巡航控制和车道保持功能,这些功能可以在交通状况允许的情况下减轻驾驶者的负担。
EAP(Enhanced Autopilot)在BAP的基础上增加了更多高级功能,例如自动变道、高速公路导航辅助(NOA)、智能召唤和自动泊车。这些功能进一步提升了车辆的自动驾驶能力,但需要用户额外购买,在美国的售价为6000美元,在中国的售价为3.2万元人民币。
FSD(Full Self-Driving)是特斯拉提供的最高级自动驾驶软件,尽管目前尚未完全实现自动驾驶,但特斯拉计划通过OTA(Over-The-Air)软件更新逐步实现这一目标。FSD目前仍处于测试Beta版本,其功能包括EAP的所有智驾功能,并且未来将增加城市街道上的自动驾驶功能。
2.1. 由 AP 到 FSD,自动驾驶技术愈发成熟
AP1.0:特斯拉首款自动驾驶软件
2014 年 10 月,AP1.0 与 HW1.0 一同 上车,其核心视觉算法来自于 Mobileye,智能驾驶等级为 L2,具备 OTA 持续升级能力。2014 年-2016 年期间,特斯拉 AP1.0 不断进化,先后增 加车道保持、速度提示、自适应巡航、防碰撞预警、自动转向、侧方位 泊车、自动出库等功能。
与 Mobileye 分道扬镳,特斯拉自研之路开启
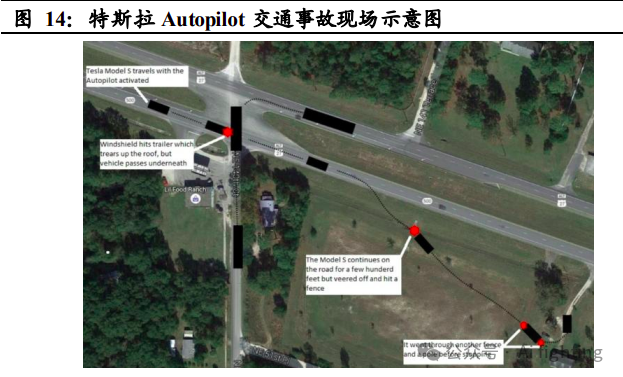
经过一段时间合作,特 斯拉逐渐意识到 Mobileye 的算法十分依赖于自身拥有的行车大数据,而 Mobileye 却无法满足特斯拉对于自动驾驶算法快速迭代的要求,这就使 得特斯拉进行算法自研的意愿愈发强烈。2015 年 4 月,特斯拉组建软件法小组 Vision,自此开始积累算法自研经验。2016 年 5 月,美国加利 福尼亚州一辆开启 Autopilot 的特斯拉 Model S 发生交通事故,特斯拉与 Mobileye 对于事故责任的认定产生争执,进而成为两者合作破裂的导火 索。2016 年 7 月,特斯拉宣布结束与 Mobileye 的合作。
AP2.0:早期效果较差,但后续通过多次更新实现优化
随着 2016 年 HW2.0 问世,特斯拉自研的 AP2.0 同步发布。因结束与 Mobileye 合作,且特斯拉视觉感知技术尚不成熟,起初 AP2.0 的体验效果弱于 AP1.0, 但随 2017 年特斯拉对 AP2.0 进行了 8.1 版本重大更新,AP2.0 增加了十 多个主动安全类功能,车辆控制也更加平滑,AP2.0 的体验效果开始逐 步优于 AP1.0。伴随着 AP2.0 的推出,特斯拉也同步发布了增值服务增强版自动辅助驾驶(EAP)与完全自动驾驶包(FSD),软硬分离的自动驾驶收费模式 确立。其中 FSD 因尚未开发完成,处于期权状态。
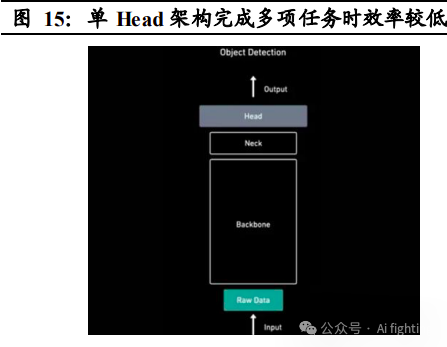
特斯拉前期算法基于传统神经网络 RNN 和 CNN,采用单 Head 架构, 多任务运行效率低
早期的自动驾驶算法基于传统神经网络 RNN 和 CNN,遵循 Input-Backbone-Neck-Head-Output 的运行逻辑,其中主干网 络 Backbone 为特征提取网络,主要用于识别图像中的多个对象,Neck 主要负责提取更为精细的特征,Head 则是在特征提取后进行检测,提供 输入的特征图表示,比如检测对象,实例分割等。在发展早期,视觉神 经网络通常只有一个 Head,这就导致算法完成多项任务时效率较低,例 如在车辆行驶过程中或面临车道线检测、人物检测与追踪、信号灯检测 同时进行的情况,而传统网络架构算法很难做到高效处理。
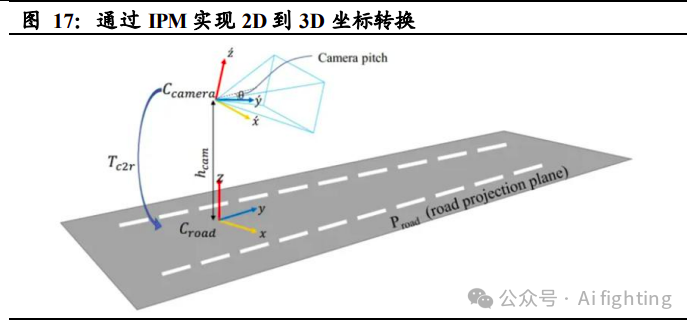
特斯拉前期算法采用 IPM+CNN/RNN 技术实现 3D 感知,精确度较差。
传统摄像头收集到的数据是 2D 图像,但自动驾驶车辆面对的现实世界 是 3D 的,因此需将 2D 图像数据通过模型分析融合后升维至3D,以赋 予自动驾驶车辆更可靠的感知能力。行业里早期的处理方式为用CNN/RNN+IPM 技术实现 3D 视角绘制,但此方案对于成像环境的要 求较高,且CNN+RNN 神经网络下的 2D 至 3D 数据处理精度较差,经 常导致转换出来的 3D 场景与实际场景失真。
特斯拉前期训练依靠人工标注
行业内早期的自动驾驶数据挖掘基于规 则或监督学习,多采用人工标注方式,存在成本高,精度差,一致性低 等问题。特斯拉早期标注方式为委托第三方公司进行人工标注,后成立 自建标注团队,成员人数最高超过 1000 人。
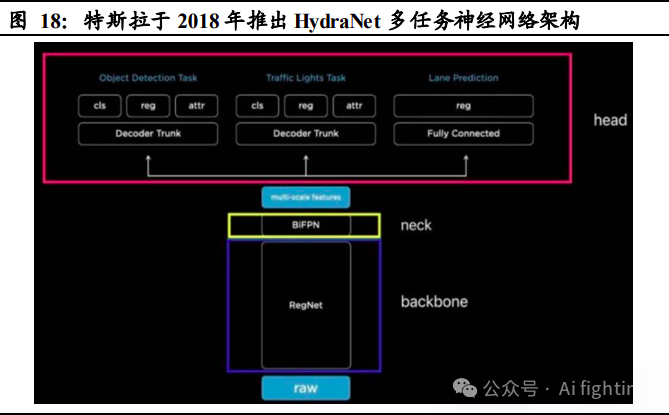
2018 年特斯拉推出 HydraNet(九头蛇)多任务神经网络架构,运行效率提升
HydraNet 系特斯拉研发的多任务学习神经网络架构,属于 Multi-Head 架构,多 Head 的布局使算法具备了多头任务处理能力。此外,HydraNet 能够减少重复的卷积计算,减少主干网络计算数量,还能够将特定任务从主干中解耦出来,进行单独微调,算法运行效率大幅提升。
FSD:
特斯拉早于 2015 年便着手 FSD 功能的实现,2016 年 FSD 作为特 斯拉 EAP 增值服务进行预售,2017 年 FSD 芯片设计完成,2019 年 3 月, 特斯拉推出基于自研芯片 FSD 的 HW 3.0,为 FSD 功能的实现提供了硬 件基础。2019 年 4 月,特斯拉将 FSD 以单独的功能进行出售。除硬件方面,FSD 功能的实现也需要依托算法的进化,但 2020 年前,特斯拉基于传统神经网络的算法能力并不出众,感知问题频出,特斯拉完全自 动驾驶的实现遇到了较大阻碍。

2020 年特斯拉对 FSD 底层软件与训练方式进行重构,算法性能迎来质变。
2020 年 8 月,马斯克在推特上发文称,Autopilot 团队正对软件的 底层代码进行重写和深度神经网络重构。2021年与2022年特斯拉AI Day 上 AP 团队陆续披露了相关重大突破与进展,其中主要包括:
1).2020 年数据由人工标注转向自动标注;
2).2021 年引入 BEV+Transformer 大 模型;
3).2021 年引入时序数据;
4).2022 年引入占用网络技术;
5.) 2022 年发布超级计算机 Dojo。
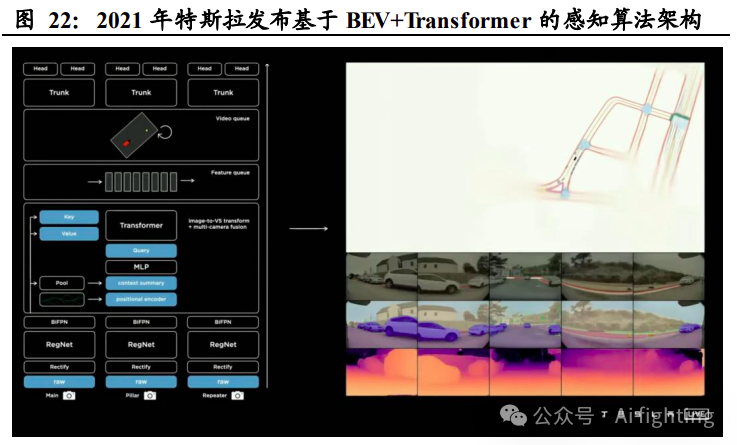
1.BEV+Transformer 大模型使搭建高精度 3D 感知模型成为可能
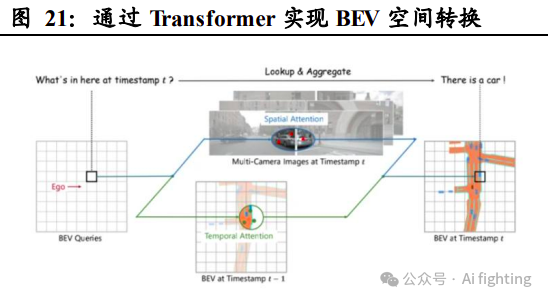
2021 年特斯拉发布基于 BEV+Transformer 的感知算法架构。BEV 即鸟瞰图 BEV 感知策略的实现方式是通过多个摄像头(或辅以激光雷达、毫米波 雷达等)获得全方位视角图像,再通过共享 2D 特征提取器对不同摄像 头获取的画面进行重建、拼接,最终形成 3D 全局视角。与传统 IPM 技 术下的后融合策略不同,BEV 感知策略借用统一的 BEV 空间实现了特 征级融合,数据失真率低,感知准确率更强。Transformer 是一种基于自 注意力的深度学习模型,该模型并不像CNN+RNN 通过串行顺序处理数 据,而是通过自注意力集中机制捕捉序列中不同元素的相关性,更适应 BEV 感知下的数据融合与处理。
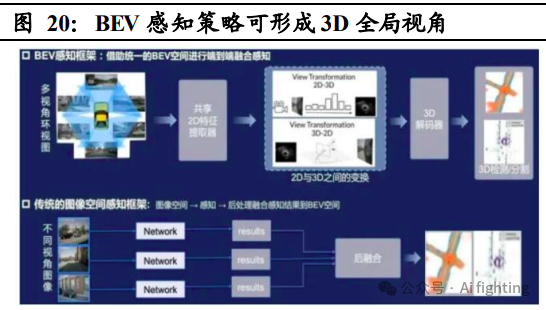
基于 BEV与 Transformer的深度学习能赋予 FSD更强的 3D感知能力, 并可摆脱对高精地图的依赖。
具体实现方式为:通过多个摄像头形成环 视图像,并在 BEV 空间内初始化特征,再通过多层 Transformer 和 2D 特征进行交互融合,最终实现 BEV 特征。BEV 与 Transformer 结构使高 准确率的 3D 视角成像成为可能,大幅提升了 FSD 的感知能力。此外, 通过 BEV 空间的搭建可以形成以车为中心的坐标系,实时绘制出高精 度空间地图,再结合众包模式实现遮挡缺失道路信息补齐,FSD 便可摆 脱对高精地图的依赖。
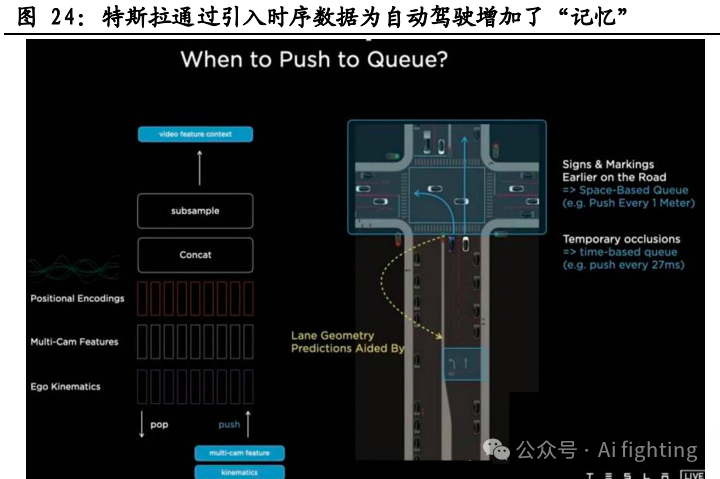
2. 时序数据为 FSD 增加了"记忆",可用于预测遮挡信息等
2021 年 特斯拉在 BEV 感知模型中加入 Video Netural Net,引入时序数据。引入 时序数据后,FSD 算法将使用视频片段,而不是图像来训练神经网络, 因此可以通过先前时间段的数据特征推算当前场景下可能性最大的结果,进而解决遮挡物体运动预测、交通指示牌记忆等问题。

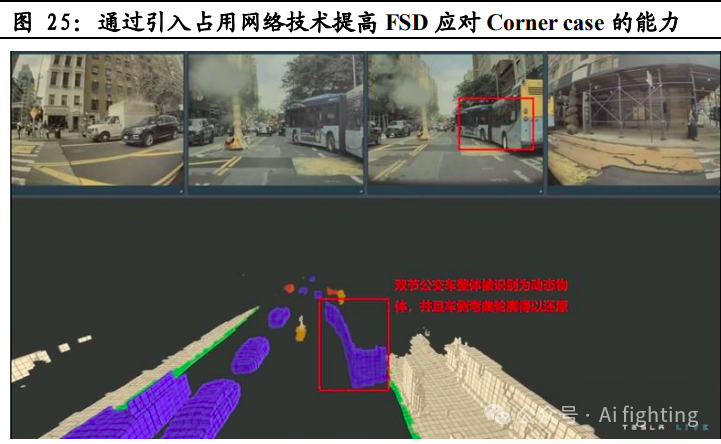
3.引入占用网络使感知算法的泛化能力大幅提升。
2022 年特斯拉引入占 用网络对 BEV 感知进行了升级。传统自动驾驶算法依照先识别判断, 后决策的运行逻辑处理障碍物,这就导致在面对未训练过的物体出现时, 算法无法进行有效检测。相比之下,占用网路技术Occupancy仅通过体素(3D 图像体素对应 2D 图像像素点)概念判断空间是否被占用,而 并不去识别障碍物是什么、这就显著增强了 FSD 的感知泛化能力,使 FSD 应对 Corner case 时更加得心应手。
4.自动标注显著提升了数据处理速度与精度,成本大幅下降
2020 年特 斯拉研发并使用了数据自动标注系统,其原理为将车辆收集到的路面信 息打包上传至服务器,由大模型进行预测性标注后反馈到车端传感器, 由于传感器视角不同,当预测标注结果在所有传感器均一致时自动标注成功。特斯拉通过大模型预训练方式的自动标注大幅提高了标注效率, 成本也显著降低。

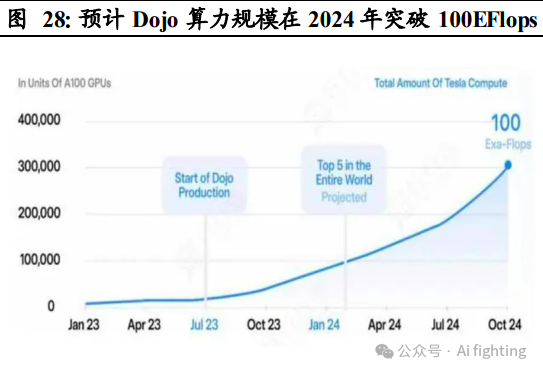
5. 超级计算机 Dojo充分应用大量行车数据。
2022 年特斯拉发布超级 计算机 Dojo,其主要功能为利用海量的数据,做无人监管的自动标注和 仿真训练。Dojo 基于特斯拉自研的 AI 训练芯片 D1,该芯片采用了 7nm 工艺制程,拥有 500 亿个晶体管和 354 个训练节点。Dojo 内部共由 25 颗 D1 芯片组成,可以提供高达 36TB/s 的带宽和 9PetaFLOPS 的算力。2023 年 7 月,Dojo 进入投产阶段。预计未来 Dojo 将凭借高算力、高稳 定性、高拓展力等特点帮助特斯拉 FSD 实现高效的自动标注和仿真训练, 算法迭代加速。

移除毫米波/超声波雷达,走向纯视觉方案。
2021 年 5 月与 2022 年 10 月,特斯拉先后从车辆配置中移除毫米波雷达与超声波传感器,正式走 上纯视觉方案,其主要原因为特斯拉认为既然人类能够利用眼睛和大脑驾驶汽车,那么只要给汽车配置相应性能的视觉设备与运算系统,汽车自动驾驶能力就不会弱于人类驾驶员。此外,纯视觉方案大幅降低了自 动驾驶硬件的成本,有助于实现更好的销量,而销量的提升将帮助特斯 拉收集到更多行车数据,算法迭代速度提升,进而使特斯拉迅速取得自 动驾驶行业领先地位。
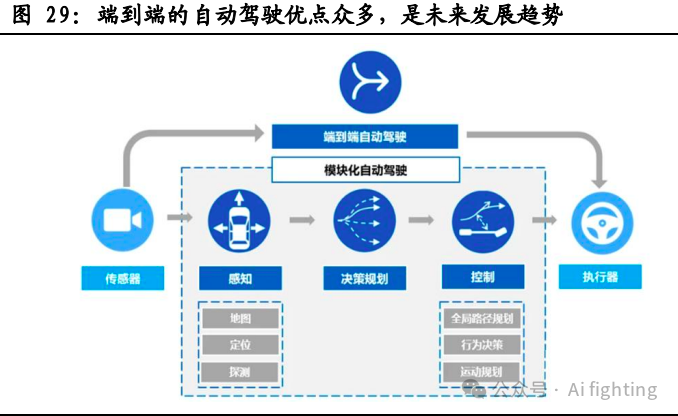
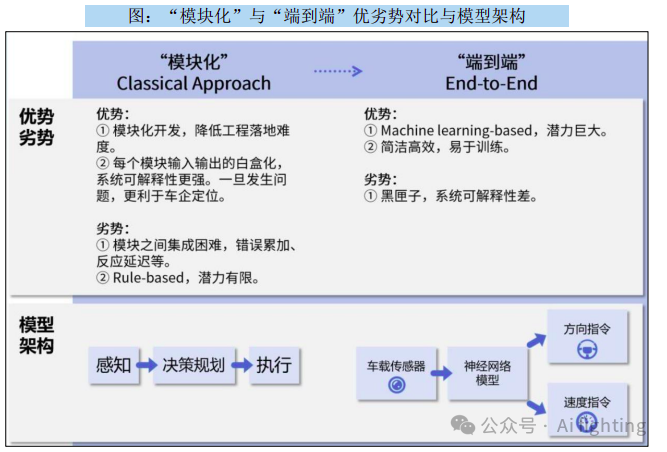
FSD V12 将完全实现端到端大模型,车辆行驶将更具拟人化。
2024年1月,特斯拉推出FSD V12 Beta,算法进入"端到端"阶段. 同时,FSD V12 Beta 是全球第一个实现 "端到端"的AI自动驾驶系统(Full AI End-to-End)。
在此之前,特斯拉采取的"模块化"技术路线,即每 个模块负责特定问题,独立进行开发和训练,然后再 将不同模块系统集成以完成自动驾驶任务。而新推出 的"端到端"技术路线实现了从多维传感器数据输入, 直到操作指令输出的整个流程;一方面将感知、预测、 规划的多模型组合架构变成了"感知决策一体化"的 单模型架构,简化系统,减少错误传递,另一方面让 神经网络完全代替了人工规则编写,替换掉了超过30 万行C++代码,实现了从规则驱动到数据驱动的转变。
FSD 技术将延伸应用至特斯拉人形机器人 Optimus
2021 年 8 月,特斯 拉在 AI 日上发布人形机器人概念图及视频,宣布特斯拉通用机器人计 划。2022 年 9 月 AI 日特斯拉 Optimus 原型机首次现身,特斯拉人形机 器人正加速推进。与自动驾驶汽车一样,人型机器人同样需要具备环境 感知、道路规划、障碍物躲避等能力,FSD 技术的深厚积累将帮助特斯 拉在人形机器人领域建立领先优势。

引用:
国泰君安自动驾驶研究报告
国信证券汽车智能化系列
AiFighing是全网第一且唯一分享自动驾驶实战,以代码、项目的形式讲解自动驾驶感知方向的关键技术,从算法训练到模型部署。
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。